源码在上篇 地址在这 :Kafka模拟器产生数据仿真-集成StructuredStreaming做到”毫秒“级实时响应StreamData落地到mysql-CSDN博客
这里分享一下一些新朋友不知道spark-submit 指令后 的参数怎么写 看这篇绝对包会
声明: 此项目是基于 maven 打包的说明,不是SBT哦
先分享一下我的原指令吧:
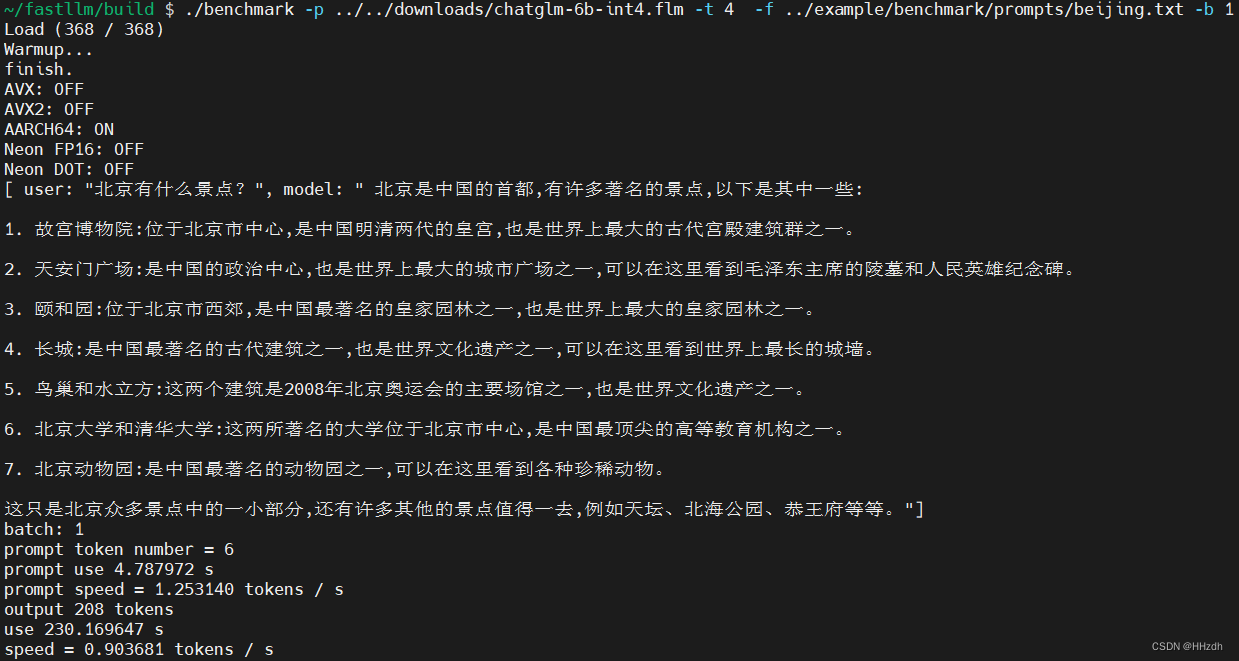
bin/spark-submit --master local[4] --class kafkaStucturestreaming.KafkaStreamSQL --jars /opt/spark_file/original-ReadFile-1.0-SNAPSHOT.jar /opt/spark_file/ReadFile-1.0-SNAPSHOT.jar 大致只需要指定: --master 参数 我这用的是本地进程 local[*] * 个数看自己
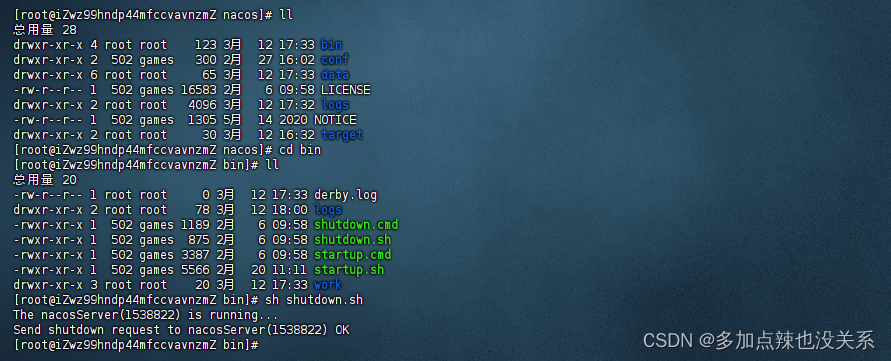
--class 这里重点一下:一些新朋友可能不知道其实就是看你程序的package 如图:首行

我的是:package kafkaStucturestreaming
所以: 你在spark-submit 指令后面跟的class 就写:kafkaStucturestreaming . 你的scala文件名即可 当然去掉scala文件后缀名就行
eg : kafkaStucturestreaming.KafkaStreamSQL 就行哦 KafkaStreamSQL 这是我spark程序的scala文件 class指向它就行,
然后 : 下一个重点是:
--jars 参数
注意点_1.如果你的项目不用依赖于pom文件中的一些依赖项组件就只需要执行 :original-ReadFile-1.0-SNAPSHOT.jar 这种的jar包即可;
注意点_2. 如果你的项目需要依赖于pom文件中的一些依赖组件eg:kafka的集成组件之类的就需要二个 maven 打包的 jar 包后放到 --class 后面 否则报因为缺少依赖组件找不到kafka的数据源
eg这样的报错就是注意点_2:Error: Missing application resource

总之需要依赖于pom文件之类的依赖组件项就将这二个jar包都写到 --class参数后面即可
最后写给出全部的spark-submit 可指定参数给大家
1.–master MASTER_URL: 指定要连接的集群模式(集群资源管理器)
standalone模式: spark://host:port, 如:spark://xxxxx:7077
Spark On Mesos模式 : mesos://host:port
Spark On YARN模式: yarn://host:port
本地模式:local
2. – deploy-mode DEPLOY_MODE : 指定任务的提交方式(client 和cluster)
3. –name appName :设置任务的名称,在webUI可查看
4. –py-files PY_FILES :加载Python外部依赖文件
5 . –driver-memory MEM:设置driver的运行内存(占用客户端内存,用于通信及调度开销,默认为1G)
6 . –executor-memory MEM:设置每一个executor的运行内存(占用工作节点内存,主要用于执行任务的内存开销),executor代表work节点上的一个进程。
7 . –total-executor-cores NUM:设置任务占用的总CPU核数(即任务的并发量),由主节点指定各个工作节点CPU的使用数。
注意:该参数选项只在Spark standalone and Mesos 模式下有效
8 . –executor-cores NUM:设置执行任务的每一个executor的CPU核数(yarn模式有效,默认为1或者工作节点的总CPU核数(standalone模式有效)
9 . –num-executors NUM:设置任务的executor进程数(yarn模式下有效)
10 . –conf PROP=VALUE:设置Spark的属性参数
–conf spark.default.parallelism=1000 设置RDD分区大小,系统默认为200
–conf spark.storage.memoryFraction=0.5 设置内存分配大小(存储),系统默认为0.6
–conf spark.shuffle.memoryFraction=0.3 设置shuffle上限内存空间,系统默认为0.2


![CVE-2022-1310:RegExp[@@replace] missing write barrier lead a UAF](https://img-blog.csdnimg.cn/direct/978ab01129444b709f5f048be247e069.png#pic_center)