目录
GBDT
提升树
梯度提升树
GBDT算法实战案例
XGBoost
😆😆😆感谢大家的观看😆😆
GBDT
梯度提升决策树(Gradient Boosting Decision Tree),是一种集成学习的算法,它通过构建多个决策树来逐步修正之前模型的错误,从而提升模型整体的预测性能。
GBDT属于Boosting方法的一种,这种方法会顺序构建一系列弱学习器(通常是决策树),每个后续模型都侧重于纠正前一个模型的错误。在GBDT中,这些弱学习器是回归决策树。GBDT利用了泰勒级数展开和梯度下降法的思想,在函数空间中使用梯度下降法进行优化。GBDT可以应用于回归和分类问题,对于多分类问题,通常会使用类似于softmax回归中提到的损失函数和梯度。
提升树
📀提升树:通过拟合残差的思想来进行提升(真实值 - 预测值)
- 预测某人的年龄为100岁
- 第1次预测:对100岁预测,因单模型在预测精度上有上限,只能预测成80岁;100 – 80 = 20(残差)
- 第2次预测:上一轮残差20岁作为目标值,只能预测成16岁;20 – 16 = 4 (残差)
- 第3次预测:上一轮的残差4岁作为目标值,只能预测成3.2岁;4 – 3.2 = 0.8(残差)
- 若三次预测的结果串联起来: 80 + 16 + 3.2 = 99.2
对于提升树来说只需要简单地拟合当前模型的残差。
梯度提升树
📀梯度提升树不再使用拟合残差,而是利用最速下降的近似方法,利用损失函数的负梯度作为提升树
算法中的残差近似值。

-
切分点1.5 将数据集分成两份 [5.56],[5.56 5.7 5.91 6.4 6.8 7.05 8.9 8.7 9. 9.05]
-
第一份的平均值为5.56 第二份数据的平均值为(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9 = 7.5011
-
第一份数据的误差为0,第二份数据的平方误差为目标值与预测值的差的平方再相加:15.7
根据计算以 6.5 作为切分点损失最小。
- 当处理回归问题时,如果损失函数是均方误差(square error loss),那么负梯度就是残差,即真实值与当前模型预测值的差值。
- 对于分类问题,特别是二元分类,通常会使用类似于逻辑回归的损失函数,如对数损失(log loss)或交叉熵损失(cross-entropy loss)。在这种情况下,负梯度是基于概率预测的梯度,而不是直接的残差。
- 在GBDT中,无论是分类还是回归问题,都使用CART算法中的回归树来拟合负梯度。这是因为负梯度是连续值,需要用回归树来进行拟合。
-
负梯度是GBDT中用来指导模型优化的方向,它根据当前模型的损失函数来计算,并通过拟合这些负梯度来训练新的决策树,从而逐步提升模型的性能。
构建第二个弱学习器
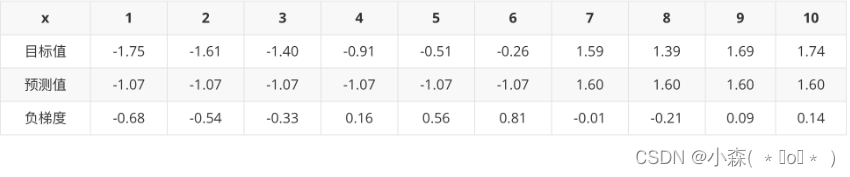
以 3.5 作为切分点损失最小
构建第三个弱学习器
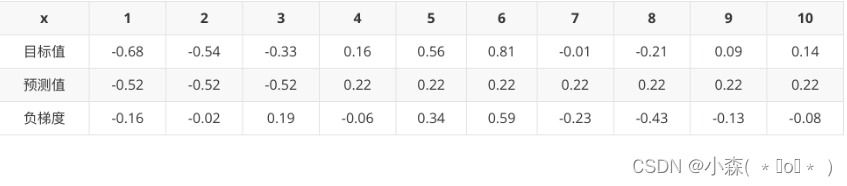
以 6.5 作为切分点损失最小
最终的强学习器 :

GBDT算法实战案例
from sklearn.datasets import load_boston
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
data = load_boston()
X, y = data.data, data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建GBDT回归模型
gbdt = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
# 训练模型
gbdt.fit(X_train, y_train)
# 预测测试集
y_pred = gbdt.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
小结:
- 梯度提升树(Gradient Boosting Trees)是一种集成学习方法,通过迭代地构建多个决策树来逐步修正之前模型的错误,从而提升模型整体的预测性能。
- 负梯度是一个重要的概念,它用于指导每棵树的学习方向。具体来说,负梯度是损失函数在当前模型预测值处的导数的相反数。对于不同的损失函数,负梯度的计算方式会有所不同。
- GBDT算法的基本步骤包括初始化模型、迭代地添加新的决策树、拟合残差或负梯度、更新模型等。在每一步迭代中,GBDT通过拟合负梯度来训练新的决策树,然后将这些树组合起来更新模型,以减少总体损失。
- GBDT算法的停止条件通常是达到预设的最大迭代次数或者模型性能达到一定的阈值。当模型性能不再显著提升时,可以提前停止迭代,以避免过拟合和过度训练的问题。
XGBoost
🔊XGBoost,全称为eXtreme Gradient Boosting,是一种基于提升算法(Boosting)的机器学习算法,旨在通过组合多个弱分类器来生成一个强大的分类器。
与传统的梯度提升方法类似,XGBoost基于加法模型,通过不断地添加决策树来逐步优化模型的预测性能。每个新加入的树都致力于纠正之前所有树的累积误差。XGBoost定义了一个具有两个主要部分的目标函数。第一部分是衡量模型预测值与实际值之间差异的损失函数,第二部分则包括了控制模型复杂度的正则化项,以防止过拟合。正则化项由树的叶子节点数量和叶子节点分数的L2模组成,分别由超参数γ和λ控制。XGBoost使用的基学习器是CART(Classification and Regression Trees)回归树。在每一步迭代中,算法选择分裂特征和切分点以最大程度地降低目标函数的值。这种优化过程涉及到遍历所有可能的特征和切分点,以找到最佳的分裂方案。
- 基本原理与GBDT相同,属于Gradient Boosting 类型的机器学习算法,是对GBDT的优化
- 在训练每一棵树的时候GBDT采用了并行的方式进行训练,提高了模型训练速度
XGBoost 属于Boosting类集成学习模型, 要串行的训练多个模型逐步逼近降低损失,我们很难找到一个函数通过梯度下降的套路来解决这个问题。
- 与传统的梯度下降法只使用一阶导数信息不同,XGBoost采用了二阶导数的泰勒展开,这不仅使用了一阶导数,还利用了二阶导数信息,从而可以更精准地找到损失函数的最小值。
- XGBoost支持在每一轮提升迭代中进行交叉验证评估,方便用户实时监控模型的性能并进行调优。
sklearn的XGBoost使用参数
booster
- gbtree:使用树模型
- gblinear:使用线性模型
- dart:使用树模型
num_feature
- 在boosting中使用特征的维度,设置为特征的最大维度
案例
import joblib
import numpy as np
import xgboost as xgb
import pandas as pd
import numpy as np
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.model_selection import StratifiedKFold
def test01():
data = pd.read_csv('wine.csv')
x = data.iloc[:, :-1]
y = data.iloc[:, -1] - 3
x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.2, stratify=y, random_state=22)
# 存储数据
pd.concat([x_train, y_train], axis=1).to_csv('data-train.csv')
pd.concat([x_valid, y_valid], axis=1).to_csv('data-valid.csv')
# 模型训练
def test02():
train_data = pd.read_csv('data类-train.csv')
valid_data = pd.read_csv('data-valid.csv')
# 训练集
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
# 测试集
x_valid = valid_data.iloc[:, :-1]
y_valid = valid_data.iloc[:, -1]
estimator = xgb.XGBClassifier(n_estimators=100,
objective='multi:softmax',
eval_metric='merror',
eta=0.1,
use_label_encoder=False,
random_state=22)
estimator.fit(x_train, y_train)
y_pred = estimator.predict(x_valid)
print(classification_report(y_true=y_valid, y_pred=y_pred))
# 模型保存
joblib.dump(estimator, 'model/xgboost.pth')除了'multi:softmax',XGBoost中还有其他的objective损失函数参数选项。以下是一些常见的选项:
- 'binary:logistic':用于二分类问题,使用逻辑回归损失函数。
- 'reg:linear':用于回归问题,使用线性回归损失函数。
- 'reg:squarederror':用于回归问题,使用平方误差损失函数。
- 'reg:squaredlogerror':用于回归问题,使用平方对数误差损失函数。
- 'count:poisson':用于计数问题的泊松回归,使用泊松分布损失函数。
- 'rank:pairwise':用于排序问题,使用成对排序损失函数。
- 'rank:ndcg':用于排序问题,使用NDCG(Normalized Discounted Cumulative Gain)评估指标。
- 'rank:map':用于排序问题,使用MAP(Mean Average Precision)评估指标。
- 'survival:cox':用于生存分析问题,使用Cox比例风险模型。
- 'multi:softprob':用于多分类问题,输出每个类别的概率。
- 'multi:softmax':用于多分类问题,输出每个类别的预测结果。
模型参数调优
from sklearn.utils import class_weight
classes_weights = class_weight.compute_sample_weight(class_weight='balanced',y=y_train)
estimator.fit(x_train, y_train,sample_weight = classes_weights)
y_pred = estimator.predict(x_valid)
print(classification_report(y_true=y_valid, y_pred=y_pred))
# 交叉验证网格搜索
train_data = pd.read_csv('data-train.csv')
valid_data = pd.read_csv('data-valid.csv')
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_valid = valid_data.iloc[:, :-1]
y_valid = valid_data.iloc[:, -1]
spliter = StratifiedKFold(n_splits=5, shuffle=True)
param_grid = {'max_depth': np.arange(3, 5, 1),
'n_estimators': np.arange(50, 150, 50),
'eta': np.arange(0.1, 1, 0.3)}
estimator = xgb.XGBClassifier(n_estimators=100,
objective='multi:softmax',
eval_metric='merror',
eta=0.1,
use_label_encoder=False,
random_state=22)
cv = GridSearchCV(estimator,param_grid,cv=spliter)
y_pred = cv.predict(x_valid)
print(classification_report(y_true=y_valid, y_pred=y_pred))使用网格搜索(GridSearchCV)来优化XGBoost模型的超参数。首先定义了一个参数网格(param_grid),包含了三个超参数:max_depth(树的最大深度)、n_estimators(弱学习器的数量)和eta(学习率)。然后使用GridSearchCV进行交叉验证,最后对验证集进行预测。
📀 classification_report 是一个用于评估分类模型性能的函数,它可以计算并显示主要的分类指标,如准确率、召回率、F1分数等。StratifiedKFold 是一个用于分层抽样的交叉验证方法,它确保每个折叠中类别的比例与整个数据集中的比例相同。
from sklearn.metrics import classification_report
from sklearn.model_selection import StratifiedKFold
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
# 加载数据集
data = load_iris()
X, y = data.data, data.target
# 创建分层抽样的交叉验证对象
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# 初始化分类器
clf = LogisticRegression()
# 存储预测结果和真实标签
y_true = []
y_pred = []
# 进行交叉验证
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred_test = clf.predict(X_test)
# 更新预测结果和真实标签
y_true.extend(y_test)
y_pred.extend(y_pred_test)
# 输出分类报告
print(classification_report(y_true, y_pred))🏷️关于交叉验证的参数问题
spliter 是一个用于数据分割的参数,它指定了交叉验证的策略。在 GridSearchCV 中,cv 参数用于控制交叉验证的折数或具体的交叉验证策略。
如果 cv 是一个整数,那么它将表示进行多少折交叉验证。例如,cv=5 表示将数据集分成 5 份,然后进行 5-fold 交叉验证。每次迭代时,其中一份数据作为测试集,其余的数据作为训练集。
如果 cv 是一个交叉验证对象(如 KFold、StratifiedKFold 等),那么它将直接指定交叉验证的策略。这些对象可以根据特定的需求对数据进行分割,例如按照一定比例划分训练集和测试集,或者根据类别的比例进行分层抽样。