大家好,我是feng,欢迎关注公众号和我一起探索。如果文章对你有所启发,请为我点赞、转发以及在下方留言自己的理解!
每次发文章都看到不少人收藏。我自己也有这个习惯,但是基本上收藏起来的东西都没再打开过。哪怕再遇到类似的问题,首先想到的却是搜索,置于收藏的东西根本想不到去查看。所以当然可以收藏,但是我更建议大家输出(写出文字、敲出代码)自己的理解,比如在评论区写上自己对本文的理解和疑问。不要小看自己写的这几十个字,帮你加深记忆的效果绝对比收藏要好得多!
所以,请在评论区输出你的收获吧!
一、历史的问题
这个历史问题,指的是之前代码对于对话历史记录的处理逻辑,其实是存在问题的。在之前的逻辑中,我们将每次的对话的历史信息加入到历史信息数组里,并被转为字符串植入提示语模板中。这样在程序运行时,确实可以执行的很好。但是当关闭程序,重新执行的情况下,我们再提出问题时,大模型是不知道答案的。那是因为历史对话记录是存储在内存中的。一旦我们终止应用程序,所有的历史记录都会丢失。所以如果我们希望应用程序能够记住用户和大模型之间的对话时长几周、几个月或几年时,我们就需要为大模型增加记忆 - Memory。使得每次我们运行应用程序时,大模型都能够记得我们之间的对话历史。
在之前的文章中,我曾经提过历史记录可以通过接口存入外部数据库、通过接口从外部数据库导入,这样确实能够实现,但这需要依赖于后端提供相关的api。借助于LangChain提供的相关api,本文将介绍前端程序可以直接将数据读取或存储到外部存储系统中。
二、了解记忆 Memory
Memory这个词,通常被翻译为内存。在AI应用场景,我认为将memory理解为大模型与用户之间的会话过程更适合一些。所以,记忆可以被定义为获取、储存、保留以及后来检索信息的过程。
人脑中有几种类型的记忆:
- 感觉记忆(Sensory Memory):这是记忆的最早阶段,提供在原始刺激结束后保留感官信息(视觉、听觉等)的印象的能力。感觉记忆通常只持续几秒钟。子类别包括视觉记忆(iconic memory)、回声记忆(echoic memory)和触觉记忆(haptic memory)。
- 短期记忆(Short-Term Memory, STM)或工作记忆(Working Memory):它储存我们当前意识到的信息,以执行复杂的认知任务,如学习和推理。短期记忆被认为有大约7个项目的容量(Miller 1956)并持续20-30秒。
- 长期记忆(Long-Term Memory, LTM):长期记忆可以储存信息很长一段时间,从几天到几十年,其储存容量基本上是无限的。LTM有两个子类型:
- 显性 / 陈述记忆(Explicit / declarative memory):这是对事实和事件的记忆,指的是那些可以被有意识地回忆的记忆,包括情景记忆(事件和经验)和语义记忆(事实和概念)。
- 隐性 / 程序记忆(Implicit / procedural memory):这种记忆是无意识的,涉及自动执行的技能和例行程序,如骑自行车或在键盘上打字。
| 记忆类型 | 映射 | 例子 |
|---|---|---|
| 感觉记忆 | 学习原始输入的嵌入表示,包括文本、图像或其他形式,短暂保留感觉印象。 | 看一张图片,然后在图片消失后能够在脑海中回想起它的视觉印象。 |
| 短期记忆 | 上下文学习(比如直接写入prompt中的信息),处理复杂任务的临时存储空间,受Transformer有限的上下文窗口长度限制。 | 在进行心算时记住几个数字,但短期记忆是有限的,只能暂时保持几个项目。 |
| 长期记忆 | 在查询时智能Agent可以关注的外部向量存储,具有快速检索和基本无限的存储容量。 | 学会骑自行车后,多年后再次骑起来时仍能掌握这项技能,这要归功于长期记忆的持久存储。 |
可以大致考虑以下对应关系:
- 将感觉记忆视为学习原始输入(包括文本、图像或其他模式)的嵌入表示;
- 将短期记忆视为在上下文中(prompt)学习。它是短暂且有限的,因为它受到Transformer的上下文窗口长度的限制。
- 将长期记忆视为代理在查询时可以注意到的外部向量存储,可以通过快速检索访问。
三、为大模型加上记忆Memory
3.1 增加记忆
mport { ChatOllama } from '@langchain/community/chat_models/ollama';
import { ChatPromptTemplate } from '@langchain/core/prompts';
import { BufferMemory } from 'langchain/memory';
import { ConversationChain } from 'langchain/chains';
// 创建模型
const model = new ChatOllama({
baseUrl: 'http://localhost:11434', // Default value
model: 'qwen:4b',
temperature: 0.7,
});
// 创建提示语
const prompt = ChatPromptTemplate.fromTemplate(`
你是一个助手。
History: {history}
{input}
`);
// 创建记忆,memoryKey代表了每次对话的唯一标识
const memory = new BufferMemory({
memoryKey: 'history',
});
// 使用 Chain 类的方式
const chain = new ConversationChain({
llm: model,
prompt,
memory,
});
// 使用LCEL
//const chain = prompt.pipe(model);
// 打印记忆中的变量
console.log('记忆中的变量:', await memory.loadMemoryVariables());
// 第一次调用
const input1 = {
input: '密码是:abc',
};
// 获取响应
const resp1 = await chain.invoke(input1);
console.log(resp1);
console.log('更新后的记忆:', await memory.loadMemoryVariables());
// 第二次调用
const input2 = {
input: '密码是什么?',
};
// 获取响应
const resp2 = await chain.invoke(input2);
console.log(resp2);
如代码注释,使用了Chain类的方式来创建一个链,ConversationChain类接收一个memory参数。代码中共调用了2次大模型。每次调用都会自动更新memory历史记录。看一下调用情况:

可以看到,在第一次调用前,通过memory.loadMemoryVariables()方法,来获取当前记忆中的变量列表是空字符串。在第一次调用完以后,记忆被更新。通过将记忆传入到提示语中,大模型才能够回答问题。
这个例子实际上也是运行在内存之中,当我们移动重新运行时,记忆中的变量仍然会被清空,这并不是本文的目的。因此我们要了解如果将记忆存到外部系统,以及如何从外部系统读取记忆。
3.2 记忆的外部存储与读取
LangChain支持多种类型的外部存储,如Postgresql、Redis、MongoDB等,详细的支持列表可以访问网址:https://js.langchain.com/docs/integrations/chat_memory
我将使用本机安装的Postgresql数据库来作为外部存储目的地。
3.2.1 配置数据库
首先,创建一个新的数据库:ai_start,在pgAdmin4中查看如图:
这是新创建的数据库,所以在默认的Schema:public下,并没有任何表存在。
3.2.2 改造代码
mport { ChatOllama } from '@langchain/community/chat_models/ollama';
import { PostgresChatMessageHistory } from '@langchain/community/stores/message/postgres';
import { RunnableWithMessageHistory } from '@langchain/core/runnables';
import {
ChatPromptTemplate,
MessagesPlaceholder,
} from '@langchain/core/prompts';
import { StringOutputParser } from '@langchain/core/output_parsers';
import pg from 'pg';
const model = new ChatOllama({
baseUrl: 'http://localhost:11434', // Default value
model: 'qwen:4b',
temperature: 0.7,
});
const poolConfig = {
host: 'localhost',
port: 5431,
user: 'bx_dev',
password: 'bx_dev',
database: 'ai_start',
};
const pool = new pg.Pool(poolConfig);
const prompt = ChatPromptTemplate.fromMessages([
('system', '你是一个很有能力的助手,尽你所有的能力来回答用户提出的问题。'),
new MessagesPlaceholder('chat_history'),
('human', '{input}'),
]);
const chain = prompt.pipe(model).pipe(new StringOutputParser());
const chainWithHistory = new RunnableWithMessageHistory({
runnable: chain,
inputMessagesKey: 'input',
historyMessagesKey: 'chat_history',
getMessageHistory: async (sessionId) => {
const chatHistory = new PostgresChatMessageHistory({
sessionId,
pool,
});
return chatHistory;
},
});
const res1 = await chainWithHistory.invoke(
{
input: '你好,我是tony。',
},
{
configurable: { sessionId: 'langchain-test-session' },
},
);
console.log('res1:', res1);
const res2 = await chainWithHistory.invoke(
{
input: '我的名字叫什么?',
},
{
configurable: { sessionId: 'langchain-test-session' },
},
);
console.log('res2:', res2);
await pool.end();
3.3.3 理解代码逻辑
- poolConfig是本机数据库的配置信息。此处主要指定了目标数据库的配置信息,特别是数据库名称。
- 由于我们对输出进行了格式化,需要消息变量的替换,所以在使用提示语模板时,使用了 fromMessages。
- RunnableWithMessageHistory,是一个可以使用历史记录的链。它主要接收一个对象类型的4个参数。
- 可运行的链对象
- 消息占位符标识
- 历史数据库标识
- 异步的获取历史数据的方法,接收一个sessionId,利用这个sessionId和数据库连接信息来获取历史记录
- 在调用链时,我们需要配置当次调用时的sessionId。
我们来看看控制台执行结果:
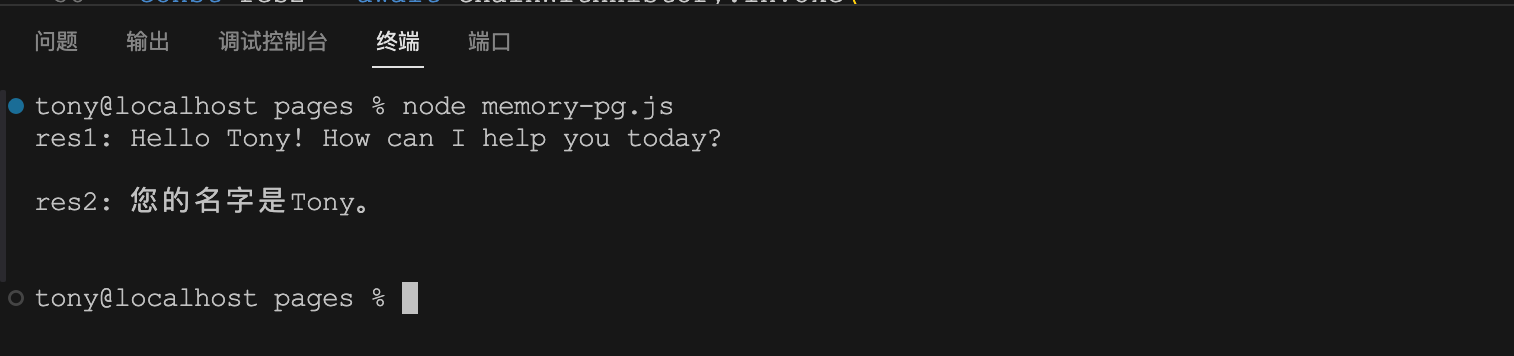
可以看到,正确的回答了问题。再来看看数据库:
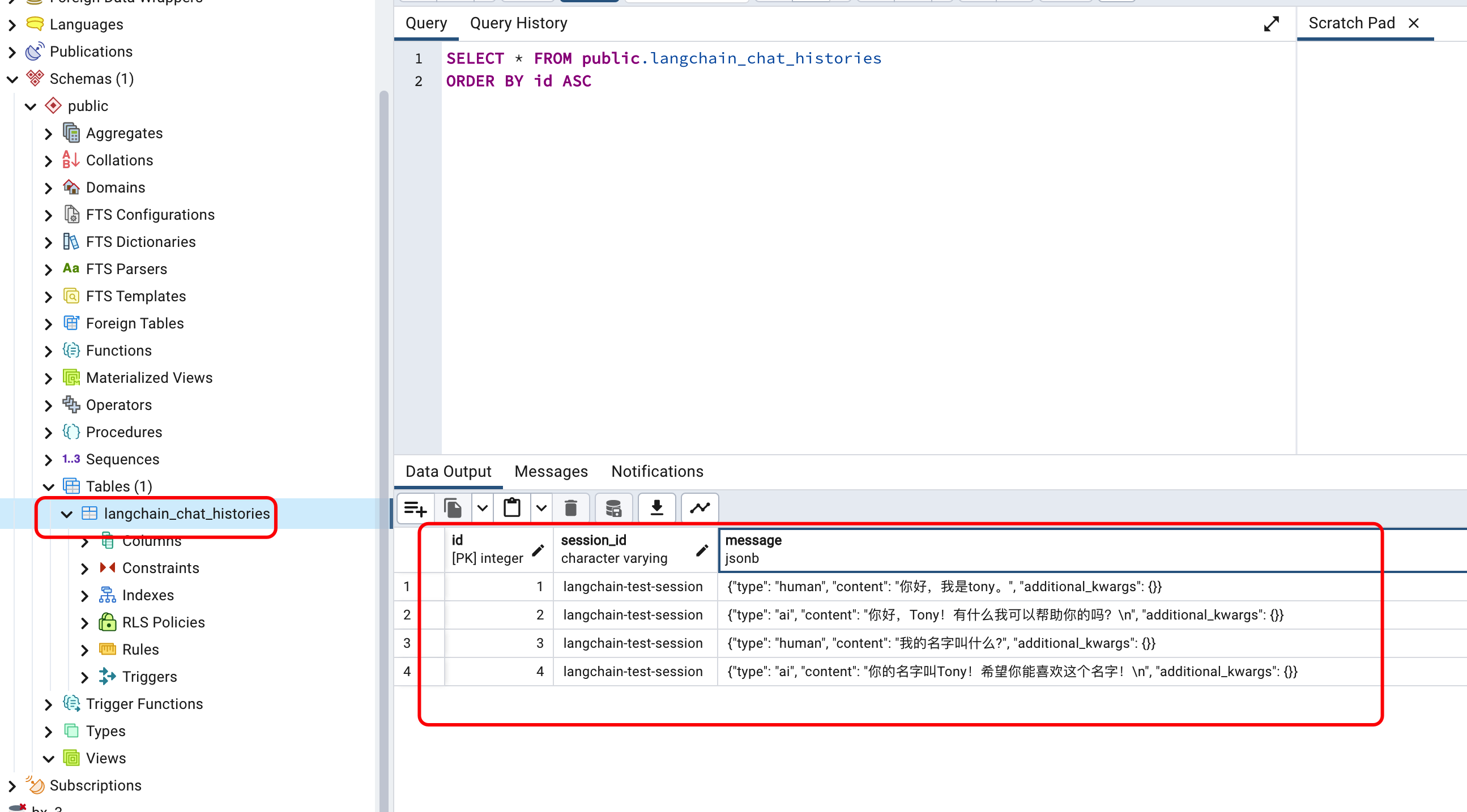
我们会发现,LangChain创建了一个名为langchain_chat_histories的表,并且在表中已经存储了程序在运行时的历史对话记录。
至此,我们实现了通过前端,将历史记录存储到外部系统,并且从外部系统获取历史数据以支持大模型的回答。
四、总结
要实现为大模型增加记忆功能,在本文中主要是RunnableWithMessageHistory对象的使用。通过配置数据连接信息,和定义获取历史记录方法,我们可以非常简单的就实现这个目的。
在Langchain官网上还有很多对话存储的api,读者可以根据自己的实际情况选择不同的实现方式。
从数据安全性角度来说,连接信息存储在前端(比如本文的例子)并不是一个好的选择。Langchain也支持通过token的形式连接云端系统,这种方式是一种选择。不过,我还是建议通过后端的api来实现存储。这样我们可以方便的使用axios库直接调用进行读取和存储记忆数据,无论从安全性、灵活性以及前端对相关技术的熟练度来说,都可能是更合适的选择。
参考
1、https://js.langchain.com/docs/integrations/chat_memory/postgres
2、https://zhuanlan.zhihu.com/p/648376562