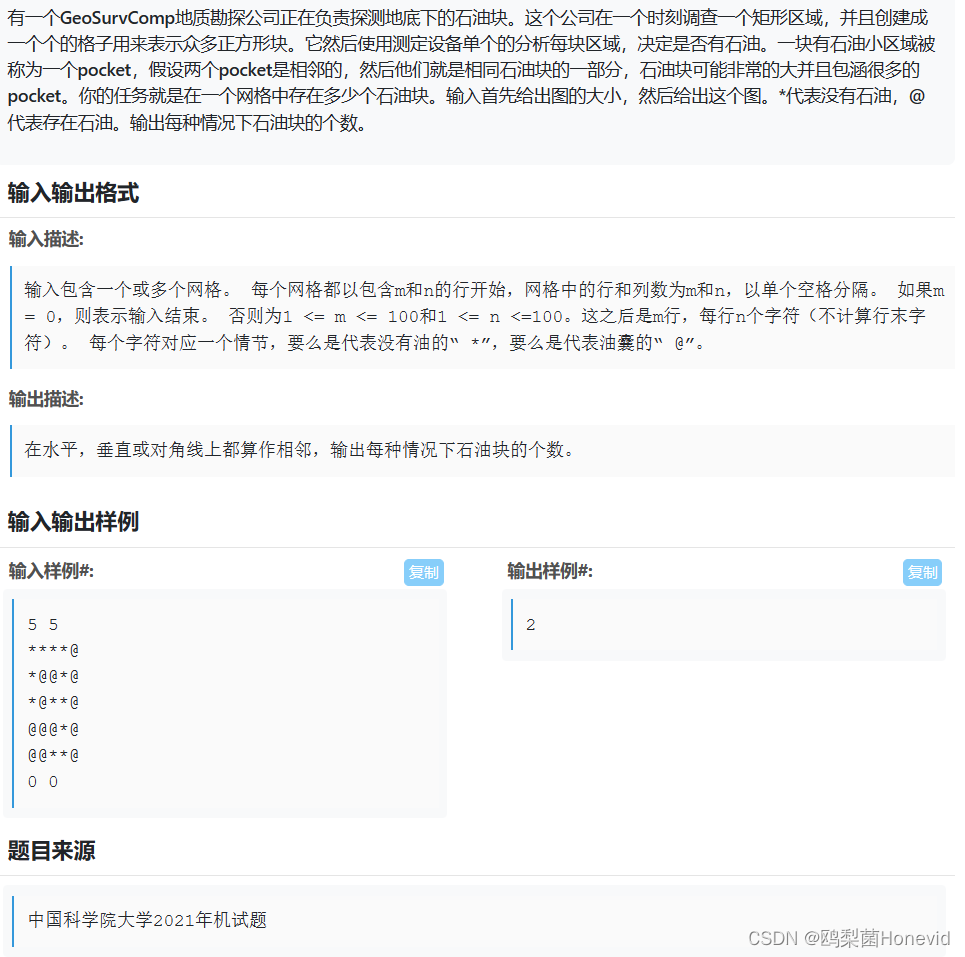
大型语言模型的目标是理解和生成与人类语言类似的文本。它们经过大规模的训练,能够对输入的文本进行分析,并生成符合语法和语境的回复。这种模型可以用于各种任务,包括问答系统、对话机器人、文本生成、翻译等。
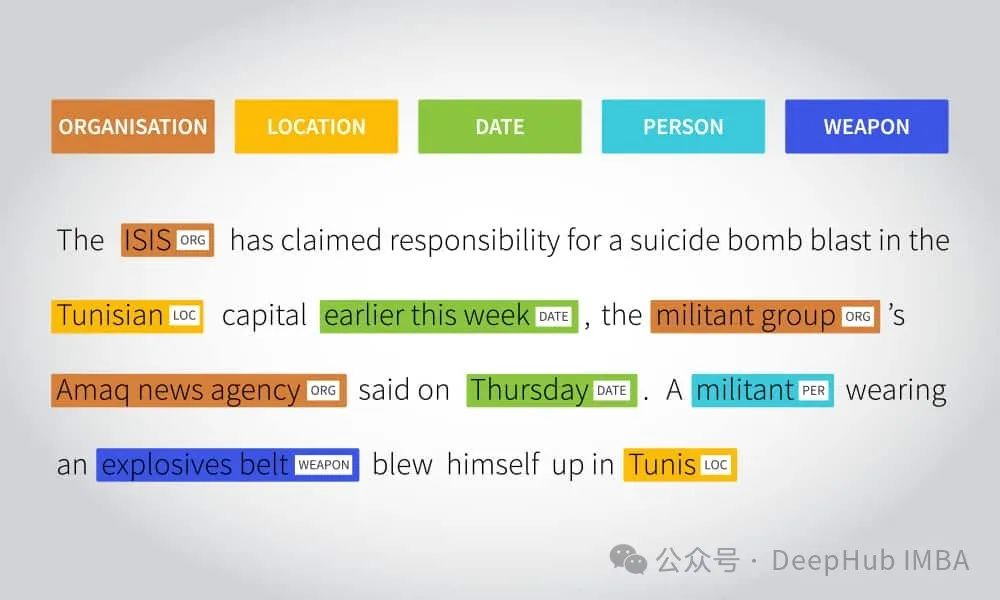
命名实体识别(Named Entity Recognition,简称NER)是一种常见的应用方法,可以让模型学会识别文本中的命名实体,如人名、地名、组织机构名等。
大型语言模型在训练时通过大量的文本数据学习了丰富的语言结构和上下文信息。这使得模型能够更好地理解命名实体在文本中的上下文,提高了识别的准确性。即使模型在训练过程中没有见过某个命名实体,它也可以通过上下文推断该实体的类别。这意味着模型可以处理新的、未知的实体,而无需重新训练。除此以外我们还能通过微调(fine-tuning)在特定任务上进行优化。这种迁移学习的方法使得在不同领域和任务上进行NER更加高效。
这篇文章总结了命名实体识别(NER)问题微调大型语言模型的经验。我们将以个人身份信息(PII)为例来介绍大型语言模型进行NER微调的方法。
个人可识别信息(Personal Identifiable Information,PII)
个人可识别信息(Personal Identifiable Information,PII)是指可以用于识别、联系或定位个人身份的数据或信息。这些信息可以单独使用或结合其他信息,使得可以辨认特定的个人。PII通常包括但不限于以下内容:
- 全名
- 电子邮件地址
- 身份证号码
- 驾驶证号码
- 社会安全号码
- 银行账号
- 生日
- 地址
这些信息的泄露可能会导致身份盗窃、个人隐私侵犯等问题,因此保护PII对于保障个人隐私和安全至关重要。
HIPAA隐私规定(Health Insurance Portability and Accountability Act Privacy Rules,简称HIPAA Privacy Rules)是一组法规,旨在保护医疗保健信息的隐私和安全。这些规定是由美国联邦政府颁布,适用于医疗保健提供者、健康计划、医疗支付者以及与这些实体交换医疗信息的其他组织和个人。
“Safe Harbor method” 是指在HIPAA(Health Insurance Portability and Accountability Act)隐私规定中的一种数据安全标准。这个方法允许医疗保健机构和其他涉及医疗信息的实体在某些条件下共享个人健康信息,而不会被认为违反HIPAA的隐私规定。
在Safe Harbor方法下,共享的个人健康信息必须经过匿名化处理,以使其不再能够识别特定的个人。HIPAA规定了一组特定的标识符,包括但不限于以下信息:
- 医疗记录号码
- 社会安全号码
- 驾驶证号码
- 信用卡号码
如果这些标识符被移除,或者通过某种方式使得个人健康信息无法与特定的个人相关联,那么这些信息就被视为符合Safe Harbor标准。
所以NER就派上了用武之地,可以对LLM进行微调,生成包含检测到的PII实体的结构良好的字符串,然后再进行匿名化处理来保证个人健康信息的安全性。
对大型语言模型进行微调
微调LLM主要有以下2个方面的挑战:
调优的LLM不应该产生命名实体的幻觉。应该从一组受控的实体标签中进行检测。
微调LLM应该生成结构良好的输出。LLM输出不应包含无关信息(例如,解释为什么检测到某些实体)。因为输出中的额外令牌导致每个输入的推理成本更高。并且下游任务也无法使用。
所以我们就先格式化训练数据
一个典型的NER输入和输出格式如下。
# INPUT
test_example="My name is John Doe and I can be contacted at 111-222-3334"
# GROUND TRUTH NER DETECTIONS
test_detections= [
{
"entity_type": "PERSON",
"entity_value": "John Doe",
"start_position": 11,
"end_position": 19,
},
{
"entity_type": "PHONE_NUMBER",
"entity_value": "111-222-3334",
"start_position": 46,
"end_position": 58,
}
]
输出数据可以通过多种方式进行格式化。对于典型的NER数据集,广泛采用BIO格式。
BIO 格式是命名实体识别(Named Entity Recognition,NER)任务中常用的标注格式,用于标记文本中的命名实体。BIO 格式包括三种标记:B、I 和 O。
- B(Beginning):表示一个命名实体的开头。
- I(Inside):表示一个命名实体的内部。
- O(Outside):表示不是命名实体的词。
## BIO Tags for sentence - Alex is going to Los Angeles in California
Alex I-PER
is O
going O
to O
Los I-LOC
Angeles I-LOC
in O
California I-LOC
BIO格式是非常具体的。它需要理解标记是特定实体标签的“内部”(I)和“外部”(O)。并且还要标识出实体标签开始的字符,这会在制定LLM任务描述提示时增加不必要的复杂性。
我们可以尝试了以下两种输出格式
# JSON encoded string with NER detections
llm_output_str = "[{\"entity_type\": \"PERSON\",\"entity_value\": \"John Doe\",\"start_position\": 11,\"end_position\": 19,},{\"entity_type\": \"PHONE_NUMBER\",\"entity_value\": \"111-222-3334\",\"start_position\": 46,\"end_position\": 58}]"
这些字符串看起来与一般的NER数据完全相同。无需对LLM输出进行任何额外的数据处理。并且我们可以直接使用json.loads(llm_output_str)来读取模型的输出。
但是这里我们必须要保证模型输出必须为正确的JSON编码字符串,并且还要记录字符串在输入的位置,这对于模型来说是有点困难的。
或者我们让模型直接将NER的标签进行标记,比如:
llm_output_str = "My name is <PERSON>John Doe</PERSON> and I can be contacted at <PHONE_NUMBER>111-222-3334</PHONE_NUMBER>"
让模型在输入中包含相关的<ENTITY_LABEL> </ENTITY_LABEL>标记,这样对于我们查看结果是非常方便的,但是对于编码来说还必须对LLM生成的输出进行后期处理,解析检测到的实体的实体以及开始和结束字符索引,这会增加我们的代码量。并且这种方法我们需要保证在输出时没有任何令牌产生幻觉,而且输入中的所有字符、标点和词序都需要保留,这对于LLM来说也有一些困难。
那么我们选择哪一个呢?在本文的最后,我们将看到哪种格式的输出字符串效果更好。
提示设计
现在我们有了输入和输出数据格式,下面就需要设计一个向LLM描述任务的提示符。提示设计是非常非常重要的,这回影响到LLM的输出
《 QUANTIFYING LANGUAGE MODELS’ SENSITIVITY TO SPURIOUS FEATURES IN PROMPT DESIGN or: How I learned to start worrying about prompt formatting》论文讨论了提示对于模型性能的变化,有兴趣的可以看看

对于任务描述,我们使用单独提示来生成json和格式的输出字符串。对于生成json字符串的模型,使用了以下任务描述
You are given a user utterance that may contain Personal Identifiable
Information (PII). You are also given a list of entity types representing
personal identifiable information (PII). Your task is to detect and identify
all instances of the supplied PII entity types in the user utterance. Provide
a JSON output with keys: 'entity_type' (label of the detected entity),
'entity_value' (actual string value of the entity), 'start_position'
(start character index of the entity in the user utterance string), and
'end_position' (end character index of the entity in the user utterance string)
Ensure accuracy in identification of entities with correct start_position and
end_position character indices. Ensure that all entities are identified. Do
not perform false identifications.
对于输出字符串,我使用了以下任务描述
You are given a user utterance that may contain Personal Identifiable
Information (PII). You are also given a list of entity types representing
Personal Identifiable Information (PII). Your task is to detect and identify
all instances of the supplied PII entity types in the user utterance.
The output must have the same content as the input. Only the tokens that match
the PII entities in the list should be enclosed within XML tags. The XML tag
comes from the PII entities described in the list below. For example, a name
of a person should be enclosed within <PERSON></PERSON> tags. Ensure that all
entities are identified. Do not perform false identifications.
提示还需要包含实体类型及其描述的列表,以确保模型只检测来自受控标签列表的实体。我选择了下面的模板
List Of Entities
PERSON: Name of a person
Rx_NUMBER: Number identifying a medical prescription
ORDER_NUMBER: Number identifying a retail order
EMAIL_ADDRESS: Email address
PHONE_NUMBER: Telephone or mobile number
DATE_TIME: Dates and Times
US_SSN: Social Security Number in the United States
我们针对上面的提示进行以下的测试
## Few shot example input
"My name is John Doe and I can be contacted at 111-222-3334"
## Few shot example output
"My name is <PERSON>John Doe</PERSON> and I can be contacted at <PHONE_NUMBER>111-222-3334</PHONE_NUMBER>"
## Actual input
"My phone number is 222-333-4445 and my name is Ana Jones"
## Incorrect Model output - model rephrases the output to match closer to few shot example output
"My name is <PERSON>Ana Jones</PERSON> and my phone number is <PHONE_NUMBER>222-333-4445</PHONE_NUMBER>"
## What model should have generated
"My phone number is <PHONE_NUMBER>222-333-4445</PHONE_NUMBER> and my name is <PERSON>Ana Jones</PERSON>"
我们可以非常明显的看到模型输出中生成虚假的标记,实体都已经区分出来了,但是位置变了。我们可以在prompt中加入一些少样本的示例来让模型强制学习,但是这回增加prompt的输入令牌数。
在提示中加入Chain-Of-Thought
除了在会话中嵌入少样本示例外,我们还可以让模型以简洁的方式重新描述指令。这加强了模型对任务的理解,可以获得更好、更一致的格式化输出。我还让模型向我“解释”,给定任务描述,为什么示例输入和输出是有意义的。比如说以下的提示
# First user message
usr_msg1="""
You are given a user utterance that may contain Personal Identifiable
Information (PII). You are also given a list of entity types representing
Personal Identifiable Information (PII). Your task is to detect and identify
all instances of the supplied PII entity types in the user utterance.
The output must have the same content as the input. Only the tokens that match
the PII entities in the list should be enclosed within XML tags. The XML tag
comes from the PII entities described in the list below. For example, a name
of a person should be enclosed within <PERSON></PERSON> tags. Ensure that all
entities are identified. Do not perform false identifications.
List Of Entities
PERSON: Name of a person
Rx_NUMBER: Number identifying a medical prescription
ORDER_NUMBER: Number identifying a retail order
EMAIL_ADDRESS: Email address
PHONE_NUMBER: Telephone or mobile number
DATE_TIME: Dates and Times
US_SSN: Social Security Number in the United States
Are the instructions clear to you?
"""
# First assistant message which is a reply to usr_msg1
# I hardcode this msg once the model produced a resonably good response.
# Note that the response comes from a non-fine-tuned version of the model.
# The idea is to sample a good 'thought' from the base version of the model.
asst_msg1="""
Yes, the instructions are clear. I will identify and enclose within the
corresponding XML tags, all instances of the specified PII entity types in
the user utterance. For example, <PERSON><Name of a person></PERSON>,
<Rx_NUMBER><Number identifying a medical prescription></Rx_NUMBER>, etc.
leaving the rest of the user utterance unchanged.
"""
# Here I hardcode a few shot example as a user message
usr_msg2="""
My name is John Doe, and can be contacted at 111-222-3334
"""
# Here I hardcode the appropriate response from the assitant as the
# correct output of the few shot example
asst_msg2="""
My name is <PERSON>John Doe</PERSON>, and can be contacted at <PHONE_NUMBER>111-222-3334</PHONE_NUMBER>
"""
# Here I ask the assistant why its response to the last user message was the
# correct response
usr_msg3="""
Give a brief explanation of why your answer is correct.
"""
# I hardcode the explaination from the model.
# Note that the explaination comes from a non-fine-tuned version of the model
asst_msg3="""
I identified and enclosed within corresponding XML tags, all instances of
the specified PII entity types in the user utterance - a Person Name
"John Doe" within the <PERSON></PERSON> tag, and a Phone Number
"111-222-3334" within the <PHONE_NUMBER></PHONE_NUMBER> tag.
The rest of the user utterance was left unchanged as it did not contain any
other identified PII entities.
"""
# The rest of the user and assistant msgs are hardcoded so that the model is
# in a state where it expects another input from the user
usr_msg4="""
Great! I am now going to give you another user utterance. Please
detect PII entities in it according to the previous instructions. Do
not include an explanation in your answer.
"""
asst_msg4="""
Sure! Please give me the user utterance.
"""
# usr_msg5 would be the actual input string on which we want to detect the
# PII entities
创建完整训练数据文件的样例函数如下所示
def get_fine_tune_prompt_xml(
rule_set: List[str],
input_str: str,
label_str: str,
tokenizer: PreTrainedTokenizerBase,
) -> torch.Tensor:
"""
Args:
rule_set (List[str]): List of strings representing entity labels and its
corresponding description
input_str (str): Actual input string on which detections need to be
performed
label_str (str): Expected output string corresponding to input_str
tokenizer (PreTrainedTokenizerBase): A tokenizer corresponding to the model
being fine-tuned
Returns:
torch.Tensor: Tensor of tokenized input ids
"""
rule_str = "\n".join(rule_set)
usr_msg1 = "You are given a user utterance that may contain Personal Identifiable Information (PII). " \
"You are also given a list of entity types representing Personal Identifiable Information (PII). " \
"Your task is to detect and identify all instances of the supplied PII entity types in the user utterance. " \
"The output must have the same content as the input. Only the tokens that match the PII entities in the " \
"list should be enclosed within XML tags. The XML tag comes from the PII entities described in the list below. " \
"For example, a name of a person should be enclosed within <PERSON></PERSON> tags." \
"Ensure that all entities are identified. Do not perform false identifications." \
f"""\n\nList Of Entities\n{rule_str}"""\
"\n\n" \
"Are the instructions clear to you?"
asst_msg1 = "Yes, the instructions are clear. I will identify and enclose within the corresponding XML tags, " \
"all instances of the specified PII entity types in the user utterance. For example, " \
"<PERSON><Name of a person></PERSON>, <Rx_NUMBER><Number identifying a medical prescription></Rx_NUMBER>, etc. " \
"leaving the rest of the user utterance unchanged."
usr_msg2 = "My name is John Doe, and can be contacted at 111-222-3334"
asst_msg2 = "My name is <PERSON>John Doe</PERSON>, and can be contacted at <PHONE_NUMBER>536-647-8464</PHONE_NUMBER>"
usr_msg3 = "Give a brief explanation of why your answer is correct."
asst_msg3 = "I identified and enclosed within corresponding XML tags, all instances of the specified PII " \
"entity types in the user utterance - a Person Name \"John Doe\" within the <PERSON></PERSON> tag, and " \
"a Phone Number \"536-647-8464\" within the <PHONE_NUMBER></PHONE_NUMBER> tag. The rest of the user " \
"utterance was left unchanged as it did not contain any other identified PII entities."
usr_msg4 = "Great! I am now going to give you another user utterance. Please detect PII entities in it " \
"according to the previous instructions. Do not include an explanation in your answer."
asst_msg4 = "Sure! Please give me the user utterance."
messages = [
{"role": "user", "content": usr_msg1},
{"role": "assistant", "content": asst_msg1},
{"role": "user", "content": usr_msg2},
{"role": "assistant", "content": asst_msg2},
{"role": "user", "content": usr_msg3},
{"role": "assistant", "content": asst_msg3},
{"role": "user", "content": usr_msg4},
{"role": "assistant", "content": asst_msg4},
{"role": "user", "content": input_str},
{"role": "assistant", "content": label_str},
]
encoded_input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt")
return encoded_input_ids
函数的输出如下所示
<s> [INST] You are given a user utterance that may contain Personal Identifiable Information (PII). You are also given a list of entity types representing Personal Identifiable Information (PII). Your task is to detect and identify all instances of the supplied PII entity types in the user utterance. The output must have the same content as the input. Only the tokens that match the PII entities in the list should be enclosed within XML tags. The XML tag comes from the PII entities described in the list below. For example, a name of a person should be enclosed within <PERSON></PERSON> tags. Ensure that all entities are identified. Do not perform false identifications.
List Of Entities
PERSON: Name of a person
Rx_NUMBER: Number identifying a medical prescription
ORDER_NUMBER: Number identifying a retail order
EMAIL_ADDRESS: Email address
PHONE_NUMBER: Telephone or mobile number
DATE_TIME: Dates and Times
US_SSN: Social Security Number in the United States
Are the instructions clear to you? [/INST]Yes, the instructions are clear. I will identify and enclose within the corresponding XML tags, all instances of the specified PII entity types in the user utterance. For example, <PERSON><Name of a person></PERSON>, <Rx_NUMBER><Number identifying a medical prescription></Rx_NUMBER>, etc. leaving the rest of the user utterance unchanged.</s> [INST] My name is John Doe, and can be contacted at 111-222-3334 [/INST]My name is <PERSON>John Doe</PERSON>, and can be contacted at <PHONE_NUMBER>111-222-3334</PHONE_NUMBER></s> [INST] Give a brief explanation of why your answer is correct. [/INST]I identified and enclosed within corresponding XML tags, all instances of the specified PII entity types in the user utterance - a Person Name "John Doe" within the <PERSON></PERSON> tag, and a Phone Number "111-222-3334" within the <PHONE_NUMBER></PHONE_NUMBER> tag. The rest of the user utterance was left unchanged as it did not contain any other identified PII entities.</s> [INST] Great! I am now going to give you another user utterance. Please detect PII entities in it according to the previous instructions. Do not include an explanation in your answer. [/INST]Sure! Please give me the user utterance.</s> [INST] Hi! is Dr. Danielle Boyd at the clinic [/INST]Hi! is Dr. <PERSON>Danielle Boyd</PERSON> at the clinic</s>
tokenizer.apply_chat_template()负责将’ [INST] ‘和’ [/INST] ‘应用于用户消息,并将’ ‘(序列令牌结束)应用于辅助消息。还要注意,标记器负责将’ '(序列的开始)标记应用到提示符的开头。这些微小的细节对模型在微调过程中是否能有效地学习和收敛有巨大的影响。
自定义损失
自回归模型(像大多数llm一样)被训练来正确预测“下一个令牌”。给定我们刚刚创建的训练数据样本和微调训练设置,模型将学习预测文本所有部分的下一个标记,即任务描述、实体列表、样本示例、会话历史中硬编码的模型思维链等。
这将使模型除了学习预测正确的结果外,还学习任务描述中的令牌分布。这使得我们的学习任务有点繁琐。我们对LLM进行微调的主要目标是为给定的输入字符串生成结构良好且正确的检测。因此,我们应该只计算输出字符串中令牌的损失。所以在我们的示例训练数据中,模型应该只计算以下令牌的损失
Hi! is Dr. <PERSON>Danielle Boyd</PERSON> at the clinic</s>
这将鼓励模型“忘记”之前的所有标记,只是“注意”主要标记并生成正确的输出字符串。我们可以使用HuggingFace的DataCollator API。
fromdataclassesimportdataclass
fromtransformers.tokenization_utils_baseimportPreTrainedTokenizerBase
fromtransformers.utilsimportPaddingStrategy
fromtypingimportAny, Callable, Dict, List, NewType, Optional, Tuple, Union
@dataclass
classCustomDataCollatorWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
tokenizer ([`PreTrainedTokenizer`] or [`PreTrainedTokenizerFast`]):
The tokenizer used for encoding the data.
padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
- `True` or `'longest'` (default): Pad to the longest sequence in the batch (or no padding if only a single
sequence is provided).
- `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
acceptable input length for the model if that argument is not provided.
- `False` or `'do_not_pad'`: No padding (i.e., can output a batch with sequences of different lengths).
max_length (`int`, *optional*):
Maximum length of the returned list and optionally padding length (see above).
pad_to_multiple_of (`int`, *optional*):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
return_tensors (`str`, *optional*, defaults to `"pt"`):
The type of Tensor to return. Allowable values are "np", "pt" and "tf".
"""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] =True
max_length: Optional[int] =None
pad_to_multiple_of: Optional[int] =None
return_tensors: str="pt"
def__call__(self, features: List[Dict[str, Any]]) ->Dict[str, Any]:
batch=self.tokenizer.pad(
features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors=self.return_tensors,
)
labels=batch["input_ids"].clone()
# Set loss mask for all pad tokens
labels[labels==self.tokenizer.pad_token_id] =-100
# Compute loss mask for appropriate tokens only
foriinrange(batch['input_ids'].shape[0]):
# Decode the training input
text_content=self.tokenizer.decode(batch['input_ids'][i][1:]) # slicing from [1:] is important because tokenizer adds bos token
# Extract substrings for prompt text in the training input
# The training input ends at the last user msg ending in [/INST]
prompt_gen_boundary=text_content.rfind("[/INST]") +len("[/INST]")
prompt_text=text_content[:prompt_gen_boundary]
# print(f"""PROMPT TEXT:\n{prompt_text}""")
# retokenize the prompt text only
prompt_text_tokenized=self.tokenizer(
prompt_text,
return_overflowing_tokens=False,
return_length=False,
)
# compute index where prompt text ends in the training input
prompt_tok_idx=len(prompt_text_tokenized['input_ids'])
# Set loss mask for all tokens in prompt text
labels[i][range(prompt_tok_idx)] =-100
# print("================DEBUGGING INFORMATION===============")
# for idx, tok in enumerate(labels[i]):
# token_id = batch['input_ids'][i][idx]
# decoded_token_id = self.tokenizer.decode(batch['input_ids'][i][idx])
# print(f"""TOKID: {token_id} | LABEL: {tok} || DECODED: {decoded_token_id}""")
batch["labels"] =labels
returnbatch
CustomDataCollatorWithPadding类可以像下面这样传递给SFTTrainer
trainer=SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=eval_dataset["val"],
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
# Using custom data collator inside SFTTrainer
data_collator=CustomDataCollatorWithPadding(
tokenizer=tokenizer,
padding="longest",
max_length=max_seq_length,
return_tensors="pt"
)
)
通过将标签令牌id设置为-100,我们可以将这些令牌位置的损失归零。这意味着从序列令牌的开头()到最后一个用户msg(以[/INST]结尾)的所有令牌都不会参与损失的计算。
结果
用这个设置微调了mistral /Mistral-7B-Instruct-v0.2模型。我有大约800个训练数据样本,大约400个测试样本和大约400个验证样本。
训练了3轮的模型,并在测试集上取得了相当高的精度/召回率/F1(96%以上)。
这里说一个结果,使用字符串标注的方法超过了生成JSON编码的方法,虽然JSON的格式是正确的,但是正如我们前面所述的,在预测正确的’ start_position ‘和’ end_position '字符索引方面结果并不好。
这里我没有确认模型是否也能很好地处理BIO输出格式,我个人认为应该不会太好。
我们添加了自定义的损失掩码,这是否有助于模型更好地泛化到看不见的实体?这个也没有进行测试。
如果把7B的模型改为13B或者34B等更大的模型的性能如何变化?训练和推理的成本是否值得性能的提升?这都是我们可以继续研究的问题,如果你对NER感兴趣可以自行研究,我也会在有结果后分享我的发现。
https://avoid.overfit.cn/post/0cb82b2fee6440b6b762a23bbf85bf59
作者:Nitin Kumar