【2024】批量查询CSDN文章质量分
- 写在最前面
- 一、分析获取步骤
- 二、获取文章列表
- 1. 前期准备
- 2. 获取文章的接口
- 3. 接口测试(更新重点)
- 三、查询质量分
- 1. 前期准备
- 2. 获取文章的接口
- 3. 接口测试
- 四、python代码实现
- 1. 分步实现
- 2. 批量获取文章信息
- 3. 从excel中读取文章url,查询质量分,再将质量分添加到excel
- 4. 全部代码

前些天发现了一个人工智能学习网站,内容深入浅出、易于理解。如果对人工智能感兴趣,不妨点击查看。
写在最前面
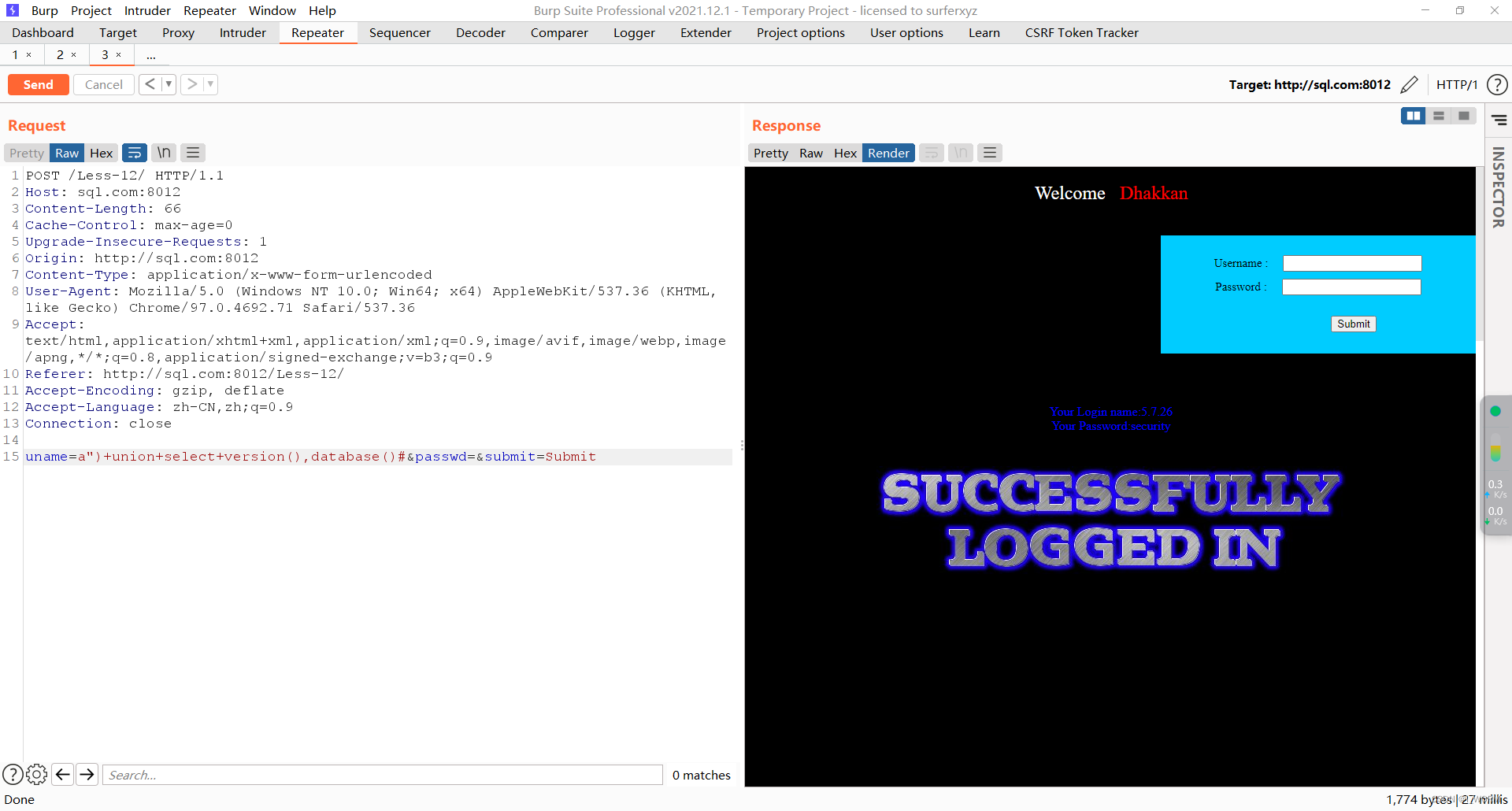
之前的代码一直报错521,不清楚什么原因
因此重新分析整个过程,并对代码进行更新
结果如图
参考:
批量获取CSDN文章对文章质量分进行检测,有助于优化文章质量
【python】我用python写了一个可以批量查询文章质量分的小项目(纯python、flask+html、打包成exe文件)
一、分析获取步骤
- 获取博主的所有文章,并且拿到对应的url地址。(需要分析接口)
- 获取到url地址,我们需要使用官方查询质量分网页的接口进行请求。(需要分析接口)
- 接口分析完成后,我们就可以按照我们的需求进行代码编写了。
二、获取文章列表
1. 前期准备
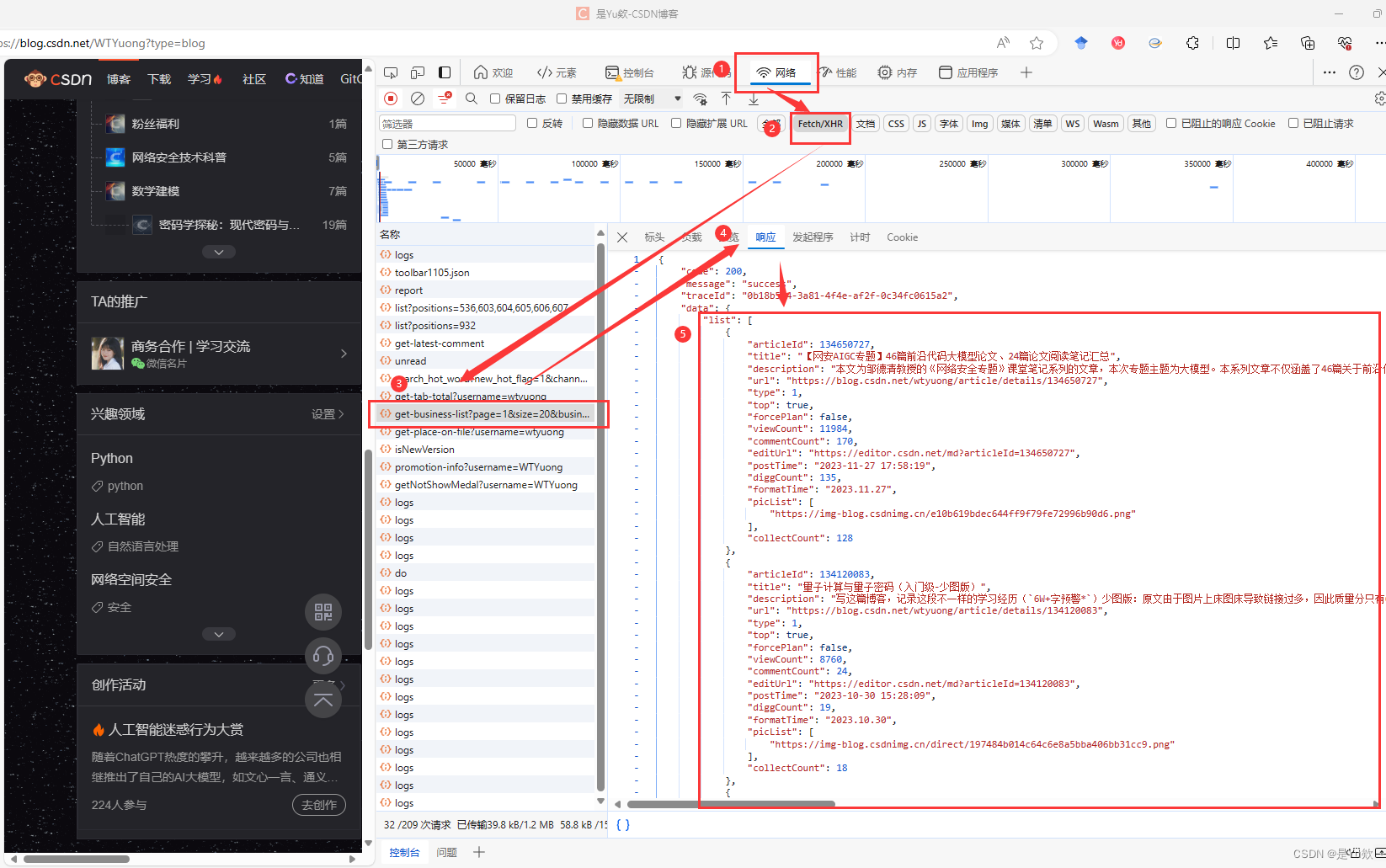
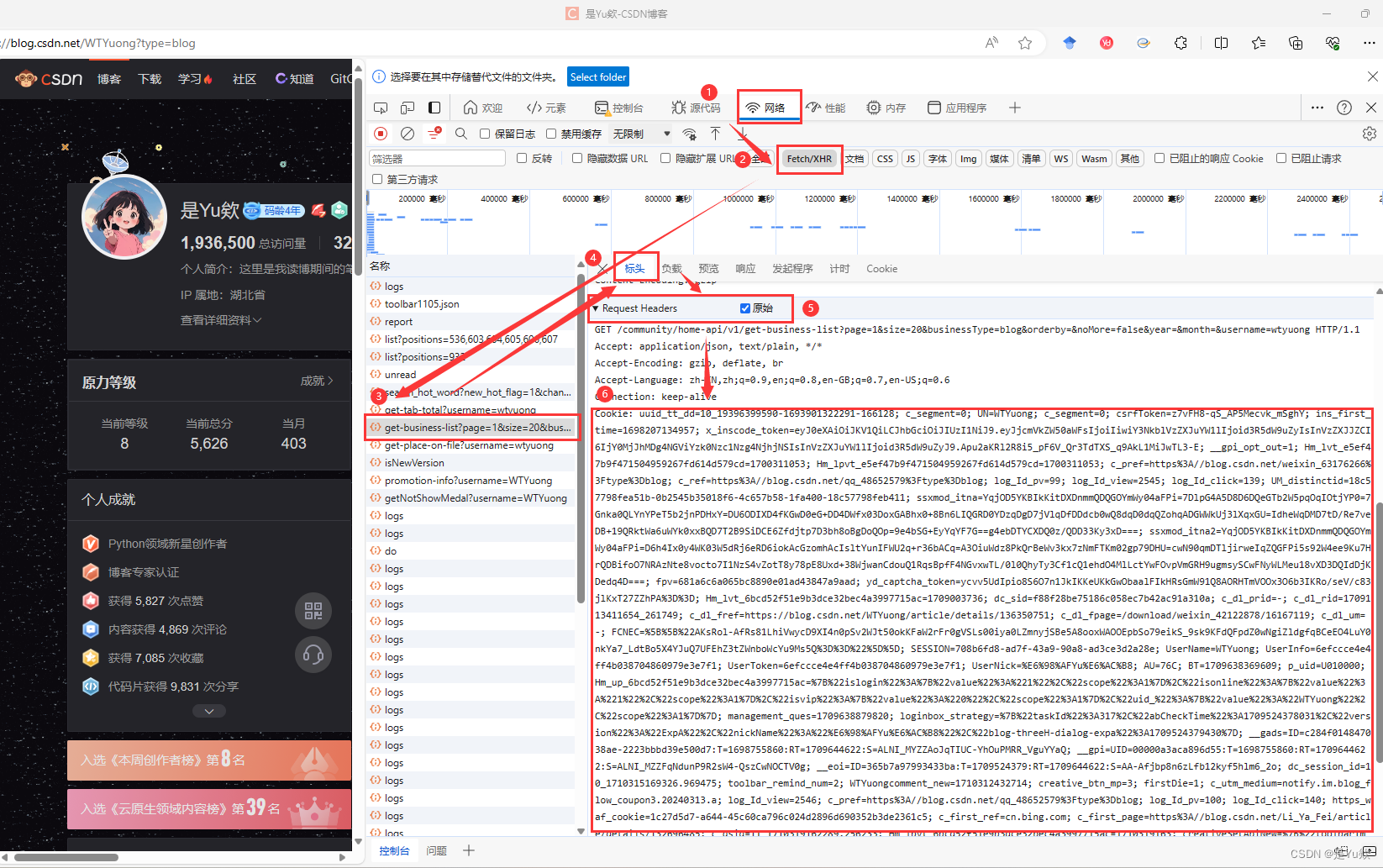
浏览器访问需要获取文章的博主首页地址,并且打开开发者工具快捷键F12
然后点击网络选项,我们在刷新页面可以看到发送的请求地址。
然后我们选择XHR过滤掉我们不需要看到请求,但是这里面也没有我们需要的请求,但是没关系,我们只要想一下什么情况下会发送请求获取文章呢?答案就是下滑底部后,会重新发送请求获取新的文章并且渲染到页面。
点击删除请求这样我们下拉就可以清晰看到请求的接口数据
发现就是该接口发送的请求获取文章数据
2. 获取文章的接口
我们主要还是研究获取文章的接口
看请求的 url,是一个 GET 请求。
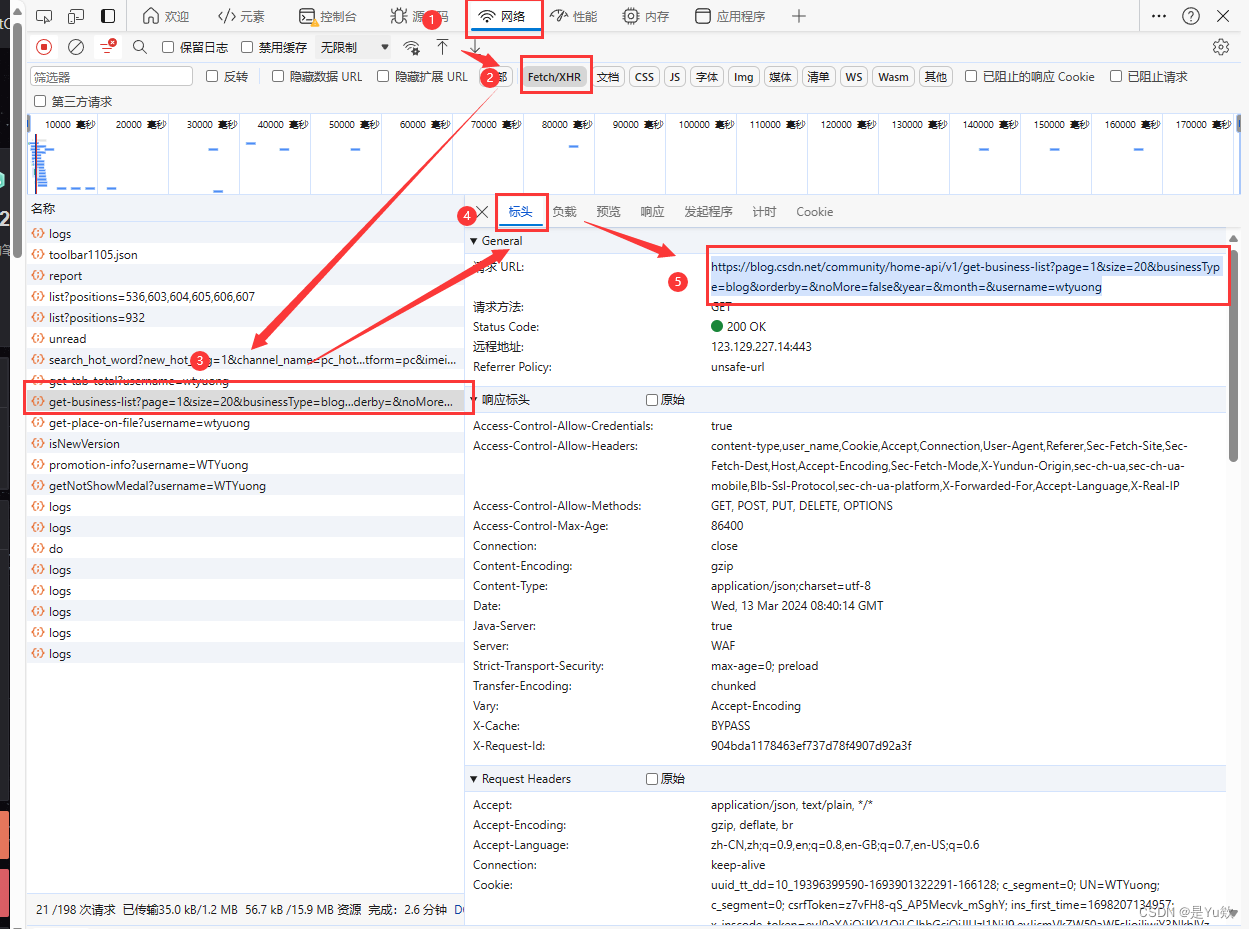
请求URL:
https://blog.csdn.net/community/home-api/v1/get-business-list
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=wtyuong
这个接口也比较简单只需要携带4个参数:
- 页码:page 第几页
- 页数:size 页码展示的条数
- 用户名称:username 需要查询的博主名(csdn id)
- 业务类型:businessType 默认使用 blog 这个类型对应
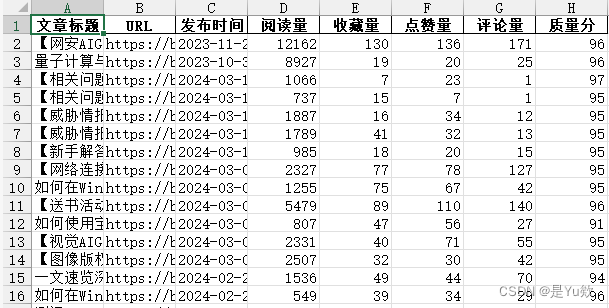
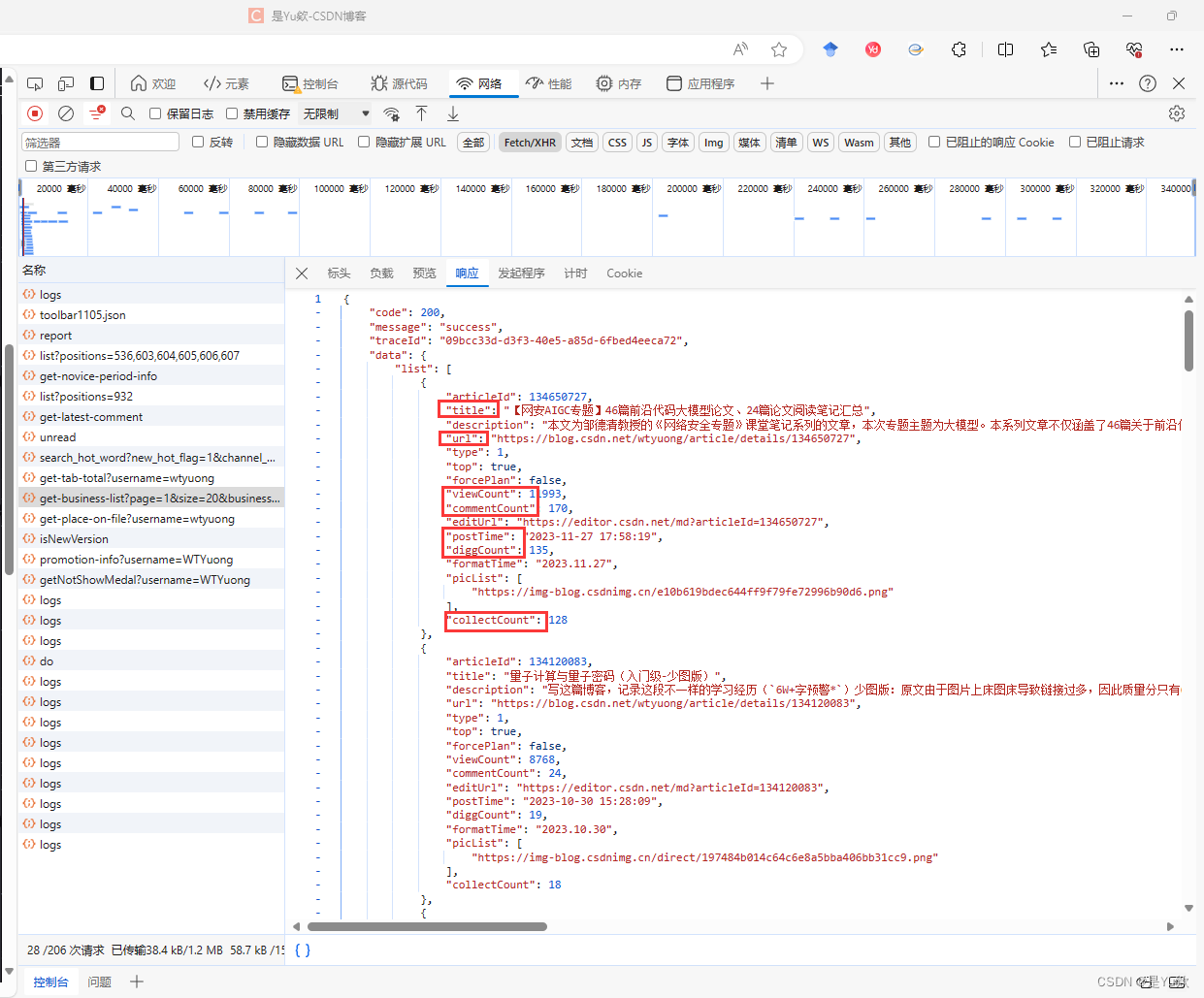
分析响应体:可以返回每篇文章的地址、阅读量、评论量等数据。
['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount']
['文章标题', 'URL', '发布时间', '阅读量', '收藏量', '点赞量', '评论量']
3. 接口测试(更新重点)
用ApiPost这个软件来进行接口测试
发现实际上,如果只发送url是会报错的,提示:请进行安全验证
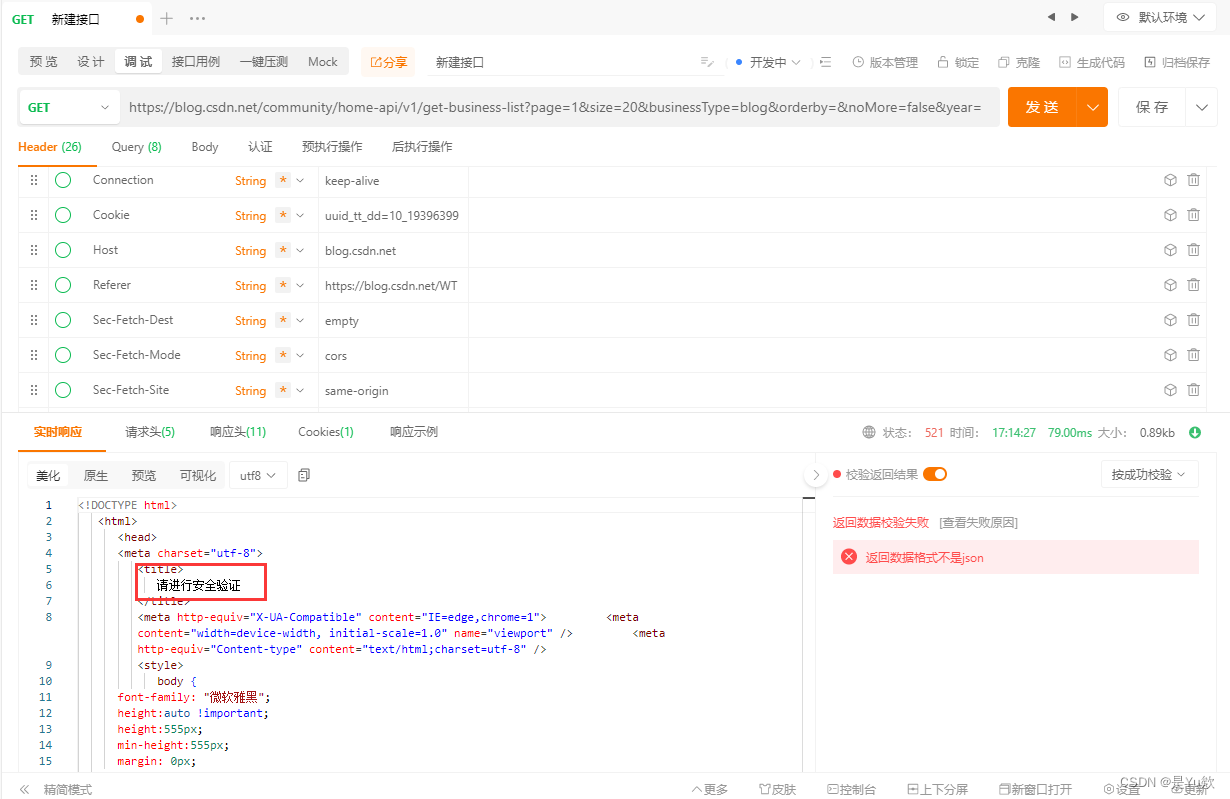
服务器要求进行“安全验证”以继续访问。这通常是网站的防爬机制之一,用于识别和阻止自动化的访问尝试。面对这种情况,有几个可能的解决方案:
用户代理(User-Agent):确保你的请求头中包含了一个合理的用户代理(User-Agent)字符串。有些网站会检查这个字段来判断请求是否来自真实的浏览器用户。尝试使用常见浏览器的用户代理字符串。
Cookies:某些网站要求请求携带有效的cookies来通过安全验证。你可以先手动访问该网站,通过浏览器获取到有效的cookies,并在你的爬虫请求中携带这些cookies。
处理JavaScript挑战:如果网站使用JavaScript生成动态内容或执行安全验证,你可能需要使用Selenium或Puppeteer这类工具,它们可以模拟真实的浏览器环境,执行JavaScript代码,并处理复杂的交互。
验证码识别:如果需要验证码验证,你可能需要集成验证码识别服务(如Google reCAPTCHA解决方案)或使用OCR(光学字符识别)技术尝试自动识别和填写验证码,虽然这可能面临法律和道德问题。
频率限制:确保你的请求频率不要太高,高频率的请求更容易触发网站的安全防护机制。尝试降低请求频率,或者在连续的请求之间增加延时。
经过测试,请求头只需要包括Cookies、Referer参数即可。
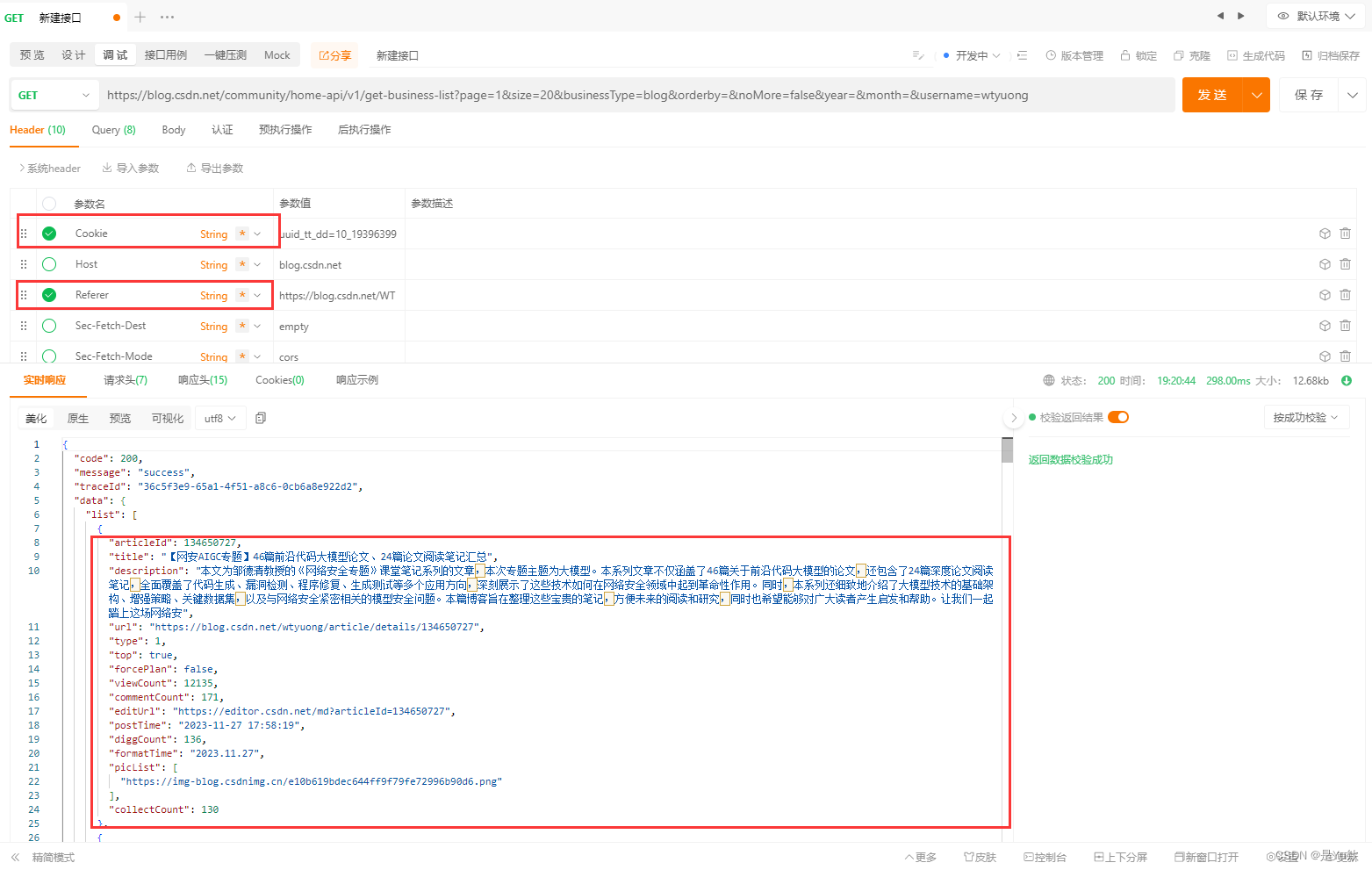
nice!
关于如何获取cookie:
三、查询质量分
流程和上述一样
1. 前期准备
先去质量查询地址:https://www.csdn.net/qc
2. 获取文章的接口
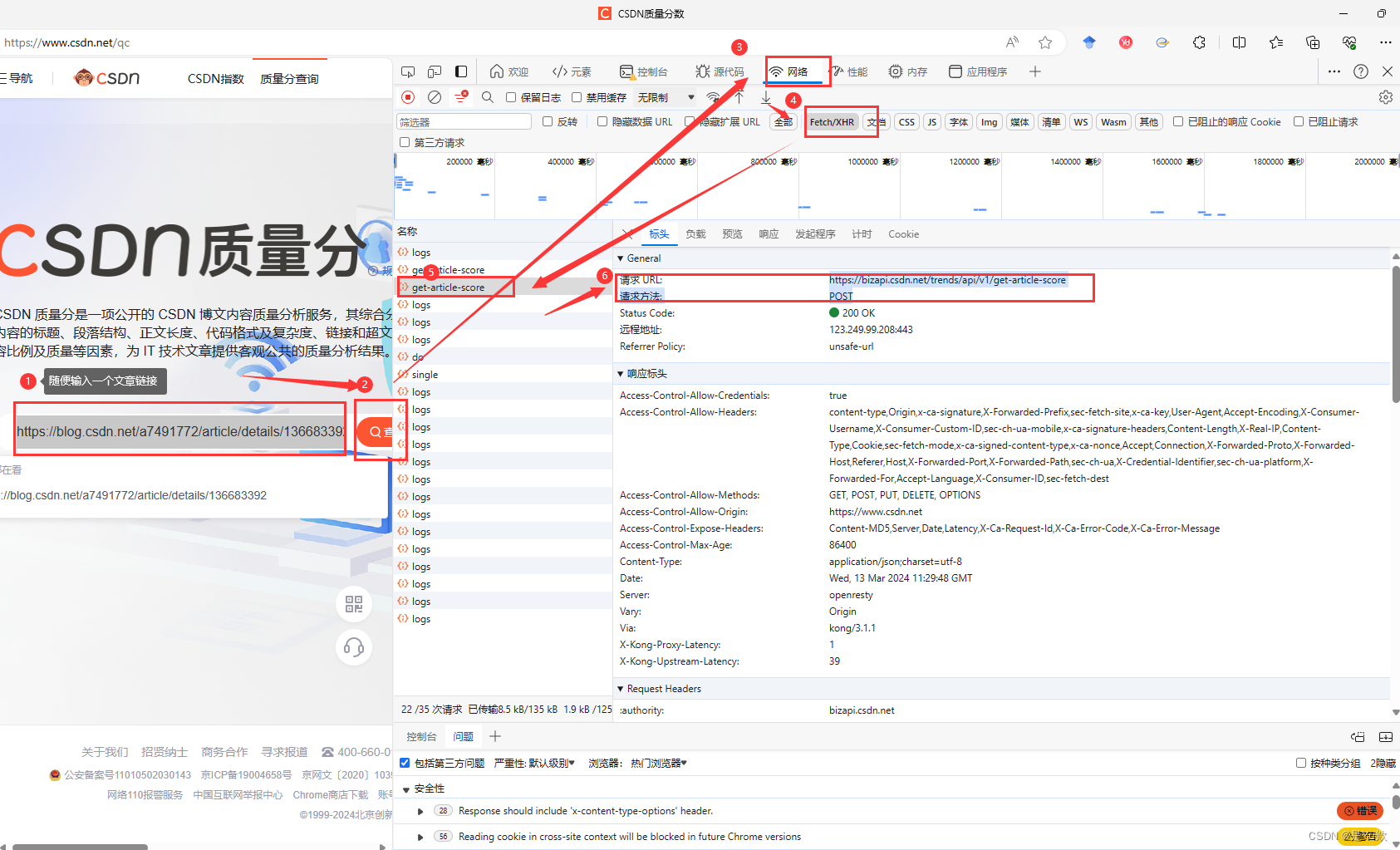
输入任意一篇文章地址进行查询,同时检查页面,在Network选项下即可看到调用的API的请求地址、请求方法、请求头、请求体等内容:
看请求的 url,是一个 POST 请求。
https://bizapi.csdn.net/trends/api/v1/get-article-score
POST 请求携带参数是 url。
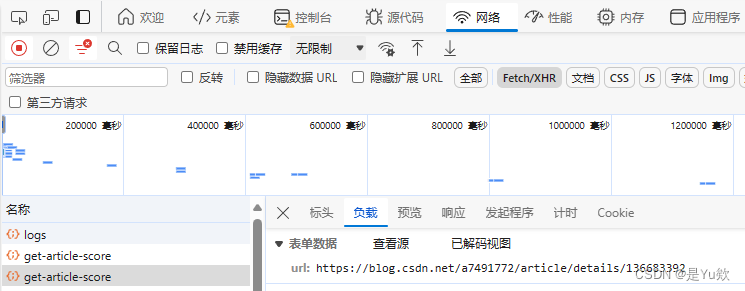
我们得到的响应数据:文章id、分数、消息、发布时间。
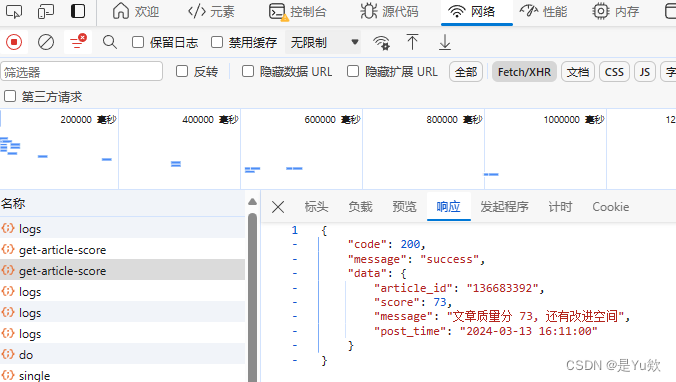
3. 接口测试
请求头里面很多参数是不需要的,我们用ApiPost这个软件来测试哪些是必要参数。
需要注意的是请求体的类型是form-data类型
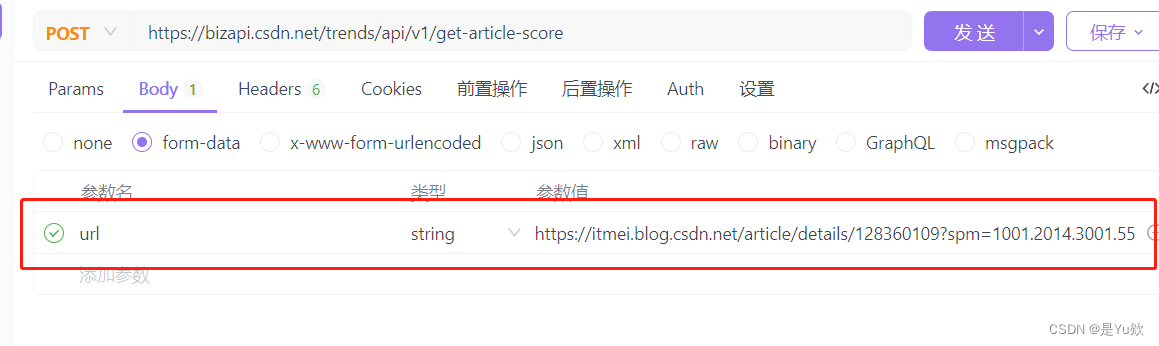
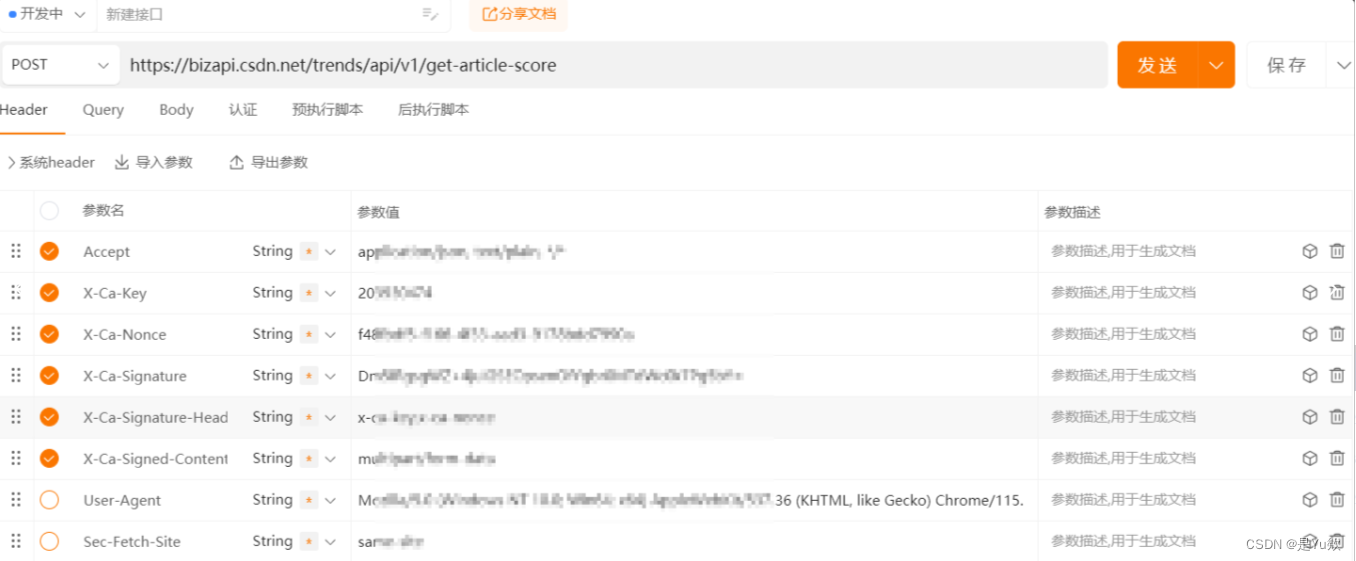
经过测试,请求头只需要下面这几个参数即可。
请求头分析
X-Ca-Key:使用自己浏览器的
X-Ca-Nonce:使用自己浏览器的
X-Ca-Signature:使用自己浏览器的
X-Ca-Signature-Headers:x-ca-key,x-ca-nonce
X-Ca-Signed-Content-Type:multipart/form-data
Accept :application/json, text/plain, /
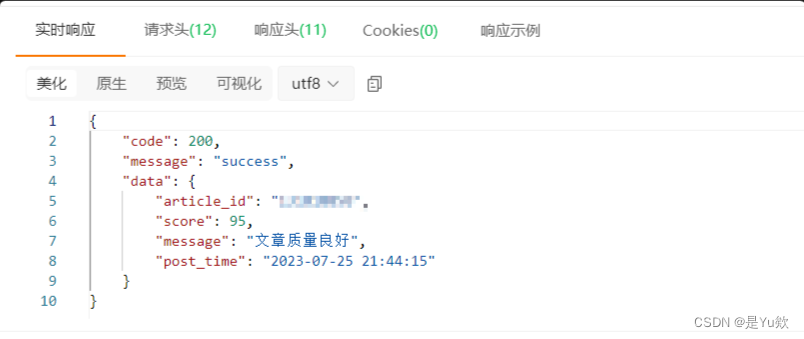
响应体分析:
- score:文章的分数
- message:给出的建议
四、python代码实现
1. 分步实现
为了便于理解,把程序分为2个部分:
- 批量获取文章信息,保存为excel文件;
- 从excel中读取文章url,查询质量分,再将质量分添加到excel。
2. 批量获取文章信息
# 批量获取文章信息并保存到excel
class CSDNArticleExporter:
def __init__(self, username, cookies, Referer, page, size, filename):
self.username = username
self.cookies = cookies
self.Referer = Referer
self.size = size
self.filename = filename
self.page = page
def get_articles(self):
url = "https://blog.csdn.net/community/home-api/v1/get-business-list"
params = {
"page": {self.page},
"size": {self.size},
"businessType": "blog",
"username": {self.username}
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Cookie': self.cookies, # Setting the cookies string directly in headers
'Referer': self.Referer
}
try:
response = requests.get(url, params=params, headers=headers)
response.raise_for_status() # Raises an HTTPError if the response status code is 4XX or 5XX
data = response.json()
return data.get('data', {}).get('list', [])
except requests.exceptions.HTTPError as e:
print(f"HTTP错误: {e.response.status_code} {e.response.reason}")
except requests.exceptions.RequestException as e:
print(f"请求异常: {e}")
except json.JSONDecodeError:
print("解析JSON失败")
return []
def export_to_excel(self):
df = pd.DataFrame(self.get_articles())
df = df[['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount']]
df.columns = ['文章标题', 'URL', '发布时间', '阅读量', '收藏量', '点赞量', '评论量']
# df.to_excel(self.filename)
# 下面的代码会让excel每列都是合适的列宽,如达到最佳阅读效果
# 你只用上面的保存也是可以的
# Create a new workbook and select the active sheet
wb = Workbook()
sheet = wb.active
# Write DataFrame to sheet
for r in dataframe_to_rows(df, index=False, header=True):
sheet.append(r)
# Iterate over the columns and set column width to the max length in each column
for column in sheet.columns:
max_length = 0
column = [cell for cell in column]
for cell in column:
try:
if len(str(cell.value)) > max_length:
max_length = len(cell.value)
except:
pass
adjusted_width = (max_length + 5)
sheet.column_dimensions[column[0].column_letter].width = adjusted_width
# Save the workbook
wb.save(self.filename)
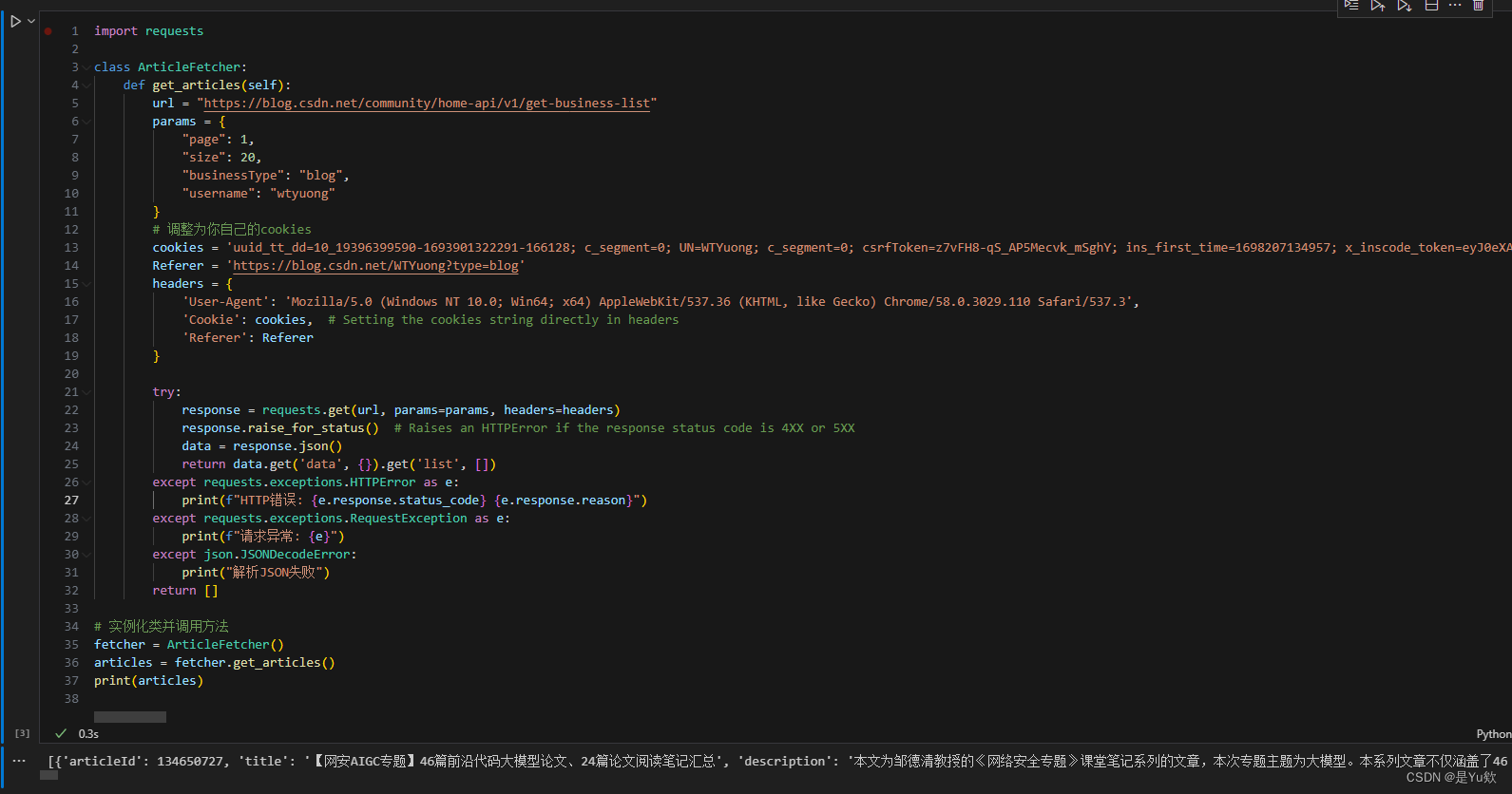
3. 从excel中读取文章url,查询质量分,再将质量分添加到excel
class ArticleScores:
def __init__(self, filepath):
self.filepath = filepath
@staticmethod
def get_article_score(article_url):
url = "https://bizapi.csdn.net/trends/api/v1/get-article-score"
# TODO: Replace with your actual headers
headers = {
"Accept": "application/json, text/plain, */*",
"X-Ca-Key": "203930474",
"X-Ca-Nonce": "b35e1821-05c2-458d-adae-3b720bb15fdf",
"X-Ca-Signature": "gjeSiKTRCh8aDv0UwThIVRITc/JtGJkgkZoLVeA6sWo=",
"X-Ca-Signature-Headers": "x-ca-key,x-ca-nonce",
"X-Ca-Signed-Content-Type": "multipart/form-data",
}
data = {"url": article_url}
try:
response = requests.post(url, headers=headers, data=data)
response.raise_for_status() # This will raise an error for bad responses
return response.json().get('data', {}).get('score', 'Score not found')
except requests.RequestException as e:
print(f"Request failed: {e}")
return "Error fetching score"
def get_scores_from_excel(self):
df = pd.read_excel(self.filepath)
urls = df['URL'].tolist()
scores = [self.get_article_score(url) for url in urls]
return scores
def write_scores_to_excel(self):
df = pd.read_excel(self.filepath)
df['质量分'] = self.get_scores_from_excel()
df.to_excel(self.filepath, index=False)
4. 全部代码
import json
import pandas as pd
from openpyxl import Workbook, load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
import math
import requests
# 批量获取文章信息并保存到excel
class CSDNArticleExporter:
def __init__(self, username, cookies, Referer, page, size, filename):
self.username = username
self.cookies = cookies
self.Referer = Referer
self.size = size
self.filename = filename
self.page = page
def get_articles(self):
url = "https://blog.csdn.net/community/home-api/v1/get-business-list"
params = {
"page": {self.page},
"size": {self.size},
"businessType": "blog",
"username": {self.username}
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Cookie': self.cookies, # Setting the cookies string directly in headers
'Referer': self.Referer
}
try:
response = requests.get(url, params=params, headers=headers)
response.raise_for_status() # Raises an HTTPError if the response status code is 4XX or 5XX
data = response.json()
return data.get('data', {}).get('list', [])
except requests.exceptions.HTTPError as e:
print(f"HTTP错误: {e.response.status_code} {e.response.reason}")
except requests.exceptions.RequestException as e:
print(f"请求异常: {e}")
except json.JSONDecodeError:
print("解析JSON失败")
return []
def export_to_excel(self):
df = pd.DataFrame(self.get_articles())
df = df[['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount']]
df.columns = ['文章标题', 'URL', '发布时间', '阅读量', '收藏量', '点赞量', '评论量']
# df.to_excel(self.filename)
# 下面的代码会让excel每列都是合适的列宽,如达到最佳阅读效果
# 你只用上面的保存也是可以的
# Create a new workbook and select the active sheet
wb = Workbook()
sheet = wb.active
# Write DataFrame to sheet
for r in dataframe_to_rows(df, index=False, header=True):
sheet.append(r)
# Iterate over the columns and set column width to the max length in each column
for column in sheet.columns:
max_length = 0
column = [cell for cell in column]
for cell in column:
try:
if len(str(cell.value)) > max_length:
max_length = len(cell.value)
except:
pass
adjusted_width = (max_length + 5)
sheet.column_dimensions[column[0].column_letter].width = adjusted_width
# Save the workbook
wb.save(self.filename)
class ArticleScores:
def __init__(self, filepath):
self.filepath = filepath
@staticmethod
def get_article_score(article_url):
url = "https://bizapi.csdn.net/trends/api/v1/get-article-score"
# TODO: Replace with your actual headers
headers = {
"Accept": "application/json, text/plain, */*",
"X-Ca-Key": "203930474",
"X-Ca-Nonce": "b35e1821-05c2-458d-adae-3b720bb15fdf",
"X-Ca-Signature": "gjeSiKTRCh8aDv0UwThIVRITc/JtGJkgkZoLVeA6sWo=",
"X-Ca-Signature-Headers": "x-ca-key,x-ca-nonce",
"X-Ca-Signed-Content-Type": "multipart/form-data",
}
data = {"url": article_url}
try:
response = requests.post(url, headers=headers, data=data)
response.raise_for_status() # This will raise an error for bad responses
return response.json().get('data', {}).get('score', 'Score not found')
except requests.RequestException as e:
print(f"Request failed: {e}")
return "Error fetching score"
def get_scores_from_excel(self):
df = pd.read_excel(self.filepath)
urls = df['URL'].tolist()
scores = [self.get_article_score(url) for url in urls]
return scores
def write_scores_to_excel(self):
df = pd.read_excel(self.filepath)
df['质量分'] = self.get_scores_from_excel()
df.to_excel(self.filepath, index=False)
if __name__ == '__main__':
total = 10 #已发文章总数量
# TODO:调整为你自己的cookies,Referer,CSDNid, headers
cookies = 'uuid_tt_dd=10' # Simplified for brevity
Referer = 'https://blog.csdn.net/WTYuong?type=blog'
CSDNid = 'WTYuong'
t_index = math.ceil(total/100)+1 #向上取整,半闭半开区间,开区间+1。
# 获取文章信息
# CSDNArticleExporter("待查询用户名", 2(分页数量,按总文章数量/100所得的分页数),总文章数量仅为设置为全部可见的文章总数。
# 100(最大单次查询文章数量不大于100), 'score1.xlsx'(待保存数据的文件,需要和下面的一致))
for index in range(1,t_index): #文章总数
filename = "score"+str(index)+".xlsx"
exporter = CSDNArticleExporter(CSDNid, cookies, Referer, index, 100, filename) # Replace with your username
exporter.export_to_excel()
# 批量获取质量分
score = ArticleScores(filename)
score.write_scores_to_excel()