写在前面
本文看下es的nested嵌套对象相关内容。
1:es用了啥范式?
在关系型数据库中定义了6大数据库范式,即1,2,3,BC,4,5的NF(normal form),分别如下:
1NF:每个列都不可拆分,即都是原子的
2NF:在满足1NF的基础上,消除部分函数依赖
3NF:在满足2NF的基础上,消除传递函数依赖
BCNF:在满足3NF的基础上,消除主属性对于码的部分函数依赖和传递函数依赖(此时和非主键列没有关系)
4NF:在满足BCNF的基础上,消除表内的多对多关系
5NF:略
数据库范式的目的在于减少更新的复杂度,以及降低磁盘的存储空间。其中对于第二个问题存储设备目前非常廉价而且容量很大,所以不是什么问题了。对于第一个更新的复杂度问题会带来的查询效率变低的问题,因为需要更多的关联join。那么对于es来说它是使用了哪种范式呢?因为es的设计目标是快速查询,所以使用到是反范式,即冗余存储。比如如下的数据:

如果按照关系型数据库范式来设计,user的信息需要存储到单独的一张表中去,但是在es中就是在一个对象中来存储,对于这种存储,es支持非常方便和高效的查询:
- 准备数据
DELETE blog
# 设置blog的 Mapping
PUT /blog
{
"mappings": {
"properties": {
"content": {
"type": "text"
},
"time": {
"type": "date"
},
"user": {
"properties": {
"city": {
"type": "text"
},
"userid": {
"type": "long"
},
"username": {
"type": "keyword"
}
}
}
}
}
}
# 插入一条 Blog 信息
PUT blog/_doc/1
{
"content":"I like Elasticsearch",
"time":"2019-01-01T00:00:00",
"user":{
"userid":1,
"username":"Jack",
"city":"Shanghai"
}
}
- 查询
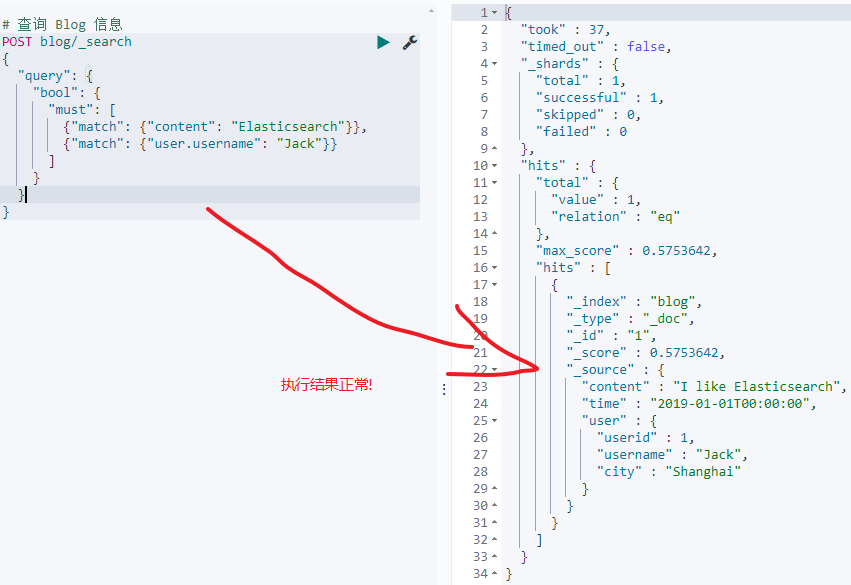
# 查询 Blog 信息
POST blog/_search
{
"query": {
"bool": {
"must": [
{"match": {"content": "Elasticsearch"}},
{"match": {"user.username": "Jack"}}
]
}
}
}
我们再来看一个存储对象数组的例子:

- 准备数据
DELETE my_movies
# 电影的Mapping信息
PUT my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"properties" : {
"first_name" : {
"type" : "keyword"
},
"last_name" : {
"type" : "keyword"
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
# 写入一条电影信息
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
- 查询first_name为Keanu并且last_name为Hopper的文档信息
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
}
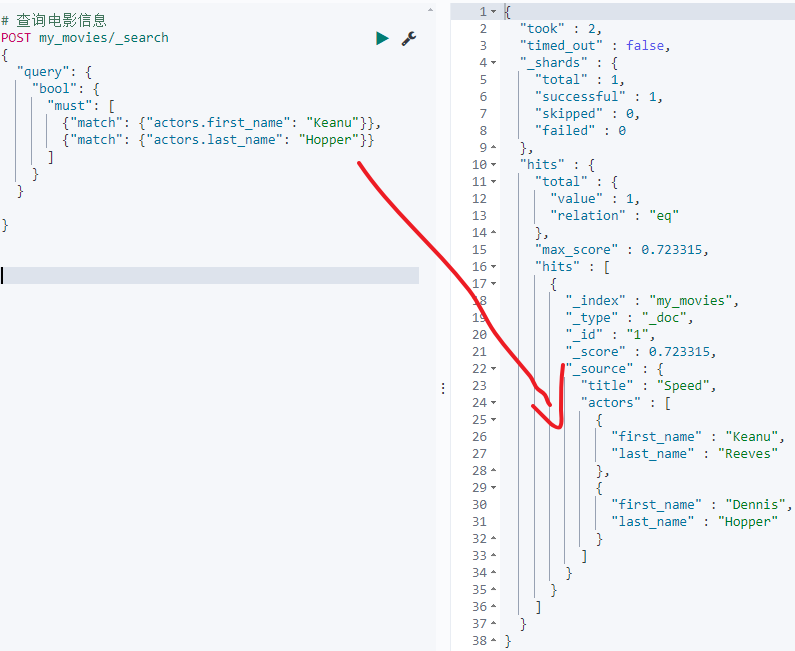
按照正常思维,应该查不到才对,但为什么查到了呢?这和es的数据存储方式有关系,对于数组es默认是按照一种扁平结构来存储的,如下:
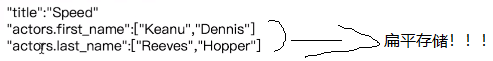
这种存储结构的好处是可以加快查询的速度,但坏处呢就是上例中反直觉结果。
所以如果能够让内部的对象也按照单独文档来存储,就能解决这个查询错误的问题了,而想要使用单独的文档来存储内部的对象,就需要用到es提供的nested对象功能,继续来看(作为本文的主题,必须单开一部分,还必须是一级标题😀😀😀)。
2:nested对象
nested是一种定义对象的数据类型,比如可通过如下方式来定义一个nested的类型:

在保存时会被保存为单独的文档,查询时通过join的方式来查询,当然此时会牺牲掉部分查询性能。
- 创建如下的mapping
DELETE my_movies
# 创建 Nested 对象 Mapping
PUT my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"type": "nested",
"properties" : {
"first_name" : {"type" : "keyword"},
"last_name" : {"type" : "keyword"}
}},
"title" : {
"type" : "text",
"fields" : {"keyword":{"type":"keyword","ignore_above":256}}
}
}
}
}
- 接着来插入测试数据
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
此时存储结构为红框中所示:

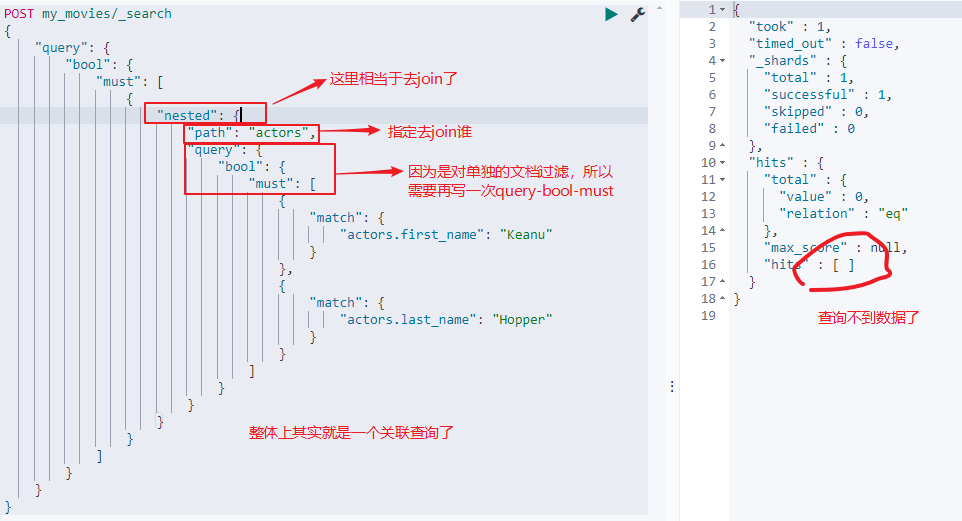
- 查询first_name为Keanu并且last_name为Hopper的文档信息
此时就查询不到了:
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "Keanu"
}
},
{
"match": {
"actors.last_name": "Hopper"
}
}
]
}
}
}
}
]
}
}
}
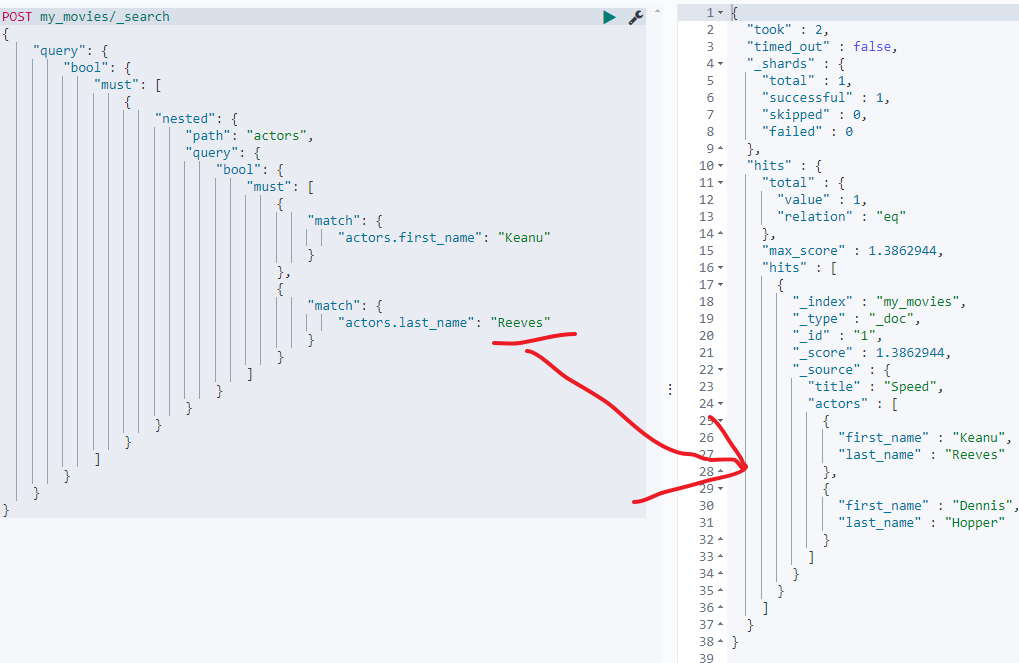
当然如果把"actors.last_name": "Hopper"改为Reeves是能查出来数据的:
写在后面
参考文章列表
关系型数据库MySQL及其优化 。