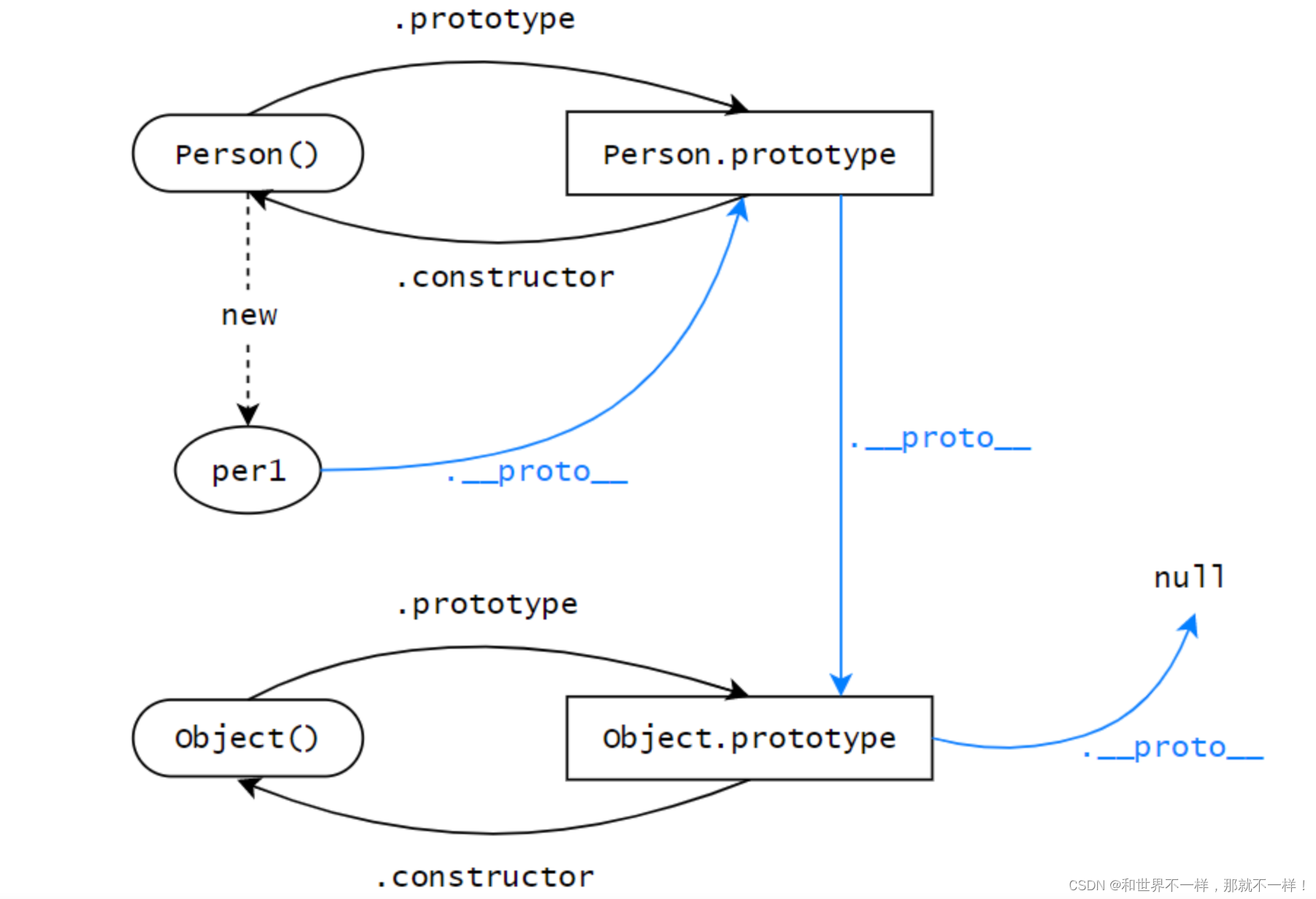
普通的哈希表增删查改的效率的确达到了令人满意的O(1),但是本质还是以空间换时间来实现的。并且哈希表中是直接存储数据的,应对一些海量数据处理的问题可能就会造成空间不足的问题。
加入现有40亿个无符号整形数字,设计一个算法来实现检测一个数字是否存在。40亿个无符号整形数字的大小大致有15G的体量,普通的内存是无法容纳这么大的文件的,因此不能通过直接的哈希映射来实现。
因此我们迫切需要设计一种能够节省空间的数据结构来实现目的。仔细想一想题目,判断存不存在,无非是一个两态的问题,是否可以把不同的状态设一个标识呢?0标识不在,1标识在是不是可以行得通。
如果我们让一个整数对应一个比特位,就可以节省很大空间了,那么现在只需要2^32-1个比特位就可以实现了(40亿整数有最大值,存在重复),通过计算现在只需要0.5GB的空间了,这绝对是一个很大的突破!
这种数据结构叫做位图
位图模拟实现源码:
https://gitee.com/chxchenhaixiao/test_c/tree/master/BitSet
位图的优缺点:
优点:通过比特位来映射数据,极大得节省了空间;不直接存储数据,提高了安全性。
缺点:只能够直接作用于整形数据,对于浮点型、字符串型、自定义类型等数据无法直接映射。因为这些数据类型得范围趋向于无穷,设置再多的比特位也无法完全标识所有数据。
实际中单纯得整形数据并不常见,常见的往往是字符串类型,既然无法直接用位图来实现,那么我们只能退而求其次,让每一个比特位能够对应多个数据,实现准确判断数据不存在的目的(存在可能是误判)。
从而衍生出布隆过滤器
那么什么是布隆过滤器呢?
布隆过滤器本质上是位图和哈希的结合,通过多个哈希函数得出多个哈希值,哈希值对应比特位。
虽然这样会导致存在的误判,但是也规避掉了很多不存在的查找。是一种高效的数据结构。
布隆过滤器模拟实现源码:
https://gitee.com/chxchenhaixiao/test_c/blob/master/BloomFitler/BloomFitler/BloomFitler.h
哈希切割,海量数据处理

精确算法:
借助哈希切割的思想
将2个大文件均拆解成相同个能够进入内存的小文件(不是平均分),读取其中一个文件中的数据,通过一个哈希函数可以得到一个哈希值n,n视作小文件的编号,将哈希值相等和近似数据存入一个小文件中;另一个文件同理。
最后只需要每次载入两个编号相同的小文件就可以得出部分答案。
由于小文件不是平均分的,可能存在某个小文件非常大不能载入内存的情况,此时可能需要对小文件再进行拆解。
每个小文件中应该有一个set对象来去重,避免小文件中的大量元素哈希冲突无法再切分的情况。