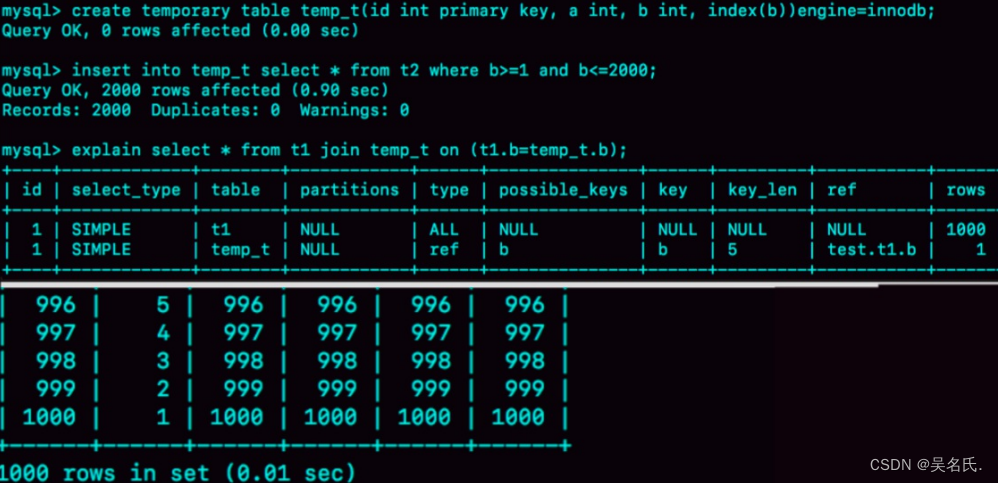
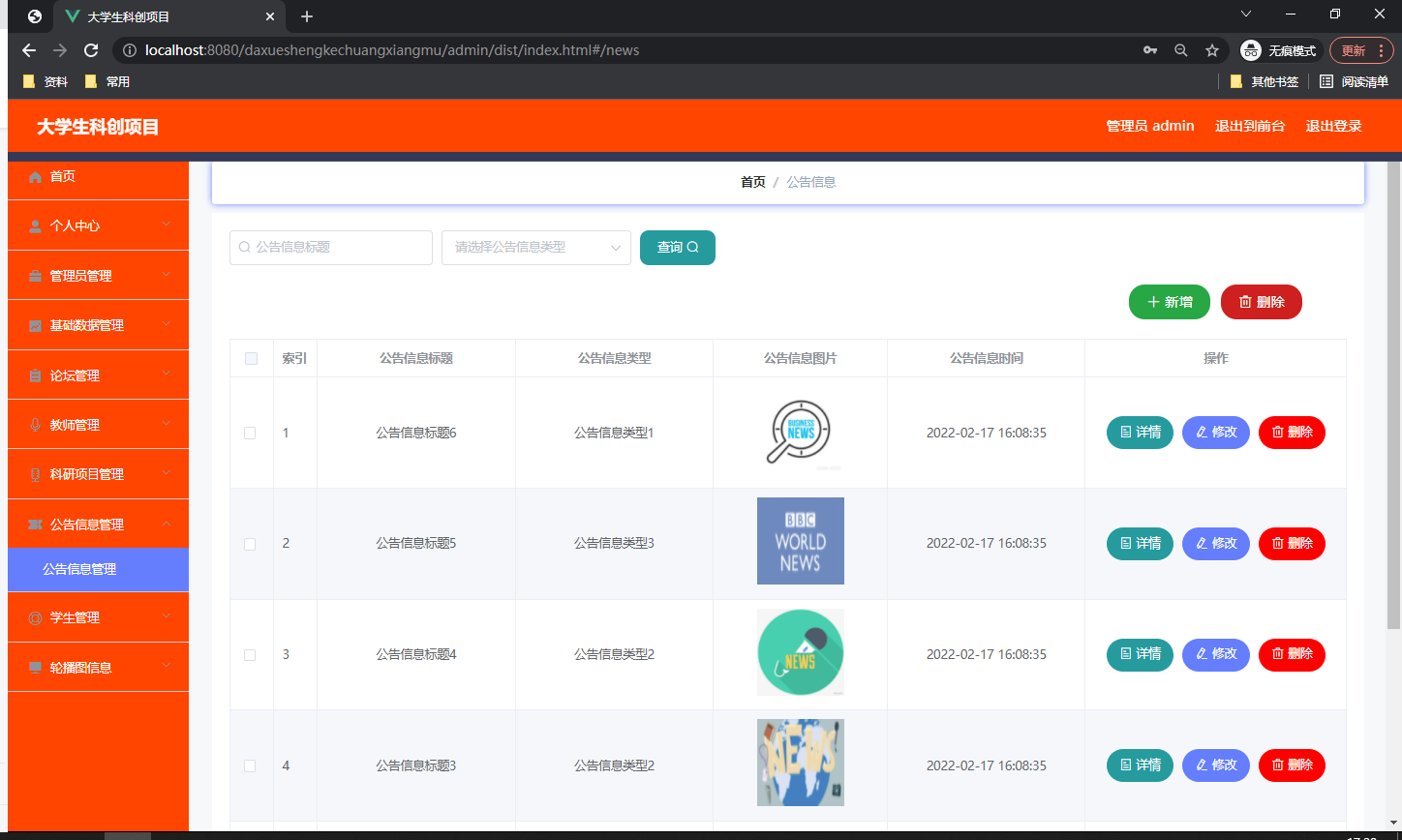
set集合继承collection,所以API都差不多,我就不多加介绍
直接见图看他们的特点

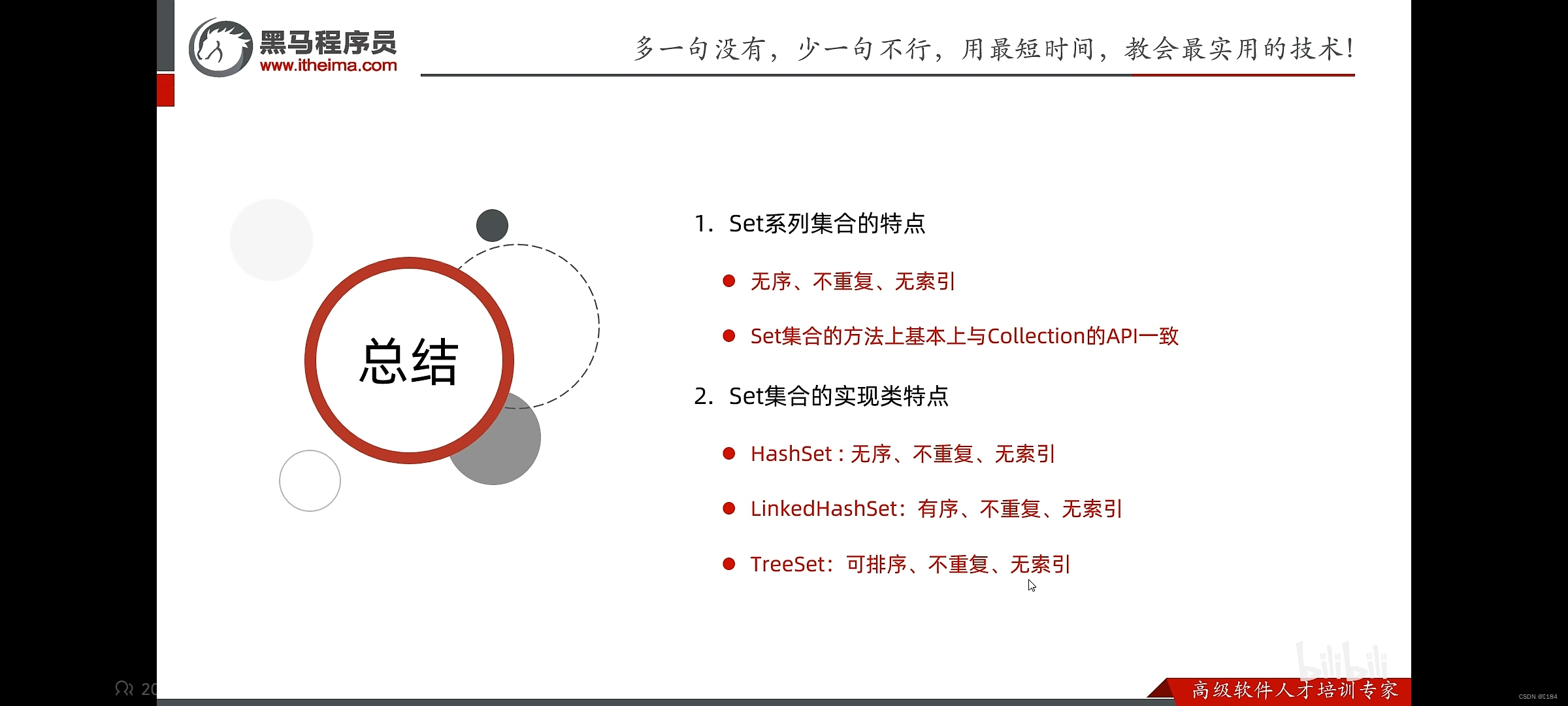
我们主要讲述的是set系列里的HashSet、LinkedHashSet、TreeSet
HashSet
HashSet它的底层是哈希表
哈希表由数组+集合+红黑树组成
特点:增删改查都性能良好
哈希表具体是什么,我也不太讲的清,具体见java上册197集
我们主要是了解它的去重
他是如何去重的呢?
通过的是HashCode方法和equals方法
当我们储存的是自定义对象时,我们就必须要重写它们
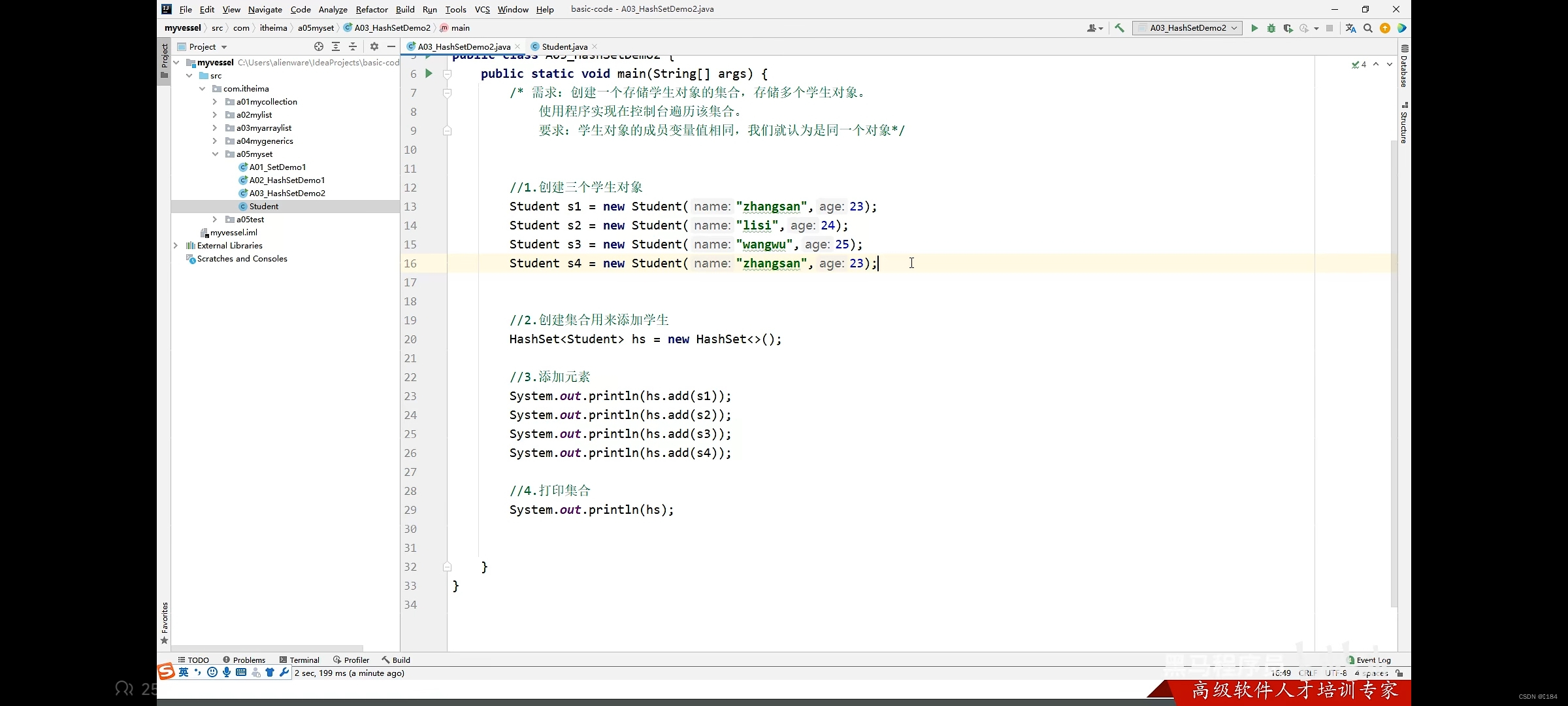
如上图,s1和s2名字和姓名重复了,我们认为是同一个人,所以我们要去重
因为HashSet底层不知到student这个自定义类,所以不会对他进行去重
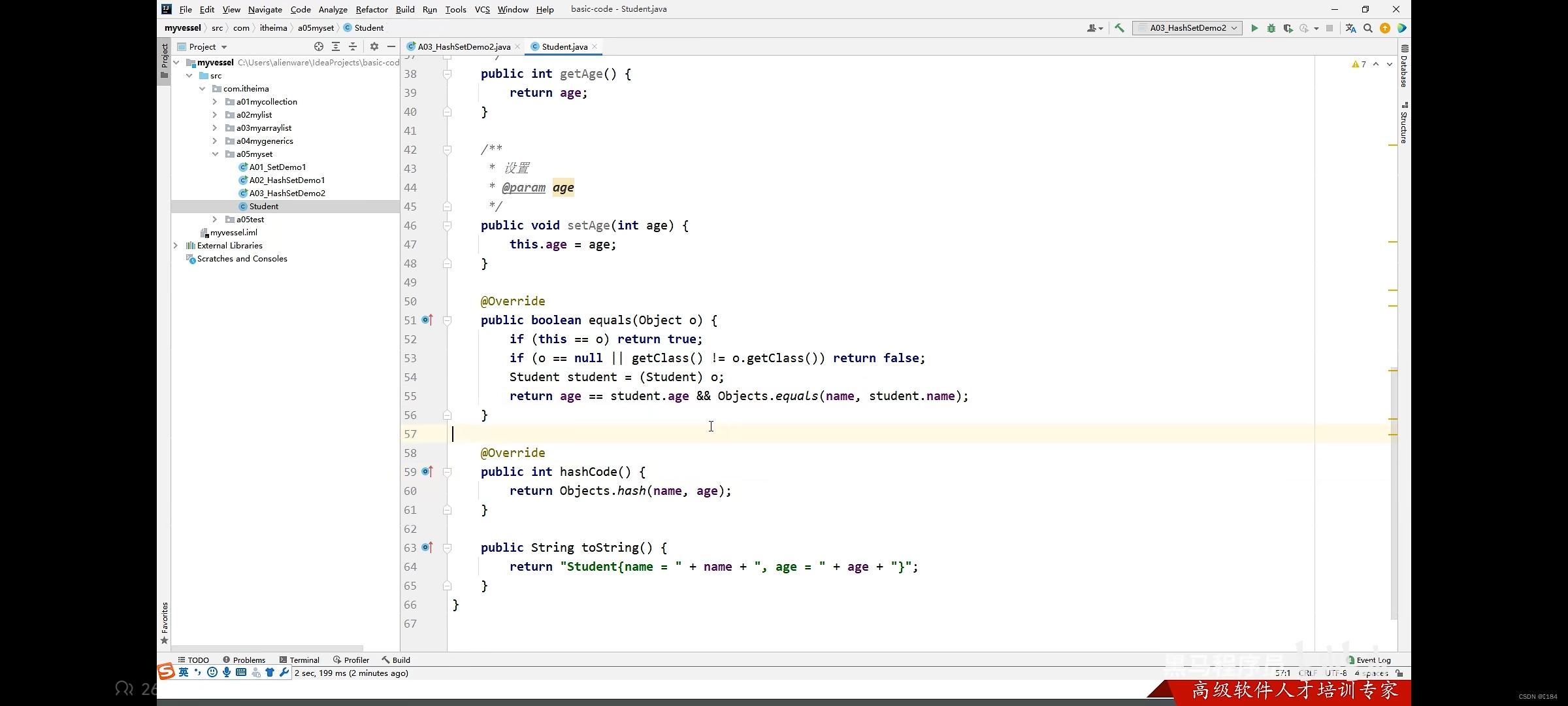
所以我们只有自己在student类里重写HashCode方法和equals方法
LinkedHashSet
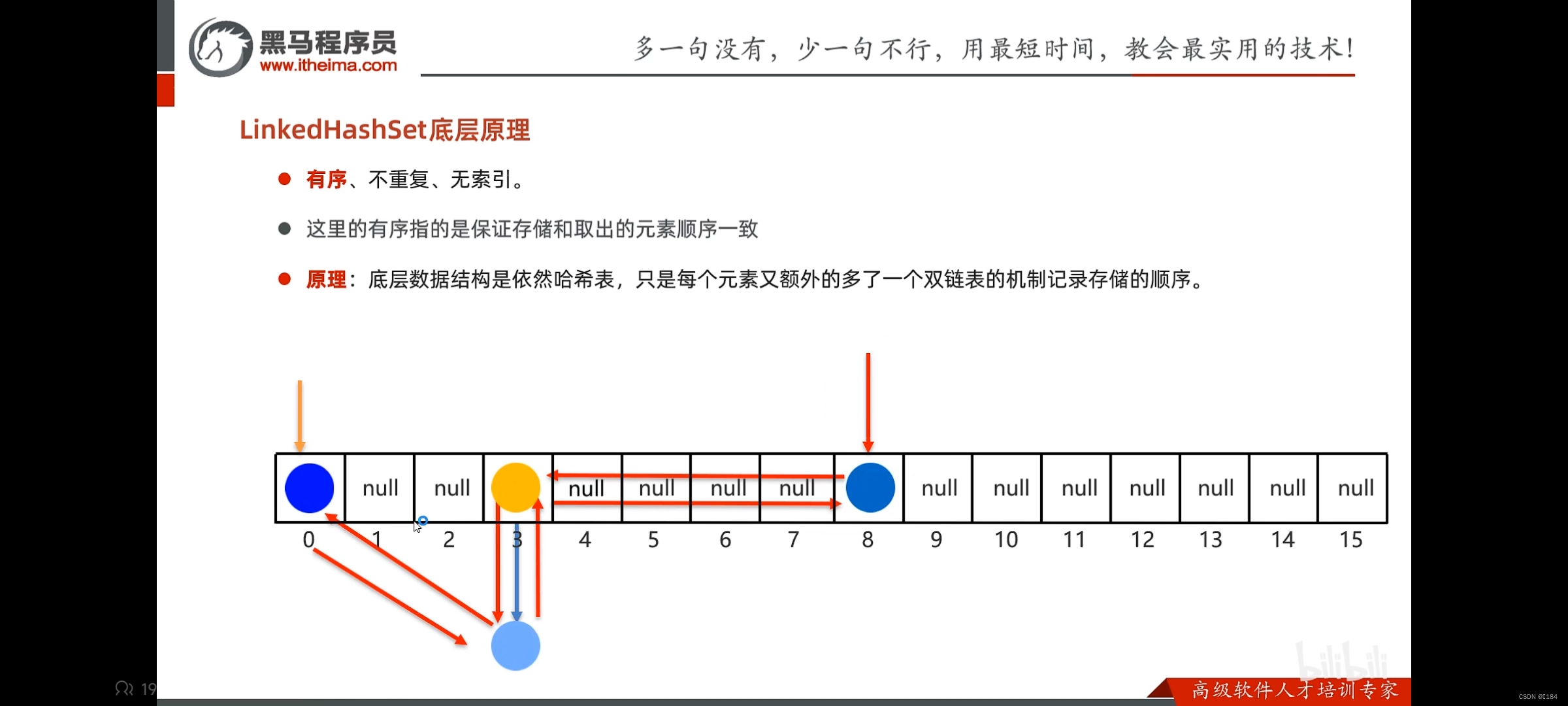
这个就是比HashSet多了个有序的特点,其余差不多
那我们以后要如何选择使用哪个呢?
见下图

TreeSet
他是Set的子类
特点:

注意了:它的特点是可排序
当我们写的泛型输入的是底层已经处理的数据类型,他们就会默认排序好
如下图
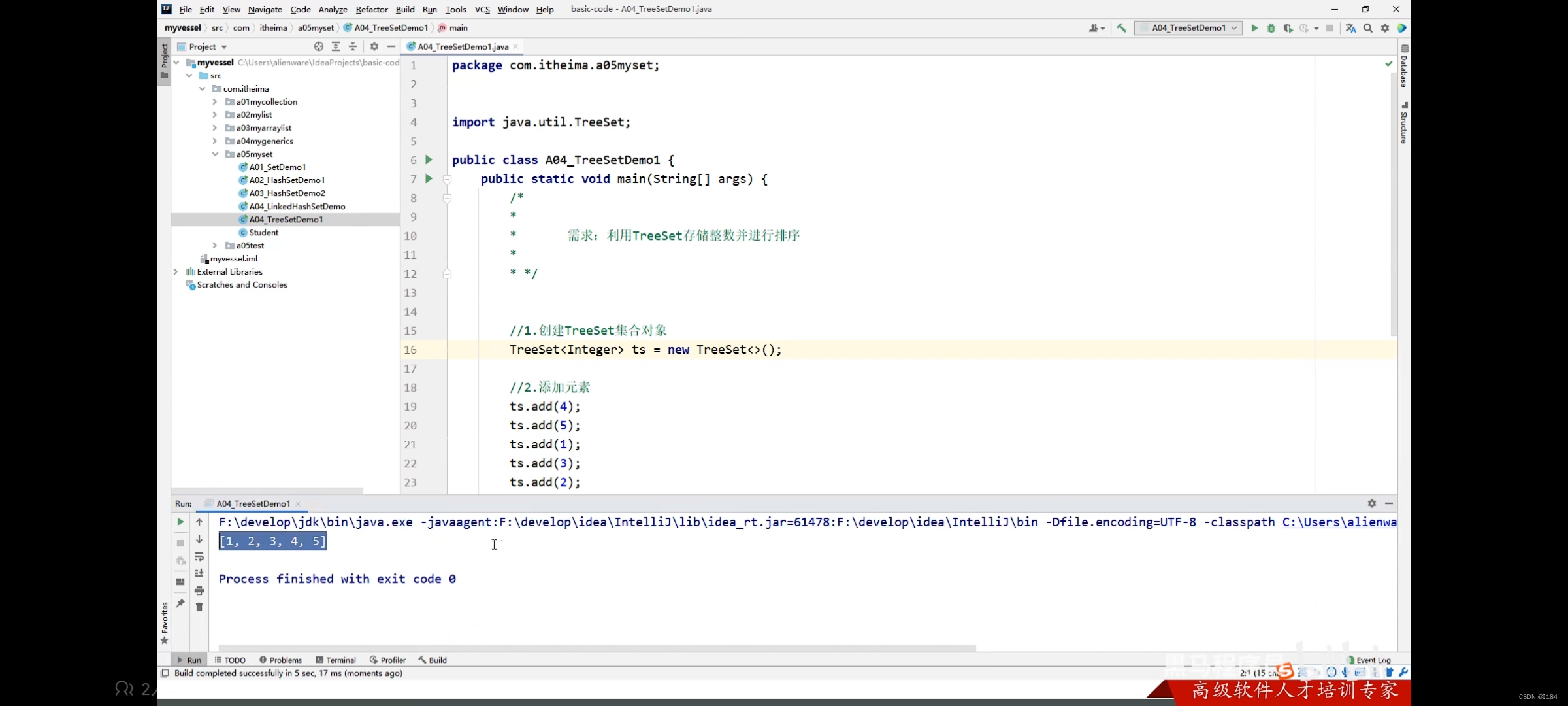
那它是怎么排序的呢?
默认排序的规则如下
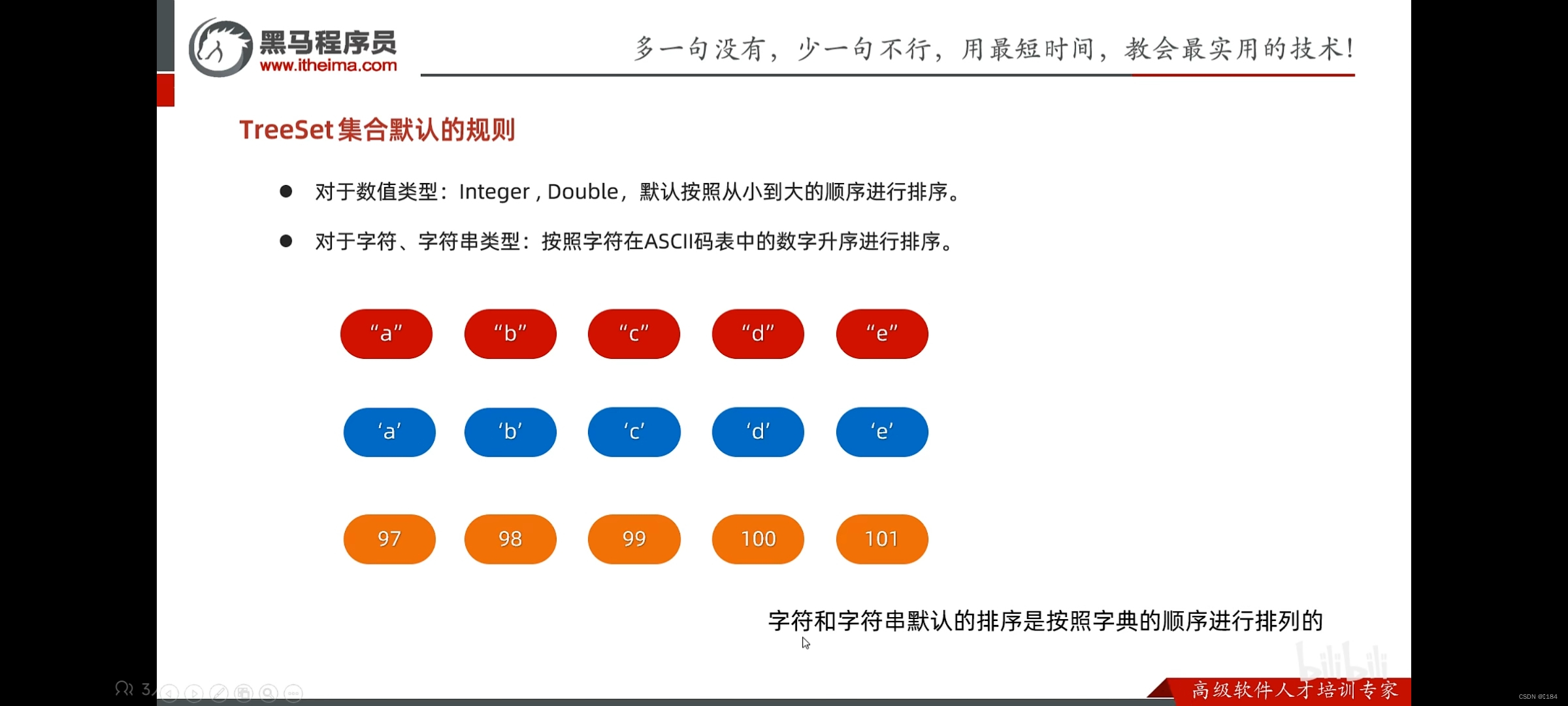
但是如果是字符串怎么比较呢?
很简单,就是逐一比较,例如cb和aaa比较哪个大呢?
显然cb大
首先逐一比较,就是cb的第一个和aaa的第一个比较
如果一样就下一个,但是如果已经比较出来了,就不会继续比较了
但是我们要想,如果我们传入的数据类型是,自定义对象类型呢?或者我们不要这默认的比较规则想改变为其他规则呢?
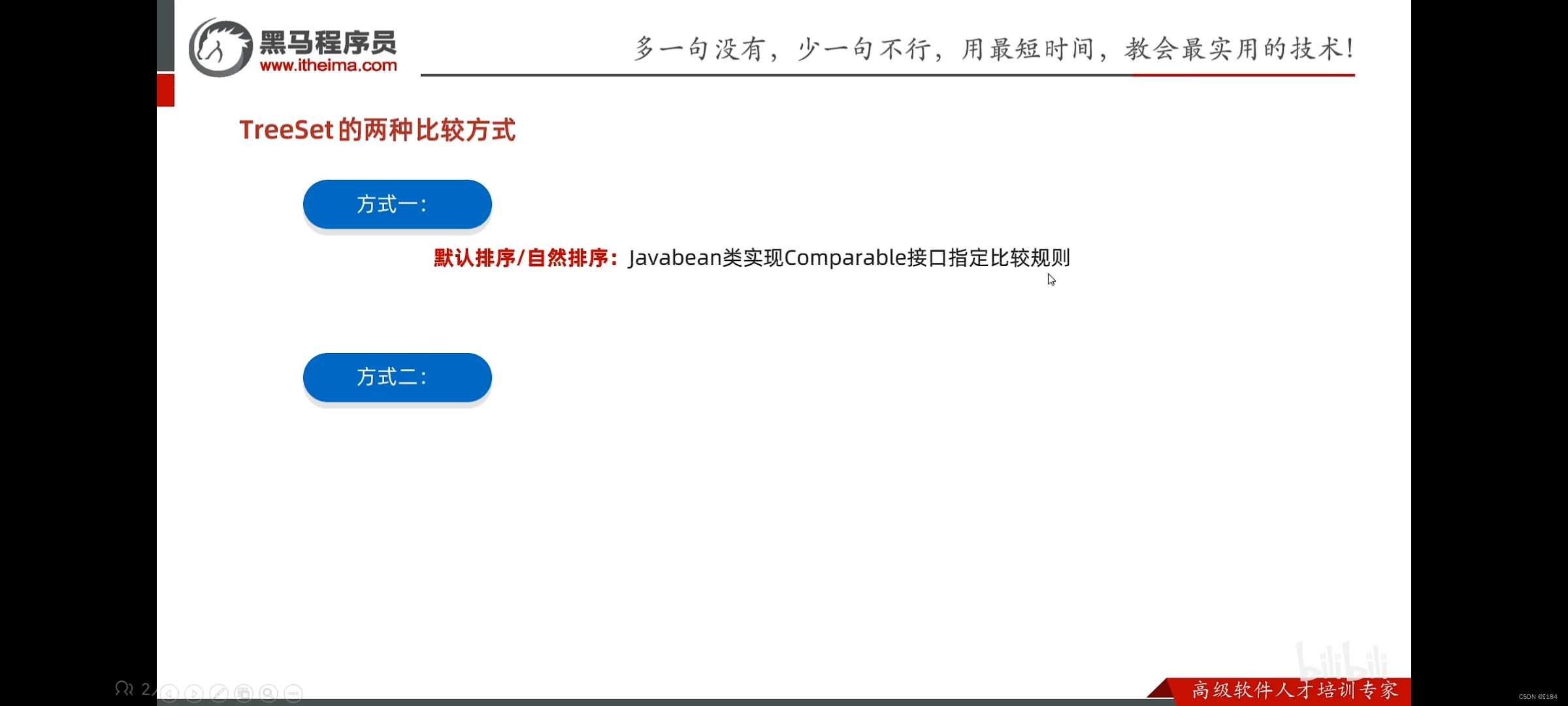
它有两种解决方法:
方法一
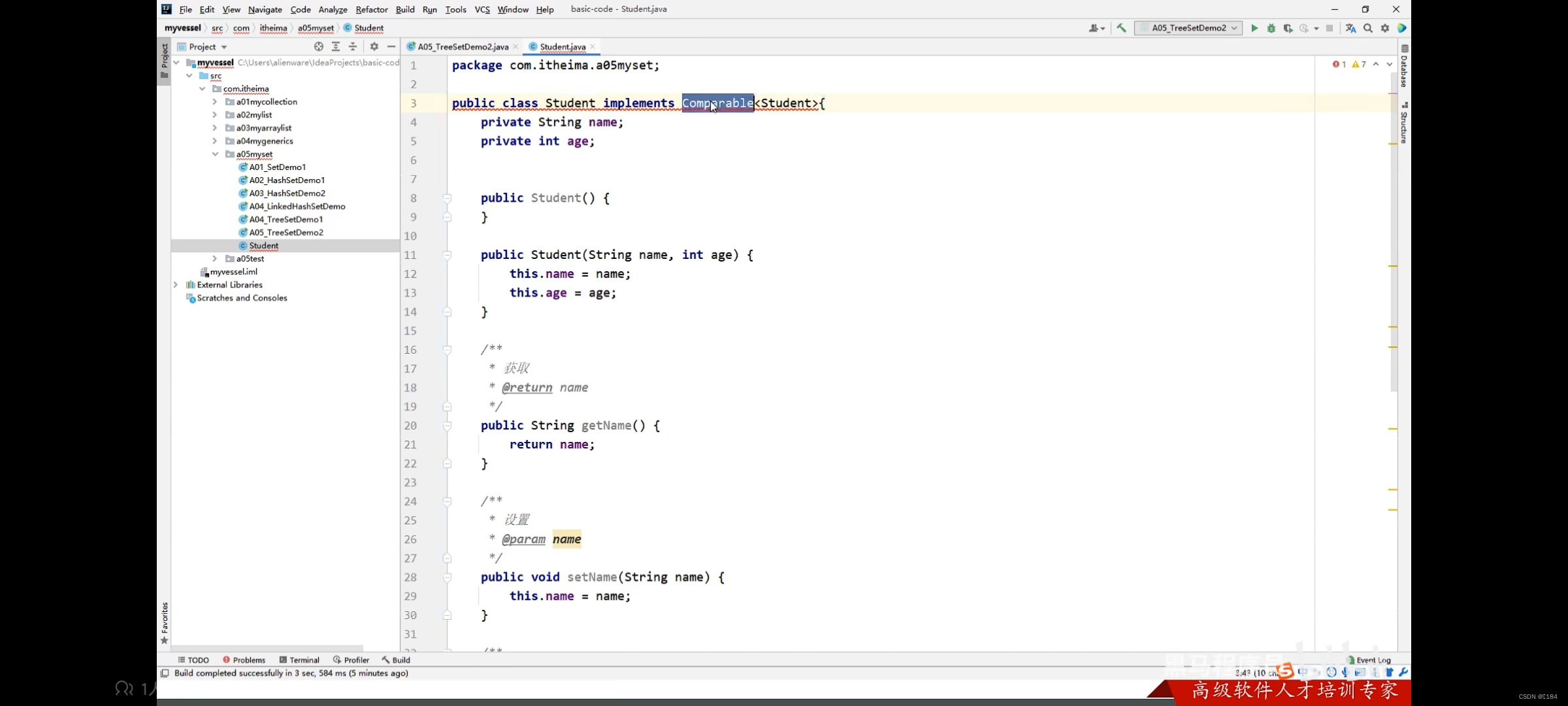
首先我们要实现接口
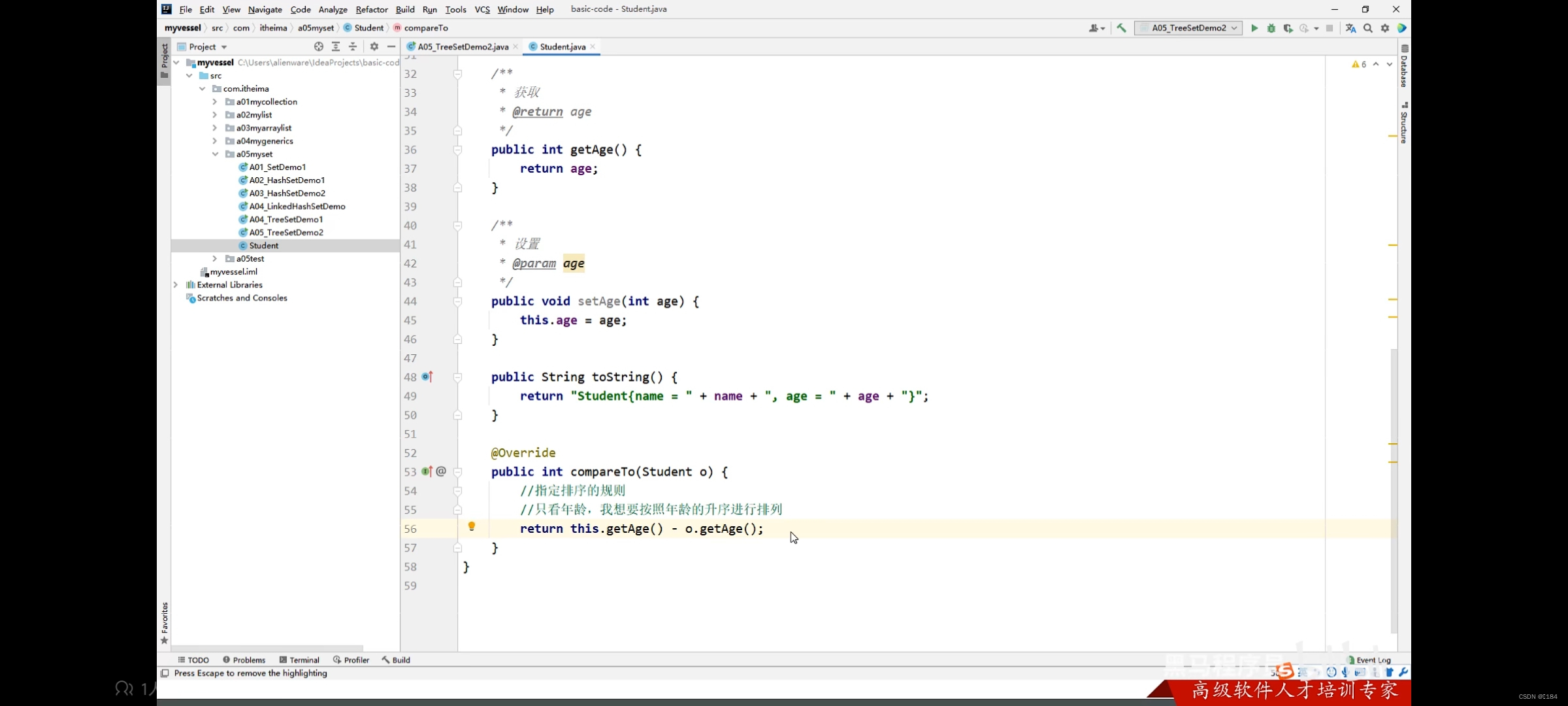
然后我们就要重写比较规则
然后就行了
但是我们刚学一般有这些疑问
这是自定义对象,我们要不要重写HashCode方法和equals方法呢
当然是不要的,这个是TreeSet系,底层是红黑树,不是哈希表,不要搞混了
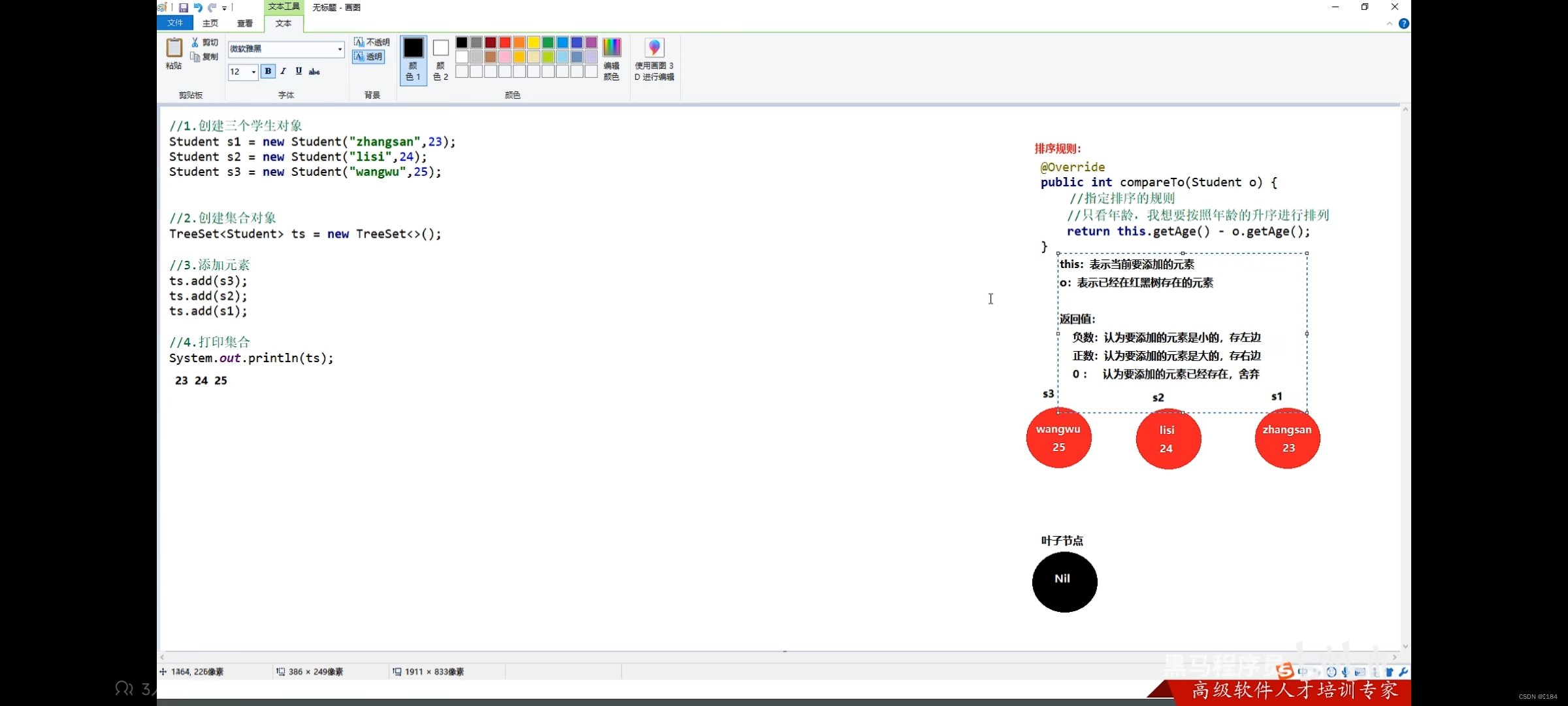
这个指定的规则里面this指什么?o又指什么?他们怎么实现排序的呢?
看下图你就能一目了解了
方法二

首先我们要知道,默认是使用第一种方法,但是如果第一种方法不能满足我们的需求,我们就只能用第二种方法
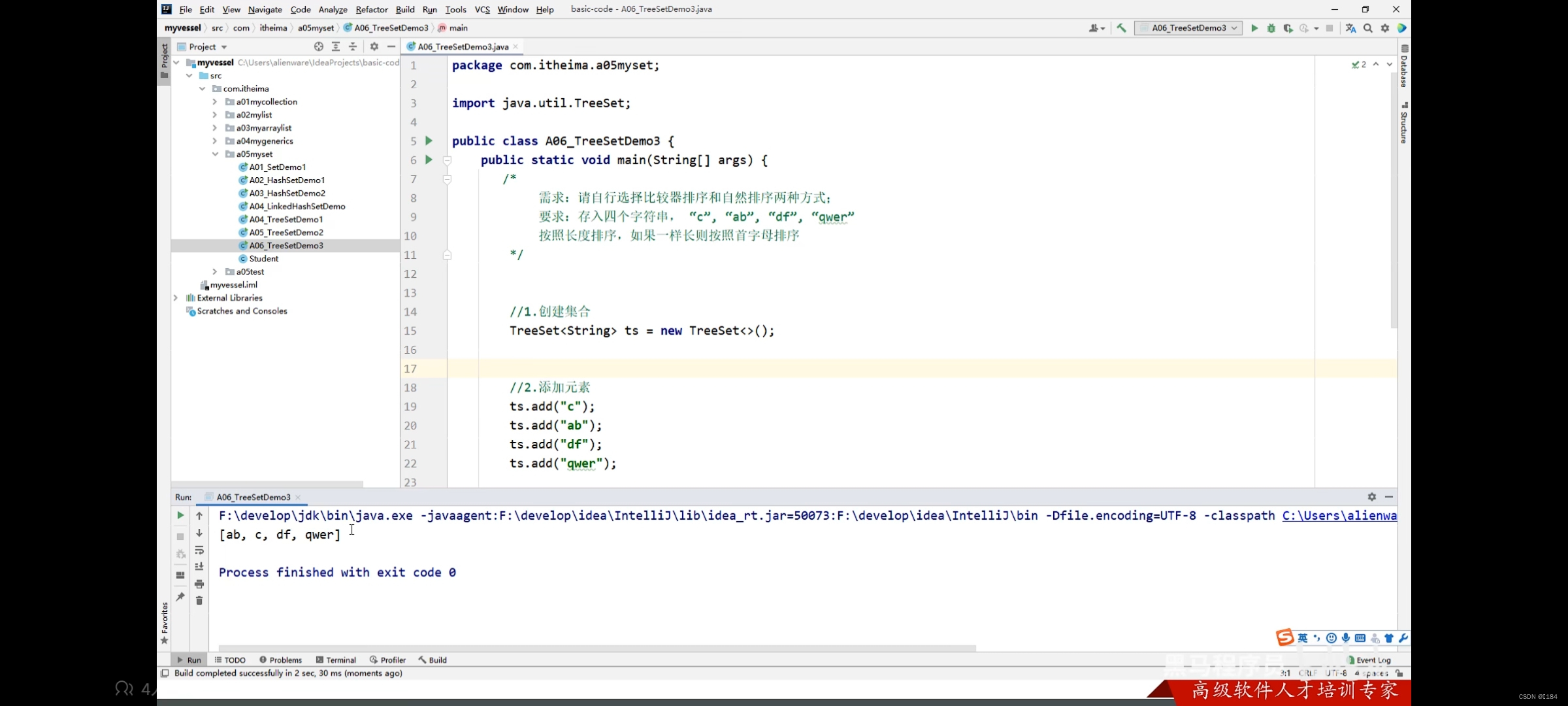
看上图,我们没有指定特定的比较规则,所以是按照第一种方法的默认规则进行排序的
但是我们现在不要这种比较规则了,我们想要根据字符串的长度来比较,长度长的就更大
那我们怎么办呢?
我们就要用到迭代器法了
如下采用匿名内部类的形式传入形参,而这个形参代表的就是比较规则

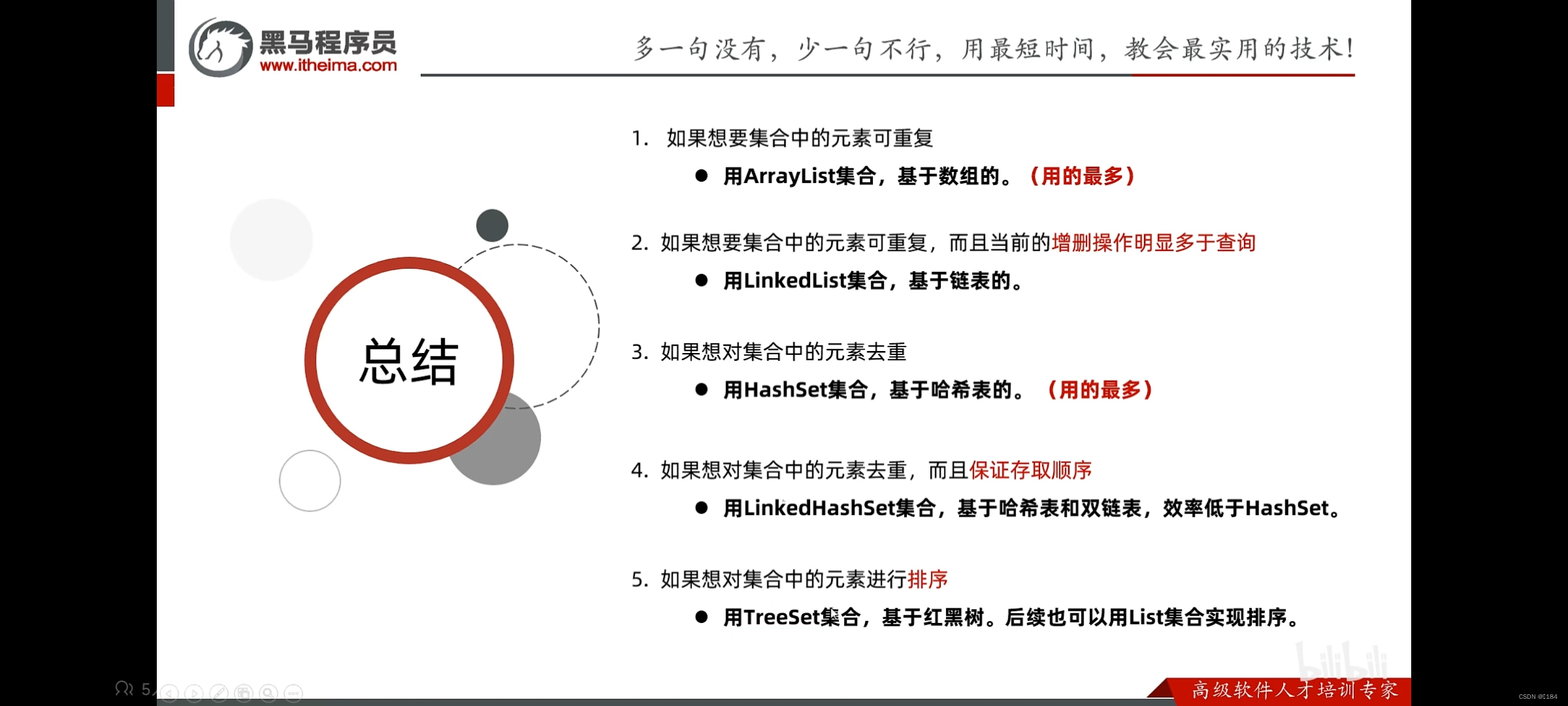
总结