- 第一部分
目录
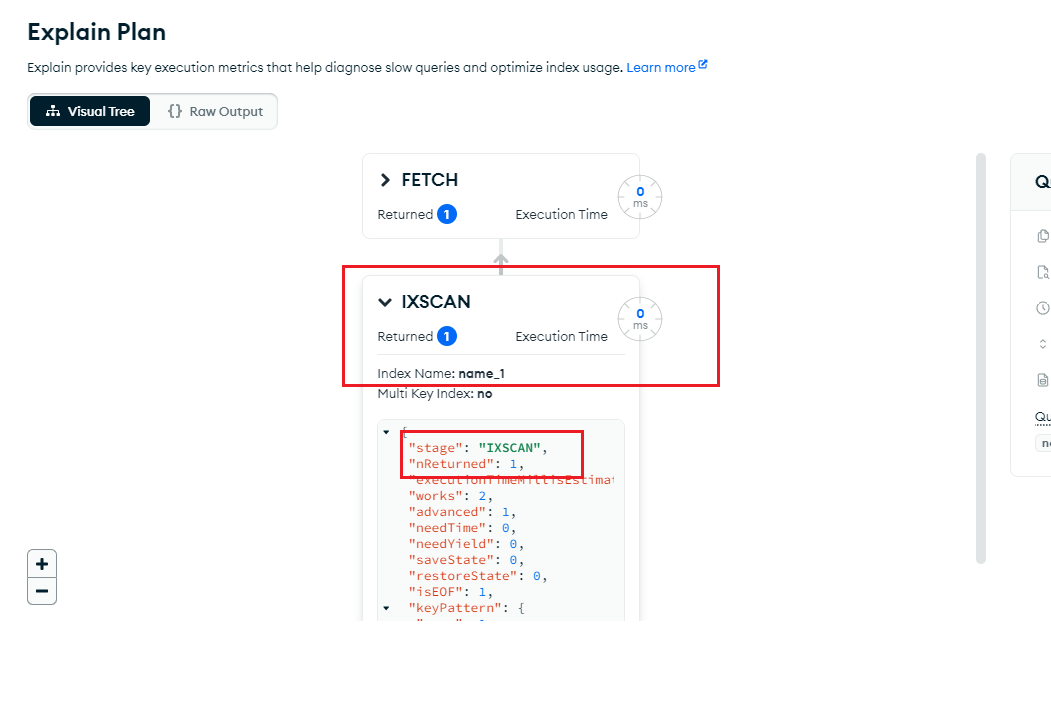
- 三、前向传播(渲染):`submodules/diff-gaussian-rasterization/cuda_rasterizer/forward.cu`
- 预备知识:CUDA编程基础
三、前向传播(渲染):submodules/diff-gaussian-rasterization/cuda_rasterizer/forward.cu
预备知识:CUDA编程基础
这部分的参考资料:
[1] CUDA Tutorial
[2] An Even Easier Introduction to CUDA
[3] Introduction to CUDA Programming
CUDA是一个为支持CUDA的GPU提供的平台和编程模型。该平台使GPU能够进行通用计算。CUDA提供了C/C++语言扩展和API,以便用户利用GPU进行高效计算。一般称CPU为host,GPU为device。
CUDA C++语言中有一个加在函数前面的关键字__global__,用于表明该函数是运行在GPU上的,并且可以被CPU调用。这种函数称为kernel。
当我们调用kernel的时候,需要在函数名和括号之间加上<<<M, T>>>,其中M是block的个数,T是每个block中线程的个数。这些线程都是并行执行的,每个线程中都在执行该函数。
根据参考资料[3],GPU在同一时刻运行一个kernel(也就是一组任务),每个kernel由多个block组成(他们是独立的ALU组),每个block有多个线程。同一block中的线程一般合作完成任务,它们可以共享内存(这部分内存速度极快,用__shared__关键字声明)。每个线程“知道”它在哪个block(通过访问内置变量blockIdx.x)和它是第几个线程(通过访问变量threadIdx.x),以及每个block有多少个线程(blockDim.x),从而确定它应该完成什么任务。

注意GPU和CPU的内存是隔离的,想要操作显存或者在显存和CPU内存之间进行交流必须显示的声明这些操作。指针也是不一样的,有可能虽然都是int*,但表示的含义却不同:device指针指向显存,host指针指向CPU内存。CUDA提供了操作内存的内置函数:cudaMalloc、cudaFree、cudaMemcpy等,它们分别类似于C函数malloc、free和memcpy。
关于同步方面,内置函数 __syncthreads()可以同步一个块中的所有线程。在CPU中调用内置函数cudaDeviceSynchronize()可以可以阻塞CPU,直到所有先前发出的CUDA调用都完成为止。
另外还有__host__关键字和__device__关键字,前者表示该函数只编译成CPU版本(这是默认状态),后者表示只编译成GPU版本。二者同时使用表示编译CPU和GPU两个版本。从CPU调用__device__函数和从GPU调用__host__函数都会报错。