文章来源于山有木兮
原文链接:https://edu.cda.cn/goods/show/3412?targetId=5695&preview=0
第1节 SQL简介与基础知识
做数据分析的,为什么要写SQL?
没有数据的情况下,我们分析数据就像是巧妇难为无米之炊。因此,为了进行数据分析,我们必须获取数据。而大多数情况下,数据都存放在数据库中,这时候我们就必须要学会SQL取数了。
除了一部分公司专人专岗,有人帮你查好数据发你做分析,大部分情况还是需要你自己取数的。
本次我们沿用之前《极简统计学入门》的“MVP”思路,用三节的内容梳理一下SQL(基于MySQL8.0),整个系列框架如下
- 第1节 SQL简介与基础知识
- SQL简介
- SQL查询基础之DDL、DML、DQL
- SQL数据类型
- SQL查询的执行顺序
- 第2节 窗口分析函数
- 窗口函数
- 分析函数
- 第3节 SQL近N日登录与连续登录N日问题
- 连续登录N天的用户数量
- 第4节 近N日留存的用户数及留存率
- 近N日留存的用户数及留存率
1. SQL简介
我们知道,SQL(结构化查询语言)是一种数据库语言,按照功能分类,有DDL、DQL、DML、DCL、TCL 五大类型,简单了解一下它们分别是做什么用的:
(1)DDL(Data Definition Language)
DDL是数据定义语言,主要用来定义或者改变表的结构。例如:create、alter、drop、truncate等语句。
(2)DQL(Data Query Language)
DQL是数据查询语言,主要用来从表中检索数据。例如:select语句。
(3)DML(Data Manipulation Language)
DML是数据操作语言,主要用来对数据库里表中的数据进行操作。例如:insert、delete、update等语句。
(4)DCL(Data Control Language)
DCL是数据控制语言,主要用来设置或更改数据库用户或角色对数据的访问权限。例如:grant、revoke等语句。
(5)TCL(Transaction Control Language)
TCL是事务控制语言,主要用来控制事务。例如:COMMIT、ROLLBACK等语句。
了解了以上分类,我们简单回顾一下其中DDL、DML、DQL的基础语法(有基础的可直接跳过看SQL查询与执行顺序)
2. SQL基础之DDL、DML、DQL
① 数据定义语言 (DDL)
定义数据库当中的对象 (库、表) 关键字: create、delete、alter、show
创建数据库
- 创建数据库
create database 数据库名 - 创建指定字符集的数据库
create database 数据库名 charset set 字符集编码 - 创建一个数据库(先判断数据库是否已存在,如果不存在则进行创建)
create database if not exist数据库名
查看数据库
- 查询所有数据库名称
show database;
- 查询指定数据库的字符集 并显示创建语句
show create database 数据库名;
删除数据库
- 删除指定数据库
drop database 数据库名;
- 删除指定数据库,如果不存在则不删除
drop database 数据库名 if exist;
进入指定数据库
use 数据库名;
创建表
create table 表名(字段名 字段类型)
create table table_name
(
column_1 int null,
column_2 int null
);
复制表
- 只复制结构
create table 新表名 like 被复制的表名;
执行上述语句后,将创建一个名为table2的新表,其结构与table1完全相同,但不会复制table1中的任何数据。
- 复制结构和数据
create table 新表名 as select * from 被复制的表名;
上述语句将创建一个名为table2的新表,其结构和数据与table1完全相同。
查询表
- 查询库里面有哪些表
show tables;
- 查询表的结构
describe 表名;
- 查询指定表的创建语句
show create table 表名;
修改表
- 给表添加 (多个) 字段
alter table 表名 add column (字段名 字段类型,字段名 字段类型);
- 修改表字段的数据类型
alter table 表名 modify column 字段名 字段类型;
- 修改表字段的字段名
alter table 表名 change column 旧字段名 新字段名 字段类型;
- 删除一个字段
alter table 表名 drop column 字段名;
- 修改表名
alter table 表名 rename 新表名;
② 数据操作语言 (DML)
操作数据 (增、删、改) 关键字: insert、delete、update
添加数据
- 指定列名添加
insert into 表名 (字段名1,字段名2) values(数值1,数值2);
- 全部列的添加
insert into 表名 values (数值1,···,最后一个数值);
- 一次性插入多条数据
insert into 表名 values
(数值1_1,数值2_1···,最后一个数值n_1),
(数值1_2,数值2_2···,最后一个数值n_2),
(数值1_n,数值2_n···,最后一个数值n_n);
删除数据
- 删除表的指定数据
delete from 表名 where 字段名 = 字段值;
- truncate 删除全表的数据
truncate table 表名;
- drop 删除全表(包括定义和数据。)
drop table 表名;
drop、truncate、delete 三者的区别
drop用于删除数据库对象,包括定义和数据。truncate用于删除表中的所有数据,但保留表的定义。delete用于删除表中的行,可以根据条件删除特定的数据,并且可以回滚。
修改数据
- 修改指定字段数据
update 表名 set 字段名 = 数据值 where 字段名 = 数据值;
- 同时修改多个字段
update 表名 set 字段名1=数据值1,字段名2=数据值2 where 字段名 = 数据值;
- 在基础数据上进行修改(某列的值减去3)
update 表名 set 字段名1 = 字段名1 -3;
③ 数据库查询语言 (DQL)
查询数据
- 查询表中所有数据
select * from 表名;
- 查询表的指定列
select 字段名1, 字段名2 from 表名;
- 指定别名查询
select 字段名 as 别名 from 表名;
- 常量列查询
select 字段名 as 自定义名字,临时常量 as 别名 from 表名;
- 合并列查询
select 字段名 as 自定义名字,(字段 1 + 字段2) as 别名 from 表名;
条件查询 (跟在 where 后面的关键字) 条件运算符
< # 小于
> # 大于
<= # 小于等于
>= # 大于等于
<> # 不等于
!= # 不等于
between…and… # 在……范围内
in # 包括
like # 模糊查询
is null # 是否为空
and # 且
or # 或
not # 非
模糊查询
select * from 表名 where 字段名 like "关键词";
select * from 表名 where 字段名 like "%hello%";
select * from 表名 where 字段名 like "%_大学%";
聚合查询
- max():获取查询后结果的最大值
select max(字段名) from 表名;
- min():获取查询后结果的最小值
select min(字段名) from 表名;
- avg():获取查询后结果的平均值
select avg(字段名) from 表名;
- sum():获取查询后结果的总和
select sum(字段名) from 表名;
- count():获取查询后结果的总记录数
select count (字段名) from 表名;
排序查询关键字: order by 默认是升序 asc,降序 desc
select *
from table_class
order by id desc;
分组查询关键字:group by
- 统计每个班级有多少人
select class_name,count(*)
from table_class
group by class_name;
- 统计班级人数大于2个人的班级
select class_name,count(*)
from table_class
group by class_name
having count (*)>=2;
内连接查询
两张表交叉后并且过滤后的数据查询 (交集)关键字: inner join
select *
from table_a a
inner join table_b b
on a.aid = b.bid;
左 (外) 连接查询
左表 (table_a) 的记录将会全部表示出来,而右表 (table_b) 只会显示符合搜索条件的记录,右表记录不足的地方均为 NULL 关键字: left join。
select *
from table_a a
left join table_b b
on a.a_id = b.b_id;
右 (外) 连接查询
左表 (a_table) 只会显示符合搜索条件的记录,而右表 (b_table) 的记录将会全部表示出来,左表记录不足的地方均为 null 关键字: right join
select *
from table_a a
right join table_b b
on a.a_id = b.b_id;
结果合并
(select colum_1,colum_2,...,colum_n
from table_a)
union
(select colum_1,colum_2,...,colum_n
from table_b)
-
两个select语句具有相同的列数和相似的数据类型。如果列数不匹配,可以使用null或者空字符串填充缺失的列
-
使用 union 时,数据完全相同的记录,将会被合并,由于合并比较耗时,一般不直接使用 union 进行合并,而是采用 union all进行合并。
(select id,name from table_a
order by id)
union all
(select id,name from table_b
order by id);
#没有排序效果
(select id,name from table_a )
union all
(select id,name from table_b )
order by id;
#有排序效果
子查询
将一个 SQL 语句的查询结果 (单列数据) 作为另一个 SQL 语句的查询条件。
select *
from table_a
where id_a in
(select id_b
from table_a);
好了,以上内容,我们简单回顾了一下SQL的基本函数,下面我们开始正式内容:
如果你接触过不同编程语言就会发现,任何编程语言的学习,都离不开3个最基本的核心要素,数据类型、流程控制、函数
数据类型是用来描述数据的性质和特征的,它决定了数据在计算和处理过程中的行为和规则。常见的数据类型包括整数、浮点数、字符串、日期等。简而言之,数据类型就是你将要操作的东西具有什么样的特点。
流程控制是指通过条件判断和循环等方式,控制程序按照一定的顺序执行不同的操作步骤。它决定了数据的处理流程,包括判断条件、循环次数、分支选择等。简而言之,流程控制解决的问题就是你要操作这个东西的基本流程是什么。
函数是一段预先定义好的代码,用于执行特定的操作或计算。它接受输入参数,并返回一个结果。函数可以用来对数据进行各种计算、转换、筛选等操作,以满足特定的需求。简而言之,函数解决的问题就是你要怎么样才能可复用地操作这一类东西。
SQL极简教程系列我们重点讨论数据类型与函数,下面我们先来看第一个核心要素:
3. 数据类型
① 整数类型
| 整数类型 | 用途 | 范围 |
|---|---|---|
| tinyint | 用于存储小整数值 | -128到127,即( − 2 7 -2^7 −27)到( 2 7 − 1 2^7-1 27−1) |
| smallint | 用于存储较小的整数值 | -32768到32767 ,即( − 2 15 -2^{15} −215)到( 2 15 − 1 2^{15}-1 215−1) |
| mediumint | 用于存储中等大小的整数值 | -8388608到 8388607 ,即( − 2 23 -2^{23} −223)到( 2 23 − 1 2^{23}-1 223−1) |
| int | 用于存储普通大小的整数值 | -2147483648到2147483647,即 ( − 2 31 -2^{31} −231)到( 2 31 − 1 2^{31}-1 231−1) |
| bigint | 用于存储大整数值 | -9223372036854775808到9223372036854775807,即 ( − 2 63 -2^{63} −263) 到 ( ( 2 63 ) − 1 (2^{63})-1 (263)−1) |
② 浮点类型
| 浮点类型 | 用途 | 范围 |
|---|---|---|
| float | 用于存储单精度浮点数值 | -3.402823466E+38到-1.175494351E-38,0,1.175494351E-38到3.402823466E+38 |
| double | 用于存储双精度浮点数值 | -1.7976931348623157E+308到-2.2250738585072014E-308,0,2.2250738585072014E-308到1.7976931348623157E+308 |
③ 字符串类型
| 数据类型 | 用途 | 特点 |
|---|---|---|
| char | 用于存储固定长度的字符串 | 存储的字符串长度固定,最多可以存储255个字符 |
| varchar | 用于存储可变长度的字符串 | 存储的字符串长度可变,最多可以存储65535个字符 |
| binary | 用于存储二进制数据 | 存储的数据以二进制形式存储,最多可以存储255个字节 |
| varbinary | 用于存储可变长度的二进制数据 | 存储的数据以二进制形式存储,长度可变,最多可以存储65535个字节 |
| text | 用于存储较长的文本数据 | 存储的文本数据长度可变,最多可以存储65535个字符 |
| blob | 用于存储较大的二进制数据 | 存储的二进制数据长度可变,最多可以存储65535个字节 |
④ 日期类型
| 数据类型 | 用途 | 范围 |
|---|---|---|
| date | 用于存储日期值 | ‘1000-01-01’到’9999-12-31’ |
| time | 用于存储时间值 | ‘-838:59:59’到’838:59:59’ |
| datetime | 用于存储日期和时间值 | ‘1000-01-01 00:00:00’到’9999-12-31 23:59:59’ |
| timestamp | 用于存储日期和时间值,自动更新 | ‘1970-01-01 00:00:01’ UTC到’2038-01-19 03:14:07’ UTC |
| year | 用于存储年份值 | 1901到2155 |
如果上面内容看明白了,恭喜你已经学会了如何描述你要操作的对象的特点了,接着我们看第二个核心问题:函数。一般无外乎针对字符串的函数、针对日期的函数、针对数值运算的函数、以及操作数据转化的函数:
5、函数
① 字符串函数
**字符串函数:**返回字符串的长度
select length('learn_mysql_and_find_a_data_analysis_job') str_len;
**字符串连接函数:**返回输入字符串连接后的结果,支持任意个输入字符串
select concat('Certified','Data','Analyst') as str_concat;
带分隔符字符串连接函数: 返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符
select concat_ws('_','Certified','Data','Analyst') as str_concat_ws;
字符串截取函数: 返回字符串从start位置到结尾的字符串
select substr('Certified_Data_Analyst',11);
select substr('Certified_Data_Analyst',-12);
字符串截取函数: 返回字符串从start位置开始,长度为len的字符串
select substr('Certified_Data_Analyst',11,4);
select substring('Certified_Data_Analyst',-7,7);
字符串转大写函数:upper,ucase 返回字符串A的大写格式
select upper('certified_data_analyst');
select ucase('certified_data_analyst');
字符串转小写函数:lower,lcase 返回字符串A的小写格式
select lower('CERTIFIED_DATA_ANALYST');
select lcase('CERTIFIED_DATA_ANALYST');
**字符串反转函数:**返回字符串的反转结果
select reverse('learn_mysql') as str_rev;
去空格函数:trim 去除字符串两边的空格
select trim(' Data ');
左边去空格函数:ltrim去除字符串左边的空格
select ltrim(' Data ');
右边去空格函数:rtrim 去除字符串右边的空格
select rtrim(' Data '); `
空格字符串函数:space 返回长度为n的字符串
select space(10);
select length(space(10));
重复字符串函数:repeat 返回重复n次后的str字符串
select repeat('SQL',5);
左补足函数:lpad 将str进行用pad进行左补足到len位
select lpad('MySQL',11,'go');
右补足函数:rpad 将str进行用pad进行右补足到len位
select rpad('MySQL',11,'go');
分割字符串函数: mysql里面没有直接做字符串分割的函数,substring_index 按照pat字符串分割str,会返回分割后的字符串数组
select substring_index('Certified_Data_Analyst', '_', 1) AS part1,
substring_index(substring_index('Certified_Data_Analyst', '_', 2), '_', -1) AS part2,
substring_index(substring_index('Certified_Data_Analyst', '_', 3), '_', -1) AS part3;
集合查找函数: find_in_set 返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0
select find_in_set('data', 'certified,data,analyst');
select find_in_set('mysql','certified,data,analyst');
正则表达式替换函数:regexp_replace将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符
select regexp_replace('learn_mysql_and_python', 'mysal|python', 'programming');
正则表达式提取函数:regexp_extract 返回第一个匹配的子字符串
select regexp_substr('mysql8', '[0-9]+') extracted_number;
② 数学函数
四舍五入:round
select round(3.14159); # round(a) 返回a的值,并对a四舍五入
select round(3.14159,3); # round(a, n) 返回保留n小数位和四舍五入后的a的值
向上取整:ceil
select ceil(3.14);
select ceiling(3.14);
select ceil(-3.14);
向下取整:floor
select floor(3.14);
select floor(-3.14);
求取随机数:rand
select rand(); # 每行返回一个double型随机数
select rand(100); # 每行返回一个double型随机数,整数seed是随机因子的种子;
其他数学运算函数
# exp(d) #返回e的 d幂次方,返回double型;
select exp(1); # e的1次方
# 2.718281828459045
# ln(d) #以自然数为底d的对数,返回double型;
select ln(exp(1)); # 以e为底e的对数
# 1
# log2(d) #以2为底d的对数,返回double型;
select log2(8);
# 3
# log10(d) #以10为底d的对数,返回double型;
select log10(100);
# 2
# log(a, b) #以a为底b的对数,返回double型;
select log(3,9);
# 2
# pow(x, n) # x 的n次幂,返回double型;
select pow(10,2);
# 100
# sqrt(DOUBLE d) #d的平方根,返回double型;
select sqrt(16);
# 4
# abs(DOUBLE d) #返回d的绝对值,结果为double型;
select abs(-3.14);
# 3.14
# sin() #返回d的正弦值,结果为double型;
select sin(radians(30));
# 0.49999999999999994
# cos() #返回d 的余弦值,结果为double型;
select tan(radians(60));
# 0.5000000000000001
# tan() #返回d的正切值,结果为double型;
select tan(radians(45));
# 0.9999999999999999
# asin() #返回d的反正弦值,结果为double型;
select degrees(asin(0.5));
# 30.000000000000004
# acos() #返回d的反余弦值,结果为double型;
select degrees(acos(0.5));
# 60.00000000000001
# atan() #返回d的反正切值,结果为double型;
select degrees(atan(1));
# 45
# PI() #数学常数Pi,圆周率;
select PI();
# 3.141593
③ 日期函数
获取日期 date() 返回时间字符串的日期部分
select date('2023-09-21 15:06:51');
获取年月日
year()、month()、day() 从一个日期中取出相应的年、月、日
select
year('2023-09-21 15:06:51'),
month('2023-09-21 15:06:51'),
day('2023-09-21 15:06:51');
获取第几周
weekofyear() 返回输入日期在该年中是第几个星期
select weekofyear('2023-09-21 15:06:51');
获取指定间隔的日期
- date_add() 在一个日期基础上增加天数
- date_sub() 在一个日期基础上减去天数
#请问,2023-09-21起,7天以后的日期是?7天前的日期是?
select date_add('2023-09-21',interval 7 day) as seven_days_after,
date_sub('2023-09-21',interval 7 day ) as seven_days_before;
# 当前日期,7天以后的日期是?7天前的日期是?
select date_add(current_date(),interval 7 day) as seven_days_after, date_sub(current_date(),interval 7 day) as seven_days_before;
获取两个日期之差
返回的是数字
- datediff() 计算开始时间startdate到结束时间enddate相差的天数
select datediff('2023-09-21 15:06:51','2003-09-21 15:06:51');
# 7305
- current_date() 返回当前日期
select current_date();
# 2023-09-21
日期时间格式化
- date_format() 按指定格式返回时间(对日期时间格式化)
#将“2023-09-21 15:06:51”转化如下格式
select date_format('2023-09-21 15:06:51', '%Y-%m-%d');
select date_format('2023-09-21 15:06:51', '%Y-%M-%D');
select date_format('2023-09-21 15:06:51', '%M-%d-%y');
select date_format('2023-09-21 15:06:51', '%m/%d/%y');
select date_format('2023-09-21 15:06:51', '%m/%d/%Y %H:%i:%s');
select date_format('2023-09-21 15:06:51', '%Y年%m月%d日 %H点%i分%s秒');
附:MySql查询当天、本周、本月、本季度、本年
# 1.今天
select to_days(now());
# 2.昨天
select to_days(now()) - 1 ;
# 3.本周
select yearweek(now());
# 4.上周
select yearweek(now()) -1;
# 5.往回推,7天前的时间
select date_sub(current_date(), interval 7 day);
# 6.往回推,30天前的时间
select date_sub(current_date(), interval 30 day);
# 7.本月
select date_format(current_date(),'%Y%m');
# 8.上月
select date_format(date_sub(current_date(),interval 1 month),'%Y%m') ;
# 9.近6个月
select date_sub(current_date(),interval 6 month);
# 10.本季度
select quarter(current_date());
# 11.上季度
select quarter(date_sub(current_date(),interval 1 quarter));
# 12.今年
select year(now());
13.去年
select year(date_sub(now(),interval 1 year));
④ 类型转换函数
类型转换函数 double、date、char
# 将字符'3.14'转换为double数值类型
select cast('3.14' as double);
# 将字符串'2023-09-21'转换为date类型
select cast('2023-09-21' as date);
interval函数
interval(a,n1,n2,n3,...);
其中,a是要判断的数值,n1,n2,n3,…是分段的间隔。这个函数的返回值是段的位置:如果比n1还小,则返回0,如果在n1和n2中间,则返回1,如果n2<=a<n3,则返回2。
select interval(1, 3, 7, 10);
# 0
select interval(5, 3, 7, 10);
# 1
select interval(9, 3, 7, 10);
# 2
interval关键词
select now()-interval '2' hour;
⑤ 条件函数
函数if
select if(80 > 60,'及格','未及格'); 条件表达式为真返回1,为假返回2
非空查找 coalesce
coalesce(v1,v2,…) 返回参数中的第一个非空值;如果所有值都为null,那么返回 null
select coalesce('Certified',null, 'Analyst');
select coalesce(null, 'Data','Analyst');
判断是否为null
isnull() 判断是否为null
- 语法:isnull(a) 如果a为null就返回1,否则返回0
select isnull(null);
select isnull('');
条件判断 case…when…
select name,
case
when score >= 80 then '优秀'
when score >= 70 and score < 80 then '良好'
when score >= 60 and score < 70 then '及格'
else '未及格'
end as score_label
from cda_exam;
看完了数据类型与函数,我们来了解一下SQL的执行顺序。了解SQL的执行顺序,不仅有助于深入理解SQL的执行过程,还能在处理异常时快速确定问题所在。
4. SQL查询的执行顺序
下面看一个包含常用SQL关键词的语句模板:
select distinct column_name,
agg_func(column_name_or_expression)
from table_a a
join table_b b
on a.column_name = b.column_name
where constraint_expression
group by column_name
having constraint_expression
order by column_name asc/desc
limit count offset count;
① from 和 join
从指定的表中选择数据
② where
从数据进行过滤。 注意:as 列别名还不能在这个阶段使用,因为这时候select还没执行,别名是一个还没执行的表达式
③ group by
按指定的列对数据进行分组。
④ having
对group by 子句中分组后的数据进行过滤。as 列别名也不能在这个阶段使用。
⑤ select
选择要返回的列,决定输出什么数据。
⑥ distinct
如果数据行有重复 distinct 将负责排重
⑦ order by
对结果做排序。此时可以用 as 别名了,select 中的表达式已经执行完了。
⑧ limit / offset
限制结果集的数量。 limmit a,b 等价于 limit b offset a
日拱一卒,功不唐捐。你所有的奋斗都不会白费!
第2节 窗口分析函数
窗口分析函数简介
窗口分析函数主要用来做数据统计分析,属于OLAP方式。
我们知道,OLAP联机分析处理和OLTP联机事务处理是两种常见的数据库处理方式,通常情况下,分析师更喜爱OLAP(分析),开发者更关注的是OLTP(事务)
窗口分析函数可以计算一定范围内、一定值域内、或者一段时间内的累积和以及移动平均值等,可以方便的实现复杂的数据统计分析需求。
- 窗口函数包括: lead、lag、first_value、last_value
- 分析函数包括: rank、row_number、percent_rank、cume_dist、ntile
- 可以结合聚集函数sum()、avg()、max(),min(),count()等使用。
窗口分析函数
lag, lead, first_value, last_value
1. lag()
学过Python的同学都知道,这个函数与pandas的
shift()十分相似
lag(col,n,default) 函数的作用是返回某列的值向下平移n行后的结果。
- 第一个参数为列名
- 第二个参数为当前行之前第n行(可选,默认为1)
- 第三个参数为缺失时默认值(当前行之前第n行为NULL没有时,返回该默认值,如不指定,则为NULL)。
本节数据/SQL下载:回复“SQL3”
user_pv表的建表及数据插入SQL如下(也可以选择网盘下载后导入,二选一即可):
例如:对每个用户当天浏览次数与前一天的浏览次数进行比较
select uid,
dt,
pv,
lag(pv, 1, 0) over (partition by uid order by dt) as lag_1_pv
from user_pv
order by uid,dt
2. lead()
lead:函数的作用是返回某列的值向上平移n行后的结果。
第一个参数为列名
第二个参数为当前行后面第n行(可选,默认为1)
第三个参数为缺失时默认值(当前行后面第n行为没有时,返回该默认值,如不指定,则为NULL)。
例如:比较每个用户当天浏览次数和后一天的浏览次数。
select uid,
dt,
pv,
lead(pv, 1, 0) over ( partition by uid order by dt) as lead_1_pv
from user_pv
order by uid,dt;
3. first_value()
例如:比较每个用户当天浏览次数与第一天浏览次数。
select uid,
dt,
pv,
first_value(pv) over (partition by uid order by dt) first_value_pv
from user_pv
order by uid,dt;
注:上面例子窗口为第一行到当前行(缺失窗口子句,有order by ,默认为rows between unbounded preceding and current row)。
所以,first_value返回窗口的第一行,即第一天浏览次数。
4. last_value()
例如:比较每个用户当天浏览次数与最后一天浏览次数进行比较。
select uid,
dt,
pv,
last_value(pv) over (partition by uid order by dt rows between current row and unbounded following) last_value_pv
from user_pv
order by uid,dt;
注:上面例子的窗口为当前行到最后一行(rows between current row and unbounded following)。
last_value返回的是窗口最后一行,即最新一天的浏览次数。
分析函数
分析函数 row_number, rank, dense_rank、cume_dist, percent_rank, ntile
1. row_number( )
按顺序排序,排序的值不会重复,总数不变;
select uid,
dt,
pv,
row_number() over (partition by uid order by pv desc) as row_number_pv
from user_pv
order by uid, pv desc;
2. rank( )
大小一样排序的值一样,但会占用排名的位置,总数不变;
下面对用户每天浏览量进行一个排名。
select uid,
dt,
pv,
rank() over (partition by uid order by pv desc) as rank_pv
from user_pv
order by uid, pv desc;
3. dense_rank( )
排序值相同时重复,排名并列,排名依次增加,排序相同时总数会减少;
例如,如果两行排名为3,则下一个排名为4,不同于RANK()函数返回5。
下面对用户每天浏览量进行一个排名:
select uid,
dt,
pv,
dense_rank() over (partition by uid order by pv desc) dense_rank_pv
from user_pv
order by uid, pv desc;
对比看下,row_number, rank, dense_rank的运行效果:
select uid,
dt,
pv,
row_number() over (partition by uid order by pv desc) as row_number_pv,
rank() over (partition by uid order by pv desc) as rank_pv,
dense_rank() over (partition by uid order by pv desc) dense_rank_pv
from user_pv
order by uid, pv desc;
总结来说,ROW_NUMBER函数为每一行分配唯一的行号,而RANK函数和DENSE_RANK函数在处理具有相同排序值的行时有所不同。RANK函数会跳过下一个排名,而DENSE_RANK函数会紧随其后。选择使用哪个函数取决于具体的需求和对重复值的处理方式。
4. cume_dist()
累积分布cume_dist()函数,用于计算当前行在排序结果中的累积分布比例。
计算公式 = 前面的行数 窗口分区中的总行数 计算公式 = \frac{前面的行数}{窗口分区中的总行数} 计算公式=窗口分区中的总行数前面的行数
# 4、5的合并案例
select uid,
dt,
pv,
cume_dist() over (partition by uid order by pv) cume_dist_pv
from user_pv
order by uid, pv;
5. percent_rank()
非常类似于cume_dist函数。同样用于计算当前行在排序结果中的累积分布比例。
计算公式 = 前面的行数 − 1 窗口分区中的总行数 − 1 计算公式 = \frac{前面的行数- 1}{窗口分区中的总行数 - 1} 计算公式=窗口分区中的总行数−1前面的行数−1
select uid,
dt,
pv,
percent_rank() over (partition by uid order by pv) as percent_rank_uv
from user_pv
order by uid, pv;
对比看下,cume_dist和 percent_rank函数的运行效果:
select uid,
dt,
pv,
cume_dist() over (partition by uid order by pv) cume_dist_pv,
percent_rank() over (partition by uid order by pv) as percent_rank_uv
from user_pv
order by uid, pv;
6. ntile()
学过Python的同学都知道,组内分桶,不就是组内
pd.cut()么
ntile()函数,将每个分区的行尽可能均匀地划分为指定数量的分组。
例如,ntile(4)表示划分为4个分组,分组取决于over子句中的order by子句。
select uid,
dt,
pv,
ntile(4) over (partition by uid order by pv) as nt_pv
from user_pv;
第3节 面试题:连续登录N天的用户数量
连续登录N天的用户数量
现有用户登录表(user_active_log)一份,里面有2个字段:userID(用户ID),createdTime(登录时间戳),需要统计2021年12月连续登录7天的用户数量。
本节例题的user_active_log数据及SQL下载:在公众号对话框回复“SQL”即可下载
分析过程:
题目要求的核心是连续登录,那么我们思考,何为连续登录呢?
顾名思义,连续登录就是指登录的日期连续,那么用数据库的语言来表达的话,我们该描述表达日期连续呢?
我们简化一下数据来考虑这个问题,一般我们有2个办法:
构造一个连续数字构成的辅助列,用原始日期减去辅助列的数字,得到一个新日期,根据这个新日期来判断是否连续;
或者构造一个连续日期构成的辅助列,用原始日期减去这个辅助列的日期,得到一个新数字,最后根据这个数字来判断连续。
这里分别展示两种思路如下:
方法A:
| 日期 | 辅助列 | 新日期 |
|---|---|---|
| 2021-12-02 | 1 | 2021-12-01 |
| 2021-12-03 | 2 | 2021-12-01 |
| 2021-12-04 | 3 | 2021-12-01 |
| 2021-12-05 | 4 | 2021-12-01 |
| 2021-12-06 | 5 | 2021-12-01 |
| 2021-12-07 | 6 | 2021-12-01 |
方法B:
| 日期 | 辅助列 | 新数字 |
|---|---|---|
| 2021-12-02 | 2021-12-01 | 1 |
| 2021-12-03 | 2021-12-02 | 1 |
| 2021-12-04 | 2021-12-03 | 1 |
| 2021-12-05 | 2021-12-04 | 1 |
| 2021-12-06 | 2021-12-05 | 1 |
| 2021-12-07 | 2021-12-06 | 1 |
一般我们为了方便统计某一起始时间连续登录了多少天,多半采用方案A。
我们接着看,刚才知道了如何在SQL里面如何描述连续登录,接下来我们逐步按照题目要求拆解即可:
- Step1:选择12月的记录,并根据用户iD和登录日期先去重(注:单个用户一天有多行登录数据的情况,只保留1行)
- Step2:创建辅助列a_rk (每个userID下的日期排序值)
- Step3:创建辅助列起步时间b_createdTime(用登录日期减去排序值,得到新时间列)
- Step4:根据起步时间列统计连续登录天数
- Step5:根据统计结果查询连续登录人数(题目要求连续7天)
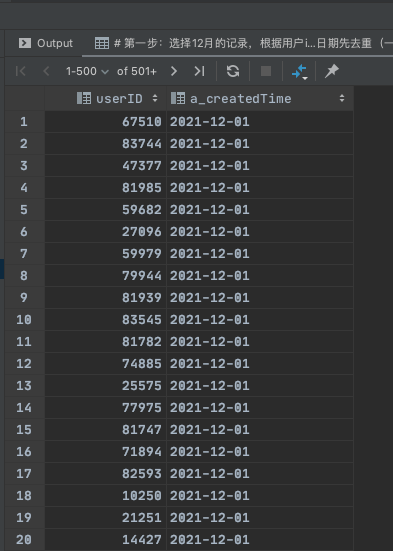
Step1:选择12月的记录,并根据用户iD和登录日期先去重(注:单个用户一天有多行登录数据的情况,只保留1行)
select userID,date(from_unixtime(createdTime)) a_createdTime
from user_active_log
where substr(date(from_unixtime(createdTime)),1,7) = '2021-12' # 知识点1:时间戳转为时间字符串格式然后取前7个字符
group by userId,date(from_unixtime(createdTime)) # 知识点2:根据userId,a_createdTime 去重
运行结果如下:
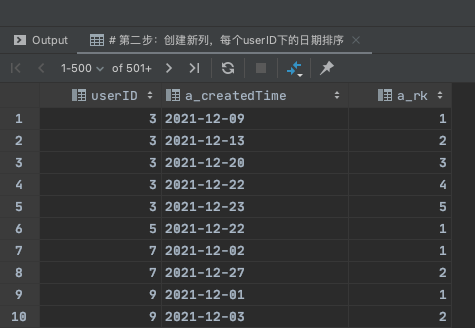
Step2:创建辅助列a_rk (每个userID下的日期排序值)
select userID,a_createdTime,row_number() over(partition by userId order by a_createdTime) a_rk # 知识点3:用row_number() 对每个userID下的a_createdTime进行排名
from
(
select userID,date(from_unixtime(createdTime)) a_createdTime
from user_active_log
where substr(from_unixtime(createdTime),1,7) = '2021-12'
group by userId,a_createdTime) t0
运行结果如下:
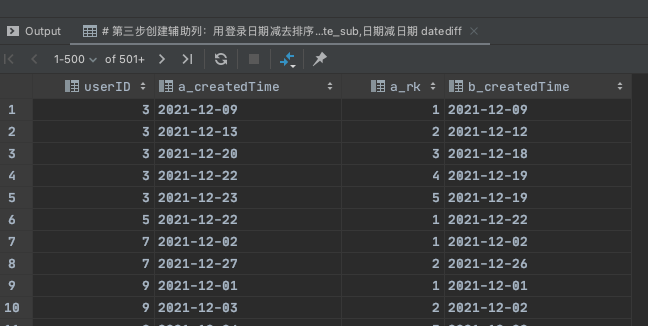
Step3:创建辅助列起步时间b_createdTime(用登录日期减去排序值,得到新时间列)
select *,date_sub(a_createdTime,interval a_rk day ) b_createdTime # 知识点4:date_sub 日期减去数字;datediff 日期减日期
from
(
select userID,a_createdTime,row_number() over(partition by userId order by a_createdTime) a_rk
from
(
select userID,date(from_unixtime(createdTime)) a_createdTime
from user_active_log
where substr(from_unixtime(createdTime),1,7) = '2021-12'
group by userId,a_createdTime) t0 )t1
运行结果如下:
Step4:根据起步时间列统计连续登录天数
select userId,b_createdTime,count(1) cts
from
(select *,date_sub(a_createdTime,interval a_rk day ) b_createdTime
from
(
select userID,a_createdTime,row_number() over(partition by userId order by a_createdTime) a_rk
from
(
select userID,date(from_unixtime(createdTime)) a_createdTime
from user_active_log
where substr(from_unixtime(createdTime),1,7) = '2021-12'
group by userId,a_createdTime) t0 ) t1 ) t2 group by userId,b_createdTime having count(1)>6 # 知识点5:having 用在groupby后做条件筛选
运行结果如下:

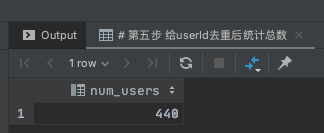
Step5:根据统计结果查询连续登录人数(题目要求连续7天)
select count(distinct userId) num_users
from
(select userId,b_createdTime,count(1) cts
from
(select *,date_sub(a_createdTime,interval a_rk day ) b_createdTime
from
(
select userID,a_createdTime,row_number() over(partition by userId order by a_createdTime) a_rk
from
(
select userID,date(from_unixtime(createdTime)) a_createdTime
from user_active_log
where substr(from_unixtime(createdTime),1,7) = '2021-12'
group by userId,a_createdTime
) t0
) t1
) t2 group by userId,b_createdTime having count(1)>6
) t3;
运行结果如下:
第4节 面试题:近N日留存的用户数及留存率
近N日留存的用户数及留存率
现有用户登录表(user_active_log)一份,里面有2个字段:userID(用户ID),createdTime(登录时间戳),需要统计近1、2、3、5、7、30日留存用户数量及留存率。
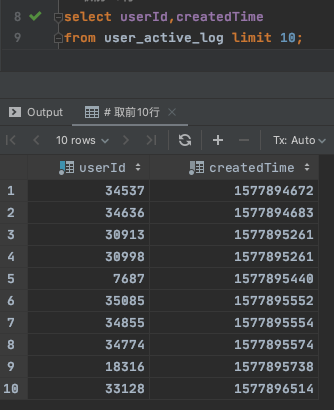
本节例题的user_active_log数据及SQL下载:在公众号对话框回复“SQL”即可下载
分析过程:
题目要求的核心是近N日留存,那么我们思考,何为近N日留存呢?
顾名思义,就是指距离某个日期的间隔为N,那么用数据库的语言来表达的话,我们该描述表达近N日留存呢?
我们简化一下数据来考虑这个问题:
构造一个起始日期构成的辅助列,用原始日期减去辅助列的日期,得到一个新数字N,根据这个新数字,结合起始日期来判断某个日期的近N日留存;
| 日期 | 辅助列 | 新数字 |
|---|---|---|
| 2021-12-02 | 2021-12-01 | 1 |
| 2021-12-03 | 2021-12-01 | 2 |
| 2021-12-04 | 2021-12-01 | 3 |
| 2021-12-05 | 2021-12-01 | 4 |
| 2021-12-06 | 2021-12-01 | 5 |
| 2021-12-07 | 2021-12-01 | 6 |
知道了如何在SQL里面如何描述连续登录,接下来我们逐步按照题目要求拆解即可:
- Step1:根据用户id和登录日期先去重
- Step2:创建新列first_time,获取每个userID下的最早登录日期
- Step3:创建辅助列delta_time,用登录日期列减去最早登录日期first_time,得到留存天数
- Step4:按first_time列统计不同留存天数对应的次数和 即 某日的近N日留存数
- Step5:用某日的近N日留存数除以首日登录人数即留存率
Step1:根据用户id和登录日期先去重
select
userID,
date(from_unixtime(createdTime)) a_createdTime
from user_active_log
group by userId,a_createdTime;
运行结果截图如下:
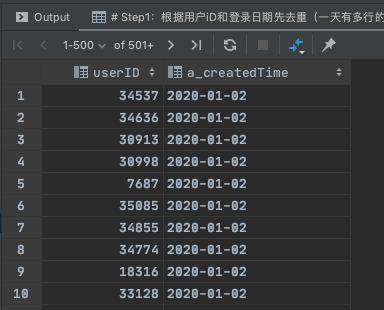
Step2:创建新列first_time,获取每个userID下的最早登录日期
select
userID,
a_createdTime,
first_value(a_createdTime) over(partition by userId order by a_createdTime ) first_time
from
(
select userID,date(from_unixtime(createdTime)) a_createdTime
from user_active_log
group by userId,a_createdTime
)t0;
运行结果截图如下:
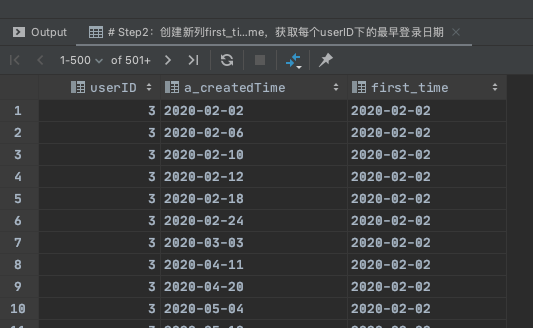
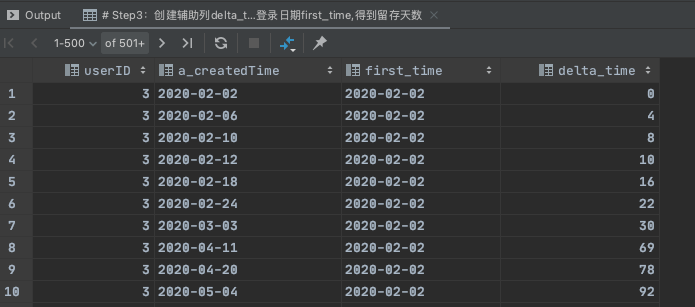
Step3:创建辅助列delta_time,用登录日期列减去最早登录日期first_time,得到留存天数
select
userID,
a_createdTime,
first_value(a_createdTime) over(partition by userId order by a_createdTime ) first_time,
datediff(a_createdTime, first_value(a_createdTime) over(partition by userId order by a_createdTime )) delta_time
from
(
select userID,date(from_unixtime(createdTime)) a_createdTime
from user_active_log
group by userId,a_createdTime
)t0;
运行结果截图如下:
Step4:按首次登录日期统计不同留存天数对应的次数和 即 某日的近N日留存数
select
t1.first_time,
sum( case when t1.delta_time = 1 then 1 else 0 end) day_1,
sum( case when t1.delta_time = 2 then 1 else 0 end) day_2,
sum( case when t1.delta_time = 3 then 1 else 0 end) day_3,
sum( case when t1.delta_time = 5 then 1 else 0 end) day_5,
sum( case when t1.delta_time = 7 then 1 else 0 end) day_7,
sum( case when t1.delta_time = 30 then 1 else 0 end ) day_30
from
(
select
userID,
a_createdTime,
first_value(a_createdTime) over(partition by userId order by a_createdTime ) first_time,
datediff(a_createdTime, first_value(a_createdTime) over(partition by userId order by a_createdTime )) delta_time
from
(
select userID,date(from_unixtime(createdTime)) a_createdTime
from user_active_log
group by userId,a_createdTime
)t0
) t1
group by t1.first_time
order by t1.first_time;

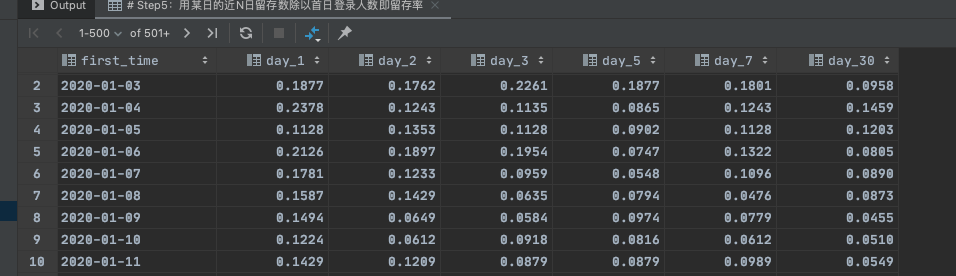
Step5:用某日的近N日留存数除以首日登录人数即留存率
select
t1.first_time,
sum( case when t1.delta_time = 1 then 1 else 0 end ) / count(distinct t1.userID) day_1,
sum( case when t1.delta_time = 2 then 1 else 0 end ) / count(distinct t1.userID) day_2,
sum( case when t1.delta_time = 3 then 1 else 0 end ) / count(distinct t1.userID) day_3,
sum( case when t1.delta_time = 5 then 1 else 0 end ) / count(distinct t1.userID) day_5,
sum( case when t1.delta_time = 7 then 1 else 0 end ) / count(distinct t1.userID) day_7,
sum( case when t1.delta_time = 30 then 1 else 0 end )/ count(distinct t1.userID) day_30
from
(
select
userID,
a_createdTime,
first_value(a_createdTime) over(partition by userId order by a_createdTime ) first_time,
datediff(a_createdTime , first_value(a_createdTime) over(partition by userId order by a_createdTime )) delta_time
from
(
select userID,date(from_unixtime(createdTime)) a_createdTime
from user_active_log
group by userId,a_createdTime
)t0
) t1
group by t1.first_time
order by t1.first_time;
“每一个不曾起舞的日子,都是对生命的辜负。”各位加油!我们下个系列见
SQL是现代数据处理和管理中不可或缺的关键组成部分。随着数据量的不断增长,有效地存储、提取和操作数据变得至关重要。正因如此,掌握SQL技能对于数据分析师、软件开发人员和数据库管理员等职业来说是无比重要的。SQL练习题作为学习工具在这一过程中扮演着重要的角色。
通过练习SQL题,巩固数据库知识、提高查询能力、实践数据处理技巧以及培养问题解决能力的机会。这些练习题涉及了基本查询、数据聚合、条件筛选、多表连接等各种类型的问题,真实模拟了在实际项目中遇到的数据处理场景。完成SQL练习题,可以加深对数据库的理解,了解SQL语句的结构和语法规则。
本文将介绍一系列有趣且有挑战性的SQL练习题,涵盖了常见的数据操作和查询场景。
无论你是刚入门学习SQL的初学者,还是希望深入挖掘数据库知识的专业人士,这些练习题都将成为提升技能和应用SQL的有力工具。让我们开始探索这50道SQL练习题,为学习数据库旅程注入新的活力!
创建表
创建课程表
create table school.Course
(
course_id int null,
course_name varchar(10) null,
teacher_id int null
);
创建学生表
create table school.Student
(
student_id int null,
student_name varchar(10) null,
birth datetime null,
gender varchar(10) null
);
创建教师表
create table school.Teacher
(
teacher_id int null,
teacher_name varchar(10) null
);
创建成绩表
create table school.Score
(
student_id int null,
course_id int null,
fraction int null
);
导入数据
导入课程科目数据
INSERT INTO school.Course (course_id, course_name, teacher_id) VALUES (1, '语文', 2);
INSERT INTO school.Course (course_id, course_name, teacher_id) VALUES (2, '数学', 1);
INSERT INTO school.Course (course_id, course_name, teacher_id) VALUES (3, '英语', 3);
导入课程成绩数据
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (1, 1, 80);
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (1, 2, 90);
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (1, 3, 99);
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (2, 1, 70);
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (2, 2, 60);
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (2, 3, 80);
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (3, 1, 80);
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (3, 2, 80);
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (3, 3, 80);
INSERT INTO school.Score (student_id, course_id, fraction) VALUES (4, 1, 50);
导入学生信息数据
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (1, '赵雷', '1990-01-01 00:00:00', '男');
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (2, '钱电', '1990-12-21 00:00:00', '男');
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (3, '孙风', '1990-05-20 00:00:00', '男');
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (4, '李云', '1990-08-06 00:00:00', '男');
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (5, '周梅', '1991-12-01 00:00:00', '女');
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (6, '吴兰', '1992-03-01 00:00:00', '女');
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (7, '郑竹', '1989-07-01 00:00:00', '女');
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (8, '王菊', '1990-01-20 00:00:00', '女');
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (9, '郑兰', '1991-10-22 14:26:57', '女');
INSERT INTO school.Student (student_id, student_name, birth, gender) VALUES (10, '李云四', '1988-07-23 09:50:15', '男');
导入教师信息数据
INSERT INTO school.Teacher (teacher_id, teacher_name) VALUES (1, '张三');
INSERT INTO school.Teacher (teacher_id, teacher_name) VALUES (2, '李四');
INSERT INTO school.Teacher (teacher_id, teacher_name) VALUES (3, '王五');
1、查询课程编号为“1”的课程比“2”的课程成绩高的所有学生的学号(重点):
select a.student_id 学生学号
from
(select student_id,fraction 课程编号1的分数
from Score
where course_id = '1') a
left join (select student_id,fraction 课程编号2的分数
from Score
where course_id = '2') b
on a.student_id = b.student_id;
where 课程编号1的分数 > 课程编号2的分数;
2、查询"01"课程比"02"课程成绩低的学生的信息及课程分数(重点):
select c.student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
,c.课程编号1的分数
,c.课程编号2的分数
from
(select a.student_id,课程编号1的分数,课程编号2的分数
from
(select student_id,fraction 课程编号1的分数
from Score
where course_id = '1') a
left join (select student_id,fraction 课程编号2的分数
from Score
where course_id = '2') b
on a.student_id = b.student_id
where 课程编号1的分数 < 课程编号2的分数) c
left join Student
on c.student_id = Student.student_id;
3、查询平均成绩大于等于60分的同学的学生学号、学生姓名和平均成绩(重点):
select
Score.student_id 学生学号
,student_name 学生姓名
,avg(Score.fraction) 平均分
from Score
left join Student
on Score.student_id = Student.student_id
GROUP BY Score.student_id,Student.student_name
having avg(Score.fraction)>=60;
4、查询平均成绩小于60分的同学的学生学号和学生姓名和平均成绩:
select Score.student_id 学生学号
,student_name 学生姓名
,avg(Score.fraction) 平均分
from Score
left join Student
on Score.student_id = Student.student_id
GROUP BY Score.student_id,Student.student_name
having avg(Score.fraction)<60;
5、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩:
select Score.student_id 学生学号
,student_name 学生姓名
,count(Score.course_id) 选课总数
,sum(Score.fraction) 总分
from Score
left join Student
on Score.student_id = Student.student_id
GROUP BY Score.student_id,Student.student_name;
6、查询"李"姓老师的数量:
select count(*) 姓李的老师人数
from Teacher
where teacher_name like '李%';
7、查询学过"张三"老师授课的同学的信息(重点):
select Student.student_id 学生学号
, student_name 学生姓名
, birth 出生日期
, gender 性别
from Teacher
left join Course
on Teacher.teacher_id = Course.teacher_id
left join Score
on Course.course_id = Score.course_id
left join Student
on Score.student_id = Student.student_id
where Teacher.teacher_name = '张三';
8、查询没学过"张三"老师授课的同学的信息(重点):
select Student.student_id 学生学号
, student_name 学生姓名
, birth 出生日期
, gender 性别
from Student
left join
(select student_id
from Score
left join Course
on Score.course_id = Course.course_id
left join Teacher
on Course.teacher_id = Teacher.teacher_id
and Teacher.teacher_name = '张三') a
on Student.student_id = a.student_id
where a.student_id is null;
9、查询学过编号为"1"并且也学过编号为"2"的课程的同学的信息(重点):
select a.student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Student
join
(select student_id
from Score
where course_id = 1) a
on Student.student_id = a.student_id
join
(select *
from Score
where course_id = 2) b
on Student.student_id = b.student_id;
10、查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息(重点):
select a.student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Student
join
(select student_id
from Score
where course_id = 1) a
on Student.student_id = a.student_id
left join
(select *
from Score
where course_id = 2) b
on Student.student_id = b.student_id
where b.student_id is null;
11、查询没有学全所有课程的同学的信息(重点):
select Score.student_id 学生学号
,Student.student_name 学生姓名
,Student.birth 出生日期
,Student.gender 性别
from Score
left join Student
on Score.student_id = Student.student_id
GROUP BY Score.student_id,Student.student_name,Student.birth, Student.gender
having count(Score.course_id)<3;
12、查询至少有一门课与学号为"1"的同学所学相同的同学的信息(重点):
select distinct Student.student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Score
join Student
on Score.student_id = Student.student_id
where course_id in (
select course_id
from Score
where student_id = 1
)
and Score.student_id != 1;
13、查询和"1"号的同学学习的课程完全相同的其他同学的信息(重点):
select Student.student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Student
where Student.student_id in (
select a.student_id from
(select Score.student_id
from Score
where course_id = 1) a
inner join (select Score.student_id
from Score
where course_id = 2) b
on a.student_id = b.student_id
inner join (select Score.student_id
from Score
where course_id = 3) c
on a.student_id = c.student_id
)
and Student.student_id != 1;
14、查询没学过"张三"老师讲授的任一门课程的学生姓名(重点):
select Student.student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Student
left join
(select Score.student_id
from Teacher
join Course
on Teacher.teacher_id = Course.teacher_id
join Score
on Score.course_id = Course.course_id
where teacher_name = '张三'
) a
on Student.student_id = a.student_id
where a.student_id is null;
15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩(重点):
select Score.student_id 学生学号
,Student.student_name 学生姓名
,avg(Score.fraction) 平均分
from Score
join Student
on Score.student_id = Student.student_id
where fraction < 60
group by Score.student_id,Student.student_name
having count(Score.student_id)>=2;
16、检索"1"课程分数小于60,按分数降序排列的学生信息(和34类似):
select Score.fraction 分数
,Student.student_id 学生学号
, student_name 学生姓名
, birth 出生日期
, gender 性别
from Score
join Student
on Score.student_id = Student.student_id
where Score.fraction< 60
and Score.course_id = 1
order by Score.fraction desc;
17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩(重点):
select student_id 学生学号,
max(case when course_id = 1 then fraction else null end) '数学',
max(case when course_id = 2 then fraction else null end) '语文',
max(case when course_id = 3 then fraction else null end) '英语',
avg(fraction) 平均分
from Score
group by student_id
order by avg(fraction) desc;
18.查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率(重点):
select Course.course_id 课程ID,
Course.course_name 课程name,
max(Score.fraction) 最高分,
min(Score.fraction) 最低分,
avg(Score.fraction) 平均分,
round(sum(case when Score.fraction>= 60 then 1 else 0 end)/count(Score.fraction),2) 及格率,
round(sum(case when Score.fraction>= 70 and Score.fraction< 80 then 1 else 0 end)/count(Score.fraction),2) 中等率,
round(sum(case when Score.fraction>= 80 and Score.fraction< 90 then 1 else 0 end)/count(Score.fraction),2) 优良率,
round(sum(case when Score.fraction>= 90 then 1 else 0 end)/count(Score.fraction),2) 优秀率
from Score
join Course
on Score.course_id = Course.course_id
group by Course.course_id,Course.course_name;
19、按各科成绩进行排序,并显示排名(重点row_number):
select Score.course_id 课程编号,
Score.fraction 分数,
row_number() over (partition by Score.course_id order by Score.fraction desc) 排名
from Score;
20、查询学生的总成绩并进行排名(重点):
select Score.student_id 学生学号,
Student.student_name 学生姓名,
sum(Score.fraction) 总成绩,
row_number() over (order by sum(Score.fraction) desc) 排名
from Score
join Student
on Score.student_id = Student.student_id
group by Score.student_id,Student.student_name;
21、查询不同老师所教不同课程平均分从高到低显示(重点):
select Teacher.teacher_name 教师姓名,
avg(Score.fraction) 课程平均分
from Score
join Course
on Score.course_id = Course.course_id
join Teacher
on Course.teacher_id = Teacher.teacher_id
group by Teacher.teacher_name
order by avg(Score.fraction) desc;
22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩(重点):
select student_name 学生姓名
,fraction 分数
,course_name 课程名
from
(select student_name,
fraction,
Course.course_name,
row_number() over (partition by course_name order by Score.fraction desc) 排名
from Score
join Course
on Score.course_id = Course.course_id
join Student
on Score.student_id = Student.student_id) a
where a.排名 = 2
or a.排名 = 3;
23、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比(重点)
select Score.course_id 课程编号,
course_name 课程名,
round(sum(case when Score.fraction>= 85 then 1 else 0 end)) r85_100,
round(sum(case when Score.fraction>= 85 then 1 else 0 end)/count(Score.fraction),2) S85_100,
round(sum(case when Score.fraction< 85 and Score.fraction>= 70 then 1 else 0 end)) r70_85,
round(sum(case when Score.fraction< 85 and Score.fraction>= 70 then 1 else 0 end)/count(Score.fraction),2) S70_85,
round(sum(case when Score.fraction< 70 and Score.fraction>= 60 then 1 else 0 end)) r60_70,
round(sum(case when Score.fraction< 70 and Score.fraction>= 60 then 1 else 0 end)/count(Score.fraction),2) S60_70,
round(sum(case when Score.fraction< 60 and Score.fraction>= 0 then 1 else 0 end)) r0_60,
round(sum(case when Score.fraction< 60 and Score.fraction>= 0 then 1 else 0 end)/count(Score.fraction),2) S0_60
from Score
join Course
on Score.course_id = Course.course_id
group by Course.course_id,Course.course_name;
24、查询学生平均成绩及其名次(重点):
select
Student.student_id 学生学号,
Student.student_name 学生姓名,
avg(Score.fraction) 平均分,
row_number() over (order by avg(Score.fraction) desc) 排名
from Score
join Student
on Score.student_id = Student.student_id
group by Student.student_id,Student.student_name;
25、查询各科成绩前三名的记录(不考虑成绩并列情况)(重点)
select a.course_id 课程编号,
a.student_name 学生姓名,
a.course_name 课程名,
a.fraction 分数
from
(select Course.course_id,
student_name,
fraction,
Course.course_name,
row_number() over (partition by course_name order by Score.fraction desc) 排名
from Score
join Course
on Score.course_id = Course.course_id
join Student
on Score.student_id = Student.student_id) a
where a.排名 < 4;
26、查询每门课程不及格的学生数:
select Course.course_name 课程名,
count(Score.course_id) 不及格的人数
from Course
join Score
on Course.course_id = Score.course_id
where fraction < 60
group by Score.course_id,Course.course_name;
27、查询出只有两门课程的全部学生的学号和姓名:
select Score.student_id 学生学号,
Student.student_name 学生姓名
from Score
join Student
on Score.student_id = Student.student_id
group by Score.student_id,Student.student_name
having count(Score.fraction) = 2;
28、查询男生、女生人数:
select Student.gender 性别,
count(Student.gender) 人数
from Student
group by Student.gender;
29、查询名字中含有"风"字的学生信息:
select Student.student_id 学生学号
, student_name 学生姓名
, birth 出生日期
, gender 性别
from Student
where student_name like '%风%';
30、查询同名不同姓并且性别相同学生名单,并统计同名人数:
select s1.student_id 学生学号
,s1.student_name 学生姓名
,s1.gender 性别
,Substring(s1.student_name,2) 名
,count(*) 人数
from Student s1,Student s2
where Substring(s1.student_name,2)=Substring(s2.student_name,2)
and s1.student_id<>s2.student_id
and s1.gender=s2.gender
group by s1.student_id,s1.student_name,s1.gender;
31、查询1990年出生的学生名单(重点year):
select student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Student
where year(birth) = '1990';
32、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列:
select Course.course_id 课程编号
,Course.course_name 课程名
,avg(Score.fraction) 平均分
from Score
join Course
on Score.course_id = Course.course_id
group by Course.course_id,Course.course_name
order by avg(Score.fraction) desc;
33、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩:
select Score.student_id 学生学号,
Student.student_name 学生姓名,
avg(Score.fraction) 平均分
from Score
join Student
on Score.student_id = Student.student_id
group by Score.student_id,Student.student_name
having avg(Score.fraction)>=85;
34、查询课程名称为"数学",且分数低于60的学生姓名和分数:
select student_name 学生姓名,
fraction 分数
from Score
join Course
on Score.course_id = Course.course_id
join Student
on Score.student_id = Student.student_id
where course_name = '数学'
and fraction < 60;
35、查询所有学生的课程及分数情况(重点):
select Student.student_name 学生姓名,
max(case when Score.course_id = 1 then fraction else 0 end) '数学',
max(case when Score.course_id = 2 then fraction else 0 end) '语文',
max(case when Score.course_id = 3 then fraction else 0 end) '英语',
sum(fraction) 总分
from Score
join Course on Score.course_id = Course.course_id
join Student on Score.student_id = Student.student_id
group by Student.student_name
order by avg(fraction) desc;
36、查询任何一门课程成绩在70分以上的学生姓名、课程名称和分数(重点):
select Student.student_name 学生姓名
,Course.course_name 课程名
,Score.fraction 分数
from Score
join Student on Score.student_id = Student.student_id
join Course on Score.course_id = Course.course_id
where fraction>70;
37、查询课程不及格的学生:
select Student.student_name 学生姓名
,Course.course_name 课程名
,Score.fraction 分数
from Score
join Student on Score.student_id = Student.student_id
join Course on Score.course_id = Course.course_id
where fraction<60;
38、查询课程编号为1且课程成绩在80分以上的学生的学号和姓名:
select Student.student_name 学生姓名,
Score.fraction 分数
from Score
join Student
on Score.student_id = Student.student_id
where fraction>=80
and Score.course_id = 1;
39、求每门课程的学生人数:
select Course.course_name 课程名
,count(Score.student_id) 人数
from Score
join Course
on Score.course_id = Course.course_id
group by Course.course_name;
40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩(重点top):
select Teacher.teacher_name 教师姓名
,Student.student_name 学生姓名
,Course.course_name 课程名
,Score.fraction 分数
from Score
join Course
on Score.course_id = Course.course_id
join Student
on Score.student_id = Student.student_id
join Teacher on Course.teacher_id = Teacher.teacher_id
where Teacher.teacher_name = '张三'
order by Score.fraction desc limit 1;
41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩(重点):
select distinct a.student_id 学生学号,
a.course_id 课程编号,
a.fraction 分数
from Score a,Score b
where a.course_id <> b.course_id and a.fraction=b.fraction;
42、查询每门课程成绩最好的前三名(重点):
select a.course_id 课程编号,
a.student_id 学生编号,
a.fraction 分数,
a.排名 排名
from
(select Score.course_id,
Score.student_id,
fraction,
row_number() over (partition by Score.course_id order by Score.fraction desc) 排名
from Score) a
where a.排名 < 4;
43、统计每门课程的选修人数(超过5人的课程才统计,查询结果按人数降序排列,若人数相同,按课程号升序排列):
select C.course_id 课程编号
,C.course_name 课程名
,count(S.course_id) 人数
from Student
join Score S on Student.student_id = S.student_id
join Course C on S.course_id = C.course_id
group by S.course_id,C.course_name
having count(S.course_id)>5
order by count(S.course_id),C.course_id asc;
44、检索至少选修两门课程的学生学号:
select Score.student_id 学生学号
,count(Score.course_id) 选修课程数量
from Score
group by Score.student_id
having count(Score.course_id) >= 2;
45、查询选修了全部课程的学生信息:
select Student.student_id 学生学号
, student_name 学生姓名
, birth 出生日期
, gender 性别
from Student
join Score
on Student.student_id = Score.student_id
group by Student.student_id, student_name, birth, gender
having count(Score.course_id) = (select count(distinct Score.course_id) from Score);
46、查询各学生的年龄(周岁):
select Student.student_name 学生姓名,
round(year(now())-year(birth)+if(month(now())-month(birth)>0,0,-1)) 年龄
from Student;
47、查询本周过生日的学生:
select student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Student
where week(birth) = week(now());
48、查询下周过生日的学生:
select student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Student
where week(birth) = week(now())+1;
49、查询本月过生日的学生:
select student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Student
where month(birth) = month(now());
50、查询12月份过生日的学生:
select student_id 学生学号
,student_name 学生姓名
,birth 出生日期
,gender 性别
from Student
where month(birth) = 12;