自然语言处理基本概念
概念:自然语言处理,是让机器理解人的语言的过程。
作用:通过使用自然语言处理,机器可以理解人的语言,从而进行语义分析,例如:从一句话中判断喜怒哀乐;从一段文字中判断是否存在存在诈骗…等等
语义分析和单纯的关键词简单检索有什么区别:
比如:对于a.你吃饭了吗? b.你?饭?吃?了?吗,语义分析可以明白这两句话意思大致相同,但是关键词检索大概率无法识别。
原理:基于多层神经网络
如果理解自然语言处理
首先要明白,人类理解一句话是一个什么过程,当人听到一句话的时候,通常通过这段话里的音素(abcd)、词汇,语法,上下文,所以在自然语言处理中,也需要针对这四个部分进行处理,那这四个过程就被称为:
自然语言处理的四个过程
- Tokenisation 标记化
- Part-of-speech tagging 将部分语音进行标记
- Syntactic Parsing: constituency and dependency 同步解析
- Name Entity Recognition 名称实体识别
使用方法
- NLTK
- spaCy
- Stanford CoreNLP
- Jieba(主要应用于中文)
这里选择spacy作为例子
官方文档地址
先pip install spacy再python -m spacy download en_core_web_sm
任务一:NLP task 1: Tokenisation
tokenisation是通过使用数据处理的方式应用在文本上,将文本分成一个个小单元,当然这些单元在英语中就是一个个单词,但是在中文中就是一个个词语注意不是单个文字!
tokenisation是很多自然语言处理的第一个步骤,因为通过这种方式可以先简单的分析我们所要分析的文本内容。
spacy如何工作呢?
spacy使用直接套用文本内容的方法进行分词,
可以查看官网如下:
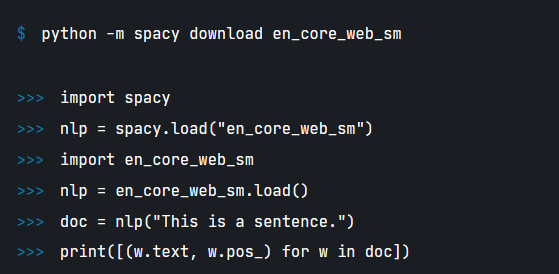
这里使用这样一句话作为例子The prime minister has said he will formally invite Joe Biden to Northern lrelandto mark the 25th anniversary of the Good Friday Agreement.
import spacy
nlp = spacy.load("en_core_web_sm")
import en_core_web_sm
nlp = en_core_web_sm.load()
doc = nlp(
"The prime minister has said he will formally invite Joe Biden to Northern lrelandto mark the 25th anniversary of the Good Friday Agreement.")
for token in doc:
print(token)
结果:
任务二:NLP task : POS tagging
是标注各个词语性质的过程,这对于整个文本的阅读是十分必要的,能够给各个词语分配他的词性。
spacy的词性介绍:
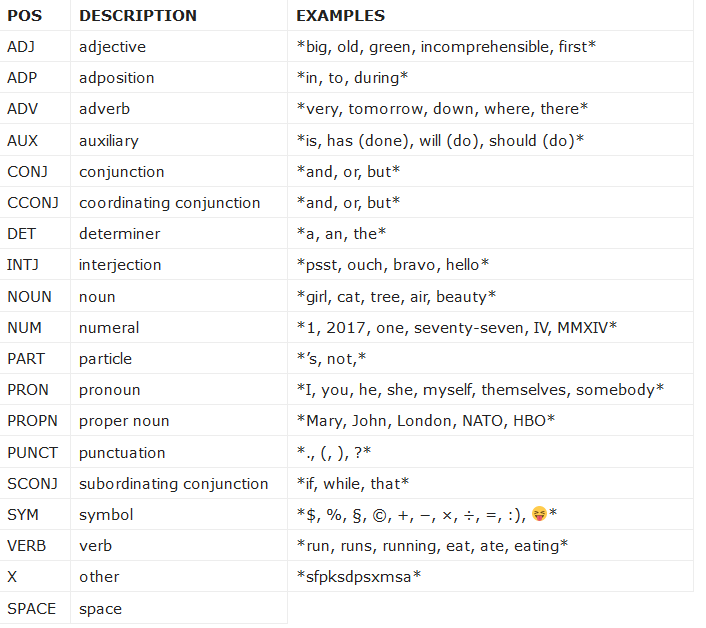
还是以上面的文本为例
# pos using spacy
import spacy
def pos_tagging_s(sen):
#print(sen.text)
#print(sen[1].pos_)
#print(sen[1].tag_)
#print(spacy.explain(sen[1].tag_))
for word in sen:
print("Word:", word.text, "\t","POS Tag:", word.pos_,"\t", "Tag for Word:", word.tag_,"Explanatation:", spacy.explain(word.tag_), "\n")
sp = spacy.load('en_core_web_sm')
sentence = sp("The prime minister has said he will formally invite Joe Biden to Northern lrelandto mark the 25th anniversary of the Good Friday Agreement.")
pos_tagging_s(sentence)
执行结果

任务三:Syntactic Parsing: constituency and dependency
这个过程通过分析语法,进行选取以及分析整段文字的依赖关系
还是以上面文字为例
#dependency parsing
import spacy
nlp = spacy.load("en_core_web_sm")
piano_text = "The prime minister has said he will formally invite Joe Biden to Northern lrelandto mark the 25th anniversary of the Good Friday Agreement."
piano_doc = nlp(piano_text)
for token in piano_doc:
print(f""" TOKEN: {token.text} ===== {token.tag_ = } {token.head.text = } {token.dep_ = }""")
在这个例子中有24种很多种关系,以部分为例。
The prime minister
这句话中的关键是minister,那么对于the和prime他们就是依赖于minister的
再以he will formally invite
这句话的关键是invite,那么对于he will formally这三个词语,都是依赖于invite的,那invite呢?翻译上面的句子,可以发现,invite其实是said的一个定语,因此是依赖于said的。
那么可以很明显的发现spacy的依赖关系分析是很强大并且有效的,可以帮助我们很快的分析出这段话中依赖关系,以便于之后机器理解语义。

任务四:Name Entity Recognition
进行一个简单的语义分析,其实就是把主谓宾定状补,转换成主谓宾,提取其中的主要信息进行分析。
piano_class_text = "The prime minister has said he will formally invite Joe Biden to Northern lrelandto mark the 25th anniversary of the Good Friday Agreement."
piano_class_doc = nlp(piano_class_text)
for ent in piano_class_doc.ents:
print(
f"""
{ent.text = }
{ent.start_char = } {ent.end_char = }
{ent.label_ = }
spacy.explain('{ent.label_}') = {spacy.explain(ent.label_)}"""
)
结果:
分别是
文字
文字开头位置结束位置
文字属于什么内容
文字的简单解释