简介
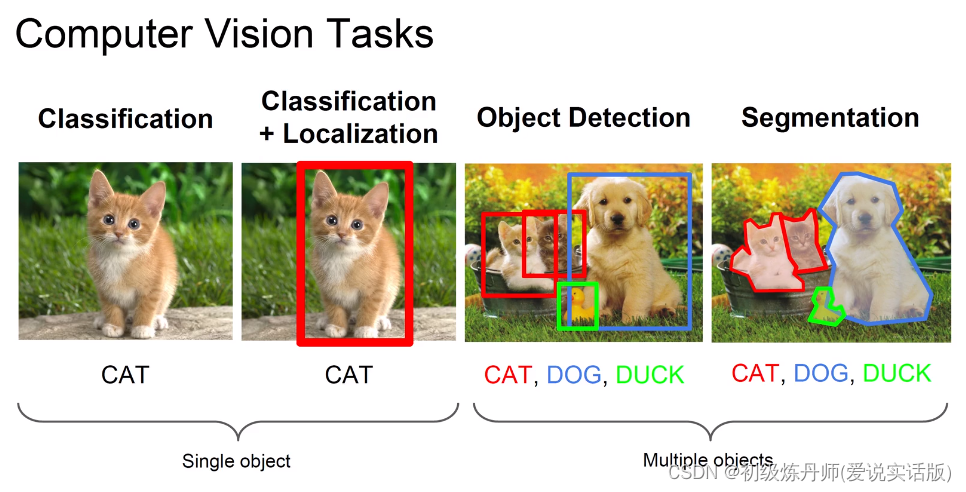 计算机视觉领域包含很多不同的方向,从处理数据的类型上分为图片,视频,点云,在2D图像的任务中再细分就分为单目标任务和多目标任务(如上图)YOLO是用于解决多目标检测问题的计算机视觉算法,相比于多阶段的目标检测算法,YOLO(单阶段目标检测方法)一经问世就以其简单高效果的特点备受关注,至今已经发展到yolov9,下面将对yolov1-v9进行梳理.
计算机视觉领域包含很多不同的方向,从处理数据的类型上分为图片,视频,点云,在2D图像的任务中再细分就分为单目标任务和多目标任务(如上图)YOLO是用于解决多目标检测问题的计算机视觉算法,相比于多阶段的目标检测算法,YOLO(单阶段目标检测方法)一经问世就以其简单高效果的特点备受关注,至今已经发展到yolov9,下面将对yolov1-v9进行梳理.
(由于本人不专门研究Object detect领域,如有错误请您指出)
(内容来自B站:同济子豪兄)
(特别鸣谢:同济子豪兄)
Object Detection前情概述

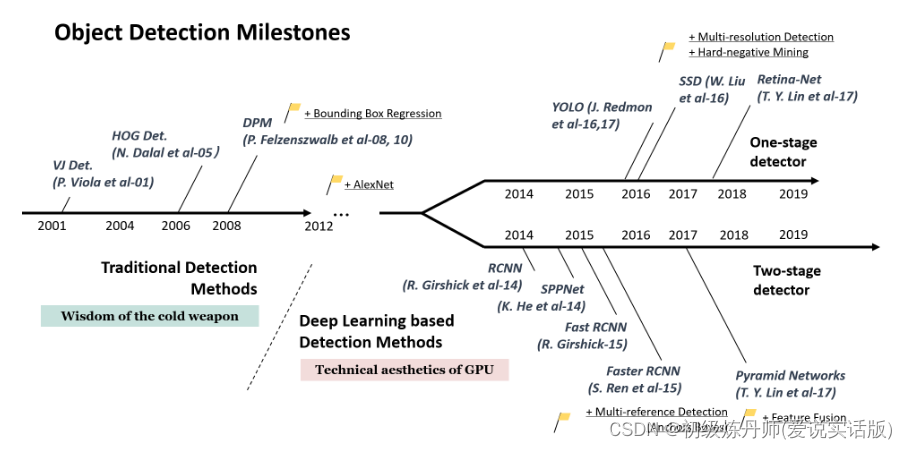
DPM,人工特征+滑动窗口

R-CNN:先提取2000个候选框(Region of interest)这个过程称为region proposal,再把2000个候选框送入CNN进行甄别,最终再经过SVM和Boundbox regression进行分类或回归,最终得到结果(2000个候选框每个都要处理一遍,要经过40s才能处理一张图片)

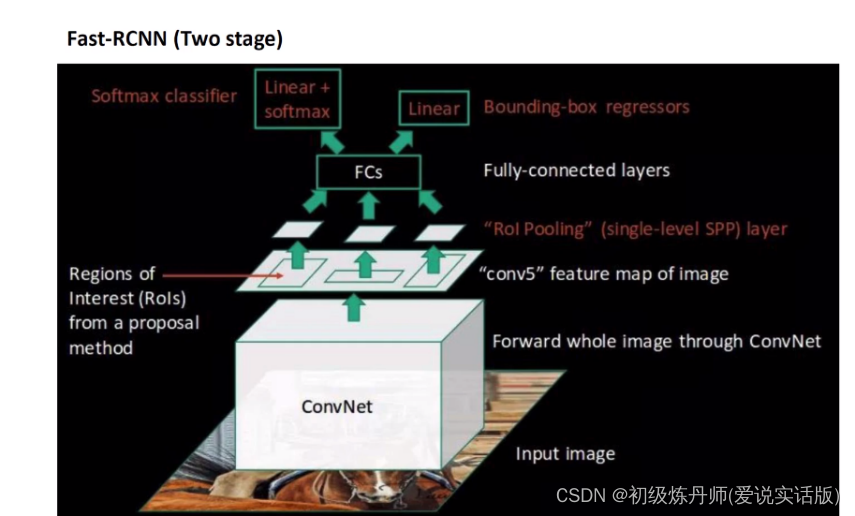
Fast-RCNN 先不着急提取候选框,先把整个图像喂到一个CNN里面,获得一个共享的特征,所有的候选框都共享这一套特征,这样可以加快一些速度
到后来还有Faster-RCNN用一个单独的RPN网络来挑选候选框..
总结
两阶段:优点:1、准确 (候选框多,效果自然好一些)
缺点: 1、慢 2、候选框太小不能看到整个图像的全景(管中窥豹)(会丢失信息:背景|背景和前景之间的关系|不同物体之间的关系|全图的关系)
单阶段:Yolo:优点:速度快,不需要复杂的上下游产业链的协同,也不需要对每一个工序单独的训练和优化,是一个,端到端,完整统一的框架
缺点:但准确率不高,对小目标和密集目标识别效果不好(当然这是以前的说法了)
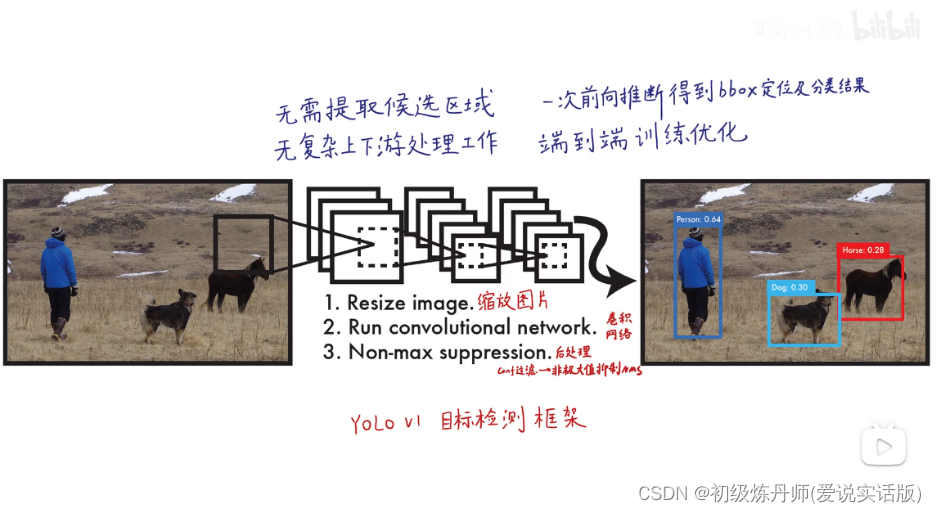
YOLOV1(CVPR2016)
backbone
先缩放到448*448*3的图像(裁剪+rgb)经过一顿处理变成了一个7*7*1024大小的feature map,经过一个(7*7*1024(拉平),4096)的线性层得到4096维的向量,再过一个(4096,1470)的线性层,得到一个1470维度的向量,把该向量reshape成7*7*30的特征图

Yolo测试过程(正向推断过程)

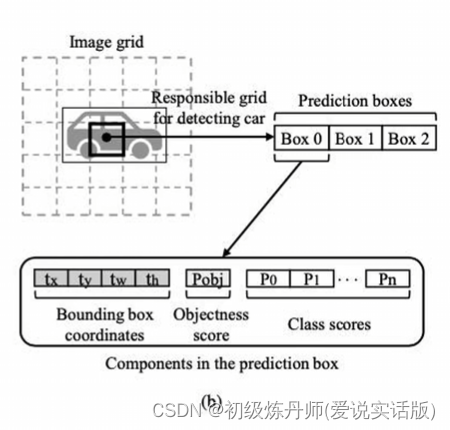
yoloV1先把图像划分成S*S(7*7)的网格(gridcell),每个gridcell预测出b个boundbox(预测框)(b=2),两个预测框地中心点落在gridsell里边,,(无论预测框的形状只要bbox的中心点落在gridcell里就说明这个bbox是由这个gridcell生成的)
所以共生成了98个bbox,每个bbox都包含四个位置参数和一个置信度参数(包含物体的概率)(x,y,w,h,c)(黑框,框的粗细代表置信度的大小)
每个网格还能生成所有类别的条件概率(假设包含某个物体的前提下是某一个类别的概率)(彩图)
将每个bbox的置信度乘以其对应的gridcell的条件概率,就能得到每个bbox是各类别的概率
结合bbox和gridcell的信息就可以获得最终的预测结果了
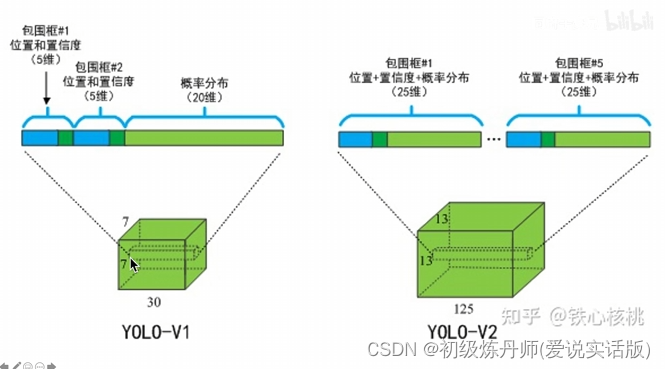
这些信息都是从那个7*7*30维的向量中获取的(S*S*(5*B+C))
7*7*30特征解读(包含所有预测框的坐标,置信度,类别结果)
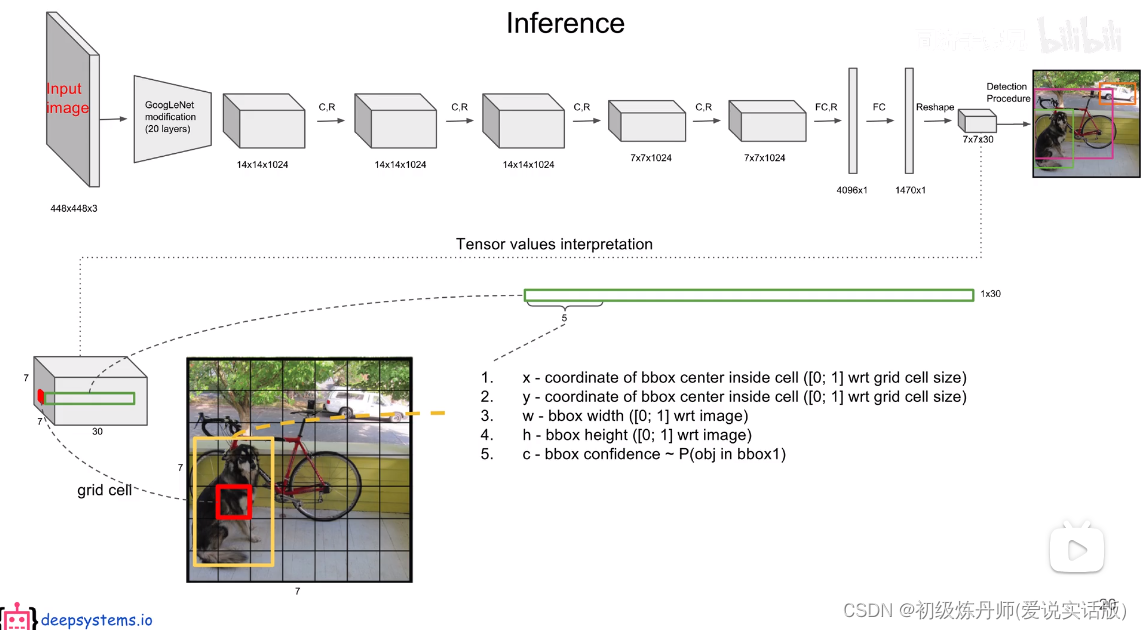
每个gridcell是30个数 组成是5+5+20,两个五表示两个预测框,20表示条件概率(在PASCOL中有20个类别)
30维的向量是一个gridcell的信息,一共7*7个gridcell就是7*7个30

输入一张图像,Yolo能输出S*S个gridcell的信息,每个gridcell包含两个bbox和20个条件概率的信息,每个bbox又包含5个参数(4个位置参数和一个置信度参数)

yolov1的缺点,49个预测框最多预测49个物体,小目标和密集目标效果差的原因

中间这个图经过一系列后处理得到最终的预测结果。
Yolo的后处理
(只有预测阶段需要后处理,训练阶段不需要后处理,训练阶段每个框都要算损失):低置信度的框过滤掉&重复的框过滤掉(NMS)

先看狗这个类别的,设阈值——>置0——>排序——>NMS(去重)
NMS(取框比IOU和IOU阈值,超过阈值,保留概率大的框,概率较低的框被认为是重复框将其概率置0,低于阈值的都保留,每一个框都和所有概率小于自己的框比IOU阈值,跳过概率为0的框)

最后不为0的类别拎出来分拎出来就是最后的结果

Yolo训练过程(反向传播)
损失函数如下(第二行中的根号的作用是使得误差对小框更敏感,对大框更不敏感,起到一种均衡的作用)

YOLOV1缺点:
1、map准确度低
2、定位性能也比较差,
3、recall也比较低(把全部目标全部检出的能力比较差)因为7*7=49个gridcell每个gridcell最多预测出一个物体,所以49个gridcell最多预测出49个物体
4、预测小目标和密集目标效果差,因为7*7=49个gridcell每个gridcell最多预测出一个物体,所以49个gridcell最多预测出49个物体
YOLOV2(YOLO9000:Better,Faster,Stronger)(CVPR2017)
简介
better:比V1性能提升。准确率高
Faster:比V1更快
Strong:V2能检测9000多种类别
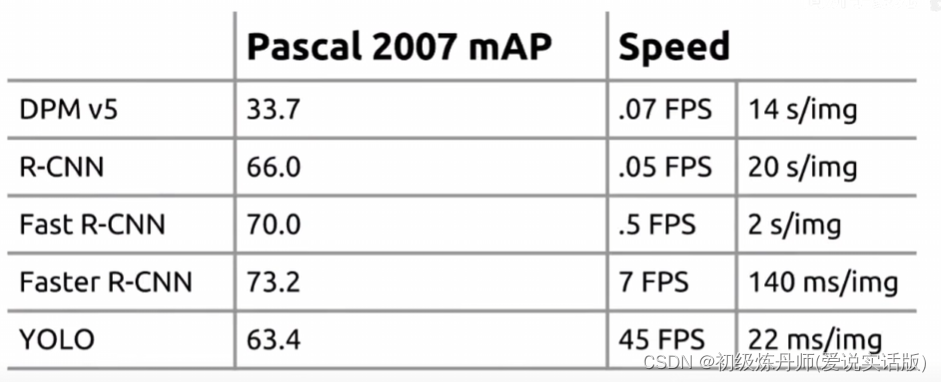
YOLOV2对YOLOV1做出了改进
Better

1、BN
BN层作用:防止梯度消失或者梯度爆炸,加快收敛
BN层原理(激活函数是tanh):

BN层方法:

BN层一般在线性层后在激活层前

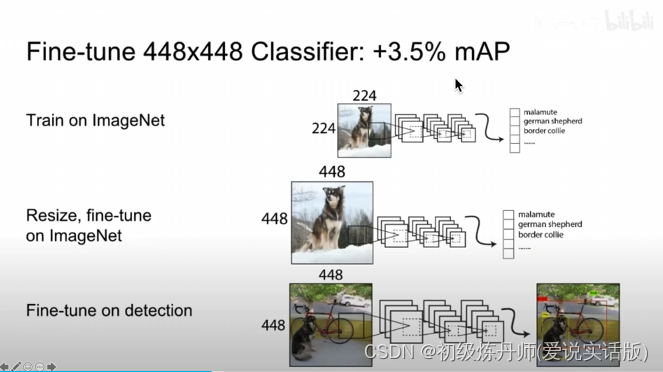
2、高分辨率判别器
迁移学习(图片大小不匹配导致性能降低)
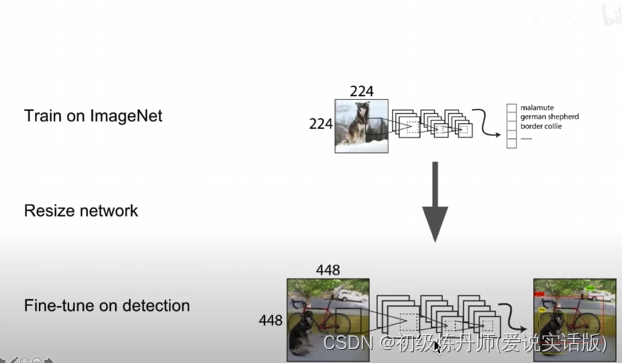
高分辨率判别器 目的是适应大分辨率的输入 直接在高分辨率图像上训练 弥补不同尺寸图像之间的gap
3、Anchor(V2-V5)
什么是Anchor?
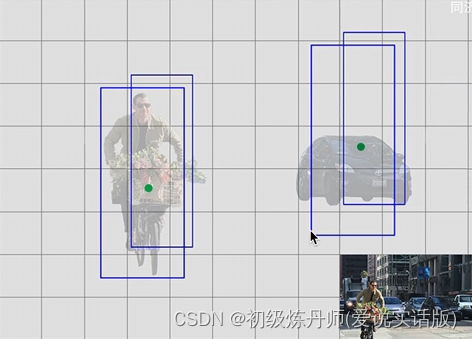
给bbox一个先验的形状,每个bbox的长宽不再是野蛮生长的,而是具有一定的高宽比(长得矮胖,或者瘦高)会使模型训练更加稳定(有固定的形状匹配,而不是谁与groundtruth的IOU大谁来匹配),每一个预测框只需要预测出它相较于anchor的偏移量就可以了(预测偏移量比从头那样瞎套要简单得多)
YoloV2的将每张图片划分成(S*S个gridcell,S=13,每个gridcell预测5个anchor,事先制定了五种长宽,大小,尺度不同的先验框,每个anchor都对应一个预测框,预测框只需要取预测它相对于anchor的偏移量就可以了)
feature map的长宽应该设置成奇数
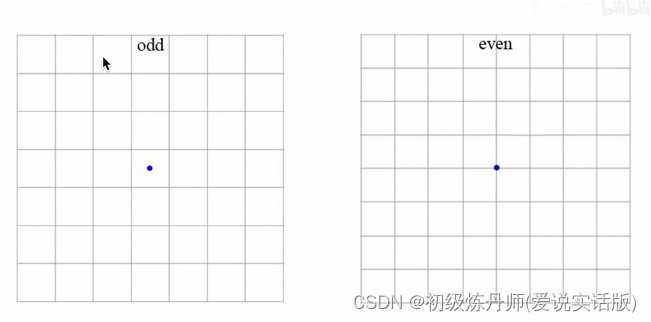
否侧中心实体就要被最靠近中心得四个gridcell争抢
模型输出得结构
类别归anchor管了,一个gridcell产生125个数(5个anchor,每个anchor25个数字)
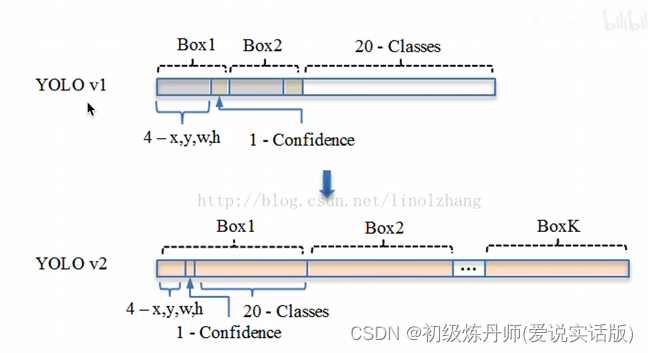
这个图更加直观
损失函数

4、Dimension Clusters

聚类确定anchor长宽比(K-means)

5、Direct location prediction
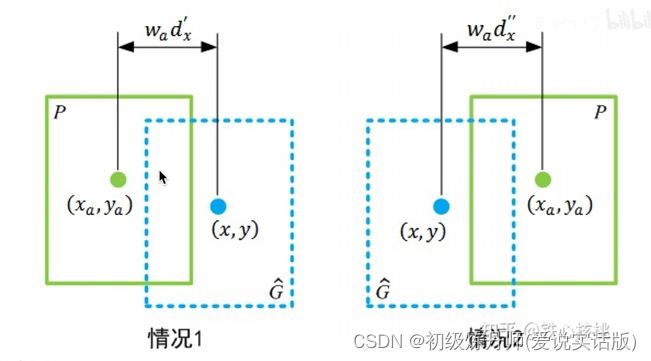
要限制预测框的位置,防止预测框乱窜
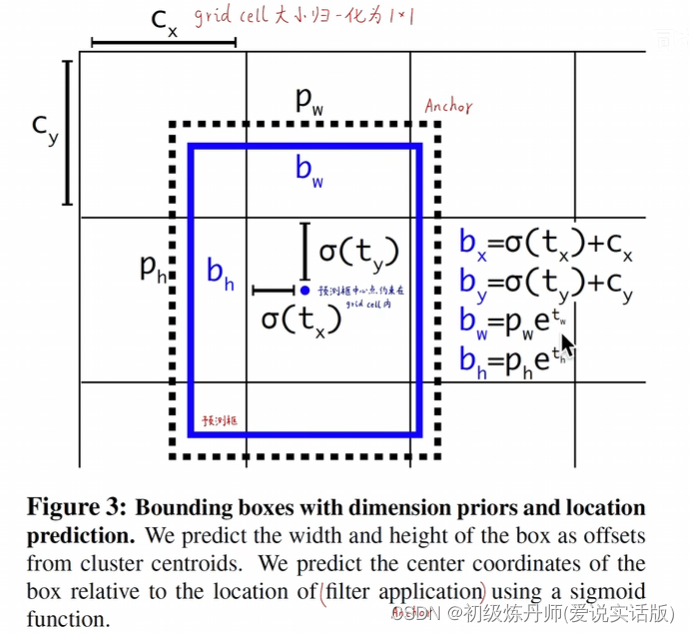
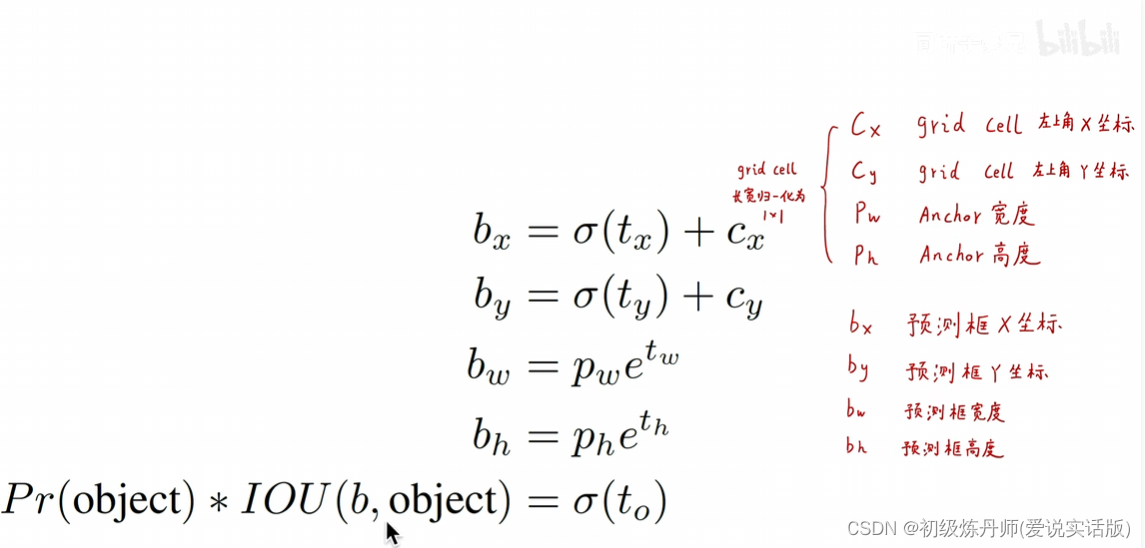
6、Fine-Grained Features
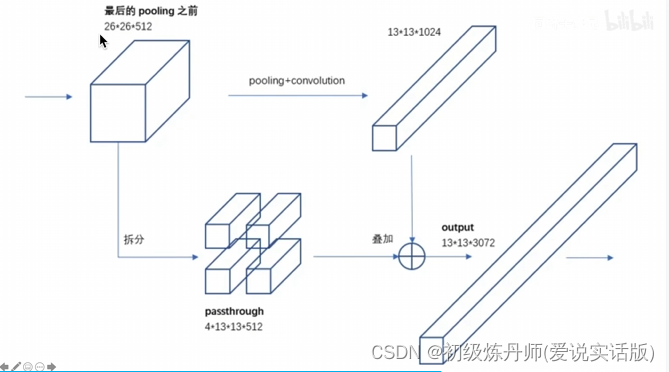
整合不同尺度得特征,有利于小目标的目标检测
7、Multi-Scale Training

能这么做的原因是有global average pooling而不是用的FNN
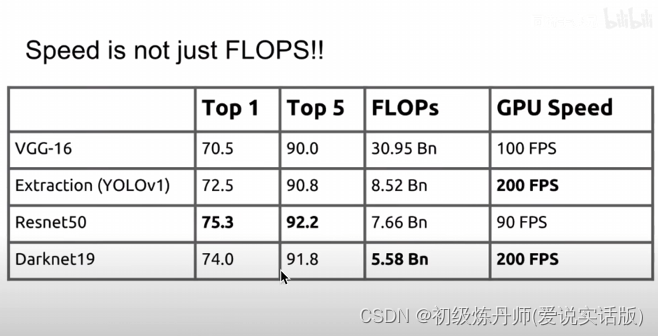
这么做可以在速度和精度之间做权衡

同准确度速度最快,同速度准确度最高
Faster(更快)
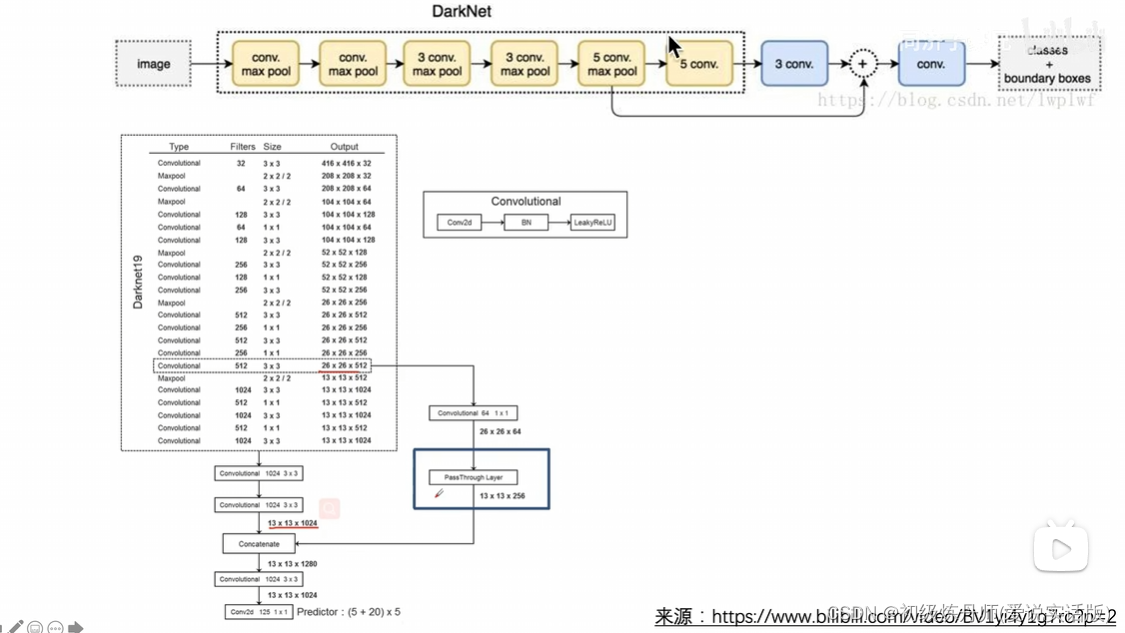
改了骨干网络 V2 用Darknet19作为backbone V3用了darknet53
Model

Stronger(类别更多)(不是重点)
联合训练

不能简单融合,类别互斥,softnet互斥

形成分层的softmax结构,同级子节点做softmax
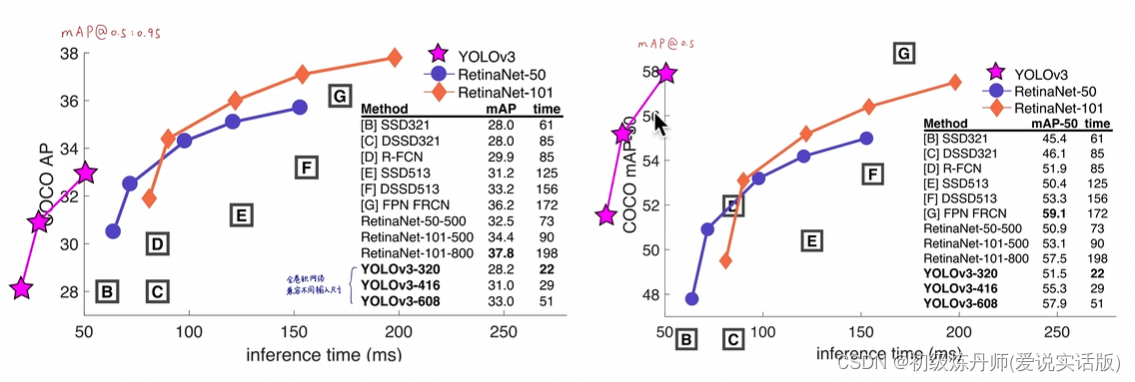
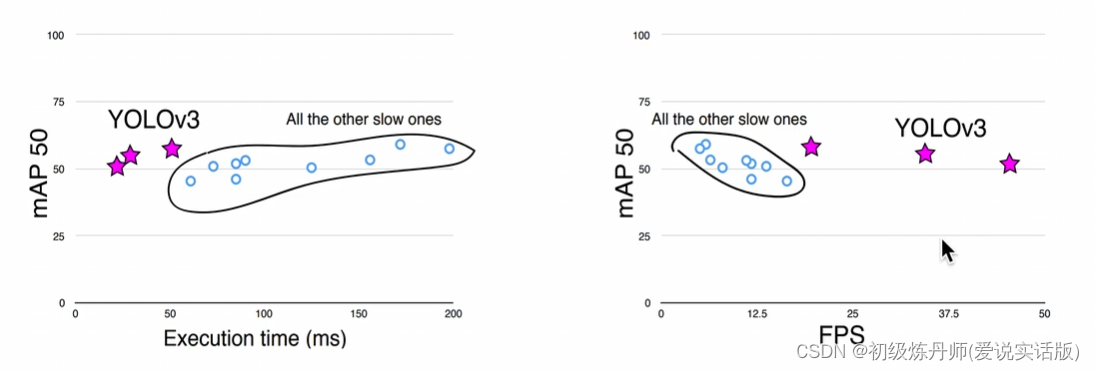
YOLOV3(An incremental improvement)(2018.4)
V4 V5 YoloX都是对V3的小修小补 并没有什么本质上的创新
基本的性能在V3就已经奠定了
包括现在很多的业界的应用用的还是yoloV3 因为它本身已经是一个很经典很优秀的算法了
唯一不太好的点就是它的论文写的不太正式,而且他的很多内容都很难推敲,各种网上的代码复现也是参差不齐
yolov3对V1和V2进行了一系列改进,解决了对小目标和(密集目标)检测不准确的问题
yolov2的骨干网络是Darknet19,有十九层
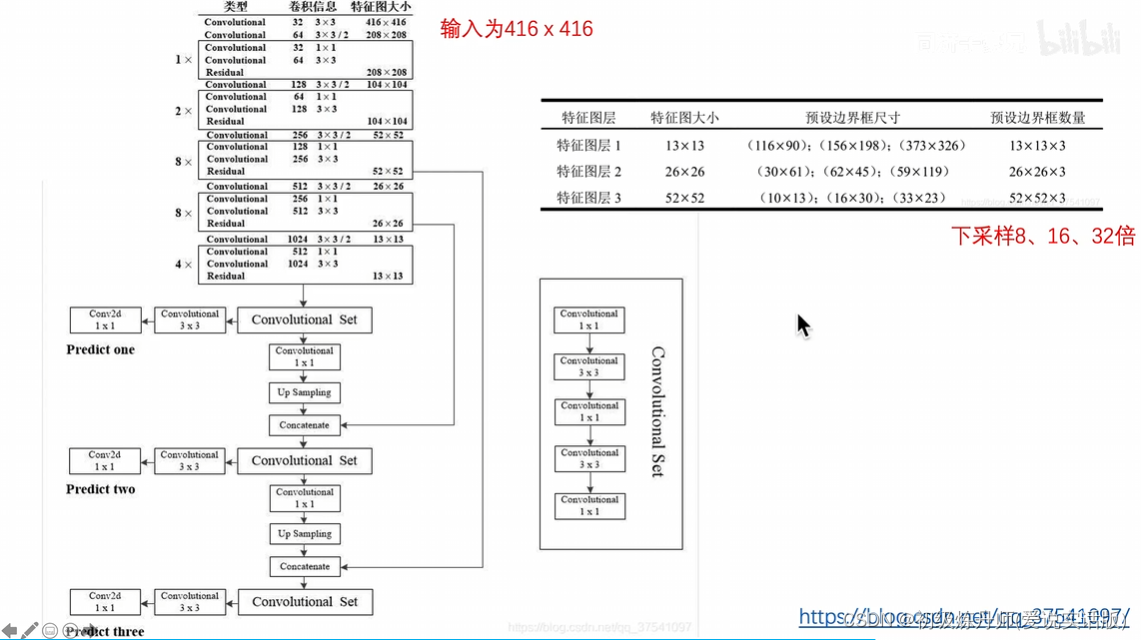
Backbone Darknet-53
(有52个卷积层和一个全连接层,并且里面加了残差连接)

(residual是残差链接不是单独的一层)
下采样是通过步长为2的卷积实现的,当作为backbone时去除了全连接层,就变成了卷积层的堆叠(backbone是全卷积层),因此可以兼容任意尺度的图像,但输入图像必须是32的倍数,因为要下采样32倍

骨干网络性能不错可以和resnet152媲美,它能够高效使用GPU,它实现了精度和速度的一个权衡
yolov3就以darknet作为骨干网络进行特征提取
Model
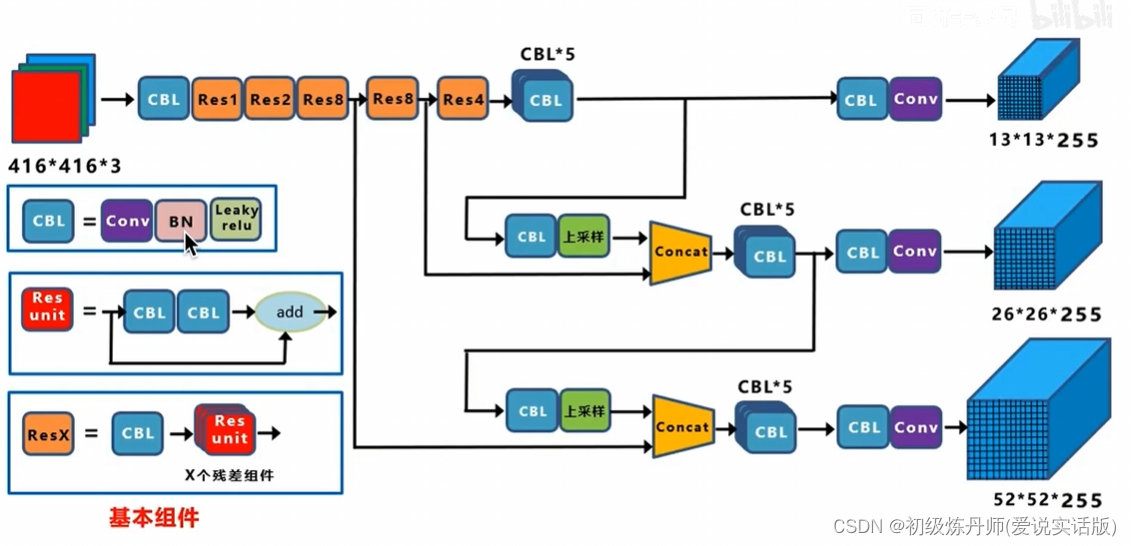
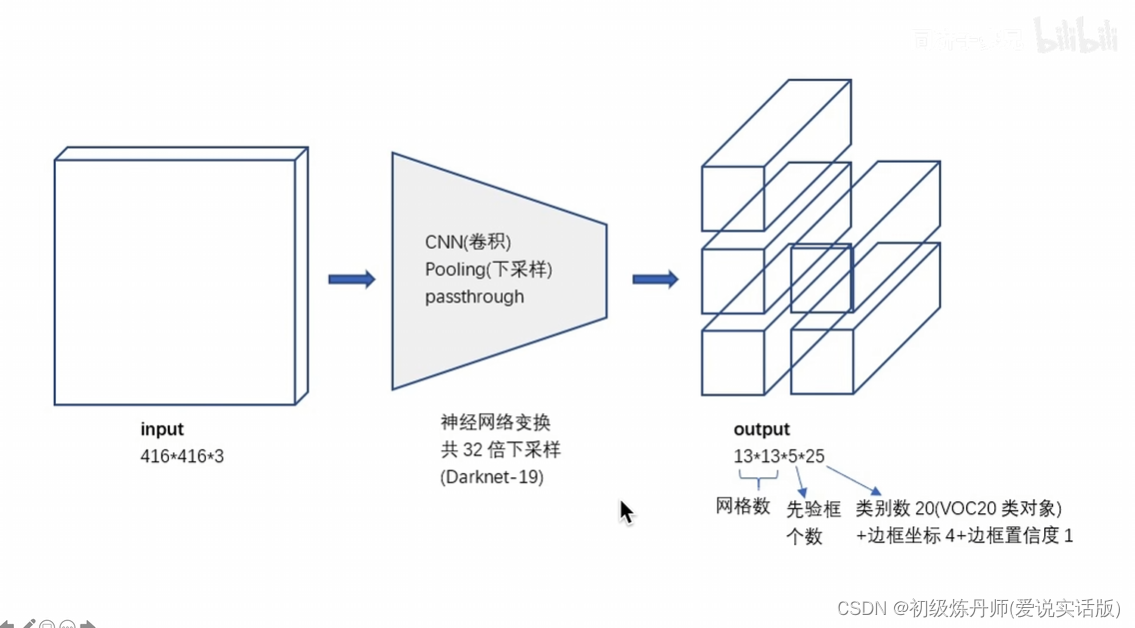
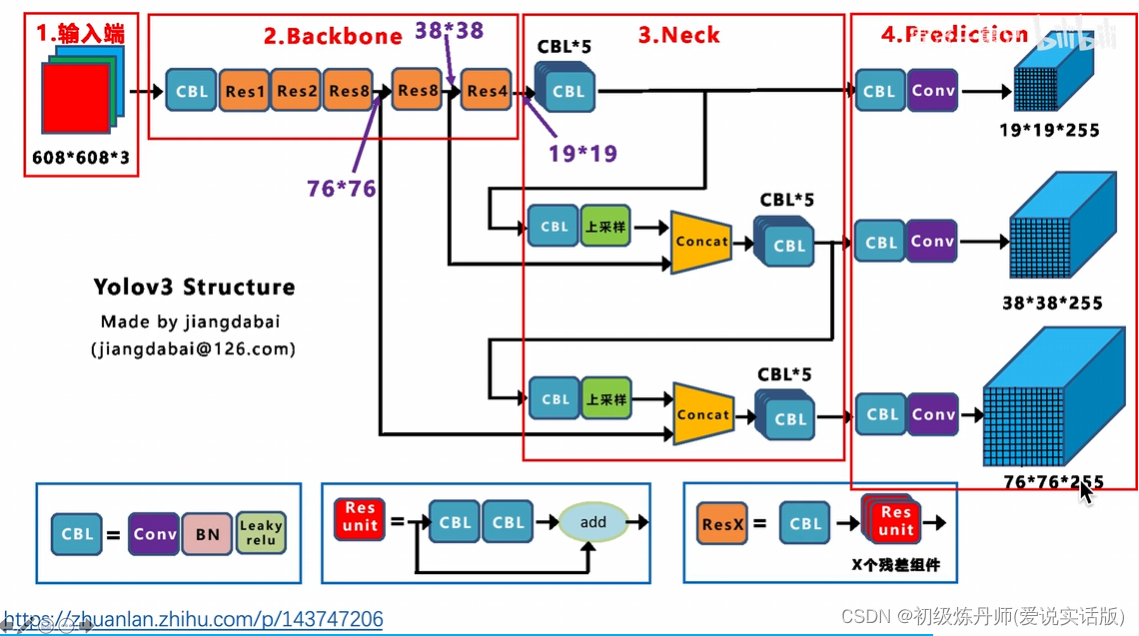
<骨架提取特征,颈部融合特征,头获得最终的预测结果>
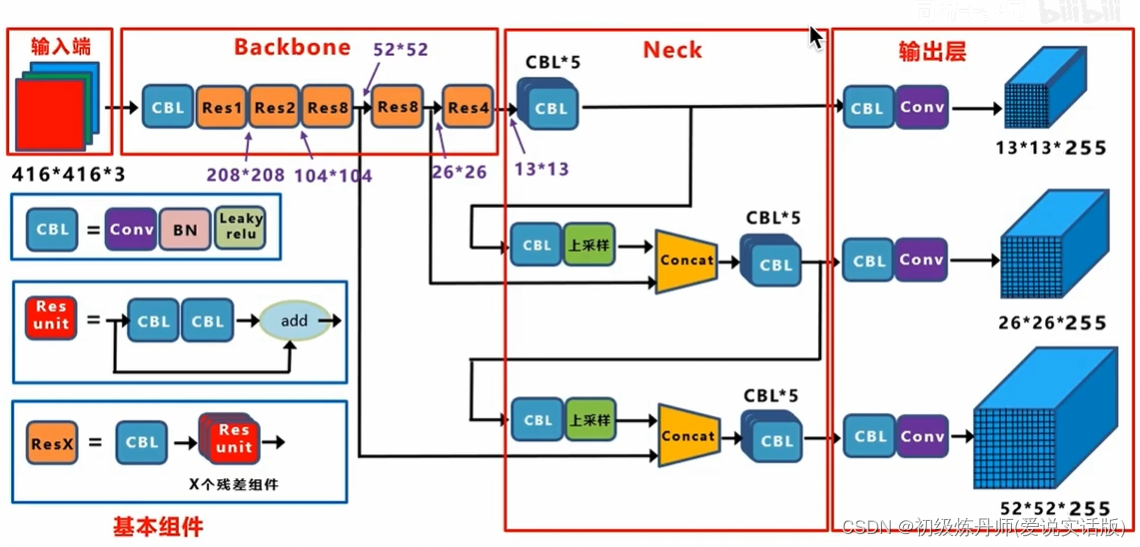
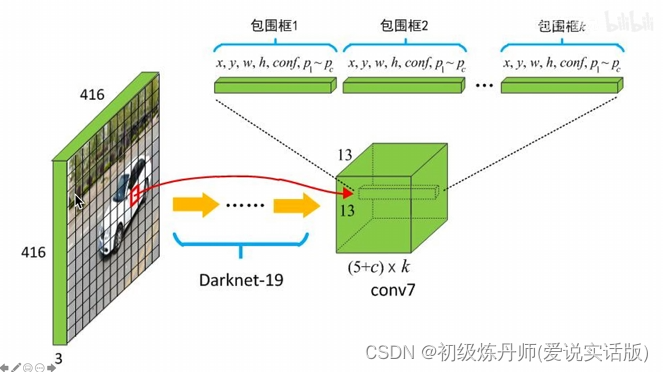
输入的是416*416*3,输出的是三个尺度的featuremap(目的是匹配多尺度的物体),分别是13*13*255,26*26*255,32*32*255,255=3*85,每个gridcell生成3个anchor,每个anchor对应一个预测框,85=5+80,5=x,y,w,h,c ,80是Coco数据集包含80个类别对应的条件类别概率,左上角的就是Darknet53的骨干网络,骨干网络分别抽取到了下采样32倍的特征下采样16倍的特征和下采样8倍的特征(表示不同粒度的特征),
通过concat操作,下采样16倍的特征融合了下采样32倍的特征,下采样8倍的特征同时融合了下采样16倍的特征和下采样32倍的特征,经过这种特征融合,52*52*255的特征既发挥了深层网络的抽象特征,也同时利用了细粒度的细节纹理特征。所以通过这种结构可以实现多尺度的特征融合和不同尺度物体的预测
再看一眼255的含义
图片缩放方法:

1、不保留原来的长宽比例直接缩放成416*416,resize:会发生一些畸变
2、在保留原始长宽比例的情况下给图片多余的部分加上灰框
一些其他细节
v1产生98个预测框(检测小目标和密集目标的能力当然很差),v2产生13*13*5=
yoloV3对一个图像产生10647个预测框3*(13*13+26*26+52*52)改善了对小目标和密集目标的检测性能
 对于yolov3来说输入的图片尺寸越大,grid数越多,输出的预测框的个数也越大。
对于yolov3来说输入的图片尺寸越大,grid数越多,输出的预测框的个数也越大。
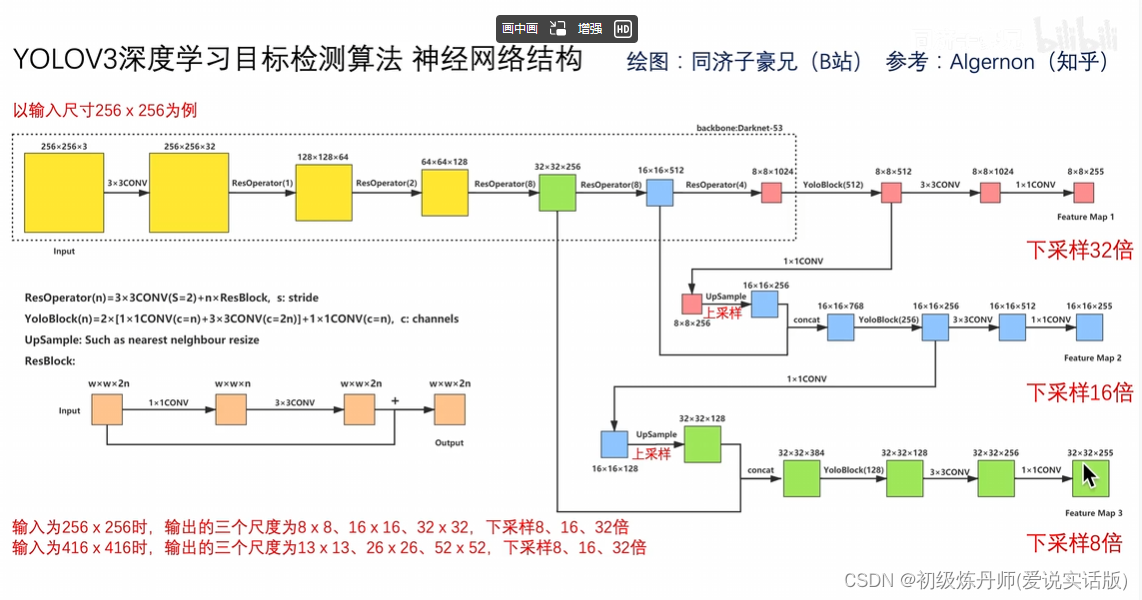 concat是先上采样再按照通道方向叠加,上图展现了一下concat细节
concat是先上采样再按照通道方向叠加,上图展现了一下concat细节
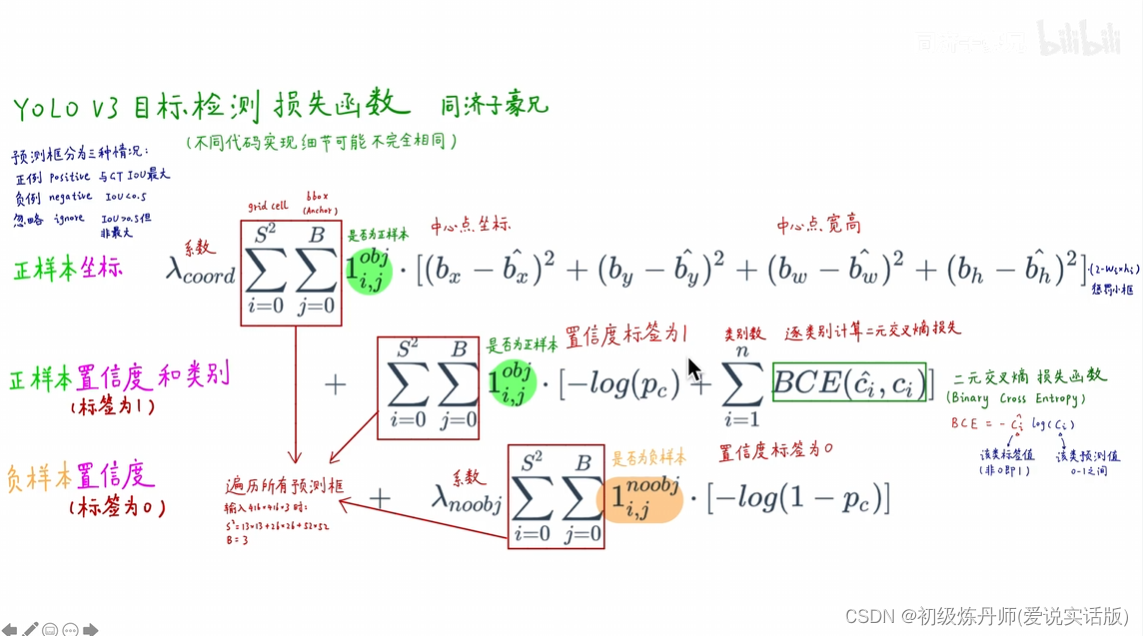
损失函数
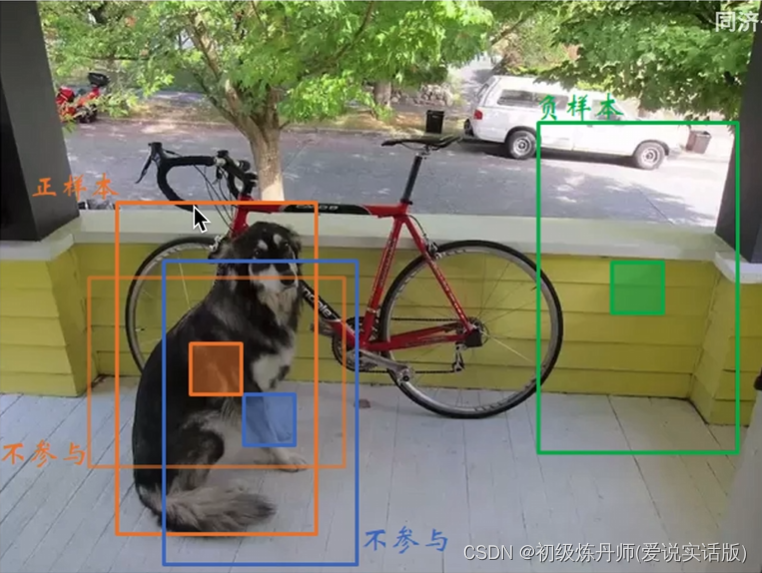 对于yoloV3来说于groundtruth IOU最大的框为正样本,IOU低于某个阈值的框为负样本,IOU处于中间位置的值不参与损失函数的计算
对于yoloV3来说于groundtruth IOU最大的框为正样本,IOU低于某个阈值的框为负样本,IOU处于中间位置的值不参与损失函数的计算
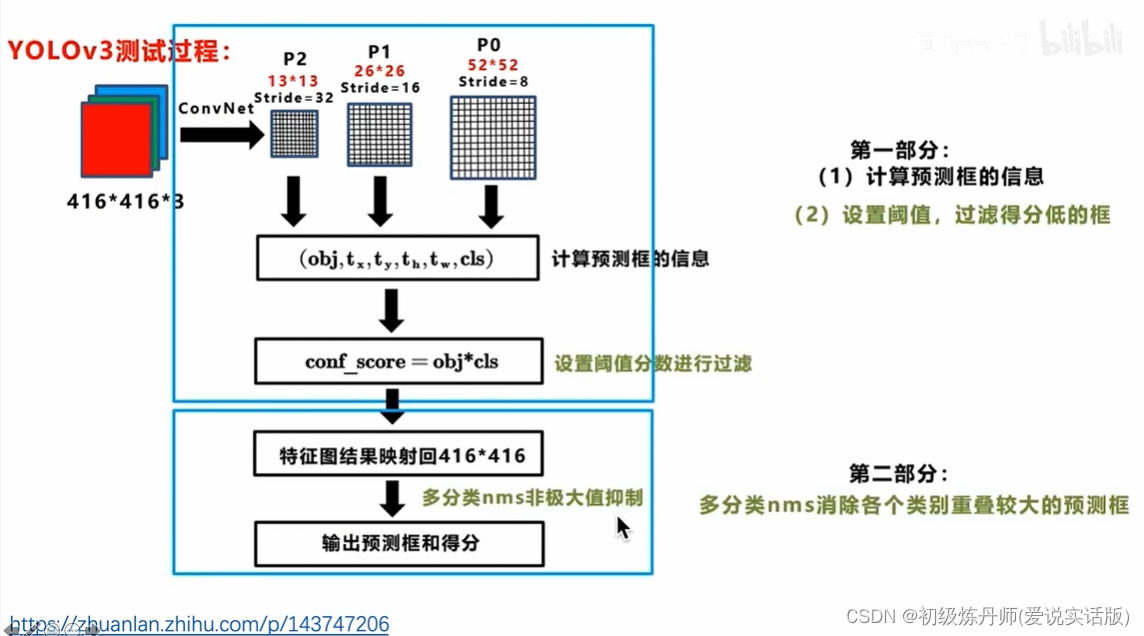
 训练过程
训练过程

测试过程
 YoloV3改进变种
YoloV3改进变种
密集连接
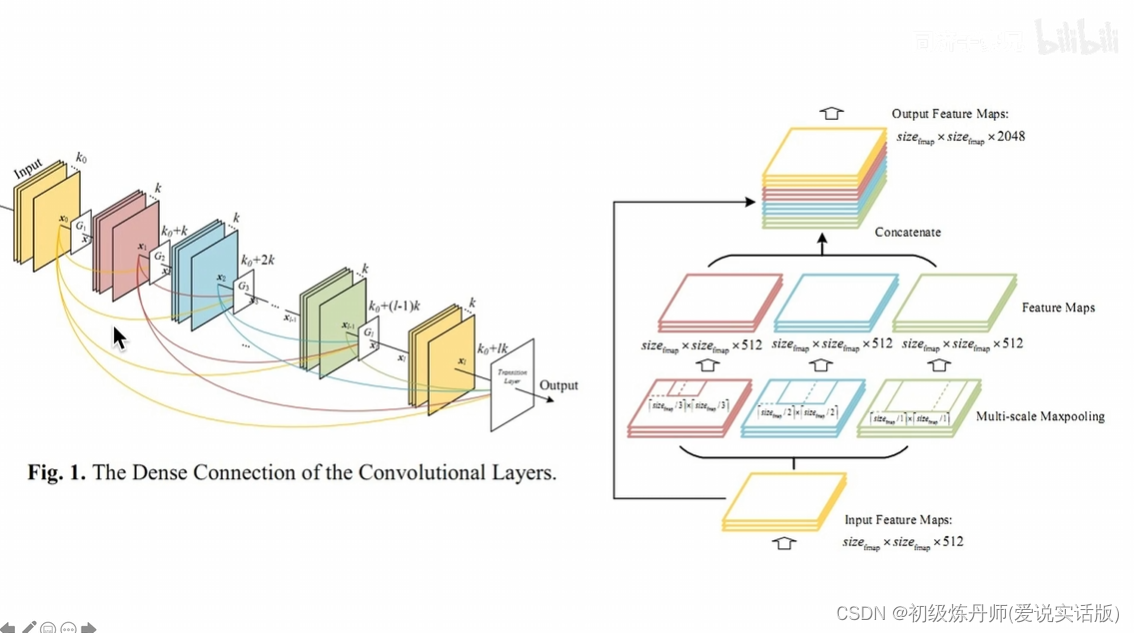
空间金字塔池化
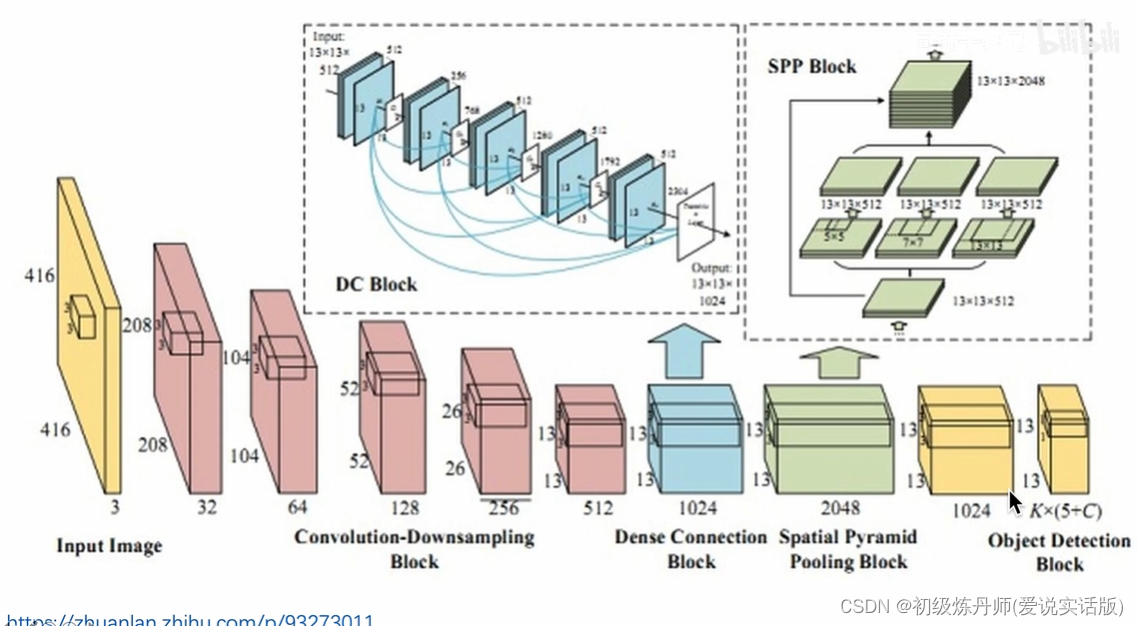 YOLOV4
YOLOV4
简介
YoloV4是YoloV3的加强版!
其主要在YOLOV3的基础上添加了一些列的小改进。
因此YOLOV4于YOLOV3整体的预测思路是没有差别的!解码过程甚至一模一样!
YOLOV4的改进
1、Backbone:Darknet53—>CSPDarknet53
2、Backbone:应用SPP和PANet结构
3、Dataset:使用了Mosaic数据增强
4、Loss:使用了CIOU作为回归LOSS
5、activatefunc:使用了MISH激活函数
Model
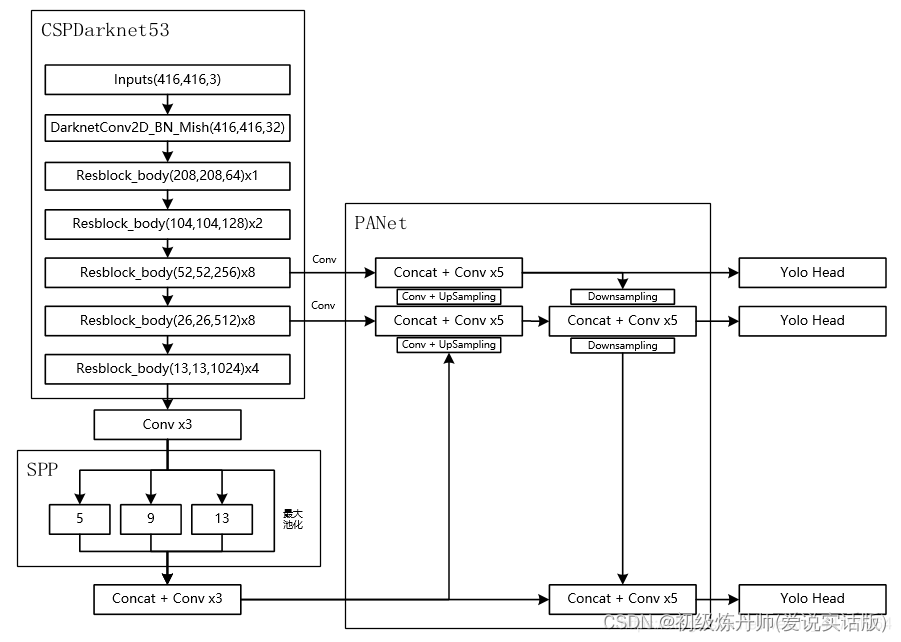
与yolov3相同,输入图像的大小可以不同
SPP是利用不同尺寸的最大池化核来对输入进来的特征层进行最大池化,池化后的结果在进行一个堆叠(concat)之后再进行三次卷积
PANet是用特征金字塔对特征进行融合
输出头与yolov3没有区别

75=3*25,25=5(X,Y,W,H,C)+20(是针对VOC数据集来讲的,有20个类)
YOLOV5
简介
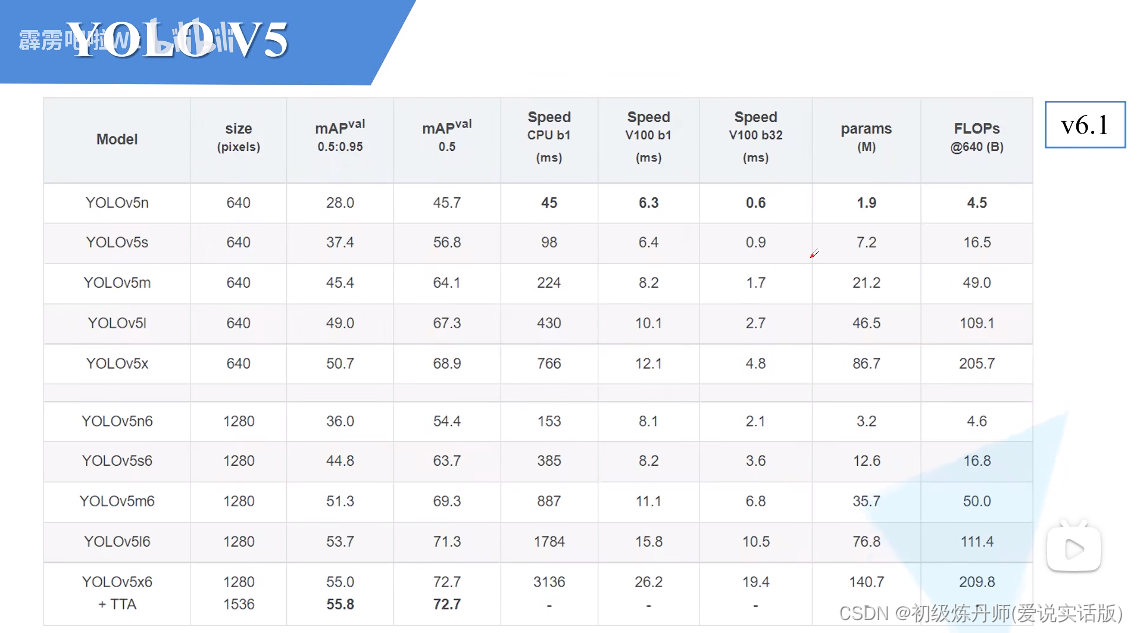
模型效果,带6的模型是处理更大尺寸的图片的
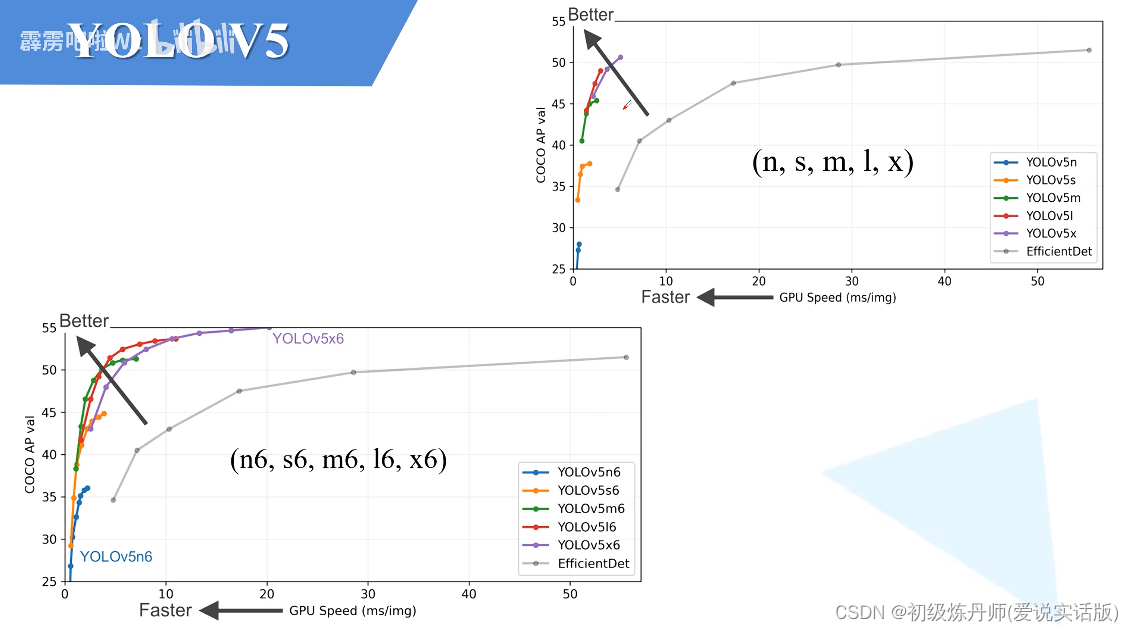
带6的和普通的除了在输入分辨率上有区别在模型的搭建上也有一些区别,
右上角模型最大的下采样倍率是32倍,所采用的预测特征层有三层(P3,P4,P5)(和之前的yolov3和V4都是一样的)
左下角这几个针对更大分辨率的模型,他们的下采样率达到了64倍(因为输入的分辨率更大,所要分的层次自然更多一些),它所采用的预测特征层一共有四层(P3,P4,P5,P6)
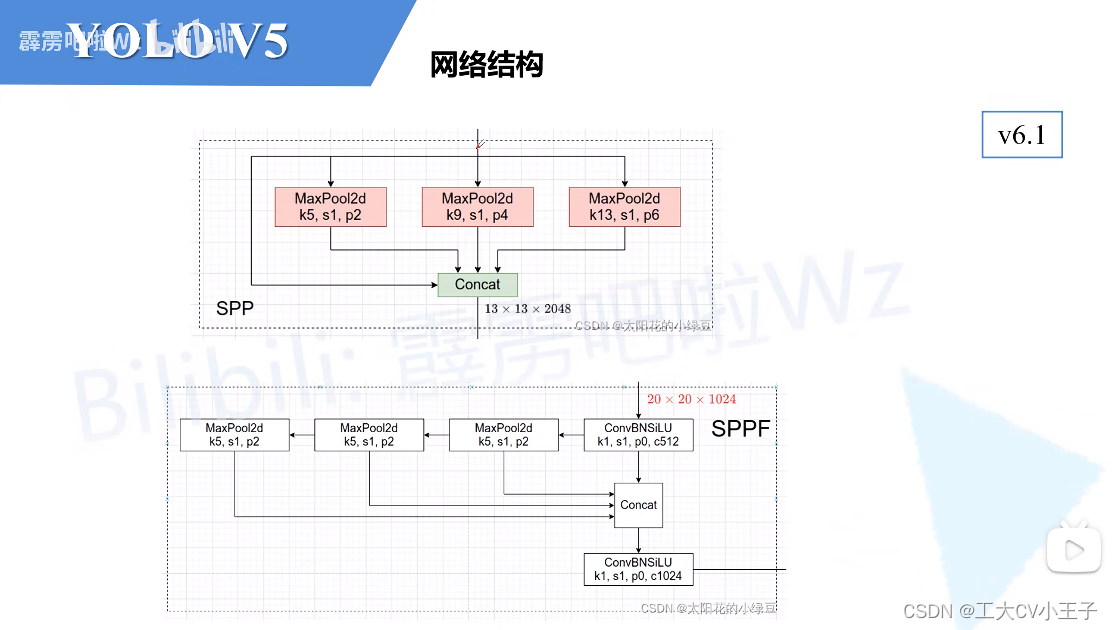
网络结构

backbone:New Csp-Darknet53
Neck:SPP->SPPF,PN->New CSP-PAN
Head:YOLOv3 Head
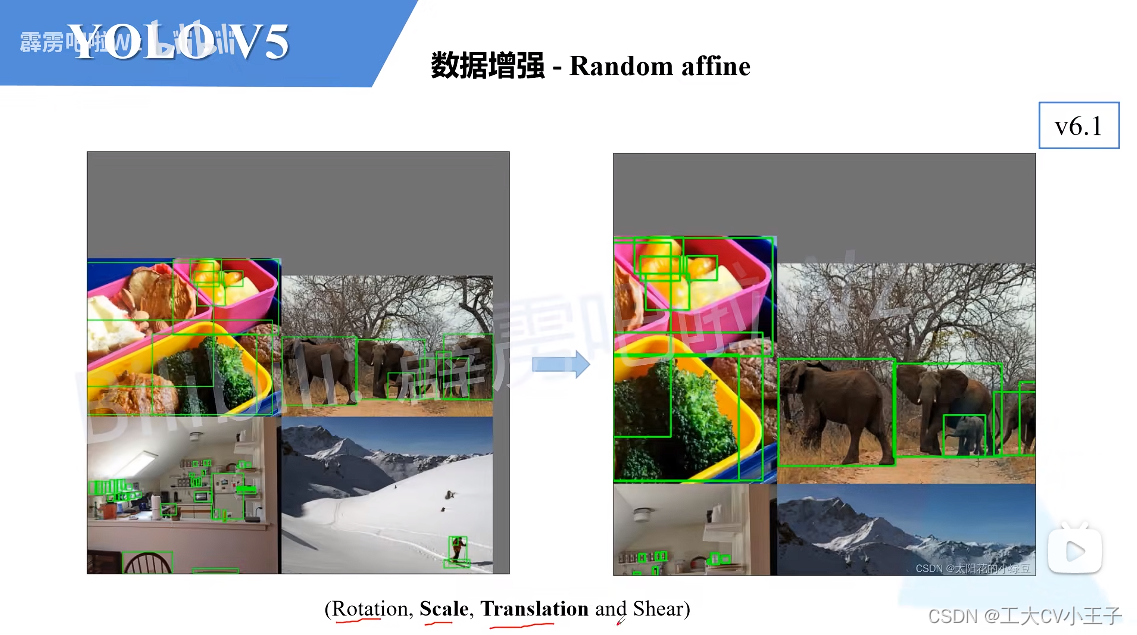
数据增强
mosaic(将四张图片拼成一张图片)

Copy paste

仿射变换
MixUp将两张图片按照一定透明程度混合成一张新的图片

Albenmentation

Augment HSV随机调整色度饱和度明度

Random horizontal filp随机水平翻转

训练策略

EMA:给学习变量加上一个动量
混合精度训练:加快训练提高GPU利用率
超参设置
其他
损失计算

平衡不同尺度损失

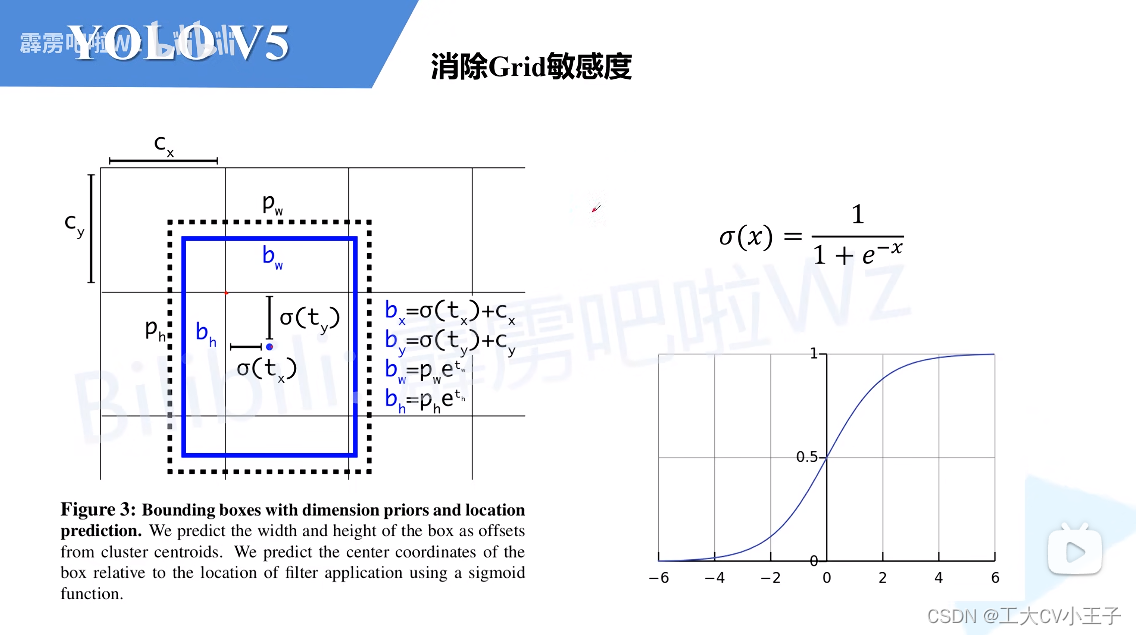
消除Grid敏感度

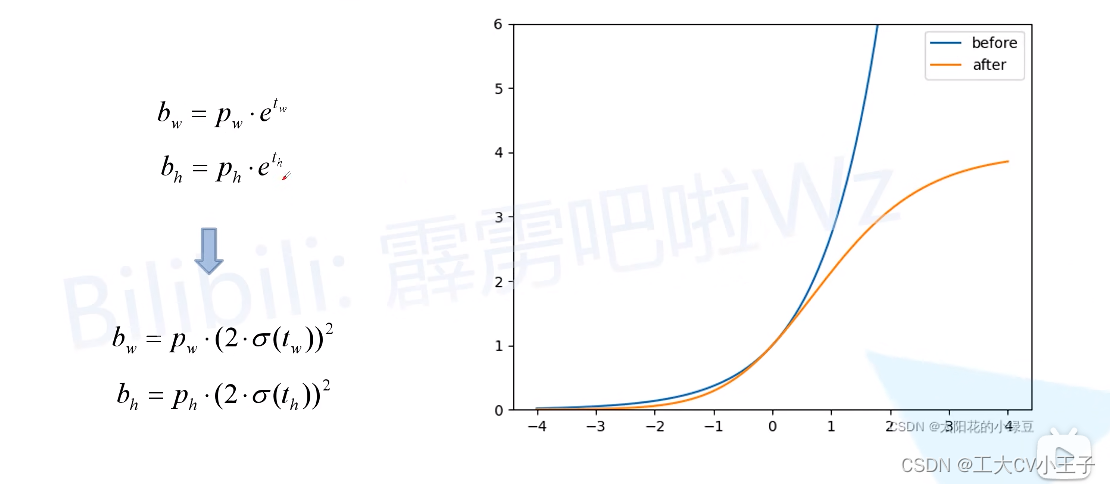
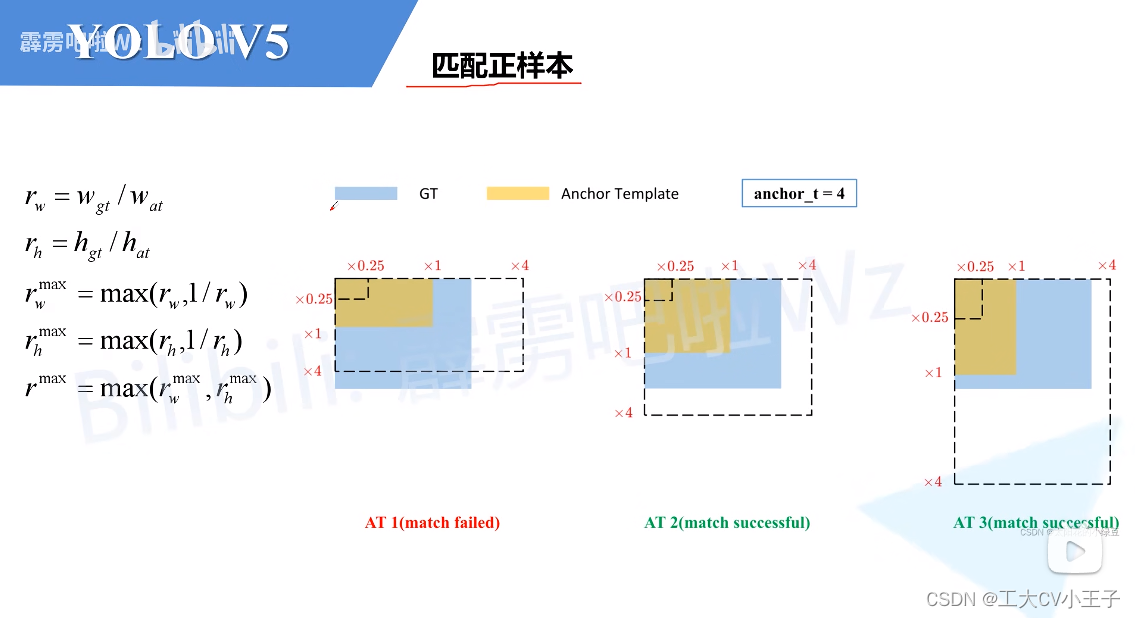
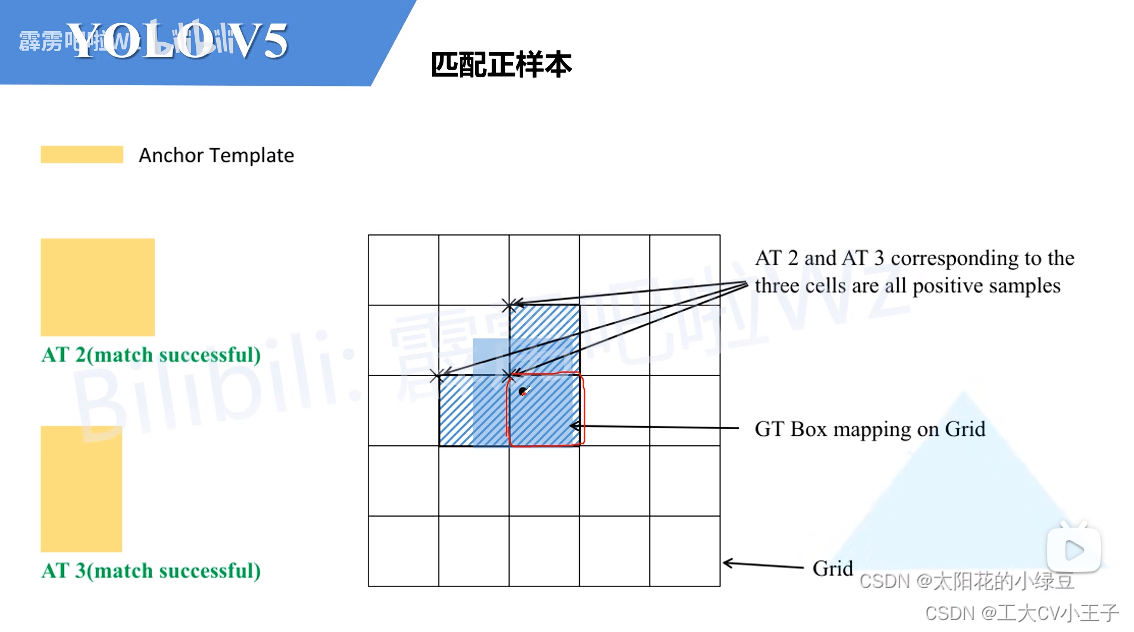
匹配正样本(Build Targets)

参考文献
【精读AI论文】YOLO V1目标检测,看我就够了_哔哩哔哩_bilibili
【精读AI论文】YOLO V2目标检测算法_哔哩哔哩_bilibili
【精读AI论文】YOLO V3目标检测(附YOLOV3代码复现)_哔哩哔哩_bilibili
科普:什么是YOLOV4目标检测算法_哔哩哔哩_bilibili
睿智的目标检测30——Pytorch搭建YoloV4目标检测平台-CSDN博客
YOLOv5网络详解_哔哩哔哩_bilibili
YOLOv5网络详解_yolov5网络结构详解-CSDN博客
YOLOv5 模型结构详细讲解_哔哩哔哩_bilibili