激活函数大汇总(八)(Maxout & Softmin附代码和详细公式)
更多激活函数见激活函数大汇总列表
一、引言
欢迎来到我们深入探索神经网络核心组成部分——激活函数的系列博客。在人工智能的世界里,激活函数扮演着不可或缺的角色,它们决定着神经元的输出,并且影响着网络的学习能力与表现力。鉴于激活函数的重要性和多样性,我们将通过几篇文章的形式,本篇详细介绍两种激活函数,旨在帮助读者深入了解各种激活函数的特点、应用场景及其对模型性能的影响。
在接下来的文章中,我们将逐一探讨各种激活函数,从经典到最新的研究成果。
限于笔者水平,对于本博客存在的纰漏和错误,欢迎大家留言指正,我将不断更新。
二、Maxout
Maxout激活函数是由Ian Goodfellow等人在2013年提出的,旨在通过学习激活函数本身来改进模型性能,特别是在深度学习领域。Maxout激活函数可以被看作是ReLU和其它线性变体激活函数的一般化,具有优秀的模型适应性和表现力。
1. 数学定义
Maxout函数实际上是一个片段线性函数,它的计算过程可以看作是对输入的一组线性变换的最大值。给定一个输入向量 x ∈ R d x \in \mathbb{R}^d x∈Rd和一组权重 W ∈ R m × d W \in \mathbb{R}^{m \times d} W∈Rm×d以及偏置 b ∈ R m b \in \mathbb{R}^m b∈Rm,Maxout激活函数的输出为:
Maxout
(
x
)
=
max
i
∈
[
1
,
k
]
(
W
i
⋅
x
+
b
i
)
\operatorname{Maxout}(x)=\max _{i \in[1, k]}\left(W_i \cdot x+b_i\right)
Maxout(x)=i∈[1,k]max(Wi⋅x+bi)
这里,
W
i
W_i
Wi是权重矩阵的第
i
i
i行,
b
i
b_i
bi是偏置向量的第
i
i
i个元素,
k
k
k是一组内的单位数,通常作为超参数进行选择。
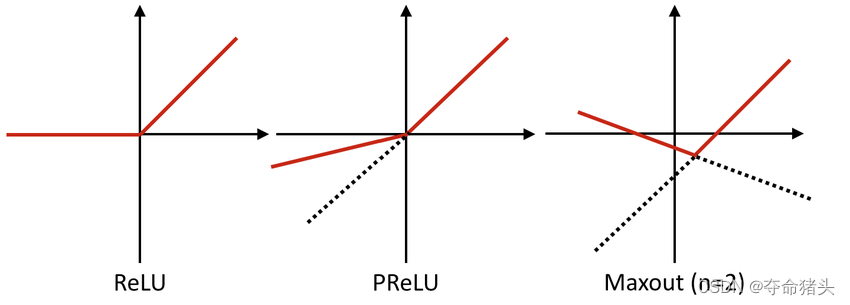
2. 函数特性
- 适应性:Maxout函数可以适应数据和任务,因为它通过学习输入的不同线性组合来形成激活函数本身,提供了极大的灵活性。
- 非饱和性:与ReLU一样,Maxout函数在一定程度上也不容易饱和,这有助于减轻梯度消失问题。
- 兼容性:Maxout可以被看作是包括ReLU、Leaky ReLU在内的多种激活函数的泛化,因此它在理论上可以复制这些激活函数的性能。
3. 导数
Maxout函数的导数取决于在前向传播过程中选择的是哪个线性组合,对于每个输入
x
x
x,只有使得
W
i
⋅
x
+
b
i
W_i \cdot x + b_i
Wi⋅x+bi最大的那个
i
i
i对应的权重和偏置会对梯度更新有贡献:
∂
Maxout
(
x
)
∂
x
=
W
i
∗
\frac{\partial \operatorname{Maxout}(x)}{\partial x}=W_{i^*}
∂x∂Maxout(x)=Wi∗
其中,
i
∗
i^*
i∗是使得
W
i
⋅
x
+
b
i
W_i \cdot x+b_i
Wi⋅x+bi达到最大的索引。
4. 使用场景与局限性
使用场景:
- 提高模型表现力:在需要模型具备高度非线性和适应性的任务中,如复杂的分类和回归问题。
- 深度学习模型:Maxout被广泛用于深度网络结构中,特别是在卷积神经网络和全连接层中。
局限性:
- 参数增加:Maxout激活函数需要学习更多的参数(由于需要对每个单元学习多个权重向量和偏置),这可能会导致模型参数显著增加,从而增加过拟合的风险。
- 计算资源需求:与简单的激活函数如ReLU相比,Maxout在计算上更为复杂和资源密集,特别是在处理大规模数据集时。
5.代码实现
实现Maxout激活函数在Python中通常涉及到对输入进行多个线性变换,并取这些变换的最大值。这里,我将展示一个简化的Maxout函数实现,它接受预先计算好的一组线性变换结果作为输入,然后返回每个样本的最大激活值。这个简化版本假设你已经有了一组线性变换的结果,例如,通过多个全连接层(每层对应一个不同的权重集和偏置)处理同一个输入得到的。
import numpy as np
def maxout(inputs):
"""
简化版的Maxout激活函数。
参数:
inputs -- 输入值,假定为一个形状为(batch_size, num_units, num_pieces)的三维数组,
其中batch_size是批处理大小,num_units是每个Maxout单元的数量,
num_pieces是每个单元中线性变换的数量。
返回:
Maxout激活后的结果,形状为(batch_size, num_units)的二维数组。
"""
return np.max(inputs, axis=2)
解读
- 输入形状:
inputs应该是一个三维数组,其中第一维是批处理大小(即一次处理多少样本),第二维是Maxout单元的数量,第三维是每个Maxout单元中进行的线性变换的数量。每个Maxout单元对应的是同一个输入通过不同的权重和偏置进行线性变换的结果。 - 最大值操作:
np.max(inputs, axis=2)计算每个Maxout单元中所有线性变换结果的最大值。这里,axis=2指定了沿着第三个维度(即每个单元中不同线性变换的结果)进行最大值操作。 - 输出:函数返回一个二维数组,形状为
(batch_size, num_units),表示每个样本在每个Maxout单元上的最大激活值。
示例使用
以下是如何使用定义的maxout函数来处理一组输入:
# 假设有一个批次包含2个样本,每个样本需要计算2个Maxout单元,每个单元有3个线性变换的结果
inputs = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
maxout_values = maxout(inputs)
print("Maxout Values:\n", maxout_values)
例子中,inputs模拟了两个样本通过两个Maxout单元(每个单元有三个线性变换)的处理结果。maxout函数计算并返回每个单元中最大的激活值。
三、Softmin
Softmin激活函数是Softmax函数的一个变体,主要用于多类分类问题中。与Softmax函数将输入向量的元素转换为对应的概率分布不同,Softmin函数关注于将输入向量转换为一个概率分布,其中较小的输入值获得较大的概率。这使得Softmin函数在某些特定的应用场景下,如需要强调较小值的情况,变得非常有用。
1. 数学定义
对于一个输入向量 x ∈ R n x \in \mathbb{R}^n x∈Rn,Softmin函数的输出是一个同样长度的向量,其第 i i i个元素定义为:
Softmin
i
(
x
)
=
e
−
x
i
∑
j
=
1
n
e
−
x
j
\operatorname{Softmin}_i(x)=\frac{e^{-x_i}}{\sum_{j=1}^n e^{-x_j}}
Softmini(x)=∑j=1ne−xje−xi
这里,
x
i
x_i
xi是输入向量中的第
i
i
i个元素,分母是所有输入元素的指数的和的负值的指数。
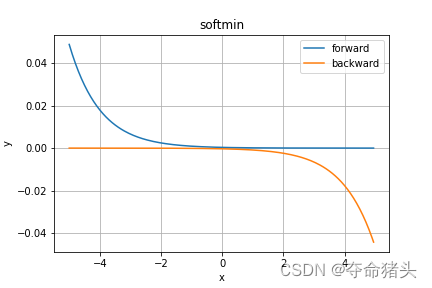
2. 函数特性
- 输出为概率分布:Softmin函数的输出是一个概率分布,其中每个元素的值介于0和1之间,且所有元素的和为1。
- 强调最小值:与Softmax强调最大值不同,Softmin函数通过将较小的输入值转换为较大的输出概率,强调了输入向量中的最小值。
- 平滑性:Softmin函数是平滑且连续的,这对于基于梯度的优化算法非常重要。
3. 导数
Softmin函数的导数相对复杂,对于输入向量 x x x中的第 i i i个元素,其导数可以表示为:
∂
Softmin
i
(
x
)
∂
x
i
=
−
Softmin
i
(
x
)
(
1
−
Softmin
i
(
x
)
)
\frac{\partial \operatorname{Softmin}_i(x)}{\partial x_i}=-\operatorname{Softmin}_i(x)\left(1-\operatorname{Softmin}_i(x)\right)
∂xi∂Softmini(x)=−Softmini(x)(1−Softmini(x))
这表明Softmin函数的导数依赖于函数自身的输出值。
4. 使用场景与局限性
使用场景:
- 多类分类的概率建模:在需要强调较小输入值的多类分类问题中,例如,在某些类型的异常检测或者成本敏感任务中,Softmin可以作为一个有效的选择。
- 配合Softmax使用:在某些情况下,Softmin可以与Softmax一起使用,以提供对输入向量中最大值和最小值的双重关注。
局限性:
- 数值稳定性:和Softmax类似,Softmin在处理具有极大或极小值的输入时可能遇到数值稳定性问题。
- 特定应用场景:Softmin的应用相比Softmax更加特定,不适用于所有类型的多类分类问题。
5.代码实现
可以使用NumPy库计算Softmin函数将每个输入元素的负指数与所有元素负指数的和的倒数相乘,从而计算出每个元素对应的概率值。
import numpy as np
def softmin(x):
"""计算Softmin激活函数的值。
参数:
x -- 输入值,可以是一个数值、一维数组(向量)或二维数组(矩阵)。
返回:
Softmin激活后的结果。
"""
e_neg_x = np.exp(-x)
return e_neg_x / np.sum(e_neg_x, axis=-1, keepdims=True)
解读
- 计算负指数:
np.exp(-x)计算输入x的每个元素的负指数。这个操作是Softmin函数的核心,因为它将输入向量转换为一个更容易处理的形式,特别是在强调较小输入值时。 - 归一化:通过
np.sum(e_neg_x, axis=-1, keepdims=True)计算所有元素负指数的和,并保持原数组的维度,以便于进行广播操作。然后,将每个元素的负指数与这个和的倒数相乘,从而得到Softmin的输出。 - 支持多维数组:通过指定
axis=-1和keepdims=True,这个实现可以支持对一维或多维数组(如批量处理时的二维数组)进行Softmin计算,使其在深度学习模型中应用更为灵活。
示例使用
以下是如何使用softmin函数来计算一组输入值的Softmin激活:
x = np.array([1.0, 2.0, 3.0, 4.0])
softmin_values = softmin(x)
print("Softmin Values:", softmin_values)
这段代码计算了数组x的Softmin激活值。
四、参考文献
Maxout
- Goodfellow, I. J., Warde-Farley, D., Mirza, M., Courville, A., & Bengio, Y. (2013). “Maxout Networks.” In Proceedings of the 30th International Conference on Machine Learning (ICML-13), pp. 1319-1327. 这篇文章首次提出了Maxout网络,详细讨论了其设计原理、优点和在多个基准数据集上的性能。
Softmin
直接关于Softmin激活函数的专门文献可能不如Softmax丰富,因为Softmin通常被视为Softmax的补充或在特定情况下的替代。然而,Softmin的概念和应用可以在涉及Softmax函数以及深度学习模型中概率输出处理的更广泛讨论中找到:
- Bishop, C. M. (2006). “Pattern Recognition and Machine Learning.” Springer. 虽然这本书没有专门讨论Softmin函数,但它提供了关于Softmax函数及其在多类分类问题中应用的深入分析,从而间接地为理解Softmin提供了背景知识。