消息的可靠性
前言
IM系统的可靠性指的是端到端的可靠性,并不是tcp的可靠性,它是指客户端A,客户端B以及服务端三端通信之间的可靠性,并不是客户端A到服务端这么一个上行消息的可靠,这个tcp就可以保证了,当然说tcp只是保证在传输层到网络层的一个可靠,进入了webserver容器,也有可能丢失,业务如果没有处理清楚,panic了,消息也有可能丢失,所以本质上来说,tcp并不是端到端的可靠,这里强调的可靠是三端可靠,上行消息可靠,下行消息可靠。当然消息可靠有他自己的一个技术约束,不重、不漏、有序、及时,也就是客户端A到客户端B的消息不能重复、不能遗漏,客户端B感知消息的顺序应该和客户端A发送消息的顺序保持一致,然后发送的速度要及时。
技术约束
- 从服务端的视角来看,我们的系统,第一高可靠,至少要5个9以上的消息可靠,因为收发消息对于im来说是核心链路,所以可靠性要求非常高
- 其次就是及时性,因为用户对消息发出去的及时性非常的敏感,所以要求低延迟
- 然后就是高吞吐,对于极端的群聊场景,比如万人群聊这种,在特点活跃时间内,每发一条消息都是一次ddos攻击
技术方案
消息的可靠分为上行消息可靠和下行消息可靠,所以把这个问题缩小,先看客户端A到服务端的上行消息可靠
- 首先是消息不漏,消息在发送的时候可能会丢失,丢失的原因可能会有很多,客户端A发送消息时可能要经过层层的中间组件,其中某个组件panic了,然后就导致消息丢失没发出去,或者消息发出去了,到某个路由器,路由器挂掉了,导致消息丢失,到了服务之后,服务的网关层panic了,这样消息也丢失了,会有很多种可能性,导致消息没到达服务端。
传统的解决方案ack和消息重试,启动一个消息的定时器,在100ms之内还没有收到ack,就重发一条,一直重发一直重发,直到服务端回复个客户端A,就把这个定时器关闭掉,这样就可以做到消息的不漏,消息一定会到达服务端。但是这样的话就会引出一个问题,如果重复发送消息的话,由于网络之间的抖动,无法区分消息丢失和延迟之间的差别,也就是说,消息有可能是真的丢了,那这时候重发是没问题的,但是这个消息有可能是延迟的,定时器超时重传又发送一条,这样相同的消息就会有两个,延迟过去之后,两条消息都到达了服务端,那么就会出现重复的现象 - 解决重复,我们给每一个message分配一个ID,这个ID由客户端分配,从0开始一直不断自增,这样就有了一个顺序,根据这个id去判断消息是否已经存储了。
- 有序的话这个messageID是一个可排序的字段,从而保证消息的顺序
最大的问题在于消息的量级会很大,不满足我们的上面的约束高可用、高吞吐和低延迟和低成本,不能因为存储messageID来消耗过大的内存,影响可用性,服务崩溃重启可能需要很长的时间来恢复。
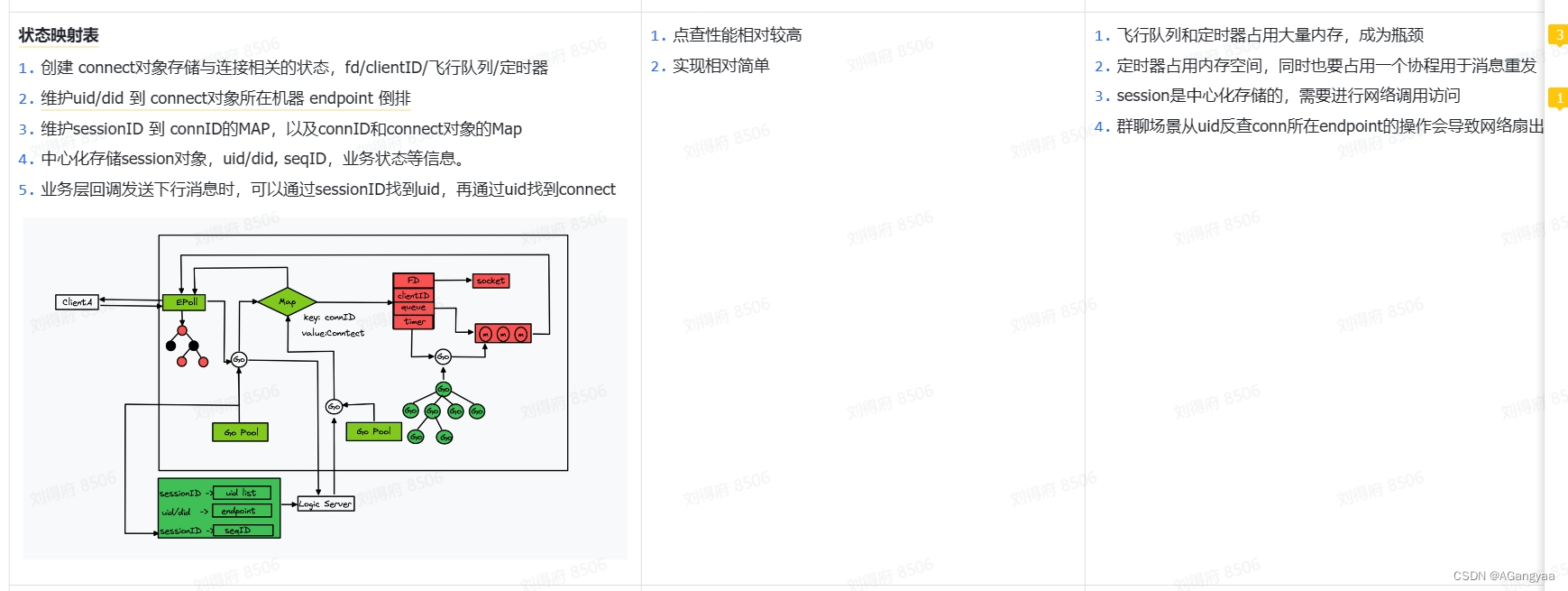
解决的办法呢首先就是tcp协议里面有个解决方案,在服务端和客户端都维护了一个list飞行消息的队列,这个消息发送出去,就存在飞行队列中,一旦ack才把这个飞行队列里的消息给删掉,服务端也是,但是对于百万长链接,可能就很耗内存。
所以退而求其次,就只保留一个消息ID就是clientID,clientID不需要全局有序,只需要客户端维护的每个会话是从零开始不断递增的,每一次发消息+1,然后每一次持久化,这样的话服务端每一次都维护一个maxID,当消息过来之后,它只会接受maxClientID+1,否则就会忽略,因为首先是在tcp上传输的,tcp已经保证了在传输层的有序性,所以在到达业务层的时候这个乱序的可能就很低了,所以这种其实不会造成大量的重试,当然也会有。所以这个TCP有序和业务上的有序其实是两个概念,要在业务层实现自己的消息有序性。
当消息存储到redis中,就会立刻push给客户端b,push的逻辑其实也需要有一个消息ID,但这个是服务端生成的,这就有讲究了,服务端是不能重启的,可能客户端只需要维护一个sessionID就可以了,服务端要维护上十亿个,所以对于服务端来说要维护的话就不能叫clientID了,应该叫messageID了,是会话维度的,不需要全局唯一,只需要sessionID+messageID能够具有唯一性就可以了,这样的话设计会简单一些,messageID假如是单调递增的,其实是有非常大的难度,客户端B只会接受max_id+1,否则忽略,接受了则回复ACK。
链接的可靠性
连接可靠性,让长链接持有的更久
系统现状
client和gateway建立连接之后,他们之间会收发消息,但这个通道和我们平常所说的tcp连接有些区别,平常我们都是在一个数据中心中的tcp,很容易建立连接,而且并不容易断开,因为经过的路由器会比较少,而且网络环境也比较稳定,但是对于im系统这种长链接服务来说,他是需要跨越公网的,这里面就会有非常多的路由节点,要跨公网建立长链接,每一个路由节点的每一个服务策略都是不同的,会造成非常多的不确定性,那我们的连接可靠性就是要消除这么一个不确定性,可靠性难做的一个原因就是数据规模大,在大数据的情况下,不可靠的事件都有可能发生。如果在持有百万连接的这种情况,那么可能会因为各种原因断开连接,造成这样连接的一个不可靠。
不可靠的原因,技术挑战
- 最常见的场景就是,公网环境下,肯定要经过运营商网络,运营商网络自己有一个为了减少服务路由的这么一个成本,因为要维护tcp路由表,表本身是占用一定的计算机资源的,即使字节数占用的很小,但也是占用一定的资源,为了减少机器的成本,就会周期性的扫描路由表,会把一段时间内没有收发消息的tcp连接清理掉,这个策略对运营商来说是非常好的,这样能有效的控制成本,不会导致黑客攻击导致占用大量的资源,整个网络陷入瘫痪,但是这样的话就会对im长链接服务造成一定的问题,运营商作为一个中间状态,在连接断开时都会发送一些final信号。所以在看客户端日志和服务端日志的,客户端会觉得是服务端断开了连接,服务端又会觉得是客户端断开了连接,感觉都是对端断开的,这种情况往往是由于服务的中间节点断开了连接,
- 其次还有数据中心都是有网关的,有l4或者l7网关,通常有两层,l4网关就是lvs,l7网关就是ngix,l就是层,l4就代表工作在四层osi的网络模型第四层的路由,不知道上游的应用层的信息,知道的是tcp、IP这些信息,根据这些信息去路由给下一层,通常会路由给l7层去代理,会做这么一个应用层的http转发,就是那url去做个转发,到真正的业务server,这种网关一般也会有一个tcp连接持有的最大时长,超过这个时长也会断开,所以要做长链接服务,要把这个也打通,
- 然后除了上面这种场景,还有一些场景比如移动互联网场景,客户端往往处于一种网络不确定性的一种状态,比如可能在可能在室内连wifi,移动到户外的时候就连接了手机的基站,这个时候长链接是必然会断开的,因为ip发生了切换。或者客户端可能会在一种高速移动的场景,在这种情况可能会出现移出漫游区域,从这个运营商基站,移动到另一个运营商基站,这种会导致ip地址的重新分配。当然有些运营商做了一些保证,虽然漫游区域发生了切换,但这个时候可能会让ip地址不发生切换,这样也就不会造成tcp长链接的断开,但如果运营商做这样的保证,连接就会断开。
- 除了这种强制的断开连接的场景,还有一些弱网的场景,就是网络状态不是很好,在地铁或者隧道当中,消息可能会传不过来,有丢包的现象,在这种弱网环境下,连接也有可能会断开,一旦连接断开,可能会非常影响用户体验,轻一点可能发消息就在那转圈,因为要重连连接,消息发不出去,重则由于连接断开,重连的时候可能会发生一些数据状态的改变,造成消息的错乱,vx好像也没完全解决这种问题,但是vx做的最好嘛,在隧道或者弱网环境体验会比较好些。
总结
- 中间代理资源的回收,这是导致连接断开的连断开
- 然后就是底层ip的切换
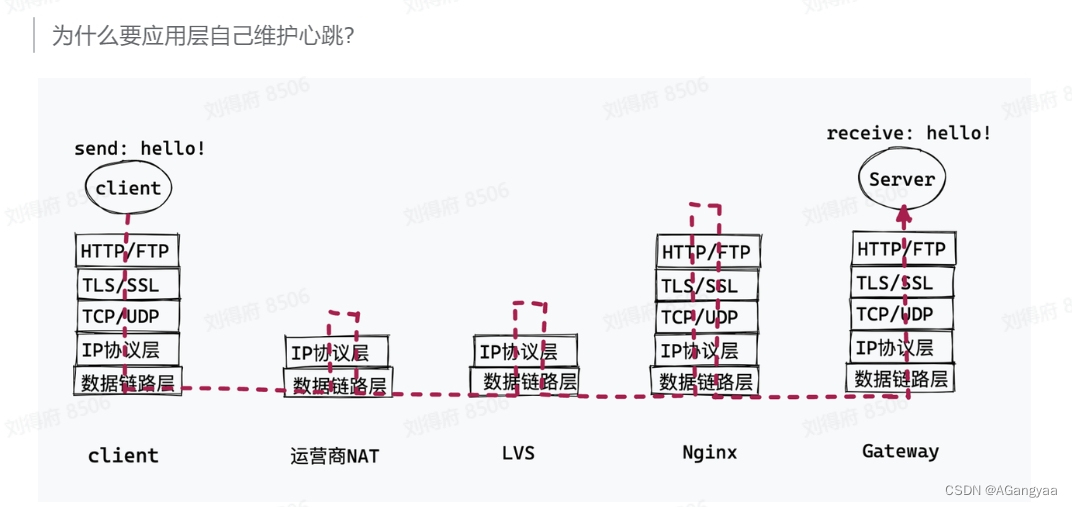
针对第一种原因,采用的方案也是im业务,无论是互联网的公司还是一些基础的开源的中间件,比如爱奇艺、喜马拉雅、知乎、vx或者像dubbo、zookeeper都会用的一种,就是心跳,心跳对于服务端来说是一种很常见的技术,也被用于很多场景,他的一个核心目标就是保活,就是告诉业务方,服务还一直存在着,因为网络是一种不受信的状态,除了通过这种心跳的方式,我们没有办法来获取一些信息知道服务还活着,只能通过心跳保活的这么一种方式。客户端会定时的给服务端发送消息,告诉服务端自己还活着,在这个过程中,就会刷新各个代理的一个超时时间,知道这个连接还是活着的,不能kill掉,会影响用户的一个体验,通常就是在链路上发送一个空的消息来防止资源的回收。但是有个前提就是,消息收发的周期要小于整个链路最小回收连接资源的周期。tcp连接作为一个传输层协议,就有一个长链接,可以开启一个长链接的选项,开启了底层就会发送一个心跳来保证长连接的状态,但是他的一个时间是两小时,但不同的运营商他的回收策略都是不一样的,中
国的话通常是5分钟,自己的网关可以自己设置,所以通常就是去服务商不可靠的这么一个最小值作为心跳的一次周期,
然后呢现在的问题就是由谁去发这个心跳,如果是服务端定期的遍历所有的socket去发,显然不可取,就比如有百万长连接,那每五分钟去遍历所有的socket,那就是一个巨大的带宽消耗,所以只能是由客户端来发消息,服务端创建一个定时器,客户端如果在规定的时间内没有发送,就把这个连接删除掉,回收资源,这就是心跳的一个设计
然后第二种原因,就是ip地址的更新,因为ip地址的切换会导致连接的断开,这种是没办法的,因为传输层技术上的一个约束。所以这个时候考虑的就不是长链接不断,因为做技术的设计,有时候要弱化嘛,退而求其次,做这种trade-off的折中设计,在这种情况下,去追求连接断开后,用户无感知的设计,那就是重试,不是说连接断开了,客户端就一定要告诉用户说连接断开了,因为用户有个反应时间,但计算机的反应时间很快,后台可以在一定时间内进行重试,直到把连接建立成功,这个时候用户在收发消息的时候,会觉得连接没有断开,但是底层已经把连接换了一个了,我们保证让这个连接断开之后,一段时间内能够快速的重连,来保证用户无感知,这是解决ip地址变更的一个办法。
然后呢,我们又根据技术上的一些约束条件以及一些资源情况做了一些优化,面试官我还要继续讲吗?
约束条件
- 资源成本,做这个连接的可靠性,要尽可能的减少服务器资源的消耗,这是接入层的一个重要目标,因为长链接要维护一个极速变化的一个服务,它不仅仅是一个有状态的server,同时对于长链接网络来说,它的变化是非常快的,基本上不可能持久化,对我们的可靠性造成一个工程性的挑战,所以为了解决这个问题,我们应该尽可能的节约一个资源成本,因为这些资源成本也就是状态,如果能维护的状态越少,就是越有利的
- 对于这个连接层最重要的就是可靠,任何各种极端情况下,都应该去快速恢复连接的一个,这是连接层非常重要的一点。
- 其次就是低延迟,不能因为维持可靠性就增加了延迟,因为毕竟是一个基础服务,基础服务延迟如果高的化,那业务就没法运作了
这是三个主要的技术约束
技术方案
- 编解码器,想要实现一个连接,就要在我们设置协议的基础上,设置一些信令,连接建立之后需要维护一些状态,比如我们就需要登录这样的一个状态,会传输一个数据包,这个数据包就告诉服务端它要登录了,这些数据包里会携带一些信息,最重要的就是设备ID,然后我们会根据这个设备id的处理逻辑生成接下来要进行消息收发访问的一些基本状态,这个就是登录的意思,当然登录指的不是账号的登录,而是连接的登录。登录好之后,然后这个心跳定时器启动,然后客户端在一定时间内频繁的发送心跳来保证连接的活跃,
- 时间轮,优化成本,成本的一个巨大开销就是定时器,因为定时器,是和长链接的是保持在一个水平扩展的状态,就是有多少长链接就要有多少心跳定时器,作为一个im,比如春节或者地铁上下班的时候,可能有个潮汐现象,大家都在这个时候登录,大量的建立连接,就会大量的创建定时器,会导致可能有很多定时器可能就在同一时刻开始定时,那这个时候,一旦定时器超时,就会产生绝大部分定时间超时,会出现调度潮汐,协程的调度可能就会出现问题,cpu的利用率会直接被拉满,同时定时器的存储也会占用极大的内存资源,那这个时候计算资源和内存资源都成为了瓶颈,golang本身想要提供一个高精度的定时器,他内部是四叉堆的实现,四叉堆的精度很好,但是会非常占用内存,同时插入和删除插入一个定时器的复杂度是logn,所以如果存在一些潮汐现象产生大量定时器都要插入这个四叉堆中,就会导致这个性能极度的损耗,为了解决这个问题,就要找到一个代替原生golang的定时器算法,因为其实并不需要高精度的定时器,这并不是一个强的技术约束,因为我们的心跳场景,迟一会或早一会都不会有什么影响,心跳的目的就是为了资源回收,不会对用户产生什么感知,所以这种场景比较适合用低精度的一个定时器,低精度的定时器可以有一个更好的时间复杂度,也就是时间轮,可以做到o1的时间复杂度,同时存储成本也会降低,优化了我们的一个性能,当然是以精度为代价的,kafka就实现了一个时间轮,很多好像和心跳相关的都基于时间轮
- 对于保证连接可靠性的时候,登录的时候要创建一个心跳定时器,然后从登录的信令中解析出一个设备ID,然后把channelID,channelID是等价于fd的,fd是存在一个bug的,fd是一个进程级别的,但是一旦跨进程传递给了stateserver,那么这个fd就不能唯一的表示这个链接了,我们是endpoint+fd,但是fd是会被复用,如果有延迟,可能会导致传到被复用的fd上,这样就把消息传递给了新的连接,可能会出现忽然有个莫名的人给你发了一条信息,造成这种消息的错乱,所以要有一个channelID的概念,这个通道表示就是一个链接,它是不可复用的,之前因为有复用的原因,所以会有消息错乱的问题,所以规定了channelID是一个int64的值是不断递增的,永远不会出现复用的问题,因为不需要维护全局的,维护一个进程级别的就可以,因为有endpoint做一个前缀,是个唯一的key,能够通过did找到endpoint和channelID找到这个链接在哪里,有这样一个路由信息
- 心跳的时候,当服务端接受到心跳消息的时候,会通过之前在登录的时候,映射的这个endpoint+channelID作为key,找到一个定时器对象,然后把这个定时器的任务重试一下,就是把这个定时器删除然后重新注册一个
- 重连的时候,我们面对的是一个ip的快速变更,所以也就是需要快速重连。也就是链接建立的状态,相对来说就是一个很重的操作,如果可以复用这个状态,那就可以做到一个快速重连的效果。比如说,这个长链接崩溃断开了,服务端感知到了,epoll中可以快速返回一个error事件,拿到这个事件后调用回调函数,直接通知给state server,让她把所有的状态、定时器、路由的key,等待一些状态全部清理掉,做链接的回收。但是我们的快速重连可以让链接断开之后,我们不会立刻回收所有的状态,而是进入一个延迟任务,这个延迟任务会执行一段时间,只要延迟任务到期之后,才会真正的把所有状态回收,也是启动一个定时器,交给时间轮,在一些极端的情况下,压力会非常大。在IP地址的变更场景,我这里是假设客户端断开连接之后是可重试的,相信这个客户端可以在10s之内快速的建立连接,然后再连接给这台机器,再连接给这台机器的时候,连接一旦创建成功,这个连接里就必须携带上次连接的channelID,所以channelID要随着ack或者心跳的方式把这个channelID返回给客户端,客户端在重连的时候告诉服务端老的channelID是什么,在重连信令中拿到老的channelID,就可以找到老的一些状态,就可以把这个channelID一替换,替换成新的channelID,相当于只换了一个底层的socket,而业务上的状态全都没有换,就实现了链接的复用,那也就不需要创建定时器,告知业务层感知,然后业务层做一些数据的处理、日志的打印或者什么一大堆的操作不需要做了,所以速度就会很快,这个就是快速重连,也就是就是资源的复用和链接的复用
客户端如何选择网关IP地址ip config
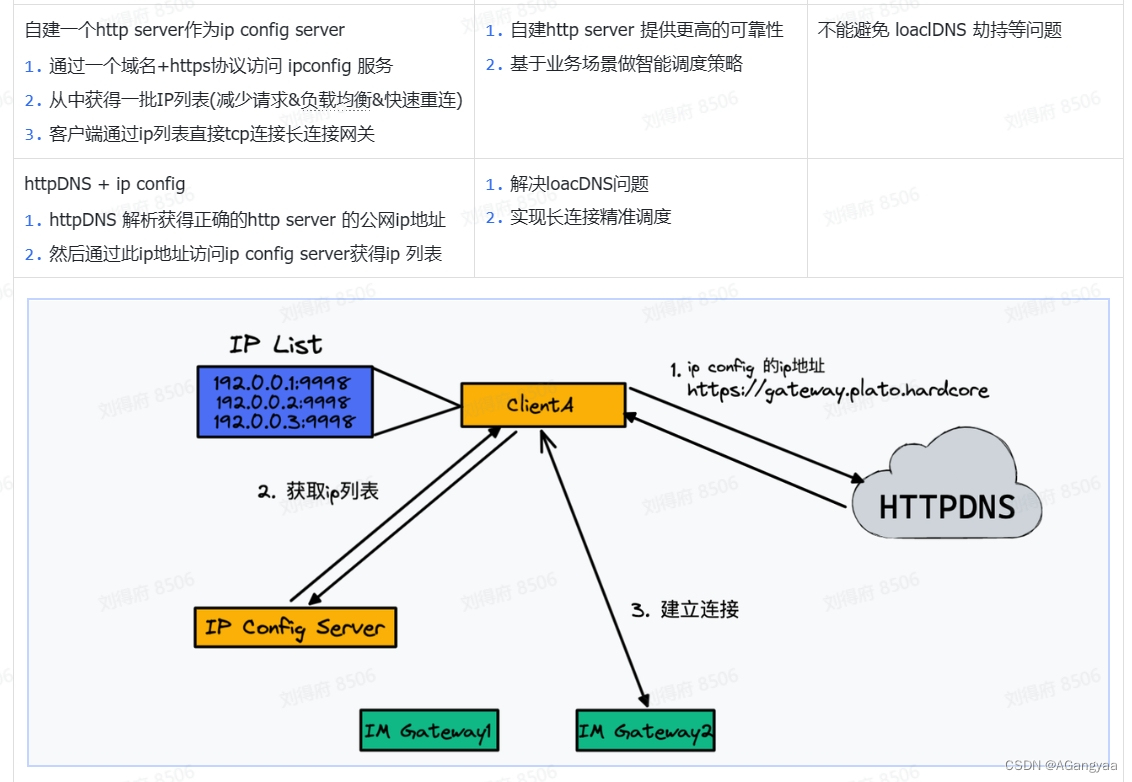




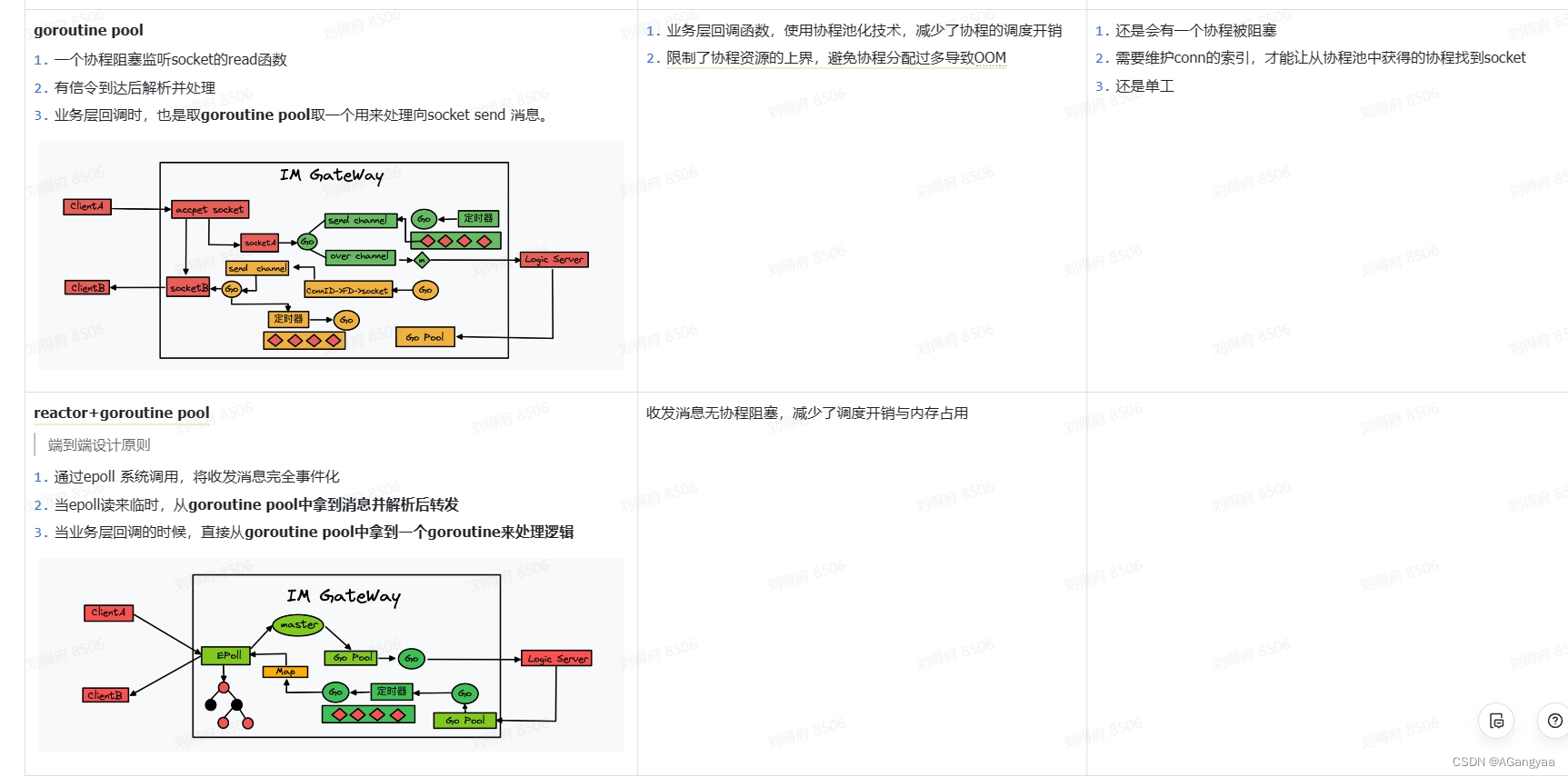
如何设计并发通信模型来收发长链接消息
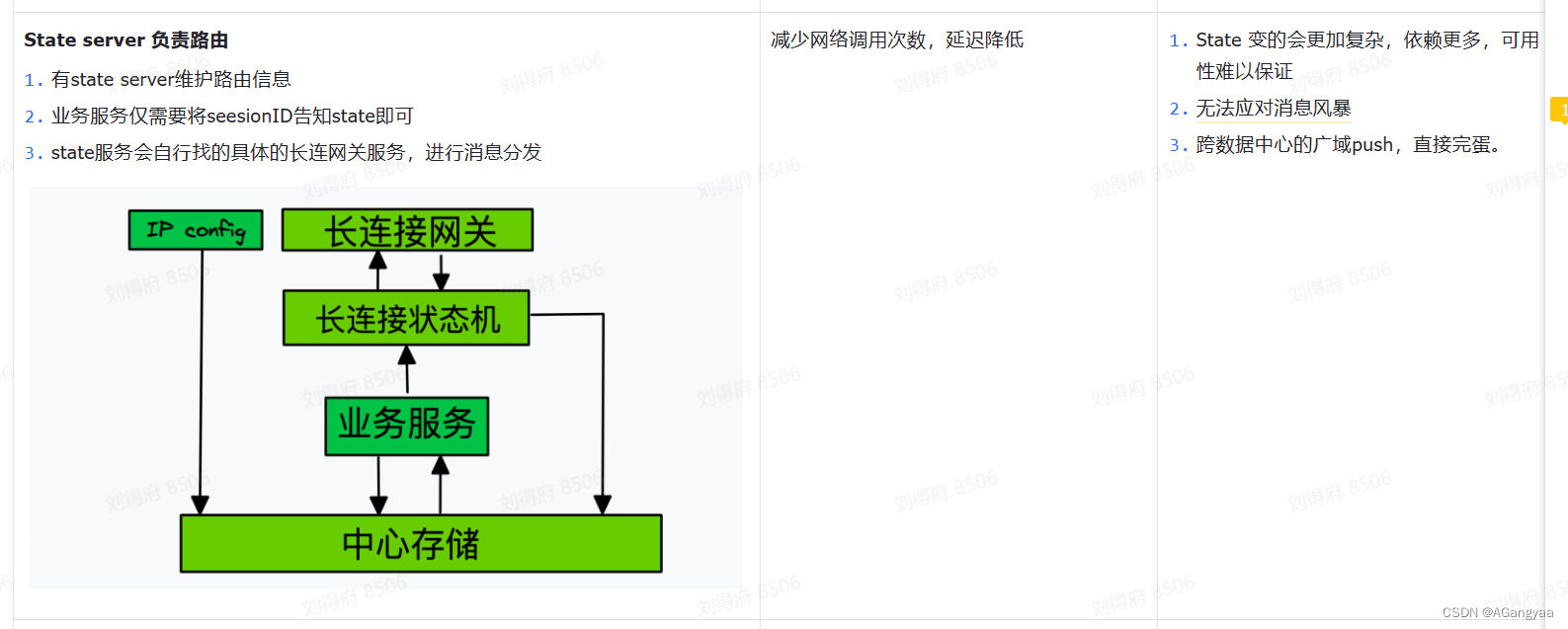
业务层怎么感知到连接在哪台机器上?并把消息分发出去呢?

为什么应用层自己维护心跳?


如何存储一个长链接的状态,才能既高效又节省内存?

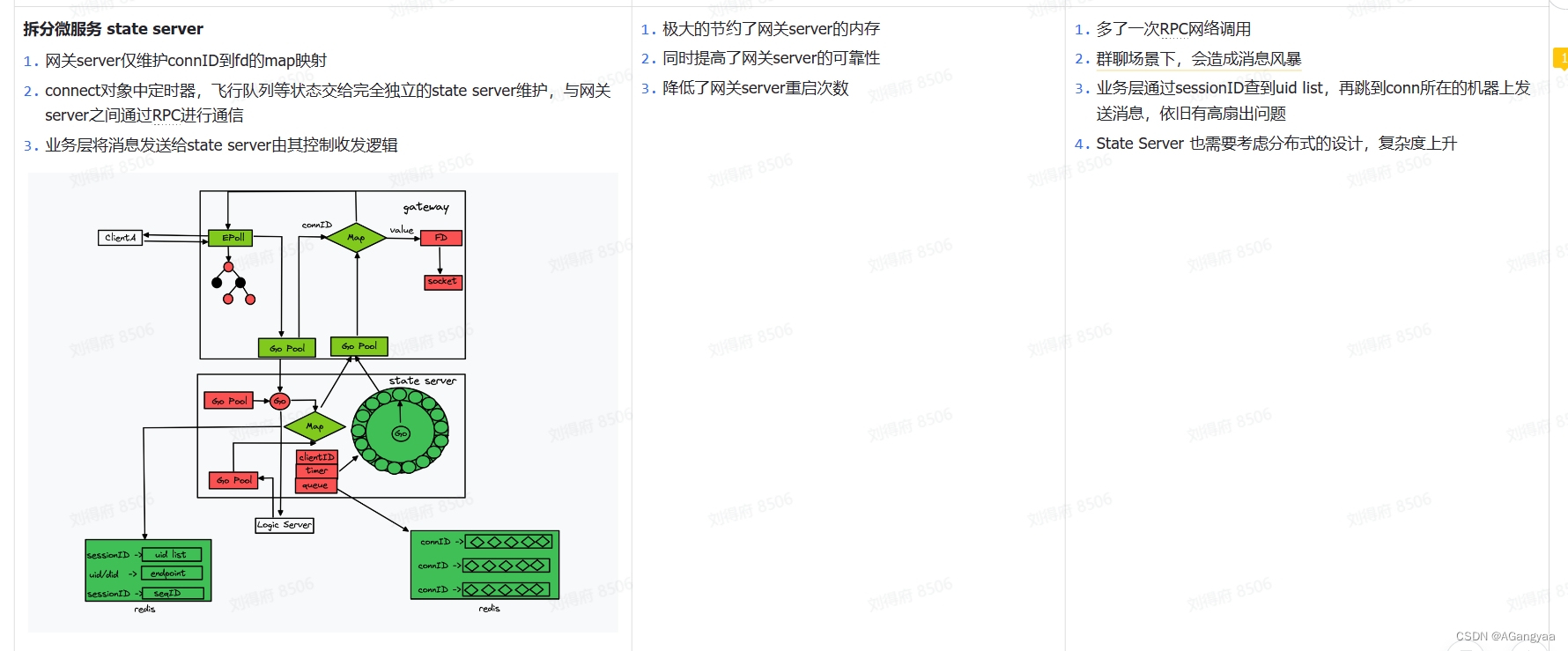

如何尽可能的减少长连接的崩溃/重启次数,做到永不死机?


Unix domain socket
虽然网络socket也可用于同一台主机的进程间通讯(通过localhost地址127.0.0.1),但是UNIX Domain Socket性能更高:不需要经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等,只是将应用层数据从一个进程拷贝到另一个进程。
与TCP套接字相比较,在同一台主机的传输速度前者是后者的两倍。
这是因为,IPC机制本质上是可靠的通讯,而网络协议是为不可靠的通讯设计的。
UNIX Domain Socket也提供面向流和面向数据包两种API接口,类似于TCP和UDP,但是面向消息的UNIX Domain Socket也是可靠的,消息既不会丢失也不会顺序错乱。
一、使用方法
第一,在创建 socket 的时候,普通的 socket 第一个参数 family 为 AF_INET, 而 UDS 指定为 AF_UNIX 即可。
第二,Server 的标识不再是 ip 和 端口,而是一个路径,例如 /dev/shm/fpm-cgi.sock。
其实在平时我们使用 UDS 并不一定需要去写一段代码,很多应用程序都支持在本机网络 IO 的时候配置。例如在 Nginx 中,如果要访问的本机 fastcgi 服务是以 UDS 方式提供服务的话,只需要在配置文件中配置这么一行就搞定了。
二、连接过程
基于 UDS 的连接过程比 inet 的 socket 连接过程要简单多了。客户端先创建一个自己用的 socket,然后调用 connect 来和服务器建立连接。
在 connect 的时候,会申请一个新 socket 给 server 端将来使用,和自己的 socket 建立好连接关系以后,就放到服务器正在监听的 socket 的接收队列中。这个时候,服务器端通过 accept 就能获取到和客户端配好对的新 socket 了。
三、发送过程
这个收发过程一样也是非常的简单。发送方是直接将数据写到接收方的接收队列里的。
时间轮
时间轮的介绍
时间轮(TimeWheel)是一种实现延迟功能(定时器)的精妙的高级算法,其算法应用范围非常广泛,在Java开发过程中常用的Dubbo、Netty、Akka、Quartz、ZooKeeper 、Kafka等各种框架中,各种操作系统的定时任务crontab调度都有用到,甚至Linux内核中都有用到,不夸张的是几乎所有和时间任务调度都采用了时间轮的思想。
时间轮的作用
高效处理批量任务
时间轮可以高效的利用线程资源来进行批量化调度,把大批量的调度任务全部都绑定时间轮上,通过时间轮进行所有任务的管理,触发以及运行。
降低时间复杂度
时间轮算法可以将插入和删除操作的时间复杂度都降为O(1),在大规模问题下还能够达到非常好的运行效果。
高效管理延时队列
能够高效地管理各种延时任务,周期任务,通知任务等,相比于JDK自带的Timer、DelayQueue + ScheduledThreadPool来说,时间轮算法是一种非常高效的调度模型。
缺点:时间精确度的问题
时间轮调度器的时间的精度可能不是很高,对于精度要求特别高的调度任务可能不太适合。因为时间轮算法的精度取决于时间段“指针”单元的最小粒度大小,比如时间轮的格子是一秒跳一次,那么调度精度小于一秒的任务就无法被时间轮所调度。
精度问题我们可以考虑后面提出的优化方案:多级时间轮。