前言
降本增效=降本增笑?增不增效暂且不清楚,但是这段时间大厂的产品频繁出现服务器宕机和产品BUG确实是十分增笑。目前来看降本增效这一理念还会不断渗透到各行各业,不单单只是互联网这块了,那么对于目前就业最为严峻的一段时期,我们能够对失业率有个全面的了解是最好的情况,所以基于此理念我们来拟定一个失业率预测分析这一微项目。
我们将会从数据获取–数据处理–LSTM建模–预测检测这四个流程依次进行最终得到一个较为合理准确的数据,当然该预测率的准确度是依赖获取到的官方数据的,至于数据真实性这个不作过多解释~大家只要了解建模过程如何和LSTM模型如何使用就好。
博主现任高级人工智能工程师,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。写文章的目的就是为了让零基础快速使用各类代码模型,保证每篇文章都为用心撰写。
且每篇文章我都会尽可能将简化涉及到垂直领域的专业知识,转化为大众小白可以读懂易于理解的知识,将繁杂的程序创建步骤逐个拆解,以逐步递进的方式由难转易逐渐掌握并实践,欢迎各位学习者关注博主,博主将不断创作技术实用前沿文章。
数据获取
不查不知道,一查确实还是挺有意思的数据,想要获取官方数据可以直接访问国家数据网站。
 因为是官方的数据所以就默认为真实情况,就不用进行数据清洗工程了。
因为是官方的数据所以就默认为真实情况,就不用进行数据清洗工程了。
数据预览
# 转换为DataFrame
df = pd.DataFrame(data)
# 将日期转换为时间序列,并设为索引
df['日期'] = pd.to_datetime(df['日期'], format='%Y年%m月')
df.set_index('日期', inplace=True)
# 由于数据是逆序的,我们需要将其反转以正确地展示时间序列
df = df.iloc[::-1]
df
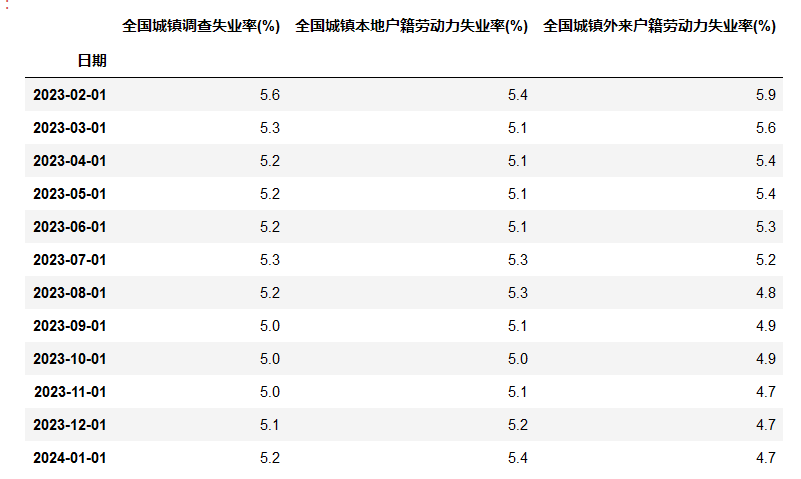
我们再来数据可视化帮我们更具体的看清楚整个数据的全貌:
# 绘制线图
plt.figure(figsize=(10, 6)) # 设置图形大小
plt.plot(df.index, df['全国城镇调查失业率(%)'], marker='o', label='全国城镇调查失业率(%)')
plt.plot(df.index, df['全国城镇本地户籍劳动力失业率(%)'], marker='s', label='全国城镇本地户籍劳动力失业率(%)')
plt.plot(df.index, df['全国城镇外来户籍劳动力失业率(%)'], marker='^', label='全国城镇外来户籍劳动力失业率(%)')
# 设置图表标题和标签
plt.title('不同类型失业率的时间序列变化')
plt.xlabel('日期')
plt.ylabel('失业率(%)')
plt.xticks(rotation=45) # 旋转x轴标签以避免重叠
plt.legend() # 显示图例
# 显示图表
plt.tight_layout() # 自动调整子图参数, 使之填充整个图像区域
plt.show()
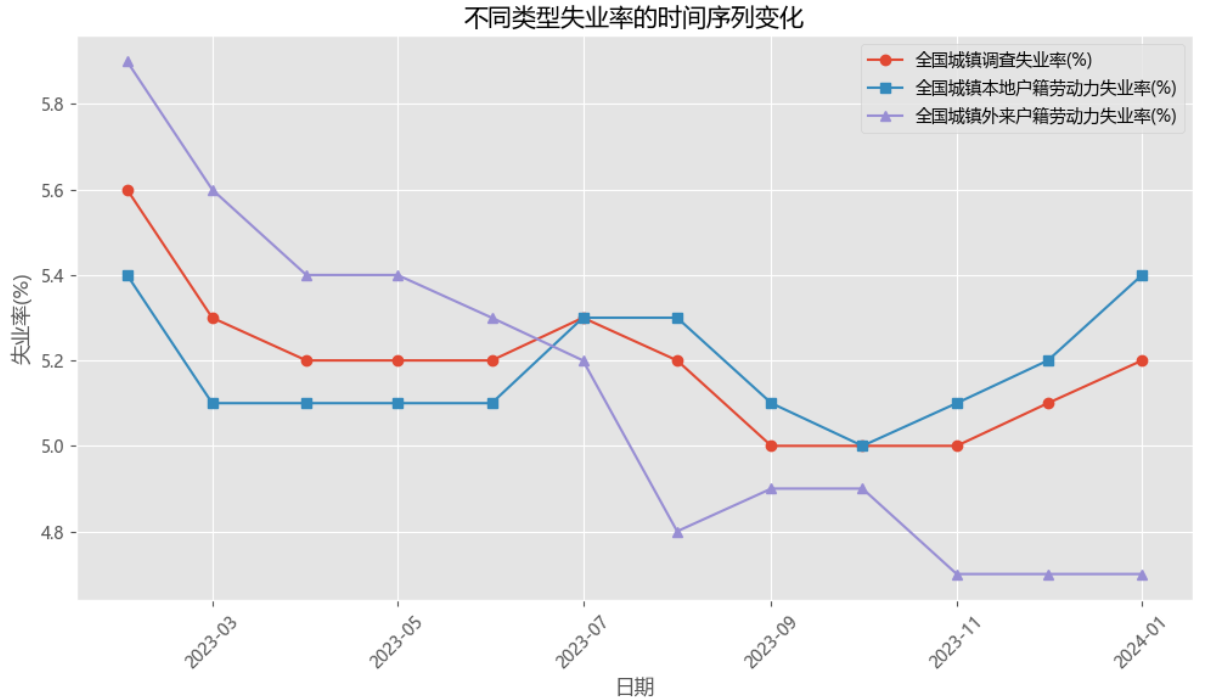
LSTM建模
那么现在我们可以来预测未来三个月的失业率到底如何,构建一个LSTM模型来预测未来三个月的失业率是一个典型的时间序列预测任务。使用PyTorch框架进行此类预测需要几个步骤:数据预处理、定义LSTM模型、训练模型、以及最后的预测。下面我会概述这个过程的每个步骤,并提供相应的示例代码。
步骤 1: 数据预处理
时间序列预测的第一步通常涉及到数据的预处理,包括标准化/归一化数据和创建适合于监督学习的时间序列数据集。
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import torch
# 假设df是包含失业率时间序列的DataFrame
# 选择一个列作为预测目标
data = df['全国城镇调查失业率(%)'].values.reshape(-1, 1)
# 数据标准化
scaler = MinMaxScaler(feature_range=(-1, 1))
data_normalized = scaler.fit_transform(data)
# 创建数据集
def create_dataset(data, look_back=1):
dataX, dataY = [], []
for i in range(len(data)-look_back):
a = data[i:(i+look_back), 0]
dataX.append(a)
dataY.append(data[i + look_back, 0])
return np.array(dataX), np.array(dataY)
look_back = 3 # 使用3个月的数据来预测下一个月
X, y = create_dataset(data_normalized, look_back)
X = X.reshape(X.shape[0], 1, X.shape[1]) # 为了LSTM输入,需要转换为[samples, time steps, features]
# 转换为PyTorch张量
X_torch = torch.from_numpy(X).float()
y_torch = torch.from_numpy(y).float()
步骤 2: 定义LSTM模型
在PyTorch中定义一个简单的LSTM模型。
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size),
torch.zeros(1,1,self.hidden_layer_size))
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq) ,1, -1), self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
步骤 3: 训练模型
接下来,定义训练循环来训练LSTM模型。
model = LSTMModel(input_size=3, hidden_layer_size=100, output_size=1) # 确保这里的参数与你的数据匹配
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
epochs = 150
for epoch in range(epochs):
total_loss = 0
for seq, labels in zip(X_torch, y_torch):
optimizer.zero_grad()
# 根据修改后的模型,不再需要外部初始化hidden_cell
y_pred = model(seq.unsqueeze(0)) # 增加一个批次维度
single_loss = loss_function(y_pred, labels.unsqueeze(0)) # 标签也需要增加一个批次维度
single_loss.backward()
optimizer.step()
total_loss += single_loss.item()
if epoch % 25 == 0:
print(f'epoch: {epoch:3} loss: {total_loss/len(X_torch):10.8f}')
训练误差:
epoch: 0 loss: 0.50735911
epoch: 25 loss: 0.09428047
epoch: 50 loss: 0.08110558
epoch: 75 loss: 0.06782570
epoch: 100 loss: 0.05745859
epoch: 125 loss: 0.05270799
模型预测
基于前面讨论的步骤和代码,使用训练好的LSTM模型和最近几个月的数据来预测未来三个月的失业率。这个过程大致分为以下几步:
- 使用最近的数据:基于
look_back参数,从最新的数据开始预测。 - 进行预测:利用模型预测下一个时间点的值。
- 更新输入数据:将预测值添加到输入数据中,用于下一步的预测。
- 重复预测过程:重复步骤2和3,直到预测了所需的未来时间点的数据。
# 如果look_back=3,我们取最后3个已知时间点的数据
input_data_normalized = data_normalized[-look_back:].reshape((1, 1, look_back))
# 转换为PyTorch张量
input_data_tensor = torch.from_numpy(input_data_normalized).float()
# 存储预测结果
predictions_normalized = []
# 进行未来三个月的预测
for _ in range(3): # 预测未来三个月
with torch.no_grad(): # 不计算梯度
# 预测下一个时间点
pred = model(input_data_tensor)
predictions_normalized.append(pred.numpy().flatten()[0]) # 存储预测结果
# 更新输入数据
input_data_tensor = torch.cat((input_data_tensor[:, :, 1:], pred.unsqueeze(0)), dim=2)
# 将预测结果逆标准化
predictions = scaler.inverse_transform(np.array(predictions_normalized).reshape(-1, 1))
print("预测的未来三个月失业率:", predictions.flatten())
预测的未来三个月失业率: [5.226562 5.1846743 5.1323695]
这个过程假定input_data_normalized包含了用于开始预测的最后look_back个时间点的数据,已经是标准化形式。每次预测后,我们都会更新这个输入数据,将最新的预测值添加进去,同时移除最旧的数据点,以便于下一次预测。预测完成后,我们使用与训练数据相同的MinMaxScaler实例scaler来逆标准化预测结果,以获取原始尺度上的预测值。
确保在进行预测之前,model已经在相似的数据上训练并且达到了满意的性能。预测的这个值大家看个乐呵就行不要太较真~
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。





![[QJS xmake] 非常简单地在Windows下编译QuickJS!](https://img-blog.csdnimg.cn/direct/406aaa7d7798422091d8d50417c02d85.png#pic_center)


