案例背景
很多经管类同学找财务数据都很困难,去找一个个查找特定的公司,然后又要去同花顺或者东方财富网一年一年的去查看报表,一年一年的数据一个个填入...太慢了。
tushare能获取金融数据的接口,他有资产负债表,利润表,现金流量表三个表全部的指标,每一年的年报基本都有,数据变量总共124多个,非常全面,什么净利润,营业收入,资产,负债,所有者权益,活动现金,应付账款等等,全都有。很简单就能获取这样标准整洁的财务数据:

这里就教大家怎么获取指定公司的财务数据。全部源代码都有,制作为程序的过程也有,
这个包的财务数据获取官网API接口示例为:Tushare数据
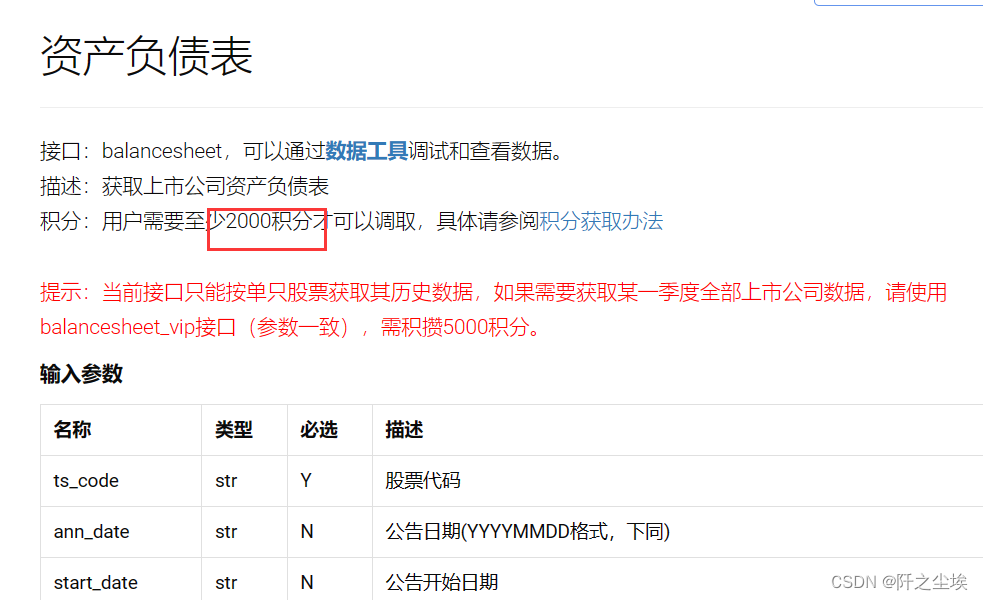
需要注意获取财务数据的权限需要2k的积分账户才行。
(PS:2k积分要充200RMB,当然有的同学嫌贵了或者不会弄代码,或者觉得后面的过程自己做起来麻烦可以咨询我获取我自己制作的程序来获取数据: 财务数据 )
(程序双击就能运行,自己改一下要获取的上市公司的名称就行,里面的源码嵌入的账号是我自己的,因此有权限获取财务数据)
tushare的财务指标很多很多,很全,下面是官网的资产负债表的部分变量:
代码实现
导入包:
import tushare as ts
import numpy as np
import pandas as pd #导入第三方库
这里tushare需要获取财务数据,那么你的账户要有2k 的积分,我这里把自己的apikey打码了,同学可以自己去参考这个官网教程,然后注册账号获取自己的apikey:Tushare数据
#Tushare API
api_key = '9cd3***2509********************755**b4'
ts.set_token(api_key)
pro = ts.pro_api()(ps:使用我做的程序就是我自己的账号,当然程序做了反编译,查看不到我的账户API,但是大家可以自己使用hh,使用很简单,双击就行。可以咨询我获取 财务数据 )
自己把要获取的上市公司的名称写到一个txt文件里面,
这个txt文件的名称命名为“公司名称列表.txt”:,![]()
里面就写你要获取的A股的股票的名称,英文逗号隔开。换行也要英文逗号

然后自定义一个读取文件函数:
def read_file_to_list(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 去除换行符
content_no_newline = content.replace('\n', '')
# 以逗号为分隔符,转换成列表
content_list = content_no_newline.split(',')
# 去除列表中的空字符串项
content_list = [item for item in content_list if item]
print('读取关键词成功')
return content_list
except FileNotFoundError:
print(f"文件 {file_path} 未找到。")
sleep(1)
return []
except Exception as e:
print(f"读取文件时发生错误:{e}")
sleep(1)
return []读取,然后可以作为程序,自然就需要输入,可以输入你需要获取的开始的年份和结束的年份。
codes_names = read_file_to_list('公司名称列表.txt')
print(codes_names)
start_date=input('请输入开始年份(例如:“2016”)')
end_date=input('请输入结束的年份/不要大于当前年份不然可能报错(例如:“2023”)')
start_date=start_date+'0101' ; end_date=end_date+'1231'
data = pro.stock_basic(exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,list_date')

获取这些股票的对应的股票代码
codes=[]
for codes_name in codes_names:
try:
# 假设data是一个DataFrame,包含股票名称和代码
longbai_code = data[data['name'].str.contains(codes_name)]['ts_code'].to_numpy()
# 尝试获取第一个匹配的股票代码
codes.append(longbai_code[0])
print(f'{codes_name}的股票代码是:{longbai_code[0]}')
except IndexError:
# 当尝试访问longbai_code[0]但longbai_code是空的时候,会触发IndexError异常
print(f'无法查询到{codes_name}对应的代码,请检查名称')
print(f"\n获取上述查询到代码的股票从{start_date}开始到{end_date}结束的财务数据")
如果你输入的股票名称是错的会找不到股票代码的。
获取对应股票代码和时间的财务数据:
def get_f(df):
return df[df['报告期'].str.contains('1231')].reset_index(drop=True)
def Company_Financial_Data(code='',start_date='20160101',end_date='20231231'):
columns1=['公告日期','实际公告日期','报告类型 见底部表','公司类型(1一般工商业2银行3保险4证券)','报告期类型']
income_data = pro.income(ts_code=code, start_date=start_date, end_date=end_date).rename(columns=variables_dict).iloc[:,:-1].drop_duplicates(['报告期']).drop(columns=columns1)
income_data = get_f(income_data)
columns2=['公告日期','实际公告日期','报表类型','公司类型(1一般工商业2银行3保险4证券)','报告期类型']
balance_sheet = pro.balancesheet(ts_code=code, start_date=start_date, end_date=end_date).rename(columns=variables_dict_2).iloc[:,:-1].drop_duplicates(['报告期']).drop(columns=columns2)
balance_sheet = get_f(balance_sheet)
columns3=['公告日期','实际公告日期','报表类型','公司类型(1一般工商业2银行3保险4证券)','报告期类型']
cash_flow = pro.cashflow(ts_code=code, start_date=start_date, end_date=end_date).rename(columns=variables_dict_3).iloc[:,:-1].drop_duplicates(['报告期']).drop(columns=columns3)
cash_flow=get_f(cash_flow)
merged_df = pd.merge(cash_flow, balance_sheet, on='报告期', how='inner', suffixes=('', '_balance'))
# 再次合并时,对 income_data 使用不同的后缀
final_merged_df = pd.merge(merged_df, income_data, on='报告期', how='inner', suffixes=('', '_income'))
# 假设你想保留 cash_flow 中的 'TS股票代码' 列,你可以删除其他重复的 'TS股票代码' 列
final_merged_df=final_merged_df.drop(columns=['TS股票代码_balance', 'TS股票代码_income']).dropna(axis=1, how='any')
return final_merged_df然后对前面获取的股票代码进行循环:获取成功后就保存到一个excel里面不同的sheet里面。
with pd.ExcelWriter('上市公司财务数据.xlsx', engine='xlsxwriter') as writer:
for code in codes:
print(f'{code}财务数据储存成功')
df = Company_Financial_Data(code=code,start_date=start_date,end_date=end_date)
# Write each DataFrame to a different worksheet, using the stock code as the sheet name
df.to_excel(writer, sheet_name=code,index=False)
这样你代码程序运行的文件夹下就会多一个“上市公司财务数据.xlsx”的表格文件了,里面每一个sheet就是一个公司,每一面就是一个公司的制定年份的所有财务数据。

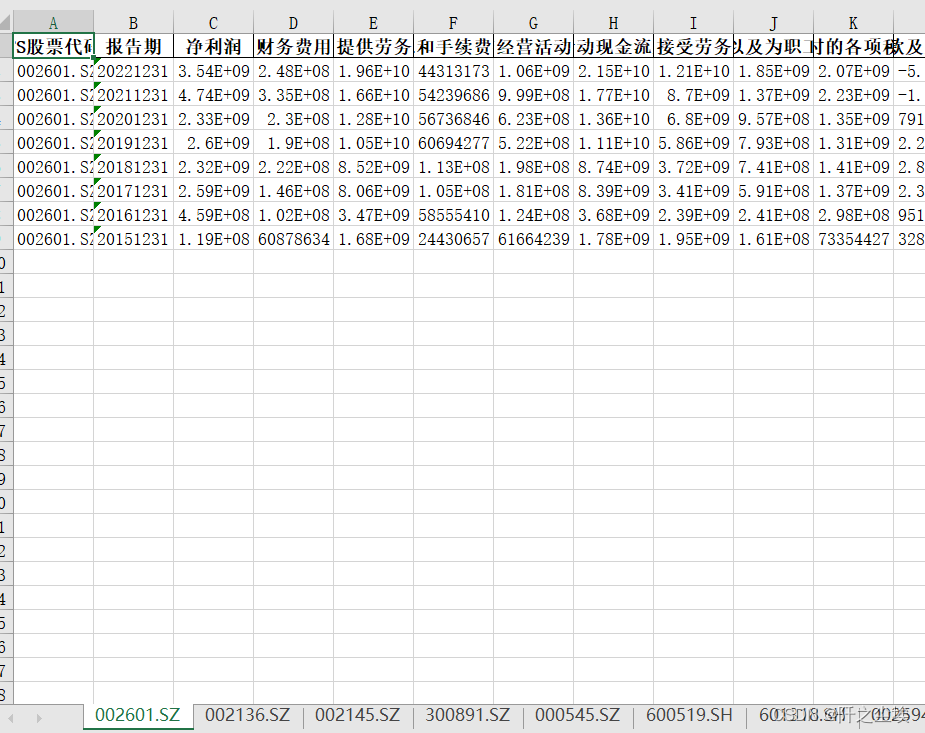
很整洁,也很好用。然后大家再这个里面挑选自己需要的财务数据取做实证分析或者别的数据分析研究就行。
源代码到这里就结束了,下面是怎么把这个代码变成exe文件。
代码打包为exe可执行的程序
由于我自己的电脑环境的Python里面没有tushare这个库,所以我需要再anaconda环境里面去对我的脚本代码打包。
我问了一下gpt,需要这样做:
-
确认 Anaconda 环境:确保你在 Anaconda Prompt 中运行命令。这可以保证你使用的是 Anaconda 的 base 环境。
-
在 base 环境中安装 PyInstaller:如果还没有安装 PyInstaller,确保在 base 环境中安装它。可以使用命令
conda install pyinstaller或pip install pyinstaller。 -
使用 Anaconda 环境的 Python 解释器运行 PyInstaller:在 Anaconda 的 base 环境中,你也可以找到 Python 解释器的路径,并使用它来确保运行的是正确的解释器。使用 Anaconda Prompt,可以通过
where python(Windows) 或which python(Mac/Linux) 来找到 Python 解释器的确切路径。然后,使用该路径直接运行 PyInstaller,例如:C:\Users\YourUsername\anaconda3\python.exe -m PyInstaller --onefile your_script.py替换上面的路径为你的实际 Python 解释器路径。
-
检查环境变量:即使是在 base 环境中,也确保 Anaconda 的安装路径(尤其是包含 Python 解释器的路径)已经添加到了你的系统环境变量中。
通过这些步骤,即使在 Anaconda 的 base 环境中,也能确保 PyInstaller 使用正确的环境进行打包。如果你按照上述步骤操作后仍遇到问题,可能需要检查具体的错误信息,看看是否有其他原因导致的问题。
我自己在anaconda prompt 里面输入:(先切换到需要储存的路径,找到自己的py解释器的位置where python)
D:\Anaconda\python.exe -m PyInstaller --onefile D:\AAA最近要用\接单项目\种子叶绿素\财务数据\行业财务数据.py就会在你的前缀后面的文件路径里面生成你需要的exe文件,就在dist里面的,
这个程序双击就能运行,很简单。但是需要你先在和这个程序统一文件夹下面放入自己需要的上市公司名称的txt文件。

我们来看看运行效果:
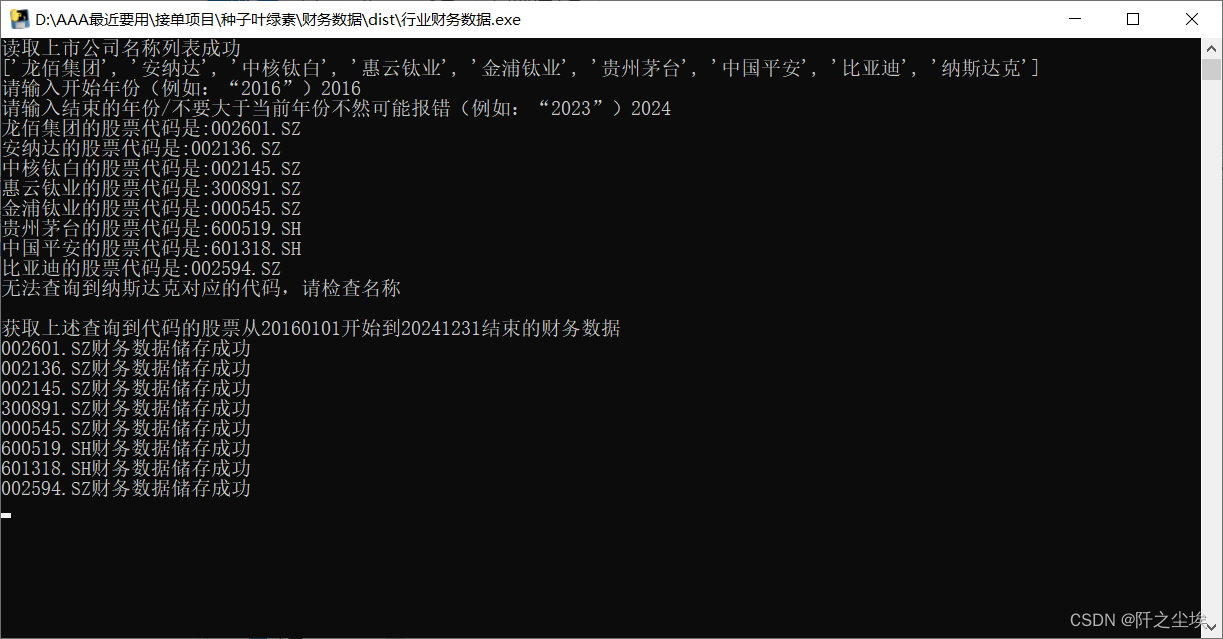
运行完了在这个文件夹下面就会多了一个Excel表,里面就是需要的公司的数据了。
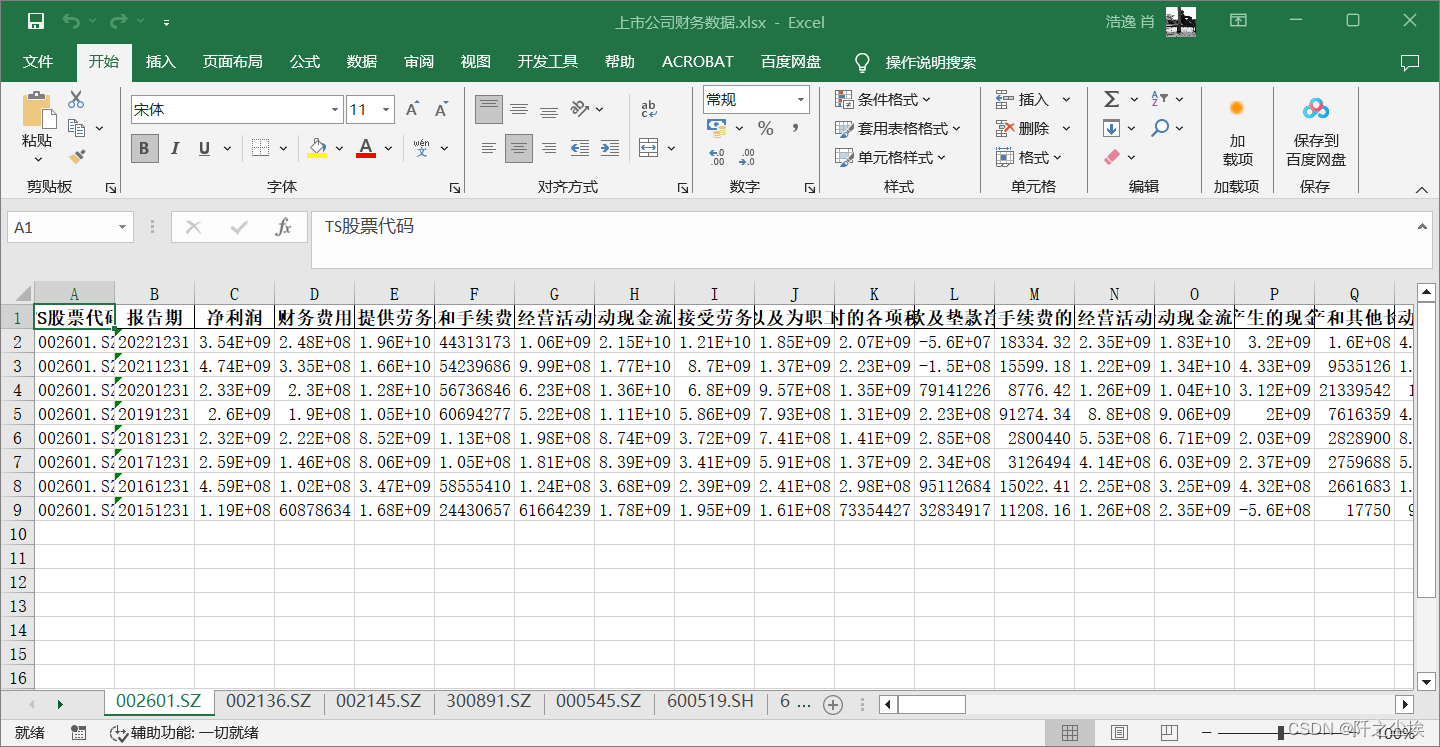
是不是很简单?如果觉得上面流程很麻烦,可以咨询我获取这个我做好的程序可以参考: 财务数据
双击就能运行,这样大家就可以很容易轻松获取自己需要的上市公司的所有财务数据了。
然后再选出自己需要的变量进行分析。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码和数据可私信)