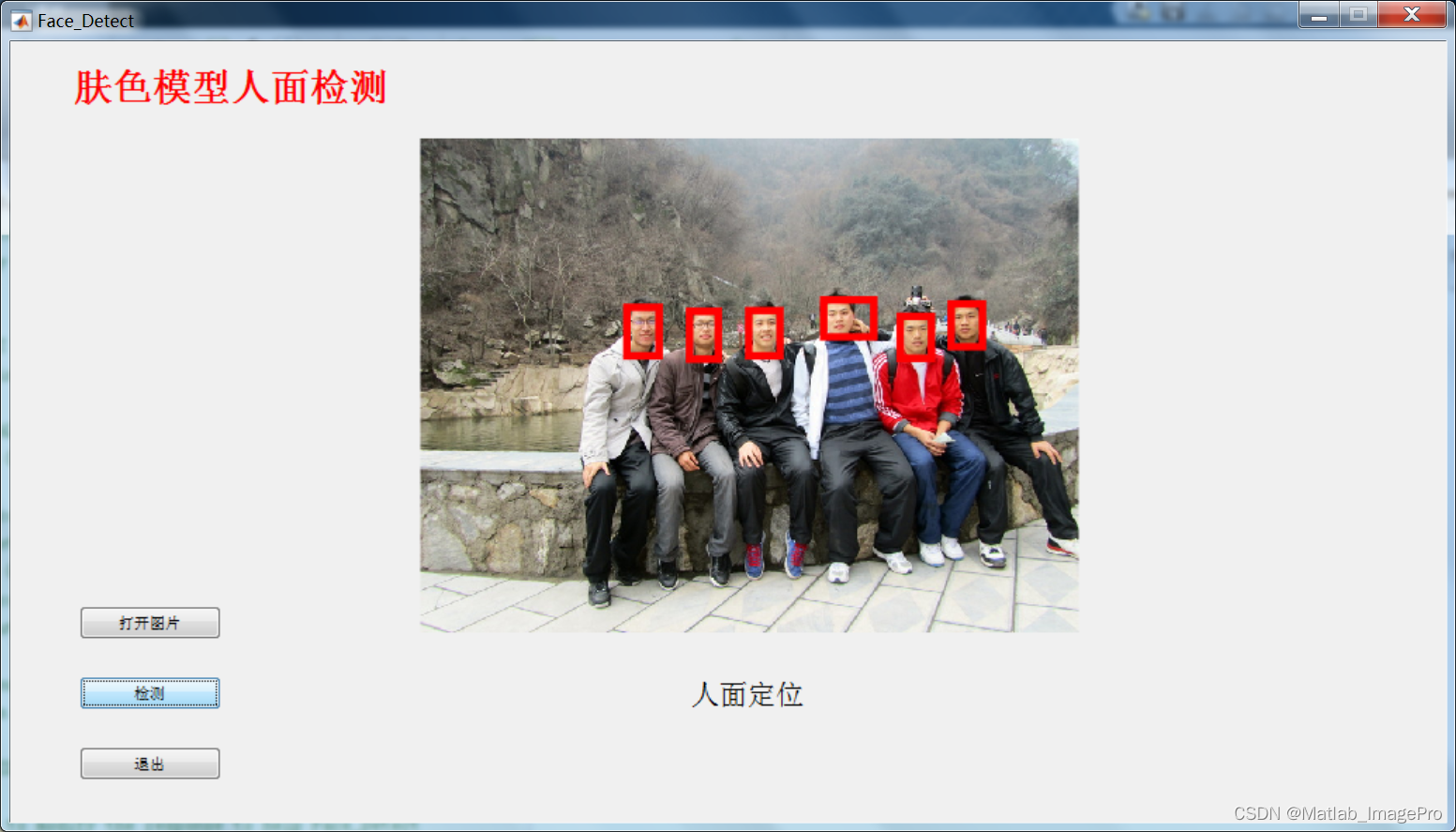
项目背景
最近遇到这样一个需求:
Python主成分分析和聚类分析?商业场景你数据不变展示,主要是用来划分用户等级,用来人文关怀。
基本概念
主成分分析(PCA)是一种常用的数据降维技术,通过线性变换将原始数据转换为一组各维度之间不相关的新变量,称为主成分。聚类分析则是一种将数据集中的对象划分为若干个类别的方法,使得同一类别内的对象相似度较高,不同类别之间的相似度较低。
相关代码
# 导入所需库
import numpy as np
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
# 创建虚拟数据
data = np.random.rand(100, 5) # 生成100个样本,每个样本有5个特征
# 主成分分析
pca = PCA(n_components=2) # 指定要保留的主成分个数为2
data_pca = pca.fit_transform(data)
# 聚类分析
kmeans = KMeans(n_clusters=3) # 指定要分为3个簇
labels = kmeans.fit_predict(data)
print("PCA结果:")
print(data_pca)
print("聚类结果:")
print(labels)注意事项
- 在使用主成分分析和聚类分析时,需要确保数据预处理工作的充分性和准确性,以保证结果的可靠性。
- 需要根据实际情况选择合适的主成分个数和簇数,这可以通过交叉验证等方法进行调参。
- 对于聚类结果,可以进一步进行结果评估和可视化,以便对数据进行更深入的分析和解释。

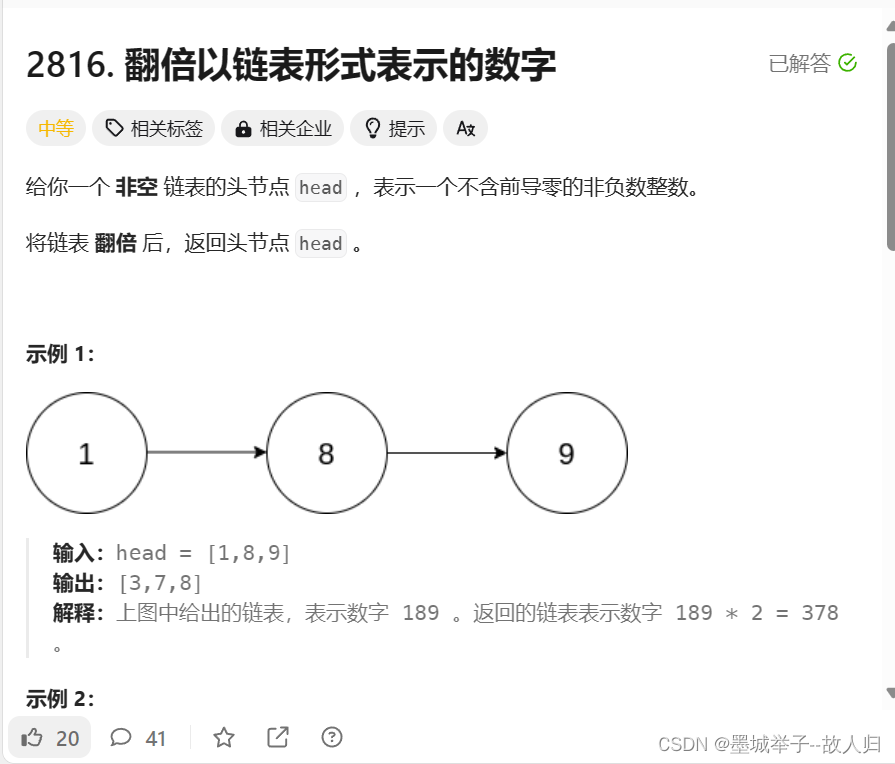

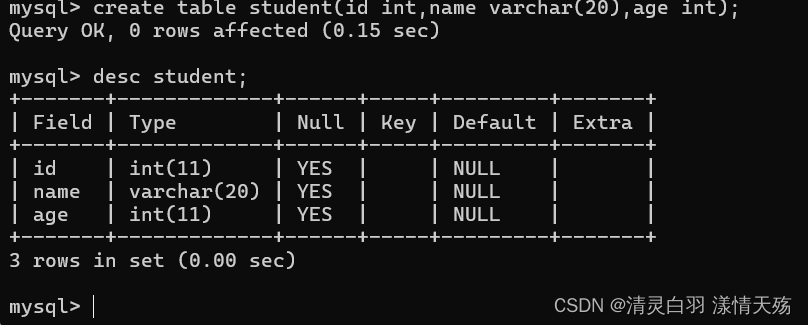









![练习8 Web [GYCTF2020]Blacklist](https://img-blog.csdnimg.cn/direct/1972477ac0484a039f5cf2d316365b65.png)