文章目录
- 1. 大模型开发范式
- 2. LangChain简介
- 3. 构建向量数据库
- 4. 搭建知识库助手
- 5. Web Demo部署
- 6. 动手实战环节
- 环境配置
- 知识库搭建
- InternLM接入LangChain
- 构建检索问答链
- 部署Web Demo
- 参考资料
1. 大模型开发范式
LLM局限性:
知识时效性:LLM无法获取最新的知识
专业能力有限:如何打造垂直领域大模型
定制化成本高:如何打造个人专属的LLM应用
两种大模型开发范式
检索增强生成RAG
外挂知识库
低成本、实时更新、受基座模型影响大、单次回答知识有限(知识库中文档占据上下文大)
LLM微调finetune
在小的数据集上进行轻量级训练
个性化微调、知识覆盖面广、成本高昂、无法实时更新
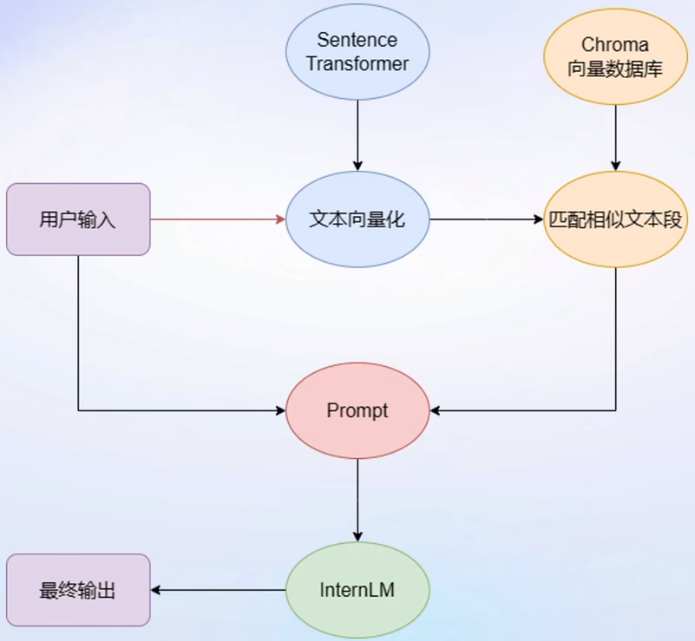
RAG检索增强生成的基本思路
一个假设是向量数据库中检索到的和用户输入文本相似的文本段大概率是包含了问题答案
2. LangChain简介
针对LLM开发,为各种LLM提供通用接口的开源框架
核心组成模块
链(Chains):封装实现一系列LLM操作实现端到端应用,如检索问答链覆盖实现了RAG的全部流程
开发思路:将开发者的私域数据直接嵌入LangChain组件来构建RAG应用
开发流程图
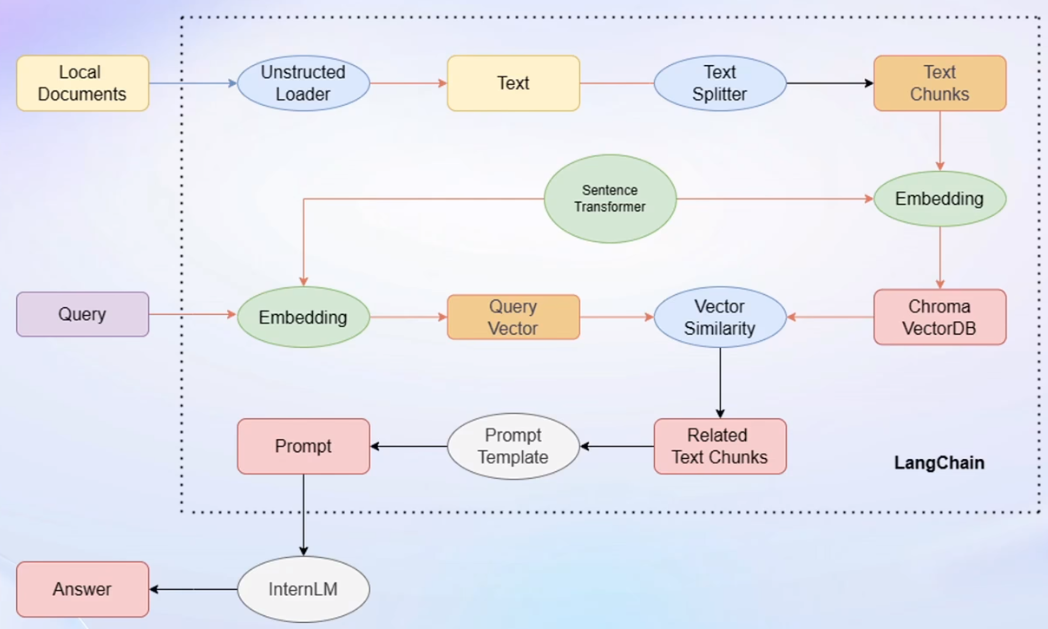
Unstructed Loader:将用户文档全部转化为纯文本格式
Text Splitter:将纯文本分割为Text Chunks 文本块
Sentence Transformer:开源词向量模型,将文本段转化为向量格式;将用户输入转化为向量
3. 构建向量数据库
步骤
加载源文件、文档分块、文档向量化
- 将不同类型的源文件使用不同的加载器统一转化为无格式字符串
- 由于LLM的上下文长度有限,按字符串长度划分已加载的文档为多个chunks
- 使用Embedding模型(Sentence Transformer)将chunks文本向量化存入支持语义检索的向量数据库(Chroma)中
4. 搭建知识库助手
将InternLM接入LangChain
将InternLM部署在本地,并封装成一个自定义的LLM类,接入到LangChain框架中,直接调用本地的InternLM
构建检索问答链
LangChain提供了检索问答链模板——实现知识检索、prompt嵌入、LLM问答的全部流程
方法:将基于InternLM的自定义LLM和已构建的向量数据库接入到检索问答链上游,再调用检索问答链就可实现知识库助手的全部功能
RAG方案优化建议
基于RAG的问答系统缺陷在于
- 检索精度:将基于字符串长度的chunk分割改为基于语义的分割以保证chunk的语义完整性;给每个chunk生成概况性索引,检索时直接匹配索引而非全文匹配
- Prompt性能:迭代优化Prompt
5. Web Demo部署
支持简易Web部署的框架:gradio、streamlit等
本次lesson使用gradio框架完成知识库助手的web部署
6. 动手实战环节
环境配置
- InternLM模型部署
- 模型下载
- LangChain相关环境配置
# 安装依赖包
pip install langchain==0.0.292
pip install gradio==4.4.0
pip install chromadb==0.4.15
pip install sentence-transformers==2.2.2
pip install unstructured==0.10.30
pip install markdown==3.3.7
Embedding选择
开源词向量模型Sentence Transformer
借助hugging face下载Embedding模型
import os
# 设置hugging face镜像的环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型 --resume-download 断点续下;--local-dir 本地存储路径
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')
- 下载NLTK相关资源
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
- 下载本项目代码
知识库搭建
-
数据收集:语料库来源

选取语料库中的.txt文件和.md文件 -
加载数据
使用LangChain提供的FileLoader对象加载目标文件,得到由目标文件解析出的纯文本内容
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
- 构建向量数据库
先对文本进行分块,再对文本块进行向量化
分块
RecursiveCharacterTextSplitter字符串递归分割器,选择分块大小为 500,块重叠长度为 150
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
块向量化
使用开源词向量模型Sentence Transformer进行文本向量化
使用Chroma向量数据库实现文本向量的本地存储
# 文本向量化
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 文本向量存储
from langchain.vectorstores import Chroma
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()
InternLM接入LangChain
为了实现将InternLM接入LangChain框架从而达到模型封装的目的,这里需要基于本地部署的 InternLM,继承 LangChain 的 LLM 类自定义一个 InternLM LLM 子类
如何自定义LangChain的LLM子类
从 LangChain.llms.base.LLM 类继承一个子类,并重写构造函数与 _call 函数
构建检索问答链
- 加载向量数据库
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings
)
- 实例化自定义LLM与Prompt Template
# 实例化自定义的LLM
from LLM import InternLM_LLM
llm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")
llm.predict("你是谁")
# 常用的Prompt Template构建
from langchain.prompts import PromptTemplate
# 我们所构造的 Prompt 模板
template = """使用以下上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答你不知道。
有用的回答:"""
# 调用 LangChain 的方法来实例化一个 Template 对象,该对象包含了 context 和 question 两个变量,在实际调用时,这两个变量会被检索到的文档片段和用户提问填充
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)
- 构建检索问答链
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
对比原生llm问答效果和加入检索问答链的llm问答效果
# 检索问答链回答效果
question = "什么是InternLM"
result = qa_chain({"query": question})
print("检索问答链回答 question 的结果:")
print(result["result"])
# 仅 LLM 回答效果
result_2 = llm(question)
print("大模型回答 question 的结果:")
print(result_2)
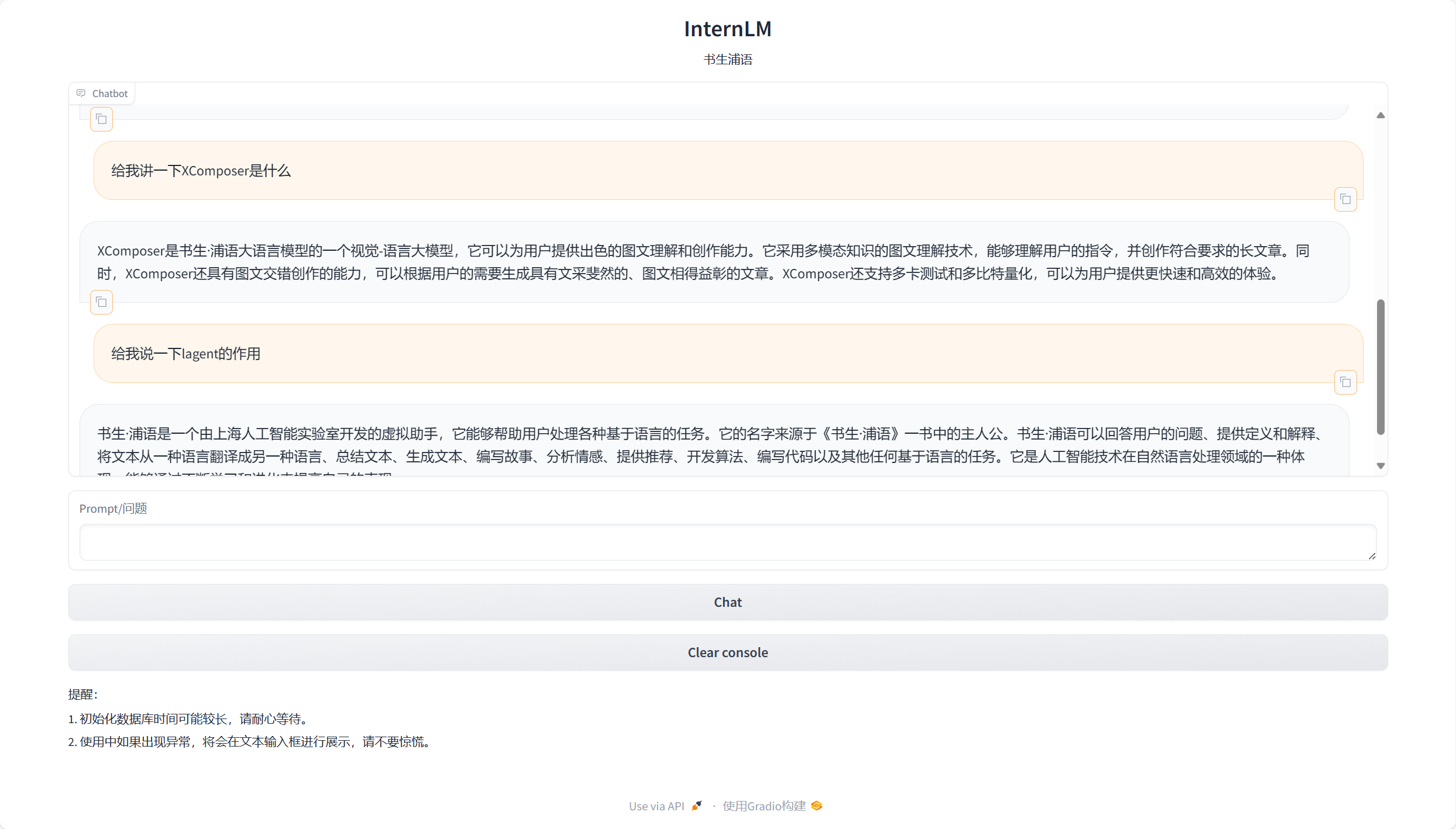
部署Web Demo
基于 Gradio 框架将上述带有检索问答链并接入了LangChain框架的InternLM部署到 Web 网页
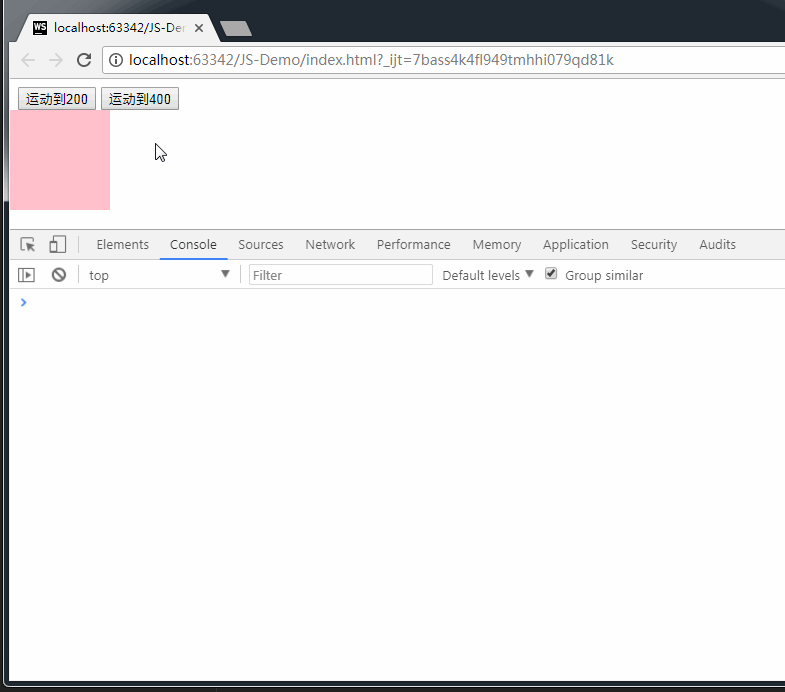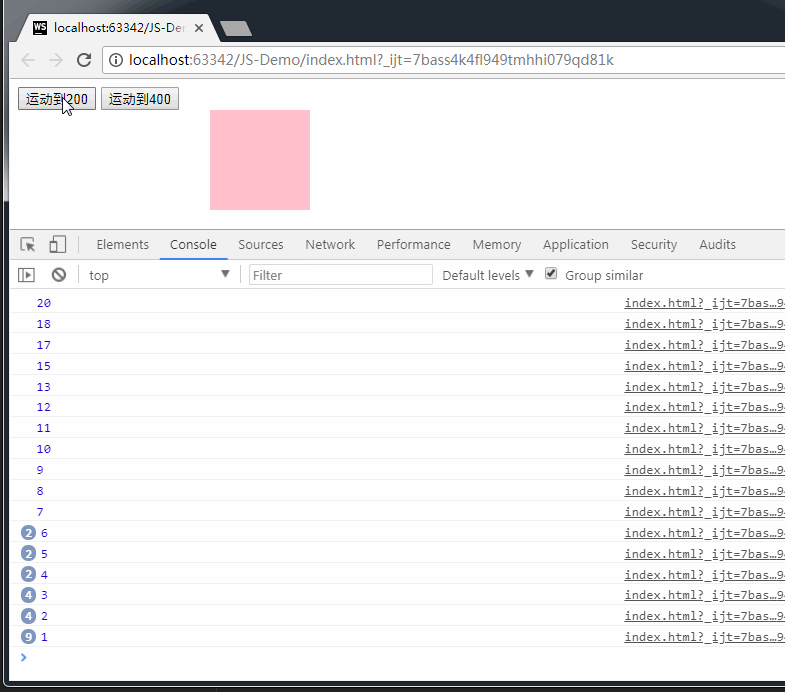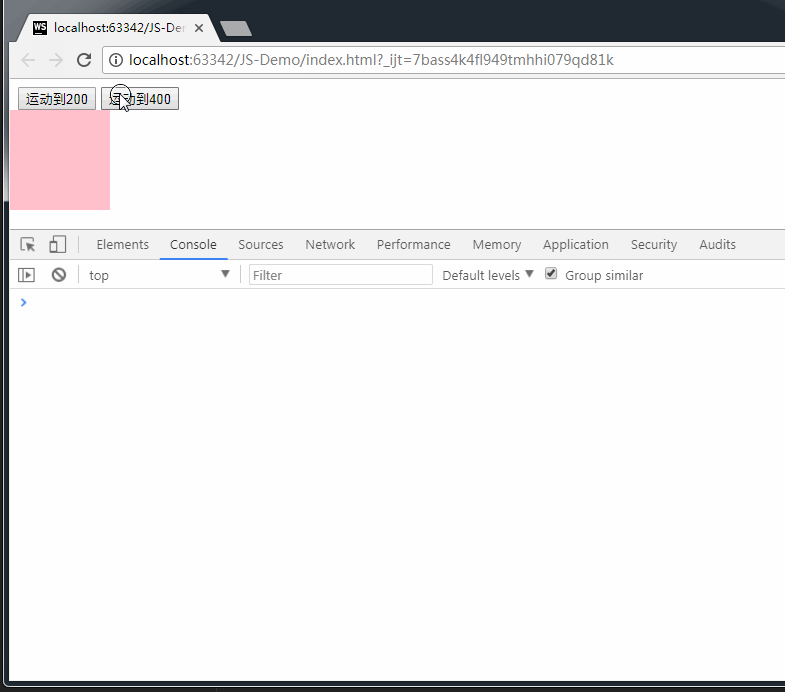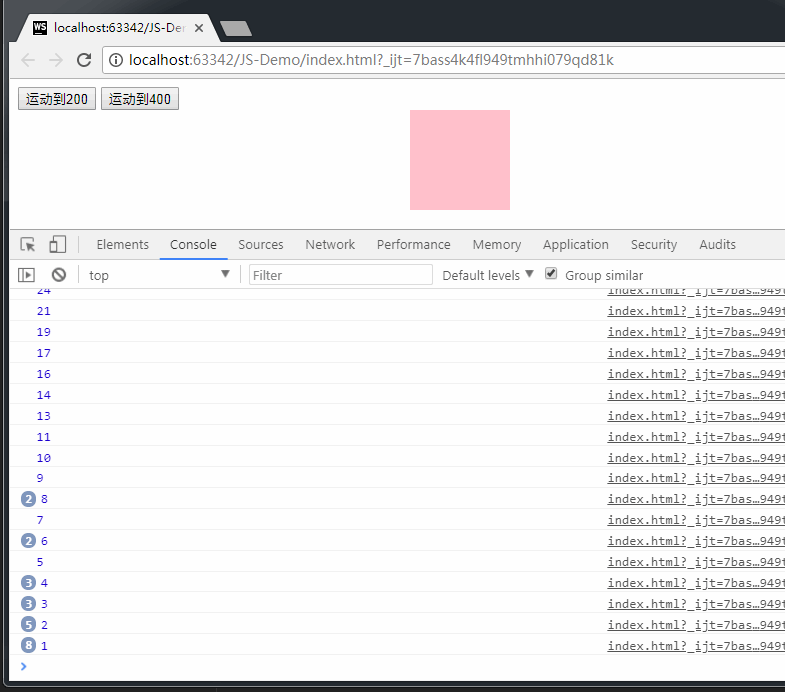
运行效果如下:
参考资料
- 书生·浦语大模型全链路开源体系