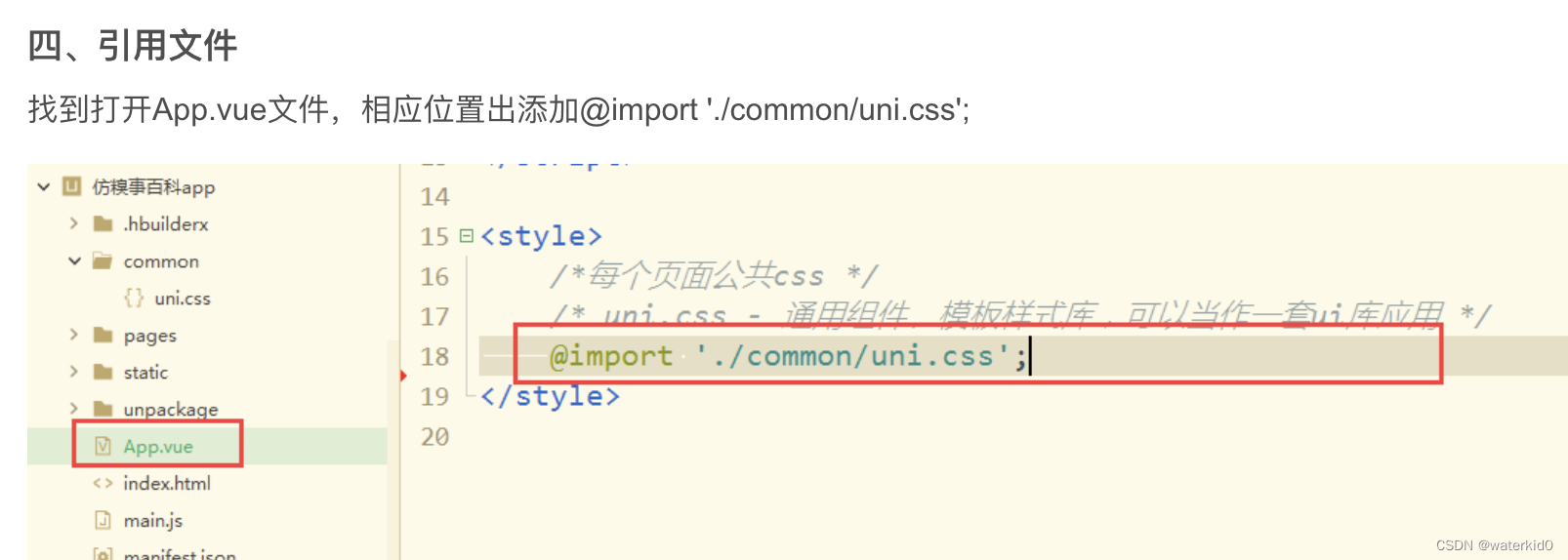
OpenCV 是一个开源的计算机视觉(Computer Vision)与机器学习软件库,提供了多种图像处理算法与接口。在 OCR 技术中,字符分割用于提取图像中的文字信息,可以应用于车牌识别、身份证识别、文档扫描等场景。本文主要记录如何使用 OpenCV 实现手写字符分割。

目录
1 工作原理
1.1 图像预处理
1.2 字符检测
1.3 字符提取
2 程序设计
1 工作原理
手写字符分割的主要目标是将连续的手写文本图像进行分割,得到单字符的图像。这里考虑字符按照水平方向书写的情况,使用 OpenCV 实现手写字符分割,主要包括以下几个步骤:
1)图像预处理:将图像转化为二值图,并进行图像去噪,使字符更容易被识别;
2)字符检测:使用轮廓检测函数,识别可能包含字符的区域;
3)字符提取:找到所有字符区域之后,从每个字符区域中提取字符。

1.1 图像预处理
在手写字符分割中,图像预处理过程包括:灰度图转换、二值化和中值滤波。其中,灰度图转换和二值化处理,使字符与背景区域之间的对比度更大,便于寻找可能的字符区域;中值滤波用于去除图像中的噪点。
使用 cv2.cvtColor() 和 cv2.threshold() 函数实现图像灰度图转换与二值化。
# 灰度图转换
gray = cv2.cvtColor(src_img, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)使用 cv2.medianBlur() 函数实现中值滤波。
# 中值滤波
filter_size = 3
binary_f = cv2.medianBlur(binary, filter_size)1.2 字符检测
图像预处理完成后,就可以使用 cv2.findContours() 函数检测图像的轮廓信息,进一步寻找字符区域。
# 查找字符区域
contours, _ = cv2.findContours(binary_f, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cv2.findContours() 函数会返回多个轮廓信息,考虑到一些特殊字符(例如 %,÷),这些字符存在多个不连接的部分,因此需要合并位置接近的轮廓,得到字符整体区域。
首先遍历所有的轮廓区域,获取最大宽度。然后计算每个区域的中点位置,若两个区域的中点位置距离小于最大宽度的一半,则拼接这两个区域。
# 遍历所有区域,寻找最大宽度
w_max = 0
for cnt in contours:
_, _, w, _ = cv2.boundingRect(cnt)
if w > w_max:
w_max = w
# 遍历所有区域,拼接x坐标接近的区域
char_dict = {}
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
x_mid = x + w//2 # 计算中点位置
if not char_dict.keys() or all(np.abs(z - x_mid) > w_max//2 for z in char_dict.keys()):
char_dict[x_mid] = cnt
else:
for z in char_dict.keys():
if np.abs(z - x_mid) <= w_max//2:
char_dict[z] = np.concatenate((char_dict[z], cnt), axis=0) # 拼接两个区域1.3 字符提取
字符区域查找完成之后,遍历所有字符区域,使用 cv2.boundingRect() 函数获取端点位置和宽高信息,就可以提取字符了。
# 遍历所有区域,提取字符
dst_img = []
for _, cnt in char_dict.items():
x, y, w, h = cv2.boundingRect(cnt)
roi = binary[y:y+h, x:x+w]
dst_img.append(roi)2 程序设计
使用 Gradio 实现交互式界面,中值滤波大小可选 3 × 3, 5 × 5 或 7 × 7。以下是 Python 实现代码:
#-*- Coding: utf-8 -*-
import cv2
import numpy as np
import gradio as gr
def charSeperate(src_img, filter_size):
"""函数功能:字符分割
@param src_img
@param filter_size
@return dst_img"""
# 灰度图
gray = cv2.cvtColor(src_img, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
binary_inv = cv2.bitwise_not(binary)
# 中值滤波
filter_size = int(filter_size[0][0]) if filter_size else 3
binary_f = cv2.medianBlur(binary_inv, filter_size)
# 查找字符区域
contours, _ = cv2.findContours(binary_f, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 遍历所有区域,寻找最大宽度
w_max = 0
for cnt in contours:
_, _, w, _ = cv2.boundingRect(cnt)
if w > w_max:
w_max = w
# 遍历所有区域,拼接x坐标接近的区域
char_dict = {}
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
x_mid = x + w//2 # 计算中点位置
if not char_dict.keys() or all(np.abs(z - x_mid) > w_max//2 for z in char_dict.keys()):
char_dict[x_mid] = cnt
else:
for z in char_dict.keys():
if np.abs(z - x_mid) <= w_max//2:
char_dict[z] = np.concatenate((char_dict[z], cnt), axis=0) # 拼接两个区域
# 按照中点坐标,对字符进行排序
char_dict = dict(sorted(char_dict.items(), key=lambda item: item[0]))
# 遍历所有区域,提取字符
dst_img = []
for _, cnt in char_dict.items():
x, y, w, h = cv2.boundingRect(cnt)
roi = binary[y:y+h, x:x+w]
dst_img.append(roi)
return dst_img
if __name__ == "__main__":
demo = gr.Interface(
fn=charSeperate,
inputs=[
gr.Image(label="input image"),
gr.Radio(['3x3', '5x5', '7x7'], value='3x3')
],
outputs=[
gr.Gallery(label="charset", columns=[3], object_fit="contain", height="auto")
],
live=True
)
demo.launch()
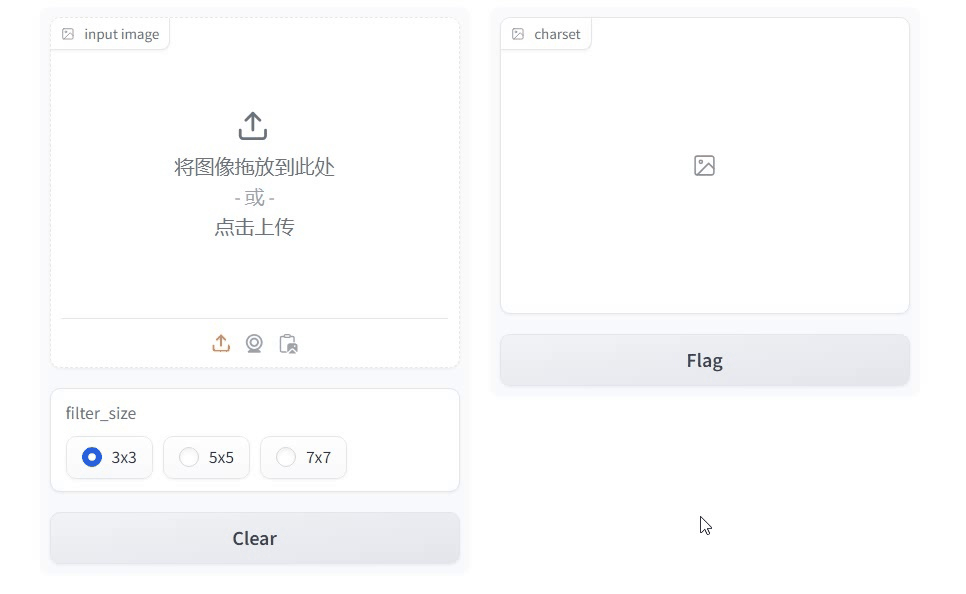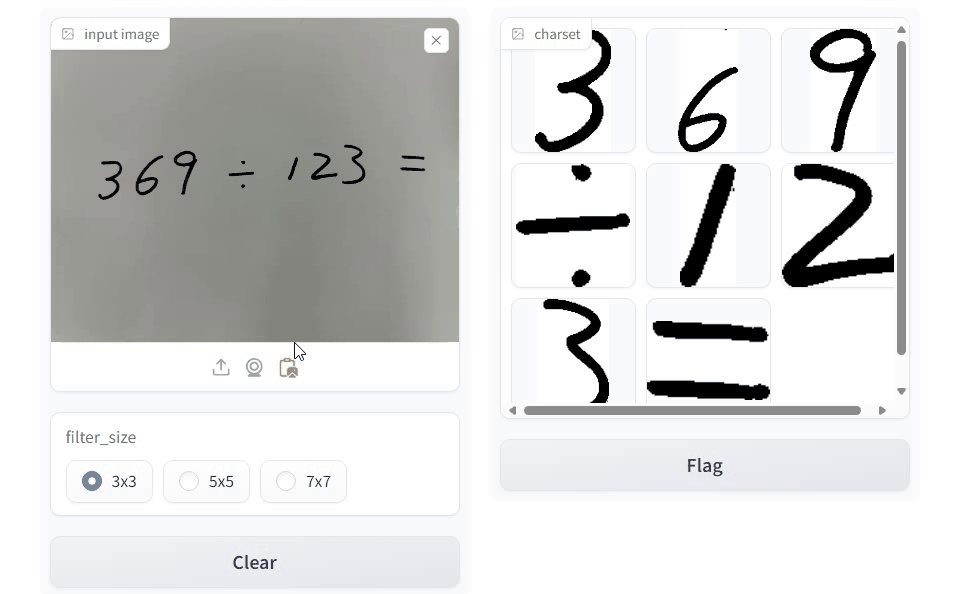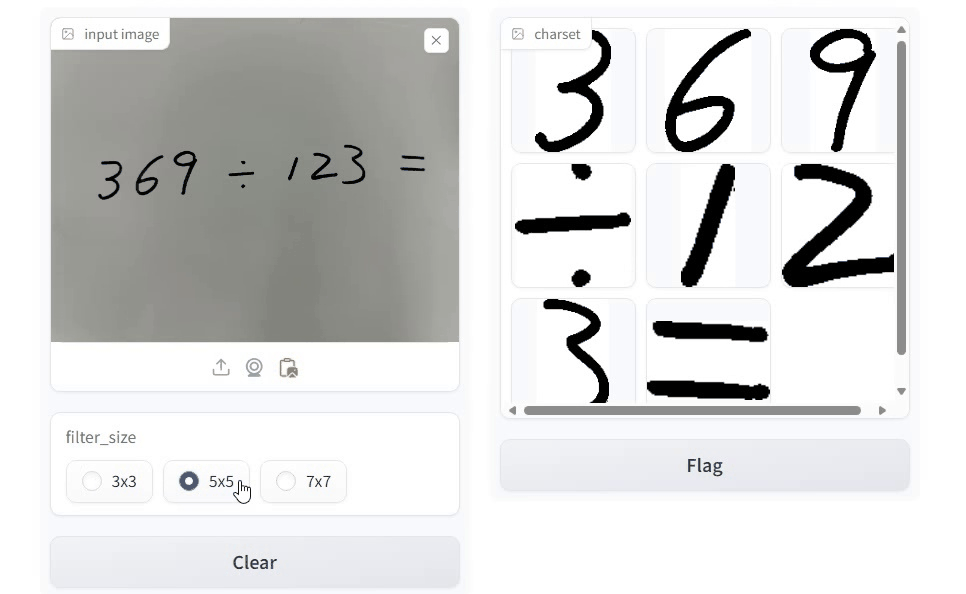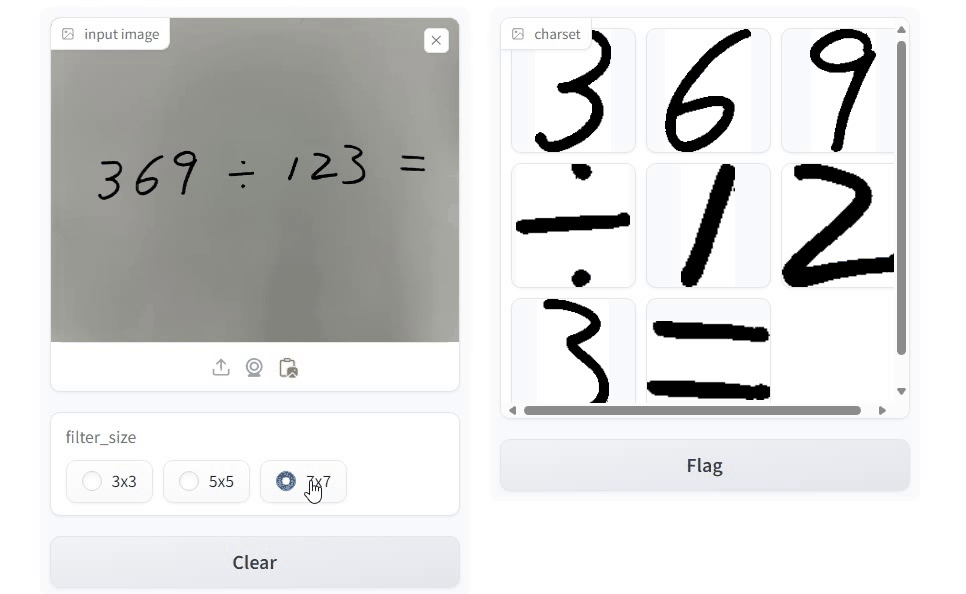
以下是代码运行效果: