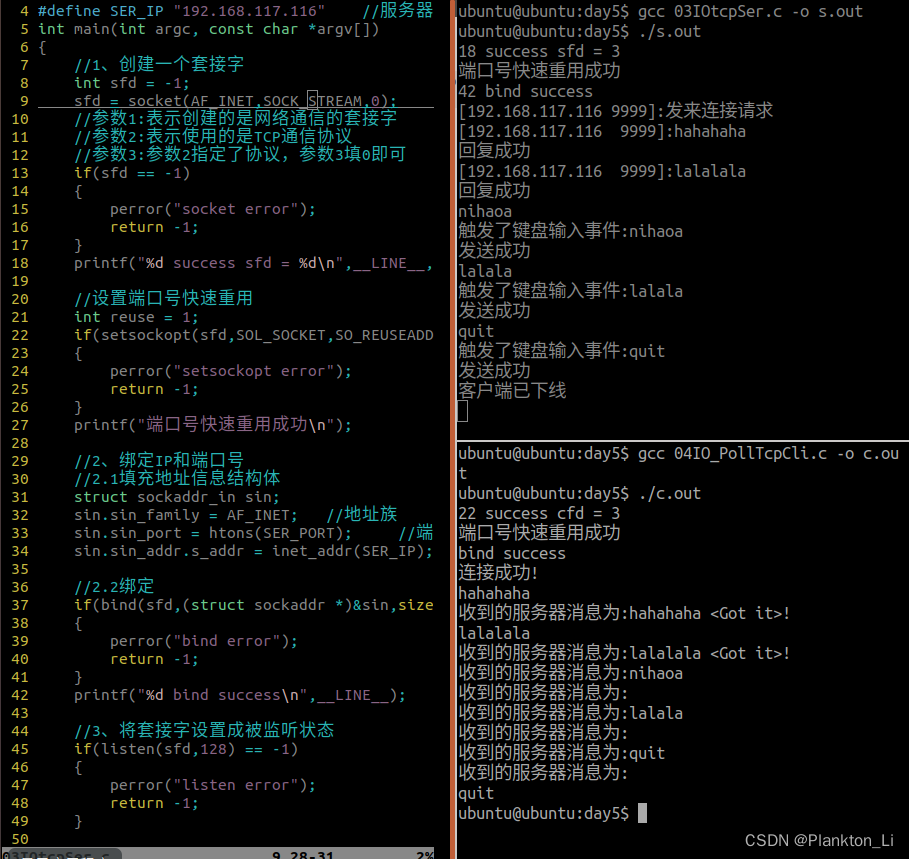
实时威胁检测可实时监控和分析数据,并及时对潜在的安全威胁作出识别和响应。与依赖定期扫描或回顾性分析的安全措施不同,实时威胁检测系统可提供即时警报,并启动自动响应来降低风险,而不会出现高延迟。
实时威胁检测有许多不同的用例,例如识别和阻止分布式拒绝服务(DDoS,Distributed Denial-of-Service)攻击、通过日志分析检测威胁以及基于常见漏洞和暴露(CVE,Common Vulnerabilities and Exposures)的分析和实时报告。
本文将介绍如何使用 RisingWave 和 Kafka 构建一个能够实时识别网络威胁的监控解决方案。
什么是实时威胁检测?
实时威胁检测采用事件驱动架构和流分析的组合来实现。不同来源的数据(如网络流量、系统日志和应用程序活动)会被持续收集和处理。通常会通过 Kafka 等平台对这些数据进行实时流处理,从而高效摄取大量数据。在此过程中,复杂的算法和机器学习模型可以对数据流进行分析,寻找可能预示着潜在威胁的模式和异常情况。一旦检测到可疑活动,系统会向管理员发出警报,并触发自动安全协议以减轻潜在威胁。在数字化不断发展的今天,威胁的迅速演变可能导致严重损失,而实时威胁检测则可提供高级保护。
实时威胁检测可以识别和阻止 DDoS 攻击。DDoS 攻击指用大量流量淹没网络或服务,破坏其稳定性,使其无法为目标用户提供服务。实时威胁检测系统可以识别攻击的早期迹象,如接收到来自通常没有用户的位置的流量,或者流量突然激增且远高于正常水平。这能够让您迅速采取应对措施,防止或尽量减少中断。
您可以使用实时威胁检测来分析审计日志等项目,这些日志是关于系统或网络活动的丰富信息源。实时威胁检测工具会在日志生成时对其进行分析,并识别任何可能表明存在安全漏洞或恶意活动的异常或可疑行为。
实时威胁检测还可以持续监控 CVE 数据库中新发布的内容,该数据库是公开的网络安全漏洞列表。当新的 CVE 发布时,系统可以分析并确定该漏洞会如何影响组织的数字资产,如通过启用未经授权的访问、数据盗窃或服务中断。根据威胁的类型,系统还可以触发自动响应,如隔离受影响的系统、应用安全更新或向网络安全团队发送警报。
利用 RisingWave 构建实时威胁检测系统
假设您所在的电商公司会产生大量的网络流量和服务器日志数据,这些数据包括时间戳、IP 地址、用户名、操作、资源和状态代码等信息。公司希望您利用 RisingWave 构建一个威胁检测系统,通过观察服务器日志数据中的异常模式或活动来识别潜在的网络威胁。
威胁检测系统由几个不同的部分组成。首先需要建立一个流平台来实现实时数据管道。您可以选择擅长处理大量数据的 Kafka。将服务器日志数据导入名为 log_data 的 Kafka Topic,该 Topic 由 Docker 容器管理,并将成为 RisingWave 的主要数据源。
随后,您需要设置 RisingWave 以连接到该 Topic。在 RisingWave 中应用特定的 SQL 查询,以识别服务器日志数据中可能表明存在潜在网络威胁的条目。已识别的数据记录将被发送回另一个名为 anomalies 的 Kafka Topic。

此架构图描述了应用程序的工作原理
开始之前
本教程要求具备以下条件:
- 已创建并激活 Python 虚拟环境。所有与 Python 相关的命令都应在此环境中运行。
- Python 3.11 或更高版本。
- 计算机已安装最新版本的 Docker(本教程使用 Docker 24.0.6)。
- 在 Docker 上运行的 Kafka 实例。Apache Kafka 是一个分布式事件流平台,您需要运行一个实例来处理数据流。
- Postgres 交互终端 psql。
生成数据集
本章节将为日志分析用例生成一个合成数据集。要生成数据,请在主目录下创建一个名为 generate_data.py 的文件,并将以下代码粘贴到该文件中:
import json
import random
from datetime import datetime
def generate_synthetic_log_entry():
# 定义一组虚假 IP 地址来模拟网络流量
ip_addresses = ["192.168.1.{}".format(i) for i in range(1, 101)]
# 定义一组用户名
users = ["user{}".format(i) for i in range(1, 21)]
# 定义一组操作
actions = ["login", "logout", "access", "modify", "delete"]
# 定义一组资源
resources = ["/api/data", "/api/user", "/api/admin", "/api/settings", "/api/info"]
# 定义一组状态代码
status_codes = [200, 301, 400, 401, 404, 500]
# 生成随机日志条目
log_entry = {
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"ip_address": random.choice(ip_addresses),
"user": random.choice(users),
"action": random.choice(actions),
"resource": random.choice(resources),
"status_code": random.choice(status_codes)
}
return log_entry
# 保存合成日志条目的 JSON 格式文件
json_file_path = 'synthetic_log_data.json'
# 生成并保存合成日志条目
with open(json_file_path, 'w') as file:
for _ in range(100):
log_entry = generate_synthetic_log_entry()
file.write(json.dumps(log_entry) + '\n') # 将每个 JSON 对象写成一行
json_file_path
该脚本会生成带有时间戳、IP 地址、用户名、操作、资源和状态代码的合成日志条目。这些条目可模拟服务器或应用程序日志文件中的典型日志。数据将保存为名为 synthetic_log_data.json 的 JSON 文件。
要执行脚本并生成数据,请在主目录中打开终端,并在事先创建的虚拟环境中运行以下命令:
python generate_data.py
数据集生成后,生成的 synthetic_log_data.json 文件的前几行应该类似如下:
{"timestamp": "2023-12-15 14:04:38", "ip_address": "192.168.1.41", "user": "user14", "action": "login", "resource": "/api/user", "status_code": 401}
{"timestamp": "2023-12-15 14:04:38", "ip_address": "192.168.1.71", "user": "user19", "action": "modify", "resource": "/api/user", "status_code": 200}
{"timestamp": "2023-12-15 14:04:38", "ip_address": "192.168.1.48", "user": "user7", "action": "logout", "resource": "/api/admin", "status_code": 401}
在 Docker 中安装 RisingWave
您将在 Docker 容器中运行 RisingWave。使用 Docker 安装 RisingWave 非常简单,Docker 可对 RisingWave 环境进行容器化,从而简化安装过程,使其更易于管理并与其他系统依赖项隔离。要安装 RisingWave,请打开终端或命令提示符,并使用以下 Docker 命令获取最新的 RisingWave Docker 镜像:
docker run -it --pull=always -p 4566:4566 -p 5691:5691 risingwavelabs/risingwave:latest playground
拉取镜像并启动和运行 RisingWave 后,可以通过 Postgres 交互终端 psql 与其进行连接。请打开一个新的终端窗口并运行以下命令:
psql -h localhost -p 4566 -d dev -U root
如果连接成功,会看到类似以下的输出:
psql (14.10 (Ubuntu 14.10-0ubuntu0.22.04.1), server 9.5.0)
Type "help" for help.
dev=>
创建 Kafka Topic
本章节将创建两个 Kafka Topic:log_data 和 anomalies。log_data 是流数据的 Source。稍后您将使用 anomalies 作为 Sink,接收 RisingWave 处理过的数据。要创建这两个 Topic,请在终端中执行以下命令:
docker exec container_name kafka-topics.sh --create --topic topic_name --partitions 1 --replication-factor 1 --bootstrap-server kafka:9092
在此命令中,container_name 应替换为运行 Kafka 的 Docker 容器的名称。执行命令时,相应地将 topic_name 更改为 log_data 或 anomalies。
要验证是否已成功创建 Topic,请在终端中执行以下命令:
docker exec container_name kafka-topics.sh --list --bootstrap-server kafka:9092
结果应如下所示:
anomalies
log_data
此输出表明您已成功创建 Topic log_data 和 anomalies。
连接 RisingWave 和 Kafka
现在您需要创建 Source。Source 是 RisingWave 从中摄取数据并进行处理的外部数据流或存储系统,是 RisingWave 架构的基本组件。Source 是数据的入口,定义了如何从 RisingWave 摄取外部系统的数据。在本例中,Source 即为先前创建的 Kafka Topic log_data。
在主目录下创建新 Python 文件 create_data_source.py,并粘贴以下代码:
import psycopg2
conn = psycopg2.connect(host="localhost", port=4566, user="root", dbname="dev")
conn.autocommit = True # 设置自动提交查询
with conn.cursor() as cur:
cur.execute("""
CREATE SOURCE IF NOT EXISTS log_data2 (
timestamp varchar,
ip_address varchar,
user varchar,
action varchar,
resource varchar,
status_code varchar
)
WITH (
connector='kafka',
topic='log_data',
properties.bootstrap.server='localhost:9093',
scan.startup.mode='earliest'
) FORMAT PLAIN ENCODE JSON;""") # 执行查询
conn.close() # 关闭连接
该脚本使用 Python 的 PostgreSQL 数据库适配器 psycopg2 连接 RisingWave 和之前创建的 Kafka Topic log_data 。其核心是一条 SQL 命令,用于在 RisingWave 中创建名为 log_data 的新数据源。该 Source 设计用于从 Kafka Topic 摄取数据。数据结构包括从创建的合成数据集中获取的字段。
执行脚本 create_data_source.py 将创建 Source。但首先需要安装 Psycopg,这是一款流行且适用于 Python 编程语言的 PostgreSQL 数据库适配器。要安装二进制文件,请按照说明进行操作。
安装完二进制文件后,在主目录中打开终端,并在事先创建的虚拟环境中使用以下命令执行脚本:
python create_data_source.py
向 Kafka Topic 生产数据
您还需要创建一个脚本,从 synthetic_log_data.json 中读取日志数据,并将其生产到 Kafka Topic log_data 中。但必须先安装 Confluent Kafka-Python 库(本教程使用 2.2.0 版本),该库可提供所需的 Consumer 和 Producer 类。您需要在事先创建的 Python 虚拟环境中安装该库。要安装该库,请打开终端并在已激活的虚拟环境中执行以下命令:
pip install confluent-kafka
然后,在主目录下创建名为 produce.py 的 Python 文件,并粘贴以下代码:
import json
from confluent_kafka import Producer
# 连接到 Kafka 的配置
config = {
'bootstrap.servers': 'localhost:9093', # 替换为你的 Kafka 服务器地址
}
# 创建一个 Producer 实例
producer = Producer(config)
# 要生产到的 Topic
topic_name = 'log_data'
# 检查消息传递是否成功的回调函数
def delivery_report(err, msg):
if err is not None:
print(f'Message delivery failed: {err}')
else:
print(f'Message delivered to {msg.topic()} [{msg.partition()}]')
# 生产消息的函数
def produce_message(data):
# 从之前的 produce() 调用中触发任何可用的送达报告回调函数
producer.poll(0)
# 异步生产消息;一旦消息生产成功或失败,就会触发送达报告回调函数
producer.produce(topic=topic_name, value=json.dumps(data), callback=delivery_report)
# 从数据文件中生产消息
def produce_data_from_file(file_path):
with open(file_path, 'r') as file:
for line in file:
record = json.loads(line.strip())
produce_message(record)
# 等待未完成的消息被传递并触发送达报告回调
producer.flush()
# 数据文件的路径
file_path = 'synthetic_log_data.json' # 替换为实际文件路径
# 开始向 Kafka Topic 生产数据
produce_data_from_file(file_path)
该 Python 脚本可设置一个 Kafka Producer,用于将消息发送到 Kafka Topic log_data。首先,它使用必要的服务器地址配置 Kafka Producer。核心功能在于 produce_message 函数,该函数异步地将消息发送到指定的 Kafka Topic。produce_data_from_file 从 synthetic_log_data.json 中读取数据,将每一行处理为一个 JSON 对象,并将这些对象作为消息发送到 Kafka Topic。
要执行脚本,请在主目录中打开终端,并在虚拟环境中运行以下命令:
python log_data_producer.py
如果数据成功发送到 Kafka Topic,则终端中的输出应该如下所示:
Message delivered to log_data [0]
…output omitted…
Message delivered to log_data [0
使用 RisingWave 进行威胁检测
在这一部分,您将转换和处理用于威胁检测的源数据。具体来说,您将定义一个 SQL 查询,使用 RisingWave 的物化视图从 Kafka Source log_data 中过滤出可能表明存在网络安全威胁的日志数据。物化视图是一种数据库对象,用于存储查询结果,以便高效检索数据。与在查询时动态生成结果的标准视图不同,物化视图会预先计算并保存查询结果。这一功能与 RisingWave 的实时分析和流处理功能相辅相成,因为它允许快速访问经常查询的数据。这对于流数据的复杂聚合或计算非常有用。
要生成用于网络威胁检测的物化视图,请在主目录下创建名为 create_mv.py 的 Python 文件,并粘贴以下代码:
import psycopg2
conn = psycopg2.connect(host="localhost", port=4566, user="root", dbname="dev")
conn.autocommit = True # 设置自动提交查询
with conn.cursor() as cur:
cur.execute("""
CREATE MATERIALIZED VIEW anomaly_detection_by_error_status AS
SELECT
ip_address,
COUNT(*) AS error_count
FROM
log_data
WHERE
status_code::integer >= 400
GROUP BY
ip_address
HAVING
COUNT(*) > 3; -- Threshold for error occurrences
""") # 执行查询
conn.close() # 关闭连接
该脚本中的物化视图 anomaly_detection_by_error_status 会选择具有高频错误状态代码的 IP 地址,这些错误状态代码可能表明存在网络威胁。具体来说,查询会从 log_data Topic 中过滤出 status_code 表明存在错误的数据(400 及以上)。然后,该查询会统计每个 ip_address 出现错误的次数。使用 HAVING 子句筛选出物化视图中错误发生次数大于 3 的 IP 地址。
要创建此物化视图,请打开终端并在虚拟环境中使用以下命令执行脚本:
python create_mv.py
如前所述,物化视图存储查询结果。为了访问结果并将其打印在控制台中,请创建一个名为 show_result.py 的 Python 文件,并粘贴以下代码:
import psycopg2
conn = psycopg2.connect(host="localhost", port=4566, user="root", dbname="dev")
conn.autocommit = True
with conn.cursor() as cur:
cur.execute("""
SELECT * FROM anomaly_detection_by_error_status; """) # 执行查询
# 从执行的查询中获取所有行
rows = cur.fetchall()
# 遍历行并打印每一行
for row in rows:
print(row)
conn.close()
像之前一样,在虚拟环境的终端中使用以下命令运行脚本:
python show_result.py
查询结果将在终端中打印出来,应该可以看到类似于这样的输出:
('192.168.1.43', 4) ('192.168.1.55', 4) ('192.168.1.59', 4) ('192.168.1.52', 4) ('192.168.1.33', 5) ('192.168.1.62', 4) ('192.168.1.60', 5) ('192.168.1.94', 6)
输出显示了 Kafka Source log_data 中的每个 IP 地址,以及该特定 IP 地址出现错误代码的次数。这可能表明这些特定 IP 地址发起了网络攻击。
将数据发送回 Kafka
在 RisingWave 中,Sink 是在其流处理系统中处理的数据端点,可向其发送经过实时分析和计算后的最终输出。它可以是数据库、文件系统或其他数据管理系统。在本用例中,先前创建的 Kafka Topic anomalies 将作为 Sink,您将向其发送被识别为潜在网络威胁的日志数据。
要设置 Sink,请创建名为 sink.py 的文件,并粘贴以下 Python 脚本:
import psycopg2
conn = psycopg2.connect(host="localhost", port=4566, user="root", dbname="dev")
conn.autocommit = True
with conn.cursor() as cur:
cur.execute("""
CREATE SINK send_data_to_kafka FROM anomaly_detection_by_error_status
WITH (
connector='kafka',
properties.bootstrap.server='localhost:9093',
topic='anomalies'
) FORMAT PLAIN ENCODE JSON (
force_append_only='true',
);""") # 执行查询
conn.close()
该 Python 脚本可连接到 RisingWave 并执行 SQL 命令,创建名为 send_data_too_kafka 的 Kafka Sink。该 Sink 经过配置,可从先前创建的 RisingWave 视图 anomaly_detection_by_error_status 向 Kafka Topic anomalies 发送数据。可以在终端中使用以下命令运行脚本:
python sink.py
您可以在终端中执行以下命令,验证数据是否已从 RisingWave 成功发送到指定的 Kafka Topic anomalies:
docker exec -it kafka bash
执行此命令,即可访问正在运行的容器 kafka 的 Bash Shell。这样就可以直接与容器内的 Kafka 环境交互。在容器内执行此命令:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic anomalies --from-beginning
执行此命令,即可在终端中列出 Topic anomalies 中的所有数据。输出结果应该类似于这样:
{"error_count":6,"ip_address":"192.168.1.94"} {"error_count":4,"ip_address":"192.168.1.52"} {"error_count":5,"ip_address":"192.168.1.60"} {"error_count":5,"ip_address":"192.168.1.33"} {"error_count":4,"ip_address":"192.168.1.55"} {"error_count":4,"ip_address":"192.168.1.59"} {"error_count":4,"ip_address":"192.168.1.43"} {"error_count":4,"ip_address":"192.168.1.62"}
如您所见,被识别为潜在威胁的数据已成功从 RisingWave 发送到 Kafka Topic anomalies。
简化用于威胁响应的监控和警报管道
识别潜在网络威胁后,还需要建立适当的监控和警报管道。您可以将包含潜在威胁数据的 Kafka Topic anomalies 与监控工具集成。集成会涉及在 Kafka Topic 和监控工具之间建立连接,以便工具能够持续接收和分析来自 Topic 的数据。
以上可以通过数据管道或允许监控工具订阅 Kafka Topic 的 API 实现。连接后,监控工具将开始接收来自 anomalies Topic 的数据流,并检查传入的数据,以估计威胁的严重程度。根据预先制定的标准,该工具可将威胁分为不同的安全类别,并根据类别确定响应的优先级。例如,如果在一个正常情况下不应该有太多网络流量的地方,发现了来自同一 Source 的多次登录失败尝试,就可能会将其标记为更为严重的网络威胁。相反,监控工具可能将在正常工作时间之外对一个低敏感度内部应用程序进行的一系列成功登录视为较轻微的网络威胁。
监控工具将威胁划分为不同类别后,就需要实施自动警报系统。当发现潜在的高严重性威胁时,警报系统可立即通知网络安全团队。警报可根据具体情况定制,包括有关威胁的信息,如其来源、类型和潜在影响。这些信息能够帮助安全团队快速评估威胁并确定应对措施的优先级。
结论
本教程介绍了如何使用 RisingWave 和 Kafka 构建实时威胁检测系统。使用 RisingWave 和 Kafka 分别进行流处理和数据传输,可为实时威胁检测提供强大的基础设施。通过在 RisingWave 中创建物化视图,可以高效查询和分析流数据,而 Kafka 则确保了系统不同组件之间的可靠数据传输。
如果有兴趣深入了解,可从该 GitHub 仓库获取本教程的完整代码,查看所有必要的脚本和配置。
RisingWave 是一款基于 Apache 2.0 协议开源的分布式流数据库,致力于为用户提供极致简单、高效的流数据处理与管理能力。RisingWave 采用存算分离架构,实现了高效的复杂查询、瞬时动态扩缩容以及快速故障恢复,并助力用户极大地简化流计算架构,轻松搭建稳定且高效的流计算应用。RisingWave 始终聆听来自社区的声音,并积极回应用户的反馈。目前,RisingWave 已汇聚了近 150 名开源贡献者和近 3000 名社区成员。全球范围内,已有上百个 RisingWave 集群在生产环境中部署。
了解更多:
官网: risingwave.com
入门教程:快速上手 | RisingWave
GitHub:risingwave.com/github
微信公众号:RisingWave中文开源社区
中文社区用户交流群:risingwave_assistant
英文社区用户交流群:https://risingwave.com/slack