目录
一、缓冲区
二、C库函数的实现
一、缓冲区
缓冲区本质就是一块内存,而缓冲区存在的意义本质是提高使用者(用户)的效率【把缓冲区理解成寄送包裹的菜鸟驿站】
缓冲区的刷新策略
1. 无缓冲(立即刷新)
2. 行缓冲(行刷新)
3. 全缓冲(缓冲区满了,再刷新) ---》 进程退出属于全刷新的一种
4. 特殊清空:用户强制刷新
显示器文件一般采用行刷新,磁盘上的文件一般采用全刷新
现象:
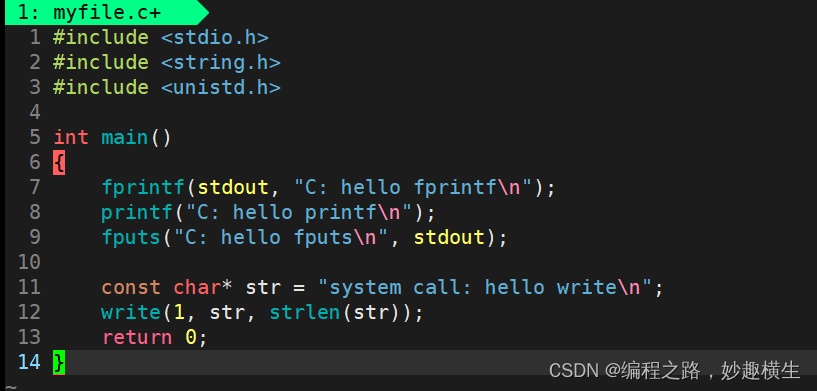


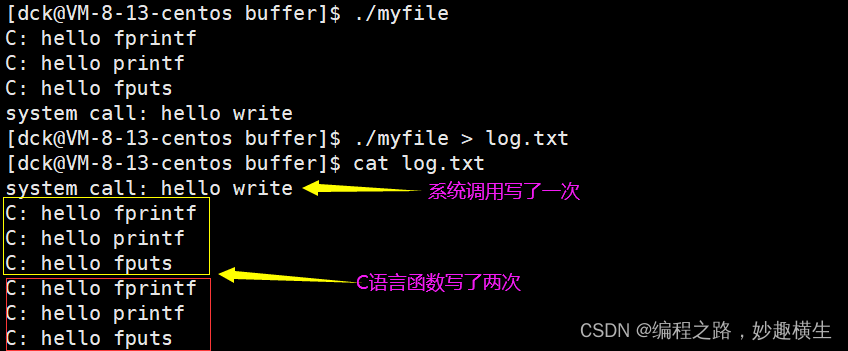
如何理解上述现象呢???
1.首先,显示器文件刷新方式是行刷新,且fork之前所有的代码都带\n, 所以fork之前,所有代码都被刷新了!而重定向到log.txt, 本质是访问了磁盘文件,刷新方式从行缓冲变成了全缓冲!这意味着缓冲区变大,实际写入的数据不足以把缓冲区写满,fork执行时,数据依然在缓冲区中!
2. 而我们发现,无论如何, 系统调用只打印了一次,而加了fork之后,重定向到文件中的函数打印了两次,因为这些函数底层封装的是write系统调用,这就说明目前我们所说的缓冲区和操作系统没有关系, 只能和C语言有关系! 我们日常用的最多的缓冲区就是C语言提供的缓冲区!
3.C/C++提供的缓冲区,里面保存的是用户的数据,属于当前进程的运行时自己的数据;而如果通过系统调用把数据写入到了OS内部,那么数据就不属于用户了!
4.当进程退出时,要刷新缓冲区,刷新缓冲区也属于写入操作,而fork创建子进程后,父子进程任何一方要对数据写入时,都要发生写时拷贝,所以数据出现两份!而系统调用只有一份,是因为系统调用是在库之下的,不适用C语言提供的缓冲区,直接将数据写入了OS, 不属于进程了,所以不发生写时拷贝,数据只有1份!
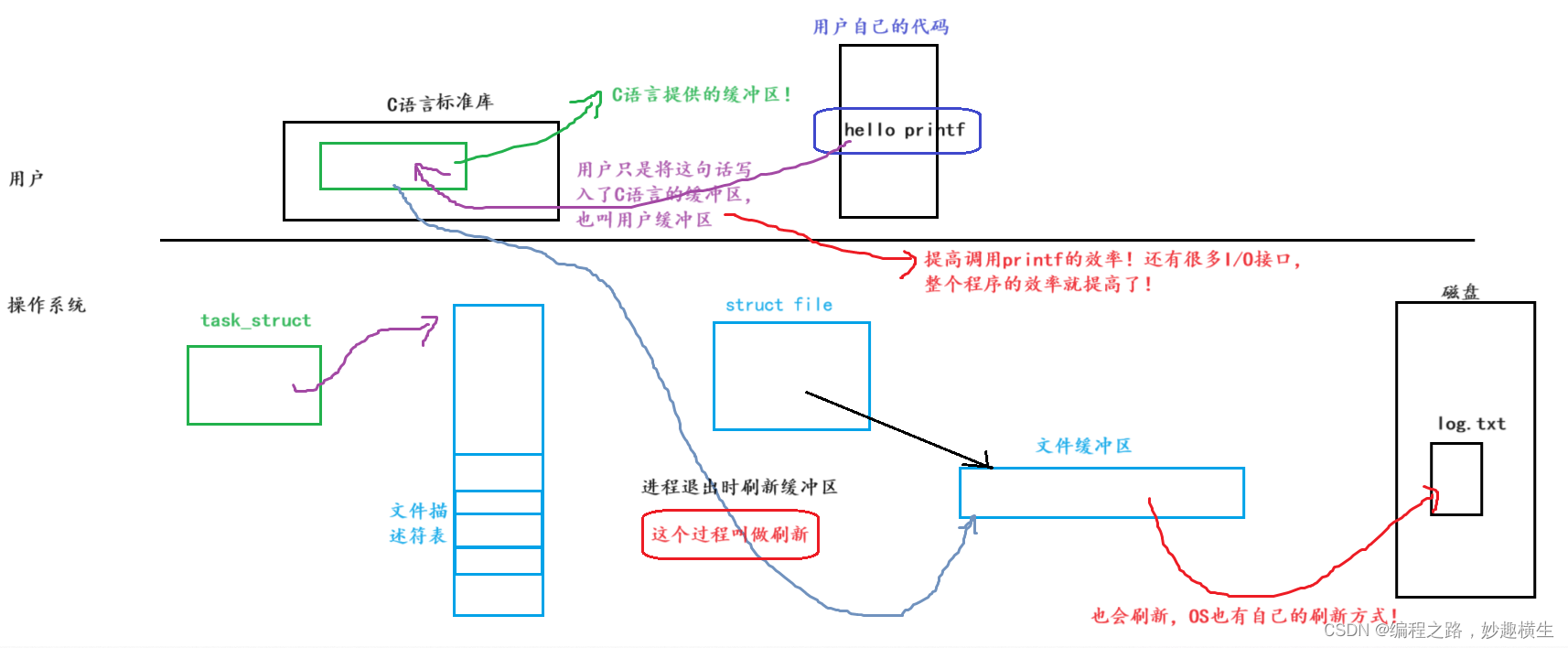
上述C语言提供的缓冲区位于FILE结构体内部!!!
二、C库函数的实现
#include "mystdio.h"
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <errno.h>
#include <stdlib.h>
#include <unistd.h>
#define DEL_MODE 0666
myFILE* my_fopen(const char *path, const char *mode)
{
int fd = 0;
int flag = 0;
if(strcmp(mode, "r") == 0)
{
flag |= O_RDONLY;
}
else if(strcmp(mode, "w") == 0)
{
flag |= (O_CREAT | O_WRONLY | O_TRUNC);
}
else if(strcmp(mode, "a") == 0)
{
flag |= (O_CREAT | O_WRONLY | O_APPEND);
}
else
{
//do nothing
}
if(flag & O_CREAT)
{
fd = open(path, flag, DEL_MODE);
}
else
{
fd = open(path, flag);
}
if(fd < 0)
{
errno = 2;
return NULL;
}
myFILE* fp = (myFILE*)malloc(sizeof(myFILE));
if(!fp)
{
errno = 3;
return NULL;
}
fp->flag = FLUSH_LINE;
fp->end = 0;
fp->fileno = fd;
return fp;
}
int my_fwrite(const char* s, int num, myFILE* stream)
{
memcpy(stream->buffer+stream->end, s, num);
stream->end += num;
//判断是否需要刷新
if((stream->flag & FLUSH_LINE) && stream->end > 0 && stream->buffer[stream->end-1] == '\n')
{
my_fflush(stream);
}
return num;
}
int my_fflush(myFILE* stream)
{
if(stream->end > 0)
{
write(stream->fileno, stream->buffer, stream->end);
//fsync(stream->fileno); //把数据刷新到内核中
stream->end = 0;
}
return 0;
}
int my_fclose(myFILE* stream)
{
my_fflush(stream);
return close(stream->fileno);
}
![三. 操作系统 (6分) [理解|计算]](https://img-blog.csdnimg.cn/direct/18d2bbd4478341e0aa06f19bbf5be332.png)