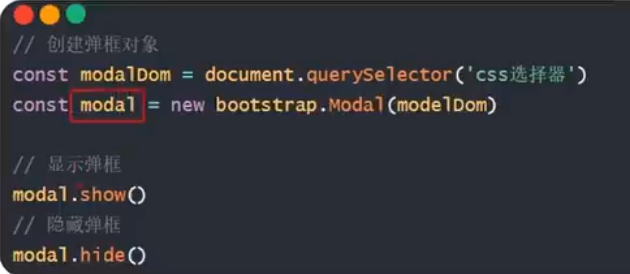
目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
4.1 网络架构与特征提取
4.2 输出表示
4.3损失函数设计
4.4预测阶段
5.算法完整程序工程
1.算法运行效果图预览






2.算法运行软件版本
matlab2022a
3.部分核心程序
load yolov2.mat% 加载训练好的目标检测器
img_size= [224,224];
imgPath = 'test/'; % 图像库路径
imgDir = dir([imgPath '*.jpg']); % 遍历所有jpg格式文件
cnt = 0;
for i = 1:8 % 遍历结构体就可以一一处理图片了
i
if mod(i,1)==0
figure
end
cnt = cnt+1;
subplot(1,1,cnt);
img = imread([imgPath imgDir(i).name]); %读取每张图片
I = imresize(img,img_size(1:2));
[bboxes,scores] = detect(detector,I,'Threshold',0.15);
if ~isempty(bboxes) % 如果检测到目标
I = insertObjectAnnotation(I,'rectangle',bboxes,scores,LineWidth=2);% 在图像上绘制检测结果
end
subplot(1,1,cnt);
imshow(I, []); % 显示带有检测结果的图像
pause(0.01);% 等待一小段时间,使图像显示更流畅
if cnt==1
cnt=0;
end
end
113
4.算法理论概述
YOLOv2是由Joseph Redmon等人在2016年提出的实时目标检测算法,其核心理念是在单个神经网络中一次性完成对整幅图像的预测。对于人脸检测任务,YOLOv2通过端到端的学习,能够在整个图像上直接预测出人脸的位置和大小。
4.1 网络架构与特征提取
YOLOv2基于Darknet-19卷积神经网络进行特征提取,该网络包含19层卷积操作,用于从输入图像中提取丰富的特征信息。每个卷积层后可能跟随批量归一化层(Batch Normalization)、Leaky ReLU激活函数等组件以提升网络性能。
4.2 输出表示
YOLOv2将图像划分为S×S 的网格(例如7×77×7)。对于每个网格单元,网络预测多个边界框(BoundingBox, BBox),每个BBox由以下五部分组成:

其中,
- x,y 是相对于网格单元左上角的预测框中心的偏移量。
- ℎw,h 是预测框的宽度和高度(相对于整幅图像的比例)。
- c 是置信度得分,表示预测框内包含人脸的概率以及预测框与真实框的IOU(Intersection over Union)。
此外,对于每一个预测框,还会预测一个额外的变量集合,代表人脸类别的条件概率:
![]()
即在给定框内存在目标的情况下,是人脸的概率。
4.3损失函数设计
YOLOv2使用多任务损失函数,包括定位误差、置信度误差和分类误差三部分:
定位误差:采用平方误差来计算预测框位置与实际框位置之间的差距。
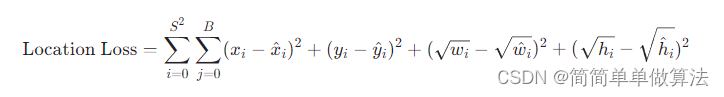
置信度误差:对于每个预测框,计算的是包含物体且预测框与实际框重合程度(IOU)较高的置信度损失,未包含物体的预测框则计算背景的置信度损失。
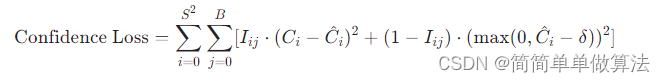
其中,Iij 是指示符函数,当第 i 个网格的第 j 个框包含物体时为1,否则为0;Ci 和 C^i 分别是预测置信度和实际置信度;δ 是一个小阈值。
分类误差:仅针对那些包含物体的预测框计算交叉熵损失。
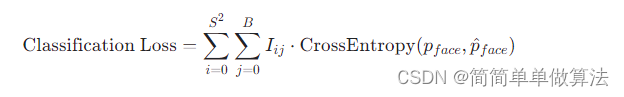
4.4预测阶段
在推理阶段,首先根据阈值筛选掉置信度较低的预测框,并对剩余框进行非极大抑制(Non-Maximum Suppression, NMS)处理,去除冗余预测,最终得到图像中的人脸检测结果。
5.算法完整程序工程
OOOOO
OOO
O