ConcurrentHashMap
由于HashMap在多线程的环境下有线程安全的问题,并且HashTable的性能低下,所以Java推出了ConcurrentHashMap,因此ConcurrentHashMap可以理解为线程安全并且性能较好的HashMap。
HashTable为什么慢?是因为使用了synchronized关键字对put等操作加锁,也就是说在多线程环境下,一旦一个线程对HashTable操作了,其他线程都会被阻塞
简介
JDK1.7和1.8下的ConcurrentHashMap的区别比较大,在1.7的版本下ConcurrentHashMap是由Segment + HashEntry分段锁的方式实现,但是在1.8的版本下,ConcurrentHashMap抛弃了Segment,转而拥抱了CAS+syncronized
Java7的ConcurrentHashMap
存储结构
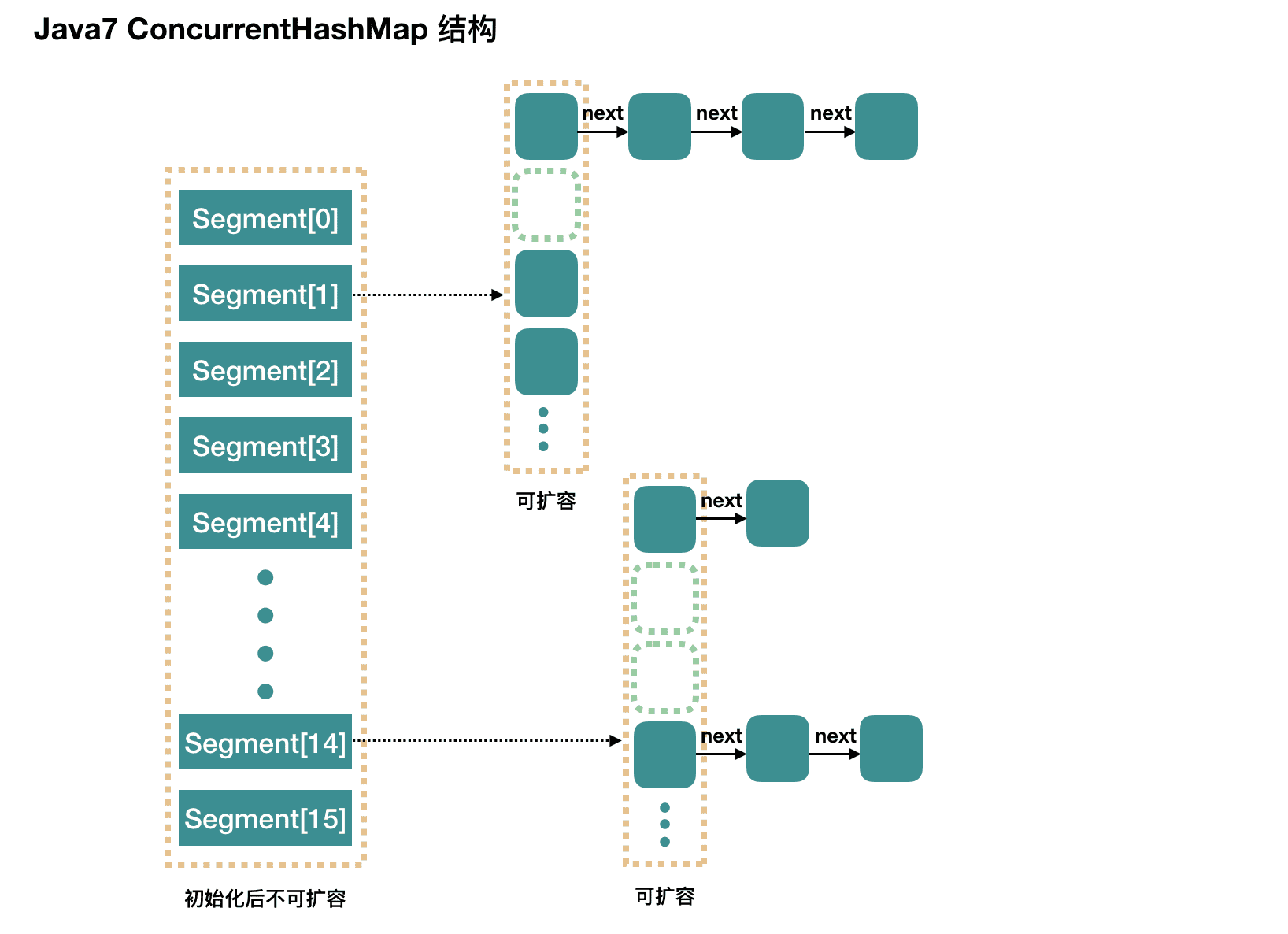
1.7版本的ConcurrentHashMap采用分段锁机制,里面包含一个Segment数组,Segment继承ReentrantLock,Segment则包含HashEntry的组数,HashEntry本身就是一个链表的结构,主要的属性有key、value以及指向下一个节点的next指针。
简单来说就是每一个Segment都是一个HashMap,默认的Segment长度是16,所以每次需要加锁的操作锁住的是一个Segment,这样只要保证每个Segment是线程安全的,也就实现了全局的线程安全,所以默认情况下ConcurrentHashMap最多支持16个线程的并发写,只要它们的操作分别分布在不同的Segment上。Segment之间相互不会受到影响
put流程
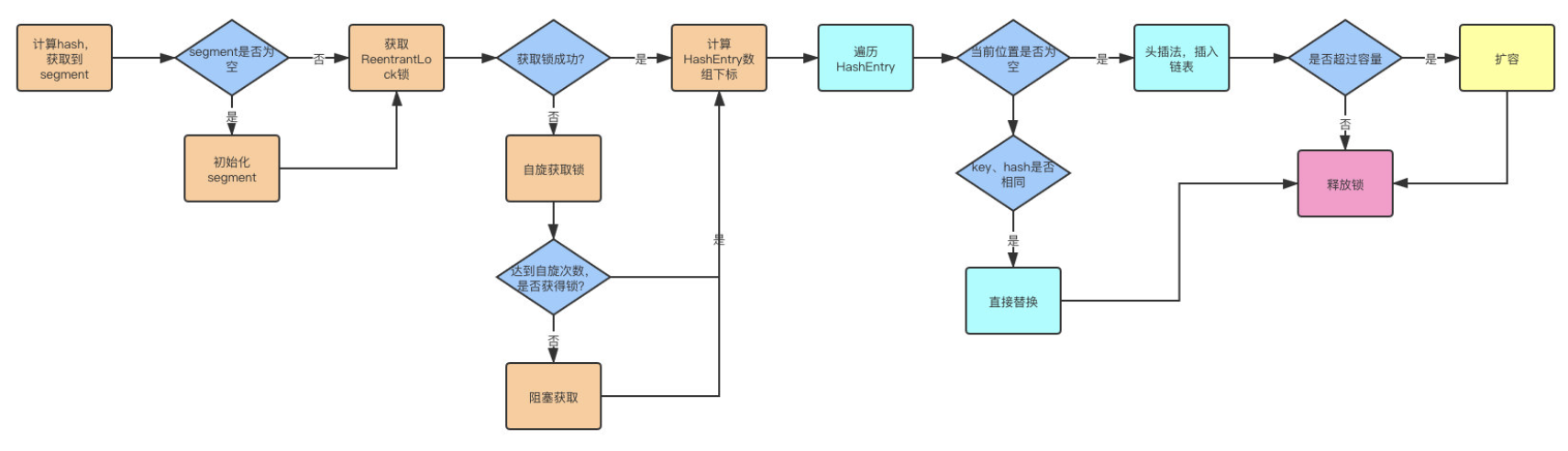
整个流程与HashMap的插入方式非常类似,只不过要先定位Segment的位置,然后通过ReentrantLock去操作而已
- 计算hash,定位到segment,segment如果是空就先初始化,但是初始化的时候需要用到CAS,防止多线程环境下重复进行初始化
- 使用ReentrantLock加锁,如果获取锁失败则尝试自旋(先不挂起线程,循环去获取锁),如果自旋超过次数就阻塞获取,保证一定获取锁成功
- 遍历HashEntry,就和HashMap一样,数组中key和hash一样就直接替换,不存在就插入链表,链表同样
get流程
get比put简单一点,key通过hash定位到segment,再遍历链表定位到具体的元素上,需要注意的是value是volatile,所以get是不需要加锁的
volatile关键字是为了保证多线程环境下,共享变量的可见性以及有序性,但是不能保证原子性;所谓可见性,就是当前线程对共享变量的修改,其他的线程可以立马看见;所谓有序性,防止多个指令之间的重排序
Java8的ConcurrentHashMap
存储结构
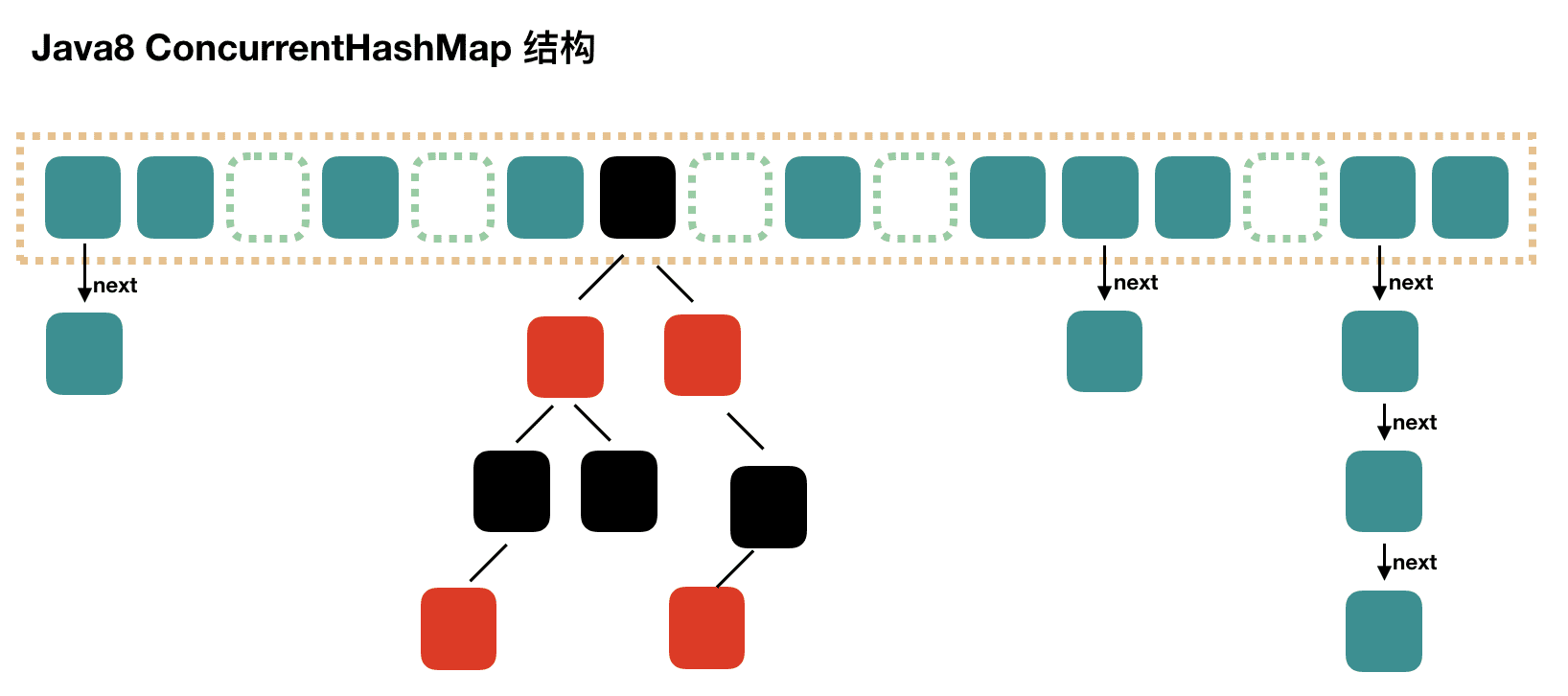
结构上和 Java8 的 HashMap 基本上一样,不过它要保证线程安全性,所以在源码上确实要复杂一些。
1.8抛弃分段锁,转为用CAS+synchronized来实现,同样HashEntry改为Node,也加入了红黑树的实现
Put流程
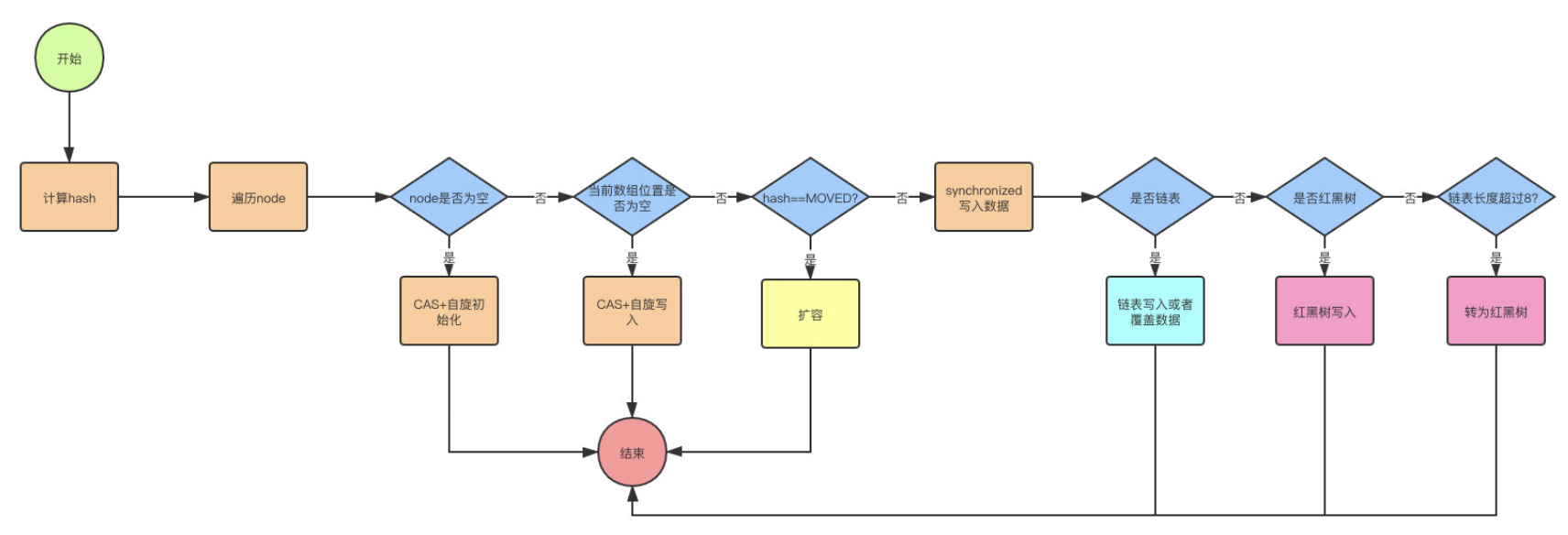
- 首先计算hash,遍历node数组,如果node是空的话,就通过CAS+自旋的方式初始化
- 如果当前数组位置是空则直接通过CAS自旋写入数据
- 如果hash==MOVED,说明需要扩容,执行扩容
- 如果都不满足,就使用syncronized写入数据,写入数据同样判断链表,红黑树,链表写入和HashMap的方式一样,key hash一样就覆盖,反之就尾插法,链表长度超过8就转换成红黑树
get流程
计算 hash 值
根据 hash 值找到数组对应位置: (n - 1) & h
根据该位置处结点性质进行相应查找
- 如果该位置为 null,那么直接返回 null 就可以了
- 如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
- 如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树
- 如果以上 3 条都不满足,那就是链表,进行遍历比对即可
对比总结
HashTable:使用了syncronized关键字对put等操作进行加锁ConcurrentHashMap JDK1.7:使用分段锁机制实现ConcurrentHashMap JDK1.8:使用数组+链表+红黑树结构和CAS
具体源码分析可以看:https://pdai.tech/md/java/thread/java-thread-x-juc-collection-ConcurrentHashMap.html#google_vignette