前言:
💞💞大家好,书生♡,今天主要和大家分享一下mysql的进阶语法,数据库的分组/分页/排序/子查询以及详细案例,希望对大家有所帮助。
💞💞前路漫漫,希望大家坚持下去,不忘初心,成为一名优秀的程序员
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
mysql基础语法:mysql基础语法 🤞🤞🤞

目录
- 1. DQL之排序查询
- 2. DQL之聚合查询
- 3.DQL之分组查询
- 3.1 分组查询--where
- 3.2分组查询--having
- 3.3 where和having的区别
- 4. DQL之分页查询
- 5. 多表关系(了解)
- 6. 外键约束
- 6.1 外键的注意事项
- 7. 多表查询之内连接
- 8.多表查询之外连接
- 8.1 多表查询之左外连接
- 8.2 多表查询之右外连接
- 9. 多表查询之as语法
- 9.1 给表起别名
- 9.2 给字段起别名
- 10. 多表查询之连接关键字的省略
- 11.多表查询之子查询
- 12. sql语句的执行顺序
- 13. 案例小结
- 13.1 案例1
- 13.2 案例2
- 14.寄语
1. DQL之排序查询
排序查询: 就是按照指定字段的大小进行排序, 排序规则分为 升序和降序
升序(ASC) : 从小到大依次递增
降序(DESC) : 从大到小依次递减
关键字: order by
格式: select 列… from 表 where 条件 order by 排序规则 [ASC|DESC];
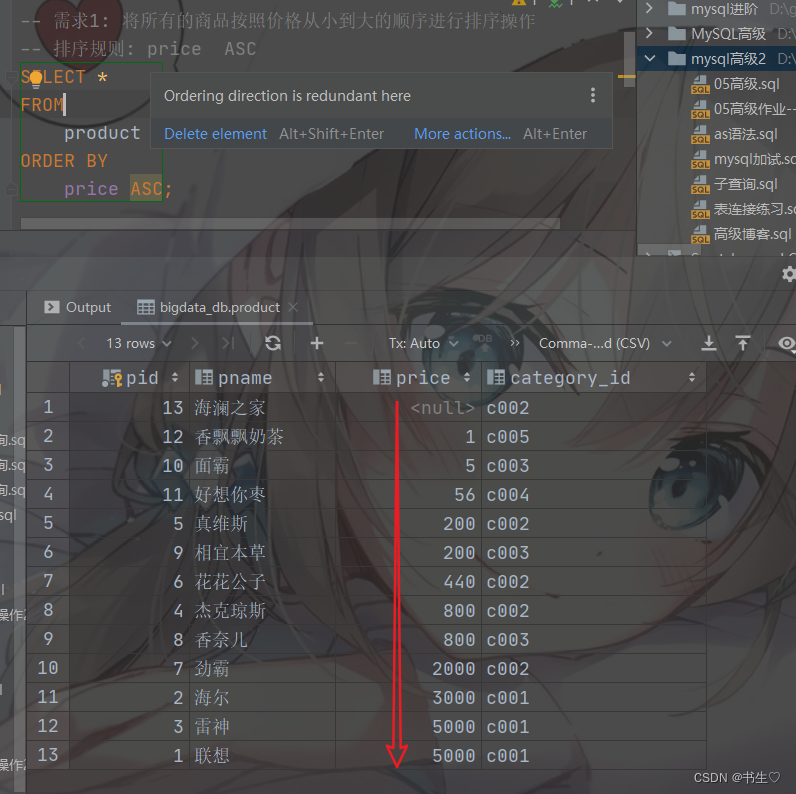
-- 需求1: 将所有的商品按照价格从小到大的顺序进行排序操作
-- 排序规则: price ASC
SELECT *
FROM
product
ORDER BY
price ASC;
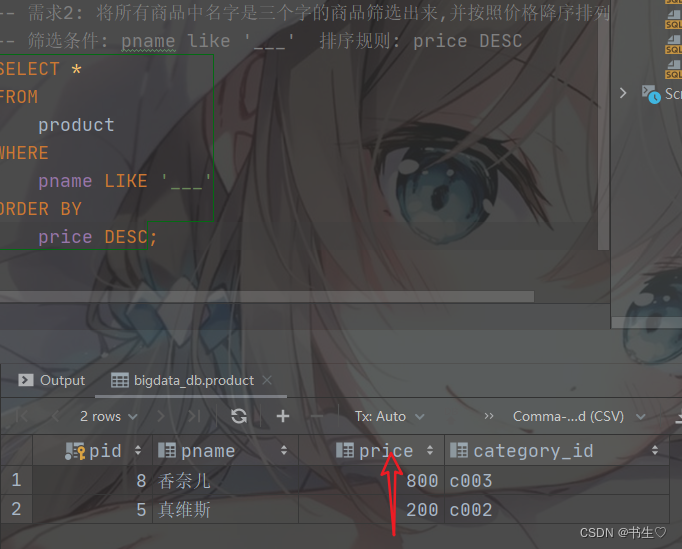
-- 需求2: 将所有商品中名字是三个字的商品筛选出来,并按照价格降序排列
-- 筛选条件: pname like '___' 排序规则: price DESC
SELECT *
FROM
product
WHERE
pname LIKE '___'
ORDER BY
price DESC;
在书写代码时, 先书写where 条件, 在书写 order by 排序, 同时,执行顺序也如此, 先筛选出需要部分,再对这一部分进行排序.
-- 需求3: 将所有的商品按照价格升序排列,如果价格相同,则按照品类降序排列
-- 排序规则: price ASC category_id DESC
SELECT *
FROM
product
ORDER BY
price, category_id DESC;
-- 解释: 对于所有商品按照商品类别降序排列, 如果类别相同,则按照价格升序排列.
SELECT *
FROM
product
ORDER BY
category_id DESC, price;
-- 结论: 当排序字段为多个字段时, 先按照第一个字段进行排序,如果字段值相同,
-- 再按照第二个字段进行排序,如果第二个也相同则使用第三个,以此类推
2. DQL之聚合查询
聚合:多个数据进行计算,最终变为一个数据的计算方式叫做聚合计算
聚合函数:
- max 最大值
- min 最小值
- avg 平均值
- count 计数
- sum 求和
-- 需求1: 获取所有商品中的最大价格
SELECT max(price) FROM product;

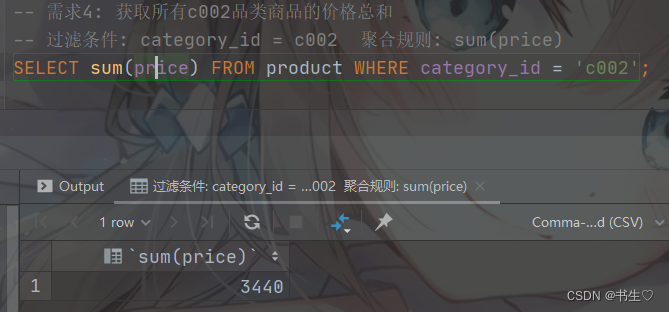
-- 需求4: 获取所有c002品类商品的价格总和
-- 过滤条件: category_id = c002 聚合规则: sum(price)
SELECT sum(price) FROM product WHERE category_id = 'c002';
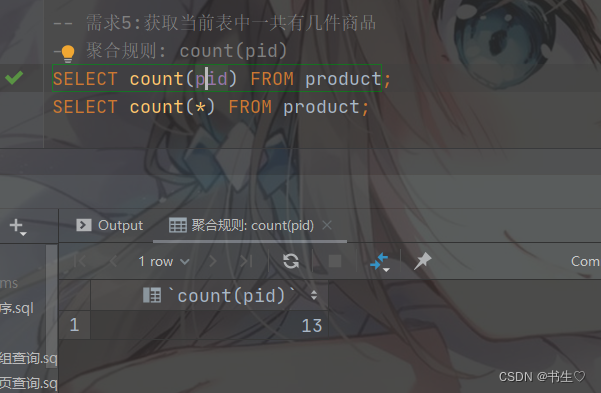
-- 需求5:获取当前表中一共有几件商品
-- 聚合规则: count(pid)
SELECT count(pid) FROM product;
SELECT count(*) FROM product;
注意: null (空值) 不参与聚合函数的计算
举例: 我们有三个同学, 分别拥有 2个苹果 4 个苹果 null (空值)
– 求每个人平均有多少个苹果: 3个 (2 + 4)/ 2 null值不参与运算
举例: 我们有三个同学, 分别拥有 2个苹果 4 个苹果 0个苹果
– 求每个人平均有多少个苹果: 2个 (2 + 4 + 0)/ 3 0参与运算
3.DQL之分组查询
3.1 分组查询–where
分组查询 : 就是按照指定字段的值的种类,将数据记录分配到不同的分组之中, 一般后续会进行按照组的聚合计算
- 关键字 : group by
- 格式 : select 分组字段, 聚合函数 from 表名 group by 分组字段;
- 完整格式 : select 分组字段, 聚合函数 from 表名 where 条件 group by 分组字段 order by 排序规则;
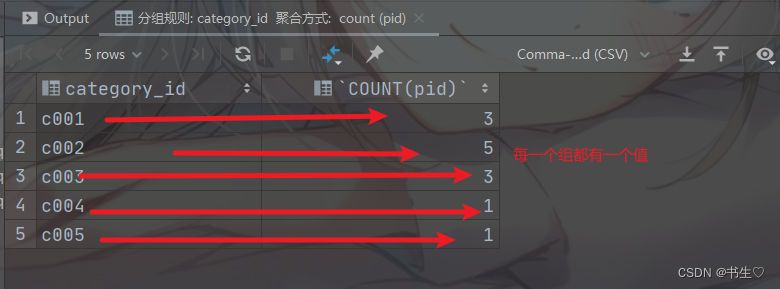
-- 需求1: 统计(按照拼配进行分组)每一个品类的商品各有(count)多少个
-- 分组规则: category_id 聚合方式: count (pid)
SELECT
category_id,
COUNT(pid)
FROM
product
GROUP BY
category_id;
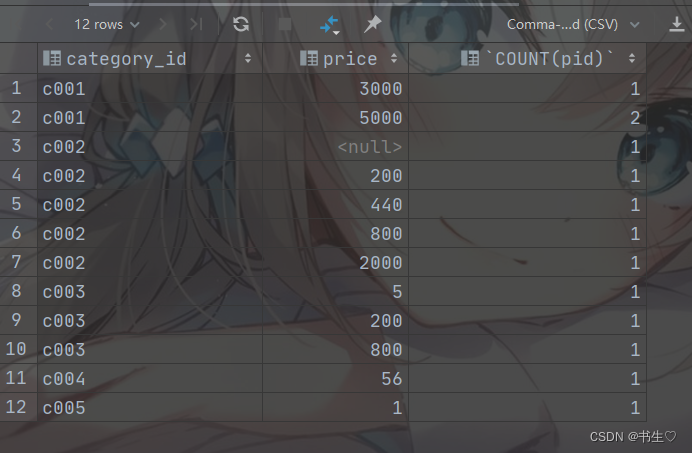
-- 需求4: 查询每种品类每个价格各有几件商品
-- 分组规则: 按照品类和价格进行分组 (category_id , price) 聚合: count(pid)
SELECT
category_id,
price,
COUNT(pid)
FROM
product
GROUP BY
category_id, price;
案例:
-- 需求2: 请列出所有品类的编号
SELECT
category_id
FROM
product
GROUP BY
category_id;
-- 需求3: 获取所有品类商品中 每个品类 最大价格
-- 分组规则: category_id 聚合方式: max(price)
SELECT
category_id,
MAX(price)
FROM
product
GROUP BY
category_id;
结论: 当我们的分组字段中有多个字段名称时, 两个字段完全相同,则分到同一组. 否则分为两个不同的组.
注意事项:
- 在使用group之后,无法在select中使用除分组字段之外的其他字段
- 聚合函数配合分组进行使用时,聚合的范围是当前分组内部.
- 我们也可以根据多个字段进行分组操作, 多个字段完全相同的会被归为一组数据.
- 在开发中where 条件筛选, 要使用在 group by 之前, order by 要用在group by 之后
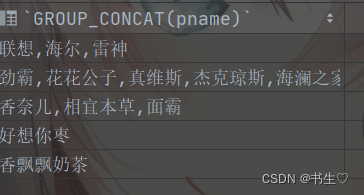
- group_concat 可以获取当前组内全部的数据
3.2分组查询–having
分组后筛选数据使用having
完整格式 : select 分组字段, 聚合函数 from 表名 where 分组前筛选条件 group by 分组字段 having 分组后筛选条件 order by 排序规则;
-- 需求7: 获取所有商品中商品数量大于2个的品类 每个品类商品的平均价格,并按照价格平均值排序 降序
-- 筛选条件: count(pid) > 2 分组规则: category_id 聚合规则: avg(price) 排序规则:
-- where 条件语句中不能使用聚合函数
-- 因为 where 是在 group by 之前调用的, 此时尚未分组, 所以不能按组聚合.
-- 如果想要在分组之后进行数据筛选, 需要使用having
SELECT
category_id,
COUNT(pid),
AVG(price)
FROM
product
GROUP BY
category_id
HAVING
COUNT(pid) > 2
ORDER BY
AVG(price) DESC
;
-- 需求8: 获取所有商品中高于200元的商品数量大于2个的品类 每个品类商品的平均价格,并按照价格平均值排序 降序
-- 筛选条件: price > 200 , count(pid) > 2 分组规则: category_id 聚合规则: avg(price) 排序规则: avg(price) desc
SELECT
category_id,
COUNT(pid),
AVG(price)
FROM
product
WHERE
price > 200 -- where 在group by 之前运行, 可以使用非分组字段, 但是不能使用聚合函数
GROUP BY
category_id -- 分组字段
HAVING
COUNT(pid) > 2 -- having 在group by 之后执行, 仅可以使用分组字段和聚合函数.
ORDER BY
AVG(price) DESC;
3.3 where和having的区别
- having是在group by 之后使用的,而where 是在group by之前使用的
- having中可以使用聚合函数, 而where中不能使用聚合函数
- having中不能使用除分组字段外的其他字段, 而where中可以使用任意字段
# 需求: 获取各商品品类中价格大于200的商品 数量,保留数量大于2的品类信息.
-- 分析: group by 之前筛选 : 商品价格大于 200 group by 之后筛选 : 商品数量大于2
-- 分组规则 : category_id 聚合规则 : count
SELECT category_id,
COUNT(*)
FROM product
WHERE price > 200
GROUP BY category_id
HAVING COUNT(*) > 2;
4. DQL之分页查询
分页查询 : 按照一定的规则,查询全部数据中的一部分信息, 又叫做边界查询
– 关键字 : limit
– 格式: select 列名 from 表名 limit m , n;
– 完整格式 : select 分组字段, 聚合函数 from 表名 where 分组前筛选条件 group by 分组字段 having 分组后筛选条件 order by 排序规则 limit m , n;
– m 代表查询数据的起始索引 : 索引值从0开始 ,如果从头开始查询,则索引值为0
– n 代表查询数据的条目数 : 如果要查询5条数据则为5
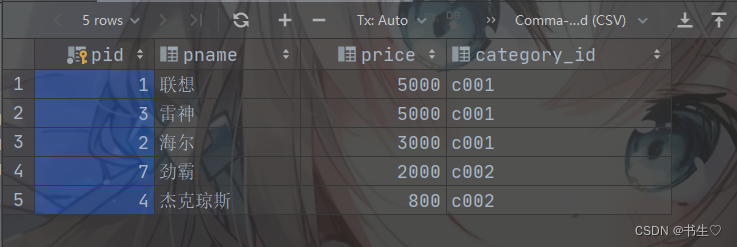
-- 需求1: 查看当前商品列表中价格最高的5件商品的全部信息.
-- 排序规则: price desc 边界规则: limit 0, 5;
SELECT *
FROM
product
ORDER BY
price DESC
LIMIT 0,5;
-- 需求2: 查看当前商品列表中价格在6-10位的商品的全部信息.
-- 排序规则: price desc 边界规则: limit 5, 5;
SELECT *
FROM
product
ORDER BY
price DESC
LIMIT 5, 5;
当我们分页查询时 每页的 n 和 n 应该是 :
- m : (页码 - 1) * 每页行数
- n : 每页行数
5. 多表关系(了解)
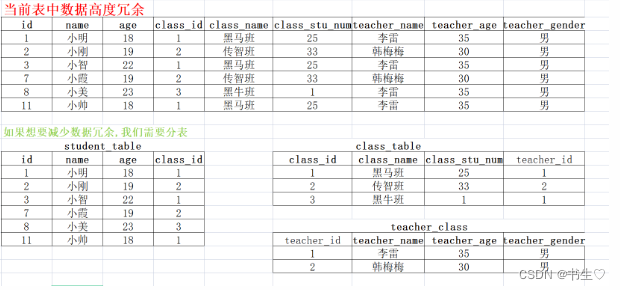
- 学生表和班级表之前,学生是多的一方,成为从表, 班级是一的一方,称为主表.
在从表中创建一个外键(class_id),绑定主表的主键(class_id) 从而形成对应关系.
- 班级表和教师表之间,班级是多的一方称为从表, 教师是一的一方,称为主表.
在从表中创建一个外键(teacher_id),绑定主表中的主键(teacher_id).形成对应关系.
- 学生表和教师表之间.没有直接关系.
6. 外键约束
外键约束: 就是主表主键和从表外键之间的关联关系, 添加约束后, 强制关联, 关联不成功则无法插入
-- 主表:
CREATE TABLE category
(
c_id INT PRIMARY KEY,
c_name VARCHAR(30)
);
-- 从表
CREATE TABLE products
(
p_id INT PRIMARY KEY,
p_name VARCHAR(30),
price DOUBLE,
category_id INT, -- 外键字段
FOREIGN KEY (category_id) REFERENCES category (c_id)
);
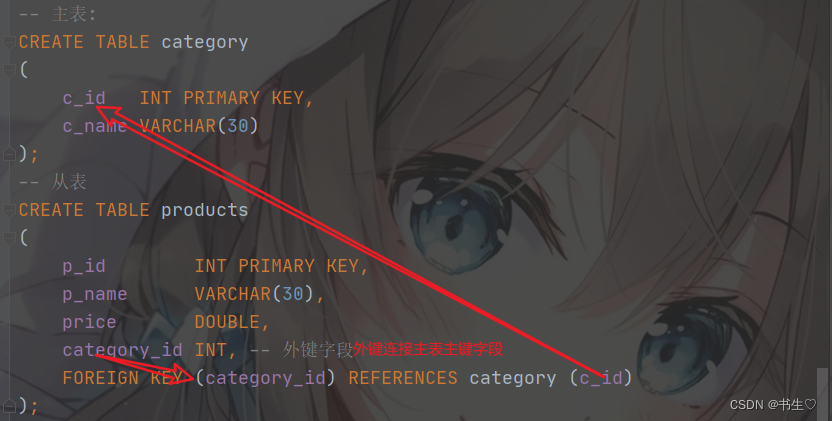
当我们需要自己添加外键的时候
-- 添加外键约束
ALTER TABLE products1 ADD CONSTRAINT fk_1 FOREIGN KEY (category_id) REFERENCES category(c_id);
删除外键
扩展: 删除外键约束,需要使用外键名称删除
ALTER TABLE products1 DROP FOREIGN KEY fk_1;
没有指定外键名称,删除外键的时候
如果我们没有指定外键名称则会使用默认名称, 此时需要使用 show create table
进行查询 products_ibfk_1 (表名_ibfk_编号)
ALTER TABLE products DROP FOREIGN KEY products_ibfk_1;
6.1 外键的注意事项
- 如果两张表绑定了外键约束规则.在从表中插入的外键值,只能是主表中存在的主键值, 但是外键值可以为空.
- 如果主表中的数据记录, 被从表的外键引用(绑定), 则 主表中的该数据记录无法被删除.
- 删除主表中的数据记录时, 该记录不能被从表中的外键引用(绑定), 否则无法删除.
外键约束的规则:
- 从表的外键字段,只能使用主表中的主键值或者null
- 删除主表记录时,该记录不能被任何从表外键引用
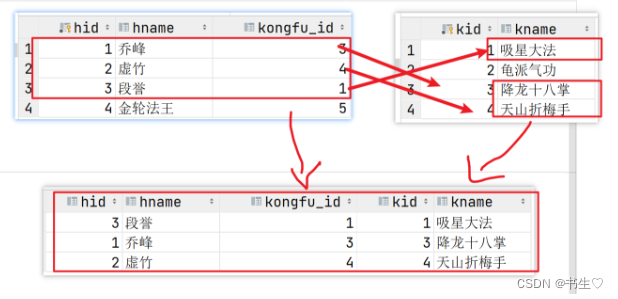
7. 多表查询之内连接
内连接获取的是,左表和右表中匹配成功的数据内容
内连接: inner join
- 规则: 左表和右表中的数据, 按照指定的规则进行连接, 连接成功则保留, 连接失败则不保留.
- 格式: select 列… from 左表 inner join 右表 on 链接规则;
SELECT *
FROM
hero
INNER JOIN kongfu ON hero.kongfu_id = kongfu.kid;
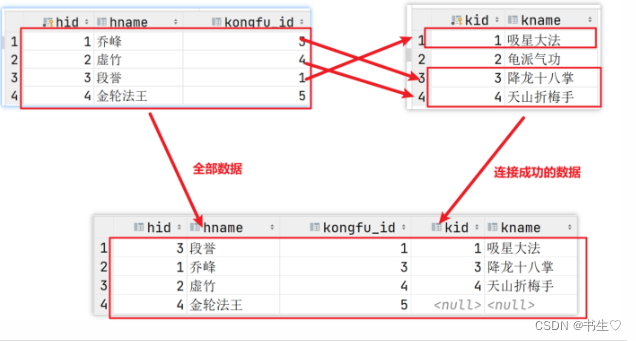
8.多表查询之外连接

8.1 多表查询之左外连接
左外连接会保留左表中的全部数据,和右表中的匹配成功数据,如果未匹配成功在末尾补null
格式: select 列… from 左表 left outer join 右表 on 连接规则;
-- 规则: 保留左表中全部的数据, 和右表中与左表连接成功的数据, 其余数据不保留
-- 解释: 左表就是写在左表的表, 和主从关系无关. 一般使用左连接,则左表的数据更重要.
SELECT *
FROM
hero
LEFT OUTER JOIN kongfu ON hero.kongfu_id = kongfu.kid;
8.2 多表查询之右外连接
保留右表中的全部数据, 和左表中与右表连接成功的数据, 其余数据不保留. 右表中连接不成功的部分补充null
格式: select 列… from 左表 right outer join 右表 on 连接规则;
注意:A 作为左表时,左连接的查询结果, 和A作为右表时的右连接查询结果相同
SELECT
hero.hid,
hero.hname,
kongfu.kname
> 这里是引用
FROM
kongfu
LEFT OUTER JOIN hero ON hero.kongfu_id = kongfu.kid;
-- 此时有同名字段kid ,所以必须增加表名.
SELECT
hero.hid,
hero.hname,
kongfu.kname
FROM
kongfu
LEFT OUTER JOIN hero ON hero.kongfu_id = kongfu.kid;
9. 多表查询之as语法
给表和字段起别名的方式.
9.1 给表起别名
作用 : 可以让我们使用表时,用更加简便的表名调用表中的字段
关键字 : as
- 格式 : 在from 后的表名 后添加 as 别名 表名 as 别名
-- 将表进行优化,使用as进行起别名
SELECT
p.pname,
p.price,
c.cname
FROM
products AS p
LEFT JOIN category AS c ON p.category_id = c.cid;
- 给表起别名后, 原始的表名将无法继续使用
- 给表起的别名只在当前sql语句中生效.遇到; 这个别名就失效了.
9.2 给字段起别名
作用 : 我们输出该数据时, 显示的字段名称为我们修改过的名称
- 关键字 : as
- 格式 : 在select 之后的字段名 添加 as 列名 as 别名
SELECT
pname,
price,
price * 1.75 + 20 + 50 AS sale_price
FROM
products
GROUP BY
sale_price
ORDER BY
sale_price;
注意:
- 以使用中文进行别名的赋值么? 可以,但是永远不要用, 因为可能由于系统环境, 或软件版本原因无法执行代码.
- 在 分组, 排序, 时可以使用别名
- 在where 条件语句中, 不能使用字段别名
10. 多表查询之连接关键字的省略
在sql开发中,经常会有一些语句中的部分关键字可以省略,我们采用省略写法,更加简洁
- inner join 中的inner 关键字可以省略
- left outer join 中的 outer关键字可以省略
- right outer join 中的 outer关键字可以省略
- 所有给表和字段起别名时书写的as关键字都可以省略
-- 1. inner join 中的inner 关键字可以省略
SELECT *
FROM products
INNER JOIN category ON products.category_id = category.cid;
-- 省略后,效果不变
SELECT *
FROM products
JOIN category ON products.category_id = category.cid;
-- 2. left outer join 中的 outer关键字可以省略
SELECT *
FROM products
LEFT OUTER JOIN category ON products.category_id = category.cid;
-- 省略后,效果不变
SELECT *
FROM products
LEFT JOIN category ON products.category_id = category.cid;
-- 3. right outer join 中的 outer关键字可以省略
SELECT *
FROM products
RIGHT OUTER JOIN category ON products.category_id = category.cid;
-- 省略后,效果不变
SELECT *
FROM products
RIGHT JOIN category ON products.category_id = category.cid;
-- 4. 所有给表和字段起别名时书写的as关键字都可以省略
SELECT c.cname,
AVG(price) AS avg_price
FROM products AS p
LEFT OUTER JOIN category AS c ON p.category_id = c.cid
GROUP BY cid, cname
ORDER BY avg_price DESC
LIMIT 1;
-- 省略后, 效果不变
SELECT c.cname,
AVG(price) avg_price
FROM products p
LEFT JOIN category c ON p.category_id = c.cid
GROUP BY cid, cname
ORDER BY avg_price DESC
LIMIT 1;

11.多表查询之子查询
子查询: 在一个select语句中,嵌套另外一个select语句, 内部的查询语句就叫做子查询.
格式: select 列 from 表 (select…)
-- 需求1: 获取所有商品中价格最高的商品的全部信息
SELECT *
FROM
products
WHERE
price = (SELECT
MAX(price)
FROM
products);
-- 子查询可以作为一个列使用
-- 需求2: 获取所有品类中,商品数量超过2个的商品信息.
SELECT *
FROM
products
WHERE
category_id IN (SELECT
category_id
FROM
products
GROUP BY
category_id
HAVING
COUNT(pid) > 2);
-- 子查询还可以作为表使用(了解)
-- 需求: 获取家电类和服饰类的全部商品信息
-- 家电类 和服饰类 这两个是 品类名称, 此时这个品类名称 在category表中
-- 使用子查询实现, 可以使用商品表 和 分类表中的家电类和服饰类的记录内连接, 连接成功则为这两类产品
SELECT *
FROM
products p
JOIN (SELECT * FROM category WHERE cname IN ('家电', '服饰')) c
ON p.category_id = c.cid;
-- 注意: 当子查询当做表出现时必须有别名, 哪怕不使用这个别名也必须有
12. sql语句的执行顺序
完整的sql语句是这个样子的.
那么我们想一想,它是以一个是怎么样的执行顺序????
SELECT
列1,
列2..... from 表1 (LEFT/RIGHT) JOIN 表2
ON 表1.字段1 = 表2.字段2
WHERE
筛选条件
GROUP BY 分组字段
HAVING
分组后筛选条件
ORDER BY 排序
LIMIT 起始索引, 条目数;
大家看下面这个

在group by 之前执行的关键字中,可以使用所有字段, 而在group by 之后的字段只能使用分组字段和聚合函数.
13. 案例小结
13.1 案例1
-- 创建数据库并使用
CREATE DATABASE test02 CHARSET = utf8;
USE test02;
-- 创建book表
-- 数据类型:int unsigned 代表无符号整数 只能保存正数
CREATE TABLE book
(
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(20),
pub_date datetime,
price decimal(5, 2)
);
INSERT INTO
book
VALUES
(0, '射雕英雄传', '1970-5-1', 36.60),
(0, '天龙八部', '1986-7-24', 50.20),
(0, '笑傲江湖', '1995-12-24', 40),
(0, '雪山飞狐', '1987-11-11', 29);
-- 创建heroes表
CREATE TABLE heroes
(
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(20),
age tinyint UNSIGNED,
gender varchar(20),
skill varchar(20),
book_id int NOT NULL
);
INSERT INTO
heroes (name, age, gender, skill, book_id)
VALUES
('郭靖', 30, '男', '降龙十八掌', 1),
('黄蓉', 30, '女', '打狗棍法', 1),
('黄药师', 60, '男', '弹指神通', 1),
('欧阳锋', 65, '男', '蛤蟆功', 1),
('梅超风', 40, '女', '九阴白骨爪', 1),
('乔峰', 33, '男', '降龙十八掌', 2),
('段誉', 25, '男', '六脉神剑', 2),
('虚竹', 27, '男', '天山六阳掌', 2),
('王语嫣', 18, '女', '神仙姐姐', 2),
('令狐冲', 32, '男', '独孤九剑', 3),
('任盈盈', 24, '女', '弹琴', 3),
('岳不群', 50, default, '华山剑法', 3),
('东方不败', 99, '中性', '葵花宝典', 3),
('胡斐', 26, '男', '胡家刀法', 4),
('苗若兰', 16, '女', '黄衣', 4),
('程灵素', 20, '女', '医术', 4),
('袁紫衣', 22, '女', '六合拳', 4);
-- 3、修改book表pub_date字段类型为date类型
ALTER TABLE book
CHANGE pub_date pub_date date;
DESC book;
SELECT
pub_date
FROM
book;
-- 4、查询所有的英雄信息以及对应的书名
-- 分析,英雄信息和书名不在同一个表中,我们需要连接表
SELECT
h.*,
b.name
FROM
heroes h
JOIN book b ON b.id = h.book_id;
-- 5、查询80年代出版的书, 中所有的女性英雄信息以及对应的书的信息
-- 出了数值型数据和null 剩下的数据都必须加引号
SELECT *
FROM
book b
JOIN heroes h ON b.id = h.book_id
WHERE
(b.pub_date BETWEEN '1980-1-1' AND '1989-12-31')
AND (h.gender = '女');
-- 6、查出会"降龙十八掌"的英雄名字, 以及对应的书名
SELECT
h.name AS hero_name,
b.name AS book_name
FROM
heroes h
JOIN book b ON b.id = h.book_id
WHERE
skill = '降龙十八掌';
-- 7、查询每本书中英雄年龄的平均值
SELECT
b.name,
AVG(age)
FROM
heroes h
JOIN book b ON b.id = h.book_id
GROUP BY
book_id;
-- 8、查询每本书中年纪最大的英雄 (了解即可)
-- 书名 英雄 join
-- 可以获取每本书中最大的年龄, 还可以获取该书的id
-- 第一步: 获取每本书中最大的年龄以及对应的id
SELECT
MAX(age),
book_id
FROM
heroes
GROUP BY
book_id;
-- 第二步: 连接第一步中产生的表和原英雄表
SELECT *
FROM
heroes h
JOIN (SELECT
MAX(age) max_age,
book_id
FROM
heroes
GROUP BY
book_id) max_h ON h.book_id = max_h.book_id AND
h.age = max_h.max_age;
13.2 案例2
# 1. 登录 mysql 然后创建一个名为py2888 数据库
CREATE DATABASE py2888 CHARSET 'utf8';
-- 2. 然后在这个数据库下创建一个
-- 职工表worker(工号id,姓名name,能力值 level<整数>,所属部门dep_id)
CREATE TABLE worker
(
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(20),
level int,
dep_id int
);
-- 3. 创建一个 部门表department(部门编号id,部门名称name,主管工号mid)
CREATE TABLE department
(
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(100),
mid int
);
-- 4. 现有职工数据如下 请使用 insert 语句插入到worker表中
INSERT INTO
worker
VALUES
(1, '黄蓉', 80, 100),
(2, '东邪', 95, 100),
(3, '梅超风', 90, 100);
-- 5. 现有职工数据如下 请使用INSERT语句插入到worker表中
INSERT INTO
worker (name, level, dep_id)
VALUES
('尹志平', 67, 200),
('丘处机', 85, 200),
('周伯通', 93, 200);
-- 6. 现有部门数据如下 请使用 INSERT 语句插入到departmen表中
INSERT INTO
department (id, name)
VALUES
(100, '桃花岛'),
(200, '全真教');
-- 7. 求出所有 职工中 能力值高于70的人的信息
SELECT *
FROM
worker
WHERE
level > 70;
-- 8. 求出所有 职工中 能力值前三甲的人的信息
SELECT *
FROM
worker
ORDER BY
level DESC
LIMIT 3;
/*SELECT w.*
FROM
worker w
JOIN (SELECT level FROM worker ORDER BY level LIMIT 3) w_3
ON w.level = w_3.level;
*/
-- 9. 求出所有 职工的 平均能力值
SELECT
AVG(level)
FROM
worker;
-- 10. 使用 SQL 语句将 东邪 设置为桃花岛组的主管
UPDATE department
SET
mid = (SELECT id FROM worker WHERE name = '东邪')
WHERE
name = '桃花岛';
-- 11. 使用 SQL 语句将 丘处机设置为全真教组的主管
UPDATE department
SET
mid = (SELECT id FROM worker WHERE name = '丘处机')
WHERE
name = '全真教';
14.寄语
💕💕在这篇文章中,我们深入探讨了MySQL相关知识,希望能为读者带来启发和收获。
💖💖感谢大家的阅读,如果您有任何疑问或建议,欢迎在评论区留言交流。同时,也请大家关注我的后续文章,一起探索更多知识领域。
愿我们共同进步,不断提升自我。💞💞💞



![小字辈[天梯赛]](https://img-blog.csdnimg.cn/direct/d4ee3d3502844b00b6a875f0b15d33c3.png)