文章目录
- 一、引言
- 二、Lazada电商平台选品实战
- 2.1、分析Lazada电商平台的商品列表接口
- 2.2、定位商品列表计算逻辑
- 2.3、封装高质量住宅IP
- 2.4、运行爬虫
- 三、数据处理及选品分析
- 四、Ownips——企业级全球静态住宅IP,高效采集公开数据
一、引言
互联网与外贸的结合,催生了蓬勃兴起的跨境电子商务。基于这种跨越国界的电子商务模式,企业不再受限于传统的地域销售,而是可以将产品推向全球市场,实现全球范围的发展。
然而,与传统的国内电商相比,国际市场消费者的需求、偏好、文化习惯等差异巨大,因此我们在选品方面也面临更为复杂的挑战。根据目标市场的需求和特点精选出适合销售的产品,直接影响一个商家的竞争力,而选品也不仅仅是销售产品,更是树立品牌形象和提升竞争力的重要手段。

对于许多初入跨境电商领域的新手而言,选品方法通常局限于国内市场的经验和视野,缺乏对全球市场的深入了解和把握,数据来源有限,难以抓住市场需求和竞争态势。本文将结合实际操作和理论分析,以Lazada电商平台为例,利用Python爬虫与Ownips(我常用的品牌)全球住宅IP,高效采集公开数据相结合的方式来进行选品,以全新的视角实战跨境电商选品,希望可以给新手商家们一些选品方法。
二、Lazada电商平台选品实战
2.1、分析Lazada电商平台的商品列表接口
熟悉电商的朋友肯定知道,一个平台的商品列表中包含了商品的名称、类别、价格、描述、评价、销售量等信息,这些信息可以帮助商家全面了解市场需求、价格竞争情况、产品特性和销售策略等方面。
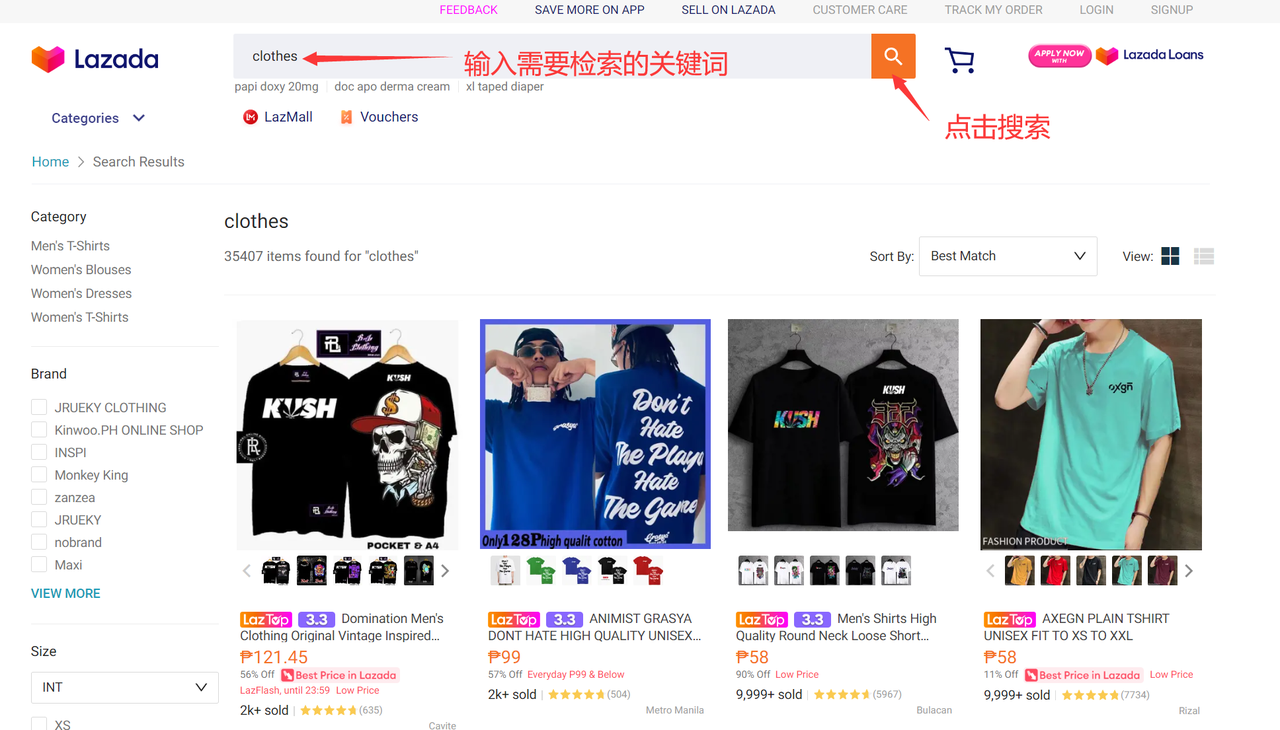
我们首先进入Lazada电商平台商品列表:https://www.lazada.com.ph/catalog,然后在搜索框中输入搜索的关键词,这里以“clothes”为例:
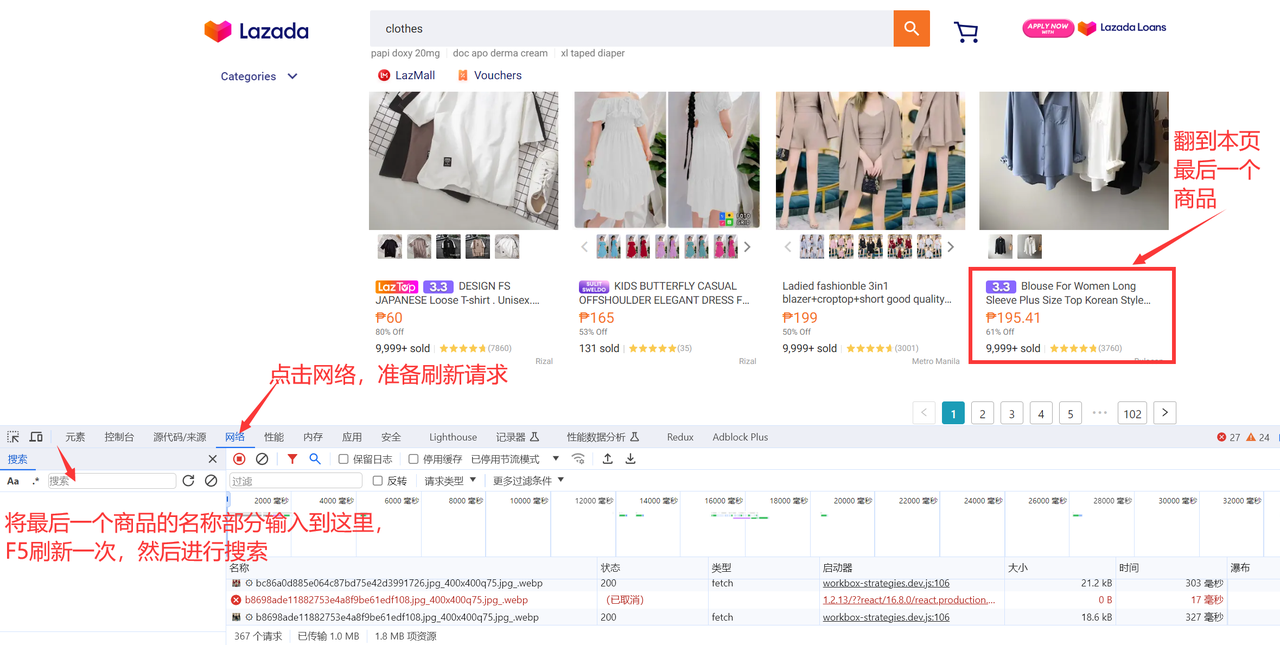
然后按下F12键,进入浏览器开发者模式界面,点击打开网络窗口和搜索窗口,按下F5刷新一次请求,搜索本页的最后一个商品的前几个词,就可以找到对应请求。
在右侧窗口中可以看到对应请求的标头、载荷和响应体:
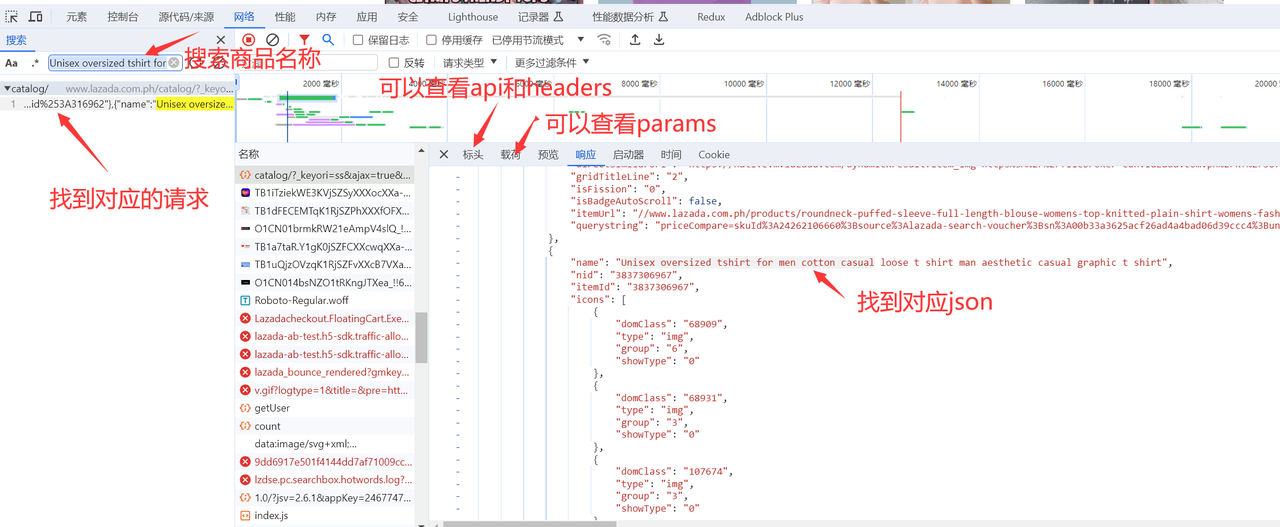
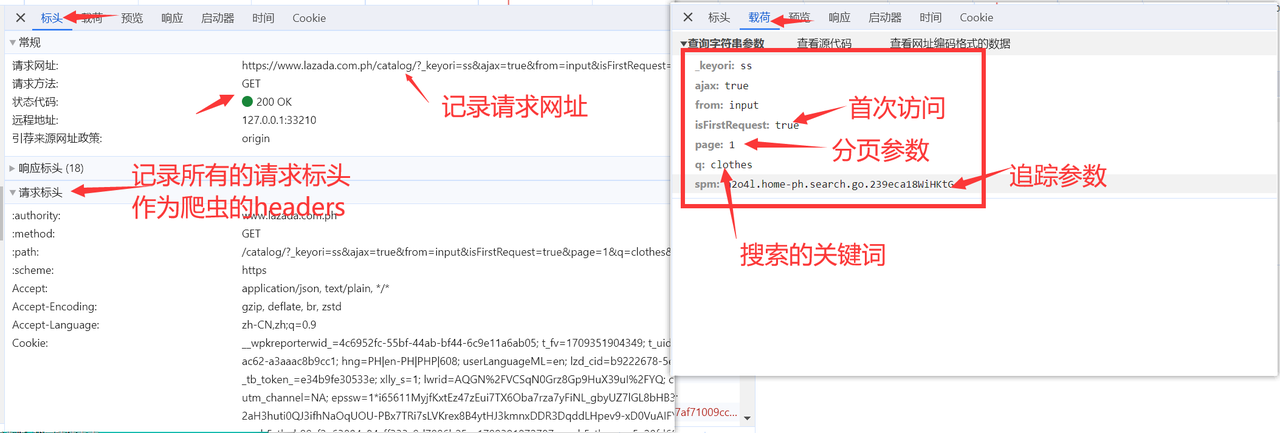
下面我们来分析这个请求,点开标头可以看到请求的网址,这里可以拿到商品搜索的api为:https://www.lazada.com.ph/catalog/,然后记录请求标头的全部内容,作为后续的headers;其次点开载荷,这里可以看到api的参数,其中比较重要的参数有:isFirstRequest表示是否为首次访问 ,page表示为当前页,q表示搜索的关键词,spm为追踪参数,平台用于追踪搜索记录。
2.2、定位商品列表计算逻辑
找到api接口并分析后,正式进入开发流程,首先我们需要对响应体进行分析,首先我们可以把这个响应体复制下来保存为json文件,然后搜索第一个商品的信息,找到商品所在的列表,然后可以搜索第二、第三个和最后一个商品,看其排序是否与列表中一致,若不一致还要重新计算排序逻辑。
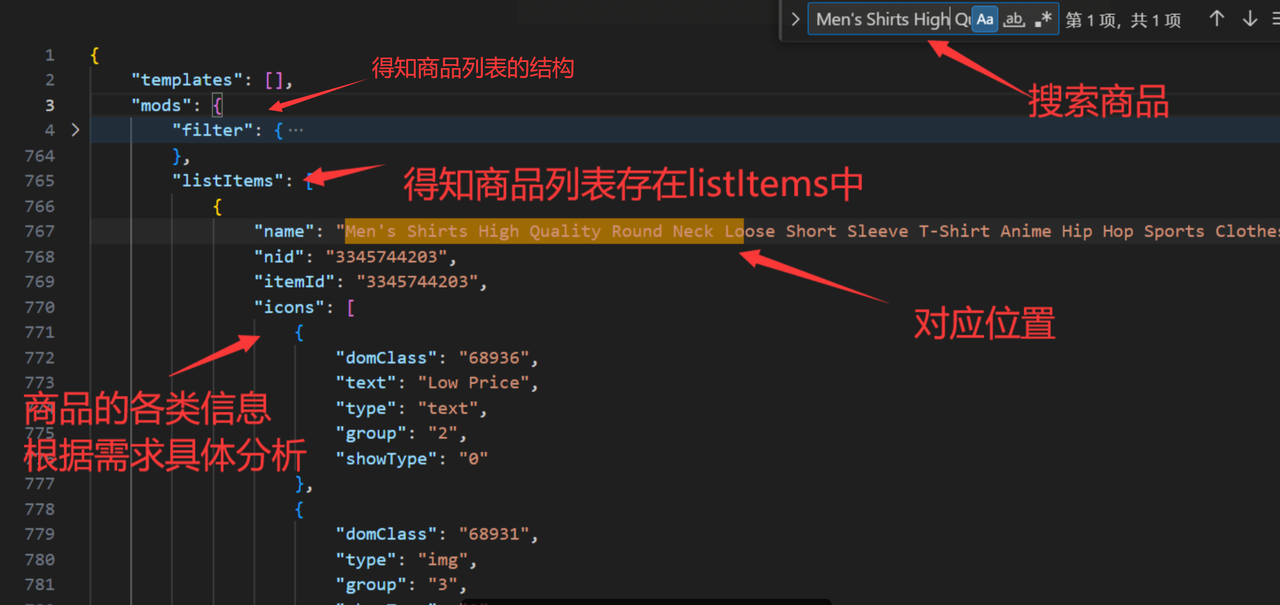
分析JSON可以得知,商品列表存在mods.listItems中,所以我们可以使用Python中的requests库发送HTTP GET请求到https://www.lazada.vn/catalog/,同时传递刚刚记录下来的参数params和请求头headers,得到response对象后,使用jsonpath模块的jsonpath函数来解析,这里可以使用JSONPath表达式'$.mods.listItems.*'来提取response中mods对象下的listItems数组的所有元素:
response = requests.get('https://www.lazada.vn/catalog/',params=params, headers=headers).json()
data = jsonpath.jsonpath(response, '$.mods.listItems.*')
print(data)
print(len(data))
得到商品列表信息后,可以打印出来看一下格式并且查到每一页的商品数量为40,这与我们在官网的商品搜索得到的数量一致,因此,我们可以通过控制分页参数page来一次性爬取多个商品的信息,比如爬取关键词为“clothes”的第1页到第3页全部商品:
for page in range (1, 4):
params = {
"_keyori": "ss",
"ajax": 'true',
"catalog_redirect_tag": 'true',
"from": "input",
"isFirstRequest": 'true',
"page": page,
"q": "clothes",
"spm":"a2o4l.home-ph.search.go.23*******tG"
}
response = requests.get('https://www.lazada.vn/catalog/',params=params, headers=headers).json()
data = jsonpath.jsonpath(response, '$.mods.listItems.*')
#print(data)
print(len(data))
至此,商品列表的基本计算逻辑已经理清。
2.3、封装高质量住宅IP
然而,Lazada一类的电商网站通常会监控和识别过于频繁的请求,如果检测到来自同一IP地址的大量请求,可能会认为其IP安全性低,无法高效采集公开数据。这里选择使用高质量住宅IP,高效采集公开数据。
这种方法不仅能够有效应对Lazada网站的机制,还可以模拟来自特定国家或地区的网络请求,从而高效管理资料,更深入地了解用户的行为和需求。
本次实战使用Ownips进行全球公开数据信息安全采集,首先登录官网,登录后根据使用的场景(跨境电商、跨境服务、社媒、论坛)和所需的地区来选择出高质量的ip,我这里选择 跨境平台–Lazada为例:
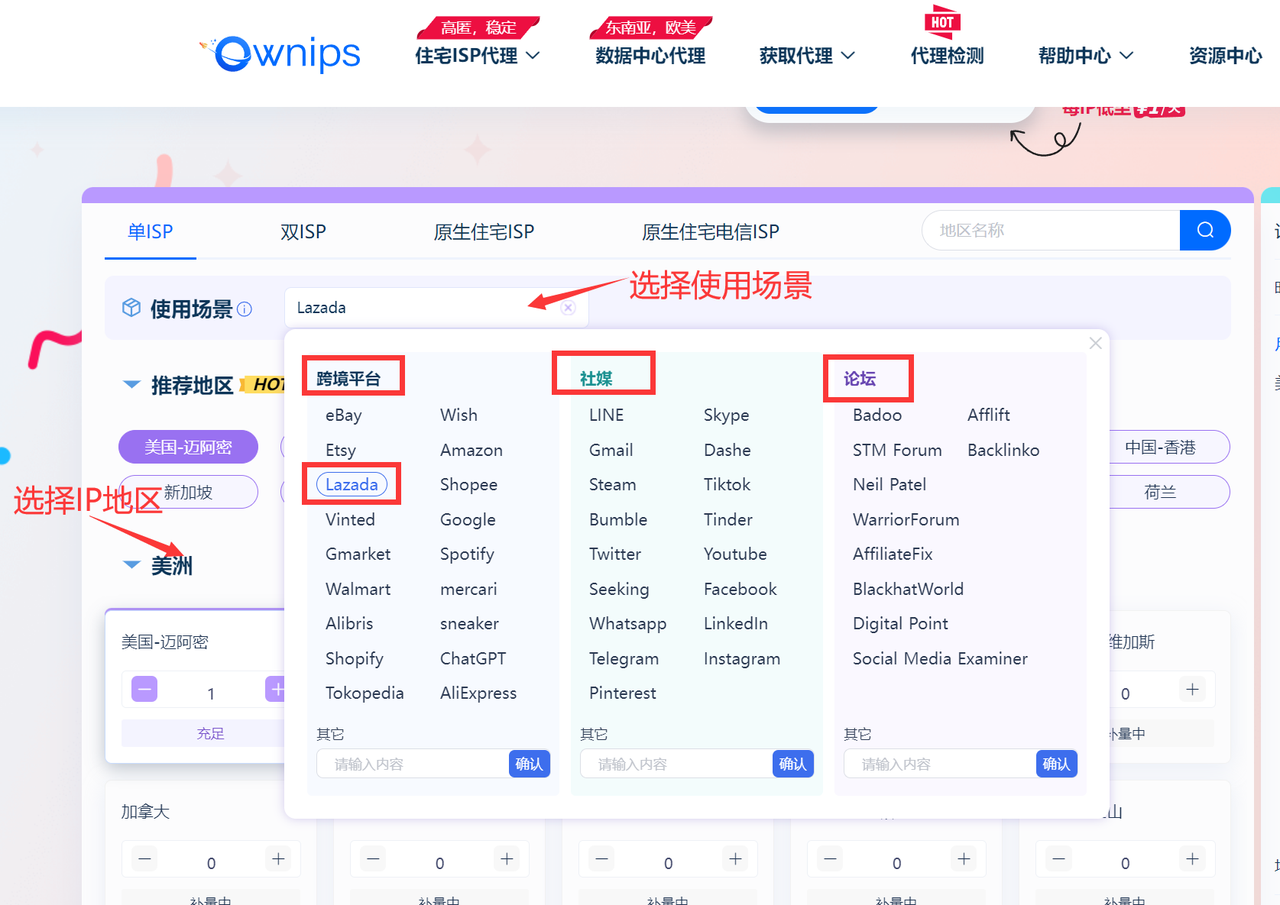
然后点击获取代理,选择API提取模式:

选择单ISP,然后选择代理协议为HTTP/HTTPS,提取格式可以就用TXT+回车换行形式:
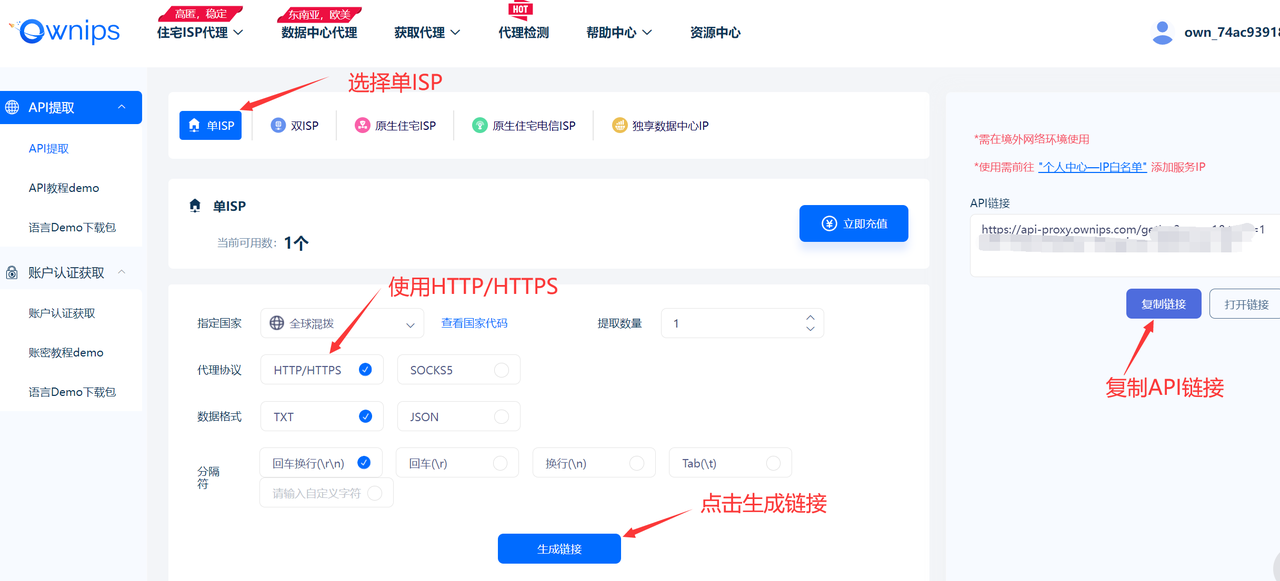
最后点击生成API链接并把本机的ip添加到白名单里,然后在将高质量和安全的企业级全球静态住宅IP封装进代码中,其主要逻辑如下:
def lazada(host, port):
###################
# 定义params、headers....
###################
proxies = {
'http': 'http://{}:{}'.format(host, port),
'https': 'http://{}:{}'.format(host, port),
}
response = requests.get('https://www.lazada.vn/catalog/',params=params,proxies = proxies, headers=headers).json()
if __name__ == '__main__':
api_url = "https://api-proxy.ownips.com/getIsp?num=1&type=2&lb=1&sb=0&flow=1®ions=&attribute=isp"
# 获取API接口返回
resp = requests.get(url=api_url, timeout=5).text
myip, myport = resp.split(":")
print("ip:" + myip + " port:" + myport)
lazada(myip, myport)
多线程:
class ThreadFactory(threading.Thread):
def __init__(self, host, port):
threading.Thread.__init__(self)
self.host = host
self.port = port
def run(self):
lazada(self.host, self.port)
if __name__ == '__main__':
api_url = "https://api-proxy.ownips.com/getIsp?num=1&type=2&lb=1&sb=0&flow=1®ions=&attribute=isp"
while 1 == 1:
# 每次提取10个,放入线程中
resp = rq.get(url=api_url, timeout=5)
try:
if resp.status_code == 200:
dataBean = json.loads(resp.text)
else:
print("获取失败")
time.sleep(1)
continue
except ValueError:
print("获取失败")
time.sleep(1)
continue
else:
# 解析json数组
print("code=", dataBean["code"])
code = dataBean["code"]
if code == 0:
threads = []
for proxy in dataBean["data"]:
threads.append(ThreadFactory(proxy["ip"], proxy["port"]))
for t in threads: # 开启线程
t.start()
time.sleep(0.01)
for t in threads: # 阻塞线程
t.join()
# break
time.sleep(1)
2.4、运行爬虫
在申请到全球住宅IP后,就可以正常进行高效管理资料数据了,首先从Ownips提供的链接获取IP和端口号,然后使用 requests.get 方法发送 HTTP GET 请求,获取到 Lazada 网站的响应,并将响应结果解析为 JSON 格式,然后使用 jsonpath.jsonpath 方法提取响应中的商品信息,并将其存储到变量 data 中。得到data后,遍历每次爬到的 data 中的每个商品信息,提取其中的商品名称、原始价格、销售价格、评分、评价数量、地点、卖家名称、卖家ID、品牌名称和品牌ID 等字段信息并使用 openpyxl 库将提取的商品信息写入到 Excel 文件中,并设置单元格的对齐方式为水平居中和垂直居中,最终保存到 result.xlsx 文件当中。
完整的源代码如下,部分敏感信息做了模糊化处理:
import requests, jsonpath, openpyxl
from openpyxl.styles import Alignment
import json
import time
def lazada(host, port):
wb = openpyxl.Workbook()
sheet = wb.active
header=['name','originalPriceShow','priceShow','ratingScore','review','location','sellerName','sellerId','brandName','brandId']
sheet.append(header)
headers = {
"authority": "www.lazada.com.ph",
"method": "GET",
"path": "/tag/%E5%A5%B3%E8%A3%85/?_keyori=ss&ajax=true&catalog_redirect_tag=true&from=input&isFirstRequest=true&page=1&q=%E5%A5%B3%E8%A3%85&spm=a2o4l.home-ph.search.go.******hBy",
"scheme": "https",
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "__wp***********************************************************AJjnU",
"Referer": "https://www.lazada.com.ph/",
"Sec-Ch-Ua": ""Not A(Brand";v="99", "Google Chrome";v="121", "Chromium";v="121"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": ""Windows"",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
"X-Csrf-Token": "e**********",
"X-Requested-With": "XMLHttpRequest"
}
proxies = {
'http': 'http://{}:{}'.format(host, port),
'https': 'http://{}:{}'.format(host, port),
}
for page in range (1, 20):
params = {
"_keyori": "ss",
"ajax": 'true',
"catalog_redirect_tag": 'true',
"from": "input",
"isFirstRequest": 'true',
"page": page,
"q": "clothes",
"spm":"a2o4l.home-ph.search.go.***********G"
}
response = requests.get('https://www.lazada.vn/catalog/',params=params,proxies = proxies, headers=headers).json()
data = jsonpath.jsonpath(response, '$.mods.listItems.*')
print(len(data))
for item in data:
name = jsonpath.jsonpath(item,'$.name')[0]
originalPriceShow = jsonpath.jsonpath(item,'$.originalPriceShow')[0]
priceShow = jsonpath.jsonpath(item,'$.priceShow')[0]
ratingScore = jsonpath.jsonpath(item,'$.ratingScore')[0]
review = jsonpath.jsonpath(item,'$.review')[0]
location = jsonpath.jsonpath(item,'$.location')[0]
sellerName = jsonpath.jsonpath(item,'$.sellerName')[0]
sellerId = jsonpath.jsonpath(item,'$.sellerId')[0]
brandName = jsonpath.jsonpath(item,'$.brandName')[0]
brandId = jsonpath.jsonpath(item,'$.brandId')[0]
sheet.append([name,originalPriceShow,priceShow,ratingScore,review,location,sellerName,sellerId,brandName,brandId])
max_rows = sheet.max_row
max_columns = sheet.max_column
align = Alignment(horizontal = 'center', vertical = 'center')
for i in range(1, max_rows + 1):
for j in range(1, max_columns + 1):
sheet.cell(i, j).alignment = align
wb.save('result.xlsx')
time.sleep(10)
print("end")
if __name__ == '__main__':
api_url = "https://api-proxy.ownips.com/getIsp?num=1&type=2&lb=1&sb=0&flow=1®ions=&attribute=isp"
resp = requests.get(url=api_url, timeout=5).text
myip, myport = resp.split(":")
print("ip:" + myip + " port:" + myport)
lazada(myip, myport)
运行完成后,最终得到的result.xlsx数据文件如下图所示:
三、数据处理及选品分析
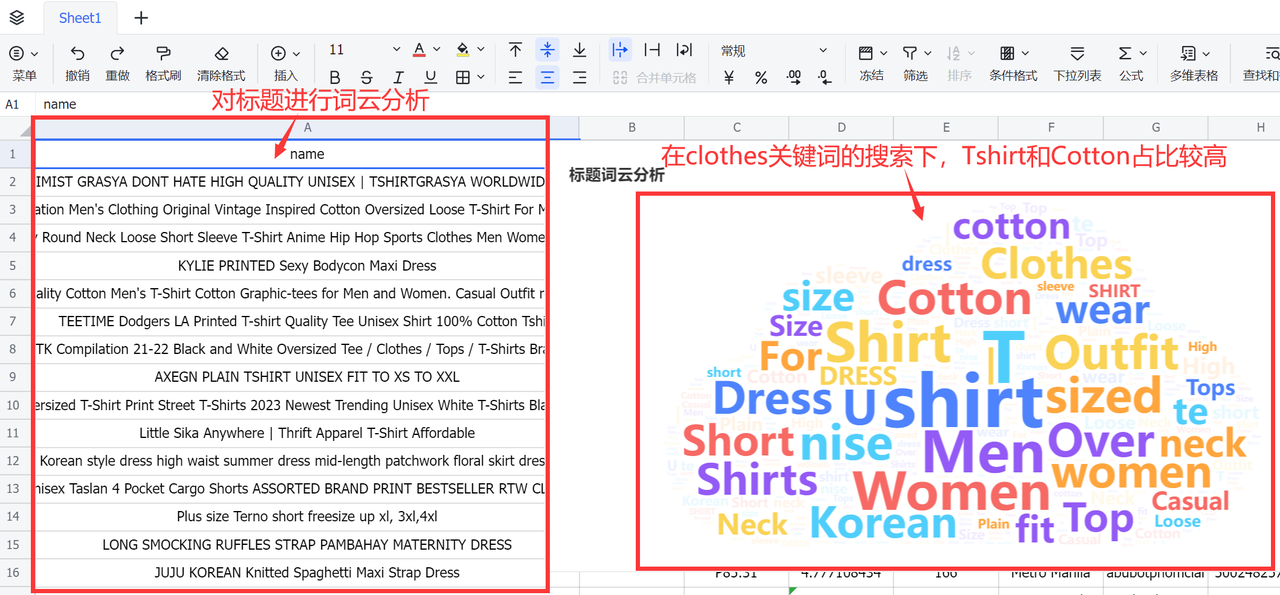
拿到数据后,就可以对第二章采集到的数据开始分析选品了,首先对平台商品的标题高频词进行词云分析,可以发现在clothes作为关键词搜索下,商品标题的Tshirt和Cotton占比较高
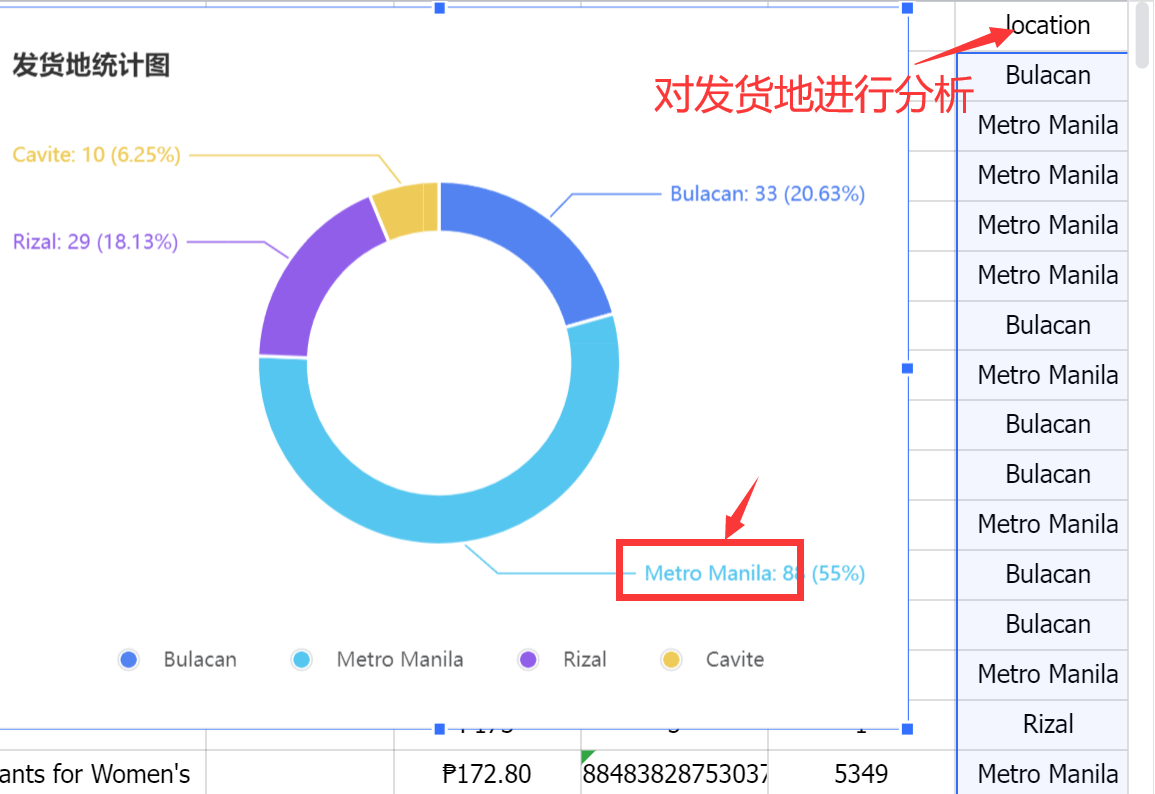
其次可以对发货地进行分析,通过统计出现频率,发现当前ip爬到的商品大部分发货地来自于Metro Manila这个地点,占比55%:
还可以从评分、销量、价格等方面多维分析,通过使用柱状图、折线图、扇形图对数据可视化:
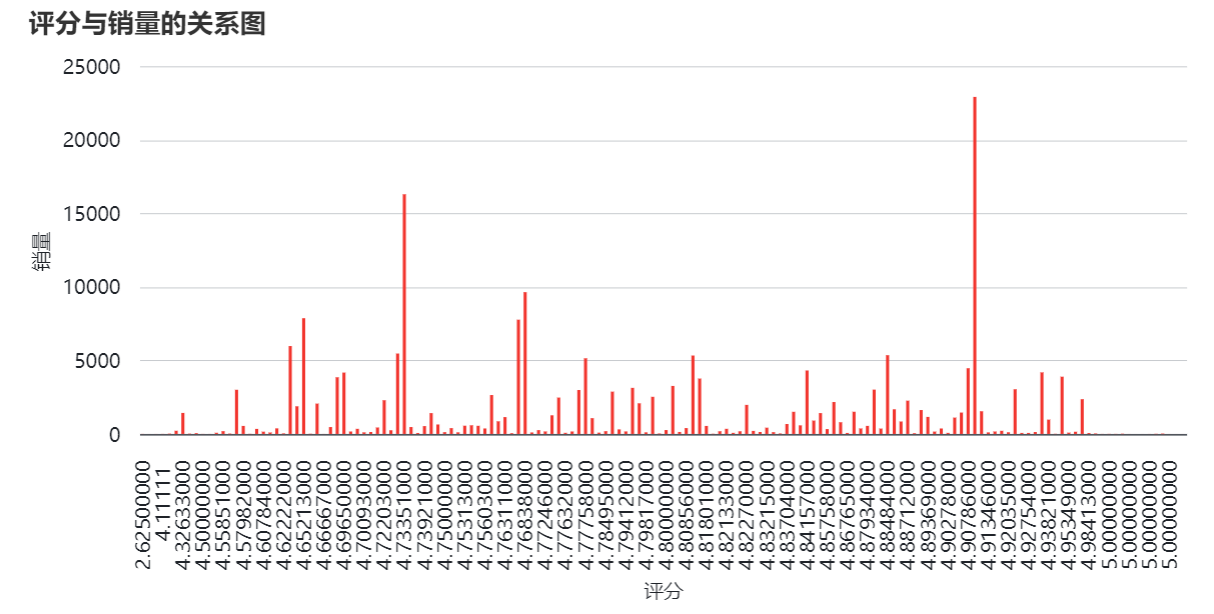
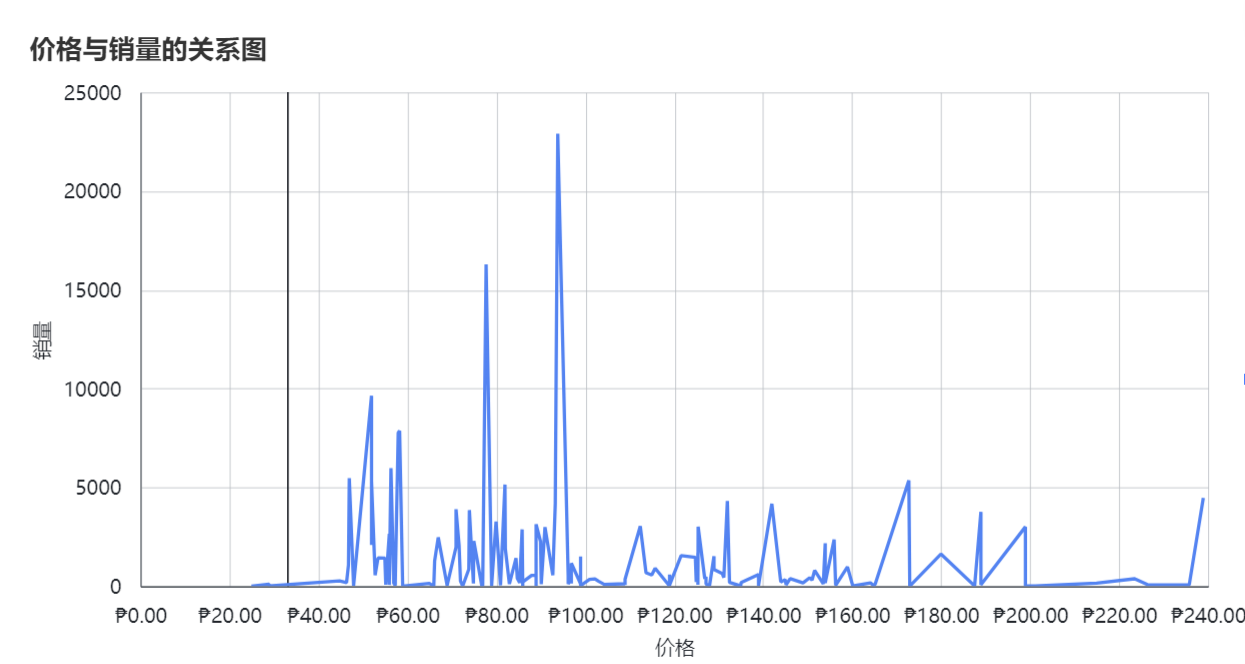
以下是可参考的选品分析方法,具体分析需要结合需求和市场去制定策略:
- 对商品的原始价格和销售价格进行统计和比较,探索商品的价格变化趋势,找出价格竞争力较强的商品。
- 对商品的评价数量和评分进行统计,分析商品的受欢迎程度和用户满意度,按照不同品牌、类别或卖家对评价和评分进行对比,找出高口碑的商品。
- 可以根据IP的地理位置信息了解不同地区的商品偏好和销售情况,进行地域性营销策略的制定。
- 对商品的品牌进行统计,了解不同品牌的市场份额和影响力,为品牌营销提供参考。
- 根据商品的排序与特征(如品牌、价格、评分等)之间的关系进行商品推荐和相似商品挖掘,根据商品的上架时间和销售情况,分析市场的发展趋势和产品生命周期。通过对商品特征的分析,预测未来市场的发展方向和趋势
四、Ownips——企业级全球静态住宅IP,高效采集公开数据
针对跨境电商领域的多样化业务需求,许多出海企业正在积极寻找可靠的解决方案来克服挑战。全球住宅IP,高效采集公开数据作为一项关键技术工具,不仅能够帮助这些企业解决访问稳定性、网站信任度以及防封禁能力等问题,还在跨境电商、跨境社媒和广告营销等领域发挥着重要作用。

这里推荐一款我经常使用的企业级全球住宅IP,高效采集公开数据服务:Ownips。Ownips优选原生本土ISP,定向提供独享静态家庭住宅和独享数据中心安全采集公开数据信息,具备以下优势:
- A++级严选原生ISP服务:Ownips专注于提供A++级严选原生ISP服务,其与全球运营商合作,资源覆盖欧美主流、东南亚等全球100+国家地区,其中,独享静态ISP来自真实住宅设备的原生私人IP,具备更高业务安全性,稳定运行不掉线,专用数据中心来自全球国家的本地原生机房和个人专用的服务器IP,具有更高稳定性和更快的连接速度。
- 完整的合作伙伴生态链:Ownips具备丰富行业经验的技术+商务团队,能够整合软件集成、跨境工具等生态资源,完美适用于各种业务场景。
- 第三方工具集成:Ownips支持与大多数指纹浏览器进行快捷集成,用户可以直接将Ownips提供的服务与指纹浏览器进行无缝连接,防止账号之间的关联,保护隐私和安全。
在经过了较长时间的体验后,可以说Ownips可以满足跨境电商在店铺管理、社媒营销、市场调查等各方面业务场景:
- 在店铺管理方面,通过使用静态全球住宅IP,高效采集公开数据可在电商平台创建并管理多个店铺账号,独立安全防止账号关联,降低账号风险。
- 在社媒营销方面,商家可以运营多个社媒平台账号,搭建引流矩阵,广告精准投放并全面覆盖消费者人群,提高广告的点击率和转化率。
- 在市场调查方面,使用全球住宅IP,高效采集公开数据了解不同国家地区用户的喜好和购买习惯,掌握海外市场分布状况,行业发展前景预测,维持竞争力。