Mysql常见面试题汇总①
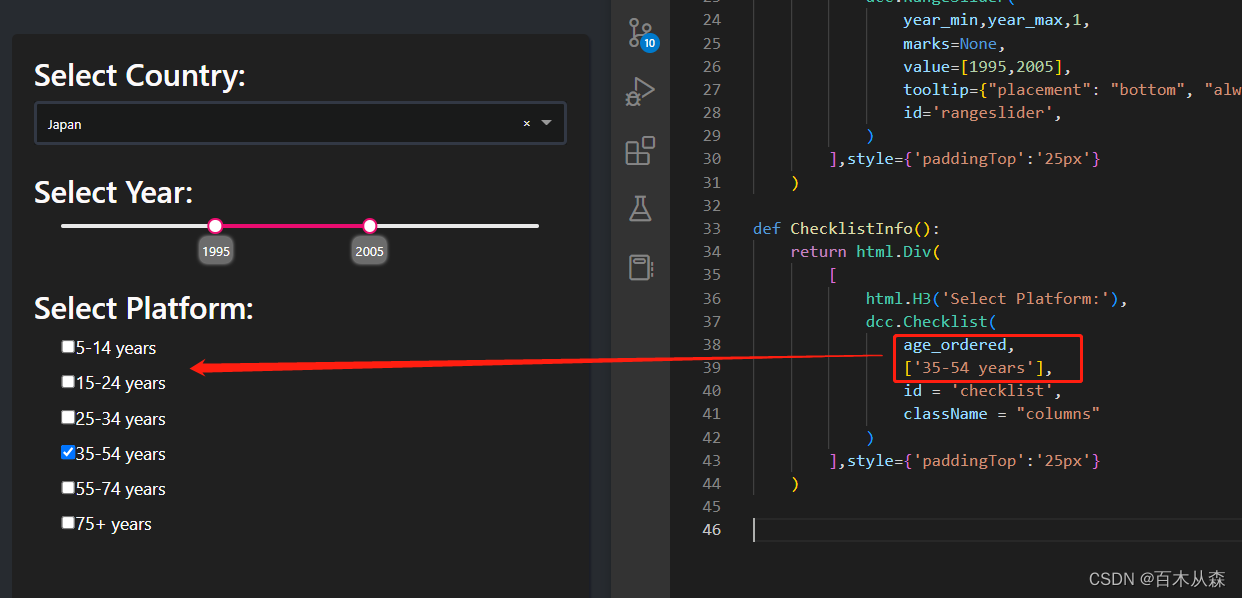
- ⭐事务的基本特性和隔离级别
- ⭐ACID靠什么保证
- ⭐什么是MVCC
- ⭐mysql的主从同步原理
- 简述MyISAM和InnoDB的区别
- 简述mysql中索引类型以及对数据库的性能影响
- ⭐索引的基本原理
- Mysql聚簇索引和非聚簇索引的区别
- ⭐B树和B+树的区别,为什么Mysql使用B+树
- Mysql索引的数据结构,各自优势
- ⭐索引设计原则
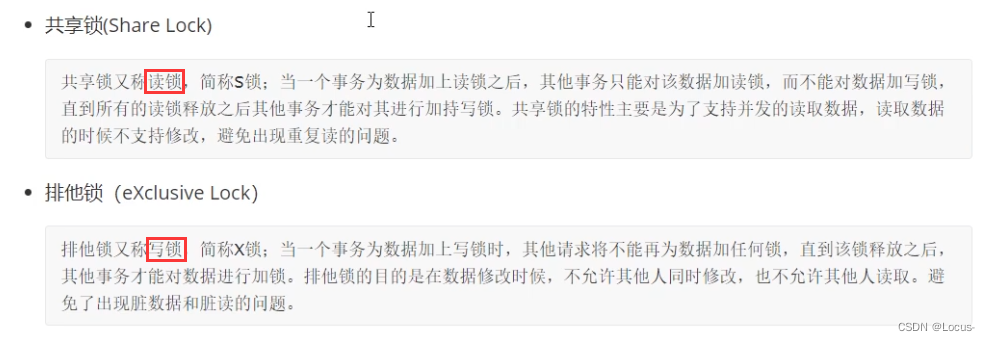
- ⭐Mysql锁的类型
- ⭐mysql执行计划怎么看
- ⭐怎么处理慢查询
- Mybatis的优缺点
- {}和${}的区别
- ⭐简述Mybatis的插件运行原理,如何编写一个插件
本文总结了目前主流平台中常见的面试题,标⭐为重点!
更多干货请点击 Locus-轨迹

⭐事务的基本特性和隔离级别


扩展:
- 脏读(Drity Read):某个事务已更新—份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后—个事务所读取的数据就会是不正确的。
- 不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
- 幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另-个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
- 不可重复读和幻读区别:不可重复读的重点是修改;同样的条件,第1次和第2次读取的值不一样。幻读的重点在于新增或者删除;同样的条件, 第1次和第2次读出来的记录数不一样。从控制角度来看,不可重复读只需要锁住满足条件的记录,幻读要锁住满足条件及其相近的记录。
⭐ACID靠什么保证
- A 原子性由undo log日志保证,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的sql
- C —致性由其他三大特性保证、程序代码要保证业务上的一致性
- l 隔离性由MVCC来保证
- D持久性由内存+redo log来保证,mysql修改数据同时在内存和redo log记录这次操作,宕机的时候可以从redolog恢复
InnoDB redo log 写盘,InnoDB,事务进入 prepare 状态。
如果前面 prepare 成功,binlog 写盘,再继续将事务日志持久化到 binlog,如果持久化成功,那么 InnoDB 事务则进入 commit 状态(在redo log里面写一个commit记录)
redolog的刷盘会在系统空闲时进行
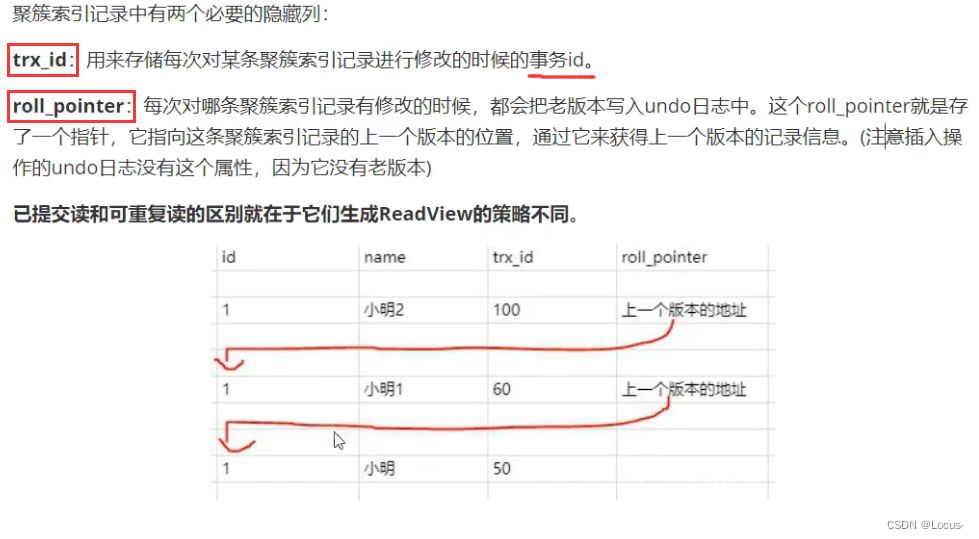
⭐什么是MVCC
MVCC就是readview+版本链
- 多版本并发控制:读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了,不同的事务session会看到自己特定版本的数据,版本链
- MVCC只在READ COMMITTED和REPEATABLE READ两个隔离级别下工作,其他两个隔离级别够和MVCC不兼容,因为READ UNCOMMITTED总是读取最新的数据行,而不是符合当前事务版本的数据行。而SERIALIZABLE则会对所有读取的行都加锁。
readview:用来存储活动事务id的排序后数组

⭐mysql的主从同步原理

由于mysql默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理,这样会产生一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。由此产生两个概念。
- 全同步复制
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方式的话性能会受到严重影响。 - 半同步复制
和全同步不同的是,半同步复制的逻辑是这样,从库写入日志成功后返回ACK确认给主库,主库收到至少一个从库的确认就认为写操作完成
简述MyISAM和InnoDB的区别
MyISAM:
- 不支持事务,但是每次查询都是原子的;
- 支持表级锁,即每次操作是对整个表加锁;
- 存储表的总行数;
- 一个MYISAM表有三个文件:索引文件、表结构文件、数据文件;
- 采用非聚集索引,索引文件的数据域存储指向数据文件的指针。辅索引与主索引基本一致,但是辅索引不用保证唯一性。
lnnoDb:
- 支持ACID的事务,支持事务的四种隔离级别;
- 支持行级锁及外键约束因此可以支持写并发;
- 不存储总行数;
- 一个InnoDb引擎存储在一个文件空间(共享表空间,表大小不受操作系统控制,一个表可能分布在多个文件里),也有可能为多个(设置为独立表空,表大小受操作系统文件大小限制,一般为2G),受操作系统文件大小的限制;
- 主键索引采用聚集索引(索引的数据域存储数据文件本身),辅索引的数据域存储主键的值;因此从辅索引查找数据,需要先通过辅索引找到主键值,再访问辅索引;最好使用自增主键,防止插入数据时,为维持B+树结构,文件的大调整。
简述mysql中索引类型以及对数据库的性能影响

⭐索引的基本原理
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。
索引的原理:就是把无序的数据变成有序的查询
- 把创建了索引的列的内容进行排序
- 对排序结果生成倒排表
- 在倒排表内容上拼上数据地址链
- 在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
Mysql聚簇索引和非聚簇索引的区别


⭐B树和B+树的区别,为什么Mysql使用B+树

Mysql索引的数据结构,各自优势
索引的数据结构和具体存储引擎的实现有关,在MySQL中使用较多的索引有Hash索引,B+树索引等,InnoDB存储引擎的默认索引实现为:B+树索引。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引
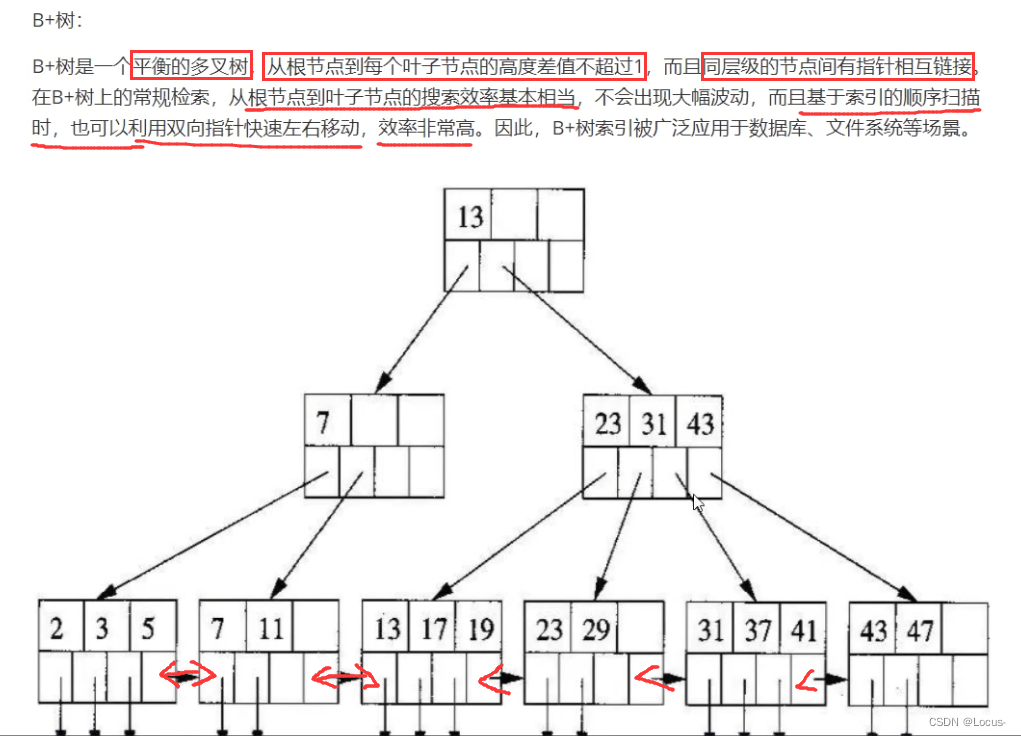
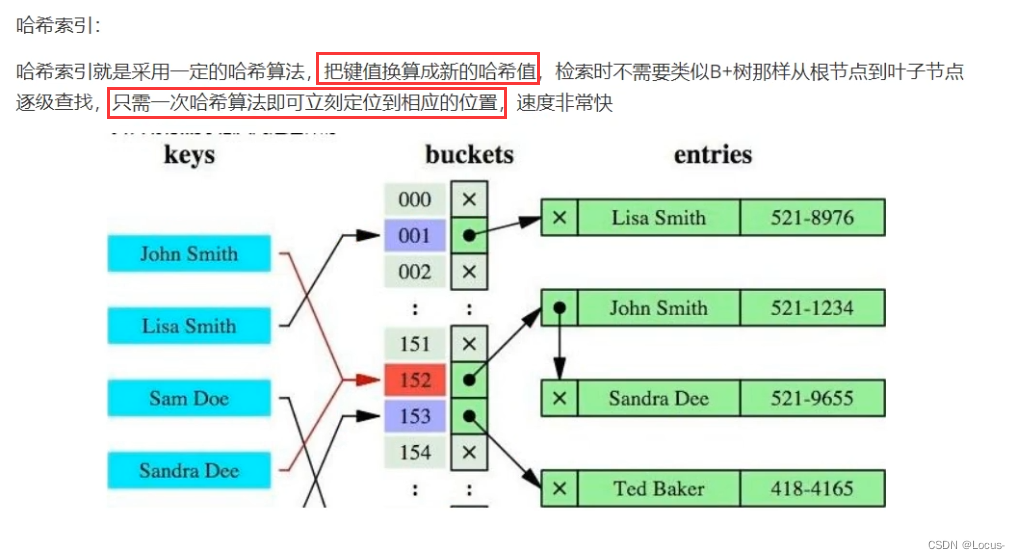
总结:
- 如果是等值查询,那么哈希索引明显有绝对优势。因为只需要经过一次算法即可找到相应的键值;前提是键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据;
- 如果是范围查询检索,这时候哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索
- 哈希索引也投办法利用索引完成排序,以及like 'xxx%'这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
- 哈希索引也不支持多列联合索引的最左匹配规则;
- B+树索引的关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在哈希碰撞问题。
⭐索引设计原则

⭐Mysql锁的类型
- 基于锁的属性分类:共享锁、排他锁。
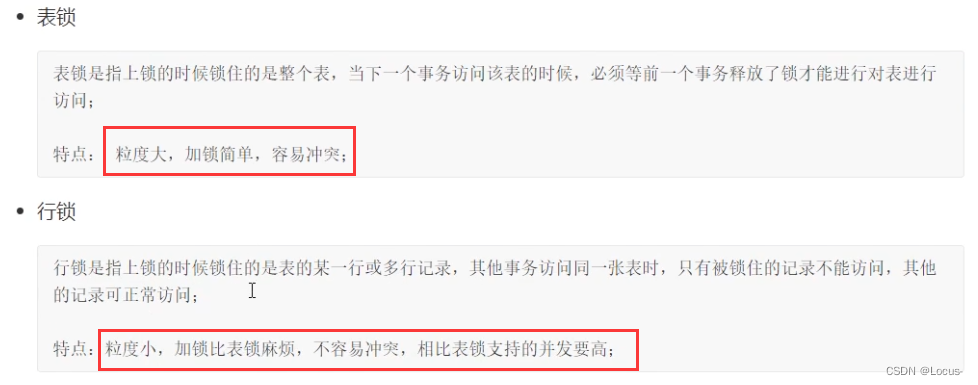
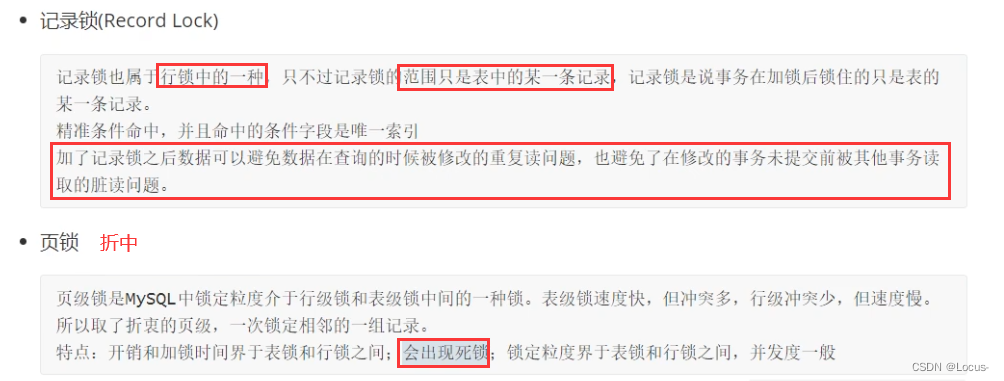
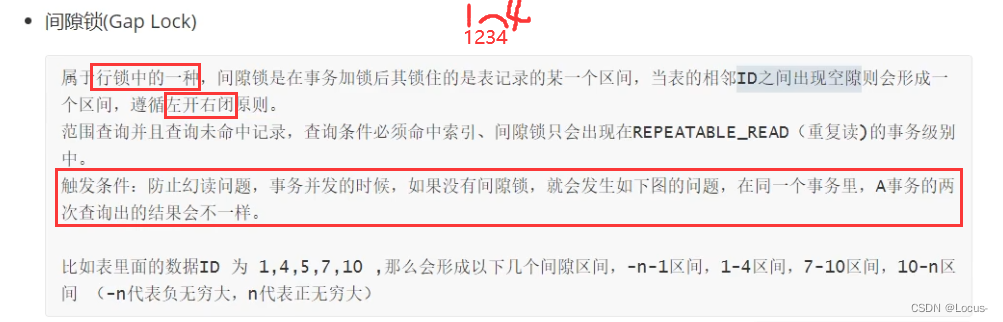
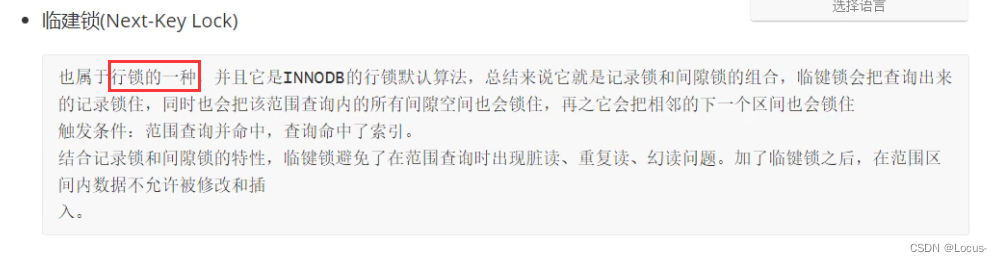
- 基于锁的粒度分类:行级锁(INNODB)、表级锁(INNODB、MYISAM)、页级锁(BDB引擎)、记录锁、间隙锁、临键锁。
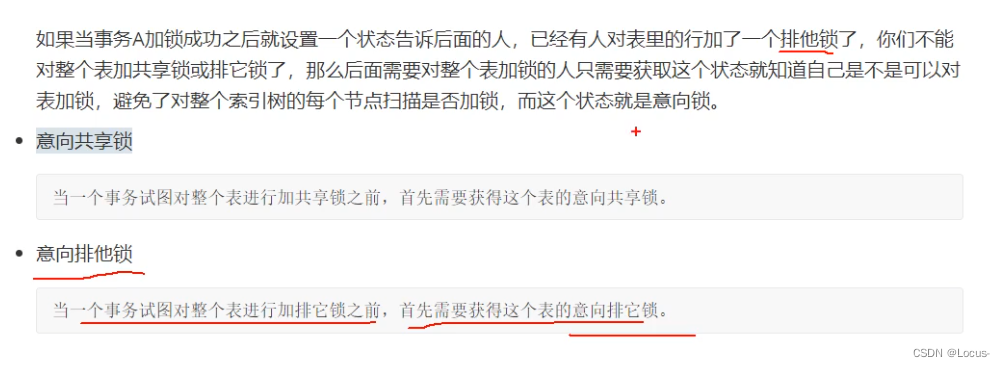
- 基于锁的状态分类:意向共享锁、意向排它锁。
基于锁的属性分类
基于锁的粒度分类
间隙锁:比如查1234.实际锁住的是234
临界锁:比如查1234.实际锁住的是1234
基于锁的状态分类:
⭐mysql执行计划怎么看
重难点



⭐怎么处理慢查询
- 在业务系统中,除了使用主键进行的查询,其他的都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。
慢查询的优化首先要搞明白慢的原因是什么:
是查询条件没有命中索引?是load了不需要的数据列?还是数据量太大?
所以优化也是针对这三个方向来的:
- 首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
- 分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
- 如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表
Mybatis的优缺点
- 优点:
- 基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用。
- 与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接;
- 很好的与各种数据库兼容(因为MyBatis 使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)。
- 能够与spring很好的集成;
- 提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护。
- 缺点:
- SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求。
- SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
{}和${}的区别

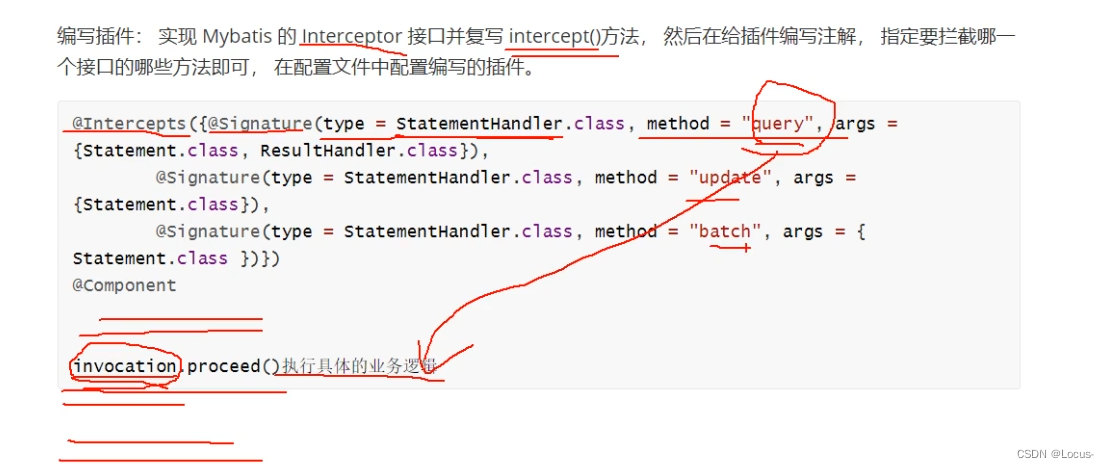
⭐简述Mybatis的插件运行原理,如何编写一个插件
Mybatis插件就是拦截器
- ParameterHandler:参数数据类型转换的工具
- ResultSetHandler:JDBC里的接口,数据库的数据映射成结果集 (映射结果)
- StatementHandler:JDBC的接口,负责设置参数,将结果集进行转换 (映射的转换动作)
- Executor:负责生成SQL语句,以及sql语句查询缓存的维护

更多干货请点击 Locus-轨迹