微服务架构的一个非常明显的特征就是一个服务所拥有的数据只能通过这个服务的API来访问。通过这种方式来解耦,这样就会带来查询问题。以前通过join就可以满足要求,现在如果需要跨多个服务集成查询就会非常麻烦。
解决思路
下面提供几个思路仅供参考
表字段冗余
想必大家已经很熟悉,几乎每天都会打交道,不用多讲。
需要指出的是冗余字段不能太多,建议控制在2-4个左右。否则会出现数据更新不一致问题,一旦冗余字段有改动,极容易产生脏数据。
解决思路
建立同步机制,必要时采取人工补偿措施。
所以,合理的字段冗余是润滑剂,减少join关联查询,让数据库执行性能更高更快。
聚合服务封装查询
简单来说,就是把不同服务的数据统一组装在一个新的服务里做聚合,对外提供统一入口API接口查询。通俗来说下,就是以前在同一个数据库里面的表之间使用join来关联,现在可能这些表不在同一个数据库上了,怎么办,可以把每一个数据库里面的数据查询出来,最后使用java等语言把最终需要的结果拼装起来。反正是需要最终的结果,没法join了,用java来拼呗。
聚合服务的数据组装是以API接口调用来实现,一般不建议直连数据库连表查询。这样做的好处是减少服务间调用次数以及查询库表压力。
在实际的业务开发中,我们经常碰到类似的需求,而聚合服务不失为一种较彻底的服务解耦实现方式。
表视图查询
如果涉及到不同数据库表之间的join查询,可以在其中某一数据库的表上建立视图(view)关系,这种方式非常高效,只需要开发一个简单接口对外提供服务就可以了,而且省去聚合服务带来调用、查询、聚合的复杂性。
前提条件
数据库需要部署在同一台服务器上
数据库账户密码必须相同,也就是在同一个schema下
另外表视图查询这种方式,是一种紧耦合的设计方式,不利于程序扩展,除非你很确定将来业务变动不大,可以考虑使用。以笔者经验来看,不适合大规模使用。
多数据源查询
这种方式是一种比较技术化的思路,简单来说就是一个微服务配置多个数据库源(DataSource),进行数据源来回切换进行库表查询,以达到获取不同数据的目的。
实现思路
利用DynamicDataSource
利用Spring的AOP动态切换数据源
利用Spring的依赖注入方式管理Bean数据源对象
分库分表:使用数据库中间件
Sharding-Shpere
想必做过分库分表的同学对他一定不陌生,其出身来至当当开源项目sharding-jdbc。非常有限的跨库查询解决方案,目前在京东内部已经广泛使用。sharding-jdbc创始人张亮已加入京东,sharding-jdbc还在不停的迭代,目前更名为sharding-shpere,已经入Apache顶级项目,进行孵化,非常看好它。
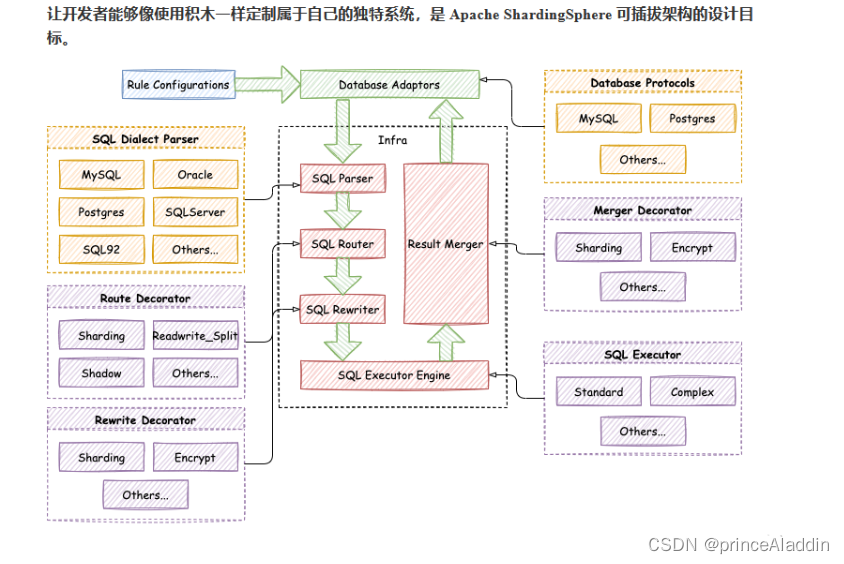
Mycat
一个彻底开源的,面向企业应用开发的大数据库集群,支持事务、ACID、可以替代MySQL的加强版数据库;一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群;一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server;结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品;一个新颖的数据库中间件产品。
总结:
在传统的单体架构的开发中,解决数据关联的问题并不难,通过关系型数据库中的关联查询功能,以及MyBatis的级联功能即可实现。
但是在分布式微服务中,整个系统都被拆分成了一个个单独的模块,每个模块也都是使用的单独的数据库。这种情况下,又如何解决不同模块之间数据关联问题呢?
事实上,分布式微服务是非常复杂的,无论是系统架构,还是数据结构设计,都没有一个统一的方案,因此根据实际情况进行确定即可,对于数据关联的跨库查询,事实上也有很多方法,在网上有如下思路:
数据冗余法
远程连接表
数据复制
使用非关系型数据库
…
下面分享一个简单的分布式微服务跨库查询操作,大家可以参考一下。
我们还是从一对多,多对多的角度来解决这个问题。
在继续往下看之前,我想先介绍一下这次的示例中所使用的组件:
Spring Cloud 2022.0.0和Spring Cloud Alibaba 2022.0.0.0-RC1
MyBatis-Plus作为ORM框架
Dynamic Datasource作为多数据源切换组件
Nacos作为注册中心
MySQL数据库
OpenFeign远程调用
因此,在往下看之前,需要先掌握上述这些组件的使用,本文不再赘述。
之前都是使用MyBatis作为ORM框架,而MyBatis-Plus可以视作其升级版,省去了我们写繁杂的Mapper.xml文件的步骤,上手特别简单。
MyBatis-Plus官方文档:传送门
Dynamic Datasource官方文档:传送门
单体架构中数据结构关联的操作方式:传送门
Maven多模块项目配置:传送门
Jackson注解过滤字段:传送门
将上述所有前置内容掌握之后,再来往下看最好。
2,跨库操作解决思路
我们从数据的联系形式,即一对多和多对多这两个角度依次进行分析。
(1) 一对多
一对多事实上比较好解决,这里我使用字段冗余 + 远程调用的方式解决。
这里以订单(Order)和用户(User)为例,订单对象中通常要包含用户关系,一个用户会产生多个订单,因此用户和订单构成了一对多的关系。
在单体架构中,我们很容易想到设计成这样:
这样,在查询订单的时候,可以通过关联查询的方式得到用户字段信息。
但是在分布式微服务中,用户和订单模块被拆分开来,两者的数据库也分开了,无法使用关联查询了,怎么办呢?
这时,我们可以在订单类中,冗余一个userId字段,可以直接从数据库取出,再通过远程调用的方式调用用户模块,用这个userId去得到用户对象,最后组装即可。
这样,订单服务查询订单对象,可以分为如下几步:
先直接从数据库取出订单对象,这样上述Order类中的id、name和userId都可以直接从数据库取出
然后拿着这个userId的值去远程调用用户服务得到用户对象,填充到user字段
与此同时,我们还可以注意一下细节:
将Order对象返回给前端时,可以过滤掉冗余字段userId,节省流量,通过Jackson注解可以实现
前端若要将Order对象作为参数传递给后端,则无需带着user字段内容,这样前端传来后可以直接丢进数据库,并且更加简洁
(2) 多对多
我们知道,多对多通常是以搭桥表方式实现关联。
在此我们增加一个商品类(Product),和订单类构成多对多关系,即需要查询一个订单中包含的所有商品,还需要查询这个商品被哪些订单包含。
在传统单体架构中,我们如下设计:
那么在分布式微服务中,数据库分开的情况下,这个搭桥表order_product放在哪呢?
可以将其单独放在一个数据库中,这个数据库在这里称之为搭桥表数据库。
这样,比如说订单服务查询订单的时候,可以分为如下几步:
先直接从订单数据库查询出订单信息,这样Order类中的id、name和userId就得到了
然后从搭桥表数据库去查询和这个订单关联的商品id,这样就得到了一个商品id列表
用这个商品id列表去远程调用商品服务,查询到每个id对应的商品对象得到一个商品对象列表
将商品列表组装到Order中的products字段中
那么反过来,商品服务也是通过一样的方式得到订单列表并组装。
可见,这两个多对多模块,有下列细节:
需要用到两个数据库,因此需要配置多数据源
两者需要暴露批量id查询的接口,但是批量id查询的时候,要注意死循环问题,这个我们在下面代码中具体来看
(3) 总结
可见上述解决数据关联的方式,都是要通过远程调用的方式来实现,这样符合微服务中职责单一原则,不过缺点是网络性能不是很好。
但是,这种方式解决规模不是特别复杂的项目已经足够了。
整体的类图和数据库如下:
那么下面,我们就来实现一下。
3,代码实现
(1) 环境配置
在写代码之前,我们先要在本地搭建并运行好MySQL和Nacos注册中心,这里我已经在本地通过Docker的方式部署好了,大家可以先自行部署。
然后在这里,整个工程模块组织如下:
存放全部实体类的模块,是普通Maven项目,被其它模块依赖
远程调用层,是普通Maven项目,其它服务模块依赖这个模块进行远程调用
订单服务模块,是Spring Boot项目
商品服务模块,是Spring Boot项目
用户服务模块,是Spring Boot项目
我们知道服务提供者和服务消费者在整个分布式微服务中是非常相对的概念,而服务消费者是需要进行远程调用的,这样每个服务消费者都要引入OpenFeign依赖并注入等等,因此我们可以 单独把所有的消费者的远程调用层feignclient抽离出来,作为这个远程调用模块。
在最后我会给出项目的仓库的地址,大家可以在示例仓库中自行查看每个模块的配置文件和依赖配置。
(2) 数据库的初始化
在MySQL中通过以下命令,创建如下数据库:
create database `db_order`;
create database `db_product`;
create database `db_user`;
create database `db_bridge`;
上述db_bridge就是专门存放搭桥表的数据库。
然后依次初始化三个数据库。
db_order数据库:
-- 订单数据库
drop table if exists `order_info`;
create table `order_info`
(
`id` int unsigned auto_increment,
`name` varchar(16) not null,
`user_id` int unsigned not null,
primary key (`id`)
) engine = InnoDB
default charset = utf8mb4;
-- 测试数据
insert into `order_info` (`name`, `user_id`)
values ('订单1', 1), -- id:1~4
('订单2', 1),
('订单3', 2),
('订单4', 3);
db_product数据库:
-- 商品数据库
drop table if exists `product`;
create table `product`
(
`id` int unsigned auto_increment,
`name` varchar(32) not null,
primary key (`id`)
) engine = InnoDB
default charset = utf8mb4;
-- 初始化测试数据
insert into `product` (`name`)
values ('商品1'), -- id:1~3
('商品2'),
('商品3');
db_user数据库:
-- 用户数据库
drop table if exists `user`;
create table `user`
(
`id` int unsigned auto_increment,
`username` varchar(16) not null,
primary key (`id`)
) engine = InnoDB
default charset = utf8mb4;
-- 初始化数据
insert into `user` (`username`)
values ('dev'), -- id:1~3
('test'),
('admin');
db_bridge数据库:
-- 多对多关联记录数据库
drop table if exists `order_product`;
-- 订单-商品多对多关联表
create table `order_product`
(
`order_id` int unsigned,
`product_id` int unsigned,
primary key (`order_id`, `product_id`)
) engine = InnoDB
default charset = utf8mb4;
-- 初始化测试数据
insert into `order_product`
values (1, 1),
(1, 2),
(2, 1),
(2, 2),
(3, 2),
(3, 3),
(4, 1),
(4, 2),
(4, 3);
(3) 实体类的定义
所有的实体类存放在db-entity模块中。
首先我们还是定义一个结果类Result<T>专用于返回给前端:
package com.gitee.swsk33.dbentity.model;
import lombok.Data;
import java.io.Serializable;
/**
* 返回给前端的结果对象
*/
@Data
public class Result<T> implements Serializable {
/**
* 是否操作成功
*/
private boolean success;
/**
* 消息
*/
private String message;
/**
* 数据
*/
private T data;
/**
* 设定成功
*
* @param message 消息
*/
public void setResultSuccess(String message) {
this.success = true;
this.message = message;
this.data = null;
}
/**
* 设定成功
*
* @param message 消息
* @param data 数据
*/
public void setResultSuccess(String message, T data) {
this.success = true;
this.message = message;
this.data = data;
}
/**
* 设定失败
*
* @param message 消息
*/
public void setResultFailed(String message) {
this.success = false;
this.message = message;
this.data = null;
}
}
然后就是数据库对象了。
1. 用户类
package com.gitee.swsk33.dbentity.dataobject;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import lombok.Data;
/**
* 用户类
*/
@Data
public class User {
/**
* 用户id
*/
@TableId(type = IdType.AUTO)
private Integer id;
/**
* 用户名
*/
private String username;
}
2. 商品类
package com.gitee.swsk33.dbentity.dataobject;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import lombok.Data;
import java.util.List;
/**
* 商品表
*/
@Data
public class Product {
/**
* 商品id
*/
@TableId(type = IdType.AUTO)
private Integer id;
/**
* 商品名
*/
private String name;
/**
* 所有购买了这个商品的订单(需组装)
*/
@TableField(exist = false)
private List<Order> orders;
}
可见这里用了@TableField注解将orders字段标注为非数据库字段,因为这个字段是我们后续要手动组装的多对多字段。
3. 订单类
package com.gitee.swsk33.dbentity.dataobject;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import lombok.Data;
import java.util.List;
/**
* 订单类
*/
@Data
@JsonIgnoreProperties(allowSetters = true, value = {"userId"})
@TableName("order_info")
public class Order {
/**
* 订单id
*/
@TableId(type = IdType.AUTO)
private Integer id;
/**
* 订单名
*/
private String name;
/**
* 关联用户id(一对多冗余字段,不返回给前端,但是前端作为参数传递)
*/
private Integer userId;
/**
* 关联用户(需组装)
*/
@TableField(exist = false)
private User user;
/**
* 这个订单中所包含的商品(需组装)
*/
@TableField(exist = false)
private List<Product> products;
}
可见这里使用了@JsonIgnoreProperties过滤掉了冗余字段userId不返回给前端。
(4) 各个服务模块
基本上每个服务模块仍然是Spring Boot的四层架构中的三层,即dao、service和api。因此这里只讲关键性的东西,其余细节可以在文末示例仓库中看代码。
来看订单模块,定义数据库操作层OrderDAO如下:
package com.gitee.swsk33.dborder.dao;
import com.baomidou.dynamic.datasource.annotation.DS;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.gitee.swsk33.dbentity.dataobject.Order;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface OrderDAO extends BaseMapper<Order> {
/**
* 添加关联记录
*
* @param orderId 订单id
* @param productId 商品id
* @return 增加记录条数
*/
@Insert("insert into `order_product` values (#{orderId}, #{productId})")
@DS("bridge")
int insertRecord(int orderId, int productId);
/**
* 根据订单id查询其对应的所有商品id列表
*
* @param orderId 订单id
* @return 商品id列表
*/
@Select("select `product_id` from `order_product` where `order_id` = #{orderId}")
@DS("bridge")
List<Integer> selectProductIds(int orderId);
/**
* 删除和某个订单关联的商品id记录
*
* @param orderId 订单id
* @return 删除记录数
*/
@Delete("delete from `order_product` where `order_id` = #{orderId}")
@DS("bridge")
int deleteProductIds(int orderId);
}
由于继承了MyBatis-Plus的BaseMapper,因此基本的增删改查这里不需要写了,所以这里只需要写对搭桥表数据库中的操作,比如说获取这个订单中包含的商品id列表等等,也可见这里只获取id或者是传入id为参数对搭桥表进行增删查操作,并且这些方法标注了@DS切换数据源查询。
再来看Service层代码:
package com.gitee.swsk33.dborder.service.impl;
import com.gitee.swsk33.dbentity.dataobject.Order;
import com.gitee.swsk33.dbentity.dataobject.Product;
import com.gitee.swsk33.dbentity.dataobject.User;
import com.gitee.swsk33.dbentity.model.Result;
import com.gitee.swsk33.dbfeign.feignclient.ProductClient;
import com.gitee.swsk33.dbfeign.feignclient.UserClient;
import com.gitee.swsk33.dborder.dao.OrderDAO;
import com.gitee.swsk33.dborder.service.OrderService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderDAO orderDAO;
@Autowired
private UserClient userClient;
@Autowired
private ProductClient productClient;
@Override
public Result<Void> add(Order order) {
Result<Void> result = new Result<>();
// 先直接插入
if (orderDAO.insert(order) < 1) {
result.setResultFailed("插入失败!");
return result;
}
// 插入后,添加与之关联的商品多对多记录
for (Product each : order.getProducts()) {
orderDAO.insertRecord(order.getId(), each.getId());
}
result.setResultSuccess("插入完成!");
return result;
}
@Override
public Result<Void> delete(int id) {
Result<Void> result = new Result<>();
// 先直接删除
if (orderDAO.deleteById(id) < 1) {
result.setResultFailed("删除失败!");
return result;
}
// 然后删除关联部分
orderDAO.deleteProductIds(id);
result.setResultSuccess("删除成功!");
return result;
}
@Override
public Result<Order> getById(int id) {
Result<Order> result = new Result<>();
// 先查询订单
Order getOrder = orderDAO.selectById(id);
if (getOrder == null) {
result.setResultFailed("查询失败!");
return result;
}
// 远程调用用户模块,组装订单中的用户对象字段(一对多关联查询)
User getUser = userClient.getById(getOrder.getUserId()).getData();
if (getUser == null) {
result.setResultFailed("查询失败!");
return result;
}
getOrder.setUser(getUser);
// 远程调用商品模块,组装订单中关联的商品列表(多对多关联查询)
List<Integer> productIds = orderDAO.selectProductIds(id);
getOrder.setProducts(productClient.getByBatchId(productIds).getData());
result.setResultSuccess("查询成功!", getOrder);
return result;
}
@Override
public Result<List<Order>> getByBatchId(List<Integer> ids) {
Result<List<Order>> result = new Result<>();
// 先批量查询
List<Order> getOrders = orderDAO.selectBatchIds(ids);
// 组装其中的用户对象字段
for (Order each : getOrders) {
each.setUser(userClient.getById(each.getUserId()).getData());
}
// 由于批量查询目前专门提供给内部模块作为多对多关联查询时远程调用,因此这里不再对每个对象进行多对多查询,否则会陷入死循环
result.setResultSuccess("查询完成!", getOrders);
return result;
}
}
可以先看代码和注释,这里面已经写好了增删查记录的时候的流程和操作,包括查询多对多搭桥表中的id以及远程调用等等,远程调用代码这里不再赘述。
然后,将这些服务暴露为接口即可,反过来商品服务模块也是基本一样的思路。
上述有以下需要注意的地方:
将搭桥表的操作,即增加、查询和删除这个订单包含的商品id的操作,定义在了OrderDAO中,反过来在商品服务中,ProductDAO中也需要定义增加、查询和删除和这个商品所有关联的订单id的操作,具体可以看项目源码
在服务中编写了getByBatchId这个方法专用于模块远程调用查询多对多的对象,但是可见在这个方法中批量查询时,没有继续组装每个对象中包含的多对多对象,防止死循环
对于远程调用,需要注意的是远程调用层的代码和这些服务不在一个模块中,因此在模块主类上标注@EnableFeignClients注解启用远程调用功能时,还需要指定需要用到的远程调用的FeignClient类,否则会注入失败: