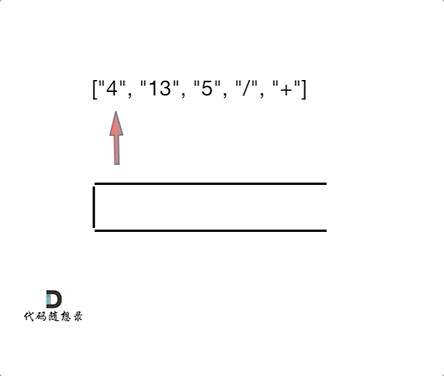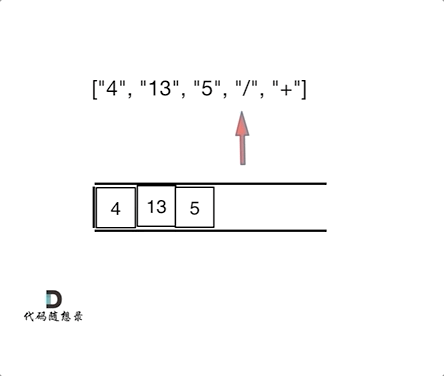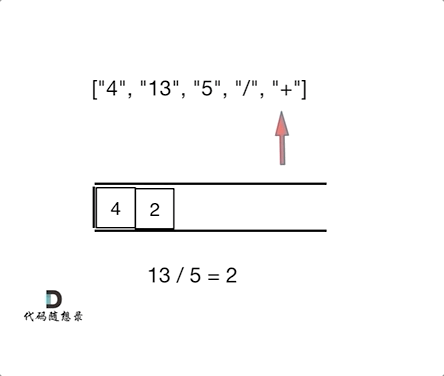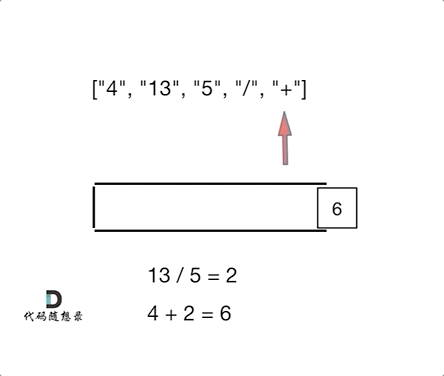
1. pc可以跑通,但是安卓编译死循环,可能是函数声明了返回类型,但是没有真正返回
2. ubuntu下根据关键词杀死所有相关进程。ps -ef | grep code | grep -v grep | cut -c 10-16 | xargs kill -s 9
top和ps基本作用都是显示系统进程状况,但top命令是动态显示,ps命令是静态显示,即ps命令只显示命令执行时的进程状况。
top |grep xxx
adb --vesion
which adb
cp xxx /usr/bin/adb
3. 代码格式化。Alt contr L,Control shift i
4.git忽略权限差异:git config core.filemode false
5.删除本地仓库:rm .git/index
6.显卡GeForce RTX 3090,该显卡仅仅支持使用cuda11以上的版本
https://www.jianshu.com/p/ab2ba5480066
7.cv2.circle画圆圈,输入要求是三通道的,否则报错:python opencv TypeError: Layout of the output array incompatible with cv::Mat
8.RaiDrive,映射网盘到本地
9.Linux操作系统中,set命令主要用于设置shell。set-e,如果code返回结果不上0,就直接退出,set-x,开启输出详细日志。
10. ubuntu添加环境变量。以添加PYTHONPATH为例:
# 使用gedit编辑器打开~/.bashrc文件
sudo gedit ~/.bashrc
# 在文件末尾添加命令
export PYTHONPATH=/home/jhm/caffe/python
export PATH=$PYTHONPATH:$PATH
# 保存退出
source ~/.bashrc
11. source insight,btop,clion
12. sudo find / pycharm.sh
13. adb version
14.ndk_build -v
15.逐像素计算,考虑OpenCL
15.HVX优化
16.strings anaconda2/lib/python2.7/site-packages/ale_python_interface/libstdc++.so.6.0 |grep GLIBCXX
17.Verifying your browser... | myfreax
18.Can't parse 'p'. Sequence item with index 0 has a wrong type。可以看出是变量类型不对,但往往是int的问题,opencv在坐标,长宽等严格要求是int型,注意把数据类型int()转换
19.
19.neon* mus5dSSHFS使用指南_eatlemon的博客-CSDN博客_sshfsm
20.du -h -d 1查看目录下一层的各个文件及其大小
21. 保存shell终端输入到文件:使用标准输出重定向运算符>将输出重定向到文件:command > file.txt,如果file.txt不存在,它会自动创建。如果你使用>再次重定向到相同的文件,文件内容将被替换为新的输出。
22. grep -iEr "ref_is_evn: 1" */Pick-result.txt > ref.txt
23. git commit 时报错,sha1 file no space left,原因是本地空间已满了
24. clang++: error: linker command failed with exit code 1
25.Linux中查看各文件夹大小命令du -h --max-depth=1
df -h
ARM NEON
26. $# 获得shell命令中参数个数,#! /bin/bash 表明使用bash作为该shell的解释器,bash 是Bourne Again Shell, $0表示shell文件名,$1~$n表示第一个到第n个参数
if [$1 -eq 0],判断第一个参数是否等于0
-gt 运算符,greater than,检测是否大于
27. sorted 排序是按照字典序lexicographical,这样10会排在1之后,2之前。使用natsort可以naturally排序
28.正则表达式,re.findall(pattern, string)
“.*?” 表示非贪心算法,表示要精确的配对。
“.*”表示贪心算法,表示要尽可能多的匹配
“()” 表示要获取括弧之间的信息。
29. 序列解包/列表前加星号*list。可用于将list中元素依次传入函数中
30.可将nn.Conv2d,nn.ConvTranspose2d,nn.BatchNorm2d,ReLu,MaxPool2d等append进list中,然后返回squential(*list),构成网络的block
31.yuv颜色空间。yuv444表示三个通道完全采样,yuv422是竖直方向完全采样,水平方向uv分别间隔采样,各采样一半,相邻像素的uv互补,所以4+2+2/(4+4+4)=2/3,节约了1/3的存储空间。yuv420是在422的基础上将v的采样放在了下一行,这样四个像素共用一对uv,这对uv分别来自两行,因为420是相对于一行说的,一行之内u或者v没有被采样,所以是420.
四、YUV图像基础_yuv420_future_sky_word的博客-CSDN博客
YUV 的存储格式,有两种:
- planar 平面格式
- 指先连续存储所有像素点的 Y 分量,然后存储 U 分量,最后是 V 分量。
- packed 打包模式
- 指每个像素点的 Y、U、V 分量是连续交替存储的
32 git reset 回到指定版本,默认是mixed,本地的还在。
33.yeild生成斐波那契数列。下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的
34. 栈空间是有限的,假如频繁大量的使用就会造成因栈空间不足而导致程序出错的问题。用inline修饰函数,调用的时候集直接用函数内部的代码替换。inline 函数仅仅是一个对编译器的建议,所以最后能否真正内联,看编译器的意思,它如果认为函数不复杂,能在调用点展开,就会真正内联,并不是说声明了内联就会内联,声明内联只是一个建议而已
35.C++的inline成员函数自带static属性。用static修饰的函数,限定在本源码文件中,不能被本源码文件以外的代码文件调用。而普通的函数,默认是extern的,也就是说它可以被其它代码文件调用。
36.正则表达式()来分段,*要求前面的有任意个。search只要有匹配的就返回true。匹配的时候要严格按照格式,区分字母和数字。\\d{10}表示10个数字,.*表示任意个字母,
正则表达式(regex)入门_码农行者的博客-CSDN博客
正则表达式 C++_std::regex_search_生活需要深度的博客-CSDN博客
37.math.gamma(n)计算n-1的阶乘。用于多项式回归的实现,
38.如果图像出现上部分正常,或者间隔行列有值,很可能是数据连续弄错了。注意memcpy要sizeof判断数据类型。
39.new是关键字,对编译器有特殊含义。关键字分为数据类型关键字,int等;控制语句关键字,for,siwtch;存储类型关键字,auto,extern,static等;其他类型,sizeof,const;
40. c++默认变量是private。private变量不能直接通过类的实例去取,设值或者取值必须通过成员函数。protected变量和private类似,但是可以继承,在派生类的成员函数可以访问。
41.std::sort自定义排序方式。默认是从小到大,默认快排?自定义可以构造函数,也可以使用lambda匿名函数
std::vector<int> v{3, 5, 1}; std::sort(v.begin(), v.end(), [&v](size_t a, size_t b){return v[a] < v[b];});
利用lambda函数的捕获参数,避免了在比较函数中需要传递v的麻烦。
总结一下,这个lambda表达式生成了一个比较v向量元素的小函数,利用捕获参数引用了外部变量,非常方便地用于诸如排序等算法中。C++笔记之STL的sort使用第三个参数来自定义排序_std::sort 自定义_笑鸿的学习笔记的博客-CSDN博客
42. 利用指针对vector初始化。
43。数组的初始化和分配。int a[5] = {1, 2, 3, 4, 5};//静态初始化,//动态数组 int *pia2 = new int[10] (); // 类似于int pia2[10] ,每个元素初始化为0。
静态分配在栈上,由编译器为对象在栈空间中分配内存。静态分配可以使代码更简单,因为不需要显式释放内存,对象的生命周期由编译器自动管理。但是,静态分配的对象无法在运行的时候改变大小或释放。而且如果对象生命周期比当前作用域范围长,可能导致过早释放或者内存泄漏。
动态分配在堆上
44. addr2line -e xxx.so addr
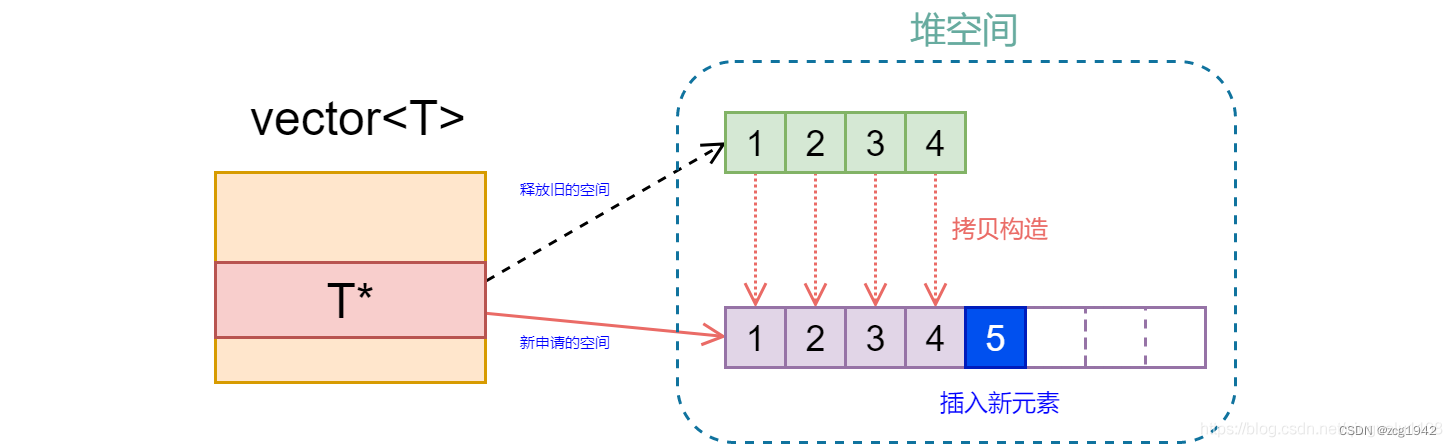
45.vector ,push_back时如果空间不够,重新申请2倍的空间,同时把用来的拷贝过来,析构旧空间。非常费内存。
vector对象本身存在栈中,其数据是在堆中的。
vector的成员函数size(),表示容器中实际存放元素的个数。capacity()函数表示vector此刻总共可以容纳元素的个数。其中capacity()函数的返回值才是vector实际占用空间的大小。
46. git reset 到某一commit,默认是Mixed,keep working tree,but reset index。
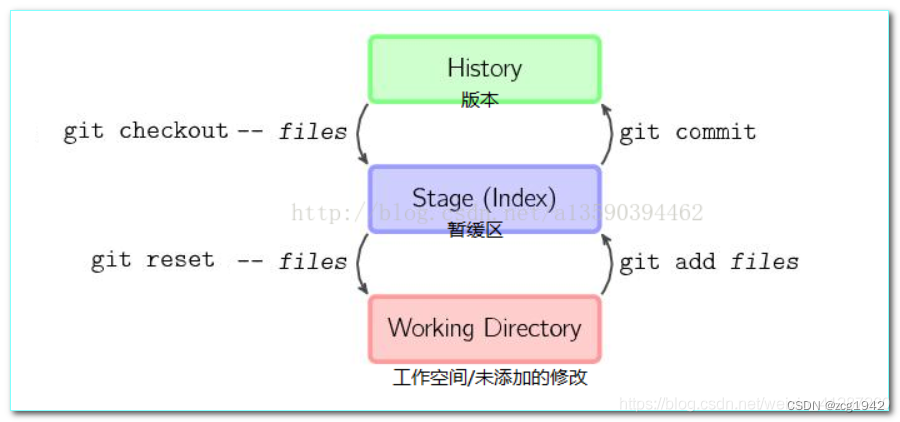
index是缓存区,缓存区是reset到指定commit的内容,而working directory还是reset之前的内容,git branch插件显示的就是working相对于index的 变化,右侧就是working directory的改变。
47. fsanitize=address,内存检查
add_definitions("-g")
add_definitions("-fsanitize=address")
add_definitions("-fno-omit-frame-pointer")
link_libraries("-fsanitize=address")
Address Sanitizer 用法 - 简书
48.
set -e(或set -o errexit)是Shell脚本中的一个选项设置,表示在任何命令执行失败(返回非零退出状态码)时立即退出脚本。这意味着如果某个命令执行失败,脚本会立即停止执行后续命令,并返回一个非零的退出状态码。set -e通常用于在脚本中快速检测错误并终止脚本执行,以避免错误继续传播。
49
import xml.etree.ElementTree as ET
tree = ET.parse(file_path) # 解析xml或者xtml文件,tree是elementTree对象。用来爬虫
root = tree.getroot()
root.findall('object') #ET支持部分的Xpath语法,XPath 使用路径表达式在 XML 文档中进行导航,Xpath有内建函数。
Python系列,网络爬虫Xpath解析入门教程(教学详细、语法基础、附实例代码) - 知乎
50. scipy.Stats.linregress( )线性回归
51. opencl本质是c语言?只能调用c语言中的函数,但是c语言中没有std::sort。有qsort,但是报错。实现冒泡排序,每次移动最小的到正确位置。
52.在 Linux 下使用 cp/mv/rm 等命令时,经常会碰到 Argument list too long 错误。
方法1:通过命令,find和xargs来解决。
方法2:通过命令,find和exec来解决。
find dusays/ -name "*.com" | xargs -i cp {} 7bu/
find dusays/ -name "*.com" -exec cp {} 7bu/ \;
find dusays/ -name "*.com" | xargs -i rm -f {}
find dusays/ -name "*.com" -exec rm -f {} \;
53.文件流类提供了许多不同的成员函数,可以用来在文件中移动。其中的一个方法如下:
seekg(offset, place);
54. tensorflow1.15之后没用tensorflow.contrib:
pip install tf_slim
55.nano保存并退出 快捷键 nano是一款基于命令行的文本编辑器,它最常用的快捷键是Ctrl+O和Ctrl+X,用于保存并退出或退出而不保存
56.苹果 iOS 使用 Shadowsocks 设置教程 | Shadowsocks
57. 第一行:“#!/bin/bash” 是一行特殊的脚本说明,表示此行以后的语句通过/bin/bash程序来解释执行;
58. set -x 与 set +x命令的作用实际是用于输出详细日志,是Shell脚本中使用echo命令输出的替代方案。更适用于输出大量日志的场景使用
set -x 是开启,set +x是关闭,set -o是查看 (xtrace,追踪一段代码的显示情况)
set -e(或set -o errexit)是Shell脚本中的一个选项设置,表示在任何命令执行失败(返回非零退出状态码)时立即退出脚本
59. 模板函数,貌似只能直接实现在头文件中?
60. python中main函数传参,可以是一个dict,在函数内部也构造一个包含缺省值的dict,然后通过.update更新使用传入的参数。
调用argparse的静态方法Namespace,自动将dict的键值对转化为argparse对象:arg=argparse.Namespace(**dict)
torch的模型也以字典的形式保存在pkl中,torch.load读取后也可以转换成argparse。
61.re.compile做正则匹配,数字和字母要区分开,数字\d+,字母.*。 匹配使用fullmatch
IMG_2101023_1934_259_VT_in_4086x3072_00_EV[0].RGGB
re.compile(r'(IMG_\d+_\d+_\d+)_.*_in_(\d+)x(\d+)_EV\[0\].RGGB')
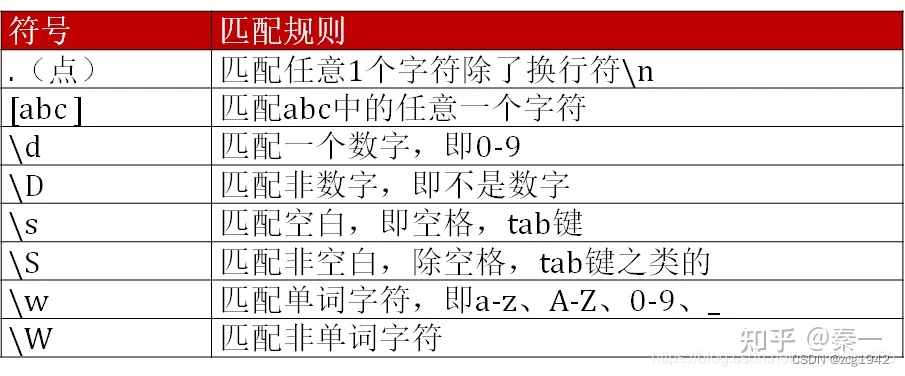

re.compile返回一个SRE_Pattern对象,可以调用search或者match函数。
>>> n = re.match('foo','hello,foo!')
>>> if n is not None:ngroup()
...
>>>
>>> n = re.search('foo','hello,foo!')
>>> if n is not None:n.group()
...
'foo'earch()的工作方式和match()完全一致,只是search()会用他的字符串参数,在任意位置对给定正则表达式模式搜索第一次出现的匹配情况
match()方法视图从字符串的起始位置部分对模式进行匹配
62. list使用insert插入到指定位置,list.index("xxxx")获得指定字符串在list中的索引
63. ctrl+P查找文件,ctrl+G定位行号
64. linux 下查询之前用过的命令。
history|grep “ls -a”
65. 使用lsb_release工具Linux Standard Base (LSB)输出Ubuntu版本信息
lsb_release -a66.docker load --input xxxx.gz,这样就会把里面的各种layer识别解析出来,得到这个docker的名称
【Docker系列】从头学起 Docker——docker run 命令详解-CSDN博客
docker load -i xxx.tar
查看一下 docker images,可以看到TAG,IMAGE ID,SIZE等属性
docker run --gpus all -it -v
为了在容器中也能使用gpu资源,需要安装nvidia-container-toolkit
报错找不到libnvidia-ml.so.1,原因可能是打包docker时把驱动和cuda打包进去了,实际调用的时候物理机的不匹配。
Ubuntu彻底解决apt-get代理设置问题(取消代理设置)_程序员_IT虾米网
取消apt代理,env | grep -i proxy 没输出不一定真的没有代理了。
加了第三方源,public key not available,apt-key添加公钥
67. nohup指令,no hang up,退出终端也不会影响程序的执行
68. tmux,terminal multipleXer,一个终端可以操作多个会话;ctrl+b之后,激活控制台,具体发生什么和接下来的按键相关:按下t显示时间,按下?列出所有快捷键,q退出控制台
69. torchrun命令,防止训练中断,定期保存snapshot,可以从中断的地方训练。这就是弹性容错。
在xxx.py之前,控制多机多卡训练。
--standalone表示单机,--nproc_per_node表示gpu个数,
--nodes表示节点,指主机或者容器。
--rdzv_backend=c10d,用来给eladticAgent指定共享存储,以供节点失败时的重新动态组网。
70. python内置函数,globals(),以字典的方式返回全局变量及其对应的值。结合字典的get函数,得到想要变量的值。
71. os.environ["LOCAL_RANK"],双机16卡分布式训练,每台机器8卡,worldsize=16,rank编号为0-15,但是localrank还是0-7(对应的是单个gpu上)。
72.python的printf不仅可以打印到屏幕,也可以打印至文件中。
1、print()函数可以输出一个值,也可以同时输出多个值,如果输出多个值,这多个值之间用半角逗号隔开;
2、sep参数指定输出的多个值之间的间隔符,如不指定,则默认间隔符是一个半角空格;
3、end参数指定输出所有的值之后再输出什么符号,如不指定,则默认输出一个换行符;
4、file参数指明输出到文件还是到屏幕,默认是输出到屏幕;
73. Pytorch并行主要有两种方式,DataParallel(DP)和DistributedDataParallel(DDP)
DistributedSampler获得采样器
DataLoader的时候使用采样器对数据集进行采样
数据集Dataset类继承自Dataset,
74. Nvidia 3090-torch 1.12+cu116+python3.9.12
75. dataloader是一个迭代器,返回前向传播需要的batch。在迭代的过程中,dataloader会自动调用dataset中的__getitem__ 函数,以获取一帧数据(item)
76. find / -name libpython3.8.so.1.0
cp /usr/local/python3/lib/libpython3.6m.so.1.0 /usr/lib/
77 addr2line -f -e xxx.so 1f2dc 定位地址在库中的位置,得到文件名和行号,ctrl+P输入行号快速跳转;
78.
将所有的int转换为str
lst1=list(map(lambda x:str(x),lst))
79. export 可新增,修改或删除环境变量
export MYENV=7 //定义环境变量并赋值
要想永久生效,需要把这行添加到环境变量文件里。有两个文件可 选:“/etc/profile”和用户主目录下的“.bash_profile”,“/etc/profile”对系统里所有用户都有效,用户主目录下 的“.bash_profile”只对这个用户有效。
> source ~/.bashrc # 使修改生效
> echo $PATH | grep ' keyword ' #查看是否有返回以及返回是否正确 来判断是否设置正确
80. md5sum xxx.so
81. cp -rv
82. CI(Continuous Integration,持续集成)/CD(Continuous Delivery,持续交付/Continuous Deployment,持续部署)属于DevOps的概念,指将传统开发过程中的代码构建、测试、部署以及基础设施配置等一系列流程的人工干预转变为自动化。
83. python中的装饰器,顾名思义就是不改变原来的函数,在原来函数基础上封装了一层,执行原来函数的同时也会执行新装饰的部分。https://www.cnblogs.com/huageyiyangdewo/p/17322678.html
Pytorch注册器机制Registry - 知乎
在pytorch中经常使用注册器来支持不同的模型结构和训练策略,注册就是通过装饰器来实现的。注册之后就可以自由选择不同的模型结构和训练策略。注册时用register函数记录在dict中,使用时调用get函数重构。
84. __name__='__main__‘,当py文件是导入的时,__name__值是文件名称,只有py文件是正在测试的代码时满足这个判断条件。__main__ 是最高层级代码运行所在环境的名称。这样把测试代码放在这个条件下面,就可以避免导入文件后错误运行一些测试代码,
85. os.name——name指操作系统的名字,主要作用是判断目前正在使用的平台,并给出操作系统的名字,如Windows 返回 'nt'; Linux/mac 返回posix
os.environ------获得一些有关系统的各种信息,有很多关键字段。
rank = int(os.environ['RANK']) //当前进程的序号,用于进程之间的通信,rank=0的主机为master节点。
local_rank = int(os.environ['LOCAL_RANK']) //当前进程对应的gpu号。
args.world_size = int(os.environ['WORLD_SIZE'])
torch.cuda.set_device(local_rank)
torch.distributed.init_process_group(backend="nccl",world_size=args.world_size,rank=rank)
86.pytorch支持多线程和分布式训练。相比于Torch.multiprocessing,torch.distributed的processes可以跑在不同的backends上,不必在同一个机器上。
Writing Distributed Applications with PyTorch — PyTorch Tutorials 2.2.0+cu121 documentation
Distributed Data Parallel — PyTorch master documentation
要想分布式,需要先初始化:
dist.init_process_group(backend,rank,word_size)
关于backend的种类,有gloo,nccl,MPI。他们就是不同的通信库。可以在pytorch手册中查看他们的区别,什么时候选取什么:如果是windows平台使用gloo,如果使用的是CUDA就使用nccl
Distributed communication package - torch.distributed — PyTorch 2.1 documentation
87.globals() 函数会以字典类型返回当前位置的全部全局变量。
一个py文件中所有导入的module,class,function都会是全局变量。还有__name__,__file__
dict.get(a,b):a是键值key,如果存在dict存在键值a,则函数返回dict[a];否则返回b,如果没有定义b参数,则返回None。
88.inspect.stack()可以获得一个数组,依次表示从内到外调用inspect.stack()的函数名称和行号等信息。比如说有好几个函数都调用了这个,就可以知道是哪个函数调用的。
89.python中{}完成引用/字符串格式化:
name = "Alice"
age = 30
# 使用双引号
message1 = f"Hello, my name is {name} and I am {age} years old."
print(message1)
# 使用单引号
message2 = f'Hello, my name is {name} and I am {age} years old.'
print(message2)90. 训练指定使用GPU:
device = torch.device('cuda')【Pytorch】torch.backends.cudnn.benchmark - 知乎
torch.backends.cudnn.benchmark=True,进一步可以加快训练时间。因为cudnn里面有多种前向卷积的算法实现,可以自动地为每层卷积选取最优的算法实现。这就要求网络结构和输入尺寸不变,不过大部分情况下都是满足的。
91.便于管理,需要修改多进程(包括子进程)的名称:
setproctitle.setproctitle('python3 main--')
92. pytorch数据集加载:
from torch.utils.data import DistributedSampler,DataLoader
from torchvision import datasets
dataset = datasets.ImageFolder(data_path, transform) // 也可以自己定义类
sampler = DistributedSampler(dataset,
shuffle=True, // 打乱数据
drop_last=True, // 丢弃最后一组数据)
loader = DataLoader(
dataset = dataset,
sampler = sampler,
shuffle =False, // 设定了采样策略sample,shuffle就必须是false
batch_size=batch_size,
num_workers= num_workers, //进程数
pin_memory =True,// 返回之前,将tensor拷贝到cuda
drop_last =True, // 丢弃最后不足一个batch的数据
)93. ln -s target link_name
创建软链接
其中,target是现有文件或目录的名称,而link_name则是符号链接的名称。
如果不提供link_name,ln将使用target的基本名称作为链接的名称。
94. 计算均值和方差的 CUDA kernel 具体实现是实现采用的 Welford迭代计算算法
95.PWD是英文Present Working Directory的缩写,意为当前工作目录
96.os.path.splitext(path)[0] 去除后缀名
97.np.array_split
import numpy as np
arr = np.array([1, 2, 3, 4, 5, 6])
newarr = np.array_split(arr, 3)
print(newarr)
np.cumsum()是numpy库中的一个函数,表示对数组元素进行累加并存储结果。
一般用来记录分段的起始点。[0]+list(np.cumsum(v1))[:-1]
98. 多进程
pool = multiprocessing.Pool(processes = 3)
pool.map(func, (msg,)) //使进程阻塞直到结果返回
pool.apply_async(func, (msg,)) //非阻塞的且支持结果返回后进行回调和多线程
99. lmdblmdb数据库的读取与转换(二) —— 数据集操作-腾讯云开发者社区-腾讯云
env = lmdb.open('./data/train/CVPR2016')
with env.begin(write=False) as txn:
# 获取图像数据
image_bin = txn.get('image-000004358'.encode())
# 将二进制文件转为十进制文件(一维数组)
image_buf = np.frombuffer(image_bin, dtype=np.uint8)
# 将数据转换(解码)成图像格式
# cv2.IMREAD_GRAYSCALE为灰度图,cv2.IMREAD_COLOR为彩色图
img = cv2.imdecode(image_buf, cv2.IMREAD_COLOR)
cv2.imwrite('show.jpg',img)100. ssh登陆主机,或者在文件浏览器add other locations,使用sftp:://10.11.11.11
默认进入的是~/,表示的是/home/用户名,但在home同级也可能有文件。