实验2:R入门2
一:实验目的与要求
1:熟悉和掌握R数据类型。
2:熟悉和掌握R语言的数据读写。
二:实验内容
1:R数据类型
【基本赋值】
Eg.1代码:
| x <- 8 x |

Eg.2代码:
| a = 'city' a |

【缺省值】
Eg.1代码:(1)生成向量z;(2)返回z的结果;(3)识别z的值是否有缺失值。
| z <- c(1:5,NA) z is.na(z) |

【查看对象类型】
Eg.1代码:创建3个不同类型的数据,展示3个辨别函数的区别,即mode<class<typeof。
| df <- data.frame(c1 = letters[1:3], c2 = 1:3, c3 = c(1,-1,3.0), stringsAsFactors = F) sapply(df, mode) sapply(df, class) sapply(df, typeof) |

【向量赋值】
Eg.1代码:用c()构建向量(左箭头)。
| x <- c(1,3,5,7,9) x |

Eg.2代码:将c()生成的数值向量赋值给y(右箭头)。
| c(1,3,5,7,9) -> y y |

Eg.3代码:将c()生成的字符向量赋值给z。
| z <- c("Male","Female","Female","Male","Male") z |

Eg.4代码:将c()生成的逻辑向量赋值给u。
| u=c(TRUE,FALSE,TRUE,FALSE,FALSE) u |

Eg.5代码:同时创建不同类型的向量。
| x1 <- c(1, 2, 3, 4) x2 <- c("a", "b","c","d") x3 <- c(TRUE, FALSE, FALSE, TRUE) x1 x2 x3 |

Eg.6代码:相同类型元素的向量创建。
| w <- c(1,3,4,5,6,7) length(w) mode(w) |

Eg.7代码:相同类型元素的向量创建。
| w1 <- c('张三','李四','王五') length(w1) mode(w1) |

Eg.8代码:相同类型元素的向量创建。
| w2 <- c(T,F,T) length(w2) mode(w2) |

Eg.9代码:不同类型元素的向量创建(强制执行类型转换)。
| w4 <- c(w,w1) w4 mode(w4) w5 <- c(w1,w2) w5 mode(w5) |

Eg.10代码:字符向量的paste()。
| v <- paste("x",1:5,sep="") v |

Eg.11代码:向量赋值的assign()。
| assign("w",c(1,3,5,7,9)) w |

【向量运算】
Eg.1代码:向量的乘法、除法、乘方运算。
| x <- c(1,3,5,7,9) c(1,3,5,7,9) -> y x*y x/y x^2 y^x |

Eg.2代码:向量的加法运算。
| c(1,3,5)+c(2,4,6,8,10) |

【产生有规则序列】
Eg.1代码:产生正则序列。
| (t <- 1:10) (r <- 5:1) 2*1:5 |

Eg.2代码:seq()产生有规则的各种序列。
| seq(1,10,2) seq(1,10) seq(10,1,-1) |

Eg.3代码:seq()产生规定长度数列。
| seq(1,by=2,length=10) |

Eg.4代码:rep()重复一个对象。
| rep(c(1,3),4) rep(c(1,3),each=4) rep(1:3,rep(2,3)) |

【向量的常见函数】
Eg.1代码:
| x <-c(1,3,5,7,9) length(x) min(x) range(x) |

【索引向量】
Eg.1代码:取出向量的某一个元素,通过赋值语句来改变一个或多个元素的值。
| x <- c(1,3,5) x[2] (c(1,2,3)+4)[2] x[2] <- 10 x x[c(1,3)] <- c(9,11) x |

Eg.2代码:以对向量进行逻辑运算。
| x <- c(1,3,5) x < 4 x[x<4] z <- c(-1,1:3,NA) z z[is.na(z)] <- 0 z z <- c(-1,1:3,NA) y <- z[!is.na(z)] y |

Eg.3代码:
| x <- c(2,4,6,8,1) x[c(1,3,5)] x[c(-2,-4)] x[c(TRUE,FALSE,TRUE,FALSE,TRUE)] |

Eg.4代码:
| names(x) <- c('one','two','three','four','five') x[c('one','three','four')] x[c(1,-1)] |

Eg.5代码:which函数,返回逻辑向量中为TRUE的位置。
| x <- c(2,4,6,8,1) which(x>3) |

Eg.6代码:which(min(x))和which(max(x))。
| which.min(x) which.max(x) |

【向量编辑】
Eg.1代码:向量编辑和向量扩展。
| x <- c(1, 2, 3, 4) (x <- c(x, c(5, 6, 7))) |

Eg.2代码:单个元素的删除和多个元素的删除。
| (x <- x[-1]) (x <- x[c(3:5)]) |

【矩阵创建】
Eg.1代码:
| matrix(data=NA,nrow=1,ncol=1,byrow=FALSE,dimnames=NULL) |

Eg.2代码:使用dimnames参数设置行和列的名称。
| (w <- seq(1:10)) (a <- matrix(w,nrow = 5,ncol = 2,byrow = T,dimnames = list(paste('r',1:5),paste('l',1:2)))) |

【矩阵转化成向量】
Eg.1代码:as.vector函数和转置矩阵t函数。
| x <- c(1:10) a <- matrix(x,ncol=2,nrow=5,byrow=T,dimnames = list(paste('r',1:5),paste('l',1:2))) b <- as.vector(a) (c <- t(a)) |

【矩阵索引】
Eg.1代码:
| x <- c(1:10) a <- matrix(x,ncol=2,nrow=5,byrow=F,dimnames = list(c("r1","r2","r3","r4","r5"),c("c1","c2"))) a a[2,1] a["r2","c1"] # 根据行列名称索引 a[1,] # 检索某行 a[,1] # 检索某列 a[c(3:5),] # 向量索引,检索多行 |

【矩阵编辑】
Eg.1代码:删除元素。
| (a5 <- a[-c(1:2),]) (a6 <- a[,-1]) |

【矩阵的行、列和维度】
Eg.1代码:dim函数返回维度。
| a_matrix <- matrix(1:10,nrow=5,ncol=2) dim(a_matrix) |

Eg.2代码:nrow函数返回行数,ncol函数返回列数。
| nrow(a_matrix) ncol(a_matrix) |

【数组创建】
Eg.1代码:
| arr <- array(data=NA,dim=c(1,2,3),dimnames=NULL) arr |

【数组索引】
Eg.1代码:
| x <- c(1:30) dim1 <- c("A1","A2","A3") dim2 <- c("B1","B2","B3","B4","B5") dim3 <- c("C1","C2") a <- array(x,dim=c(3,5,2),dimnames=list(dim1,dim2,dim3)) a[2,4,1] a["A2","B4","C1"] dim(a) |

【数据框创建】
Eg.1代码:向量组成数据框。
| my.datasheet <- data.frame(site=c('A','B','A','A','B'),season=c('winter','summer','summer','spring','fall'),pH=c(7.4,6.3,8.6,7.2,8.9)) my.datasheet |

Eg.2代码:矩阵转化成为数据框。
| (data_matrix <- matrix(1:8,c(4,2))) (data.frame(data_matrix)) |

【数据框索引】
Eg.1代码:列名称和列下标索引。
| iris$Sepal.Length iris[["Sepal.Length"]] iris[[2]] iris[,2] |

Eg.2代码:行下标检索。
| iris[1:2,] |

【数据框变量名称编辑】
Eg.1代码:names函数读取并编辑列名称。
| my.datasheet <- data.frame(site=c('A','B','A','A','B'),season=c('winter','summer','summer','spring','fall'),pH=c(7.4,6.3,8.6,7.2,8.9)) names(my.datasheet) names(my.datasheet)[1] <- 'type' names(my.datasheet) |

【数据框数据编辑】
Eg.1代码:rbin函数增加样本数据,cbin函数增加新的属性。
| data_iris <- data.frame(Sepal.Length=c(5.1,4.9,4.7,4.6),Sepal.Width=c(3.5,3.0,3.2,3.1),Petal.Length=c(1.4,1.4,1.3,1.5),Petal.Width=rep(0.2,4)) data_iris data_iris <- rbind(data_iris,list(5.0,3.6,1.4,0.2)) data_iris <- cbind(data_iris,Species=rep("setosa",5)) data_iris[,-1] data_iris[-1,] |

【列表创建】
Eg.1代码:
| (my.list <- list(stud.id=34453,stud.name='张三',stud.marks=c(14.3,12,15,19))) length(my.list) unlist(my.list) |

【列表索引】
Eg.1代码:
| x <- c(1,1,2,2,3,3,3) y <- c("女","男","男","女","女","女","男") z <- c(80,85,92,76,61,95,83) LST <- list(class=x,sex=y,score=z) LST$class names(LST) LST["sex"] LST[1] LST[2] LST[[2]][1:3] LST$score |

【因子】
Eg.1代码:factor函数创建因子。
| (ff <- factor(substring("statistics",1:10,1:10),levels=letters)) (f. <- factor(ff)) ff[,drop=TRUE] |

Eg.2代码:
| factor(letters[1:20],labels="letter") z <- factor(LETTERS[3:1],ordered=TRUE) z |

【txt数据读入】
操作1:在environment下的import dataset下读入文件。

操作2代码:
| a1 = read.table("design.txt",header=T,sep="\t") a2 = read.table("C:\\Users\\86158\\Desktop\\design.txt",header=T) |

【csv数据读入】
Eg.1代码:
| b <- read.csv("mtcars.csv",header = T,sep = ",") head(b) tail(b) |

【excel数据读入】
Eg.1代码:使用openxlsx包。
| install.packages("openxlsx") library(openxlsx) (c <- read.xlsx("C:\\Users\\86158\\Desktop\\CO2.xlsx",sheet=1,startRow=1,colNames=T,rowNames=F,rows=1:60,cols=1:5)) |

【修改读入数据】

【quantmod案例】
Eg.1代码:
| install.packages("quantmod") library(quantmod) getSymbols("AAPL", src = "av", api.key ="ESLSN43SQCZO9ZUG") tail(AAPL) |

Eg.2代码:主绘图函数。
| chartSeries(AAPL,theme='white') |

Eg.3代码:条形图。
| barChart(AAPL,theme='white') |

Eg.4代码:蜡烛图。
| candleChart(AAPL,theme='white') |

Eg.5代码:线图。
| lineChart(AAPL,theme='white') |

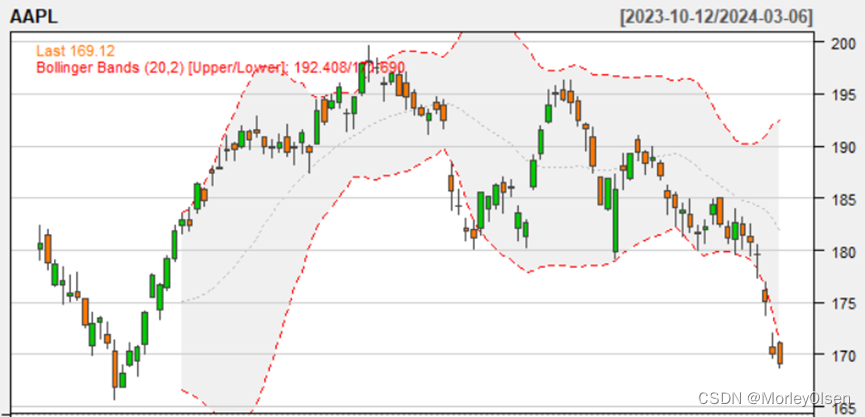
Eg.6代码:技术分析图。
| chartSeries(AAPL,theme='white') require(TTR) addADX() addATR() addBBands() addCCI() addEMA() |




【XML包举例】
Eg.1代码:
| install.packages("XML") library(XML) strurl <- 'http://sports.163.com/zc' tables <- readHTMLTable(strurl,header=FALSE,stringAsFactors=FALSE) |
![]()
四:课堂练习
【练习1】PPT-02,第24页
练习1代码:创建一个向量x,内含等差数列:首位为1.7,等差为0.1,长度为5。
| x <- seq(1.7,by=0.1,length=5) x |

练习1代码:创建向量y,y为重复序列:元素为“red”、“orange”、“green”,各元素重复两次,序列长度为5。
| y <- rep(c("red","orange","green"),2,length=5) y |

若为先重复再组成向量,则代码如下:
| y <- rep(c("red","orange","green"),each=2,length=5) y |

【练习2】PPT-02,第38页
练习2代码:使用matrix()函数,以向量形式输入矩阵中的全部元素,使用ncol和nrow设置矩阵的行和列数。
| (w <- seq(1:10)) (a <- matrix(w,nrow=5,ncol=2)) |

若为按行填充,则代码如下:
| (a <- matrix(w,nrow=5,ncol=2,byrow=T)) |

【练习3】PPT-02,第46页

练习3代码:建立如图所示的矩阵,对第2行、第3列进行索引。
| (w1 <- seq(1:6)) (w2 <- seq(7,by=1,length=6)) (a <- matrix(w1,nrow=3,ncol=2,byrow=T,dimnames=list(paste('u',1:3),paste('v',1:2)))) (b <- matrix(w2,nrow=3,ncol=2,dimnames=list(paste('u',1:3),paste('v',3:4)))) cbind(a,b) cbind(a,b)[2,] cbind(a,b)[,3] cbind(a,b)[2,3] |

【练习4】PPT-03,第39页

代码1:在R中读入design.txt文件。
| (a <- read.table("C:\\Users\\86158\\Desktop\\design.txt",header=T,sep="\t")) |

代码2:在R中读入mtcars.csv文件。
| (b <- read.csv("C:\\Users\\86158\\Desktop\\mtcars.csv",header=T,sep=",")) head(b) tail(b) names(b) |


代码3:在R中读入biomass.xlsx文件的sheet1中前60行、5列数据。
| ( c <- read.xlsx("C:\\Users\\86158\\Desktop\\biomass.xlsx", sheet = 2, startRow = 1, colNames = TRUE, rowNames = FALSE, rows = 1:60, cols = 1:5)) |


代码4:将example.xls文件的数据读入R。
| (d <- read.xlsx("C:\\Users\\86158\\Desktop\\example.xlsx",sheet=1,startRow=1,colNames=T,rowNames=F,rows=1:12,cols=1:12)) |

四:实验总结
1:常见的辨别和转换对象类型的函数。

2:R用于存储数据的对象类型,包括向量、矩阵、数组、数据框、列表。

3:seq函数产生等距间隔数列的基本形式。

4:向量常见函数。

5:索引向量的常见形式。

6:向量排序的形式。

7:矩阵计算的常用函数。

8:矩阵编辑(合并、删除)的常用函数。

五:遇到的问题和解决方案
问题1:矩阵创建时,出现以下报错。

解决1:dimnames输入错误,修改拼写后运行正确。
问题2:按照PPT03-第12页的代码执行时,出现以下报错。

解决2:出现拼写错误,需要将data.iris改为data_iris。
问题3:PPT03-第33页,关于getSymbols('AAPL',src=’yahoo’)代码的内容无法爬虫,会出现以下HTTP报错。

解决3:更换source,经过查询后得到可在网站(Free Stock APIs in JSON & Excel | Alpha Vantage.)上注册免费的API。
问题4:PPT03-第37页的url1网站无法打开,Rcurl举例无法复现。
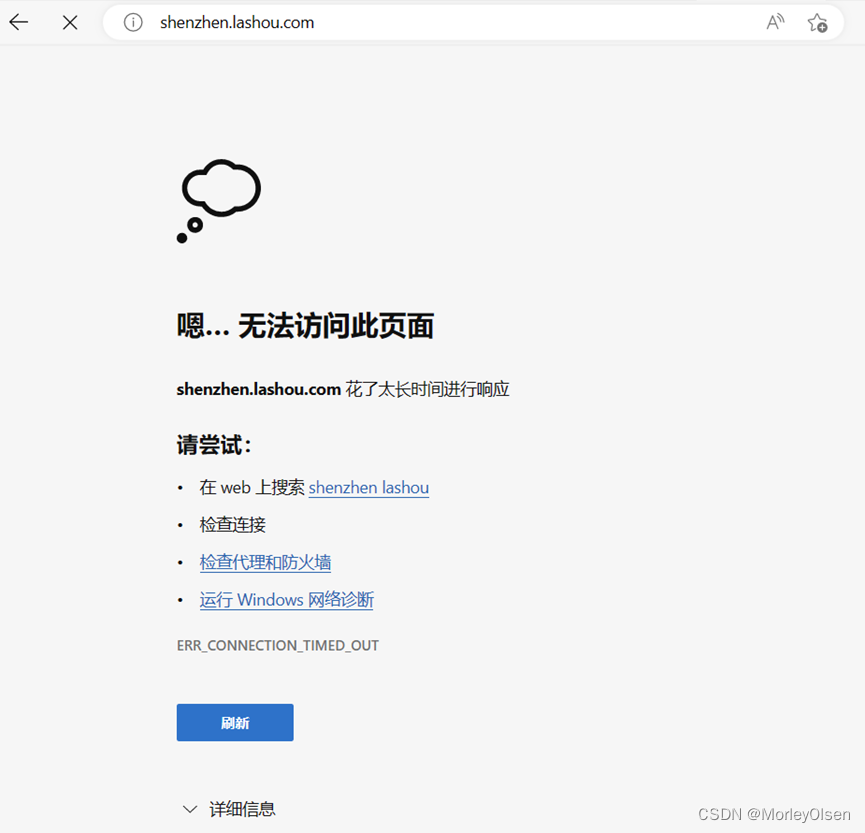
解决4:暂无。
问题5:使用excel读取时,出现以下报错。
| Error in read.xlsx("C:\\Users\\86158\\Desktop\\biomass.xlsx", sheet = 2, : 没有"read.xlsx"这个函数 |
解决5:安装openxlsx依赖包。
| install.packages("openxlsx") library(openxlsx) |