1、集群模式的启动和初始化
当开启了cluster-enabled,在初始化服务initServer方法中会调用clusterInit方法将redis带入cluster模式。
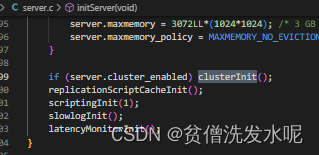
clusterInit
void clusterInit(void) {
int saveconf = 0;
//初始化clusterState结构
server.cluster = zmalloc(sizeof(clusterState));
server.cluster->myself = NULL;
server.cluster->currentEpoch = 0;
server.cluster->state = CLUSTER_FAIL;
server.cluster->size = 1;
server.cluster->todo_before_sleep = 0;
server.cluster->nodes = dictCreate(&clusterNodesDictType,NULL);
server.cluster->nodes_black_list =
dictCreate(&clusterNodesBlackListDictType,NULL);
server.cluster->failover_auth_time = 0;
server.cluster->failover_auth_count = 0;
server.cluster->failover_auth_rank = 0;
server.cluster->failover_auth_epoch = 0;
server.cluster->cant_failover_reason = CLUSTER_CANT_FAILOVER_NONE;
server.cluster->lastVoteEpoch = 0;
for (int i = 0; i < CLUSTERMSG_TYPE_COUNT; i++) {
server.cluster->stats_bus_messages_sent[i] = 0;
server.cluster->stats_bus_messages_received[i] = 0;
}
server.cluster->stats_pfail_nodes = 0;
memset(server.cluster->slots,0, sizeof(server.cluster->slots));
clusterCloseAllSlots();
server.cluster_config_file_lock_fd = -1;
if (clusterLockConfig(server.cluster_configfile) == C_ERR)
exit(1);
// 加载或创建一个节点配置文件
if (clusterLoadConfig(server.cluster_configfile) == C_ERR) {
//如果配置文件不存在,则通过 createClusterNode 来创建一个 flags = MYSELF|MASTER 且名字随机的新节点
myself = server.cluster->myself =
createClusterNode(NULL,CLUSTER_NODE_MYSELF|CLUSTER_NODE_MASTER);
serverLog(LL_NOTICE,"No cluster configuration found, I'm %.40s",
myself->name);
clusterAddNode(myself);
saveconf = 1;
}
//保存节点配置文件,具体的配置文件名由参数 cluster-config-file 来指定
if (saveconf) clusterSaveConfigOrDie(1);
// 打开 cluster 通道的 非阻塞监听端口
server.cfd_count = 0;
if (server.port > (65535-CLUSTER_PORT_INCR)) {
serverLog(LL_WARNING, "Redis port number too high. "
"Cluster communication port is 10,000 port "
"numbers higher than your Redis port. "
"Your Redis port number must be "
"lower than 55535.");
exit(1);
}
if (listenToPort(server.port+CLUSTER_PORT_INCR,
server.cfd,&server.cfd_count) == C_ERR)
{
exit(1);
} else {
int j;
//绑定事件处理器clusterAcceptHandler
for (j = 0; j < server.cfd_count; j++) {
if (aeCreateFileEvent(server.el, server.cfd[j], AE_READABLE,
clusterAcceptHandler, NULL) == AE_ERR)
serverPanic("Unrecoverable error creating Redis Cluster "
"file event.");
}
}
//初始化保存键值对的槽
server.cluster->slots_to_keys = raxNew();
memset(server.cluster->slots_keys_count,0,
sizeof(server.cluster->slots_keys_count));
//对外暴露的服务、通信端口(兼容NAT和Docker的通信模式)
myself->port = server.port;
myself->cport = server.port+CLUSTER_PORT_INCR;
if (server.cluster_announce_port)
myself->port = server.cluster_announce_port;
if (server.cluster_announce_bus_port)
myself->cport = server.cluster_announce_bus_port;
server.cluster->mf_end = 0;
resetManualFailover();
clusterUpdateMyselfFlags();
}
此方法主要就是
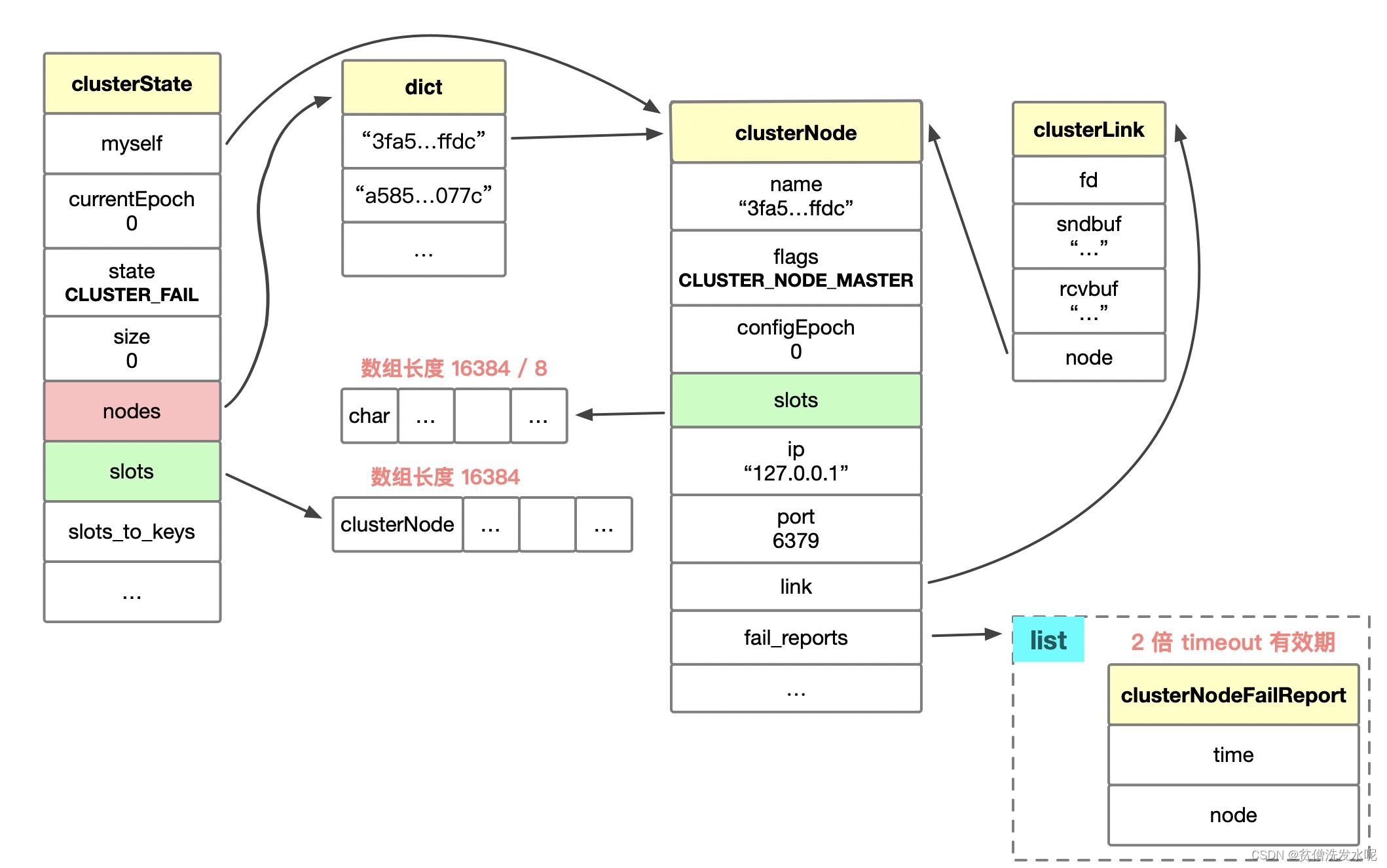
1、初始化集群数据结构(集群数据结构关系附在最后)
2、加载/创建集群配置文件
3、集群总线 cluster bus 通道监听
每个 Redis 集群节点都需要打开两个 TCP 连接。一个用于为客户端提供服务的正常 Redis TCP 端口,例如 6379。还有一个基于 6379 端口加 10000 的端口,比如 16379。
第二个端口用于集群总线也就是cluster bus,这是一个使用二进制协议的节点到节点通信通道。节点使用集群总线进行故障检测、配置更新、故障转移授权等等。
2、集群节点的握手
众所周知,搭建一个redis集群至少需要6个节点。现假设已有6个redis服务都开启了cluster-enabled配置并启动了,但目前这6个节点还都是独立的个体。那么他们彼此之间是如何建立联系成为一个集群?槽位又是如何分配的呢?以及主从关系又是如何指定的呢?
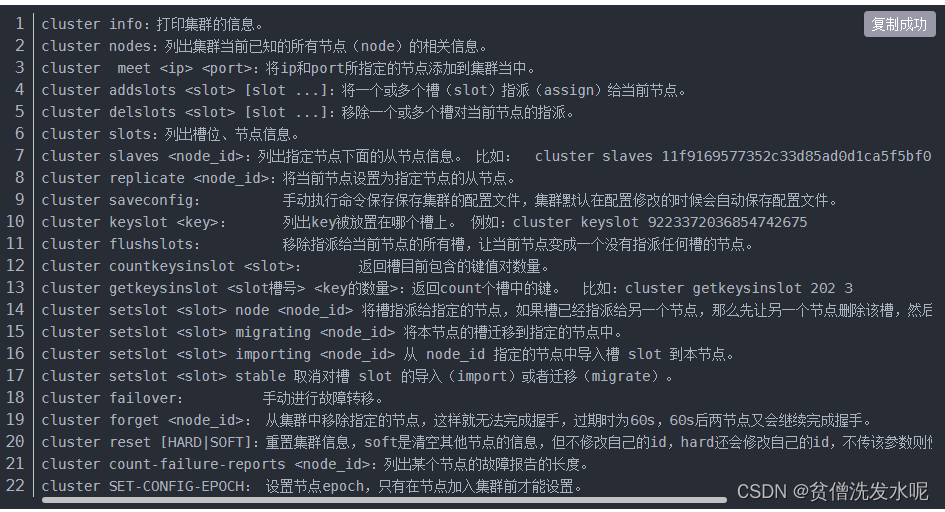
这个时候就需要用到cluster的相关命令搭建集群。使用cluster meet命令连接集群各个节点。cluster addslots命令对各个节点槽指派。cluster replicate命令指定主从关系。(集群相关命令附在篇末)。
也可以直接用redis-cli工具,如:redis-cli --cluster create --cluster-replicas 1 host:port host:port host:port。无论是手动搭建还是redis-cli工具搭建,都是通过发送cluster相关命令给服务端执行实现的。
cluster与get命令一样,都是命令,所以肯定有与之映射的命令处理器。查看redisCommandTable可以看到cluster命令对应的处理函数是clusterCommand
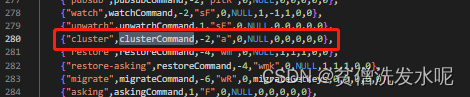
不难发现,无论是cluster meet,还是cluster addslots,还是其他只要是cluster命令都会经过这个处理器。
这里先讲集群间的握手,即cluster meet。
cluster meet
在clusterCommand中找到对cluster meet的处理部分。
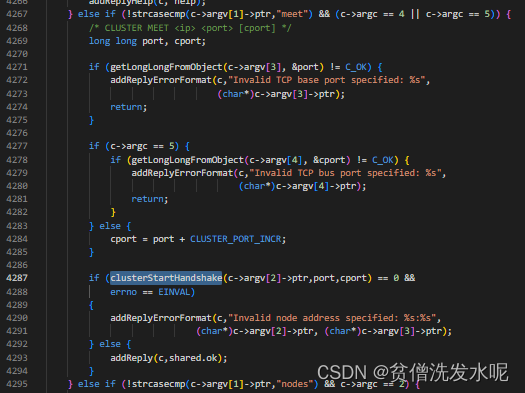
A handshake B
来到clusterStartHandshake函数,这个函数即是对meet的节点进行handshake(握手)。
int clusterStartHandshake(char *ip, int port, int cport) {
clusterNode *n;
char norm_ip[NET_IP_STR_LEN];
struct sockaddr_storage sa;
//检查IP合法性
if (inet_pton(AF_INET,ip,
&(((struct sockaddr_in *)&sa)->sin_addr)))
{
sa.ss_family = AF_INET;
} else if (inet_pton(AF_INET6,ip,
&(((struct sockaddr_in6 *)&sa)->sin6_addr)))
{
sa.ss_family = AF_INET6;
} else {
errno = EINVAL;
return 0;
}
//检查端口合法性
if (port <= 0 || port > 65535 || cport <= 0 || cport > 65535) {
errno = EINVAL;
return 0;
}
//规范化ip端口的字符串表示形式
memset(norm_ip,0,NET_IP_STR_LEN);
if (sa.ss_family == AF_INET)
inet_ntop(AF_INET,
(void*)&(((struct sockaddr_in *)&sa)->sin_addr),
norm_ip,NET_IP_STR_LEN);
else
inet_ntop(AF_INET6,
(void*)&(((struct sockaddr_in6 *)&sa)->sin6_addr),
norm_ip,NET_IP_STR_LEN);
//检查节点 norm_ip:port 是否正在握手
if (clusterHandshakeInProgress(norm_ip,port,cport)) {
errno = EAGAIN;
return 0;
}
// 创建一个含随机名字的 node,标记 为 CLUSTER_NODE_HANDSHAKE|CLUSTER_NODE_MEET
n = createClusterNode(NULL,CLUSTER_NODE_HANDSHAKE|CLUSTER_NODE_MEET);
memcpy(n->ip,norm_ip,sizeof(n->ip));
n->port = port;
n->cport = cport;
clusterAddNode(n);
return 1;
}
可以发现 clusterStartHandshake 也仅仅只知道对方的ip和port,其他信息一概不知,甚至对方的名字都是随机取的。真实的信息是由后续定时任务 clusterCron 的 gossip 通信更新的
A与B建立连接,并发送gossip meet给B
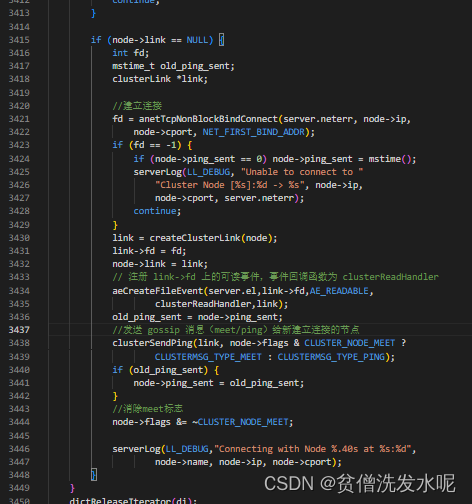
假设这里执行的是 A cluster meet B。在后续A的clusterCron定时任务中,cluster meet 命令新加入B节点link为null会被检测到并做一些事情。
1、与B的ip和启动端口号+10000 为 gossip 通信端口建立连接,注册可读事件,处理函数为 clusterReadHandler。
2、发送 gossip meet 消息给 B 节点,消除掉 B 节点 flag 中CLUSTER_NODE_MEET 状态。
B接受连接和对gossip meet消息的处理及回复
B如何处理A发起的连接和meet消息?
首先我们回到初始化启动时对集群端口绑定的连接事件处理器 clusterAcceptHandler 。当 B 接收集群内的连接请求时,会调用连接事件处理器 clusterAcceptHandler 创建一个新的套接字连接,并绑定对新创建的套接字注册可读事件,回调函数为 clusterReadHandle。当后续对新建立的套接字连接发送gossip meet消息时,就会触发对应的clusterReadHandle处理器。
clusterAcceptHandler
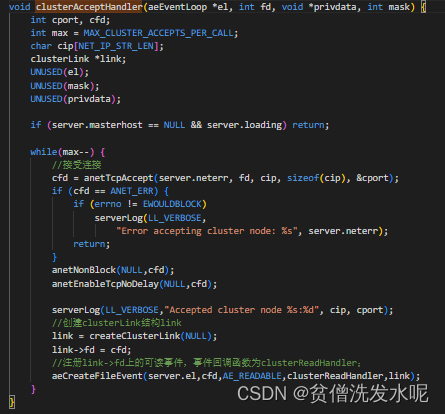
需要注意,这一步收到 connnet 请求后创建的新 link 中,link-> node 是 null 。因为根据 socket 里的信息无法确定节点是哪个,暂时置空。而 clusterCron 里的主动建连的node不为空,这也是在 gossip 消息处理中,区分主动发包还是被动收包的依据。
clusterReadHandle
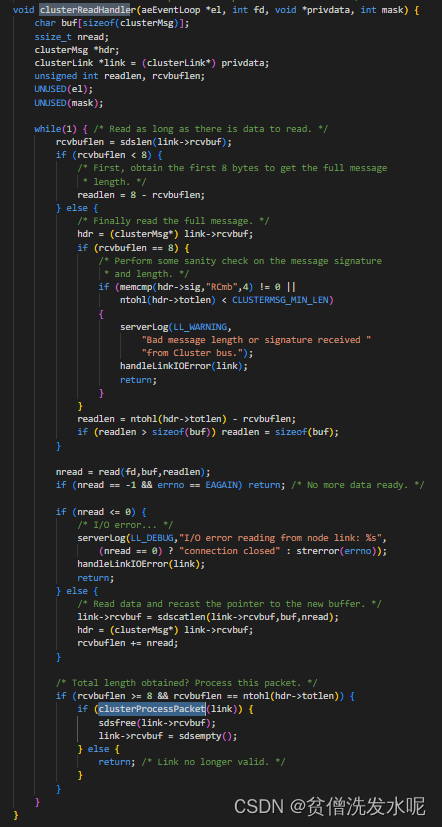
主要逻辑在 clusterProcessPacket
在clusterProcessPacke函数中,首先尝试在server.cluster->nodes字典中,以发送者的名字为key寻找发送者节点sender,因为此时节点B对于节点A一无所知,自然找不到对应的节点。如果找不到发送者节点,并且收到的报文为MEET报文,则以REDIS_NODE_HANDSHAKE为标志,创建一个clusterNode结构表示节点A,该结构的ip和port分别置为节点A的ip和port,并将该节点插入到字典server.cluster->nodes中。并回复PONG包给节点A。
这部分的代码如下:
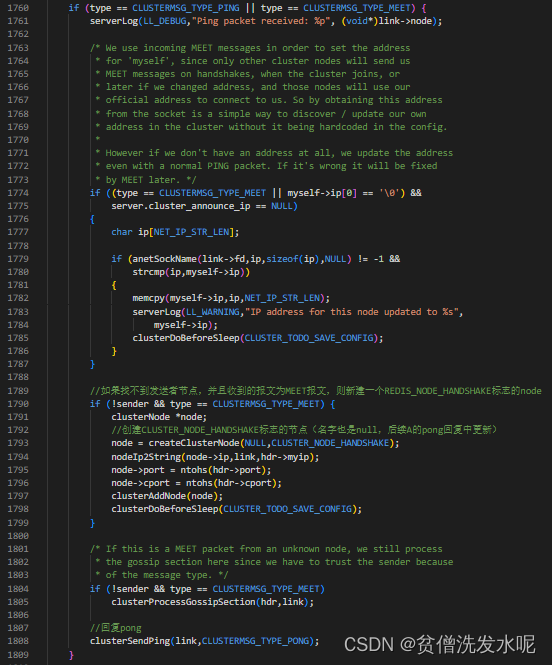
A接收B的pong回复
A对B回复的pong处理逻辑也同样在clusterReadHandle函数。**A会根据B的pong回复更新B的名字和消除handshake状态以及根据回复的角色将master或者slave标记到B节点。**此时B的各种状态在A看来就是完全正常的了。
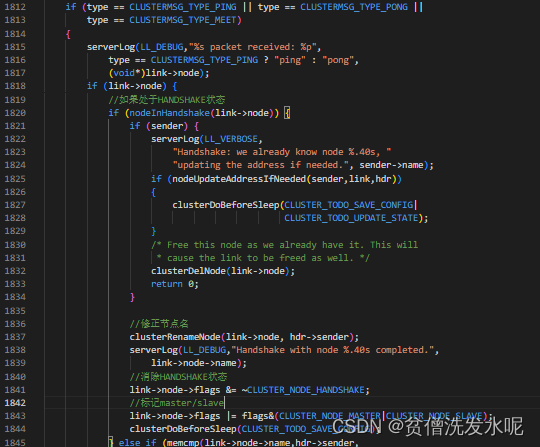
B认识A
上面有提到在节点B接收A发来的MEET消息时,会创建相应的节点到server.cluster->nodes中,此时A节点的link也为null。与上面中A节点的步骤类似,在节点B的clustercron中也会向A发起TCP建链,并且在建链之后发送ping包给A,表示B开始向A握手。A收到B发来的ping也同样会回复一个pong。B也同样最终会调用clusterProcessPacket函数处理。此时同样也在server.cluster->nodes字典中,以发送者的名字寻找匹配的节点,因为B还没设置A的名字,所以同样找不到对应的sender。此时在B中,A也同样处于handshake状态,所以B同样也用A回复的pong包更新A的名字和消除handshake状态,并且根据pong包回复的角色将master或者slave标记到A节点。至此B向A的握手也算完成,A和B之间就算相互认识了。
3、心跳消息和下线检测及故障转移
那么问题来了,一个cluster meet认识一个节点,现在假设有N个节点,那不是新加入一个节点的时候要在N个原有节点上都执行cluster meet吗?当然这么做法是不可能的,实际上只需要在任意一台机器上执行cluster meet即可,让集群内的其中一台认识新节点,随后会通过gossip协议达到一个最终一致性的状态。换句话说就是,只要告诉集群内的任一节点,这个节点就会告诉集群内的其他节点他知道的新加入的节点。如此类推,一传十,十传百,最后集群内的所有节点终会知道加入的节点。
具体到Redis集群中就是集群内的节点每隔一段时间就会向其他节点发送心跳包,心跳包中除了包含自己的信息之外,还会包含若干认识的其他节点的信息(这就是所谓的gossip部分)。节点收到心跳包后,会检查是否有自己不认识的节点,如果有,就会发起握手。
注意,上面说到gossip部分的并不是所有认识的其他节点信息,而是若干个其他节点信息。那么这个若干个如何定义,redis目前是这样规定的:gossip部分的节点数应该是所有节点数的1/10,但是最少应该包含3个节点信息。
心跳消息
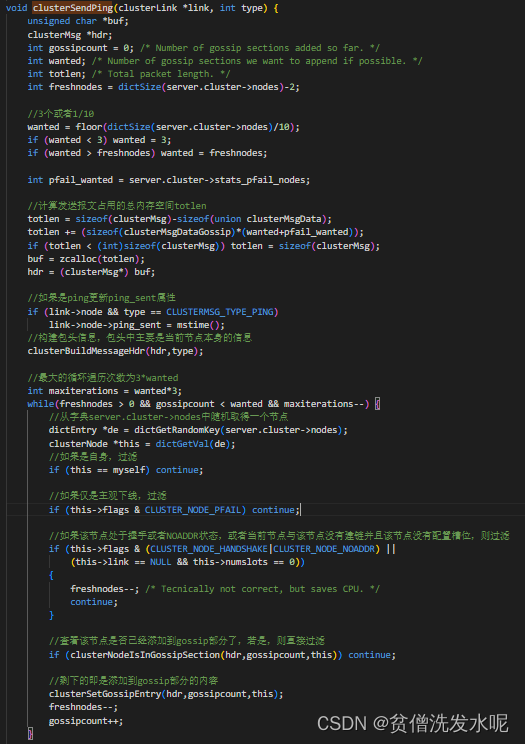
发送心跳包
集群每隔一段时间就会向其他节点发送ping包,节点收到ping包后会回复相同格式的pong包,只是通过包头的type区分类型。因此,ping和pong包都称为心跳包。
节点发送ping包的策略是:每隔1秒,随机挑选5个节点取其中pong_received值最小的一个节点发送ping。除此之外,还会轮询字典内的所有节点,当发现有超过 NODE_TIMEOUT/2的时间没有向该节点发送过PING包了,就会立即向该节点发送PING包。其代码逻辑同样在clusterCron定时器中。
每秒随机ping一个节点

ping超过NODE_TIMEOUT/2未发送ping包的节点
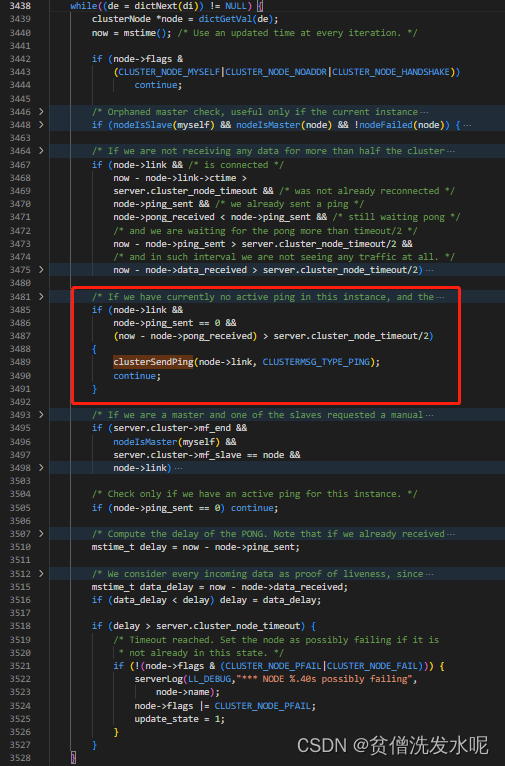
node->ping_sent:发送ping包时置为当时时间,当收到ping回复时重置为0;
node->pong_received:发送ping包时重置为0,收到pong回复时置为当时时间;
gossip
在实际发送/接收心跳包时用到了gossip协议
发送端
接收端
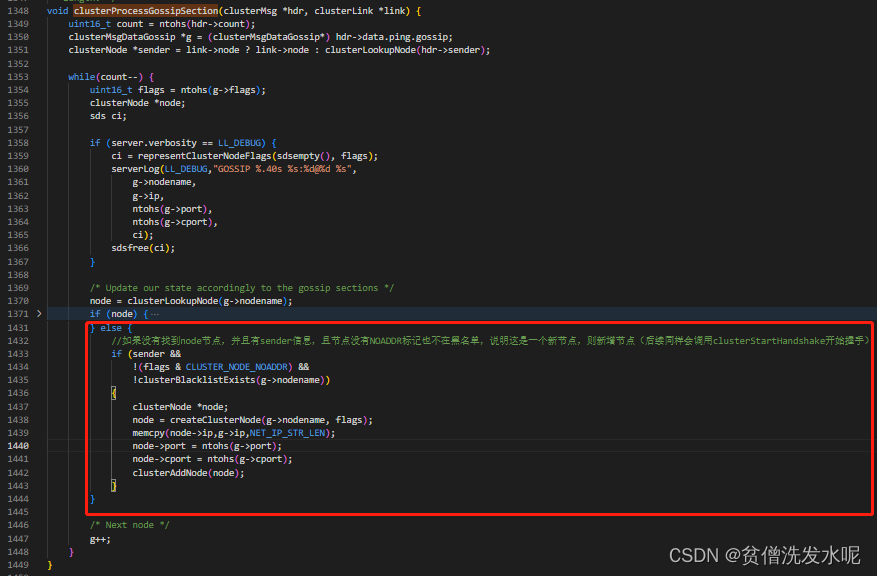
当前节点收到其他节点发来的PING、PONG或MEET包后,会调用clusterProcessPacket处理,之后会调用clusterProcessGossipSection函数处理包中的gossip部分。

clusterProcessGossipSection
下线检测
集群节点是通过节点能及时回复PING包来判断该节点是否下线的。这里的下线有两种状态:主观下线(PFAIL)和客观下线(FAIL)。
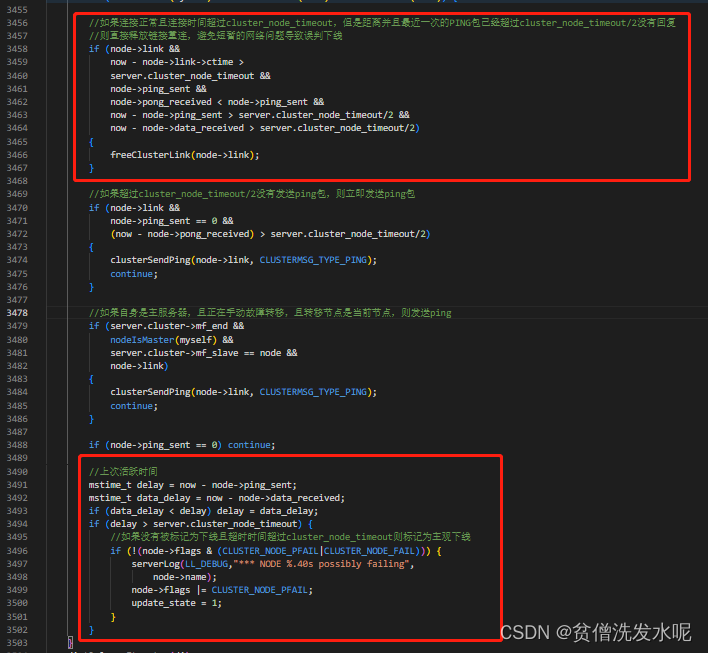
主观下线
在clusterCron中,如果节点超过server.cluster_node_timeout的时间没有活跃,则将其标记为主观下线。
客观下线
一旦节点被标记为PFAIL之后,则发出去的心跳包中,在gossip部分就可能会带有PFAIL节点的信息。其他节点收到心跳包后,解析其中的gossip部分,就会发现被标记为PFAIL的节点,然后就会将更新被标记成PFAIL节点的下线报告记录fail_reports。
即每收到一次节点下线报告,就会更新对应节点的fail_reports并统计列表中报告下线的节点个数,若在server.cluster_node_timeout*2的时间内,超过一半的节点报告其下线,则将其标记成客观下线。
这部分逻辑也在clusterProcessPacket方法里对gossip部分的处理方法clusterProcessGossipSection
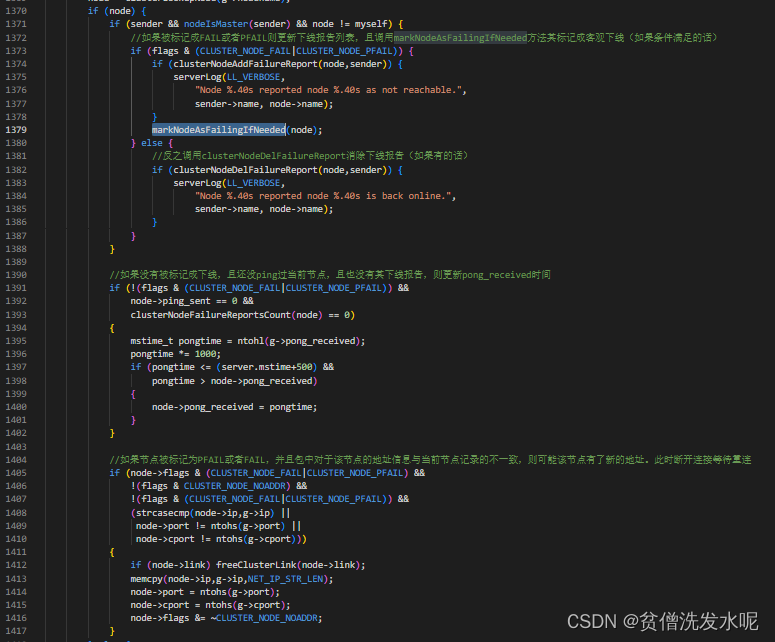
其中markNodeAsFailingIfNeeded逻辑如下
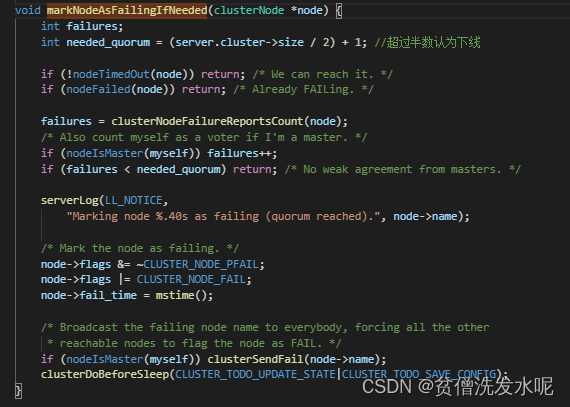
可以发现最后会调用clusterSendFail向其他节点广播FAIL包,其他节点在收到FAIL包后,在包处理函数clusterProcessPacket中不管之前有没有PFAIL(主观下线)都会立即将其标记成FAIL(客观下线)。这部分逻辑如下。
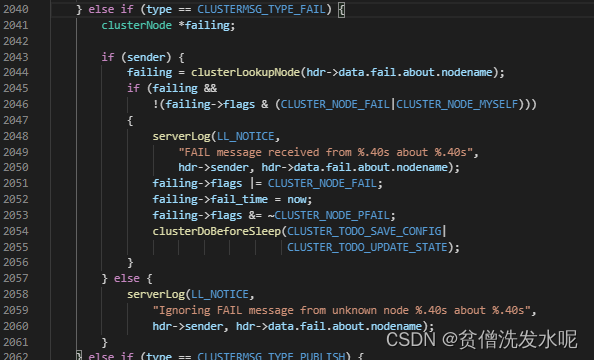
故障转移
下线检测发现节点下线后,不会显式触发故障转移。而是由clusterCron定时器去执行clusterHandleSlaveFailover检测是否满足故障转移的条件和处理故障转移相关的逻辑。

clusterHandleSlaveFailover逻辑如下
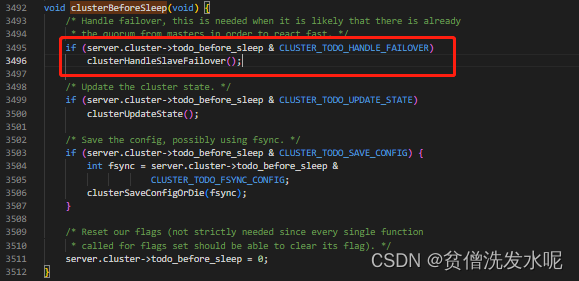
void clusterHandleSlaveFailover(void) {
//主从复制延迟时间
mstime_t data_age;
//距离发起故障转移流程,已经过去了多少时间
mstime_t auth_age = mstime() - server.cluster->failover_auth_time;
//至少需要多少选票才能晋升主节点
int needed_quorum = (server.cluster->size / 2) + 1;
//是否手动执行故障转移
int manual_failover = server.cluster->mf_end != 0 &&
server.cluster->mf_can_start;
mstime_t auth_timeout, auth_retry_time;
//取消CLUSTER_TODO_HANDLE_FAILOVER状态
server.cluster->todo_before_sleep &= ~CLUSTER_TODO_HANDLE_FAILOVER;
//等待投票超时时间为集群中设置的超时时间的2倍
auth_timeout = server.cluster_node_timeout*2;
//等待投票超时时间最小为2s
if (auth_timeout < 2000) auth_timeout = 2000;
//等待重试时间为超时时间的2倍
auth_retry_time = auth_timeout*2;
//检查是否满足故障转移条件(以下任何一种情况都不进行故障状态)
if (nodeIsMaster(myself) || 本身是主节点或者
myself->slaveof == NULL || //所属主节点为空或者
(!nodeFailed(myself->slaveof) && !manual_failover) || //所属主节点不处于下线状态并且不是手动故障转移
(server.cluster_slave_no_failover && !manual_failover) || //不允许从节点执行故障切换并且不是手动进行故障转移
myself->slaveof->numslots == 0) //所属主节点负责的槽位为空
{
server.cluster->cant_failover_reason = CLUSTER_CANT_FAILOVER_NONE;
return;
}
//设置主从复制延迟时间
if (server.repl_state == REPL_STATE_CONNECTED) {
data_age = (mstime_t)(server.unixtime - server.master->lastinteraction)
* 1000;
} else {
data_age = (mstime_t)(server.unixtime - server.repl_down_since) * 1000;
}
if (data_age > server.cluster_node_timeout)
data_age -= server.cluster_node_timeout;
if (server.cluster_slave_validity_factor &&//cluster_slave_validity_factor设置了故障切换最大主从复制延迟时间因子,如果不为0需要校验主从复制延迟时间是否符合要求
data_age > //如果主从复制延迟时间 大于(master向从节点发送PING消息的周期 + 超时时间 * 故障切换主从复制延迟时间因子) ,表示主从复制延迟过大,不能进行故障切换
(((mstime_t)server.repl_ping_slave_period * 1000) +
(server.cluster_node_timeout * server.cluster_slave_validity_factor)))
{
//如果不是手动执行故障切换
if (!manual_failover) {
//设置不能执行故障切换的原因,主从复制进度不符合要求
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_DATA_AGE);
return;
}
}
//如果距离上次发起选举的时间大于重试时间,则根据排名计算自身发起投票的时间
if (auth_age > auth_retry_time) {
//设置本轮投票发起时间 当前时间+500ms+随机值(0-500ms)+ 排名*1000ms
//随机值防止同一时间多个节点同时发起投票,排名是根据复制量从多到少排,因为复制的越多越可能成为主节点
server.cluster->failover_auth_time = mstime() +
500 +
random() % 500;
server.cluster->failover_auth_count = 0;
server.cluster->failover_auth_sent = 0;
server.cluster->failover_auth_rank = clusterGetSlaveRank();
server.cluster->failover_auth_time +=
server.cluster->failover_auth_rank * 1000;
//如果是手动进行故障转移,不需要设置延迟
if (server.cluster->mf_end) {
server.cluster->failover_auth_time = mstime();
server.cluster->failover_auth_rank = 0;
clusterDoBeforeSleep(CLUSTER_TODO_HANDLE_FAILOVER);
}
serverLog(LL_WARNING,
"Start of election delayed for %lld milliseconds "
"(rank #%d, offset %lld).",
server.cluster->failover_auth_time - mstime(),
server.cluster->failover_auth_rank,
replicationGetSlaveOffset());
//广播pong消息(更新其他节点对自身的认知,以便于持续更新排名)
clusterBroadcastPong(CLUSTER_BROADCAST_LOCAL_SLAVES);
return;
}
//如果还没开始投票且不是手动执行故障转移,(当排名比之前大的时)更新排名和发起选举时间
if (server.cluster->failover_auth_sent == 0 &&
server.cluster->mf_end == 0)
{
int newrank = clusterGetSlaveRank();
if (newrank > server.cluster->failover_auth_rank) {
long long added_delay =
(newrank - server.cluster->failover_auth_rank) * 1000;
server.cluster->failover_auth_time += added_delay;
server.cluster->failover_auth_rank = newrank;
serverLog(LL_WARNING,
"Replica rank updated to #%d, added %lld milliseconds of delay.",
newrank, added_delay);
}
}
//如果还没到时间则记录延迟发起选举的日志
if (mstime() < server.cluster->failover_auth_time) {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_DELAY);
return;
}
//记录选举超时日志
if (auth_age > auth_timeout) {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_EXPIRED);
return;
}
//发起投票
if (server.cluster->failover_auth_sent == 0) {
//增加当前节点的currentEpoch的值
server.cluster->currentEpoch++;
//此时该从节点的currentEpoch就是所有集群节点中最大的,将该currentEpoch记录到server.cluster->failover_auth_epoch中
server.cluster->failover_auth_epoch = server.cluster->currentEpoch;
serverLog(LL_WARNING,"Starting a failover election for epoch %llu.",
(unsigned long long) server.cluster->currentEpoch);
//广播发送 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 消息拉票
clusterRequestFailoverAuth();
//更新failover_auth_sent,表示已经发起投票了
server.cluster->failover_auth_sent = 1;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE|
CLUSTER_TODO_FSYNC_CONFIG);
return;
}
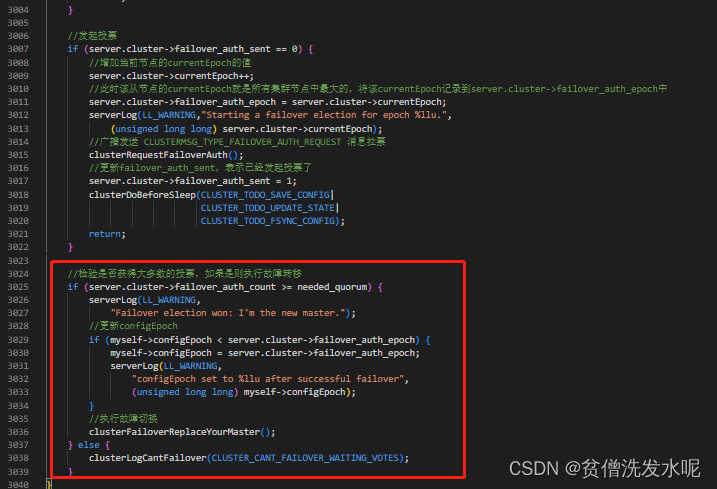
//检验是否获得大多数的投票,如果是则执行故障转移
if (server.cluster->failover_auth_count >= needed_quorum) {
serverLog(LL_WARNING,
"Failover election won: I'm the new master.");
//更新configEpoch
if (myself->configEpoch < server.cluster->failover_auth_epoch) {
myself->configEpoch = server.cluster->failover_auth_epoch;
serverLog(LL_WARNING,
"configEpoch set to %llu after successful failover",
(unsigned long long) myself->configEpoch);
}
//执行故障切换
clusterFailoverReplaceYourMaster();
} else {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_VOTES);
}
}
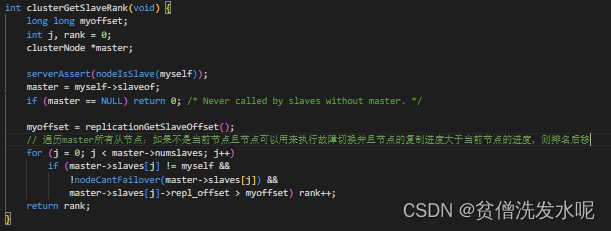
发起投票
可以发现,如果不是手动发起的故障转移,发起投票的时间带有一个随机的延迟,并且会理想情况下复制量越大的从节点越早发起投票(意味着越可能升级成主节点)。
发起投票的时间记录在 server.cluster->failover_auth_time 属性,而
server.cluster->failover_auth_time = 当前时间+500ms+随机值(0-500ms)+ 排名*1000ms
其中排名由clusterGetSlaveRank根据复制的数据量从大到小排。
当到达发起投票时间时,节点就会广播 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 进行拉票。广播拉票消息的逻辑在clusterRequestFailoverAuth方法
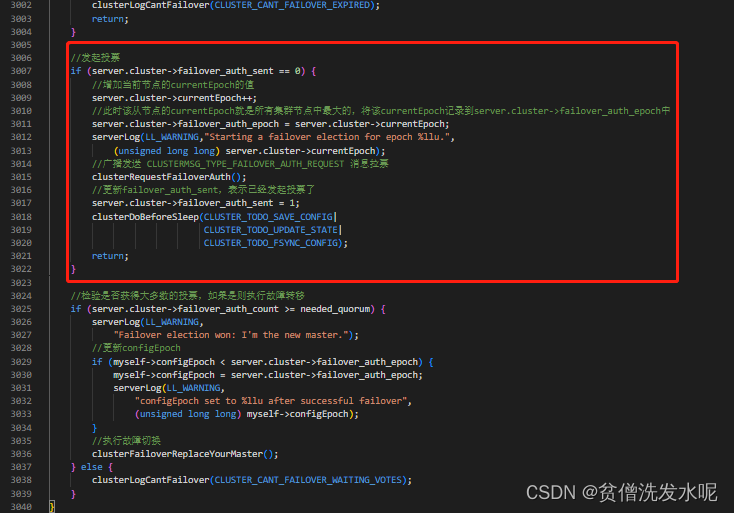
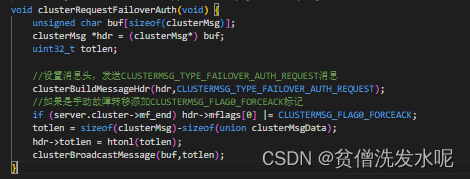
主节点投票
主节点收到CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息后,在clusterProcessPacket里的处理逻辑如下

可以发现调用了clusterSendFailoverAuthIfNeeded方法进行投票,逻辑如下
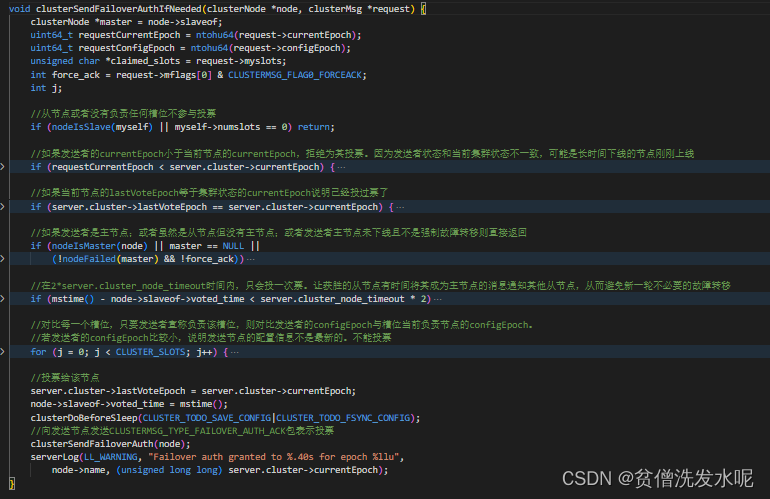
可以发现,主节点会对满足条件的从节点发送CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK包表示投票给该节点。
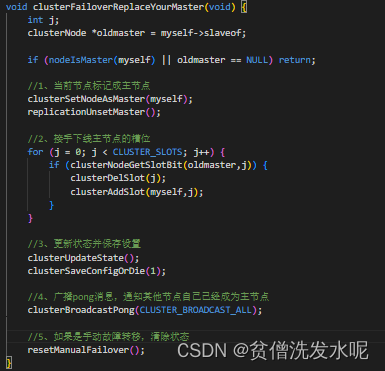
从节点升级成主节点
从节点对CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK投票回复的处理同样clusterProcessPacket函数中
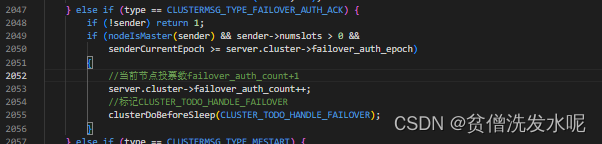
当从节点有收到投票时,就会标记CLUSTER_TODO_HANDLE_FAILOVER表示等待故障转移(当然在升级成主节点之前还需判断是否满足票数)而对CLUSTER_TODO_HANDLE_FAILOVER标记的处理在beforeSleep函数里的clusterBeforeSleep函数,最终又调回了clusterHandleSlaveFailover函数
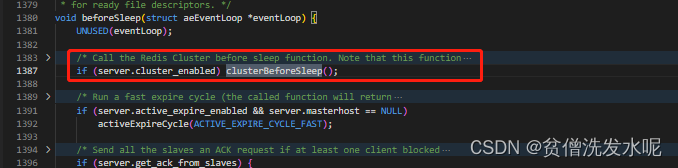
clusterHandleSlaveFailover里会统计票数是否满足成为主节点,若票数足够多,就会调用clusterFailoverReplaceYourMaster升级成主节点
4、槽的分配和迁移
现在,各个节点之间已经互相认识同在一个集群内了。接下来就是,槽位的分配。
众所周知,集群共有16384个槽位被分至各个master节点。
数据结构
在clusterState结构体中,与槽位相关的属性有
struct clusterState {
...
clusterNode *slots[16384]; //记录了槽位由哪个集群节点负责
clusterNode *migrating_slots_to[16384]; //记录了槽位正在迁出到哪个节点
clusterNode *importing_slots_from[16384]; //记录了槽位正在从哪个节点迁出
zskiplist *slots_to_keys; //是一个跳跃表,以槽位号为分数进行排序,记录了槽位上都有哪些key
...
}
在clusterNode结构体中,与槽位相关的属性有
struct clusterNode {
...
unsigned char slots[16384/8]; //这是一个bit数组,共16384位,记录了对应槽位是否由该节点负责
int numslots; //记录了该节点共负责了多少个槽位
...
}
槽位的分配
在集群刚建立时,需要手动对槽位进行分配。而分配槽位的命令则是cluster addslots。
cluster命令的处理函数clusterCommand中处理cluster addslots部分的代码逻辑如下
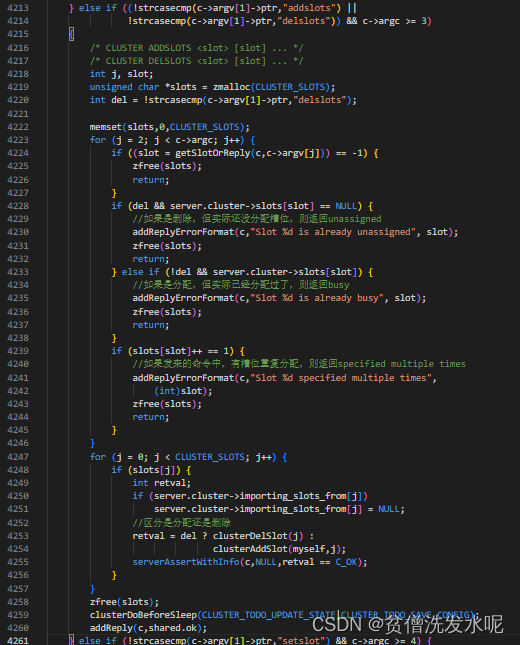
之后集群在发送心跳包时,会附带自己记录的槽位信息(clusterNode结构中的位数组slots),这样最终集群中各个节点就知道了槽位的分配情况了。
槽位的迁移
槽位迁移也是需要手动完成的,其步骤是
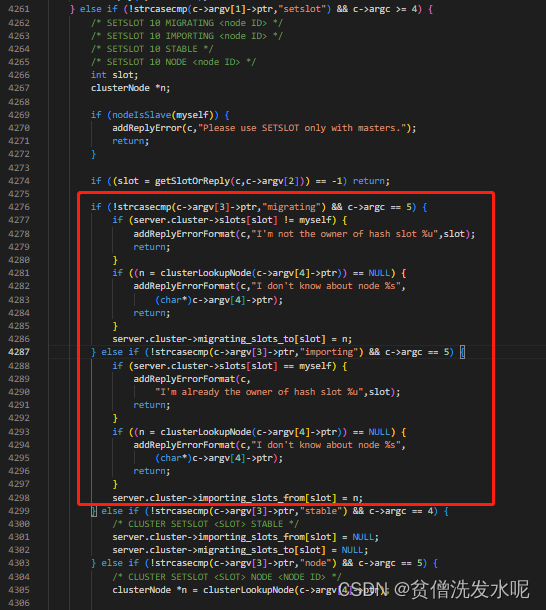
a:向迁入节点发送 CLUSTER SETSLOT <slot> IMPORTING <node> 命令
b:向迁出节点发送 CLUSTER SETSLOT <slot> MIGRATING <node> 命令
这两步的代码逻辑如下
主要就是更新了对应的importing_slots_from和migrating_slots_to数组
c:向迁出节点发送 MIGRATE <target_host> <target_port> <key> <target_database> <timeout> [COPY |REPLACE] 命令
使用migrate命令将key从目标节点的数据库迁出
如果最后一个参数是REPLACE,则发送成功之后,还要在当前实例中删除该key;如果是COPY,则无需删除key;默认参数就是REPLACE。
该命令不仅可以用于集群节点间的key迁移,还能用于普通节点间的key迁移。如果是在集群模式下,则target_database固定为0。
那么问题来了,我们如何知道需要迁出的key是什么?
这个时候可以先用 culster getkeysinslot <solt> <count> 命令去得到槽位上的key。然后再对所以key执行迁出操作,直至槽位中没有剩余的key为止。
culster getkeysinslot逻辑如下
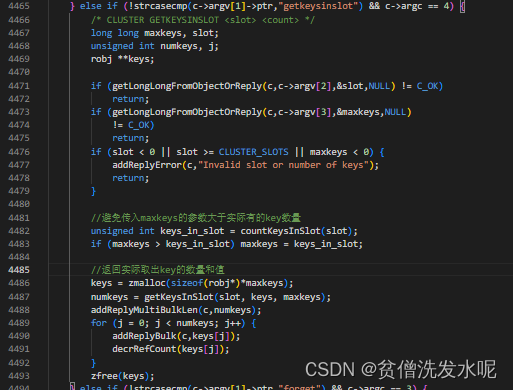
现在已经有了需要迁出的key了,回到migrate命令将其带入即可,其命令处理器是migrateCommand

migrateCommand逻辑如下
void migrateCommand(client *c) {
migrateCachedSocket *cs;
int copy = 0, replace = 0, j;
char *password = NULL;
long timeout;
long dbid;
robj **ov = NULL; //key 值数组
robj **kv = NULL; //key 名数组
robj **newargv = NULL;
rio cmd, payload;
int may_retry = 1;
int write_error = 0;
int argv_rewritten = 0;
int first_key = 3; //key参数的起始位置
int num_keys = 1; //实际迁移的key数量
/******************解析参数*******************/
for (j = 6; j < c->argc; j++) {
int moreargs = j < c->argc-1;
if (!strcasecmp(c->argv[j]->ptr,"copy")) {
copy = 1;
} else if (!strcasecmp(c->argv[j]->ptr,"replace")) {
replace = 1;
} else if (!strcasecmp(c->argv[j]->ptr,"auth")) {
if (!moreargs) {
addReply(c,shared.syntaxerr);
return;
}
j++;
password = c->argv[j]->ptr;
} else if (!strcasecmp(c->argv[j]->ptr,"keys")) {
if (sdslen(c->argv[3]->ptr) != 0) {
addReplyError(c,
"When using MIGRATE KEYS option, the key argument"
" must be set to the empty string");
return;
}
first_key = j+1;
num_keys = c->argc - j - 1;
break; /* All the remaining args are keys. */
} else {
addReply(c,shared.syntaxerr);
return;
}
}
if (getLongFromObjectOrReply(c,c->argv[5],&timeout,NULL) != C_OK ||
getLongFromObjectOrReply(c,c->argv[4],&dbid,NULL) != C_OK)
{
return;
}
if (timeout <= 0) timeout = 1000;
//在连接的数据库中找对应key,若不存在则返回NOKEY。(可能刚好被删了)
ov = zrealloc(ov,sizeof(robj*)*num_keys);
kv = zrealloc(kv,sizeof(robj*)*num_keys);
int oi = 0;
for (j = 0; j < num_keys; j++) {
if ((ov[oi] = lookupKeyRead(c->db,c->argv[first_key+j])) != NULL) {
kv[oi] = c->argv[first_key+j];
oi++;
}
}
num_keys = oi;
if (num_keys == 0) {
zfree(ov); zfree(kv);
addReplySds(c,sdsnew("+NOKEY\r\n"));
return;
}
try_again:
write_error = 0;
/******************建立连接*******************/
//由于会频繁的与目标节点建立连接,所以这一步会建立一个连接缓存,当长时间没有操作时就会自动断开连接(由定时器serverCron检查)。
cs = migrateGetSocket(c,c->argv[1],c->argv[2],timeout);
if (cs == NULL) {
zfree(ov); zfree(kv);
return;
}
/******************填充cmd*******************/
//初始化rio结构的cmd buffer记录要发送的命令
rioInitWithBuffer(&cmd,sdsempty());
//auth命令
if (password) {
serverAssertWithInfo(c,NULL,rioWriteBulkCount(&cmd,'*',2));
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"AUTH",4));
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,password,
sdslen(password)));
}
//若cs连接中上次的dbid和这次的不一样,发送select dbid选择数据库
int select = cs->last_dbid != dbid;
if (select) {
serverAssertWithInfo(c,NULL,rioWriteBulkCount(&cmd,'*',2));
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"SELECT",6));
serverAssertWithInfo(c,NULL,rioWriteBulkLongLong(&cmd,dbid));
}
//依次处理每个需要迁移的key,发送Restore命令
int non_expired = 0;
for (j = 0; j < num_keys; j++) {
//跳过过期的key
long long ttl = 0;
long long expireat = getExpire(c->db,kv[j]);
if (expireat != -1) {
ttl = expireat-mstime();
if (ttl < 0) {
continue;
}
if (ttl < 1) ttl = 1;
}
kv[non_expired++] = kv[j];
serverAssertWithInfo(c,NULL,
rioWriteBulkCount(&cmd,'*',replace ? 5 : 4));
//如果是集群,发送RESTORE-ASKING,反正RESTORE
if (server.cluster_enabled)
serverAssertWithInfo(c,NULL,
rioWriteBulkString(&cmd,"RESTORE-ASKING",14));
else
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"RESTORE",7));
serverAssertWithInfo(c,NULL,sdsEncodedObject(kv[j]));
//发送key对象的ptr数据
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,kv[j]->ptr,
sdslen(kv[j]->ptr)));
//发送key的ttl过期时间
serverAssertWithInfo(c,NULL,rioWriteBulkLongLong(&cmd,ttl));
//向cmd中填充key,以及ttl;然后调用createDumpPayload函数,将值对象o,按照DUMP的格式填充到payload中,然后再将payload填充到cmd中
createDumpPayload(&payload,ov[j],kv[j]);
serverAssertWithInfo(c,NULL,
rioWriteBulkString(&cmd,payload.io.buffer.ptr,
sdslen(payload.io.buffer.ptr)));
sdsfree(payload.io.buffer.ptr);
//如果是集群,发送REPLACE参数
if (replace)
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"REPLACE",7));
}
/******************发送cmd*******************/
num_keys = non_expired;
errno = 0;
{
sds buf = cmd.io.buffer.ptr;
size_t pos = 0, towrite;
int nwritten = 0;
//循环调用syncWrite函数,向远端Redis同步发送cmd中的内容,每次最多发送64k个字节
while ((towrite = sdslen(buf)-pos) > 0) {
towrite = (towrite > (64*1024) ? (64*1024) : towrite);
nwritten = syncWrite(cs->fd,buf+pos,towrite,timeout);
if (nwritten != (signed)towrite) {
write_error = 1;
goto socket_err;
}
pos += nwritten;
}
}
/******************接收cmd回复*******************/
char buf0[1024]; //auth 回复缓存
char buf1[1024]; //select 回复缓存
char buf2[1024]; //restore 回复缓存
//auth回复
if (password && syncReadLine(cs->fd, buf0, sizeof(buf0), timeout) <= 0)
goto socket_err;
//select回复
if (select && syncReadLine(cs->fd, buf1, sizeof(buf1), timeout) <= 0)
goto socket_err;
//restore回复
int error_from_target = 0;
int socket_error = 0;
int del_idx = 1;
//如果最后一个参数不是copy,需要记录本地要删除的key
if (!copy) newargv = zmalloc(sizeof(robj*)*(num_keys+1));
for (j = 0; j < num_keys; j++) {
if (syncReadLine(cs->fd, buf2, sizeof(buf2), timeout) <= 0) {
socket_error = 1;
break;
}
if ((password && buf0[0] == '-') ||
(select && buf1[0] == '-') ||
buf2[0] == '-')
{
//如果回复中第一个字符是'-',说明回复了错误。先设置cs->last_dbid为-1,这样下次迁移时会强制发送"SELECT"命令
if (!error_from_target) {
cs->last_dbid = -1;
char *errbuf;
if (password && buf0[0] == '-') errbuf = buf0;
else if (select && buf1[0] == '-') errbuf = buf1;
else errbuf = buf2;
error_from_target = 1;
addReplyErrorFormat(c,"Target instance replied with error: %s",
errbuf+1);
}
} else {
//如果回复没有'-',说明没有回复错误
if (!copy) {
//此时看最后一个参数是否是copy。如果不是copy则需要将key从本地数据库删除。并记录删除的key,用于后续发送del key命令传播至aof文件或从节点
dbDelete(c->db,kv[j]);
signalModifiedKey(c->db,kv[j]);
server.dirty++;
newargv[del_idx++] = kv[j];
incrRefCount(kv[j]);
}
}
}
if (!error_from_target && socket_error && j == 0 && may_retry &&
errno != ETIMEDOUT)
{
goto socket_err;
}
if (socket_error) migrateCloseSocket(c->argv[1],c->argv[2]);
if (!copy) {
//如果不是copy参数,还需发送del key命令。这样接下来在propagate函数中,才会将该删除操作传递给AOF文件或从节点;
if (del_idx > 1) {
newargv[0] = createStringObject("DEL",3);
replaceClientCommandVector(c,del_idx,newargv);
argv_rewritten = 1;
} else {
zfree(newargv);
}
newargv = NULL;
}
if (!error_from_target && socket_error) {
may_retry = 0;
goto socket_err;
}
if (!error_from_target) {
//更新此次dbid
cs->last_dbid = dbid;
addReply(c,shared.ok);
} else {
/* On error we already sent it in the for loop above, and set
* the currently selected socket to -1 to force SELECT the next time. */
}
sdsfree(cmd.io.buffer.ptr);
zfree(ov); zfree(kv); zfree(newargv);
return;
socket_err:
sdsfree(cmd.io.buffer.ptr);
if (!argv_rewritten) migrateCloseSocket(c->argv[1],c->argv[2]);
zfree(newargv);
newargv = NULL;
//如果写命令或读回复发生错误且不是超时错误且还没重试过的话,则重试一次
if (errno != ETIMEDOUT && may_retry) {
may_retry = 0;
goto try_again;
}
zfree(ov); zfree(kv);
addReplySds(c,
sdscatprintf(sdsempty(),
"-IOERR error or timeout %s to target instance\r\n",
write_error ? "writing" : "reading"));
return;
}
而被迁移的目标节点在收到RESTORE-ASKING或RESTORE命令后,将命令中的key和value保存到本地数据库中。
这两个命令的区别是:RESTORE-ASKING命令用于集群节点间的key迁移,RESTORE命令用于普通节点间的key迁移。RESTORE-ASKING命令对应的redisCommand结构标志位中带有’k’标记,这样在键迁移时,就不会返回ASK重定向错误;
这两个命令的命令处理器restoreCommand

restoreCommand 逻辑如下
void restoreCommand(client *c) {
long long ttl, lfu_freq = -1, lru_idle = -1, lru_clock = -1;
rio payload;
int j, type, replace = 0, absttl = 0;
robj *obj;
//解析参数
for (j = 4; j < c->argc; j++) {
int additional = c->argc-j-1;
if (!strcasecmp(c->argv[j]->ptr,"replace")) {
replace = 1;
} else if (!strcasecmp(c->argv[j]->ptr,"absttl")) {
absttl = 1;
} else if (!strcasecmp(c->argv[j]->ptr,"idletime") && additional >= 1 &&
lfu_freq == -1)
{
if (getLongLongFromObjectOrReply(c,c->argv[j+1],&lru_idle,NULL)
!= C_OK) return;
if (lru_idle < 0) {
addReplyError(c,"Invalid IDLETIME value, must be >= 0");
return;
}
lru_clock = LRU_CLOCK();
j++; /* Consume additional arg. */
} else if (!strcasecmp(c->argv[j]->ptr,"freq") && additional >= 1 &&
lru_idle == -1)
{
if (getLongLongFromObjectOrReply(c,c->argv[j+1],&lfu_freq,NULL)
!= C_OK) return;
if (lfu_freq < 0 || lfu_freq > 255) {
addReplyError(c,"Invalid FREQ value, must be >= 0 and <= 255");
return;
}
j++; /* Consume additional arg. */
} else {
addReply(c,shared.syntaxerr);
return;
}
}
//如果replace为1,则从数据库中查找相应的key,如果查不到,则直接回复客户端错误信息;
robj *key = c->argv[1];
if (!replace && lookupKeyWrite(c->db,key) != NULL) {
addReply(c,shared.busykeyerr);
return;
}
//解析ttl
if (getLongLongFromObjectOrReply(c,c->argv[2],&ttl,NULL) != C_OK) {
return;
} else if (ttl < 0) {
addReplyError(c,"Invalid TTL value, must be >= 0");
return;
}
//验证DUMP格式的值对象参数中的验证码是否正确
if (verifyDumpPayload(c->argv[3]->ptr,sdslen(c->argv[3]->ptr)) == C_ERR)
{
addReplyError(c,"DUMP payload version or checksum are wrong");
return;
}
//从命令参数中解析出值对象的类型和值对象本身保存到对应的变量
rioInitWithBuffer(&payload,c->argv[3]->ptr);
if (((type = rdbLoadObjectType(&payload)) == -1) ||
((obj = rdbLoadObject(type,&payload,key)) == NULL))
{
addReplyError(c,"Bad data format");
return;
}
//如果replace为1,则将key数据库删除
int deleted = 0;
if (replace)
deleted = dbDelete(c->db,key);
if (ttl && !absttl) ttl+=mstime();
if (ttl && checkAlreadyExpired(ttl)) {
if (deleted) {
rewriteClientCommandVector(c,2,shared.del,key);
signalModifiedKey(c->db,key);
notifyKeyspaceEvent(NOTIFY_GENERIC,"del",key,c->db->id);
server.dirty++;
}
decrRefCount(obj);
addReply(c, shared.ok);
return;
}
//db添加key,value
dbAdd(c->db,key,obj);
//如果有ttl,设置ttl
if (ttl) {
setExpire(c,c->db,key,ttl);
}
objectSetLRUOrLFU(obj,lfu_freq,lru_idle,lru_clock);
signalModifiedKey(c->db,key);
addReply(c,shared.ok);
server.dirty++;
}
至此,就完成了key的迁移过程。
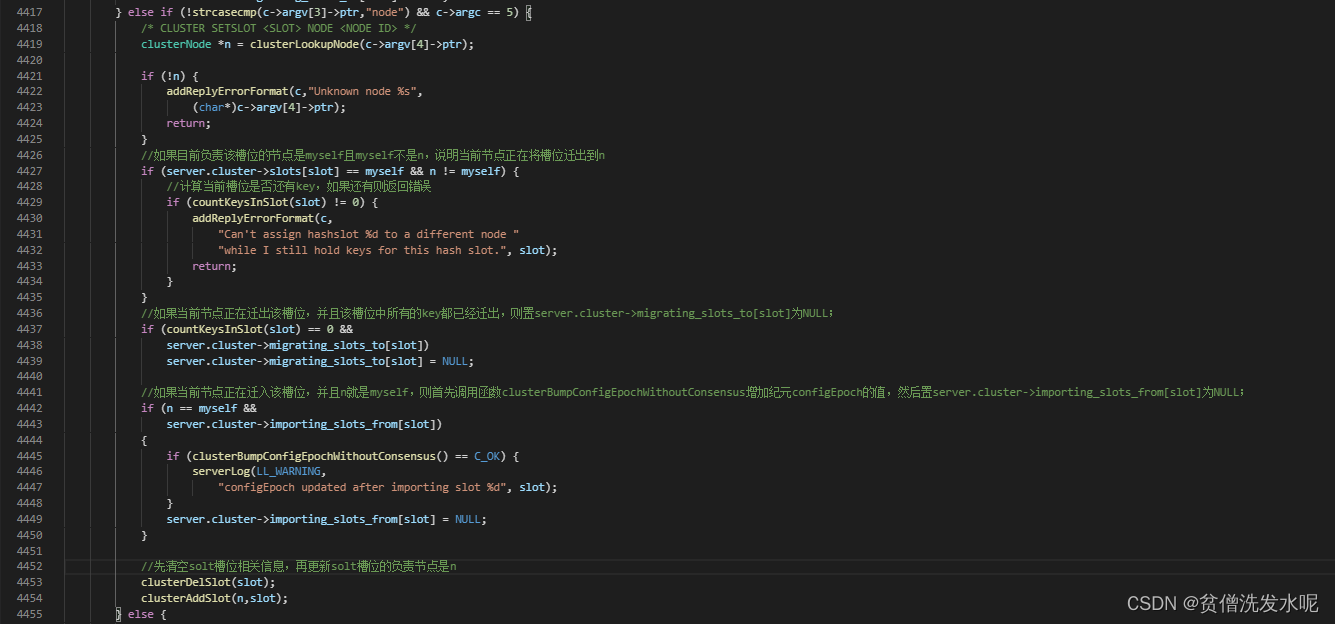
d:向所有节点发送 CLUSTER SETSLOT <slot> NODE <nodeid> 命令
当所有key迁移完成后,即可向所有节点发送 CLUSTER SETSLOT <slot> NODE <nodeid> 以便通知所有节点,更新槽位 新的负责节点为。
在cluster命令处理器clusterCommand中, 对应的处理逻辑如下
5、集群节点命令的执行
如果开启了集群模式,在执行命令时会先判断命令中的key是否存在与本节点,如果是则直接处理。如果不是且正在迁移槽位则返回ASKING重定向到迁出节点。如果也没有正在迁出槽位,则返回MOVED重定向到该key真正负责的节点。
ASK错误和MOVED错误都会导致客户端转向,它们的区别在于:
a:MOVED错误代表槽位的负责权已经从一个节点转移到了另一个节点:在客户端收到 关于槽位i的MOVED错误之后,会更新槽位i及其负责节点的对应关系,这样下次遇到关于槽位i的命令请求时,就可以直接将命令请求发送新的负责节点。
b:ASK错误只是两个节点在迁移槽的过程中使用的一种临时措施:客户端收到关于槽位i的ASK错误之后,客户端只会在接下来的一次命令请求中将关于槽位i的命令请求发送至ASK错误所指示的节点,但这种重定向不会对客户端今后发送关于槽位i的命令请求产生任何影响,客户端之后仍然会将关于槽位i的命令请求发送至目前负责处理该槽位的节点,除非ASK错误再次出现。
processCommand中这部分的处理逻辑如下
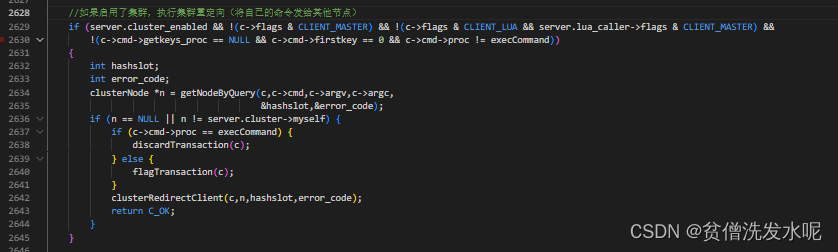
其中getNodeByQuery则是查询负责key的节点,而clusterRedirectClient则会根据查询key节点过程中error_code的不同做不同的重定向。
getNodeByQuery逻辑如下
clusterNode *getNodeByQuery(client *c, struct redisCommand *cmd, robj **argv, int argc, int *hashslot, int *error_code) {
clusterNode *n = NULL;
robj *firstkey = NULL;
int multiple_keys = 0;
multiState *ms, _ms;
multiCmd mc;
int i, slot = 0, migrating_slot = 0, importing_slot = 0, missing_keys = 0;
if (server.cluster_module_flags & CLUSTER_MODULE_FLAG_NO_REDIRECTION)
return myself;
if (error_code) *error_code = CLUSTER_REDIR_NONE;
//统一按事务模式处理
if (cmd->proc == execCommand) {
if (!(c->flags & CLIENT_MULTI)) return myself;
ms = &c->mstate;
} else {
ms = &_ms;
_ms.commands = &mc;
_ms.count = 1;
mc.argv = argv;
mc.argc = argc;
mc.cmd = cmd;
}
//循环处理所有命令
for (i = 0; i < ms->count; i++) {
struct redisCommand *mcmd;
robj **margv;
int margc, *keyindex, numkeys, j;
mcmd = ms->commands[i].cmd;
margc = ms->commands[i].argc;
margv = ms->commands[i].argv;
//循环处理本条命令中的所有key
keyindex = getKeysFromCommand(mcmd,margv,margc,&numkeys);
for (j = 0; j < numkeys; j++) {
robj *thiskey = margv[keyindex[j]];
//计算该key所属的槽位号thisslot
int thisslot = keyHashSlot((char*)thiskey->ptr,
sdslen(thiskey->ptr));
if (firstkey == NULL) {
firstkey = thiskey;
slot = thisslot; //记录槽位
n = server.cluster->slots[slot]; //根据槽位寻找节点记录到n
//如果n为NULL,则说明该槽位没有节点负责,集群目前处于下线状态,因此设置error_code为REDIS_CLUSTER_REDIR_DOWN_UNBOUND
if (n == NULL) {
getKeysFreeResult(keyindex);
if (error_code)
*error_code = CLUSTER_REDIR_DOWN_UNBOUND;
return NULL;
}
//如果n是myself,看是否正在迁入迁出当前槽位并标记
if (n == myself &&
server.cluster->migrating_slots_to[slot] != NULL)
{
migrating_slot = 1;
} else if (server.cluster->importing_slots_from[slot] != NULL) {
importing_slot = 1;
}
} else {
//检查key是否在同一个槽位,如果不是返回CLUSTER_REDIR_CROSS_SLOT错误
if (!equalStringObjects(firstkey,thiskey)) {
if (slot != thisslot) {
getKeysFreeResult(keyindex);
if (error_code)
*error_code = CLUSTER_REDIR_CROSS_SLOT;
return NULL;
} else {
multiple_keys = 1;
}
}
}
//如果当前节点正在迁入或者迁出该槽位,并且在0号数据库中找不到该key,则增加missing_keys的值
if ((migrating_slot || importing_slot) &&
lookupKeyRead(&server.db[0],thiskey) == NULL)
{
missing_keys++;
}
}
getKeysFreeResult(keyindex);
}
//遍历完所有命令的所有key后,走到现在,能保证所有key都属于同一个槽位slot,该槽位由节点n负责处理
//如果n为NULL,说明所有命令中都不包含任何key,因此返回myself,表示当前节点可以处理该命令
if (n == NULL) return myself;
//如果集群下线,返回CLUSTER_REDIR_DOWN_STATE错误
if (server.cluster->state != CLUSTER_OK) {
if (error_code) *error_code = CLUSTER_REDIR_DOWN_STATE;
return NULL;
}
//将槽位保存到出参hashslot
if (hashslot) *hashslot = slot;
//如果正在迁入/迁出槽位,且命令是migrateCommand则返回本节点
if ((migrating_slot || importing_slot) && cmd->proc == migrateCommand)
return myself;
//如果当前节点正在迁出槽位,并且命令中的key有的已经不再当前节点中了,则设置错误码为REDIS_CLUSTER_REDIR_ASK,并返回该槽位所迁出的目的地节点
if (migrating_slot && missing_keys) {
if (error_code) *error_code = CLUSTER_REDIR_ASK;
return server.cluster->migrating_slots_to[slot];
}
//如果当前节点正在迁入槽位,并且客户端具有ASKING标记(客户端之前发来过”ASKING”命令)或者该命令本身就具有ASKING标记(”RESTORE-ASKING”命令)
if (importing_slot &&
(c->flags & CLIENT_ASKING || cmd->flags & CMD_ASKING))
{
//则只有在涉及多个key,并且有的key不在当前节点中的情况下,才设置错误码为REDIS_CLUSTER_REDIR_UNSTABLE,并返回NULL;否则,返回当前节点
if (multiple_keys && missing_keys) {
if (error_code) *error_code = CLUSTER_REDIR_UNSTABLE;
return NULL;
} else {
return myself;
}
}
//如果当前节点正好为n节点的从节点,而且客户端是只读客户端,并且该命令是只读命令,则返回当前节点
if (c->flags & CLIENT_READONLY &&
(cmd->flags & CMD_READONLY || cmd->proc == evalCommand ||
cmd->proc == evalShaCommand) &&
nodeIsSlave(myself) &&
myself->slaveof == n)
{
return myself;
}
//moved重定向
if (n != myself && error_code) *error_code = CLUSTER_REDIR_MOVED;
return n;
}
clusterRedirectClient逻辑如下
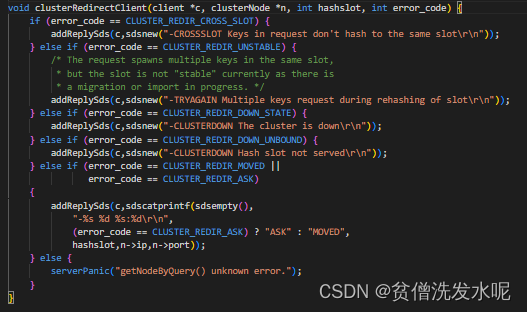
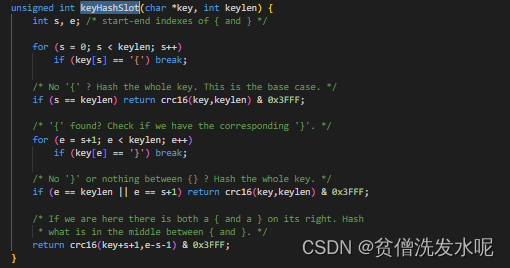
最后再提一下getNodeByQuery中的keyHashSlot函数。这个函数是集群计算key槽位的逻辑。用到的是hash slot算法。计算key的CRC16值,然后对16384取模,得到对应的槽位。
6、主从复制
为了保证高可用性,一般情况下,主节点都会至少有一个从节点。在集群中,可以向集群节点发送CLUSTER REPLICATE <nodeID>命令使其成为nodeId的从节点。
在函数clusterCommand中,处理这部分的代码如下
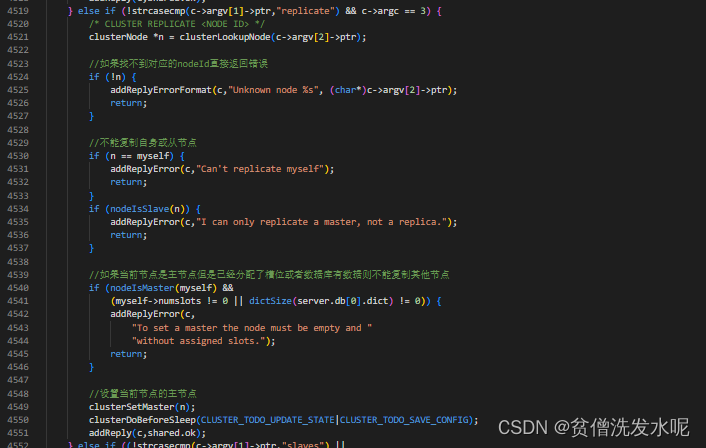
其中clusterSetMaster则是建立新的主从关系函数,逻辑如下
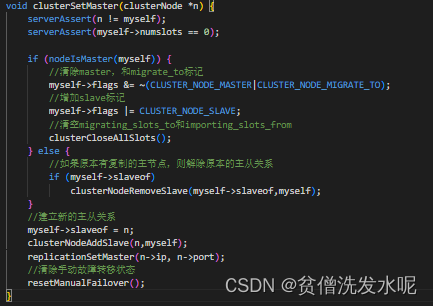
可以发现最后调用了replicationSetMaster(相当于执行了SLAVE OF命令开始redis的主从复制流程)。
附录
集群数据结构关系图



集群命令
槽分配为什么不用一致性hash算法
1:一致性hash算法可能导致循环雪崩
2:hash slot比较简单粗暴,所以无论是新增/删除节点还是宕机后的维护成本都比较低,方便人工干预
3:hash slot可以分配的更均匀
参考文献
《Redis设计与实现》黄健宏著
redis-5.0.14源码
https://www.cnblogs.com/gqtcgq/p/7247042.html

![[5]. 最长回文子串](https://img-blog.csdnimg.cn/1571a759ab84465db29c18557d217591.png)


![[C语言]进一步的来了解指针(多多多图详解)](https://img-blog.csdnimg.cn/ccedd1ff336345b68453dfaa8201fb51.png)