声明
本文章基于哔哩哔哩付费课程《小白也能听懂的人工智能原理》。仅供学习记录、分享,严禁他用!!如有侵权,请联系删除
目录
一、知识引入
(一)二维输入数据
(二)数据特征维度
二、编程实验--接收2个输入的神经元
(一)观察数据
(二)编写预测模型
(三)前向传播
(四)反向传播+随机梯度下降
一、知识引入
(一)二维输入数据
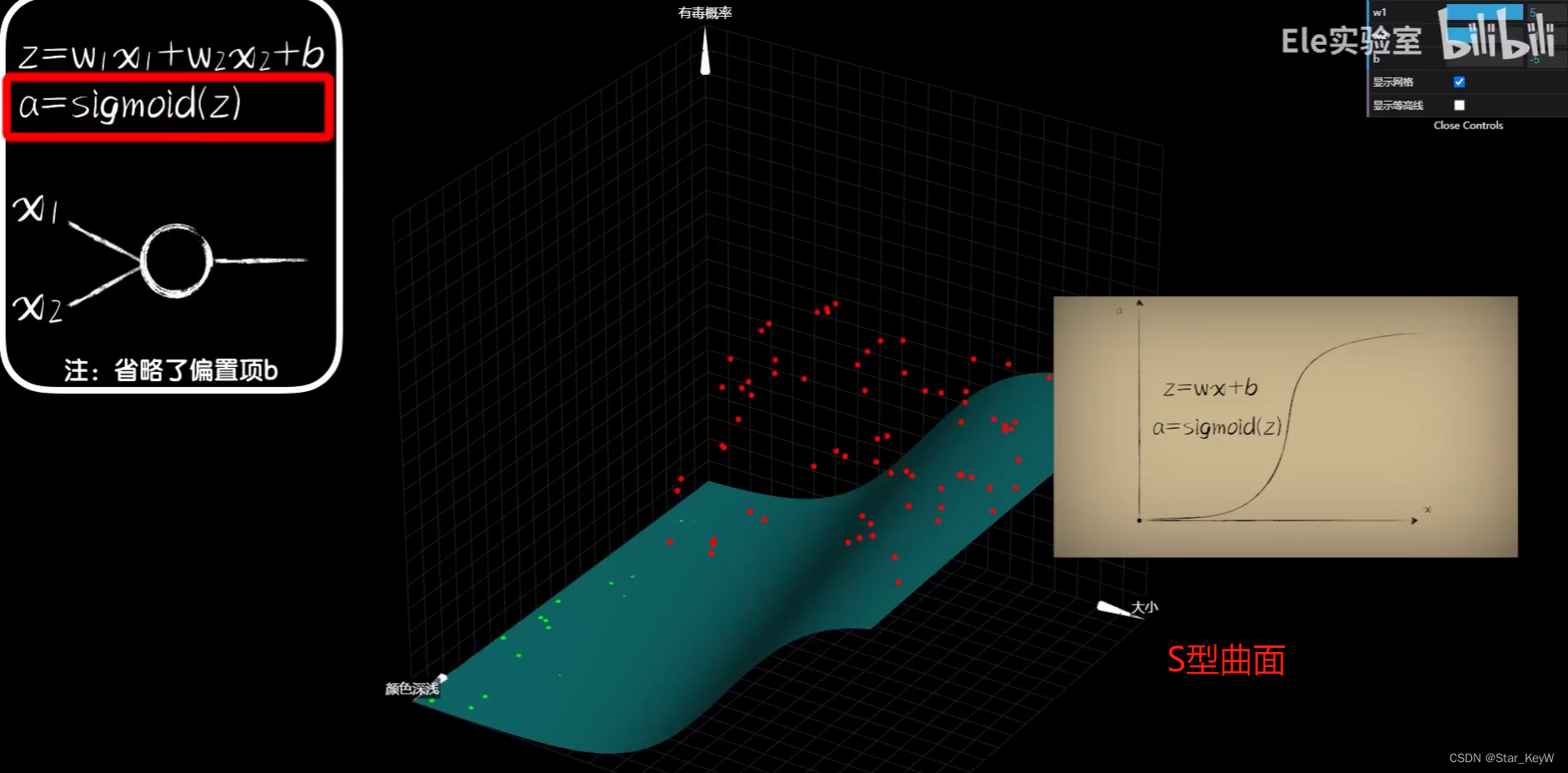
豆豆的毒性不仅和它的大小有关,也和它的颜色深浅有关系。这时就不能仅靠一个二维平面坐标系,就需要一个三维的空间坐标系。神经元也需要2个树突来接收输入。同时,过去的一元一次函数就需要变为-->二元一次函数,“颜色深浅”成为了另外一个“元”。
二元一次函数在三维空间中,是一个平面。套上一层sigmoid激活函数后,就形成了曲面。
表示当大小和颜色深浅去某个值时,对有毒概率的预测结果。
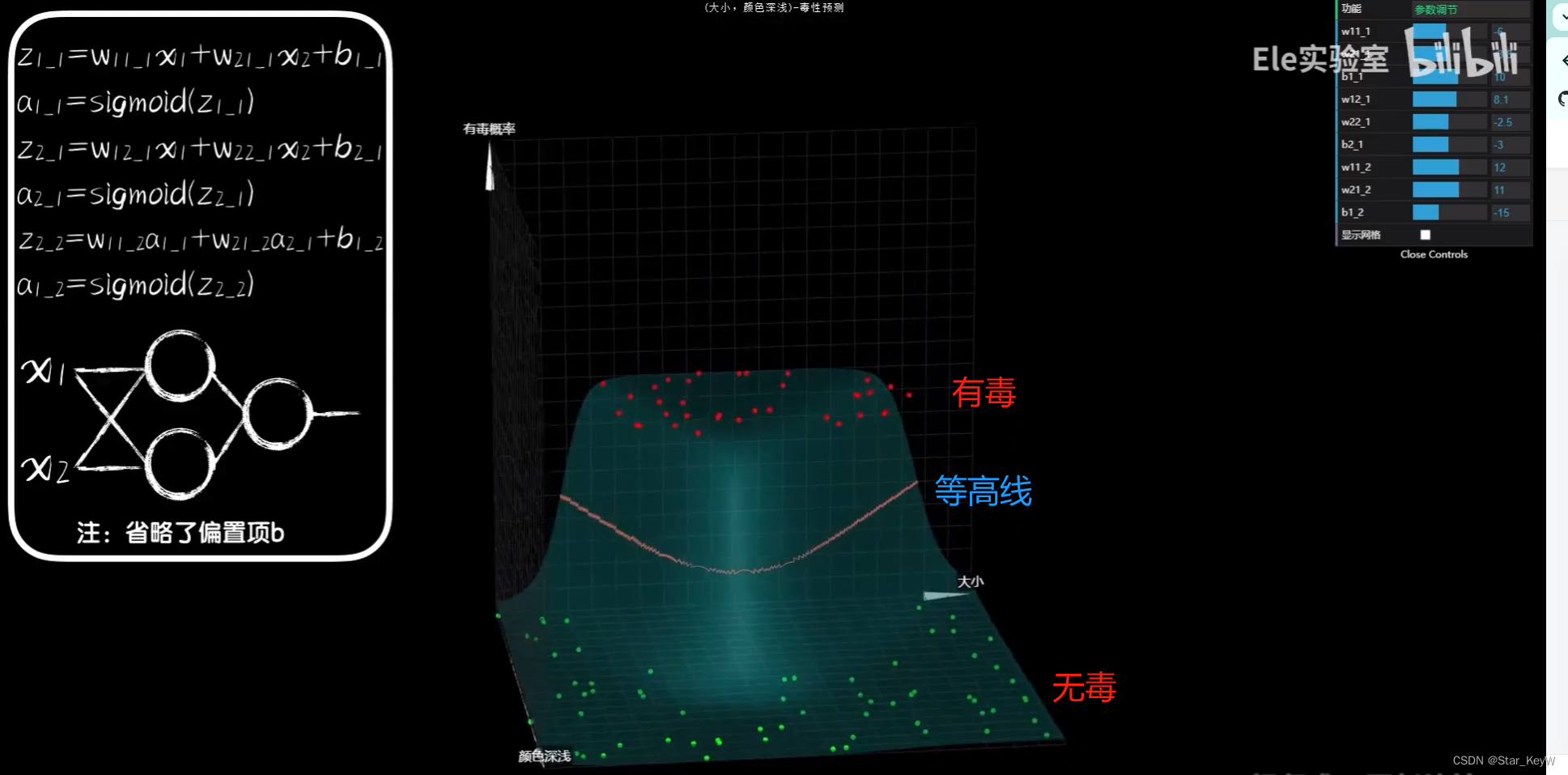
引入隐藏层神经元后,就可以扭曲三维空间中的面,让其组合出不同的曲面。
(二)数据特征维度
当问题数据特征越来越多,也就是说,我们采集豆豆的更多特征,eg:除了大小和颜色深浅以外,再加入一个外壳硬度作为输入数据时,我们就只能再添加一个维度去描述预测模型的图像。需要在四维空间作图。
输入数据有多少种类别,也就是所谓的特征维度,也叫数据维度(数据特征维度)。实际上我们把豆豆的特征提取越多,也就是我们从更多维去观察问题,也就能更好地预测它的毒性。
当输入数据的维度越来越多时,权重参数也越来越多。一个一个地去编写它们的函数表达式未免有点麻烦和拖沓。
二、编程实验--接收2个输入的神经元

(一)观察数据
import numpy as np
import dataset
# 封装了绘图工具
import plot_utils
# 获取豆豆数据
num = 100
# xs是一个二维数组,表示输入数据的2个特征维度
# ys仍然是一维数组,0和1,代表每个豆豆是否有毒,0表示无毒、1表示有毒
xs, ys = dataset.get_beans(num)
# 绘制数据的散点图
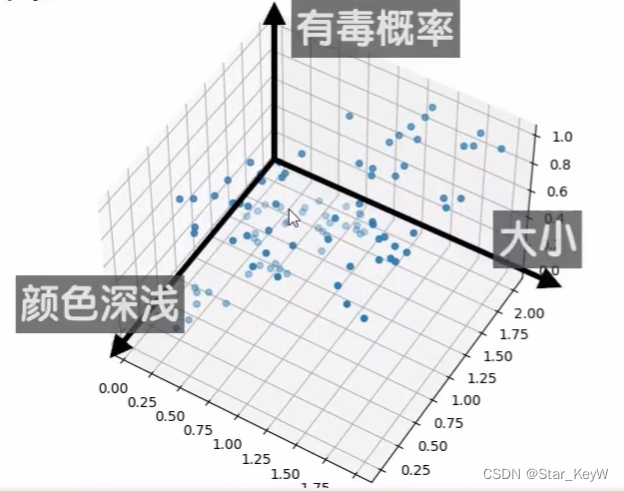
plot_utils.show_scatter(xs, ys)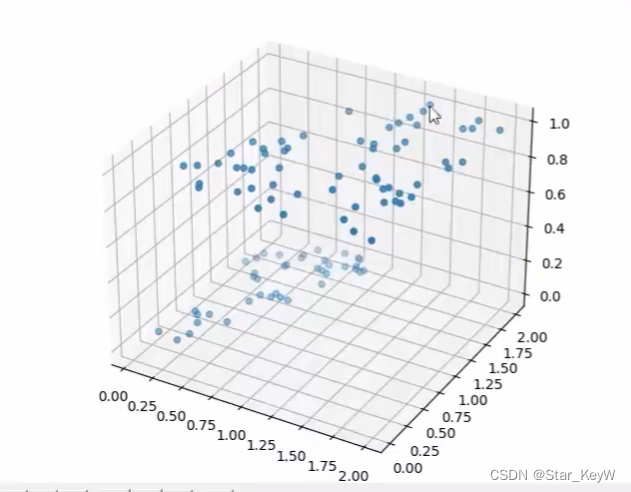
(二)编写预测模型
# 编写预测模型
# 因为有2个树突,所以输入和神经元之间有2个权重参数
w1 = 0.1
w2 = 0.1
b = 0.1(三)前向传播
# 编写前向传播代码
# 豆豆大小数据,在所有的行上,把第0列切割下来形成一个新的数组
x1s = xs[:, 0]
# 豆豆颜色数据,在所有的行上,把第1列切割下来形成一个新的数组
x2s = xs[:, 1]
# 前向传播
def forward_propagation(x1s, x2s):
z = w1 * x1s + w2 * x2s + b
a = 1 / (1 + np.exp(-z))
return a
# 同时画出豆豆的散点图和预测曲面
plot_utils.show_scatter_surface(xs, ys, forward_propgation)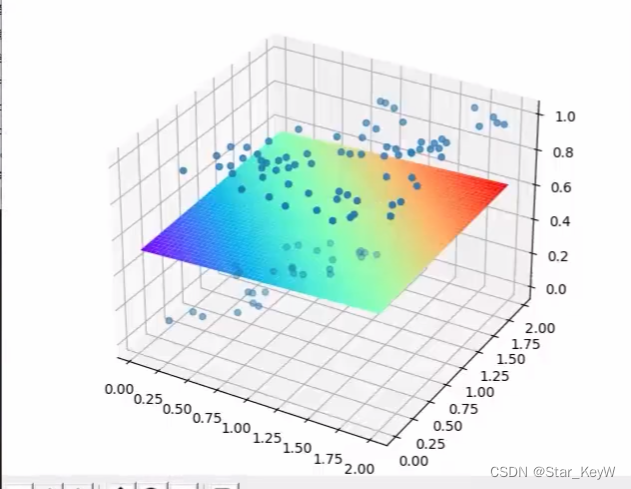
(四)反向传播+随机梯度下降
for _ in range(5000):
for i in range(num):
x = xs[i]
y = ys[i]
x1 = x[0]
x2 = x[1]
a = forward_propagation(x1, x2)
e = (y - a)**2
deda = -2 * (y - a)
dadz = a * (1 - a)
dzdw1 = x1
dzdw2 = x2
dzdb = 1
dedw1 = deda * dadz * dzdw1
dedw2 = deda * dadz * dzdw2
dedb = deda * dadz * dzdb
alpha = 0.0.1
w1 = w1 - alpha * dedw1
w2 = w2 - alpha * dedw2
b = b - alpha * dedb
plot_utils.show_scatter_surface(xs, ys, forward_propgation) 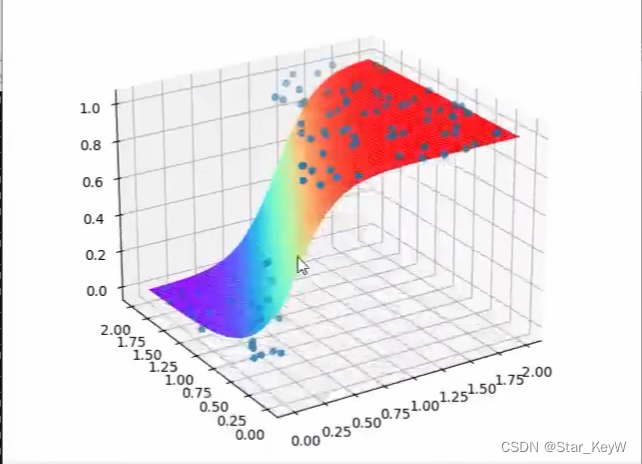



![flask之ssti [WesternCTF2018]shrine1](https://img-blog.csdnimg.cn/direct/9db481941a844b6da32e8093be44f411.png)