目录
一、fork函数
1、概念
2、父子进程的共享
3、 为什么父子进程会从fork()调用之后的位置继续执行代码
4、写时拷贝
5、为什么需要写时拷贝
6、写时拷贝的好处
7、fork常规用法
8、fork调用失败的原因
9、查看系统最大进程数
二、进程终止
1、进程退出场景
2、查看进程退出码
3、进程终止常见方式
正常终止(main,exit,_exit)
异常退出
4、三种进程终止区别
库函数(如exit())
系统接口(如_exit())
缓冲区
return 与进程退出
一、fork函数
1、概念
#include <unistd.h>
pid_t fork(void);返回值:自进程中返回0,父进程返回子进程id,出错返回-1
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中
- fork返回,开始调度器调度
2、父子进程的共享
- 当创建子进程时,操作系统会为之分配特定的内核结构,以确保其具有独立性。理论上,这意味着子进程应拥有自己的代码和数据副本。
- 然而,在实际操作中,我们通常不会经历一个显式的加载过程来为子进程提供独立的代码和数据。这导致子进程实际上是在“共享”父进程的代码和数据。
- 对于代码部分,由于它是只读的,父子进程共享同一份代码不会引起问题。这种方法既高效又节省内存,因为不需要为每个子进程复制代码。
- 对于数据部分,情况则大不相同。
- 由于数据可能会被进程修改,保持数据的独立性变得尤为重要。如果父子进程共享相同的数据副本,任何一方对数据的修改都会影响到另一方,破坏了进程间的独立性。
- 因此,操作系统采用了一种机制,如写时拷贝,在必要时将数据复制一份,确保子进程在需要修改数据时能够拥有自己的独立数据副本。这样既保证了进程间的独立性,又在不必要的复制操作上节省了资源。
观察下面程序:
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t id=fork();
if(id<0)
{
//创建失败
perror("fork");
return 1;
}
else if(id==0)
{
//child process
while(1)
{
printf("I am child, pid:%d, ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
else
{
//parent process
while(1)
{
printf("I am father, pid:%d, ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
printf("you can see me\n");
sleep(1);//进程退出顺序不一样
return 0;
}
fork创建进程后,根据id的不同执行父子进程对应的代码,也就是说fork函数会有两个返回值?

使用fork()函数创建一个新的子进程,该子进程是调用进程的副本。在fork()之后,程序会有两个不同的执行流,父进程和子进程将会从fork()调用之后的位置继续执行代码。(思考为什么?)- 由于
fork()在父进程和子进程中都会进行返回,也就是fork()函数内部return会被执行两次:在父进程中返回新创建的子进程的PID(进程ID),在子进程中返回0,所以return的本质就是对变量id进行写入。
3、 为什么父子进程会从fork()调用之后的位置继续执行代码
在
fork()之后,程序会有两个不同的执行流,父进程和子进程将会从fork()调用之后的位置继续执行代码。
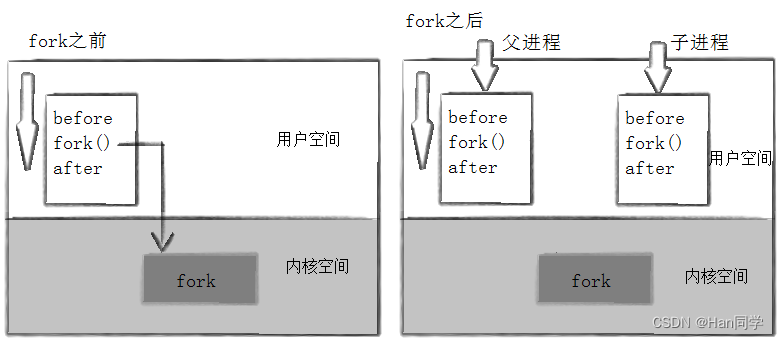
fork之后,父子进程代码共享,是after这部分共享,还是所有的代码都共享?
- 答案:所有代码都会共享。
解释上面问题前,我们先来复习两个概念:
- 程序计数器(PC):PC是一个特殊的寄存器,用来存储下一条要执行的指令的地址。在任意时刻,PC都指向程序中当前正在执行或即将执行的代码位置。
- 进程上下文:当操作系统进行进程切换时,它保存当前进程的状态(包括PC和其他寄存器的值),以便该进程在未来某个时刻继续执行时,能从正确的位置恢复。这个保存的状态集合就是所谓的“进程上下文”。
我们现在来回答刚才的问题:
fork()之后的行为:当fork()被调用时,操作系统会为子进程创建一个与父进程几乎完全相同的副本,包括代码、数据、堆和栈的复制(通过写时复制技术优化),但是父子进程会有各自独立的进程上下文。- 尽管它们可能共享相同的代码段,但是各自的PC值会指向
fork()调用后的下一条指令,使得父子进程从fork()之后的代码位置继续各自的执行流。这意味着,虽然父子进程在物理上共享代码,但它们执行的路径可以完全不同,因为它们的执行流、栈、寄存器状态等是独立的。
因此,在fork()之后,子进程认为自己的程序计数器(PC)起始值就是fork()调用之后的代码位置,从这一点继续执行,而与父进程的执行流相互独立。这种设计使得父子进程能在共享代码的同时,执行各自独立的任务。
4、写时拷贝
Linux操作系统在使用写时拷贝(Copy-On-Write, COW)技术管理进程内存时,确实会使得父进程和子进程共享代码段,而只有在写操作尝试发生时才会拷贝数据段或者堆栈段。这种设计是为了提高内存使用效率和减少不必要的数据复制。

-
共享代码段:当一个进程(父进程)创建一个子进程时,Linux操作系统会使子进程与父进程共享相同的代码段。这是因为代码是静态的、只读的,不会被进程修改,所以多个进程可以安全地共享同一份代码。这部分共享的代码通常存在于操作系统的物理内存中,在内存的某个位置。
-
拷贝数据段和堆栈段:对于数据段和堆栈段,原则上是每个进程有自己的一份,以存储各自的全局变量、局部变量、堆分配的内存等。当使用写时拷贝机制时,只有当某个进程试图修改这些共享的数据段或堆栈段中的内容时,操作系统才会为该进程创建这部分内存的私有拷贝,以确保修改不会影响到其他共享这部分内存的进程。
-
访问代码:当子进程访问代码段时,它通过自己的页表映射到相同的物理内存地址上,这块内存存储了父进程的代码段。由于代码是只读的,所以多个进程(无论是父进程还是子进程)都可以共享这一块内存,而不会造成数据的不一致。
-
修改数据:当子进程需要修改数据时,操作系统利用写时拷贝机制来处理这一请求。如果子进程尝试写入一个共享的数据页,操作系统会首先为这个数据页创建一个拷贝,然后更新子进程的页表,使得这个被写入的地址映射到这个新的、属于子进程自己的物理内存页上。因此,这次写操作只会影响子进程自己的数据页,而不会影响到父进程或其他共享这个数据页的进程。
通过下面的例子来理解一下:
#include <stdio.h>
#include <unistd.h>
int g_val=100;
int main()
{
pid_t id=fork();
if(id==0)
{
int n=0;
while(1)
{
printf("I am child. pid: %d, ppid %d, g_val: %d, &g_val: %p\n",\
getpid(),getppid(),g_val,&g_val);
sleep(1);
n++;
if(n==5)
{
g_val=200;
printf("child change g_val 100 -> 200 success\n");
}
}
}
else
{
while(1)
{
printf("I am father. pid: %d, ppid %d, g_val: %d, &g_val: %p\n",\
getpid(),getppid(),g_val,&g_val);
sleep(1);
}
}
return 0;
}
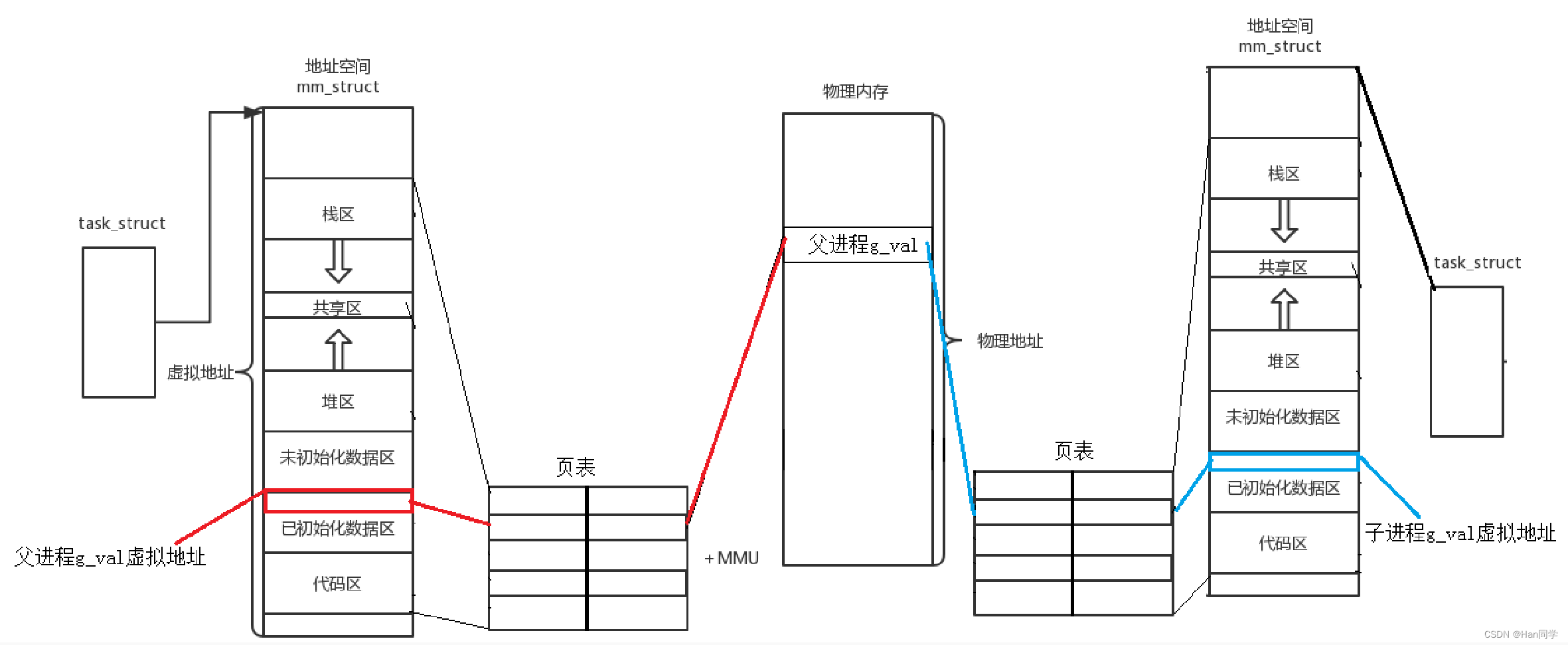
我们可以看到,一开始子进程和父进程的g_val的值相同,而且地址也相同。当子进程修改全局变量g_val的值之后,父子进程的g_val的值不同了,但父子进程中g_val的地址依然相同,这是为什么呢?

-
我们观察到父进程和子进程在子进程修改全局变量
g_val之前共享相同的变量值和地址。这是因为Linux采用了写时拷贝(Copy-On-Write, COW)机制来优化内存使用。-
在
fork()调用之后(子进程未修改g_val时),父进程和子进程实际上共享相同的物理内存页,包括全局变量g_val。这就是为什么一开始g_val的地址在父子进程中看起来相同的原因。
-
-
当子进程尝试修改
g_val的值时,操作系统侦测到这一写操作,并触发写时拷贝机制。-
这时,操作系统为子进程分配一个新的物理内存页,用于存储修改后的
g_val值,而父进程继续使用原来的物理内存页。 -

-
因此,尽管父子进程中
g_val的虚拟地址未变,它们现在指向不同的物理地址,这就是为什么修改后子进程中g_val的值变为200,而父进程中g_val的值仍然是100的原因。
-
总结来说,
- 写时拷贝机制确保了在子进程尝试修改共享数据之前,父子进程可以高效地共享相同的物理内存页。
- 一旦发生写操作,操作系统会为子进程分配新的物理内存页,以保持父子进程数据的独立性。
这就解释了为什么在子进程修改
g_val之后,父子进程的g_val值不同,但它们的虚拟地址仍然相同的现象。
5、为什么需要写时拷贝
字面意思理解:为何要选择写时拷贝的技术?对父子进程进行分离
- 用的时候,再分配,是高效使用内存的一种表现。
- 操作系统无法在代码执行前预知那些空间会被访问,所以不提前分配。
写时拷贝本质上是一种延迟分配策略。它允许操作系统延迟数据的复制直到实际需要修改数据时,从而优化内存使用和提高系统效率。
对于数据处理而言,进程创建时采用“写时拷贝”(Copy-On-Write, COW)技术的原因可以从几个方面来理解:
-
内存效率:当创建一个进程时,操作系统初期并不直接为子进程拷贝所有父进程的数据空间,因为这样做可能会拷贝大量子进程根本不会用到的数据。这不仅浪费了宝贵的内存资源,还增加了进程创建的时间。通过写时拷贝技术,只有当父进程或子进程尝试写入某个内存区域时,才会实际拷贝这部分内存。这样,只有被修改的数据才会被复制,未修改的数据则可以由父子进程共享,从而极大地提高了内存使用效率。
-
不可预知性:在进程运行之前,操作系统通常无法知道哪些具体的数据会被访问或修改。如果采用预先拷贝的方式,可能会拷贝很多最终未被使用或仅被读取的数据。写时拷贝技术允许系统延迟拷贝的决定,直到确实需要修改数据的那一刻,从而更加合理地利用资源。
-
优化资源利用:通过延迟数据拷贝,写时拷贝不仅减少了内存的占用,也减轻了操作系统的负担,因为只有在必要时才进行数据复制。这种策略意味着系统可以更有效地管理内存,同时也简化了进程创建和数据管理的过程。
6、写时拷贝的好处
- 因为写时拷贝的存在,父子进程得以彻底分离,这样就保证了进程独立性。
- 写时拷贝,是一种延时申请技术,可以提高整机内存的使用率。
7、fork常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子 进程来处理请求。
- 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
8、fork调用失败的原因
- 系统中有太多的进程。
- 实际用户的进程数超过了限制。
9、查看系统最大进程数
#include <stdio.h>
#include <unistd.h>
int main()
{
int max_cnt=0;
while(1)
{
pid_t id=fork();
if(id<0)
{
printf("fork error:%d\n",max_cnt);
break;
}
if(id==0)
{
while(1)
{
sleep(1);
}
}
else
{
}
max_cnt++;
}
}
输出结果:
![]()
删除刚刚用于统计所创建的进程

二、进程终止
进程终止时,操作系统做了什么?
- 当然要释放进程申请的相关内核数据结构和对应的数据和代码,本质就是释放系统资源。
1、进程退出场景
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码异常终止
在程序设计和开发中,
main函数的返回值扮演着重要的角色,它向操作系统或上一级进程传达了程序执行的最终状态。这个返回值,也被称为退出码(Exit Code)或退出状态(Exit Status),是进程终止时的一个标识,用于表示程序的执行结果。
-
代码执行完成,结果正确: 这是最理想的情况,程序按照预期执行完所有的操作,并且输出了正确的结果。在这种情况下,进程通常通过执行完毕其入口点(如C语言的
main函数)中的所有代码自然终止。如果是在main函数中,通常会看到一个return 0;语句,表示程序正常退出。 -
代码执行完成,结果不正确: 程序虽然执行到了最后,但是由于逻辑错误、错误的输入等原因,其输出的结果并不是预期的。在这种情况下,进程也是通过执行完毕其入口点中的所有代码终止,但是可以通过
main函数返回一个非零值来表示错误的发生。这个非零值可以是任意的,不同的值可以代表不同的错误类型,这样做可以帮助开发者快速定位问题。 -
代码没有执行完,程序崩溃: 这种情况通常是由于程序中存在严重的错误,如访问非法内存、除零操作等,导致操作系统强制终止了程序的执行。在程序崩溃的情况下,
main函数中的return语句不会被执行,因此程序的退出码没有意义。程序崩溃通常需要开发者通过调试工具来分析程序的崩溃原因。
2、查看进程退出码
可以通过在终端中执行
echo $?命令来查看上一个终止的进程的退出码。
我们看下面代码,可以用变量代替退出码。
#include <stdio.h>
#include <unistd.h>
int sum(int top)
{
int s=0;
for(int i=1;i<=top;i++)
{
s+=i;
}
return s;
}
int main()
{
int ret=0;
printf("hello world: pid: %d, ppid: %d\n",getpid(),getppid());
int res=sum(100);
if(res!=5050)
{
ret=1;
}
return ret;
}
[hbr@VM-16-9-centos control]$ make
gcc -o myproc myproc.c
[hbr@VM-16-9-centos control]$ ./myproc
hello world: pid: 7676, ppid: 4960
[hbr@VM-16-9-centos control]$ echo $?
0
将res修改为计算1到101的累加和,退出码为1,表示程序判断错误,累加和不等于5050。
[hbr@VM-16-9-centos control]$ vim myproc.c
[hbr@VM-16-9-centos control]$ make
gcc -o myproc myproc.c
[hbr@VM-16-9-centos control]$ ./myproc
hello world: pid: 8304, ppid: 4960
[hbr@VM-16-9-centos control]$ echo $?
1
打印系统错误信息:
strerror()函数会根据传入的错误号码返回相应的错误信息字符串。这些错误信息是系统定义的,可以帮助开发者诊断程序中出现的问题。
#include <stdio.h>
#include <string.h>
int main()
{
for(int number=0;number<100;number++)
{
printf("%d: %s\n",number,strerror(number));
}
}

使用ls 查看一个不存在的目录或文件,这时打印错误信息,得到错误码为2,由上图可知,2对应的就是下面程序的错误信息 No such file or directory。
[hbr@VM-16-9-centos control]$ ls file
ls: cannot access file: No such file or directory
[hbr@VM-16-9-centos control]$ echo $?
23、进程终止常见方式
正常终止(main,exit,_exit)
正常终止意味着程序按预期完成了其任务或者明确地由于某种原因结束了执行。这可以通过以下几种方式实现:
从main函数返回:这是最常见的终止方式。程序执行完毕后,main函数返回一个整数值给操作系统。返回值0通常表示程序成功执行,没有错误。而返回非零值(如1)则表示程序遇到了某种错误或问题。例如:
int main() {
// 程序代码
return 0; // 正常退出
return 1; // 出现错误
}调用exit函数:exit函数可以在程序的任何地方被调用,用来立即终止程序,并将退出码返回给操作系统。这对于在深层嵌套函数中终止程序非常有用。
#include <unistd.h>
void exit(int status);exit最后也会调用_exit, 但在调用_exit之前,还做了其他工作:
- 执行用户通过 atexit或on_exit定义的清理函数。
- 关闭所有打开的流,所有的缓存数据均被写入
- 调用_exit
调用_exit或_Exit函数:这两个函数与exit类似,但是它们不会调用任何注册的退出处理函数(如由atexit注册的函数),也不会刷新标准I/O缓冲区。它们通常用在需要立即退出程序而不进行任何清理操作的情况下。
#include <unistd.h>
void _exit(int status);- 说明:虽然status是int,但是仅有低8位可以被父进程所用。所以_exit(-1)时,在终端执行$?发现返回值是255。
异常退出
异常退出通常是由于程序运行时遇到了错误或者被外部信号强制终止。
信号终止:程序可以通过接收到特定的信号而被异常终止。
- 例如,当你在终端中按
Ctrl + C时,会向前台进程组发送SIGINT信号,这通常会导致程序异常终止。
处理这类信号通常需要在程序中显式地捕获和处理这些信号,以决定是否终止程序或执行某些特定的清理操作。
4、三种进程终止区别
库函数(如exit())
库函数是编程语言提供的,用于执行特定任务的函数,它们是应用层的接口。
- 例如,
exit()函数是C标准库的一部分,用于结束当前进程并进行适当的清理操作,比如关闭文件描述符、清空标准输入输出的缓冲区等。 - 库函数为开发者提供了一个高级的抽象,隐藏了底层操作系统的复杂性,使得开发者可以更容易地编写跨平台的应用程序。
系统接口(如_exit())
系统接口,或称为系统调用,是操作系统提供给应用程序的接口。
_exit()函数是一个系统调用,直接由操作系统提供,用于立即结束进程,不执行标准库的清理和缓冲区刷新操作。- 系统接口让应用程序能够请求操作系统的服务,如文件操作、进程控制等。
缓冲区
谈到
printf函数,所提到的“缓冲区”指的是一个临时存储区,用于暂存输出数据。这个缓冲区是由C标准库维护的,而不是操作系统。
- C库提供的输入输出函数(如
printf和scanf)通常使用这些缓冲区来提高数据处理的效率,通过减少对操作系统调用的次数来达到优化性能的目的。 - 当调用
exit()函数时,C标准库会负责刷新输出缓冲区,确保所有暂存的输出数据都被正确地写入其目标介质,如终端或文件。相反,如果直接调用_exit(),这种刷新操作不会发生,因为_exit()绕过了标准库,直接请求操作系统结束进程。
return 与进程退出
- 在C程序中,从
main函数执行return操作是结束进程的一种常见方法。 - 实际上,执行
return n;在main函数中的效果等同于调用exit(n);,因为C程序的启动代码(运行时环境)会捕捉到main函数的return返回值,并将其作为参数传给exit函数。这样,即便是通过return退出,也能保证执行标准库的清理工作,如刷新缓冲区和关闭文件。