Gemma: Open Models Based on Gemini Research and Technology
相关链接:arxiv
关键字:Gemma、Google DeepMind、open models、language understanding、reasoning
摘要
这项工作介绍了Gemma,一系列轻量级、最先进的开放模型,基于创建Gemini模型所用的研究和技术。Gemma模型在语言理解、推理和安全性方面的学术基准测试中显示出强大的性能。我们发布了两种大小的模型(20亿和70亿参数),并提供了预训练和微调后的检查点。在18个文本为基础的任务中,Gemma在11项上超越了同等规模的开放模型。同时,我们对模型的安全性和责任方面进行了全面评估,并详细描述了模型开发过程。我们认为负责任地发布这些大型语言模型对提高模型安全性、使能下一代语言模型创新至关重要。
核心方法
- 模型架构:Gemma模型基于Transformer Decoder架构,训练数据量高达6T tokens,使用了与Gemini模型家族类似的架构、数据和训练配方。Gemma模型具有在文本领域的广泛适用性,并在大规模下展现出最先进的理解和推理能力。
- 技术改进:Gemma模型引入了诸多改进技术,包括:
- Multi-Query Attention:对于7B模型使用多头注意力,而2B模型则使用多查询注意力。
- RoPE Embeddings:不使用绝对位置编码,而是在每一层使用旋转位置编码,并在输入和输出之间共享嵌入以减少模型大小。
- GeGLU激活函数:用标准的ReLU非线性激活函数替换为GeGLU激活函数。
- RMSNorm:对每个Transformer子层的输入,即注意力层和前馈层,使用RMSNorm进行归一化。
- 训练基础设施:使用TPUv5e进行训练;7B模型在16个POD上训练,总计4096个TPUv5e。
- 碳足迹:预计Gemma模型预训练的碳排放为约131 tCO2eq。
实验说明
自动化基准评估:评估包括多个领域,如物理推理、社会推理、问答、编码、数学、常识推理等。
人类偏好评估:对终版候选模型进行人类评价研究,以测试其指令遵循能力和基本安全协议。
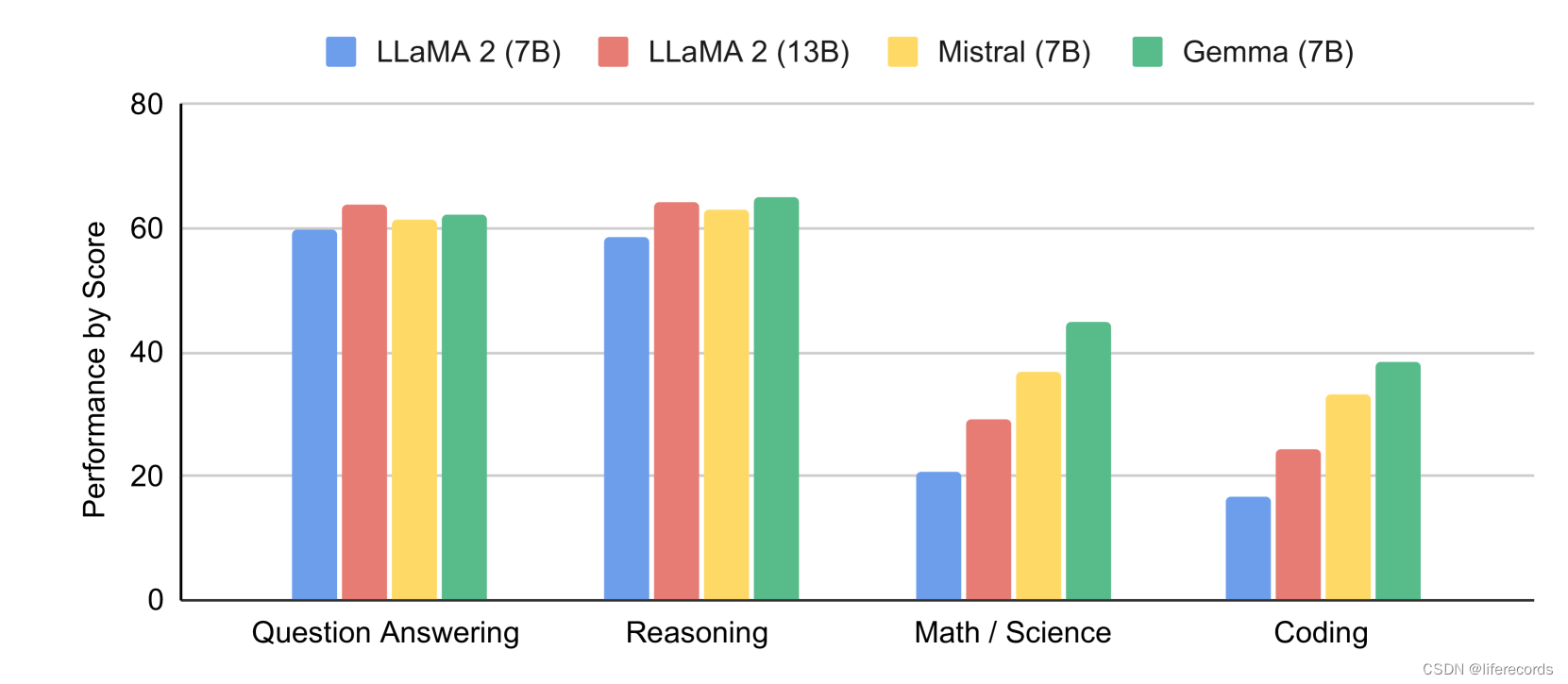
一些评估结果:
- 在约1000个提示方面的创意写作任务中,Gemma 7B IT的正面胜率为51.7%,Gemma 2B IT为41.6%。
- 在约400个面向基本安全协议的提示中,Gemma 7B IT的胜率为58%,Gemma 2B IT为56.5%。
自动化基准测试:Gemma模型在包括MMLU、HellaSwag和PIQA等基准测试中获得了表现优异的结果。
结论
我们展示了Gemma,一个用于文本和代码的公开可用的生成式语言模型家族。Gemma在开放的语言模型性能、安全性和负责任的发展方面推动了最先进的水平。通过充分的安全评估和缓解措施,我们相信Gemma模型将为社区带来净收益。不过,我们承认这种发布是不可逆的,开放模型可能带来的危害尚未明确定义,因此我们将继续采取与这些模型可能带来的潜在风险相称的评估和安全缓解措施。此外,我们的模型在6项标准安全基准上的表现超越了竞争对手,并在人与人之间的比较中也占上风。
Gemma模型改善了包括对话、推理、数学和代码生成在内的广泛领域的表现。在MMLU(64.3%)和MBPP(44.4%)上的结果不仅显示了Gemma的高性能,也展示了公开LLM的巨大潜力。我们期待社区会基于Gemma展开广泛的研究,并希望开发者能够创造出有益的新应用、用户体验和其他功能。