前言
序言
如果你拿起这本书,你可能已经意识到深度学习在最近对人工智能领域所代表的非凡进步。我们从几乎无法使用的计算机视觉和自然语言处理发展到了在你每天使用的产品中大规模部署的高性能系统。这一突然进步的后果几乎影响到了每一个行业。我们已经将深度学习应用于几乎每个领域的重要问题,跨越了医学影像、农业、自动驾驶、教育、灾害预防和制造等不同领域。
然而,我认为深度学习仍处于早期阶段。到目前为止,它只实现了其潜力的一小部分。随着时间的推移,它将走向能够帮助的每一个问题——这是一个需要多年时间才能实现的转变。
为了开始将深度学习技术应用于它能解决的每一个问题,我们需要让尽可能多的人能够访问它,包括非专家——那些不是研究人员或研究生的人。为了使深度学习发挥其全部潜力,我们需要彻底实现其民主化。如今,我相信我们正处于一个历史性转变的关键时刻,深度学习正在从学术实验室和大型科技公司的研发部门走向成为每个开发者工具箱中不可或缺的一部分——不同于上世纪 90 年代末网页开发的轨迹。现在几乎任何人都可以建立一个网站或网络应用程序,而在 1998 年,这需要一个小团队的专业工程师。在不久的将来,任何有想法和基本编码技能的人都将能够构建能够从数据中学习的智能应用程序。
当我在 2015 年 3 月发布了 Keras 深度学习框架的第一个版本时,AI 的民主化并不是我考虑的问题。我已经在机器学习领域做了几年的研究,并建立了 Keras 来帮助我进行实验。但自 2015 年以来,成千上万的新人进入了深度学习领域;其中许多人选择了 Keras 作为他们的首选工具。当我看到许多聪明的人以出乎意料的强大方式使用 Keras 时,我开始非常关心 AI 的可访问性和民主化。我意识到,我们传播这些技术的范围越广,它们就变得越有用和有价值。可访问性很快成为 Keras 开发中的一个明确目标,在短短几年内,Keras 开发者社区在这方面取得了巨大成就。我们让成千上万的人掌握了深度学习,这些人又在使用它来解决直到最近被认为是无法解决的问题。
你手中的这本书是让尽可能多的人了解深度学习的又一步。Keras 一直需要一个伴随课程,同时涵盖深度学习的基础知识、深度学习最佳实践和 Keras 的使用模式。在 2016 年和 2017 年,我尽力制作了这样一门课程,成为了这本书的第一版,于 2017 年 12 月发布。它很快成为了一本机器学习畅销书,销量超过了 5 万册,并被翻译成了 12 种语言。
然而,深度学习领域发展迅速。自第一版发布以来,许多重要的发展已经发生——TensorFlow 2 的发布、Transformer 架构的日益流行等。因此,在 2019 年底,我开始更新我的书。最初,我相当天真地认为,它将包含大约 50%的新内容,并且最终长度大致与第一版相同。实际上,在两年的工作后,它变得比第一版长了三分之一以上,大约有 75%的新内容。它不仅仅是一次更新,而是一本全新的书。
我写这本书的重点是尽可能使深度学习背后的概念及其实现变得易于理解。这并不需要我简化任何内容——我坚信深度学习中没有难懂的概念。我希望你会发现这本书有价值,并且能让你开始构建智能应用程序并解决你关心的问题。
致谢
首先,我要感谢 Keras 社区使这本书得以问世。在过去的六年里,Keras 已经发展成拥有数百名开源贡献者和超过一百万用户。你们的贡献和反馈使 Keras 成为今天的样子。
在更个人的层面上,我要感谢我的妻子在开发 Keras 和写作这本书期间给予我的无限支持。
我还要感谢 Google 支持 Keras 项目。看到 Keras 被采用为 TensorFlow 的高级 API 真是太棒了。Keras 和 TensorFlow 之间的顺畅集成极大地使 TensorFlow 用户和 Keras 用户受益,并使深度学习对大多数人都变得可访问。
我要感谢 Manning 出版社的工作人员,使这本书得以问世:出版商 Marjan Bace 以及编辑和制作团队的每一位,包括 Michael Stephens、Jennifer Stout、Aleksandar Dragosavljević 等许多在幕后工作的人。
特别感谢技术同行审阅者:Billy O’Callaghan、Christian Weisstanner、Conrad Taylor、Daniela Zapata Riesco、David Jacobs、Edmon Begoli、Edmund Ronald 博士、Hao Liu、Jared Duncan、Kee Nam、Ken Fricklas、Kjell Jansson、Milan Šarenac、Nguyen Cao、Nikos Kanakaris、Oliver Korten、Raushan Jha、Sayak Paul、Sergio Govoni、Shashank Polasa、Todd Cook 以及 Viton Vitanis,以及所有其他向我们反馈书稿的人。
在技术方面,特别感谢担任本书技术编辑的 Frances Buontempo,以及担任本书技术校对的 Karsten Strøbæk。
关于这本书
这本书是为任何希望从零开始探索深度学习或扩展对深度学习理解的人而写的。无论你是实践中的机器学习工程师、软件开发人员还是大学生,你都会在这些页面中找到价值。
你将以一种易于理解的方式探索深度学习——从简单开始,然后逐步掌握最先进的技术。你会发现这本书在直觉、理论和实践之间取得了平衡。它避免使用数学符号,而是更倾向于通过详细的代码片段和直观的心智模型解释机器学习和深度学习的核心思想。你将从丰富的代码示例中学习,其中包括广泛的评论、实用建议以及关于开始使用深度学习解决具体问题所需了解的一切的简单高层解释。
代码示例使用 Python 深度学习框架 Keras,以 TensorFlow 2 作为其数值引擎。它们展示了截至 2021 年的现代 Keras 和 TensorFlow 2 最佳实践。
阅读完这本书后,你将对深度学习是什么、何时适用以及其局限性有扎实的理解。你将熟悉处理和解决机器学习问题的标准工作流程,并且知道如何解决常见问题。你将能够使用 Keras 处理从计算机视觉到自然语言处理的真实问题:图像分类、图像分割、时间序列预测、文本分类、机器翻译、文本生成等等。
谁应该阅读这本书
这本书是为具有 Python 编程经验且想开始学习机器学习和深度学习的人而写的。但这本书也对许多不同类型的读者有价值:
-
如果您是熟悉机器学习的数据科学家,本书将为您提供对深度学习的坚实、实用的介绍,这是机器学习中增长最快、最重要的子领域。
-
如果您是一名深度学习研究人员或从业者,希望开始使用 Keras 框架,您会发现本书是理想的 Keras 入门课程。
-
如果您是在正式环境中学习深度学习的研究生,您会发现本书是对您教育的实用补充,帮助您建立对深度神经网络行为的直觉,并让您熟悉关键的最佳实践。
即使是不经常编码的技术人员,也会发现本书对基本和高级深度学习概念的介绍很有用。
为了理解代码示例,您需要具备合理的 Python 熟练程度。此外,熟悉 NumPy 库将会有所帮助,尽管不是必需的。您不需要有机器学习或深度学习的先前经验:本书从头开始覆盖了所有必要的基础知识。您也不需要有高级数学背景,高中水平的数学知识应该足以让您跟上。
关于代码
本书包含许多源代码示例,既在编号列表中,也在普通文本中。在这两种情况下,源代码都以固定宽度 字体 的形式 呈现,以将其与普通文本分开。
在许多情况下,原始源代码已经被重新格式化;我们添加了换行符并重新调整了缩进以适应书中可用的页面空间。此外,在文本中描述代码时,源代码中的注释通常会从列表中删除。代码注释伴随着许多列表,突出显示重要概念。
本书中的所有代码示例都可以从 Manning 网站 www.manning.com/books/deep-learning-with-python-second-edition 获取,并且作为 Jupyter notebooks 在 GitHub github.com/fchollet/deep-learning-with-python-notebooks 上提供。您可以直接在浏览器中通过 Google Colaboratory 运行它们,这是一个免费使用的托管 Jupyter notebook 环境。您只需要互联网连接和桌面网络浏览器即可开始深度学习。
关于作者
 | 弗朗瓦·肖莱是 Keras 的创始人,这是最广泛使用的深度学习框架之一。他目前是 Google 的软件工程师,负责领导 Keras 团队。此外,他还在研究抽象、推理以及如何在人工智能中实现更大的普适性。 |
|---|
关于封面插图
Python 深度学习第二版封面上的人物题为“1568 年波斯女士的习惯”。这幅插图取自托马斯·杰弗里斯(Thomas Jefferys)的《不同国家古代和现代服饰集》(四卷本),伦敦,1757 年至 1772 年出版。封面上说明这些是手工上色的铜版画,使用了胶质增白。
托马斯·杰弗里斯(1719-1771)被称为“乔治三世国王的地理学家”。他是当时主要的地图供应商,为政府和其他官方机构刻制和印刷地图,并制作了各种商业地图和地图集,尤其是北美地区的地图。他作为地图制作者的工作引发了对他测绘和绘制地图的土地的本地服装习俗的兴趣,这些习俗在这个收藏中得到了精彩展示。对遥远土地的着迷和为了愉悦而旅行是 18 世纪末相对较新的现象,这样的收藏品很受欢迎,向游客和坐在家里的旅行者介绍了其他国家的居民。
杰弗里斯(Jefferys)的作品中的多样化插图生动地展示了大约 200 年前世界各国的独特性和个性。自那时以来,着装规范已经发生了变化,当时如此丰富的地区和国家的多样性已经消失。现在很难区分一个大陆的居民和另一个大陆的居民。也许,试图乐观地看待,我们已经用更加多样化的个人生活,或者更加多样化和有趣的智力和技术生活来交换文化和视觉多样性。
在很难区分一本计算机书籍和另一本计算机书籍的时候,曼宁(Manning)通过基于两个世纪前丰富多样的地区生活的书籍封面,重新展现了杰弗里斯(Jefferys)的插图所呈现的丰富多样性,来庆祝计算机行业的创造力和主动性。
一、什么是深度学习?
本章涵盖
-
基本概念的高级定义
-
机器学习发展的时间线
-
深度学习日益普及和未来潜力背后的关键因素
在过去几年中,人工智能(AI)一直是媒体炒作的对象。机器学习、深度学习和人工智能在无数文章中出现,通常是在技术类出版物之外。我们被承诺一个智能聊天机器人、自动驾驶汽车和虚拟助手的未来——有时被描绘成一个阴暗的未来,有时被描绘成乌托邦,人类的工作将变得稀缺,大部分经济活动将由机器人或人工智能代理处理。对于一个未来或现在从事机器学习的从业者来说,能够辨别出噪音中的信号是很重要的,这样你就可以从被炒作的新闻稿中找出改变世界的发展。我们的未来岌岌可危,这是一个你有积极参与的未来:阅读完本书后,你将成为那些开发这些人工智能系统的人之一。所以让我们来解决这些问题:深度学习到目前为止取得了什么成就?它有多重要?我们接下来将走向何方?你应该相信这种炒作吗?
本章提供了围绕人工智能、机器学习和深度学习的基本背景。
1.1 人工智能、机器学习和深度学习
首先,当我们提到人工智能时,我们需要清楚地定义我们所讨论的内容。人工智能、机器学习和深度学习是什么(见图 1.1)?它们之间的关系是怎样的?
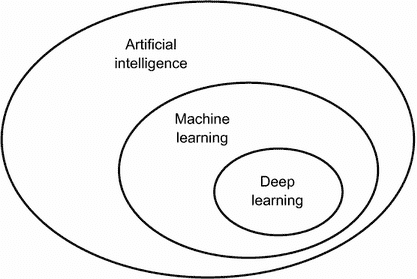
图 1.1 人工智能、机器学习和深度学习
1.1.1 人工智能
人工智能诞生于 20 世纪 50 年代,当时一小群计算机科学领域的先驱开始思考计算机是否能够“思考”——这个问题的影响至今仍在探索中。
尽管许多潜在的想法在之前的几年甚至几十年中一直在酝酿,“人工智能”最终在 1956 年作为一个研究领域得以凝结,当时约翰·麦卡锡(John McCarthy)在达特茅斯学院(Dartmouth College)担任年轻的数学助理教授,组织了一个夏季研讨会,提出了以下建议:
这项研究的基础是一个假设,即学习的每个方面或智能的任何其他特征原则上都可以被描述得如此精确,以至于可以制造一台机器来模拟它。我们将尝试找出如何使机器使用语言,形成抽象和概念,解决目前仅保留给人类的问题,并改进自己。我们认为,如果一组精心挑选的科学家们在一起为此工作一个夏天,就可以在这些问题中的一个或多个问题上取得重大进展。
夏天结束时,研讨会没有完全解决它旨在调查的谜团。然而,许多参与者后来成为该领域的先驱,并引发了一场至今仍在进行的知识革命。
简而言之,人工智能可以被描述为自动执行人类通常执行的智力任务的努力。因此,人工智能是一个涵盖机器学习和深度学习的广泛领域,但也包括许多不涉及任何学习的方法。考虑到直到 1980 年代,大多数人工智能教科书根本没有提到“学习”!例如,早期的下棋程序只涉及由程序员精心制作的硬编码规则,并不符合机器学习的条件。事实上,相当长一段时间,大多数专家认为,通过让程序员手工制作足够大量的明确规则来操作存储在明确数据库中的知识,就可以实现人类水平的人工智能。这种方法被称为符号人工智能。它是从 1950 年代到 1980 年代末的人工智能中的主导范式,并在 1980 年代的专家系统繁荣期达到了其最高流行度。
尽管符号人工智能适用于解决定义明确的逻辑问题,例如下棋,但发现解决更复杂、模糊问题的明确规则是困难的,例如图像分类、语音识别或自然语言翻译。出现了一种新的方法来取代符号人工智能:机器学习。
1.1.2 机器学习
在维多利亚时代的英格兰,艾达·洛夫莱斯夫人是查尔斯·巴贝奇的朋友和合作者,他是第一台已知的通用机械计算机——分析引擎的发明者。尽管分析引擎具有远见卓识,超前于其时代,但在 1830 年代和 1840 年代设计时,并不是作为通用计算机,因为通用计算的概念尚未被发明。它只是作为一种使用机械操作来自动执行数学分析领域中某些计算的方式——因此得名为分析引擎。因此,它是早期尝试将数学运算编码为齿轮形式的智力后代,例如帕斯卡计算器或莱布尼茨的步进计算器,后者是帕斯卡计算器的改进版本。由布莱斯·帕斯卡于 1642 年(19 岁时!)设计,帕斯卡计算器是世界上第一台机械计算器——它可以加法、减法、乘法,甚至除法。
1843 年,艾达·洛夫莱斯评论了分析引擎的发明,
分析引擎根本没有创造任何东西的意图。它只能执行我们知道如何命令它执行的任务……它的职责是帮助我们利用我们已经熟悉的东西。
即使有着 178 年的历史视角,洛夫莱斯夫人的观察仍然令人震撼。通用计算机是否能“创造”任何东西,或者它是否总是被束缚在我们人类完全理解的过程中?它是否能够产生任何原创思想?它是否能够从经验中学习?它是否能展现创造力?
她的言论后来被人工智能先驱艾伦·图灵在他 1950 年的里程碑论文“计算机与智能”中引用为“洛夫莱斯夫人的反对意见”,该论文引入了图灵测试以及后来塑造人工智能的关键概念。图灵当时认为——这在当时是极具挑衅性的——计算机原则上可以模拟人类智能的所有方面。
让计算机执行有用工作的通常方法是让人类程序员编写规则——一个计算机程序——以将输入数据转换为适当的答案,就像洛夫莱斯夫人为分析引擎编写逐步指令一样。机器学习将这个过程颠倒过来:机器查看输入数据和相应的答案,并找出规则应该是什么(见图 1.2)。机器学习系统是训练而不是明确编程的。它被呈现许多与任务相关的示例,并在这些示例中找到统计结构,最终使系统能够提出自动化任务的规则。例如,如果您希望自动化标记您的度假照片的任务,您可以向机器学习系统提供许多已由人类标记的图片示例,系统将学习将特定图片与特定标签相关联的统计规则。
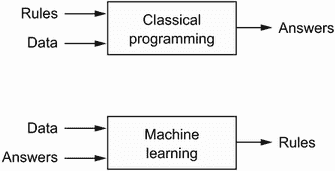
图 1.2 机器学习:一种新的编程范式
尽管机器学习在 1990 年代才开始蓬勃发展,但它迅速成为人工智能中最受欢迎和最成功的子领域,这一趋势受到更快硬件和更大数据集的推动。机器学习与数理统计有关,但在几个重要方面与统计学不同,就像医学与化学有关但不能简化为化学一样,因为医学处理具有独特属性的独特系统。与统计学不同,机器学习往往处理大型、复杂的数据集(例如包含数百万图像的数据集,每个图像由数万像素组成),传统的统计分析如贝叶斯分析在这种情况下将不切实际。因此,机器学习,尤其是深度学习,展示了相对较少的数学理论——也许太少了——并且基本上是一门工程学科。与理论物理或数学不同,机器学习是一个非常实践的领域,受到经验发现的驱动,并且深度依赖于软件和硬件的进步。
1.1.3 从数据中学习规则和表示
要定义深度学习并了解深度学习与其他机器学习方法的区别,首先我们需要对机器学习算法的工作原理有一些了解。我们刚刚说过,机器学习发现执行数据处理任务的规则,给定预期的示例。因此,要进行机器学习,我们需要三样东西:
-
输入数据点——例如,如果任务是语音识别,这些数据点可以是人们说话的声音文件。如果任务是图像标记,它们可以是图片。
-
预期输出的示例——在语音识别任务中,这些可以是人类生成的声音文件转录。在图像任务中,预期输出可以是“狗”、“猫”等标签。
-
衡量算法表现的方法——这是为了确定算法当前输出与预期输出之间的距离。该测量用作反馈信号,以调整算法的工作方式。这个调整步骤就是我们所说的学习。
机器学习模型将其输入数据转换为有意义的输出,这个过程是从已知输入和输出示例中“学习”的。因此,机器学习和深度学习的核心问题是有意义地转换数据:换句话说,学习输入数据的有用表示——这些表示使我们更接近预期的输出。
在我们继续之前:什么是表示?在其核心,它是查看数据的不同方式——表示或编码数据。例如,彩色图像可以用 RGB 格式(红-绿-蓝)或 HSV 格式(色调-饱和度-值)编码:这是相同数据的两种不同表示。一些在一种表示中可能困难的任务,在另一种表示中可能变得简单。例如,“选择图像中的所有红色像素”任务在 RGB 格式中更简单,而“使图像饱和度降低”在 HSV 格式中更简单。机器学习模型的全部内容都是找到适合其输入数据的适当表示——使数据更适合手头任务的转换。
让我们具体化一下。考虑一个x轴,一个y轴,以及一些通过它们在(x, y)系统中的坐标表示的点,如图 1.3 所示。
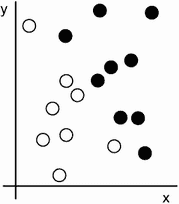
图 1.3 一些示例数据
正如你所看到的,我们有一些白点和一些黑点。假设我们想开发一个算法,可以接受一个点的坐标(x, y)并输出该点可能是黑色还是白色。在这种情况下,
-
输入是我们点的坐标。
-
预期的输出是我们点的颜色。
-
衡量我们的算法是否做得好的一种方法可能是,例如,被正确分类的点的百分比。
我们需要的是我们数据的一个新表示,清晰地将白点与黑点分开。我们可以使用的一种转换,除了许多其他可能性之外,是一个坐标变换,如图 1.4 所示。
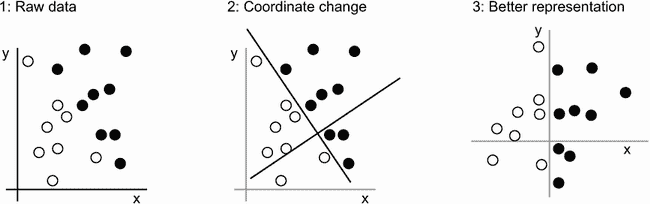
图 1.4 坐标变换
在这个新的坐标系中,我们点的坐标可以说是我们数据的新表示。而且这是一个好的表示!通过这个表示,黑/白分类问题可以表达为一个简单的规则:“黑点是那些x>0 的点”,或者“白点是那些x<0 的点”。这个新表示,结合这个简单规则,巧妙地解决了分类问题。
在这种情况下,我们手动定义了坐标变换:我们利用我们的人类智慧提出了我们自己的数据适当表示。对于这样一个极其简单的问题来说这是可以的,但是如果任务是分类手写数字的图像,你能做到同样吗?你能写出明确的、可由计算机执行的图像转换,以阐明 6 和 8 之间的差异,1 和 7 之间的差异,以及各种不同手写之间的差异吗?
这在一定程度上是可能的。基于数字表示的规则,比如“闭环数量”或者垂直和水平像素直方图,可以很好地区分手写数字。但是手动找到这样有用的表示是一项艰苦的工作,而且,正如你可以想象的,由此产生的基于规则的系统是脆弱的——难以维护的噩梦。每当你遇到一个打破你精心考虑的规则的新手写示例时,你将不得不添加新的数据转换和新的规则,同时考虑它们与每个先前规则的互动。
你可能在想,如果这个过程如此痛苦,我们能自动化吗?如果我们尝试系统地搜索不同集合的自动生成的数据表示和基于它们的规则,通过使用一些开发数据集中被正确分类的数字的百分比作为反馈来识别好的表示,我们将会进行机器学习。学习,在机器学习的背景下,描述了一种自动搜索数据转换的过程,产生一些有用的数据表示,通过一些反馈信号引导——这些表示适合于解决手头任务的简单规则。
这些转换可以是坐标变换(就像我们的 2D 坐标分类示例中),或者是取像素直方图并计算循环次数(就像我们的数字分类示例中),但它们也可以是线性投影、平移、非线性操作(比如“选择所有* x > 0 的点”)等。机器学习算法通常不会在发现这些转换时具有创造性;它们只是在预定义的一组操作中搜索,称为假设空间*。例如,在 2D 坐标分类示例中,所有可能的坐标变换空间将是我们的假设空间。
所以,简洁地说,机器学习就是在预定义的可能性空间内,通过反馈信号的指导,搜索一些输入数据的有用表示和规则。这个简单的想法允许解决一系列广泛的智力任务,从语音识别到自动驾驶。
现在你明白了我们所说的学习是什么意思,让我们看看深度学习有什么特别之处。
1.1.4 “深度学习”中的“深度”
深度学习是机器学习的一个特定子领域:一种从数据中学习表示的新方法,强调学习逐渐具有意义的表示的连续层。 “深度学习”中的“深度”并不是指这种方法所达到的更深层次的理解;相反,它代表了这种连续表示层的概念。对数据模型有多少层贡献被称为模型的深度。该领域的其他适当名称可能是分层表示学习或层次表示学习。现代深度学习通常涉及数十甚至数百个连续的表示层,它们都是通过暴露于训练数据中自动学习的。与此同时,其他机器学习方法往往专注于学习数据的一两层表示(比如,获取像素直方图然后应用分类规则);因此,它们有时被称为浅层学习。
在深度学习中,这些分层表示是通过称为神经网络的模型学习的,这些模型以字面意义上相互堆叠的层结构。术语“神经网络”指的是神经生物学,但尽管深度学习中的一些核心概念部分是通过从我们对大脑的理解中汲取灵感而发展的(特别是视觉皮层),深度学习模型并不是大脑的模型。没有证据表明大脑实现了任何类似于现代深度学习模型中使用的学习机制。你可能会看到一些流行科学文章宣称深度学习如何像大脑工作或是模仿大脑,但事实并非如此。对于新手来说,将深度学习与神经生物学有任何关联是令人困惑和适得其反的;你不需要那种“就像我们的思维一样”的神秘感和神秘性,你可能会忘记任何你可能读到的关于深度学习和生物学之间假设联系的内容。对于我们的目的,深度学习是从数据中学习表示的数学框架。
深度学习算法学习的表示是什么样子的?让我们看看一个几层深的网络(见图 1.5)如何转换图像以识别出是哪个数字。

图 1.5 数字分类的深度神经网络
正如你在图 1.6 中看到的,网络将数字图像转换为与原始图像越来越不同且越来越有关于最终结果的信息的表示。你可以将深度网络看作是一个多阶段的信息提炼过程,其中信息通过连续的滤波器并最终纯化(即,对某个任务有用)出来。

图 1.6 由数字分类模型学习到的数据表示
所以从技术上讲,这就是深度学习:学习数据表示的多阶段方式。这是一个简单的想法—但事实证明,非常简单的机制,足够扩展,最终看起来像魔术。
1.1.5 通过三个图形理解深度学习的工作原理
到目前为止,你知道机器学习是关于将输入(如图像)映射到目标(如标签“猫”),这是通过观察许多输入和目标示例来完成的。你还知道深度神经网络通过一系列简单的数据转换(层)的深度序列来实现这种输入到目标的映射,并且这些数据转换是通过示例学习的。现在让我们具体看看这个学习是如何进行的。
层对输入数据执行的操作规范存储在层的权重中,本质上是一堆数字。在技术术语中,我们会说层实现的转换是由其权重参数化的(见图 1.7)。(权重有时也称为层的参数。)在这个背景下,学习意味着找到网络中所有层的权重的一组值,使网络能够正确地将示例输入映射到它们关联的目标。但问题在于:一个深度神经网络可能包含数千万个参数。找到所有这些参数的正确值可能看起来像一项艰巨的任务,特别是考虑到修改一个参数的值将影响所有其他参数的行为!

图 1.7 一个神经网络由其权重参数化。
要控制某物,首先你需要能够观察它。要控制神经网络的输出,你需要能够衡量这个输出与你期望的结果有多大差距。这就是网络的损失函数的工作,有时也称为目标函数或成本函数。损失函数接受网络的预测和真实目标(你希望网络输出的内容)并计算一个距离分数,捕捉网络在这个特定示例上表现如何(见图 1.8)。
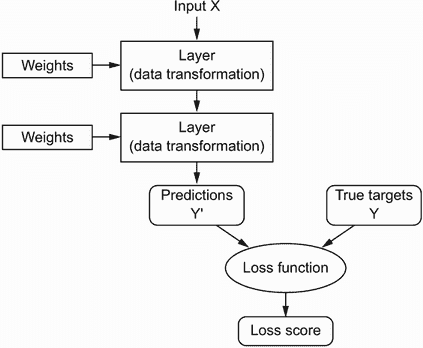
图 1.8 损失函数衡量网络输出的质量。
深度学习中的基本技巧是使用这个分数作为反馈信号,稍微调整权重的值,以降低当前示例的损失分数(见图 1.9)。这种调整是优化器的工作,它实现了所谓的反向传播算法:深度学习中的核心算法。下一章将更详细地解释反向传播的工作原理。

图 1.9 损失分数被用作反馈信号来调整权重。
最初,网络的权重被分配随机值,因此网络仅实现一系列随机转换。自然地,它的输出与理想情况相去甚远,损失分数相应地非常高。但随着网络处理每个示例,权重会稍微朝正确方向调整,损失分数会减少。这就是训练循环,重复足够多次(通常是数千个示例的数十次迭代),得到最小化损失函数的权重值。具有最小损失的网络是输出尽可能接近目标的网络:一个经过训练的网络。再一次,这是一个简单的机制,一旦扩展,最终看起来像魔术。
1.1.6 到目前为止深度学习取得了什么成就
尽管深度学习是机器学习的一个相当古老的子领域,但直到 2010 年代初才开始崭露头角。在此后的几年里,它在领域中取得了一场革命性的成就,对感知任务甚至自然语言处理任务产生了显著的结果——这些问题涉及到对人类似乎自然和直观的技能,但长期以来一直是机器难以掌握的。
特别是,深度学习已经在历史上困难的机器学习领域实现了以下突破:
-
近乎人类水平的图像分类
-
近乎人类水平的语音转录
-
近乎人类水平的手写转录
-
大幅改进的机器翻译
-
大幅改进的文本转语音转换
-
诸如 Google Assistant 和 Amazon Alexa 等数字助手
-
近乎人类水平的自动驾驶
-
改进的广告定位,如 Google、百度或必应所使用的
-
网络搜索结果的改进
-
能够回答自然语言问题
-
超人类水平的围棋对弈
我们仍在探索深度学习的全部潜力。我们已经开始将其成功应用于一系列几年前被认为无法解决的问题——自动转录梵蒂冈宗座档案馆中保存的数以万计的古代手稿,使用简单的智能手机检测和分类田间植物疾病,协助肿瘤学家或放射科医生解释医学成像数据,预测洪水、飓风甚至地震等自然灾害等。随着每一个里程碑的实现,我们越来越接近一个时代,在这个时代,深度学习将在人类的每一个活动和领域中协助我们——科学、医学、制造业、能源、交通、软件开发、农业,甚至艺术创作。
1.1.7 不要相信短期炒作
尽管深度学习在近年取得了显著的成就,对于该领域在未来十年能够实现的期望往往比实际可能实现的要高得多。尽管一些像自动驾驶汽车这样改变世界的应用已经近在眼前,但许多其他应用可能在很长一段时间内仍然难以实现,比如可信的对话系统、跨任意语言的人类级机器翻译以及人类级自然语言理解。特别是,对于短期内实现人类级通用智能的讨论不应该太过认真。对于短期内高期望的风险在于,随着技术无法交付,研究投资将枯竭,长期减缓进展。
这种情况已经发生过。在过去的两次中,人工智能经历了一轮强烈的乐观主义,随后是失望和怀疑,导致资金短缺。它始于 20 世纪 60 年代的符号人工智能。在那些早期,关于人工智能的预测飞得很高。符号人工智能方法中最著名的先驱和支持者之一是马文·明斯基,他在 1967 年声称:“在一代人内……创造‘人工智能’的问题将得到实质性解决。”三年后,即 1970 年,他做出了更为精确的预测:“在三到八年内,我们将拥有一台具有普通人类智能的机器。”到 2021 年,这样的成就似乎仍然遥不可及——远远超出我们无法预测需要多长时间才能实现的范围——但在 20 世纪 60 年代和 70 年代初,一些专家相信这一成就就在眼前(就像今天的许多人一样)。几年后,随着这些高期望未能实现,研究人员和政府资金转向其他领域,标志着第一次人工智能寒冬的开始(这是对核冬天的一个参考,因为这是在冷战的高峰之后不久)。
这不会是最后一个。在 20 世纪 80 年代,一种新的符号人工智能专家系统开始在大公司中蓬勃发展。一些最初的成功案例引发了一波投资热潮,全球各地的公司开始建立自己的内部人工智能部门来开发专家系统。到 1985 年左右,公司每年在这项技术上的支出超过 10 亿美元;但到了 90 年代初,这些系统已经被证明难以维护、难以扩展和范围有限,兴趣逐渐消退。于是第二次人工智能寒冬开始了。
我们可能目前正在见证人工智能炒作和失望的第三个周期,我们仍处于强烈乐观的阶段。最好是对短期期望保持适度,确保对该领域技术方面不太熟悉的人清楚了解深度学习能够做什么和不能做什么。
1.1.8 人工智能的承诺
尽管我们可能对人工智能有着不切实际的短期期望,但长期前景看起来是光明的。我们才刚刚开始将深度学习应用于许多重要问题,这些问题可能会发生转变,从医学诊断到数字助手。过去十年来,人工智能研究取得了惊人的快速进展,这在很大程度上是由于人工智能短暂历史中前所未有的资金水平,但迄今为止,这些进展中相对较少的部分已经应用到构成我们世界的产品和流程中。深度学习的大部分研究成果尚未得到应用,或者至少没有应用到它们可以解决的所有行业的所有问题范围内。你的医生还没有使用人工智能,你的会计师也没有。在日常生活中,你可能并不经常使用人工智能技术。当然,你可以向智能手机提出简单问题并得到合理的答案,你可以在 Amazon.com 上获得相当有用的产品推荐,你可以在 Google 照片中搜索“生日”并立即找到上个月女儿生日派对的照片。这与这些技术过去所处的位置相去甚远。但这些工具仍然只是我们日常生活的附件。人工智能尚未过渡到成为我们工作、思考和生活方式的核心。
现在,也许很难相信人工智能会对我们的世界产生巨大影响,因为它尚未被广泛应用——就像在 1995 年,很难相信互联网未来的影响一样。那时,大多数人并没有看到互联网对他们的相关性以及它将如何改变他们的生活。对于今天的深度学习和人工智能也是如此。但不要误解:人工智能即将到来。在不久的将来,人工智能将成为你的助手,甚至是你的朋友;它将回答你的问题,帮助教育你的孩子,并关注你的健康。它将把你的杂货送到家门口,并把你从 A 点开车到 B 点。它将成为你与日益复杂和信息密集的世界接触的接口。更重要的是,人工智能将帮助整个人类向前迈进,通过协助人类科学家在所有科学领域中进行新的突破性发现,从基因组学到数学。
在这个过程中,我们可能会遇到一些挫折,甚至可能会迎来新的人工智能寒冬——就像互联网行业在 1998-99 年被过度炒作并遭受了一场导致在 2000 年代初期投资枯竭的崩溃一样。但我们最终会到达那里。人工智能最终将应用于构成我们社会和日常生活的几乎每一个过程,就像互联网今天一样。
不要相信短期炒作,但要相信长期愿景。人工智能可能需要一段时间才能发挥其真正潜力——一个全面程度还没有人敢于梦想的潜力——但人工智能即将到来,它将以一种奇妙的方式改变我们的世界。
1.2 在深度学习之前:机器学习的简史
深度学习已经达到了公众关注和行业投资的水平,这在人工智能历史上从未见过,但它并不是机器学习的第一个成功形式。可以肯定地说,今天工业中使用的大多数机器学习算法并不是深度学习算法。深度学习并不总是解决问题的正确工具——有时候数据不足以应用深度学习,有时候问题更适合用不同的算法解决。如果深度学习是你与机器学习的第一次接触,你可能会发现自己处于这样一种情况:你手头只有深度学习的锤子,而每个机器学习问题看起来都像一个钉子。避免陷入这种陷阱的唯一方法是熟悉其他方法,并在适当时练习它们。
对经典机器学习方法的详细讨论超出了本书的范围,但我将简要介绍它们,并描述它们开发的历史背景。这将使我们能够将深度学习置于机器学习更广泛的背景中,并更好地理解深度学习的来源和重要性。
1.2.1 概率建模
概率建模是将统计原理应用于数据分析的过程。它是机器学习的最早形式之一,至今仍然广泛使用。在这一类别中最著名的算法之一是朴素贝叶斯算法。
朴素贝叶斯是一种基于应用贝叶斯定理的机器学习分类器,假设输入数据中的特征都是独立的(这是一个强大或“朴素”的假设,这也是名称的由来)。这种形式的数据分析早在计算机出现之前就存在,并且在首次计算机实现之前就通过手工应用(很可能可以追溯到 20 世纪 50 年代)了。贝叶斯定理和统计学的基础可以让您开始使用朴素贝叶斯分类器。
一个密切相关的模型是逻辑回归(简称 logreg),有时被认为是现代机器学习的“Hello World”。不要被它的名字误导——logreg 是一个分类算法而不是回归算法。与朴素贝叶斯类似,logreg 在计算机出现很久之前就存在了,但由于其简单且多功能的特性,至今仍然很有用。它通常是数据科学家在数据集上尝试的第一件事,以了解手头的分类任务。
1.2.2 早期神经网络
早期的神经网络已经被这些页面中涵盖的现代变体完全取代,但了解深度学习的起源仍然很有帮助。尽管神经网络的核心思想早在 20 世纪 50 年代就以玩具形式进行了研究,但这种方法花了几十年才开始。很长一段时间,缺失的部分是训练大型神经网络的有效方法。这种情况在 20 世纪 80 年代中期发生了变化,当时多人独立重新发现了反向传播算法——一种使用梯度下降优化训练参数化操作链的方法(我们将在本书后面精确定义这些概念)——并开始将其应用于神经网络。
1989 年,贝尔实验室首次成功应用神经网络的实际应用来自杨立昆,他将卷积神经网络和反向传播的早期思想结合起来,并将它们应用于手写数字分类问题。由此产生的网络被称为LeNet,在上世纪 90 年代被美国邮政服务用于自动读取信封上的邮政编码。
1.2.3 核方法
当神经网络在 1990 年代开始在研究人员中获得一些尊重时,由于这一初步成功,一种新的机器学习方法崭露头角,并迅速将神经网络送回到遗忘之中:核方法。核方法是一组分类算法,其中最著名的是支持向量机(SVM)。SVM 的现代形式是由弗拉基米尔·瓦普尼克和 Corinna Cortes 在贝尔实验室于 1990 年代初开发,并于 1995 年发表的,尽管早在 1963 年,瓦普尼克和 Alexey Chervonenkis 就已经发表了一个较早的线性形式。
SVM 是一种分类算法,通过找到分隔两类的“决策边界”来工作(见图 1.10)。SVM 通过两个步骤来找到这些边界:
-
数据被映射到一个新的高维表示,其中决策边界可以表示为一个超平面(如果数据是二维的,如图 1.10,超平面将是一条直线)。
-
通过尝试最大化超平面与每个类别最近数据点之间的距离来计算一个良好的决策边界(一个分离超平面),这一步骤称为最大化间隔。这使得边界能够很好地泛化到训练数据集之外的新样本。

图 1.10 决策边界
将数据映射到高维表示的技术,使得分类问题变得更简单,看起来在理论上很不错,但在实践中通常是计算上难以处理的。这就是核技巧的用武之地(核方法以此命名的关键思想)。这是其要点:为了在新表示空间中找到良好的决策超平面,你不必显式计算点在新空间中的坐标;你只需要计算该空间中点对之间的距离,这可以通过核函数有效地完成。核函数是一种计算上易处理的操作,将初始空间中的任意两点映射到目标表示空间中这些点之间的距离,完全绕过了新表示的显式计算。核函数通常是手工制作而非从数据中学习的——在 SVM 的情况下,只有分离超平面是被学习的。
在它们被开发的时候,SVM 在简单分类问题上表现出色,并且是少数几种机器学习方法之一,具有广泛的理论支持,并且易于进行严格的数学分析,使得它们被充分理解和容易解释。由于这些有用的特性,SVM 在该领域长期以来非常受欢迎。
但 SVM 很难扩展到大型数据集,并且对于感知问题(如图像分类)没有提供良好的结果。因为 SVM 是一种浅层方法,将 SVM 应用于感知问题需要首先手动提取有用的表示(称为特征工程),这是困难且脆弱的。例如,如果你想使用 SVM 来分类手写数字,你不能从原始像素开始;你应该首先手动找到使问题更易处理的有用表示,就像我之前提到的像素直方图一样。
1.2.4 决策树、随机森林和梯度提升机
决策树是类似流程图的结构,让你对输入数据点进行分类或根据输入预测输出值(见图 1.11)。它们易于可视化和解释。从数据中学习的决策树在 2000 年代开始受到重要的研究兴趣,到 2010 年,它们通常被优先于核方法。
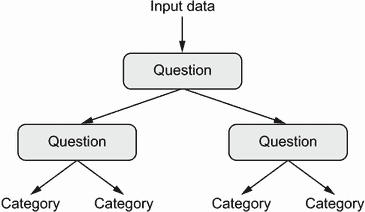
图 1.11 决策树:学习的参数是关于数据的问题。一个问题可能是,“数据中的系数 2 是否大于 3.5?”
特别是随机森林算法引入了一种稳健、实用的决策树学习方法,涉及构建大量专门的决策树,然后将它们的输出组合在一起。 随机森林适用于各种问题——你可以说它们几乎总是任何浅层机器学习任务的第二好算法。 当流行的机器学习竞赛网站 Kaggle (kaggle.com)在 2010 年开始时,随机森林迅速成为该平台上的热门选择,直到 2014 年,梯度提升机取代了它。 梯度提升机与随机森林类似,是一种基于集成弱预测模型的机器学习技术,通常是决策树。 它使用梯度提升,一种通过迭代训练新模型来改进任何机器学习模型的方法,这些新模型专门解决前一模型的弱点。 应用于决策树时,使用梯度提升技术会导致大多数情况下严格优于随机森林的模型,同时具有类似的性质。 它可能是处理非感知数据的最佳算法之一,如果不是最佳的话。 与深度学习并列,它是 Kaggle 竞赛中最常用的技术之一。
1.2.5 回到神经网络
大约在 2010 年,尽管神经网络几乎被科学界完全忽视,但仍有一些人在神经网络上取得重要突破:多伦多大学的 Geoffrey Hinton 小组,蒙特利尔大学的 Yoshua Bengio 小组,纽约大学的 Yann LeCun 小组,以及瑞士的 IDSIA。
2011 年,来自 IDSIA 的 Dan Ciresan 开始使用 GPU 训练的深度神经网络赢得学术图像分类竞赛——这是现代深度学习的第一个实际成功案例。 但转折点发生在 2012 年,当 Hinton 的小组参加了每年一次的大规模图像分类挑战 ImageNet(ImageNet 大规模视觉识别挑战,简称 ILSVRC)。 当时,ImageNet 挑战非常困难,包括在训练了 140 万张图像后,将高分辨率彩色图像分类为 1,000 个不同类别。 2011 年,基于传统计算机视觉方法的获胜模型的前五准确率仅为 74.3%。⁵ 然后,在 2012 年,由 Alex Krizhevsky 领导并由 Geoffrey Hinton 指导的团队取得了 83.6%的前五准确率——这是一个重大突破。 从那时起,每年的比赛都被深度卷积神经网络所主导。 到 2015 年,获胜者的准确率达到 96.4%,而 ImageNet 上的分类任务被认为是一个完全解决的问题。
自 2012 年以来,深度卷积神经网络(convnets)已成为所有计算机视觉任务的首选算法;更一般地,它们适用于所有感知任务。 在 2015 年之后的任何一次重要计算机视觉会议上,几乎不可能找到不涉及 convnets 的演示。 与此同时,深度学习还在许多其他类型的问题中找到了应用,如自然语言处理。 它已经完全取代了 SVM 和决策树在许多应用中的使用。 例如,多年来,欧洲核子研究组织 CERN 一直使用基于决策树的方法来分析大型强子对撞机(LHC)上 ATLAS 探测器的粒子数据,但最终 CERN 转而使用基于 Keras 的深度神经网络,因为它们在大型数据集上具有更高的性能和训练的便利性。
1.2.6 深度学习的不同之处
深度学习之所以迅速崛起的主要原因是它在许多问题上提供了更好的性能。但这并不是唯一的原因。深度学习还使问题解决变得更加容易,因为它完全自动化了曾经是机器学习工作流程中最关键的步骤:特征工程。
以前的机器学习技术——浅层学习——只涉及将输入数据转换为一两个连续的表示空间,通常通过简单的转换,如高维非线性投影(SVM)或决策树。但复杂问题所需的精细表示通常无法通过这种技术实现。因此,人们不得不费尽心思地使初始输入数据更易于通过这些方法处理:他们必须手动为数据工程好表示层。这就是所谓的特征工程。另一方面,深度学习完全自动化了这一步骤:通过深度学习,你可以一次性学习所有特征,而不必自己进行工程设计。这大大简化了机器学习工作流程,通常用一个简单的端到端深度学习模型取代了复杂的多阶段流水线。
你可能会问,如果问题的关键在于具有多个连续的表示层,那么浅层方法是否可以重复应用以模拟深度学习的效果?实际上,连续应用浅层学习方法会产生快速递减的回报,因为在三层模型中的最佳第一表示层并不是一层或两层模型中的最佳第一层。深度学习的革命性之处在于它允许模型同时学习所有表示层,而不是按顺序(贪婪地)学习。通过联合特征学习,每当模型调整其内部特征时,所有依赖于它的其他特征都会自动适应变化,而无需人为干预。一切都由单一的反馈信号监督:模型中的每一次变化都服务于最终目标。这比贪婪地堆叠浅层模型更加强大,因为它允许通过将复杂的抽象表示分解为一系列中间空间(层)来学习它们;每个空间与前一个空间之间只有一个简单的转换。
这是深度学习从数据中学习的两个基本特征:逐渐增加、逐层发展越来越复杂的表示方式,以及这些中间逐步增加的表示是联合学习的,每一层都被更新以同时遵循上面一层的表示需求和下面一层的需求。这两个特性共同使深度学习比以前的机器学习方法更加成功。
1.2.7 现代机器学习格局
了解当前机器学习算法和工具的现状的一个好方法是查看 Kaggle 上的机器学习竞赛。由于其高度竞争的环境(一些比赛有数千名参与者和百万美元的奖金)以及涵盖的各种机器学习问题,Kaggle 提供了一个评估什么有效、什么无效的现实方法。那么哪种算法可靠地赢得比赛?顶尖参与者使用什么工具?
2019 年初,Kaggle 进行了一项调查,询问自 2017 年以来在任何比赛中获得前五名的团队使用的主要软件工具是什么(见图 1.12)。结果表明,顶尖团队倾向于使用深度学习方法(通常通过 Keras 库)或梯度提升树(通常通过 LightGBM 或 XGBoost 库)。

图 1.12 Kaggle 顶尖团队使用的机器学习工具
不仅仅是竞赛冠军。Kaggle 还每年对全球机器学习和数据科学专业人士进行调查。有数万名受访者参与,这项调查是我们关于行业状况最可靠的信息来源之一。图 1.13 显示了不同机器学习软件框架的使用百分比。
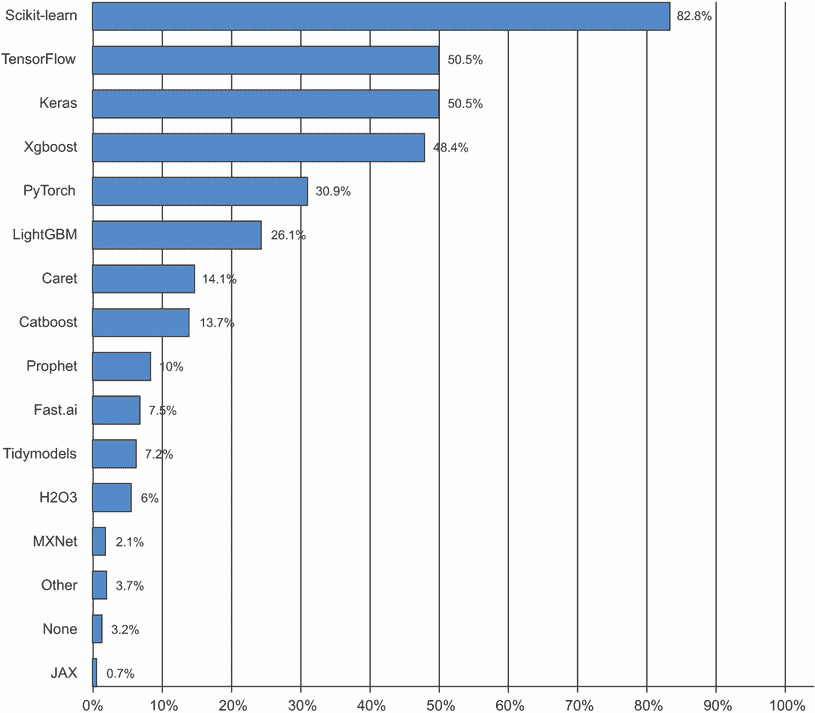
图 1.13 工具在机器学习和数据科学行业中的使用情况(来源:www.kaggle.com/kaggle-survey-2020)
从 2016 年到 2020 年,整个机器学习和数据科学行业都被这两种方法主导:深度学习和梯度提升树。具体来说,梯度提升树用于有结构化数据的问题,而深度学习用于感知问题,如图像分类。
使用梯度提升树的用户倾向于使用 Scikit-learn、XGBoost 或 LightGBM。与此同时,大多数深度学习从业者使用 Keras,通常与其母框架 TensorFlow 结合使用。这些工具的共同点是它们都是 Python 库:Python 是迄今为止机器学习和数据科学中最广泛使用的语言。
这是您今天在应用机器学习中应该最熟悉的两种技术:梯度提升树,用于浅层学习问题;深度学习,用于感知问题。在技术上,这意味着您需要熟悉 Scikit-learn、XGBoost 和 Keras 这三个目前主导 Kaggle 竞赛的库。有了这本书,您已经更接近成功了一大步。
1.3 为什么深度学习?为什么现在?
深度学习在计算机视觉中的两个关键思想——卷积神经网络和反向传播——在 1990 年就已经被充分理解。长短期记忆(LSTM)算法,对于时间序列的深度学习至关重要,于 1997 年开发,至今几乎没有改变。那么为什么深度学习直到 2012 年后才起飞?这两个十年发生了什么变化?
总的来说,有三个技术力量推动了机器学习的进步:
-
硬件
-
数据集和基准测试
-
算法进步
因为该领域是由实验结果而不是理论指导的,只有在适当的数据和硬件可用于尝试新想法(或扩展旧想法,通常情况下)时,算法进步才成为可能。机器学习不是数学或物理学,那里可以用一支笔和一张纸做出重大进步。这是一门工程科学。
20 世纪 90 年代和 2000 年代的真正瓶颈是数据和硬件。但在那段时间发生了什么呢:互联网蓬勃发展,高性能图形芯片为游戏市场的需求而开发。
1.3.1 硬件
从 1990 年到 2010 年,现成的 CPU 速度提高了约 5,000 倍。因此,现在可以在笔记本电脑上运行小型深度学习模型,而在 25 年前这是不可行的。
但是,在计算机视觉或语音识别中使用的典型深度学习模型需要比您的笔记本电脑提供的计算能力高出几个数量级。在 2000 年代,像 NVIDIA 和 AMD 这样的公司投资了数十亿美元开发快速、大规模并行芯片(图形处理单元,或 GPU),以提供越来越逼真的视频游戏图形 - 廉价、单一用途的超级计算机,旨在实时在屏幕上渲染复杂的 3D 场景。当 NVIDIA 于 2007 年推出 CUDA(developer.nvidia.com/about-cuda)时,这项投资开始造福科学界,CUDA 是其 GPU 系列的编程接口。少量 GPU 开始取代各种高度可并行化的应用程序中的大型 CPU 集群,从物理建模开始。由许多小矩阵乘法组成的深度神经网络也是高度可并行化的,大约在 2011 年左右,一些研究人员开始编写神经网络的 CUDA 实现 - 丹·西雷桑⁶和亚历克斯·克里兹赫夫斯基⁷是最早的几位。
发生的事情是游戏市场为下一代人工智能应用程序提供了超级计算的资助。有时,大事情从游戏开始。如今,NVIDIA Titan RTX,一款在 2019 年底售价为 2500 美元的 GPU,在单精度(每秒 16 万亿float32操作)方面达到峰值 16 teraFLOPS。这大约是 1990 年世界上最快超级计算机 Intel Touchstone Delta 的 500 倍计算能力。在 Titan RTX 上,只需要几个小时就可以训练出类似于 2012 或 2013 年将赢得 ILSVRC 比赛的 ImageNet 模型。与此同时,大公司在数百个 GPU 的集群上训练深度学习模型。
此外,深度学习行业已经超越了 GPU,正在投资于越来越专门化、高效的深度学习芯片。2016 年,在其年度 I/O 大会上,Google 公布了其张量处理单元(TPU)项目:一种全新的芯片设计,旨在比顶级 GPU 运行深度神经网络更快且更节能。如今,在 2020 年,TPU 卡的第三代代表着 420 teraFLOPS 的计算能力。这比 1990 年的 Intel Touchstone Delta 高出 10,000 倍。
这些 TPU 卡设计为组装成大规模配置,称为“pods”。一个 pod(1024 个 TPU 卡)峰值为 100 petaFLOPS。就规模而言,这大约是当前最大超级计算机 IBM Summit 在奥克岭国家实验室的峰值计算能力的 10%,该计算机由 27,000 个 NVIDIA GPU 组成,峰值约为 1.1 exaFLOPS。
1.3.2 数据
人工智能有时被誉为新的工业革命。如果深度学习是这场革命的蒸汽机,那么数据就是其煤炭:为我们的智能机器提供动力的原材料,没有它什么也不可能。在数据方面,除了过去 20 年存储硬件的指数级进步(遵循摩尔定律)之外,互联网的兴起也是一个改变游戏规则的因素,使得收集和分发非常大的机器学习数据集成为可能。如今,大公司使用图像数据集、视频数据集和自然语言数据集,这些数据集如果没有互联网是无法收集的。例如,Flickr 上用户生成的图像标签一直是计算机视觉的数据宝库。YouTube 视频也是如此。维基百科是自然语言处理的关键数据集。
如果有一个数据集促进了深度学习的崛起,那就是 ImageNet 数据集,包含了 140 万张手动注释的图像,涵盖了 1000 个图像类别(每个图像一个类别)。但是 ImageNet 之所以特别,不仅仅是因为其规模庞大,还因为与之相关的年度竞赛。
正如 Kaggle 自 2010 年以来一直在展示的那样,公开竞赛是激励研究人员和工程师突破界限的绝佳方式。研究人员竞争击败的共同基准已经极大地帮助了深度学习的崛起,突显了其成功与传统机器学习方法的对比。
1.3.3 算法
除了硬件和数据外,直到 2000 年代末,我们一直缺乏一种可靠的方法来训练非常深的神经网络。因此,神经网络仍然相对较浅,只使用一两层表示;因此,它们无法与更精细的浅层方法(如 SVM 和随机森林)相媲美。关键问题在于梯度传播穿过深层堆栈的问题。用于训练神经网络的反馈信号会随着层数的增加而逐渐消失。
这在 2009-2010 年左右发生了变化,凭借几项简单但重要的算法改进,使得更好的梯度传播成为可能:
-
更好的神经层激活函数
-
更好的权重初始化方案,从逐层预训练开始,然后很快被放弃
-
更好的优化方案,如 RMSProp 和 Adam
只有当这些改进开始允许训练具有 10 层或更多层的模型时,深度学习才开始发光。
最终,在 2014 年、2015 年和 2016 年,发现了更先进的改进梯度传播的方法,如批量归一化、残差连接和深度可分离卷积。
如今,我们可以从头开始训练任意深度的模型。这解锁了使用极其庞大模型的可能性,这些模型具有相当大的表征能力,即编码非常丰富的假设空间。这种极端的可扩展性是现代深度学习的定义特征之一。大规模模型架构,具有数十层和数千万参数,已经在计算机视觉(例如 ResNet、Inception 或 Xception 等架构)和自然语言处理(例如大型基于 Transformer 的架构,如 BERT、GPT-3 或 XLNet)方面带来了关键进展。
1.3.4 新一轮投资
随着深度学习在 2012-2013 年成为计算机视觉的新技术标准,最终成为所有感知任务的新标准,行业领袖开始关注。随之而来的是一波逐渐增长的行业投资,远远超出了人工智能历史上此前所见的任何规模(见图 1.14)。

图 1.14 OECD 估计的人工智能初创公司的总投资(来源:mng.bz/zGN6)
在深度学习引起关注之前的 2011 年,全球人工智能风险投资总额不到 10 亿美元,几乎全部投向了浅层机器学习方法的实际应用。到了 2015 年,这一数字已经上升到 50 多亿美元,2017 年更是激增至 160 亿美元。在这几年间,数百家初创公司涌现,试图利用深度学习的热潮。与此同时,谷歌、亚马逊和微软等大型科技公司在内部研究部门的投资金额很可能超过了风险投资资金的流入量。
机器学习——特别是深度学习——已经成为这些科技巨头的产品战略的核心。2015 年底,谷歌 CEO 桑达尔·皮查伊表示:“机器学习是我们重新思考我们如何做一切的核心、变革性方式。我们正在全面应用它,无论是搜索、广告、YouTube 还是 Play。我们还处于早期阶段,但你会看到我们以系统化的方式在所有这些领域应用机器学习。”
由于这波投资浪潮,从事深度学习工作的人数在不到 10 年的时间里从几百人增加到数万人,研究进展达到了疯狂的速度。
1.3.5 深度学习的民主化
推动深度学习中新面孔涌入的一个关键因素是该领域使用的工具集的民主化。在早期,进行深度学习需要大量的 C++和 CUDA 专业知识,而这种专业知识很少有人掌握。
如今,基本的 Python 脚本技能就足以进行高级深度学习研究。这主要得益于现已废弃的 Theano 库的发展,以及 TensorFlow 库——这两个用于 Python 的符号张量操作框架支持自动微分,极大地简化了新模型的实现——以及像 Keras 这样的用户友好库的崛起,使得深度学习就像操纵乐高积木一样简单。在 2015 年初发布后,Keras 迅速成为大量新创企业、研究生和转入该领域的研究人员的首选深度学习解决方案。
1.3.6 它会持续吗?
深度神经网络有什么特别之处,使得它们成为公司投资和研究人员涌入的“正确”选择?或者深度学习只是一个可能不会持续的时尚?20 年后我们还会使用深度神经网络吗?
深度学习具有几个属性,这些属性证明了它作为人工智能革命的地位,并且它将会持续存在。也许 20 年后我们不会再使用神经网络,但无论我们使用什么,都将直接继承现代深度学习及其核心概念。这些重要属性可以广泛分为三类:
-
简单性——深度学习消除了特征工程的需求,用简单的端到端可训练模型取代了复杂、脆弱、工程密集型的流水线,通常仅使用五到六种不同的张量操作构建。
-
可扩展性——深度学习非常适合在 GPU 或 TPU 上并行化,因此可以充分利用摩尔定律。此外,深度学习模型通过迭代小批量数据进行训练,使其能够在任意大小的数据集上进行训练。(唯一的瓶颈是可用的并行计算能力量,由于摩尔定律的存在,这是一个快速移动的障碍。)
-
多功能性和可重用性——与许多先前的机器学习方法不同,深度学习模型可以在不从头开始重新启动的情况下训练额外的数据,使其适用于连续在线学习——这对于非常大的生产模型是一个重要的特性。此外,经过训练的深度学习模型是可重用的:例如,可以将经过图像分类训练的深度学习模型放入视频处理流水线中。这使我们能够将以前的工作重新投资到越来越复杂和强大的模型中。这也使得深度学习适用于相当小的数据集。
深度学习仅仅在聚光灯下曝光了几年,我们可能还没有确定其能够做到的全部范围。随着每一年的过去,我们了解到新的用例和工程改进,这些改进消除了以前的限制。在科学革命之后,进展通常遵循 S 形曲线:它从快速进展的阶段开始,逐渐稳定下来,研究人员遇到严重限制,然后进一步的改进变得渐进式。
当我写第一版这本书时,也就是 2016 年,我预测深度学习仍处于 S 形曲线的上半部,接下来几年将会有更多变革性的进展。实践证明这一点是正确的,因为 2017 年和 2018 年见证了基于 Transformer 的深度学习模型在自然语言处理领域的崛起,这在该领域引起了一场革命,同时深度学习在计算机视觉和语音识别领域也持续稳步取得进展。如今,2021 年,深度学习似乎已经进入 S 形曲线的下半部。我们仍然应该期待未来几年的重大进展,但我们可能已经走出了爆炸性进展的初始阶段。
今天,我对深度学习技术应用于解决各种问题感到非常兴奋——问题的范围是无限的。深度学习仍然是一场正在进行中的革命,要实现其全部潜力还需要很多年。
¹ 艾伦·图灵,“计算机器械与智能”,心灵 59,第 236 期(1950 年):433–460。
² 尽管图灵测试有时被解释为一种字面测试——人工智能领域应该设定的目标——但图灵只是将其作为一个概念设备,用于关于认知本质的哲学讨论。
³ 弗拉基米尔·瓦普尼克和科琳娜·科尔特斯,“支持向量网络”,机器学习 20,第 3 期(1995 年):273–297。
⁴ 弗拉基米尔·瓦普尼克和亚历克谢·切尔沃年基斯,“关于一类感知机的注记”,自动化与遥感控制 25(1964 年)。
⁵ “前五准确率”衡量模型在其前五个猜测中多少次选择了正确答案(在 ImageNet 的情况下,共有 1,000 个可能的答案)。
⁶ 参见“用于图像分类的灵活、高性能卷积神经网络”,第 22 届国际人工智能联合会议论文集(2011),www.ijcai.org/Proceedings/11/Papers/210.pdf。
⁷ 参见“使用深度卷积神经网络进行 ImageNet 分类”,神经信息处理系统进展 25(2012),mng.bz/2286。
⁸ ImageNet 大规模视觉识别挑战(ILSVRC),www.image-net.org/challenges/LSVRC。
⁹ 桑达尔·皮查伊,Alphabet 财报电话会议,2015 年 10 月 22 日。
二、神经网络的数学基础
本章涵盖
-
神经网络的第一个例子
-
张量和张量操作
-
神经网络如何通过反向传播和梯度下降学习
理解深度学习需要熟悉许多简单的数学概念:张量、张量操作、微分、梯度下降等。本章的目标是在不过于技术化的情况下建立您对这些概念的直觉。特别是,我们将避开数学符号,这可能会给没有数学背景的人带来不必要的障碍,并且不是解释事物的必要条件。数学操作的最精确、明确的描述是其可执行代码。
为了为引入张量和梯度下降提供足够的背景,我们将从一个神经网络的实际例子开始本章。然后我们将逐点地讨论每个新引入的概念。请记住,这些概念对于您理解以下章节中的实际示例至关重要!
阅读完本章后,您将对深度学习背后的数学理论有直观的理解,并准备好在第三章开始深入研究 Keras 和 TensorFlow。
2.1 神经网络的初步了解
让我们看一个具体的例子,一个使用 Python 库 Keras 学习分类手写数字的神经网络。除非您已经有使用 Keras 或类似库的经验,否则您不会立即理解这个第一个例子的所有内容。没关系。在下一章中,我们将逐个审查示例中的每个元素并详细解释它们。所以如果有些步骤看起来随意或对您来说像魔术一样,请不要担心!我们必须从某个地方开始。
我们要解决的问题是将手写数字的灰度图像(28×28 像素)分类为它们的 10 个类别(0 到 9)。我们将使用 MNIST 数据集,这是机器学习社区中的经典数据集,几乎与该领域本身一样久远并受到密切研究。这是由国家标准技术研究所(MNIST 中的 NIST)在上世纪 80 年代汇编的一组 60000 个训练图像和 10000 个测试图像。您可以将“解决”MNIST 看作是深度学习的“Hello World” - 这是您验证算法是否按预期工作的方法。随着您成为机器学习从业者,您会发现 MNIST 在科学论文、博客文章等中反复出现。您可以在图 2.1 中看到一些 MNIST 样本。

图 2.1 MNIST 样本数字
在机器学习中,分类问题中的类别称为类。数据点称为样本。与特定样本相关联的类称为标签。
您现在不需要在您的机器上尝试复制这个例子。如果您希望这样做,您首先需要设置一个深度学习工作空间,这在第三章中有介绍。
MNIST 数据集已经预装在 Keras 中,以四个 NumPy 数组的形式存在。
列表 2.1 在 Keras 中加载 MNIST 数据集
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images和train_labels组成训练集,模型将从中学习。然后模型将在测试集test_images和test_labels上进行测试。图像被编码为 NumPy 数组,标签是一个从 0 到 9 的数字数组。图像和标签之间有一一对应关系。
让我们看一下训练数据:
>>> train_images.shape
(60000, 28, 28)
>>> len(train_labels)
60000
>>> train_labels
array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
这里是测试数据:
>>> test_images.shape
(10000, 28, 28)
>>> len(test_labels)
10000
>>> test_labels
array([7, 2, 1, ..., 4, 5, 6], dtype=uint8)
工作流程如下:首先,我们将向神经网络提供训练数据train_images和train_labels。然后网络将学习将图像和标签关联起来。最后,我们将要求网络为test_images生成预测,并验证这些预测是否与test_labels中的标签匹配。
让我们构建网络—再次提醒您,您不必完全理解这个示例的所有内容。
列表 2.2 网络架构
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
神经网络的核心构建块是层。您可以将层视为数据的过滤器:一些数据进入,以更有用的形式输出。具体来说,层从输入的数据中提取表示,希望这些表示对手头的问题更有意义。大部分深度学习都是将一些简单层链接在一起,这些层将实现一种渐进数据精炼形式。深度学习模型就像是数据处理的筛子,由一系列越来越精细的数据过滤器(层)组成。
在这里,我们的模型由两个Dense层的序列组成,这些层是密集连接(也称为全连接)的神经层。第二(也是最后)层是一个 10 路softmax 分类层,这意味着它将返回一个总和为 1 的 10 个概率分数数组。每个分数将是当前数字图像属于我们的 10 个数字类别之一的概率。
为了使模型准备好进行训练,我们需要在编译步骤中选择另外三个事项:
-
优化器—模型将根据其看到的训练数据更新自身的机制,以提高其性能。
-
损失函数—模型如何能够衡量其在训练数据上的表现,从而如何能够引导自己朝着正确的方向前进。
-
在训练和测试过程中监控的指标—在这里,我们只关心准确率(被正确分类的图像的比例)。
损失函数和优化器的确切目的将在接下来的两章中明确。
列表 2.3 编译步骤
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
在训练之前,我们将通过重新调整数据的形状以及缩放数据,使所有值都在[0, 1]区间内来预处理数据。之前,我们的训练图像存储在一个形状为(60000, 28, 28)的uint8类型数组中,值在[0, 255]区间内。我们将其转换为一个形状为(60000, 28 * 28)的float32数组,值在 0 到 1 之间。
列表 2.4 准备图像数据
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
现在我们准备训练模型,在 Keras 中通过调用模型的fit()方法来完成——我们将模型与其训练数据拟合。
列表 2.5 “拟合”模型
>>> model.fit(train_images, train_labels, epochs=5, batch_size=128)
Epoch 1/5
60000/60000 [===========================] - 5s - loss: 0.2524 - acc: 0.9273
Epoch 2/5
51328/60000 [=====================>.....] - ETA: 1s - loss: 0.1035 - acc: 0.9692
在训练过程中显示两个量:模型在训练数据上的损失和模型在训练数据上的准确率。我们很快就在训练数据上达到了 0.989(98.9%)的准确率。
现在我们有了一个经过训练的模型,我们可以使用它来预测新数字的类别概率—这些图像不是训练数据的一部分,就像测试集中的那些图像一样。
列表 2.6 使用模型进行预测
>>> test_digits = test_images[0:10]
>>> predictions = model.predict(test_digits)
>>> predictions[0]
array([1.0726176e-10, 1.6918376e-10, 6.1314843e-08, 8.4106023e-06,
2.9967067e-11, 3.0331331e-09, 8.3651971e-14, 9.9999106e-01,
2.6657624e-08, 3.8127661e-07], dtype=float32)
数组中索引i处的每个数字对应于数字图像test_digits[0]属于类别i的概率。
这个第一个测试数字在索引 7 处具有最高的概率分数(0.99999106,接近 1),因此根据我们的模型,它必须是一个 7:
>>> predictions[0].argmax()
7
>>> predictions[0][7]
0.99999106
我们可以检查测试标签是否一致:
>>> test_labels[0]
7
我们的模型在对这些以前从未见过的数字进行分类时,平均表现如何?让我们通过计算整个测试集上的平均准确率来检查。
列表 2.7 在新数据上评估模型
>>> test_loss, test_acc = model.evaluate(test_images, test_labels)
>>> print(f"test_acc: {test_acc}")
test_acc: 0.9785
测试集准确率为 97.8%—这比训练集准确率(98.9%)要低得多。训练准确率和测试准确率之间的差距是过拟合的一个例子:机器学习模型在新数据上的表现往往不如在其训练数据上。过拟合是第三章的一个核心主题。
这就结束了我们的第一个示例——你刚刚看到如何构建和训练一个神经网络来对手写数字进行分类,只需不到 15 行的 Python 代码。在本章和下一章中,我们将详细介绍我们刚刚预览的每个移动部分,并澄清幕后发生的事情。你将了解张量,这些数据存储对象进入模型;张量操作,层是由什么组成的;以及梯度下降,它允许你的模型从训练示例中学习。
2.2 神经网络的数据表示
在前面的示例中,我们从存储在多维 NumPy 数组中的数据开始,也称为张量。一般来说,所有当前的机器学习系统都使用张量作为它们的基本数据结构。张量对于这个领域是基础的——以至于 TensorFlow 就是以它们命名的。那么什么是张量?
从本质上讲,张量是数据的容器——通常是数值数据。因此,它是一个数字的容器。你可能已经熟悉矩阵,它们是秩为 2 的张量:张量是对矩阵到任意数量的维度的泛化(请注意,在张量的上下文中,维度通常被称为轴)。
2.2.1 标量(秩为 0 的张量)
只包含一个数字的张量称为标量(或标量张量,或秩为 0 的张量,或 0D 张量)。在 NumPy 中,float32或float64数字是标量张量(或标量数组)。你可以通过ndim属性显示 NumPy 张量的轴数;标量张量有 0 个轴(ndim == 0)。张量的轴数也称为其秩。这是一个 NumPy 标量:
>>> import numpy as np
>>> x = np.array(12)
>>> x
array(12)
>>> x.ndim
0
2.2.2 向量(秩为 1 的张量)
一组数字称为向量,或秩为 1 的张量,或 1D 张量。秩为 1 的张量被称为具有一个轴。以下是一个 NumPy 向量:
>>> x = np.array([12, 3, 6, 14, 7])
>>> x
array([12, 3, 6, 14, 7])
>>> x.ndim
1
这个向量有五个条目,因此被称为5 维向量。不要混淆 5D 向量和 5D 张量!一个 5D 向量只有一个轴,并且沿着轴有五个维度,而一个 5D 张量有五个轴(并且可以有任意数量的维度沿着每个轴)。维度可以表示沿着特定轴的条目数(如我们的 5D 向量的情况),或者张量中轴的数量(比如 5D 张量),这有时可能会令人困惑。在后一种情况下,从技术上讲,谈论秩为 5 的张量更正确(张量的秩是轴的数量),但是不明确的符号5D 张量是常见的。
2.2.3 矩阵(秩为 2 的张量)
一组向量是一个矩阵,或秩为 2 的张量,或 2D 张量。矩阵有两个轴(通常称为行和列)。你可以将矩阵视为一个数字矩形网格。这是一个 NumPy 矩阵:
>>> x = np.array([[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])
>>> x.ndim
2
第一个轴的条目称为行,第二个轴的条目称为列。在前面的示例中,[5, 78, 2, 34, 0]是x的第一行,[5, 6, 7]是第一列。
2.2.4 秩为 3 及更高秩的张量
如果你将这些矩阵打包到一个新数组中,你将得到一个秩为 3 的张量(或 3D 张量),你可以将其视为一个数字立方体。以下是一个 NumPy 秩为 3 的张量:
>>> x = np.array([[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]]])
>>> x.ndim
3
通过在数组中打包秩为 3 的张量,你可以创建一个秩为 4 的张量,依此类推。在深度学习中,你通常会处理秩为 0 到 4 的张量,尽管如果处理视频数据可能会升到 5。
2.2.5 关键属性
一个张量由三个关键属性定义:
-
轴的数量(秩)—例如,一个秩为 3 的张量有三个轴,一个矩阵有两个轴。这在 Python 库(如 NumPy 或 TensorFlow)中也被称为张量的
ndim。 -
形状—这是一个描述张量沿着每个轴有多少维度的整数元组。例如,前面的矩阵示例的形状为
(3,5),而秩为 3 的张量示例的形状为(3,3,5)。一个向量的形状有一个单一元素,如(5,),而一个标量的形状为空,()。 -
数据类型(通常在 Python 库中称为
dtype)—这是张量中包含的数据类型;例如,张量的类型可以是float16、float32、float64、uint8等。在 TensorFlow 中,您也可能会遇到string张量。
为了更具体地说明这一点,让我们回顾一下在 MNIST 示例中处理的数据。首先,我们加载 MNIST 数据集:
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
接下来,我们显示张量train_images的轴数,ndim属性:
>>> train_images.ndim
3
这是它的形状:
>>> train_images.shape
(60000, 28, 28)
这是它的数据类型,dtype属性:
>>> train_images.dtype
uint8
因此,我们这里有一个 8 位整数的秩-3 张量。更准确地说,它是一个由 60,000 个 28×28 整数矩阵组成的数组。每个这样的矩阵都是一个灰度图像,系数介于 0 和 255 之间。
让我们使用 Matplotlib 库(Colab 中预装的著名 Python 数据可视化库)显示这个秩-3 张量中的第四个数字;参见图 2.2。

图 2.2 数据集中的第四个样本
列表 2.8 显示第四个数字
import matplotlib.pyplot as plt
digit = train_images[4]
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()
当然,相应的标签是整数 9:
>>> train_labels[4]
9
2.2.6 在 NumPy 中操作张量
在先前的示例中,我们使用语法train_images[i]沿着第一个轴选择了一个特定的数字。在张量中选择特定元素称为张量切片。让我们看看您可以在 NumPy 数组上进行的张量切片操作。
以下示例选择了第 10 到第 100 个数字(不包括第 100 个)并将它们放入形状为(90, 28, 28)的数组中:
>>> my_slice = train_images[10:100]
>>> my_slice.shape
(90, 28, 28)
这等同于更详细的表示法,它为每个张量轴上的切片指定了起始索引和停止索引。请注意,:等同于选择整个轴:
>>> my_slice = train_images[10:100, :, :] # ❶
>>> my_slice.shape
(90, 28, 28)
>>> my_slice = train_images[10:100, 0:28, 0:28] # ❷
>>> my_slice.shape
(90, 28, 28)
❶ 等同于前面的示例
❷ 也等同于前面的示例
通常,您可以在每个张量轴上选择任意两个索引之间的切片。例如,为了选择所有图像右下角的 14×14 像素,您可以这样做:
my_slice = train_images[:, 14:, 14:]
也可以使用负索引。与 Python 列表中的负索引类似,它们表示相对于当前轴末尾的位置。为了将图像裁剪为中心 14×14 像素的补丁,您可以这样做:
my_slice = train_images[:, 7:-7, 7:-7]
2.2.7 数据批次的概念
通常,在深度学习中您会遇到的所有数据张量中的第一个轴(轴 0,因为索引从 0 开始)将是样本轴(有时称为样本维度)。在 MNIST 示例中,“样本”是数字的图像。
此外,深度学习模型不会一次处理整个数据集;相反,它们将数据分成小批次。具体来说,这是我们 MNIST 数字的一个批次,批量大小为 128:
batch = train_images[:128]
这是下一个批次:
batch = train_images[128:256]
和第n批次:
n = 3
batch = train_images[128 * n:128 * (n + 1)]
在考虑这样一个批量张量时,第一个轴(轴 0)被称为批量轴或批量维度。这是您在使用 Keras 和其他深度学习库时经常遇到的术语。
2.2.8 数据张量的现实世界示例
让我们通过几个类似于您以后会遇到的示例来更具体地说明数据张量。您将处理的数据几乎总是属于以下类别之一:
-
向量数据—形状为
(samples,features)的秩-2 张量,其中每个样本是一个数值属性(“特征”)向量 -
时间序列数据或序列数据—形状为
(samples,timesteps,features)的秩-3 张量,其中每个样本是一个长度为timesteps的特征向量序列 -
图像—形状为
(samples,height,width,channels)的秩-4 张量,其中每个样本是一个像素网格,每个像素由一组值(“通道”)表示 -
视频—形状为
(samples,frames,height,width,channels)的秩-5 张量,其中每个样本是一个图像序列(长度为frames)
2.2.9 向量数据
这是最常见的情况之一。在这样的数据集中,每个单个数据点可以被编码为一个向量,因此数据的批次将被编码为一个二阶张量(即向量数组),其中第一个轴是样本轴,第二个轴是特征轴。
让我们看两个例子:
-
一个人们的精算数据集,我们考虑每个人的年龄、性别和收入。每个人可以被描述为一个包含 3 个值的向量,因此一个包含 10 万人的完整数据集可以存储在形状为
(100000, 3)的二阶张量中。 -
一个文本文档数据集,我们通过每个单词在文档中出现的次数(在一个包含 2 万个常见单词的字典中)来表示每个文档。每个文档可以被编码为一个包含 2 万个值的向量(字典中每个单词的计数),因此一个包含 500 个文档的完整数据集可以存储在形状为
(500, 20000)的张量中。
2.2.10 时间序列数据或序列数据
每当数据中涉及时间(或序列顺序的概念)时,将其存储在具有显式时间轴的三阶张量中是有意义的。每个样本可以被编码为一系列向量(一个二阶张量),因此数据的批次将被编码为一个三阶张量(见图 2.3)。
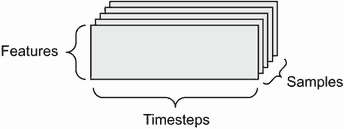
图 2.3 一个三阶时间序列数据张量
按照惯例,时间轴始终是第二轴(索引为 1 的轴)。让我们看几个例子:
-
一个股票价格数据集。每分钟,我们存储股票的当前价格、过去一分钟内的最高价格和最低价格。因此,每分钟被编码为一个三维向量,整个交易日被编码为形状为
(390, 3)的矩阵(一个交易日有 390 分钟),250 天的数据可以存储在形状为(250, 390, 3)的三阶张量中。在这里,每个样本将是一天的数据。 -
一个推文数据集,我们将每条推文编码为一个由 128 个唯一字符组成的字母表中的 280 个字符序列。在这种情况下,每个字符可以被编码为一个大小为 128 的二进制向量(除了在对应字符的索引处有一个 1 条目外,其他都是全零向量)。然后,每条推文可以被编码为形状为
(280, 128)的二阶张量,100 万条推文的数据集可以存储在形状为(1000000, 280, 128)的张量中。
2.2.11 图像数据
图像通常具有三个维度:高度、宽度和颜色深度。尽管灰度图像(如我们的 MNIST 数字)只有一个颜色通道,因此可以存储在二阶张量中,但按照惯例,图像张量始终是三阶的,对于灰度图像有一个一维颜色通道。因此,一个包含 128 个尺寸为 256×256 的灰度图像的批次可以存储在形状为(128, 256, 256, 1)的张量中,而一个包含 128 个彩色图像的批次可以存储在形状为(128, 256, 256, 3)的张量中(见图 2.4)。
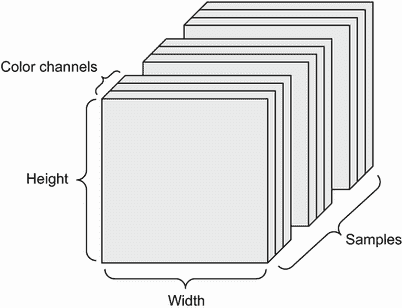
图 2.4 一个四阶图像数据张量
图像张量的形状有两种约定:通道最后约定(在 TensorFlow 中是标准的)和通道优先约定(越来越不受青睐)。
通道最后的约定将颜色深度轴放在最后:(样本数, 高度, 宽度, 颜色深度)。与此同时,通道优先的约定将颜色深度轴放在批次轴之后:(样本数, 颜色深度, 高度, 宽度)。使用通道优先的约定,前面的例子将变为(128, 1, 256, 256)和(128, 3, 256, 256)。Keras API 支持这两种格式。
2.2.12 视频数据
视频数据是少数几种需要使用五阶张量的真实世界数据之一。视频可以被理解为一系列帧,每一帧都是一幅彩色图像。因为每一帧可以存储在一个三阶张量中(height, width, color_ depth),一系列帧可以存储在一个四阶张量中(frames, height, width, color_depth),因此一批不同视频可以存储在一个形状为(samples, frames, height, width, color_depth)的五阶张量中。
例如,一个 60 秒、144 × 256 的 YouTube 视频剪辑,每秒采样 4 帧,将有 240 帧。四个这样的视频剪辑批次将存储在一个形状为(4, 240, 144, 256, 3)的张量中。总共有 106,168,320 个值!如果张量的dtype是float32,每个值将以 32 位存储,因此张量将表示 405 MB。非常庞大!在现实生活中遇到的视频要轻得多,因为它们不是以float32存储的,通常会被大幅压缩(例如 MPEG 格式)。
2.3 神经网络的齿轮:张量操作
就像任何计算机程序最终都可以简化为对二进制输入进行的一小组二进制操作(AND、OR、NOR 等)一样,深度神经网络学习到的所有变换都可以简化为应用于数值数据张量的一小组张量操作(或张量函数)。例如,可以对张量进行加法、乘法等操作。
在我们的初始示例中,我们通过将Dense层堆叠在一起来构建我们的模型。一个 Keras 层实例看起来像这样:
keras.layers.Dense(512, activation="relu")
这一层可以被解释为一个函数,它以一个矩阵作为输入并返回另一个矩阵——输入张量的新表示。具体来说,函数如下(其中W是矩阵,b是向量,都是该层的属性):
output = relu(dot(input, W) + b)
让我们详细解释一下。这里有三个张量操作:
-
输入张量和名为
W的张量之间的点积(dot) -
结果矩阵和向量
b之间的加法(+) -
一个
relu操作:relu(x)是max(x,0);relu代表“修正线性单元”
注意 尽管本节完全涉及线性代数表达式,但这里不会找到任何数学符号。我发现,如果将数学概念表达为简短的 Python 代码片段而不是数学方程式,那么没有数学背景的程序员更容易掌握。因此,我们将在整个过程中使用 NumPy 和 TensorFlow 代码。
2.3.1 逐元素操作
relu 操作和加法都是逐元素操作:这些操作独立应用于所考虑张量中的每个条目。这意味着这些操作非常适合于高度并行的实现(矢量化实现,这个术语来自于 20 世纪 70-90 年代的矢量处理器超级计算机架构)。如果你想编写一个逐元素操作的朴素 Python 实现,你会使用一个for循环,就像这个逐元素relu操作的朴素实现中所示:
def naive_relu(x):
assert len(x.shape) == 2 # ❶
x = x.copy() # ❷
for i in range(x.shape[0]):
for j in range(x.shape[1]):
x[i, j] = max(x[i, j], 0)
return x
❶ x 是一个二阶 NumPy 张量。
❷ 避免覆盖输入张量。
你可以对加法做同样的操作:
def naive_add(x, y):
assert len(x.shape) == 2 # ❶
assert x.shape == y.shape
x = x.copy() # ❷
for i in range(x.shape[0]):
for j in range(x.shape[1]):
x[i, j] += y[i, j]
return x
❶ x 和 y 是二阶 NumPy 张量。
❷ 避免覆盖输入张量。
在同样的原则下,你可以进行逐元素乘法、减法等操作。
在实践中,处理 NumPy 数组时,这些操作也作为优化良好的内置 NumPy 函数可用,它们本身将繁重的工作委托给基本线性代数子程序(BLAS)实现。BLAS 是低级别、高度并行、高效的张量操作例程,通常用 Fortran 或 C 实现。
因此,在 NumPy 中,你可以进行以下逐元素操作,速度将非常快:
import numpy as np
z = x + y # ❶
z = np.maximum(z, 0.) # ❷
❶ 逐元素加法
❷ 逐元素 relu
让我们实际计算一下时间差异:
import time
x = np.random.random((20, 100))
y = np.random.random((20, 100))
t0 = time.time()
for _ in range(1000):
z = x + y
z = np.maximum(z, 0.)
print("Took: {0:.2f} s".format(time.time() - t0))
这需要 0.02 秒。与此同时,朴素版本需要惊人的 2.45 秒:
t0 = time.time()
for _ in range(1000):
z = naive_add(x, y)
z = naive_relu(z)
print("Took: {0:.2f} s".format(time.time() - t0))
同样,在 GPU 上运行 TensorFlow 代码时,通过完全向量化的 CUDA 实现执行元素级操作,可以最好地利用高度并行的 GPU 芯片架构。
2.3.2 广播
我们之前天真的实现naive_add仅支持具有相同形状的秩为 2 的张量的加法。但在之前介绍的Dense层中,我们添加了一个秩为 2 的张量和一个向量。当被加的两个张量的形状不同时,加法会发生什么?
在可能的情况下,如果没有歧义,较小的张量将被广播以匹配较大张量的形状。广播包括两个步骤:
-
轴(称为广播轴)被添加到较小的张量中,以匹配较大张量的
ndim。 -
较小的张量沿着这些新轴重复,以匹配较大张量的完整形状。
让我们看一个具体的例子。考虑形状为(32, 10)的X和形状为(10,)的y:
import numpy as np
X = np.random.random((32, 10)) # ❶
y = np.random.random((10,)) # ❷
❶ X 是一个形状为(32, 10)的随机矩阵。
❷ y 是一个 NumPy 向量。
首先,我们向y添加一个空的第一个轴,其形状变为(1, 10):
y = np.expand_dims(y, axis=0) # ❶
❶ y 的形状现在是(1, 10)。
然后,我们沿着这个新轴重复y 32 次,这样我们就得到了一个形状为(32, 10)的张量Y,其中Y[i, :] == y,对于i 在 range(0, 32):
Y = np.concatenate([y] * 32, axis=0) # ❶
❶ 沿着轴 0 重复 y 32 次,得到形状为(32, 10)的 Y。
此时,我们可以继续添加X和Y,因为它们具有相同的形状。
在实现方面,不会创建新的秩为 2 的张量,因为那样会非常低效。重复操作完全是虚拟的:它发生在算法级别而不是内存级别。但想象向量沿着新轴重复 10 次是一个有用的心理模型。以下是天真实现的样子:
def naive_add_matrix_and_vector(x, y):
assert len(x.shape) == 2 # ❶
assert len(y.shape) == 1 # ❷
assert x.shape[1] == y.shape[0]
x = x.copy() # ❸
for i in range(x.shape[0]):
for j in range(x.shape[1]):
x[i, j] += y[j]
return x
❶ x 是一个秩为 2 的 NumPy 张量。
❷ y 是一个 NumPy 向量。
❸ 避免覆盖输入张量。
使用广播,如果一个张量的形状为(a, b, ... n, n + 1, ... m),另一个张量的形状为(n, n + 1, ... m),通常可以执行元素级操作。广播将自动发生在轴a到n - 1。
以下示例通过广播将两个不同形状的张量应用于元素级maximum操作:
import numpy as np
x = np.random.random((64, 3, 32, 10)) # ❶
y = np.random.random((32, 10)) # ❷
z = np.maximum(x, y) # ❸
❶ x 是一个形状为(64, 3, 32, 10)的随机张量。
❷ y 是一个形状为(32, 10)的随机张量。
❸ 输出 z 的形状与 x 相同,为(64, 3, 32, 10)。
2.3.3 张量积
张量积或点积(不要与逐元素乘积,即*运算符混淆)是最常见、最有用的张量操作之一。
在 NumPy 中,使用np.dot函数进行张量积(因为张量积的数学表示通常是一个点):
x = np.random.random((32,))
y = np.random.random((32,))
z = np.dot(x, y)
在数学表示中,您会用一个点(•)表示该操作:
z = x • y
从数学上讲,点操作是什么?让我们从两个向量x和y的点积开始。计算如下:
def naive_vector_dot(x, y):
assert len(x.shape) == 1 # ❶
assert len(y.shape) == 1 # ❶
assert x.shape[0] == y.shape[0]
z = 0.
for i in range(x.shape[0]):
z += x[i] * y[i]
return z
❶ x 和 y 是 NumPy 向量。
您可能已经注意到两个向量之间的点积是一个标量,只有元素数量相同的向量才适用于点积。
您还可以计算矩阵x和向量y之间的点积,返回一个向量,其中系数是y和x的行之间的点积。您可以按如下方式实现它:
def naive_matrix_vector_dot(x, y):
assert len(x.shape) == 2 # ❶
assert len(y.shape) == 1 # ❷
assert x.shape[1] == y.shape[0] # ❸
z = np.zeros(x.shape[0]) # ❹
for i in range(x.shape[0]):
for j in range(x.shape[1]):
z[i] += x[i, j] * y[j]
return z
❶ x 是一个 NumPy 矩阵。
❷ y 是一个 NumPy 向量。
❸ x 的第一个维度必须与 y 的第 0 维度相同!
❹ 此操作返回一个与 y 形状相同的 0 向量。
您还可以重用我们之前编写的代码,这突显了矩阵-向量乘积与向量乘积之间的关系:
def naive_matrix_vector_dot(x, y):
z = np.zeros(x.shape[0])
for i in range(x.shape[0]):
z[i] = naive_vector_dot(x[i, :], y)
return z
请注意,只要两个张量中的一个的ndim大于 1,dot就不再是对称的,也就是说dot(x, y)不等同于dot(y, x)。
当然,点积可以推广到具有任意数量轴的张量。最常见的应用可能是两个矩阵之间的点积。只有当 x.shape[1] == y.shape[0] 时,你才能计算两个矩阵 x 和 y 的点积(dot(x, y))。结果是一个形状为 (x.shape[0], y.shape[1]) 的矩阵,其中系数是 x 的行和 y 的列之间的向量积。这是一个简单的实现:
def naive_matrix_dot(x, y):
assert len(x.shape) == 2 # ❶
assert len(y.shape) == 2 # ❶
assert x.shape[1] == y.shape[0] # ❷
z = np.zeros((x.shape[0], y.shape[1])) # ❸
for i in range(x.shape[0]): # ❹
for j in range(y.shape[1]): # ❺
row_x = x[i, :]
column_y = y[:, j]
z[i, j] = naive_vector_dot(row_x, column_y)
return z
❶ x 和 y 是 NumPy 矩阵。
❷ x 的第一个维度必须与 y 的第 0 维度相同!
❸ 此操作返回一个具有特定形状的零矩阵。
❹ 迭代 x 的行 . . .
❺ . . . 并在 y 的列上。
要理解点积形状兼容性,有助于通过将输入和输出张量对齐来可视化它们,如图 2.5 所示。

图 2.5 矩阵点积框图
在图中,x、y 和 z 被描绘为矩形(系数的字面框)。因为 x 的行和 y 的列必须具有相同的大小,所以 x 的宽度必须与 y 的高度匹配。如果你继续开发新的机器学习算法,你可能会经常画这样的图。
更一般地,你可以按照前面为 2D 情况概述的相同形状兼容性规则,计算更高维度张量之间的点积:
(a, b, c, d) • (d,) → (a, b, c)
(a, b, c, d) • (d, e) → (a, b, c, e)
等等。
2.3.4 张量重塑
理解的第三种张量操作是张量重塑。虽然在我们第一个神经网络示例中的Dense层中没有使用它,但在将手写数字数据输入模型之前对数据进行预处理时使用了它:
train_images = train_images.reshape((60000, 28 * 28))
重塑张量意味着重新排列其行和列以匹配目标形状。显然,重塑后的张量与初始张量具有相同数量的系数。通过简单的例子最容易理解重塑:
>>> x = np.array([[0., 1.],
[2., 3.],
[4., 5.]])
>>> x.shape
(3, 2)
>>> x = x.reshape((6, 1))
>>> x
array([[ 0.],
[ 1.],
[ 2.],
[ 3.],
[ 4.],
[ 5.]])
>>> x = x.reshape((2, 3))
>>> x
array([[ 0., 1., 2.],
[ 3., 4., 5.]])
常见的重塑的一个特殊情况是转置。转置矩阵意味着交换其行和列,使得 x[i, :] 变为 x[:, i]:
>>> x = np.zeros((300, 20)) # ❶
>>> x = np.transpose(x)
>>> x.shape
(20, 300)
❶ 创建一个形状为 (300, 20) 的全零矩阵
2.3.5 张量操作的几何解释
因为张量操作中的张量内容可以被解释为某个几何空间中点的坐标,所以所有张量操作都有几何解释。例如,让我们从以下向量开始:
A = [0.5, 1]
这是二维空间中的一个点(参见图 2.6)。通常将向量描绘为连接原点和点的箭头,如图 2.7 所示。
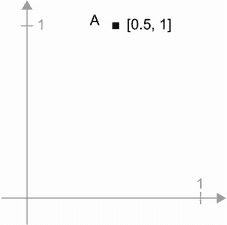
图 2.6 二维空间中的一个点

图 2.7 作为箭头的二维空间中的点
让我们考虑一个新点,B = [1, 0.25],我们将其添加到之前的点上。这是通过将向量箭头链接在一起几何地完成的,结果位置是代表前两个向量之和的向量(参见图 2.8)。如你所见,将向量 B 添加到向量 A 表示将点 A 复制到一个新位置,其距离和方向从原始点 A 确定为向量 B。如果你将相同的向量加法应用于平面上的一组点(一个“对象”),你将在一个新位置创建整个对象的副本(参见图 2.9)。因此,张量加法表示平移对象(在不扭曲对象的情况下移动对象)到某个方向的某个距离。

图 2.8 两个向量之和的几何解释
一般来说,诸如平移、旋转、缩放、倾斜等基本几何操作可以表示为张量操作。以下是一些例子:
-
平移:正如你刚刚看到的,向点添加一个向量将使点沿着固定方向移动固定量。应用于一组点(如 2D 对象),这称为“平移”(见图 2.9)。
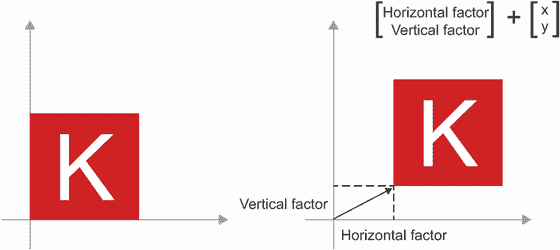
图 2.9 2D 平移作为向量相加
-
旋转:通过角度θ逆时针旋转 2D 向量(见图 2.10)可以通过与 2 × 2 矩阵
R=[[cos(theta),-sin(theta)],[sin(theta),cos(theta)]]进行点积实现。
图 2.10 2D 旋转(逆时针)作为点积
-
缩放:图像的垂直和水平缩放(见图 2.11)可以通过与 2 × 2 矩阵
S=[[horizontal_factor,0],[0,vertical_factor]]进行点积实现(请注意,这样的矩阵称为“对角矩阵”,因为它只在从左上到右下的“对角线”上有非零系数)。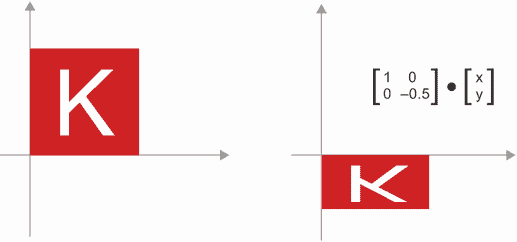
图 2.11 2D 缩放作为点积
-
线性变换:与任意矩阵进行点积实现了线性变换。请注意,前面列出的缩放和旋转按定义都是线性变换。
-
仿射变换:仿射变换(见图 2.12)是线性变换(通过与某些矩阵进行点积实现)和平移(通过向量相加实现)的组合。你可能已经意识到,这正是
Dense层实现的y=W•x+b计算!没有激活函数的Dense层就是一个仿射层。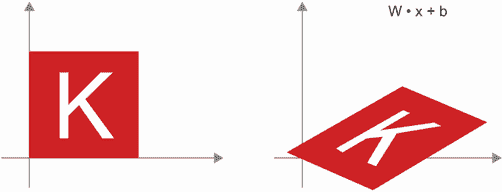
图 2.12 平面中的仿射变换
-
带有
relu激活的 Dense 层:关于仿射变换的一个重要观察是,如果你重复应用许多次,最终仍然得到一个仿射变换(因此你可以一开始就应用那一个仿射变换)。让我们尝试两次:affine2(affine1(x))=W2•(W1•x+b1)+b2=(W2•W1)•x+(W2•b1+b2)。这是一个仿射变换,其中线性部分是矩阵W2•W1,平移部分是向量W2•b1+b2。因此,一个完全由Dense层组成且没有激活函数的多层神经网络等效于单个Dense层。这种“深度”神经网络实际上只是一个伪装的线性模型!这就是为什么我们需要激活函数,比如relu(在图 2.13 中展示)。由于激活函数,一系列Dense层可以实现非常复杂、非线性的几何变换,为你的深度神经网络提供非常丰富的假设空间。我们将在下一章更详细地讨论这个想法。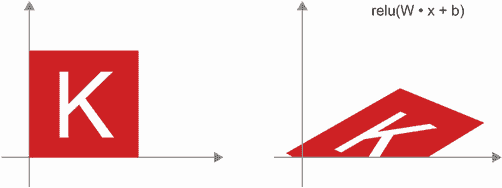
图 2.13 仿射变换后跟
relu激活
2.3.6 深度学习的几何解释
你刚刚学到神经网络完全由张量操作链组成,而这些张量操作只是输入数据的简单几何变换。由此可见,你可以将神经网络解释为在高维空间中非常复杂的几何变换,通过一系列简单步骤实现。
在 3D 中,以下心理形象可能会有所帮助。想象两张彩纸:一张红色,一张蓝色。将它们叠在一起。现在将它们一起揉成一个小球。那个揉皱的纸球就是你的输入数据,每张纸是分类问题中的一个数据类别。神经网络的目的是找出一个可以展开纸球的变换,使得两个类别再次清晰可分(见图 2.14)。通过深度学习,这将被实现为对 3D 空间的一系列简单变换,就像你可以用手指在纸球上一次移动一次一样。

图 2.14 展开复杂数据流形
展开纸团就是机器学习的目的:在高维空间中找到复杂、高度折叠数据流形的整洁表示(流形是一个连续的表面,就像我们折叠的纸张)。此时,你应该对为什么深度学习擅长这一点有很好的直觉:它采用逐步将复杂的几何变换分解为一长串基本变换的方法,这几乎就是人类展开纸团时会遵循的策略。深度网络中的每一层应用一个能稍微解开数据的变换,而深层堆叠的层使得一个极其复杂的解开过程变得可行。
2.4 神经网络的引擎:基于梯度的优化
正如你在前一节中看到的,我们第一个模型示例中的每个神经层将其输入数据转换如下:
output = relu(dot(input, W) + b)
在这个表达式中,W和b是层的属性的张量。它们被称为层的权重或可训练参数(分别是kernel和bias属性)。这些权重包含了模型从训练数据中学到的信息。
最初,这些权重矩阵被填充了小的随机值(这一步被称为随机初始化)。当W和b是随机的时候,当然没有理由期望relu(dot(input, W) + b)会产生任何有用的表示。得到的表示是毫无意义的,但它们是一个起点。接下来要做的是逐渐调整这些权重,基于一个反馈信号。这种逐渐调整,也称为训练,就是机器学习的学习过程。
这发生在所谓的训练循环中,其工作方式如下。重复这些步骤直到损失看起来足够低:
-
绘制一批训练样本
x和相应的目标y_true。 -
在
x上运行模型(称为前向传播)以获得预测值y_pred。 -
计算模型在批次上的损失,这是
y_pred和y_true之间的不匹配度的度量。 -
更新模型的所有权重,以稍微减少这一批次上的损失。
最终,你会得到一个在训练数据上损失非常低的模型:预测值y_pred与期望目标y_true之间的匹配度很低。模型已经“学会”将其输入映射到正确的目标。从远处看,这可能看起来像魔术,但当你将其简化为基本步骤时,它其实很简单。
第一步听起来足够简单——只是 I/O 代码。第二步和第三步仅仅是应用少量张量操作,所以你可以纯粹根据你在前一节中学到的内容来实现这些步骤。困难的部分在于第四步:更新模型的权重。给定模型中的一个单独权重系数,你如何计算这个系数应该增加还是减少,以及增加多少?
一个天真的解决方案是冻结模型中除了正在考虑的一个标量系数之外的所有权重,并尝试不同的值来调整这个系数。假设系数的初始值是 0.3。在一批数据上进行前向传播后,模型在该批次上的损失为 0.5。如果你将系数的值更改为 0.35 并重新运行前向传播,损失增加到 0.6。但如果你将系数降低到 0.25,损失降至 0.4。在这种情况下,似乎通过减小系数-0.05 来有助于最小化损失。这将需要对模型中的所有系数重复进行。
但这样的方法将非常低效,因为你需要为每个单独的系数(通常有成千上万甚至数百万个)计算两次前向传播(这是昂贵的)。幸运的是,有一个更好的方法:梯度下降。
梯度下降是现代神经网络的优化技术。这是其要点。我们模型中使用的所有函数(如 dot 或 +)以平滑连续的方式转换其输入:例如,如果你看 z = x + y,那么 y 的微小变化只会导致 z 的微小变化,如果你知道 y 变化的方向,你就可以推断出 z 变化的方向。从数学上讲,你会说这些函数是可导的。如果你将这些函数链接在一起,你得到的更大函数仍然是可导的。特别是,这适用于将模型系数映射到批量数据上的模型损失的函数:模型系数的微小变化导致损失值的微小、可预测的变化。这使你能够使用一种称为梯度的数学运算符描述损失随着你将模型系数朝不同方向移动而变化的方式。如果你计算这个梯度,你可以使用它来移动系数(一次性全部更新,而不是逐个更新),朝着减小损失的方向移动系数。
如果你已经知道可导的含义和梯度是什么,你可以跳到第 2.4.3 节。否则,接下来的两节将帮助你理解这些概念。
2.4.1 什么是导数?
考虑一个连续、平滑的函数 f(x) = y,将一个数字 x 映射到一个新的数字 y。我们可以以图 2.15 中的函数作为例子。
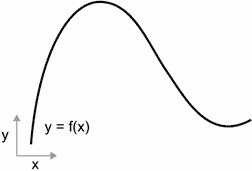
图 2.15 一个连续、平滑的函数
因为函数是连续的,x 的微小变化只会导致 y 的微小变化——这就是连续性背后的直觉。假设你将 x 增加一个小因子 epsilon_x:这会导致 y 有一个小的 epsilon_y 变化,如图 2.16 所示。
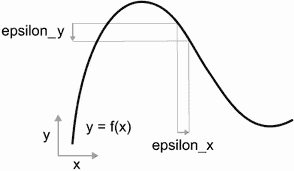
图 2.16 对于连续函数,x 的微小变化导致 y 的微小变化。
此外,因为函数是平滑的(其曲线没有任何突然的角度),当 epsilon_x 足够小,围绕某一点 p,可以将 f 近似为斜率 a 的线性函数,使得 epsilon_y 变为 a * epsilon_x:
f(x + epsilon_x) = y + a * epsilon_x
显然,这种线性近似仅在 x 足够接近 p 时才有效。
斜率 a 在 p 处被称为 f 的导数。如果 a 是负的,这意味着在 p 附近将 x 稍微增加会导致 f(x) 减少(如图 2.17 所示),如果 a 是正的,将 x 稍微增加会导致 f(x) 增加。此外,a 的绝对值(导数的大小)告诉你这种增加或减少会有多快发生。

图 2.17 在 p 处的 f 的导数
对于每个可导函数 f(x)(可导意味着“可以求导”:例如,平滑、连续函数可以求导),都存在一个导数函数 f'(x),将 x 的值映射到这些点上 f 的局部线性近似的斜率。例如,cos(x) 的导数是 -sin(x),f(x) = a * x 的导数是 f'(x) = a,等等。
能够求导函数是在优化方面非常强大的工具,即找到使 f(x) 最小化的 x 的值的任务。如果你试图通过一个因子 epsilon_x 更新 x 以最小化 f(x),并且你知道 f 的导数,那么你的任务就完成了:导数完全描述了当你改变 x 时 f(x) 的演变方式。如果你想减小 f(x) 的值,你只需要将 x 沿着导数的相反方向移动一点。
2.4.2 张量操作的导数:梯度
我们刚刚看的函数将标量值x转换为另一个标量值y:你可以将其绘制为二维平面上的曲线。现在想象一个将标量元组(x, y)转换为标量值z的函数:那将是一个矢量操作。你可以将其绘制为三维空间中的二维表面(由坐标x, y, z索引)。同样,你可以想象将矩阵作为输入的函数,将秩-3 张量作为输入的函数等。
导数的概念可以应用于任何这样的函数,只要它们描述的表面是连续且光滑的。张量操作(或张量函数)的导数称为梯度。梯度只是将导数的概念推广到以张量作为输入的函数。还记得对于标量函数,导数代表函数曲线的局部斜率吗?同样,张量函数的梯度代表函数描述的多维表面的曲率。它描述了当输入参数变化时函数输出如何变化。
让我们看一个基于机器学习的例子。
-
一个输入向量
x(数据集中的样本) -
一个矩阵
W(模型的权重) -
一个目标
y_true(模型应该学会将其与x关联起来的内容) -
一个损失函数
loss(旨在衡量模型当前预测与y_true之间的差距)
你可以使用W计算目标候选y_pred,然后计算目标候选y_pred与目标y_true之间的损失或不匹配:
y_pred = dot(W, x) # ❶
loss_value = loss(y_pred, y_true) # ❷
❶ 我们使用模型权重W来对x进行预测。
❷ 我们估计预测有多大偏差。
现在我们想要使用梯度来找出如何更新W以使loss_value变小。我们该如何做?
给定固定的输入x和y_true,前述操作可以解释为将W(模型的权重)的值映射到损失值的函数:
loss_value = f(W) # ❶
❶ f 描述了当 W 变化时损失值形成的曲线(或高维表面)。
假设当前W的值为W0。那么在点W0处的f的导数是一个张量grad(loss_value, W0),与W具有相同的形状,其中每个系数grad(loss_value, W0)[i, j]指示修改W0[i, j]时观察到的loss_value变化的方向和大小。该张量grad(loss_value, W0)是函数f(W) = loss_value在W0处的梯度,也称为“关于W在W0周围的loss_value的梯度”。
偏导数
张量操作grad(f(W), W)(以矩阵W为输入)可以表示为标量函数的组合,grad_ij(f(W), w_ij),每个函数将返回loss_value = f(W)相对于W[i, j]系数的导数,假设所有其他系数都是常数。grad_ij称为相对于W[i, j]的f 的偏导数。
具体来说,grad(loss_value, W0)代表什么?你之前看到函数f(x)的导数可以解释为f的曲线的斜率。同样,grad(loss_value, W0)可以解释为描述loss_value = f(W)在W0周围的最陡上升方向的张量,以及这种上升的斜率。每个偏导数描述了特定方向上f的斜率。
出于同样的原因,就像对于函数f(x),您可以通过将x稍微朝着导数的相反方向移动来减小f(x)的值一样,对于张量的函数f(W),您可以通过将W朝着梯度的相反方向移动来减小loss_value = f(W):例如,W1 = W0 - step * grad(f(W0), W0)(其中step是一个小的缩放因子)。这意味着沿着f的最陡上升方向的相反方向,直观上应该使您在曲线上更低。请注意,缩放因子step是必需的,因为当您接近W0时,grad(loss_value, W0)仅近似曲率,因此您不希望离W0太远。
2.4.3 随机梯度下降
鉴于可微函数,从理论上讲,可以通过分析找到其最小值:已知函数的最小值是导数为 0 的点,因此您只需找到所有导数为 0 的点,并检查这些点中哪个点的函数值最低。
应用于神经网络,意味着找到分析上产生最小可能损失函数的权重值的组合。这可以通过解方程grad(f(W), W) = 0来实现W。这是一个N个变量的多项式方程,其中N是模型中的系数数量。虽然对于N = 2或N = 3可以解决这样的方程,但对于真实的神经网络来说,这是不可行的,因为参数数量从不少于几千个,通常可以达到几千万个。
相反,您可以使用本节开头概述的四步算法:根据随机数据批次的当前损失值逐渐修改参数。因为您正在处理可微函数,所以可以计算其梯度,这为您实现第 4 步提供了一种高效的方法。如果您根据梯度的相反方向更新权重,那么每次损失都会减少一点:
-
绘制一批训练样本
x和相应的目标y_true。 -
在
x上运行模型以获得预测值y_pred(这称为前向传递)。 -
计算模型在批次上的损失,即
y_pred和y_true之间的不匹配度的度量。 -
计算损失相对于模型参数的梯度(这称为反向传递)。
-
将参数稍微朝着梯度的相反方向移动,例如
W-=learning_rate*gradient,从而在批次上减少一点损失。学习率(这里是learning_rate)将是一个标量因子,调节梯度下降过程的“速度”。
很简单!我们刚刚描述的是小批量随机梯度下降(mini-batch SGD)。术语随机指的是每个数据批次都是随机抽取的(随机是随机的科学同义词)。图 2.18 说明了在 1D 中发生的情况,当模型只有一个参数且您只有一个训练样本时。

图 2.18 SGD 沿着 1D 损失曲线下降(一个可学习参数)
如您所见,直观上选择合理的learning_rate因子值很重要。如果太小,曲线下降将需要许多迭代,并且可能会陷入局部最小值。如果learning_rate太大,您的更新可能会使您完全随机地移动到曲线上的位置。
请注意,小批量 SGD 算法的一个变体是在每次迭代中绘制单个样本和目标,而不是绘制一批数据。这将是真正的SGD(而不是小批量SGD)。或者,走向相反的极端,您可以在所有可用数据上运行每一步,这被称为批量梯度下降。然后,每次更新将更准确,但成本更高。在这两个极端之间的有效折衷方案是使用合理大小的小批量。
尽管图 2.18 展示了在 1D 参数空间中的梯度下降,但在实践中,您将在高维空间中使用梯度下降:神经网络中的每个权重系数都是空间中的一个自由维度,可能有成千上万甚至数百万个。为了帮助您建立对损失曲面的直觉,您还可以将梯度下降可视化为 2D 损失曲面上的过程,如图 2.19 所示。但您不可能可视化训练神经网络的实际过程——您无法以人类能理解的方式表示一个 1000000 维空间。因此,要记住通过这些低维表示形成的直觉在实践中可能并不总是准确的。这在深度学习研究领域历史上一直是一个问题。

图 2.19 梯度下降在 2D 损失曲面上(两个可学习参数)
另外,还有多种 SGD 的变体,它们在计算下一个权重更新时考虑了先前的权重更新,而不仅仅是查看梯度的当前值。例如,有带有动量的 SGD,以及 Adagrad、RMSprop 等几种。这些变体被称为优化方法或优化器。特别是,许多这些变体中使用的动量概念值得关注。动量解决了 SGD 的两个问题:收敛速度和局部最小值。考虑图 2.20,显示了损失作为模型参数函数的曲线。

图 2.20 一个局部最小值和一个全局最小值
如您所见,在某个参数值附近,存在一个局部最小值:在该点附近,向左移动会导致损失增加,但向右移动也是如此。如果正在通过具有较小学习率的 SGD 优化考虑的参数,则优化过程可能会卡在局部最小值处,而不是朝着全局最小值前进。
您可以通过使用动量来避免这些问题,动量从物理学中汲取灵感。在这里一个有用的心理形象是将优化过程视为一个小球沿着损失曲线滚动。如果它有足够的动量,小球就不会卡在峡谷中,最终会到达全局最小值。动量的实现是基于每一步移动小球的不仅仅是当前斜率值(当前加速度),还有当前速度(由过去加速度产生)。在实践中,这意味着根据不仅仅是当前梯度值,还有先前参数更新来更新参数w,就像在这个简单实现中一样:
past_velocity = 0.
momentum = 0.1 # ❶
while loss > 0.01: # ❷
w, loss, gradient = get_current_parameters()
velocity = past_velocity * momentum - learning_rate * gradient
w = w + momentum * velocity - learning_rate * gradient
past_velocity = velocity
update_parameter(w)
❶ 恒定的动量因子
❷ 优化循环
2.4.4 链式求导:反向传播算法
在前面的算法中,我们随意假设因为一个函数是可微的,我们可以轻松计算它的梯度。但这是真的吗?在实践中如何计算复杂表达式的梯度?在我们本章开始的两层模型中,如何计算损失相对于权重的梯度?这就是反向传播算法的作用。
链式法则
反向传播是一种利用简单操作的导数(如加法、relu 或张量乘积)来轻松计算这些原子操作任意复杂组合的梯度的方法。关键是,神经网络由许多张量操作链在一起组成,每个操作都有简单的已知导数。例如,列表 2.2 中定义的模型可以表示为由变量W1、b1、W2和b2(分别属于第一和第二个Dense层)参数化的函数,涉及原子操作dot、relu、softmax和+,以及我们的损失函数loss,这些都很容易可微:
loss_value = loss(y_true, softmax(dot(relu(dot(inputs, W1) + b1), W2) + b2))
微积分告诉我们,这样的函数链可以使用以下恒等式导出,称为链式法则。
考虑两个函数f和g,以及组合函数fg,使得fg(x) == f(g(x)):
def fg(x):
x1 = g(x)
y = f(x1)
return y
然后链式法则表明grad(y, x) == grad(y, x1) * grad(x1, x)。只要您知道f和g的导数,就可以计算fg的导数。链式法则之所以被命名为链式法则,是因为当您添加更多中间函数时,它开始看起来像一个链条:
def fghj(x):
x1 = j(x)
x2 = h(x1)
x3 = g(x2)
y = f(x3)
return y
grad(y, x) == (grad(y, x3) * grad(x3, x2) *
grad(x2, x1) * grad(x1, x))
将链式法则应用于神经网络梯度值的计算会产生一种称为反向传播的算法。让我们看看具体是如何工作的。
使用计算图进行自动微分
以计算图的方式思考反向传播是一种有用的方式。计算图是 TensorFlow 和深度学习革命的核心数据结构。它是操作的有向无环图 - 在我们的情况下,是张量操作。例如,图 2.21 显示了我们第一个模型的图表示。
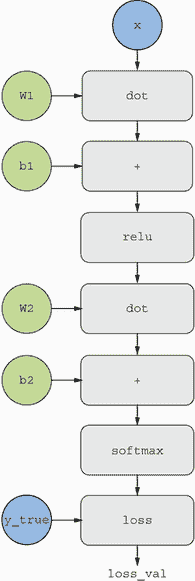
图 2.21 我们两层模型的计算图表示
计算图在计算机科学中是一个非常成功的抽象,因为它使我们能够将计算视为数据:可计算表达式被编码为一种可用作另一个程序的输入或输出的机器可读数据结构。例如,您可以想象一个接收计算图并返回实现相同计算的大规模分布式版本的新计算图的程序 - 这意味着您可以分发任何计算而无需自己编写分发逻辑。或者想象一个接收计算图并可以自动生成其表示的表达式的导数的程序。如果您的计算表达为显式图数据结构而不是.py 文件中的 ASCII 字符行,这些事情要容易得多。
为了清楚地解释反向传播,让我们看一个计算图的真正基本的例子(见图 2.22)。我们将考虑图 2.21 的简化版本,其中只有一个线性层,所有变量都是标量。我们将取两个标量变量w和b,一个标量输入x,并对它们应用一些操作将它们组合成输出y。最后,我们将应用一个绝对值误差损失函数:loss_val = abs(y_true - y)。由于我们希望以最小化loss_val的方式更新w和b,我们有兴趣计算grad(loss_val, b)和grad(loss _val, w)。

图 2.22 计算图的基本示例
让我们为图中的“输入节点”设置具体值,也就是说,输入x、目标y_true、w和b。我们将这些值从顶部传播到图中的所有节点,直到达到loss_val。这是前向传递(见图 2.23)。
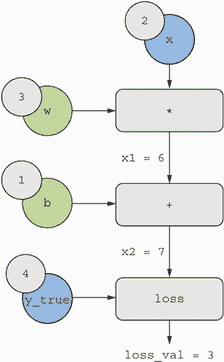
图 2.23 运行前向传递
现在让我们“反转”图表:对于图表中从A到B的每条边,我们将创建一个从B到A的相反边,并问,当A变化时B变化多少?也就是说,grad(B, A)是多少?我们将用这个值注释每个反转边。这个反向图代表了反向传递(见图 2.24)。

图 2.24 运行反向传播
我们有以下内容:
-
grad(loss_val,x2)=1,因为当x2变化一个 epsilon 时,loss_val=abs(4-x2)也会变化相同的量。 -
grad(x2,x1)=1,因为当x1变化一个 epsilon 时,x2=x1+b=x1+1也会变化相同的量。 -
grad(x2,b)=1,因为当b变化一个 epsilon 时,x2=x1+b=6+b也会变化相同的量。 -
grad(x1,w)=2,因为当w变化一个 epsilon 时,x1=x*w=2*w也会变化2*epsilon。
链式法则关于这个反向图的含义是,你可以通过乘以连接两个节点路径上的每个边的导数来获得一个节点相对于另一个节点的导数。例如,grad(loss_val, w) = grad(loss_val, x2) * grad(x2, x1) * grad(x1, w)(见图 2.25)。

图 2.25 从loss_val到w的反向图路径
通过将链式法则应用于我们的图表,我们得到了我们要找的内容:
-
grad(loss_val,w)=1*1*2=2 -
grad(loss_val,b)=1*1=1
注意:如果在反向图中存在多条连接两个感兴趣节点a和b的路径,我们可以通过对所有路径的贡献求和来得到grad(b, a)。
通过这样,你刚刚看到了反向传播的过程!反向传播简单地是将链式法则应用于计算图。没有更多了。反向传播从最终损失值开始,从顶层向底层向后计算每个参数对损失值的贡献。这就是“反向传播”这个名字的由来:我们在计算图中“反向传播”不同节点的损失贡献。
如今,人们在现代框架中实现神经网络,这些框架能够进行自动微分,例如 TensorFlow。自动微分是使用你刚刚看到的计算图实现的。自动微分使得能够检索任意可微张量操作组合的梯度成为可能,而无需额外工作,只需编写前向传播。在 2000 年代我用 C 语言编写我的第一个神经网络时,我不得不手动编写梯度。现在,由于现代自动微分工具,你永远不必自己实现反向传播。算你运气好!
TensorFlow 中的梯度磁带
你可以利用 TensorFlow 强大的自动微分功能的 API 是GradientTape。它是一个 Python 范围,将在其中运行的张量操作“记录”为计算图(有时称为“磁带”)。然后可以使用此图检索任何输出相对于任何变量或一组变量(tf.Variable类的实例)的梯度。tf.Variable是一种特定类型的张量,用于保存可变状态,例如神经网络的权重始终是tf.Variable实例。
import tensorflow as tf
x = tf.Variable(0.) # ❶
with tf.GradientTape() as tape: # ❷
y = 2 * x + 3 # ❸
grad_of_y_wrt_x = tape.gradient(y, x) # ❹
❶ 实例化一个初始值为 0 的标量变量。
❷ 打开一个 GradientTape 范围。
❸ 在范围内,对我们的变量应用一些张量操作。
❹ 使用磁带检索输出 y 相对于我们的变量 x 的梯度。
GradientTape与张量操作一起工作:
x = tf.Variable(tf.random.uniform((2, 2))) # ❶
with tf.GradientTape() as tape:
y = 2 * x + 3
grad_of_y_wrt_x = tape.gradient(y, x) # ❷
❶ 实例化一个形状为(2, 2)且初始值全为零的变量。
❷ grad_of_y_wrt_x是一个形状为(2, 2)(像 x 一样)的张量,描述了 y = 2 * a + 3 在 x = [[0, 0], [0, 0]]周围的曲率。
它也适用于变量列表:
W = tf.Variable(tf.random.uniform((2, 2)))
b = tf.Variable(tf.zeros((2,)))
x = tf.random.uniform((2, 2))
with tf.GradientTape() as tape:
y = tf.matmul(x, W) + b # ❶
grad_of_y_wrt_W_and_b = tape.gradient(y, [W, b]) # ❷
❶ matmul 是在 TensorFlow 中表示“点积”的方式。
❷ grad_of_y_wrt_W_and_b 是两个张量列表,形状与 W 和 b 相同。
你将在下一章学习关于梯度带的知识。
2.5 回顾我们的第一个例子
你已经接近本章的结束,现在应该对神经网络背后的运作有一个大致的了解。在本章开始时是一个神奇的黑匣子,现在已经变成了一个更清晰的画面,如图 2.26 所示:模型由相互链接的层组成,将输入数据映射到预测结果。损失函数然后将这些预测与目标进行比较,产生一个损失值:衡量模型预测与预期值匹配程度的指标。优化器使用这个损失值来更新模型的权重。

图 2.26 网络、层、损失函数和优化器之间的关系
让我们回到本章的第一个例子,并根据你学到的知识来逐一审查每个部分。
这是输入数据:
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
现在你明白了输入图像存储在 NumPy 张量中,这里格式化为(60000, 784)(训练数据)和(10000, 784)(测试数据)的float32张量。
这是我们的模型:
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
现在你明白了这个模型由两个Dense层的链条组成,每个层对输入数据应用了一些简单的张量操作,并且这些操作涉及权重张量。权重张量是属于层的属性,是模型的知识所在。
这是模型编译步骤:
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
现在你明白了sparse_categorical_crossentropy是用作学习权重张量的反馈信号的损失函数,训练阶段将尝试最小化它。你还知道这种损失的减少是通过小批量随机梯度下降来实现的。具体规则由作为第一个参数传递的rmsprop优化器定义。
最后,这是训练循环:
model.fit(train_images, train_labels, epochs=5, batch_size=128)
现在你明白了当你调用fit时会发生什么:模型将开始在 128 个样本的小批量数据上进行 5 次迭代(每次迭代所有训练数据都被称为epoch)。对于每个批次,模型将计算损失相对于权重的梯度(使用源自微积分链式法则的反向传播算法),并将权重朝着减少该批次损失值的方向移动。
在这 5 个 epoch 之后,模型将执行 2,345 次梯度更新(每个 epoch 469 次),并且模型的损失将足够低,以至于模型能够以高准确度对手写数字进行分类。
在这一点上,你已经了解了大部分关于神经网络的常识。让我们通过逐步在 TensorFlow 中“从头开始”重新实现那个第一个例子来证明它。
2.5.1 在 TensorFlow 中从头开始重新实现我们的第一个例子
有什么比从头开始实现一切更能展示出完全、明确的理解呢?当然,“从头开始”在这里是相对的:我们不会重新实现基本的张量操作,也不会实现反向传播。但我们会降到一个低到几乎不使用任何 Keras 功能的水平。
如果你现在还不理解这个例子中的每一个细节,不要担心。下一章将更详细地深入探讨 TensorFlow API。现在,只需尝试理解正在发生的事情的要点——这个例子的目的是帮助你通过具体实现来澄清对深度学习数学的理解。让我们开始吧!
一个简单的 Dense 类
你之前学过Dense层实现以下输入转换,其中W和b是模型参数,activation是逐元素函数(通常是relu,但对于最后一层可能是softmax):
output = activation(dot(W, input) + b)
让我们实现一个简单的 Python 类NaiveDense,它创建两个 TensorFlow 变量W和b,并公开一个__call__()方法,应用前述转换。
import tensorflow as tf
class NaiveDense:
def __init__(self, input_size, output_size, activation):
self.activation = activation
w_shape = (input_size, output_size) # ❶
w_initial_value = tf.random.uniform(w_shape, minval=0, maxval=1e-1)
self.W = tf.Variable(w_initial_value)
b_shape = (output_size, # ❷
b_initial_value = tf.zeros(b_shape)
self.b = tf.Variable(b_initial_value)
def __call__(self, inputs):: # ❸
return self.activation(tf.matmul(inputs, self.W) + self.b)
@property
def weights(self): # ❹
return [self.W, self.b]
❶ 创建一个形状为(input_size, output_size)的矩阵 W,用随机值初始化。
❷ 创建一个形状为(output_size,)的向量 b,用零初始化。
❸ 应用前向传播。
❹ 用于检索层权重的便利方法
一个简单的 Sequential 类
现在,让我们创建一个NaiveSequential类来链接这些层。它包装了一系列层,并公开一个__call__()方法,简单地按顺序在输入上调用底层层。它还具有一个weights属性,方便跟踪层的参数。
class NaiveSequential:
def __init__(self, layers):
self.layers = layers
def __call__(self, inputs):
x = inputs
for layer in self.layers:
x = layer(x)
return x
@property
def weights(self):
weights = []
for layer in self.layers:
weights += layer.weights
return weights
使用这个NaiveDense类和这个NaiveSequential类,我们可以创建一个模拟的 Keras 模型:
model = NaiveSequential([
NaiveDense(input_size=28 * 28, output_size=512, activation=tf.nn.relu),
NaiveDense(input_size=512, output_size=10, activation=tf.nn.softmax)
])
assert len(model.weights) == 4
一个批生成器
接下来,我们需要一种方法以小批量迭代 MNIST 数据。这很容易:
import math
class BatchGenerator:
def __init__(self, images, labels, batch_size=128):
assert len(images) == len(labels)
self.index = 0
self.images = images
self.labels = labels
self.batch_size = batch_size
self.num_batches = math.ceil(len(images) / batch_size)
def next(self):
images = self.images[self.index : self.index + self.batch_size]
labels = self.labels[self.index : self.index + self.batch_size]
self.index += self.batch_size
return images, labels
2.5.2 运行一个训练步骤
这个过程中最困难的部分是“训练步骤”:在一个数据批次上运行模型后更新模型的权重。我们需要
-
计算模型对批次中图像的预测。
-
计算这些预测的损失值,给定实际标签。
-
计算损失相对于模型权重的梯度。
-
将权重沿着梯度相反的方向移动一小步。
要计算梯度,我们将使用在第 2.4.4 节中介绍的 TensorFlow GradientTape对象:
def one_training_step(model, images_batch, labels_batch):
with tf.GradientTape() as tape: # ❶
predictions = model(images_batch) # ❶
per_sample_losses = tf.keras.losses.sparse_categorical_crossentropy(# ❶
labels_batch, predictions) # ❶
average_loss = tf.reduce_mean(per_sample_losses) # ❶
gradients = tape.gradient(average_loss, model.weights) # ❷
update_weights(gradients, model.weights) # ❸
return average_loss
❶ 运行“前向传播”(在 GradientTape 范围内计算模型的预测)。
❷ 计算损失相对于权重的梯度。输出梯度是一个列表,其中每个条目对应于模型权重列表中的一个权重。
❸ 使用梯度更新权重(我们将很快定义这个函数)。
正如你已经知道的,“权重更新”步骤的目的(由前面的update_weights函数表示)是将权重向“减少此批次上的损失”的方向移动一点。移动的大小由“学习率”确定,通常是一个小量。实现这个update_weights函数的最简单方法是从每个权重中减去gradient * learning_rate:
learning_rate = 1e-3
def update_weights(gradients, weights):
for g, w in zip(gradients, weights):
w.assign_sub(g * learning_rate) # ❶
❶ assign_sub是 TensorFlow 变量的-=的等效操作。
在实践中,你几乎永远不会手动实现这样的权重更新步骤。相反,你会使用 Keras 中的Optimizer实例,就像这样:
from tensorflow.keras import optimizers
optimizer = optimizers.SGD(learning_rate=1e-3)
def update_weights(gradients, weights):
optimizer.apply_gradients(zip(gradients, weights))
现在我们的每批训练步骤已经准备好,我们可以继续实现整个训练时期。
2.5.3 完整的训练循环
训练的一个时期简单地包括对训练数据中的每个批次重复进行训练步骤,完整的训练循环只是一个时期的重复:
def fit(model, images, labels, epochs, batch_size=128):
for epoch_counter in range(epochs):
print(f"Epoch {epoch_counter}")
batch_generator = BatchGenerator(images, labels)
for batch_counter in range(batch_generator.num_batches):
images_batch, labels_batch = batch_generator.next()
loss = one_training_step(model, images_batch, labels_batch)
if batch_counter % 100 == 0:
print(f"loss at batch {batch_counter}: {loss:.2f}")
让我们来试一下:
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
fit(model, train_images, train_labels, epochs=10, batch_size=128)
2.5.4 评估模型
我们可以通过对测试图像的预测取argmax,并将其与预期标签进行比较来评估模型:
predictions = model(test_images)
predictions = predictions.numpy() # ❶
predicted_labels = np.argmax(predictions, axis=1)
matches = predicted_labels == test_labels
print(f"accuracy: {matches.mean():.2f}")
❶ 在 TensorFlow 张量上调用.numpy()会将其转换为 NumPy 张量。
完成了!正如你所看到的,手动完成“几行 Keras 代码可以完成的工作”需要做很多工作。但是因为你已经经历了这些步骤,现在应该对在调用fit()时神经网络内部发生的事情有一个清晰的理解。拥有这种低级别的心智模型,了解代码在幕后执行的操作,将使你更能利用 Keras API 的高级功能。
摘要
-
张量构成现代机器学习系统的基础。它们具有各种
dtype、rank和shape。 -
你可以通过张量操作(如加法、张量积或逐元素乘法)来操作数值张量,这可以被解释为编码几何变换。总的来说,深度学习中的一切都可以被解释为几何解释。
-
深度学习模型由一系列简单的张量操作组成,由权重参数化,它们本身也是张量。模型的权重是存储其“知识”的地方。
-
学习意味着找到一组值,使模型的权重最小化给定一组训练数据样本及其对应目标的损失函数。
-
学习是通过随机抽取数据样本及其目标,并计算模型参数相对于批次上的损失的梯度来实现的。然后,模型参数向相反方向移动一点(移动的大小由学习率定义)。这被称为小批量随机梯度下降。
-
整个学习过程之所以可能,是因为神经网络中的所有张量操作都是可微的,因此可以应用导数的链式法则来找到将当前参数和当前数据批次映射到梯度值的梯度函数。这被称为反向传播。
-
你将经常在未来章节中看到的两个关键概念是损失和优化器。这是在开始向模型输入数据之前需要定义的两件事。
-
损失是在训练过程中你将尝试最小化的量,因此它应该代表你尝试解决的任务的成功度量。
-
优化器指定了损失的梯度将如何用于更新参数的确切方式:例如,可以是 RMSProp 优化器、带动量的 SGD 等。
-
三、Keras 和 TensorFlow 简介
本章内容包括
-
仔细研究 TensorFlow、Keras 及它们之间的关系
-
设置深度学习工作空间
-
深入了解核心深度学习概念如何转化为 Keras 和 TensorFlow
本章旨在为您提供开始实践深度学习所需的一切。我将为您快速介绍 Keras(keras.io)和 TensorFlow(tensorflow.org),这是本书中将使用的基于 Python 的深度学习工具。您将了解如何设置深度学习工作空间,使用 TensorFlow、Keras 和 GPU 支持。最后,基于您在第二章中对 Keras 和 TensorFlow 的初步接触,我们将回顾神经网络的核心组件以及它们如何转化为 Keras 和 TensorFlow 的 API。
到本章结束时,您将准备好进入实际的现实世界应用程序,这将从第四章开始。
3.1 什么是 TensorFlow?
TensorFlow 是一个基于 Python 的免费、开源的机器学习平台,主要由 Google 开发。与 NumPy 类似,TensorFlow 的主要目的是使工程师和研究人员能够在数值张量上操作数学表达式。但是 TensorFlow 在以下方面远远超出了 NumPy 的范围:
-
它可以自动计算任何可微表达式的梯度(正如您在第二章中看到的),使其非常适合机器学习。
-
它不仅可以在 CPU 上运行,还可以在 GPU 和 TPU 上运行,高度并行的硬件加速器。
-
在 TensorFlow 中定义的计算可以轻松地分布到许多机器上。
-
TensorFlow 程序可以导出到其他运行时,例如 C++、JavaScript(用于基于浏览器的应用程序)或 TensorFlow Lite(用于在移动设备或嵌入式设备上运行的应用程序)等。这使得 TensorFlow 应用程序在实际环境中易于部署。
重要的是要记住,TensorFlow 远不止是一个单一的库。它实际上是一个平台,拥有庞大的组件生态系统,其中一些由 Google 开发,一些由第三方开发。例如,有用于强化学习研究的 TF-Agents,用于工业强度机器学习工作流管理的 TFX,用于生产部署的 TensorFlow Serving,以及预训练模型的 TensorFlow Hub 存储库。这些组件共同涵盖了非常广泛的用例,从前沿研究到大规模生产应用。
TensorFlow 的扩展性相当不错:例如,奥克岭国家实验室的科学家们已经使用它在 IBM Summit 超级计算机的 27000 个 GPU 上训练了一个 1.1 艾克斯佛洛普的极端天气预测模型。同样,谷歌已经使用 TensorFlow 开发了非常计算密集的深度学习应用程序,例如下棋和围棋代理 AlphaZero。对于您自己的模型,如果有预算,您可以实际上希望在小型 TPU 架或在 Google Cloud 或 AWS 上租用的大型 GPU 集群上扩展到约 10 petaFLOPS。这仍然约占 2019 年顶级超级计算机峰值计算能力的 1%!
3.2 什么是 Keras?
Keras 是一个基于 TensorFlow 的 Python 深度学习 API,提供了一种方便的方式来定义和训练任何类型的深度学习模型。Keras 最初是为研究而开发的,旨在实现快速的深度学习实验。
通过 TensorFlow,Keras 可以在不同类型的硬件上运行(见图 3.1)—GPU、TPU 或普通 CPU,并且可以无缝地扩展到数千台机器。

图 3.1 Keras 和 TensorFlow:TensorFlow 是一个低级张量计算平台,而 Keras 是一个高级深度学习 API
Keras 以优先考虑开发者体验而闻名。它是为人类而设计的 API,而不是为机器。它遵循减少认知负荷的最佳实践:提供一致简单的工作流程,最小化常见用例所需的操作数量,并在用户出错时提供清晰可行的反馈。这使得 Keras 对初学者易于学习,对专家使用高效。
截至 2021 年底,Keras 已经拥有超过一百万用户,包括学术研究人员、工程师、数据科学家、初创公司和大公司的研究生和爱好者。Keras 在 Google、Netflix、Uber、CERN、NASA、Yelp、Instacart、Square 等公司中被使用,以及数百家从事各行各业各种问题的初创公司。你的 YouTube 推荐源自 Keras 模型。Waymo 自动驾驶汽车是使用 Keras 模型开发的。Keras 也是 Kaggle 上的热门框架,大多数深度学习竞赛都是使用 Keras 赢得的。
由于 Keras 拥有庞大且多样化的用户群,它不会强迫你遵循单一的“正确”模型构建和训练方式。相反,它支持各种不同的工作流程,从非常高级到非常低级,对应不同的用户配置文件。例如,你有多种构建模型和训练模型的方式,每种方式都代表着可用性和灵活性之间的某种权衡。在第五章中,我们将详细审查这种工作流程的一部分。你可以像使用 Scikit-learn 一样使用 Keras——只需调用 fit(),让框架自行处理——或者像使用 NumPy 一样使用它——完全控制每一个细节。
这意味着你现在学习的所有内容在你成为专家后仍然是相关的。你可以轻松入门,然后逐渐深入到需要从头开始编写更多逻辑的工作流程中。在从学生转变为研究人员,或者从数据科学家转变为深度学习工程师时,你不必切换到完全不同的框架。
这种哲学与 Python 本身的哲学非常相似!有些语言只提供一种编写程序的方式——例如,面向对象编程或函数式编程。而 Python 是一种多范式语言:它提供了一系列可能的使用模式,它们都可以很好地协同工作。这使得 Python 适用于各种非常不同的用例:系统管理、数据科学、机器学习工程、Web 开发……或者只是学习如何编程。同样,你可以将 Keras 视为深度学习的 Python:一种用户友好的深度学习语言,为不同用户配置文件提供各种工作流程。
3.3 Keras 和 TensorFlow:简史
Keras 比 TensorFlow 早八个月发布。它于 2015 年 3 月发布,而 TensorFlow 则于 2015 年 11 月发布。你可能会问,如果 Keras 是建立在 TensorFlow 之上的,那么在 TensorFlow 发布之前它是如何存在的?Keras 最初是建立在 Theano 之上的,Theano 是另一个提供自动微分和 GPU 支持的张量操作库,是最早的之一。Theano 在蒙特利尔大学机器学习算法研究所(MILA)开发,从许多方面来看是 TensorFlow 的前身。它开创了使用静态计算图进行自动微分和将代码编译到 CPU 和 GPU 的想法。
在 TensorFlow 发布后的 2015 年底,Keras 被重构为多后端架构:可以使用 Keras 与 Theano 或 TensorFlow,而在两者之间切换就像更改环境变量一样简单。到 2016 年 9 月,TensorFlow 达到了技术成熟的水平,使其成为 Keras 的默认后端选项成为可能。2017 年,Keras 添加了两个新的后端选项:CNTK(由微软开发)和 MXNet(由亚马逊开发)。如今,Theano 和 CNTK 已经停止开发,MXNet 在亚马逊之外并不广泛使用。Keras 又回到了基于 TensorFlow 的单一后端 API。
多年来,Keras 和 TensorFlow 之间建立了一种共生关系。在 2016 年和 2017 年期间,Keras 成为了开发 TensorFlow 应用程序的用户友好方式,将新用户引入 TensorFlow 生态系统。到 2017 年底,大多数 TensorFlow 用户都是通过 Keras 或与 Keras 结合使用。2018 年,TensorFlow 领导层选择了 Keras 作为 TensorFlow 的官方高级 API。因此,Keras API 在 2019 年 9 月发布的 TensorFlow 2.0 中占据了重要位置——这是 TensorFlow 和 Keras 的全面重新设计,考虑了四年多的用户反馈和技术进步。
到这个时候,你一定迫不及待地想要开始实践运行 Keras 和 TensorFlow 代码了。让我们开始吧。
3.4 设置深度学习工作空间
在开始开发深度学习应用程序之前,你需要设置好你的开发环境。强烈建议,尽管不是绝对必要的,你应该在现代 NVIDIA GPU 上运行深度学习代码,而不是在计算机的 CPU 上运行。一些应用程序——特别是使用卷积网络进行图像处理的应用程序——在 CPU 上会非常慢,即使是快速的多核 CPU。即使对于可以在 CPU 上运行的应用程序,使用最新 GPU 通常会使速度提高 5 到 10 倍。
要在 GPU 上进行深度学习,你有三个选择:
-
在你的工作站上购买并安装一块物理 NVIDIA GPU。
-
使用 Google Cloud 或 AWS EC2 上的 GPU 实例。
-
使用 Colaboratory 提供的免费 GPU 运行时,这是 Google 提供的托管笔记本服务(有关“笔记本”是什么的详细信息,请参见下一节)。
Colaboratory 是最简单的入门方式,因为它不需要购买硬件,也不需要安装软件——只需在浏览器中打开一个标签页并开始编码。这是我们推荐在本书中运行代码示例的选项。然而,Colaboratory 的免费版本只适用于小型工作负载。如果你想扩大规模,你将不得不使用第一或第二个选项。
如果你还没有可以用于深度学习的 GPU(一块最新的高端 NVIDIA GPU),那么在云中运行深度学习实验是一个简单、低成本的方式,让你能够扩展到更大的工作负载,而无需购买任何额外的硬件。如果你正在使用 Jupyter 笔记本进行开发,那么在云中运行的体验与本地运行没有任何区别。
但是,如果你是深度学习的重度用户,这种设置在长期内甚至在几个月内都是不可持续的。云实例并不便宜:在 2021 年中期,你将为 Google Cloud 上的 V100 GPU 每小时支付 2.48 美元。与此同时,一块可靠的消费级 GPU 的价格在 1500 到 2500 美元之间——即使这些 GPU 的规格不断改进,价格也保持相对稳定。如果你是深度学习的重度用户,请考虑设置一个带有一块或多块 GPU 的本地工作站。
另外,无论您是在本地运行还是在云端运行,最好使用 Unix 工作站。虽然在 Windows 上直接运行 Keras 在技术上是可能的,但我们不建议这样做。如果您是 Windows 用户,并且想在自己的工作站上进行深度学习,最简单的解决方案是在您的机器上设置一个 Ubuntu 双系统引导,或者利用 Windows Subsystem for Linux(WSL),这是一个兼容层,使您能够从 Windows 运行 Linux 应用程序。这可能看起来有点麻烦,但从长远来看,这将为您节省大量时间和麻烦。
3.4.1 Jupyter 笔记本:运行深度学习实验的首选方式
Jupyter 笔记本是运行深度学习实验的绝佳方式,特别是本书中的许多代码示例。它们在数据科学和机器学习社区中被广泛使用。笔记本是由 Jupyter Notebook 应用程序生成的文件(jupyter.org),您可以在浏览器中编辑。它结合了执行 Python 代码的能力和用于注释您正在进行的操作的丰富文本编辑功能。笔记本还允许您将长实验分解为可以独立执行的较小部分,这使得开发交互式,并且意味着如果实验的后期出现问题,您不必重新运行之前的所有代码。
我建议使用 Jupyter 笔记本来开始使用 Keras,尽管这不是必需的:您也可以运行独立的 Python 脚本或在诸如 PyCharm 这样的 IDE 中运行代码。本书中的所有代码示例都作为开源笔记本提供;您可以从 GitHub 上下载它们:github.com/fchollet/deep-learning-with-python-notebooks。
3.4.2 使用 Colaboratory
Colaboratory(简称 Colab)是一个免费的 Jupyter 笔记本服务,无需安装,完全在云端运行。实际上,它是一个网页,让您可以立即编写和执行 Keras 脚本。它为您提供免费(但有限)的 GPU 运行时,甚至还有 TPU 运行时,因此您不必购买自己的 GPU。Colaboratory 是我们推荐用于运行本书中代码示例的工具。
使用 Colaboratory 的第一步
要开始使用 Colab,请访问 colab.research.google.com 并单击 New Notebook 按钮。您将看到图 3.2 中显示的标准笔记本界面。

图 3.2 一个 Colab 笔记本
您会在工具栏中看到两个按钮:+ Code 和 + Text。它们分别用于创建可执行的 Python 代码单元格和注释文本单元格。在代码单元格中输入代码后,按 Shift-Enter 将执行它(参见图 3.3)。

图 3.3 创建一个代码单元格
在文本单元格中,您可以使用 Markdown 语法(参见图 3.4)。按 Shift-Enter 在文本单元格上将渲染它。

图 3.4 创建一个文本单元格
文本单元格对于为您的笔记本提供可读的结构非常有用:使用它们为您的代码添加部分标题和长说明段落或嵌入图像。笔记本旨在成为一种多媒体体验!
使用 pip 安装软件包
默认的 Colab 环境已经安装了 TensorFlow 和 Keras,因此您可以立即开始使用它,无需任何安装步骤。但是,如果您需要使用 pip 安装某些内容,您可以在代码单元格中使用以下语法进行安装(请注意,该行以 ! 开头,表示这是一个 shell 命令而不是 Python 代码):
!pip install package_name
使用 GPU 运行时
要在 Colab 中使用 GPU 运行时,请在菜单中选择 Runtime > Change Runtime Type,并选择 GPU 作为硬件加速器(参见图 3.5)。

图 3.5 使用 Colab 的 GPU 运行时
如果 GPU 可用,TensorFlow 和 Keras 将自动在 GPU 上执行,所以在选择了 GPU 运行时后,你无需做其他操作。
你会注意到在硬件加速器下拉菜单中还有一个 TPU 运行时选项。与 GPU 运行时不同,使用 TensorFlow 和 Keras 的 TPU 运行时需要在代码中进行一些手动设置。我们将在第十三章中介绍这个内容。目前,我们建议你选择 GPU 运行时,以便跟随本书中的代码示例。
现在你有了一个开始在实践中运行 Keras 代码的方法。接下来,让我们看看你在第二章学到的关键思想如何转化为 Keras 和 TensorFlow 代码。
3.5 TensorFlow 的第一步
正如你在之前的章节中看到的,训练神经网络围绕着以下概念展开:
-
首先,低级张量操作——支撑所有现代机器学习的基础设施。这转化为 TensorFlow API:
-
张量,包括存储网络状态的特殊张量(变量)
-
张量操作,如加法、
relu、matmul -
反向传播,一种计算数学表达式梯度的方法(在 TensorFlow 中通过
GradientTape对象处理)
-
-
其次,高级深度学习概念。这转化为 Keras API:
-
层,这些层组合成一个模型
-
一个损失函数,定义用于学习的反馈信号
-
一个优化器,确定学习如何进行
-
指标用于评估模型性能,如准确度
-
执行小批量随机梯度下降的训练循环
-
在上一章中,你已经初步接触了一些对应的 TensorFlow 和 Keras API:你已经简要使用了 TensorFlow 的Variable类、matmul操作和GradientTape。你实例化了 Keras 的Dense层,将它们打包成一个Sequential模型,并用fit()方法训练了该模型。
现在让我们深入了解如何使用 TensorFlow 和 Keras 在实践中处理所有这些不同概念。
3.5.1 常量张量和变量
要在 TensorFlow 中做任何事情,我们需要一些张量。张量需要用一些初始值创建。例如,你可以创建全为 1 或全为 0 的张量(见列表 3.1),或者从随机分布中抽取值的张量(见列表 3.2)。
列表 3.1 全为 1 或全为 0 的张量
>>> import tensorflow as tf
>>> x = tf.ones(shape=(2, 1)) # ❶
>>> print(x)
tf.Tensor(
[[1.]
[1.]], shape=(2, 1), dtype=float32)
>>> x = tf.zeros(shape=(2, 1)) # ❷
>>> print(x)
tf.Tensor(
[[0.]
[0.]], shape=(2, 1), dtype=float32)
❶ 等同于 np.ones(shape=(2, 1))
❷ 等同于 np.zeros(shape=(2, 1))
列表 3.2 随机张量
>>> x = tf.random.normal(shape=(3, 1), mean=0., stddev=1.) # ❶
>>> print(x)
tf.Tensor(
[[-0.14208166]
[-0.95319825]
[ 1.1096532 ]], shape=(3, 1), dtype=float32)
>>> x = tf.random.uniform(shape=(3, 1), minval=0., maxval=1.) # ❷
>>> print(x)
tf.Tensor(
[[0.33779848]
[0.06692922]
[0.7749394 ]], shape=(3, 1), dtype=float32)
❶ 从均值为 0、标准差为 1 的正态分布中抽取的随机值张量。等同于 np.random.normal(size=(3, 1), loc=0., scale=1.)。
❷ 从 0 到 1 之间均匀分布的随机值张量。等同于 np.random.uniform(size=(3, 1), low=0., high=1.)。
NumPy 数组和 TensorFlow 张量之间的一个重要区别是 TensorFlow 张量不可赋值:它们是常量。例如,在 NumPy 中,你可以这样做。
列表 3.3 NumPy 数组是可赋值的
import numpy as np
x = np.ones(shape=(2, 2))
x[0, 0] = 0.
尝试在 TensorFlow 中做同样的事情,你会得到一个错误:“EagerTensor 对象不支持项目赋值。”
列表 3.4 TensorFlow 张量不可赋值
x = tf.ones(shape=(2, 2))
x[0, 0] = 0. # ❶
❶ 这将失败,因为张量不可赋值。
要训练一个模型,我们需要更新它的状态,这是一组张量。如果张量不可赋值,我们该怎么办?这就是变量发挥作用的地方。tf.Variable是 TensorFlow 中用来管理可修改状态的类。你在第二章末尾的训练循环实现中已经简要看到它的作用。
要创建一个变量,你需要提供一些初始值,比如一个随机张量。
列表 3.5 创建一个 TensorFlow 变量
>>> v = tf.Variable(initial_value=tf.random.normal(shape=(3, 1)))
>>> print(v)
array([[-0.75133973],
[-0.4872893 ],
[ 1.6626885 ]], dtype=float32)>
变量的状态可以通过其assign方法修改,如下所示。
列表 3.6 给 TensorFlow 变量赋值
>>> v.assign(tf.ones((3, 1)))
array([[1.],
[1.],
[1.]], dtype=float32)>
它也适用于一部分系数。
列表 3.7 给 TensorFlow 变量的子集赋值
>>> v[0, 0].assign(3.)
array([[3.],
[1.],
[1.]], dtype=float32)>
同样,assign_add() 和 assign_sub() 是+= 和 -= 的高效等价物,如下所示。
列表 3.8 使用assign_add()
>>> v.assign_add(tf.ones((3, 1)))
array([[2.],
[2.],
[2.]], dtype=float32)>
3.5.2 张量操作:在 TensorFlow 中进行数学运算
就像 NumPy 一样,TensorFlow 提供了大量的张量操作来表达数学公式。以下是一些示例。
列表 3.9 几个基本数学操作
a = tf.ones((2, 2))
b = tf.square(a) # ❶
c = tf.sqrt(a) # ❷
d = b + c # ❸
e = tf.matmul(a, b) # ❹
e *= d # ❺
❶ 求平方。
❷ 求平方根。
❸ 两个张量相加(逐元素)。
❹ 两个张量的乘积(如第二章中讨论的)。
❺ 两个张量相乘(逐元素)。
重要的是,前面的每个操作都是即时执行的:在任何时候,你都可以打印出当前的结果,就像在 NumPy 中一样。我们称之为即时执行。
3.5.3 再看一下 GradientTape API
到目前为止,TensorFlow 看起来很像 NumPy。但这里有一件 NumPy 做不到的事情:检索任何可微表达式相对于其任何输入的梯度。只需打开一个GradientTape范围,对一个或多个输入张量应用一些计算,并检索结果相对于输入的梯度。
列表 3.10 使用GradientTape
input_var = tf.Variable(initial_value=3.)
with tf.GradientTape() as tape:
result = tf.square(input_var)
gradient = tape.gradient(result, input_var)
这通常用于检索模型损失相对于其权重的梯度:gradients = tape.gradient(loss, weights)。你在第二章中看到了这个过程。
到目前为止,你只看到了tape.gradient()中输入张量是 TensorFlow 变量的情况。实际上,这些输入可以是任意张量。然而,默认只有可训练变量会被跟踪。对于常量张量,你需要手动调用tape.watch()来标记它被跟踪。
列表 3.11 使用带有常量张量输入的GradientTape
input_const = tf.constant(3.)
with tf.GradientTape() as tape:
tape.watch(input_const)
result = tf.square(input_const)
gradient = tape.gradient(result, input_const)
为什么这是必要的?因为预先存储计算任何东西相对于任何东西的梯度所需的信息将会太昂贵。为了避免浪费资源,磁带需要知道要观察什么。可训练变量默认会被监视,因为计算损失相对于一组可训练变量的梯度是梯度磁带最常见的用法。
梯度磁带是一个强大的实用工具,甚至能够计算二阶梯度,也就是说,一个梯度的梯度。例如,一个物体的位置相对于时间的梯度是该物体的速度,而二阶梯度是它的加速度。
如果你测量一个沿垂直轴下落的苹果随时间的位置,并发现它验证position(time) = 4.9 * time ** 2,那么它的加速度是多少?让我们使用两个嵌套的梯度磁带来找出答案。
列表 3.12 使用嵌套的梯度磁带计算二阶梯度
time = tf.Variable(0.)
with tf.GradientTape() as outer_tape:
with tf.GradientTape() as inner_tape:
position = 4.9 * time ** 2
speed = inner_tape.gradient(position, time)
acceleration = outer_tape.gradient(speed, time) # ❶
❶ 我们使用外部磁带来计算内部磁带的梯度。自然地,答案是 4.9 * 2 = 9.8。
3.5.4 一个端到端的示例:在纯 TensorFlow 中的线性分类器
你已经了解了张量、变量和张量操作,也知道如何计算梯度。这足以构建基于梯度下降的任何机器学习模型。而你只是在第三章!
在机器学习工作面试中,你可能会被要求在 TensorFlow 中从头开始实现一个线性分类器:这是一个非常简单的任务,可以作为筛选具有一些最低机器学习背景和没有背景的候选人之间的过滤器。让我们帮你通过这个筛选器,并利用你对 TensorFlow 的新知识来实现这样一个线性分类器。
首先,让我们想出一些线性可分的合成数据来处理:2D 平面上的两类点。我们将通过从具有特定协方差矩阵和特定均值的随机分布中绘制它们的坐标来生成每一类点。直观地,协方差矩阵描述了点云的形状,均值描述了它在平面上的位置(参见图 3.6)。我们将为两个点云重复使用相同的协方差矩阵,但我们将使用两个不同的均值值——点云将具有相同的形状,但不同的位置。
列表 3.13 在 2D 平面上生成两类随机点
num_samples_per_class = 1000
negative_samples = np.random.multivariate_normal( # ❶
mean=[0, 3], # ❶
cov=[[1, 0.5],[0.5, 1]], # ❶
size=num_samples_per_class) # ❶
positive_samples = np.random.multivariate_normal( # ❷
mean=[3, 0], # ❷
cov=[[1, 0.5],[0.5, 1]], # ❷
size=num_samples_per_class) # ❷
❶ 生成第一类点:1000 个随机的 2D 点。cov=[[1, 0.5],[0.5, 1]] 对应于一个从左下到右上方向的椭圆形点云。
❷ 用不同均值和相同协方差矩阵生成另一类点。
在上述代码中,negative_samples 和 positive_samples 都是形状为 (1000, 2) 的数组。让我们将它们堆叠成一个形状为 (2000, 2) 的单一数组。
列表 3.14 将两类堆叠成形状为 (2000, 2) 的数组
inputs = np.vstack((negative_samples, positive_samples)).astype(np.float32)
让我们生成相应的目标标签,一个形状为 (2000, 1) 的零和一的数组,其中 targets[i, 0] 为 0,如果 inputs[i] 属于类 0(反之亦然)。
列表 3.15 生成相应的目标值 (0 和 1)
targets = np.vstack((np.zeros((num_samples_per_class, 1), dtype="float32"),
np.ones((num_samples_per_class, 1), dtype="float32")))
接下来,让我们用 Matplotlib 绘制我们的数据。
列表 3.16 绘制两类点(参见图 3.6)
import matplotlib.pyplot as plt
plt.scatter(inputs[:, 0], inputs[:, 1], c=targets[:, 0])
plt.show()

图 3.6 我们的合成数据:2D 平面上的两类随机点
现在让我们创建一个线性分类器,它可以学会分离这两个斑点。线性分类器是一个仿射变换(prediction = W • input + b),训练以最小化预测与目标之间差的平方。
正如你将看到的,这实际上比第二章末尾看到的玩具两层神经网络的端到端示例要简单得多。然而,这次你应该能够逐行理解代码的一切。
让我们创建我们的变量,W 和 b,分别用随机值和零值初始化。
列表 3.17 创建线性分类器变量
input_dim = 2 # ❶
output_dim = 1 # ❷
W = tf.Variable(initial_value=tf.random.uniform(shape=(input_dim, output_dim)))
b = tf.Variable(initial_value=tf.zeros(shape=(output_dim,)))
❶ 输入将是 2D 点。
❷ 输出预测将是每个样本的单个分数(如果样本被预测为类 0,则接近 0,如果样本被预测为类 1,则接近 1)。
这是我们的前向传播函数。
列表 3.18 前向传播函数
def model(inputs):
return tf.matmul(inputs, W) + b
因为我们的线性分类器操作在 2D 输入上,W 实际上只是两个标量系数,w1 和 w2:W = [[w1], [w2]]。同时,b 是一个单一的标量系数。因此,对于给定的输入点 [x, y],其预测值为 prediction = [[w1], [w2]] • [x, y] + b = w1 * x + w2 * y + b。
以下列表显示了我们的损失函数。
列表 3.19 均方误差损失函数
def square_loss(targets, predictions):
per_sample_losses = tf.square(targets - predictions) # ❶
return tf.reduce_mean(per_sample_losses) # ❷
❶ per_sample_losses 将是一个与目标和预测相同形状的张量,包含每个样本的损失分数。
❷ 我们需要将这些每个样本的损失函数平均为单个标量损失值:这就是 reduce_mean 所做的。
接下来是训练步骤,它接收一些训练数据并更新权重 W 和 b,以使数据上的损失最小化。
列表 3.20 训练步骤函数
learning_rate = 0.1
def training_step(inputs, targets):
with tf.GradientTape() as tape: # ❶
predictions = model(inputs) # ❶
loss = square_loss(predictions, targets) # ❶
grad_loss_wrt_W, grad_loss_wrt_b = tape.gradient(loss, [W, b]) # ❷
W.assign_sub(grad_loss_wrt_W * learning_rate) # ❸
b.assign_sub(grad_loss_wrt_b * learning_rate) # ❸
return loss
❶ 前向传播,在梯度磁带范围内
❷ 检索损失相对于权重的梯度。
❸ 更新权重。
为了简单起见,我们将进行批量训练而不是小批量训练:我们将对所有数据运行每个训练步骤(梯度计算和权重更新),而不是在小批量中迭代数据。一方面,这意味着每个训练步骤将需要更长时间运行,因为我们将一次计算 2,000 个样本的前向传播和梯度。另一方面,每个梯度更新将更有效地减少训练数据上的损失,因为它将包含所有训练样本的信息,而不是仅仅 128 个随机样本。因此,我们将需要更少的训练步骤,并且我们应该使用比通常用于小批量训练更大的学习率(我们将使用learning_rate = 0.1,在列表 3.20 中定义)。
列表 3.21 批量训练循环
for step in range(40):
loss = training_step(inputs, targets)
print(f"Loss at step {step}: {loss:.4f}")
经过 40 步,训练损失似乎已经稳定在 0.025 左右。让我们绘制我们的线性模型如何对训练数据点进行分类。因为我们的目标是 0 和 1,给定输入点将被分类为“0”,如果其预测值低于 0.5,将被分类为“1”,如果高于 0.5(见图 3.7):
predictions = model(inputs)
plt.scatter(inputs[:, 0], inputs[:, 1], c=predictions[:, 0] > 0.5)
plt.show()
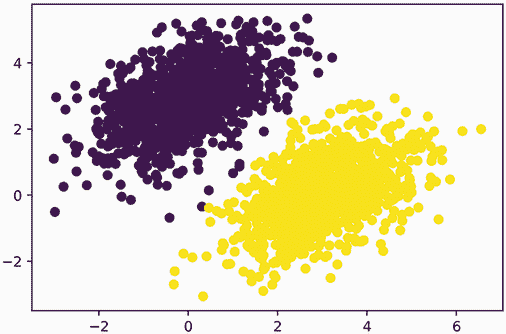
图 3.7 我们模型对训练输入的预测:与训练目标非常相似
请记住,给定点[x, y]的预测值简单地为prediction == [[w1], [w2]] • [x, y] + b == w1 * x + w2 * y + b。因此,类 0 被定义为w1 * x + w2 * y + b < 0.5,类 1 被定义为w1 * x + w2 * y + b > 0.5。你会注意到你所看到的实际上是二维平面上的一条直线方程:w1 * x + w2 * y + b = 0.5。在直线上方是类 1,在直线下方是类 0。你可能习惯于看到直线方程的格式为y = a * x + b;以相同格式,我们的直线变成了y = - w1 / w2 * x + (0.5 - b) / w2。
让我们绘制这条直线(如图 3.8 所示):
x = np.linspace(-1, 4, 100) # ❶
y = - W[0] / W[1] * x + (0.5 - b) / W[1] # ❷
plt.plot(x, y, "-r") # ❸
plt.scatter(inputs[:, 0], inputs[:, 1], c=predictions[:, 0] > 0.5) # ❹
❶ 生成 100 个在-1 到 4 之间均匀间隔的数字,我们将用它们来绘制我们的直线。
❷ 这是我们直线的方程。
❸ 绘制我们的直线("-r"表示“将其绘制为红色线”)。
❹ 绘制我们模型的预测在同一图中。
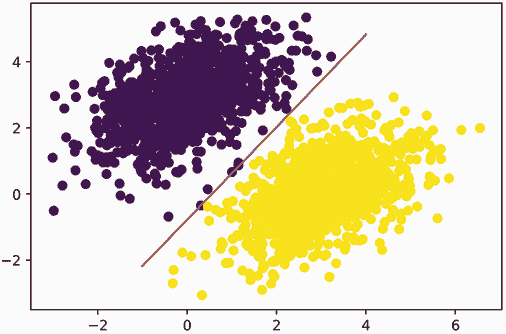
图 3.8 我们模型,可视化为一条直线
这才是线性分类器的真正含义:找到一个线(或者在更高维空间中,一个超平面)的参数,将两类数据清晰地分开。
3.6 神经网络的解剖:理解核心 Keras API
到目前为止,你已经了解了 TensorFlow 的基础知识,并且可以使用它从头开始实现一个玩具模型,比如前一节中的批量线性分类器,或者第二章末尾的玩具神经网络。这是一个坚实的基础,可以继续建立。现在是时候转向更具生产力、更健壮的深度学习路径了:Keras API。
3.6.1 层:深度学习的构建模块
神经网络中的基本数据结构是层,你在第二章中已经介绍过。层是一个数据处理模块,它以一个或多个张量作为输入,并输出一个或多个张量。一些层是无状态的,但更频繁的情况是层有一个状态:层的权重,一个或多个使用随机梯度下降学习的张量,它们一起包含网络的知识。
不同类型的层适用于不同的张量格式和不同类型的数据处理。例如,简单的向量数据,存储在形状为(samples, features)的秩-2 张量中,通常由密集连接层处理,也称为全连接或密集层(Keras 中的Dense类)。序列数据,存储在形状为(samples, timesteps, features)的秩-3 张量中,通常由循环层处理,例如LSTM层,或 1D 卷积层(Conv1D)。图像数据,存储在秩-4 张量中,通常由 2D 卷积层(Conv2D)处理。
你可以把层想象成深度学习的乐高积木,这个比喻在 Keras 中是明确的。在 Keras 中构建深度学习模型是通过将兼容的层剪辑在一起形成有用的数据转换流水线。
Keras 中的基础 Layer 类
一个简单的 API 应该围绕一个单一的抽象进行中心化。在 Keras 中,这就是Layer类。Keras 中的一切都是一个Layer或与Layer紧密交互的东西。
一个Layer是一个封装了一些状态(权重)和一些计算(前向传播)的对象。权重通常在build()中定义(尽管它们也可以在构造函数__init__()中创建),计算在call()方法中定义。
在前一章中,我们实现了一个NaiveDense类,其中包含两个权重W和b,并应用了计算output = activation(dot(input, W) + b)。这就是在 Keras 中相同层的样子。
列表 3.22 作为Layer子类实现的Dense层
from tensorflow import keras
class SimpleDense(keras.layers.Layer): # ❶
def __init__(self, units, activation=None):
super().__init__()
self.units = units
self.activation = activation
def build(self, input_shape): # ❷
input_dim = input_shape[-1]
self.W = self.add_weight(shape=(input_dim, self.units), # ❸
initializer="random_normal")
self.b = self.add_weight(shape=(self.units,),
initializer="zeros")
def call(self, inputs): # ❹
y = tf.matmul(inputs, self.W) + self.b
if self.activation is not None:
y = self.activation(y)
return y
❶ 所有的 Keras 层都继承自基础的 Layer 类。
❷ 权重的创建发生在build()方法中。
❸ add_weight()是一个创建权重的快捷方法。也可以创建独立的变量并将它们分配为层属性,如self.W = tf.Variable(tf.random.uniform(w_shape))。
❹ 我们在call()方法中定义了前向传播计算。
在接下来的部分中,我们将详细介绍这些build()和call()方法的目的。如果你现在还不理解,不要担心!
一旦实例化,像这样的层可以像函数一样使用,以 TensorFlow 张量作为输入:
>>> my_dense = SimpleDense(units=32, activation=tf.nn.relu) # ❶
>>> input_tensor = tf.ones(shape=(2, 784)) # ❷
>>> output_tensor = my_dense(input_tensor) # ❸
>>> print(output_tensor.shape)
(2, 32))
❶ 实例化我们之前定义的层。
❷ 创建一些测试输入。
❸ 在输入上调用层,就像调用函数一样。
你可能会想,为什么我们要实现call()和build(),因为我们最终只是简单地调用了我们的层,也就是说,使用了它的__call__()方法?这是因为我们希望能够及时创建状态。让我们看看它是如何工作的。
自动形状推断:动态构建层
就像乐高积木一样,你只能“连接”兼容的层。这里的层兼容性概念特指每个层只接受特定形状的输入张量,并返回特定形状的输出张量。考虑以下示例:
from tensorflow.keras import layers
layer = layers.Dense(32, activation="relu") # ❶
❶ 一个具有 32 个输出单元的密集层
这个层将返回一个张量,其中第一个维度已经被转换为 32。它只能连接到一个期望 32 维向量作为输入的下游层。
在使用 Keras 时,大多数情况下你不必担心大小的兼容性,因为你添加到模型中的层会动态构建以匹配传入层的形状。例如,假设你写下以下内容:
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential([
layers.Dense(32, activation="relu"),
layers.Dense(32)
])
层没有接收到关于它们输入形状的任何信息——相反,它们自动推断它们的输入形状为它们看到的第一个输入的形状。
在我们在第二章中实现的Dense层的玩具版本中(我们称之为NaiveDense),我们必须显式地将层的输入大小传递给构造函数,以便能够创建其权重。这并不理想,因为这将导致模型看起来像这样,其中每个新层都需要知道其前一层的形状:
model = NaiveSequential([
NaiveDense(input_size=784, output_size=32, activation="relu"),
NaiveDense(input_size=32, output_size=64, activation="relu"),
NaiveDense(input_size=64, output_size=32, activation="relu"),
NaiveDense(input_size=32, output_size=10, activation="softmax")
])
如果一个层用于生成其输出形状的规则很复杂,情况会变得更糟。例如,如果我们的层返回形状为(batch, input_ size * 2 if input_size % 2 == 0 else input_size * 3)的输出会怎样?
如果我们要将我们的NaiveDense层重新实现为一个能够自动推断形状的 Keras 层,它将看起来像之前的SimpleDense层(见列表 3.22),具有其build()和call()方法。
在SimpleDense中,我们不再像NaiveDense示例中那样在构造函数中创建权重;相反,我们在一个专门的状态创建方法build()中创建它们,该方法接收层首次看到的第一个输入形状作为参数。build()方法在第一次调用层时(通过其__call__()方法)会自动调用。事实上,这就是为什么我们将计算定义在单独的call()方法中而不是直接在__call__()方法中的原因。基础层的__call__()方法基本上是这样的:
def __call__(self, inputs):
if not self.built:
self.build(inputs.shape)
self.built = True
return self.call(inputs)
有了自动形状推断,我们之前的示例变得简单而整洁:
model = keras.Sequential([
SimpleDense(32, activation="relu"),
SimpleDense(64, activation="relu"),
SimpleDense(32, activation="relu"),
SimpleDense(10, activation="softmax")
])
请注意,自动形状推断并不是Layer类的__call__()方法处理的唯一事情。它还处理许多其他事情,特别是在eager和graph执行之间的路由(这是你将在第七章学习的概念),以及输入掩码(我们将在第十一章中介绍)。现在,只需记住:当实现自己的层时,将前向传播放在call()方法中。
3.6.2 从层到模型
深度学习模型是一系列层的图。在 Keras 中,这就是Model类。到目前为止,你只看到过Sequential模型(Model的子类),它们是简单的层堆叠,将单个输入映射到单个输出。但随着你的学习,你将接触到更广泛的网络拓扑。以下是一些常见的拓扑结构:
-
双分支网络
-
多头网络
-
残差连接
网络拓扑可能会变得非常复杂。例如,图 3.9 显示了 Transformer 的层图拓扑,这是一种常见的用于处理文本数据的架构。
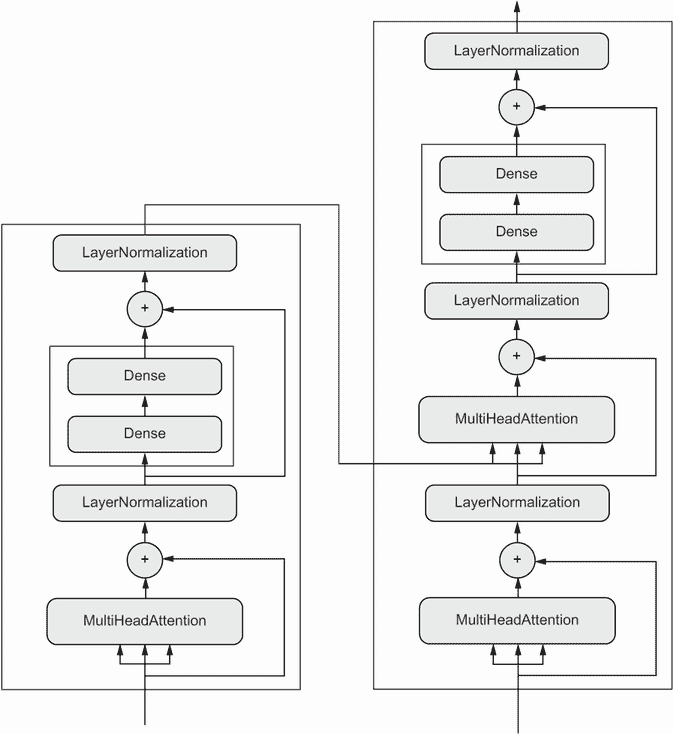
图 3.9 变压器架构(在第十一章中介绍)。这里面有很多内容。在接下来的几章中,你将逐步理解它。
在 Keras 中通常有两种构建这种模型的方法:你可以直接子类化Model类,或者你可以使用 Functional API,它让你用更少的代码做更多的事情。我们将在第七章中涵盖这两种方法。
模型的拓扑定义了一个假设空间。你可能还记得,在第一章中我们将机器学习描述为在预定义的可能性空间内搜索一些输入数据的有用表示,使用来自反馈信号的指导。通过选择网络拓扑,你将限制你的可能性空间(假设空间)到一系列特定的张量操作,将输入数据映射到输出数据。接下来,你将搜索这些张量操作中涉及的权重张量的良好值集。
要从数据中学习,您必须对其进行假设。这些假设定义了可以学到的内容。因此,您的假设空间的结构——模型的架构——非常重要。它编码了您对问题的假设,模型开始的先验知识。例如,如果您正在处理一个由单个Dense层组成且没有激活函数(纯仿射变换)的模型的两类分类问题,那么您假设您的两类是线性可分的。
选择正确的网络架构更多地是一门艺术而不是一门科学,尽管有一些最佳实践和原则可以依靠,但只有实践才能帮助你成为一个合格的神经网络架构师。接下来的几章将教授您构建神经网络的明确原则,并帮助您培养对于特定问题的有效性或无效性的直觉。您将建立对于不同类型问题适用的模型架构的坚实直觉,如何在实践中构建这些网络,如何选择正确的学习配置,以及如何调整模型直到产生您想要看到的结果。
3.6.3 “compile”步骤:配置学习过程
一旦模型架构被定义,您仍然必须选择另外三个事项:
-
损失函数(目标函数)—在训练过程中将被最小化的数量。它代表了任务的成功度量。
-
优化器—根据损失函数确定网络要如何更新。它实现了随机梯度下降(SGD)的特定变体。
-
Metrics—在训练和验证过程中要监视的成功度量,例如分类准确度。与损失不同,训练不会直接为这些指标进行优化。因此,指标不需要可微分。
一旦您选择了损失、优化器和指标,您可以使用内置的compile()和fit()方法开始训练您的模型。或者,您也可以编写自己的自定义训练循环——我们将在第七章中介绍如何做到这一点。这是更多的工作!现在,让我们看看compile()和fit()。
compile()方法配置训练过程——你在第二章的第一个神经网络示例中已经见过它。它接受optimizer、loss和metrics(一个列表)作为参数:
model = keras.Sequential([keras.layers.Dense(1)]) # ❶
model.compile(optimizer="rmsprop", # ❷
loss="mean_squared_error", # ❸
metrics=["accuracy"]) # ❹
❶ 定义一个线性分类器。
❷ 通过名称指定优化器:RMSprop(不区分大小写)。
❸ 通过名称指定损失:均方误差。
❹ 指定一个指标列表:在这种情况下,只有准确度。
在前面对compile()的调用中,我们将优化器、损失和指标作为字符串传递(例如"rmsprop")。这些字符串实际上是转换为 Python 对象的快捷方式。例如,"rmsprop"变成了keras.optimizers.RMSprop()。重要的是,也可以将这些参数指定为对象实例,如下所示:
model.compile(optimizer=keras.optimizers.RMSprop(),
loss=keras.losses.MeanSquaredError(),
metrics=[keras.metrics.BinaryAccuracy()])
如果您想传递自定义损失或指标,或者如果您想进一步配置您正在使用的对象,例如通过向优化器传递learning_rate参数:
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=1e-4),
loss=my_custom_loss,
metrics=[my_custom_metric_1, my_custom_metric_2])
在第七章中,我们将介绍如何创建自定义损失和指标。一般来说,您不必从头开始创建自己的损失、指标或优化器,因为 Keras 提供了广泛的内置选项,很可能包括您需要的内容:
优化器:
-
SGD(带有或不带有动量) -
RMSprop -
Adam -
Adagrad -
等等。
损失:
-
CategoricalCrossentropy -
SparseCategoricalCrossentropy -
BinaryCrossentropy -
MeanSquaredError -
KLDivergence -
CosineSimilarity -
等等。
指标:
-
CategoricalAccuracy -
SparseCategoricalAccuracy -
BinaryAccuracy -
AUC -
Precision -
Recall -
等等。
在本书中,您将看到许多这些选项的具体应用。
3.6.4 选择损失函数
为正确的问题选择正确的损失函数非常重要:你的网络会尽其所能缩小损失,因此如果目标与当前任务的成功并不完全相关,你的网络最终可能会执行一些你不希望的操作。想象一下,通过使用这个选择不当的目标函数(“最大化所有活着人类的平均幸福感”)进行 SGD 训练的愚蠢、全能的 AI。为了简化工作,这个 AI 可能选择杀死除少数人外的所有人类,并专注于剩下人的幸福感——因为平均幸福感不受剩余人数的影响。这可能不是你想要的结果!请记住,你构建的所有神经网络都会像这样无情地降低它们的损失函数,因此明智地选择目标,否则你将面临意想不到的副作用。
幸运的是,对于常见问题如分类、回归和序列预测,你可以遵循简单的准则来选择正确的损失函数。例如,对于两类分类问题,你将使用二元交叉熵,对于多类分类问题,你将使用分类交叉熵,依此类推。只有在处理真正新的研究问题时,你才需要开发自己的损失函数。在接下来的几章中,我们将明确详细地介绍为各种常见任务选择哪些损失函数。
3.6.5 理解 fit() 方法
在 compile() 之后是 fit()。fit() 方法实现了训练循环本身。以下是它的关键参数:
-
用于训练的数据(输入和目标)。通常会以 NumPy 数组或 TensorFlow
Dataset对象的形式传递。你将在接下来的章节中更多地了解DatasetAPI。 -
训练的轮数:训练循环应该迭代传递的数据多少次。
-
在每个迷你批次梯度下降的 epoch 中使用的批次大小:用于计算一次权重更新步骤的训练示例数量。
第 3.23 节 使用 NumPy 数据调用 fit()
history = model.fit(
inputs, # ❶
targets, # ❷
epochs=5, # ❸
batch_size=128 # ❹
)
❶ 输入示例,作为 NumPy 数组
❷ 相应的训练目标,作为 NumPy 数组
❸ 训练循环将在数据上迭代 5 次。
❹ 训练循环将以 128 个示例的批次迭代数据。
调用 fit() 返回一个 History 对象。该对象包含一个 history 字段,它是一个将诸如 "loss" 或特定指标名称映射到每个 epoch 值列表的字典。
>>> history.history
{"binary_accuracy": [0.855, 0.9565, 0.9555, 0.95, 0.951],
"loss": [0.6573270302042366,
0.07434618508815766,
0.07687718723714351,
0.07412414988875389,
0.07617757616937161]}
3.6.6 监控验证数据上的损失和指标
机器学习的目标不是获得在训练数据上表现良好的模型,这很容易——你只需遵循梯度。目标是获得在一般情况下表现良好的模型,特别是在模型从未遇到过的数据点上表现良好。仅仅因为一个模型在训练数据上表现良好并不意味着它会在从未见过的数据上表现良好!例如,你的模型可能最终只是记忆训练样本和它们的目标之间的映射,这对于预测模型从未见过的数据的目标是无用的。我们将在第五章中更详细地讨论这一点。
为了监视模型在新数据上的表现,通常会将训练数据的一个子集保留为验证数据:你不会在这些数据上训练模型,但会用它们来计算损失值和指标值。你可以通过在 fit() 中使用 validation_data 参数来实现这一点。与训练数据类似,验证数据可以作为 NumPy 数组或 TensorFlow Dataset 对象传递。
第 3.24 节 使用 validation_data 参数
model = keras.Sequential([keras.layers.Dense(1)])
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=0.1),
loss=keras.losses.MeanSquaredError(),
metrics=[keras.metrics.BinaryAccuracy()])
indices_permutation = np.random.permutation(len(inputs)) # ❶
shuffled_inputs = inputs[indices_permutation] # ❶
shuffled_targets = targets[indices_permutation] # ❶
num_validation_samples = int(0.3 * len(inputs)) # ❷
val_inputs = shuffled_inputs[:num_validation_samples] # ❷
val_targets = shuffled_targets[:num_validation_samples] # ❷
training_inputs = shuffled_inputs[num_validation_samples:] # ❷
training_targets = shuffled_targets[num_validation_samples:] # ❷
model.fit(
training_inputs, # ❸
training_targets, # ❸
epochs=5,
batch_size=16,
validation_data=(val_inputs, val_targets) # ❹
)
❶ 为了避免在验证数据中只有一个类的样本,使用随机索引排列来对输入和目标进行洗牌。
❷ 保留 30%的训练输入和目标用于验证(我们将排除这些样本进行训练,并保留它们来计算验证损失和指标)。
❸ 用于更新模型权重的训练数据
❹ 仅用于监控验证损失和指标的验证数据
在验证数据上的损失值称为“验证损失”,以区别于“训练损失”。请注意,保持训练数据和验证数据严格分开是至关重要的:验证的目的是监测模型学习的内容是否实际上对新数据有用。如果模型在训练过程中看到任何验证数据,您的验证损失和指标将是有缺陷的。
请注意,如果您想在训练完成后计算验证损失和指标,可以调用evaluate()方法:
loss_and_metrics = model.evaluate(val_inputs, val_targets, batch_size=128)
evaluate()将在传递的数据上以批量(大小为batch_size)迭代,并返回一个标量列表,其中第一个条目是验证损失,后一个条目是验证指标。如果模型没有指标,只返回验证损失(而不是列表)。
3.6.7 推断:在训练后使用模型
一旦您训练好模型,您将想要使用它在新数据上进行预测。这被称为推断。为此,一个简单的方法就是简单地__call__()模型:
predictions = model(new_inputs) # ❶
❶ 接受一个 NumPy 数组或 TensorFlow 张量,并返回一个 TensorFlow 张量
然而,这将一次性处理new_inputs中的所有输入,如果你要处理大量数据可能不可行(特别是可能需要比你的 GPU 更多的内存)。
进行推断的更好方法是使用predict()方法。它将以小批量迭代数据,并返回一个预测的 NumPy 数组。与__call__()不同,它还可以处理 TensorFlow 的Dataset对象。
predictions = model.predict(new_inputs, batch_size=128) # ❶
❶ 接受一个 NumPy 数组或数据集,并返回一个 NumPy 数组
例如,如果我们对之前训练过的线性模型使用predict()在一些验证数据上,我们会得到对应于模型对每个输入样本的预测的标量分数:
>>> predictions = model.predict(val_inputs, batch_size=128)
>>> print(predictions[:10])
[[0.3590725 ]
[0.82706255]
[0.74428225]
[0.682058 ]
[0.7312616 ]
[0.6059811 ]
[0.78046083]
[0.025846 ]
[0.16594526]
[0.72068727]]
目前,这就是您需要了解的关于 Keras 模型的全部内容。您已经准备好在下一章节中使用 Keras 解决真实世界的机器学习问题了。
摘要
-
TensorFlow 是一个工业强度的数值计算框架,可以在 CPU、GPU 或 TPU 上运行。它可以自动计算任何可微表达式的梯度,可以分布到许多设备,还可以将程序导出到各种外部运行时,甚至 JavaScript。
-
Keras 是使用 TensorFlow 进行深度学习的标准 API。这是我们将在整本书中使用的。
-
TensorFlow 的关键对象包括张量、变量、张量操作和梯度带。
-
Keras 的核心类是
Layer。一个层封装了一些权重和一些计算。层被组装成模型。 -
在开始训练模型之前,您需要选择一个优化器,一个损失和一些指标,您可以通过
model.compile()方法指定。 -
要训练一个模型,您可以使用
fit()方法,它为您运行小批量梯度下降。您还可以使用它来监视您在验证数据上的损失和指标,这是模型在训练过程中没有看到的一组输入。 -
一旦您的模型训练完成,您可以使用
model.predict()方法在新输入上生成预测。



![练习 10 Web [MRCTF2020]你传你呢](https://img-blog.csdnimg.cn/direct/16aad8fae7fc4c0395601e3c49b0ec82.png)







![[pytorch] detr源码浅析](https://img-blog.csdnimg.cn/direct/5a5e7332291f4706a4f3848527cf32af.png)