目录
一 、读取access数据库
(一)execl读取数据库
1.搜索ODBC(注意自己的execl是64位还是32位)
2.安装数据源的驱动程序
3.打开execl
4. 补充:选择数据源时,也可以直接在execl中选择数据源
(二)Python读取数据源
1.python读取mdb文件数据
(1)忽略警告userWarning
二 、读取mysql数据库
(一)execl连接MySQL数据库
1.下载 MySQL ODBC
2. 安装数据源的驱动程序
3.打开execl
(二)python读取Mysql数据
一 、读取access数据库
Microsoft Office Access是专为Windows用户设计的一个桌面数据库系统,它提供了一种简便的方式来创建和管理数据库。
一般文件格式是mdb

(一)execl读取数据库
比如要获取mdb文件的数据源
1.搜索ODBC(注意自己的execl是64位还是32位)

windows电脑搜索ODBC数据源(正常内置都有,没有的话就得自己安装)

2.安装数据源的驱动程序
2.1 Microsoft Access Driver(用于访问mdb文件数据源)
(1)用户DSN--添加--确定--》Microsoft Access Driver--完成
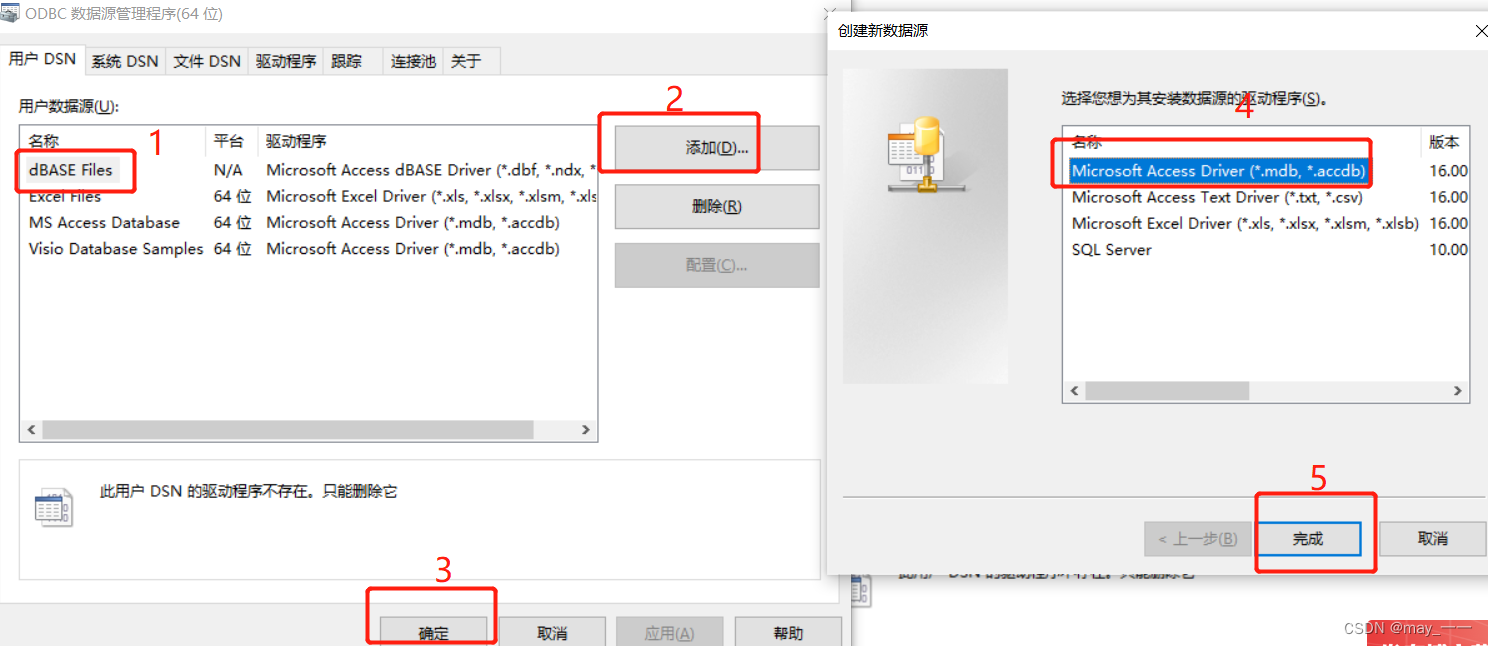
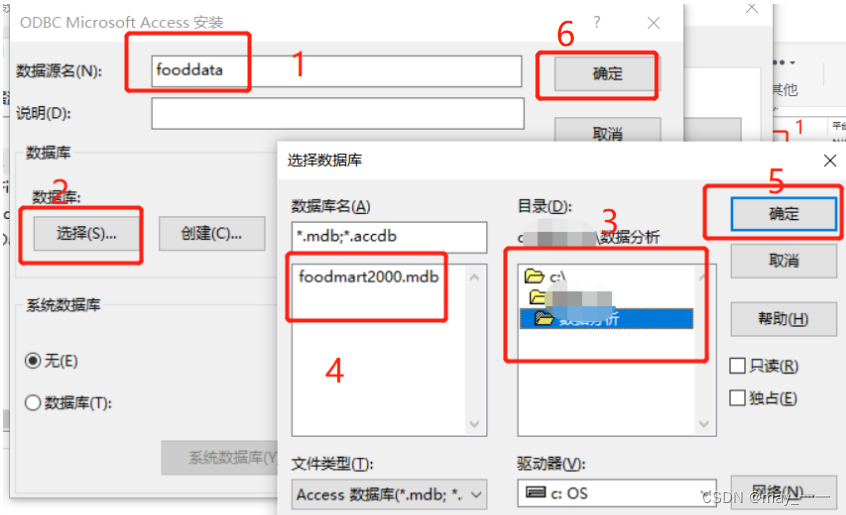
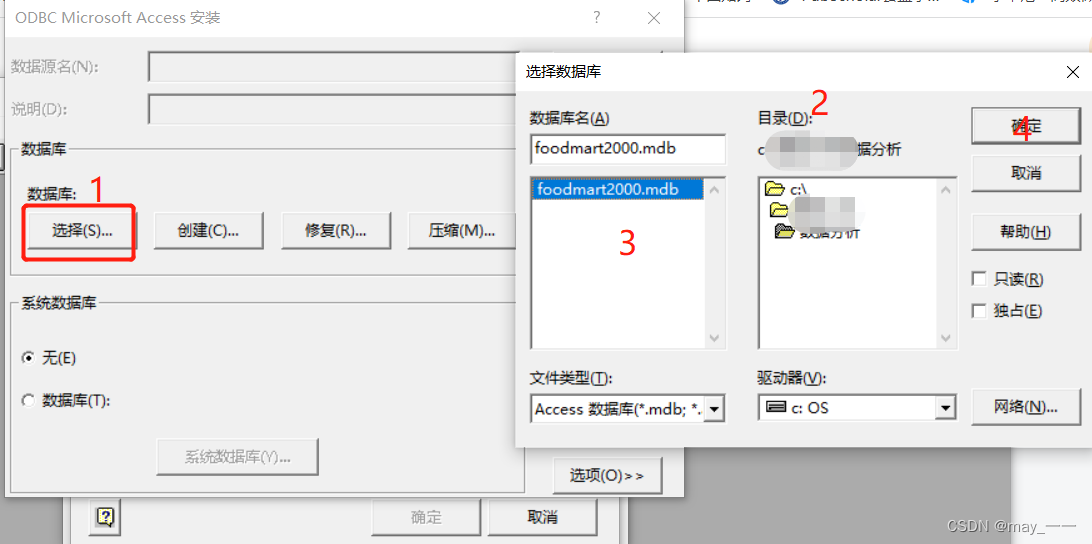
(2)ODBC Microsoft Access安装
数据源名可随意设置,根据自己的需要--“选择”(选择自己mdb文件的存放路径)
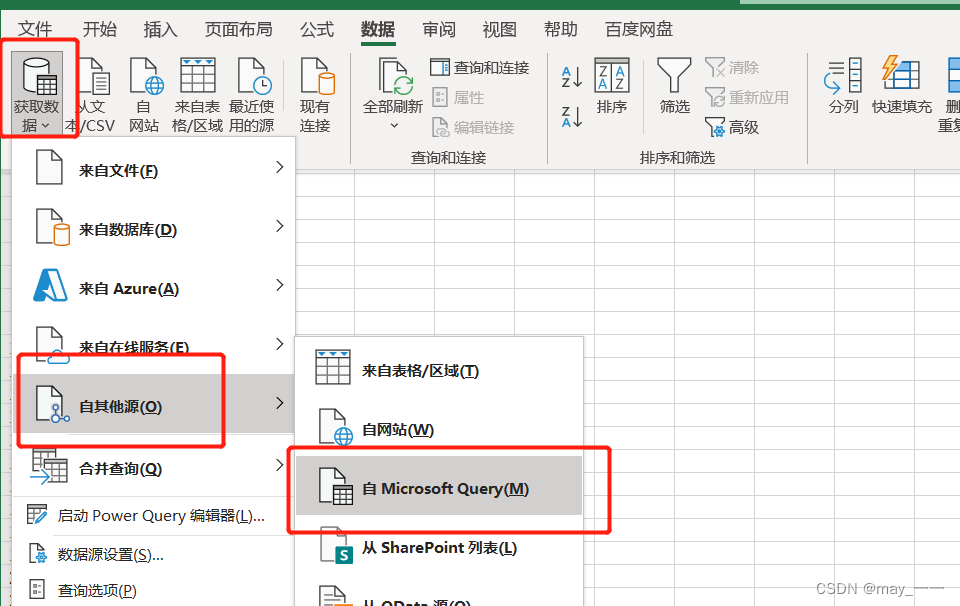
3.打开execl
数据--获取数据--自其他源--自Microsoft Query(M)--上一步设置的数据源名
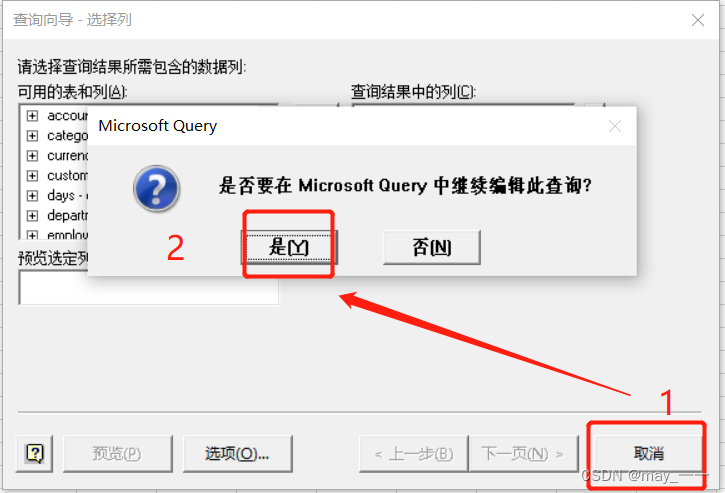
选择上一步设置的数据源名

在选择列的过程中,点击“取消”
 选择需要的表进行添加
选择需要的表进行添加

选择需要的字段
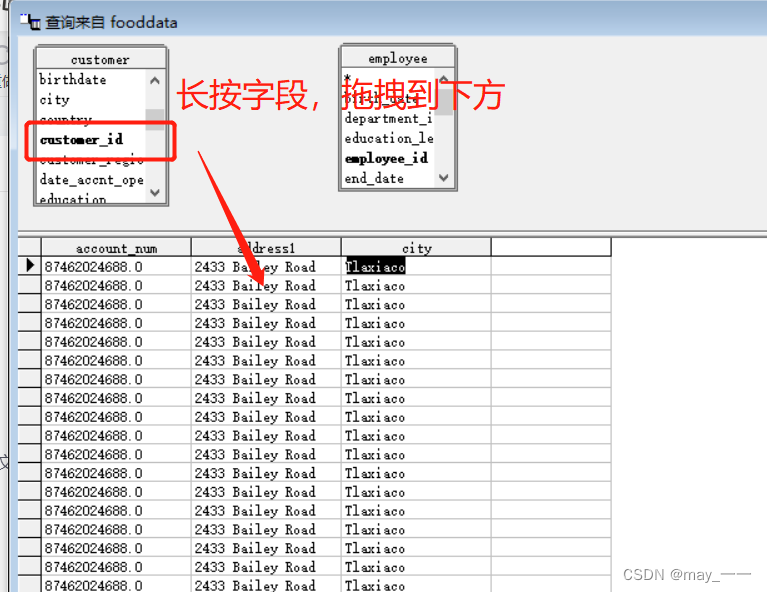 保存
保存

导入execl

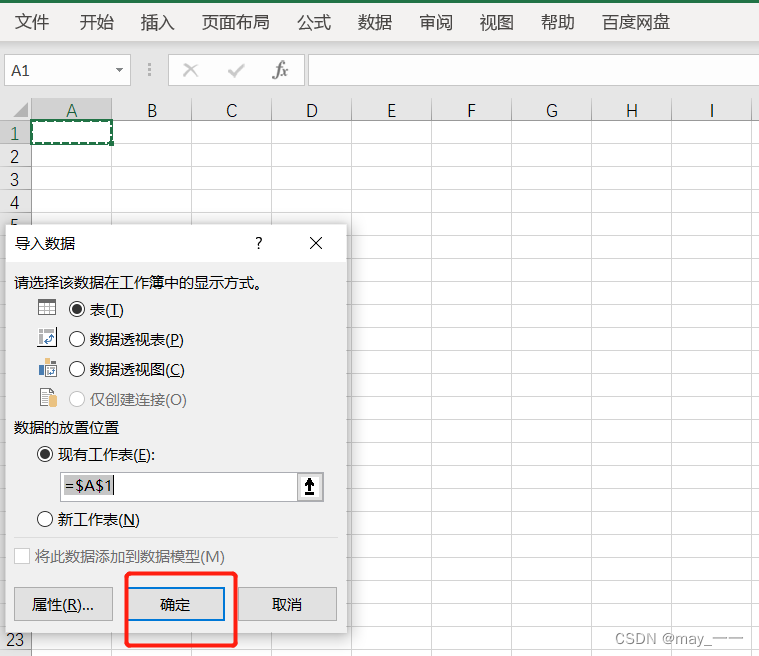
效果如下:

4. 补充:选择数据源时,也可以直接在execl中选择数据源
数据--获取数据--自其他源--自Microsoft Query(M)--新数据源
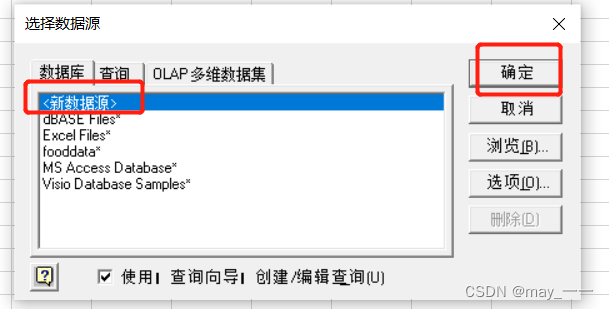
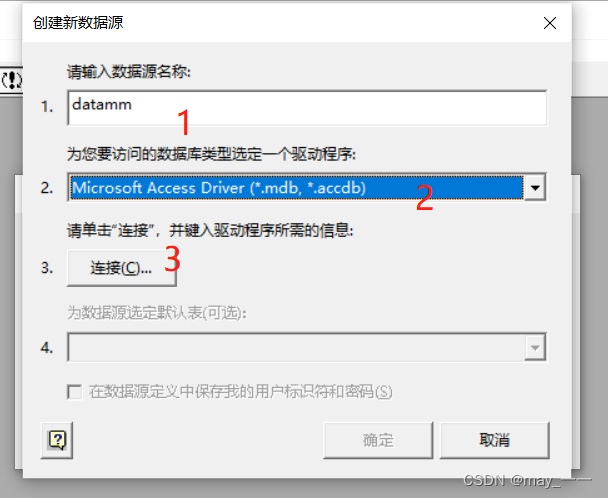
(二)Python读取数据源
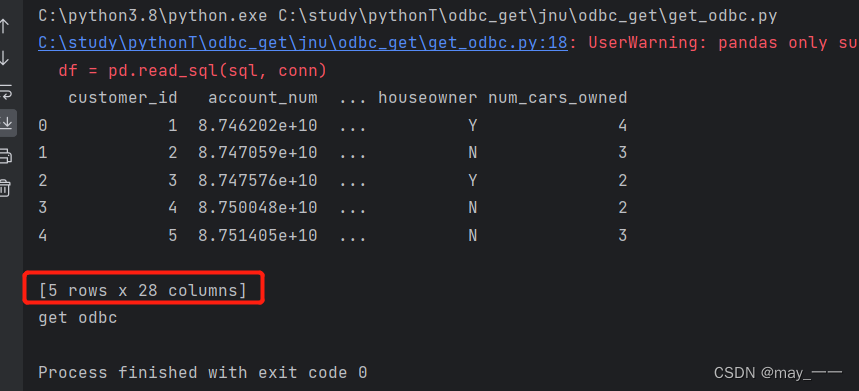
1.python读取mdb文件数据
# 下面代码为打开和阅读foodmart2000.mdb数据的代码
import pyodbc
import pandas as pd
# 创建连接字符串
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=C:\**\foodmart2000.mdb;' # mdb文件的位置
)
# 创建连接
conn = pyodbc.connect(conn_str)
# 执行 SQL 查询并将结果存储在 DataFrame 中
sql = 'SELECT * FROM customer' # 替换为你的表名
df = pd.read_sql_query(sql, conn)
# 打印 DataFrame
#print(df)
# 关闭连接
conn.close()
# 打印前5行
df.head(5)
if __name__ == '__main__':
print('get odbc')上面的方法有警告
UserWarning: pandas only supports SQLAlchemy connectable (engine/connection) or database string URI or sqlite3 DBAPI2 connection. Other DBAPI2 objects are not tested. Please consider using SQLAlchemy.
(1)忽略警告userWarning
import warnings
warnings.filterwarnings("ignore")再次运行正常
二 、读取mysql数据库
(一)execl连接MySQL数据库
1.下载 MySQL ODBC
MySQL :: Download Connector/ODBC
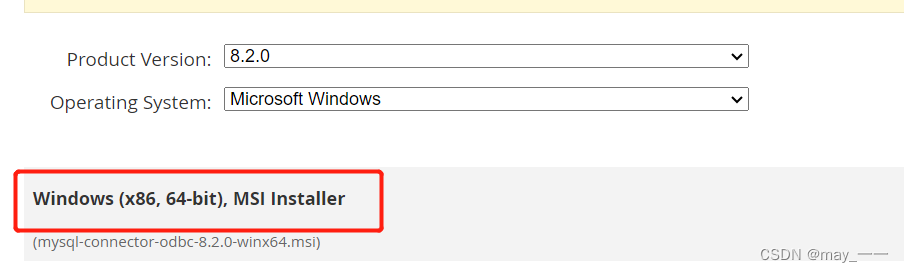
注意根据execcl版本下载(64或32位,很重要!!)

需要先按照Visual Studio 2019 x64,然后再运行下载的应用


在ODBC数据源管理中的驱动程序就可以看到有关MySQL的内容
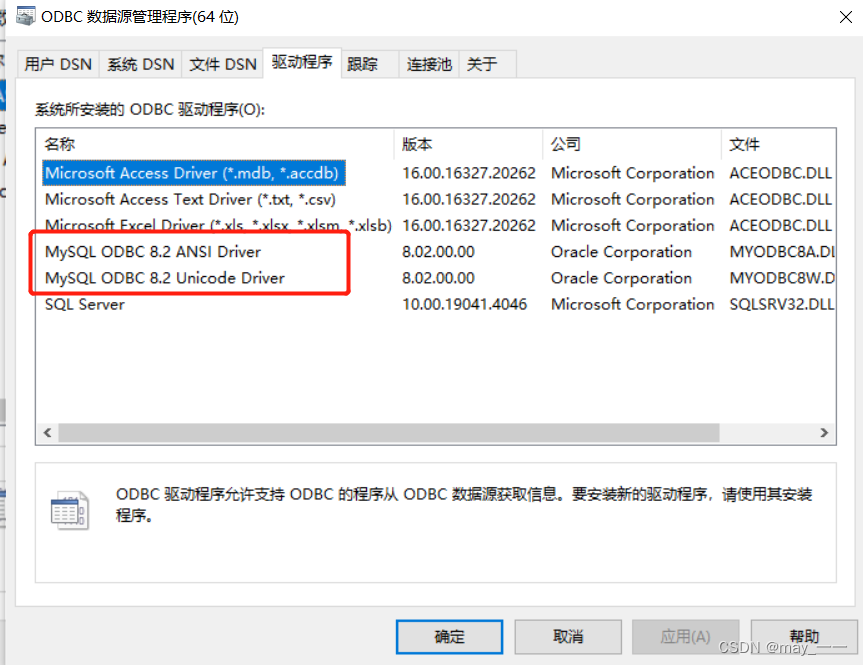
2. 安装数据源的驱动程序
(1)用户DSN--添加--确定--》MySQL ODBC 8.2 Unicode Driver--完成


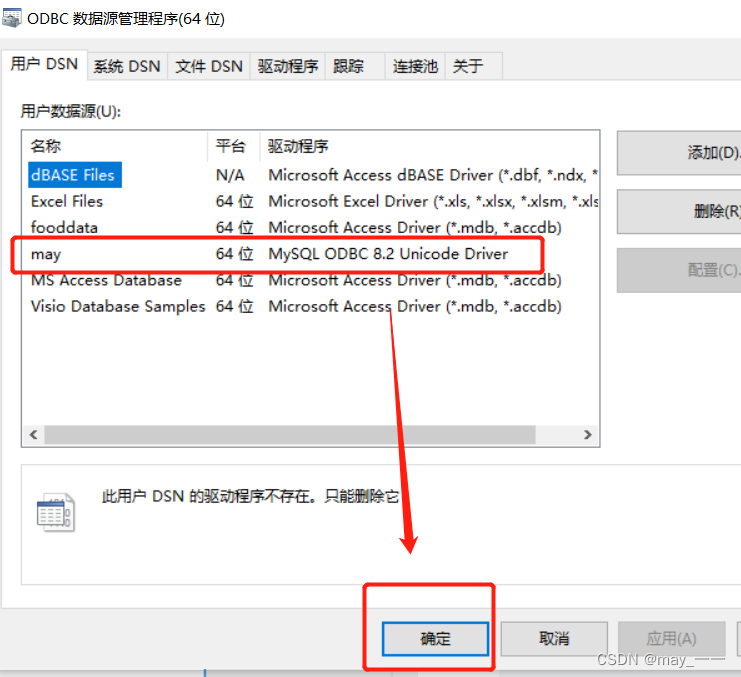
3.打开execl
数据--获取数据--自其他源--从ODBC(D)--确定

选择需要的表
效果如下:弹出Power Query编辑器

根据需要增删数据,然后“关闭并上载”
(二)python读取Mysql数据
启动MySQLf服务(管理员运行cmd)
net start mysql # 启动服务
net stop mysql # 停止服务进入MySQL命令模式
mysql -u root -p获取mysql的host和user名
select host,user from mysql.user; 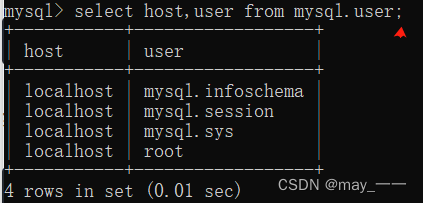
#导入包
import pandas as pd
import sqlalchemy as sql
# 建立链接
engine = sql.create_engine('mysql+pymysql://root:***@localhost:3306/mayfood')
# 格式 engine = sql.create_engine('mysql+pymysql://用户名:密码@地址:端口号/数据库名字')
# 查询语句
sql24 = '''select * from customer'''
# 读入到Python
df = pd.read_sql(sql24, engine)
# f = df.head(20) # 获取前20条数据
# print(f)
# 如果还需要导出到xlsx或csv
df.to_excel("food_e.xlsx", index=False)
df.to_csv("food_c.csv", index=False, encoding="utf_8_sig")
if __name__ == '__main__':
print('get odbc')
补充:
pd.read_sql( )完整函数
read_sql(sql,con,index_col='None',coerce_float='True',params='None',parse_dates='None',columns='None',chunksize:None='None')
ead_sql方法是pandas中用来在数据库中执行指定的SQL语句查询或对指定的整张表进行查询,以DataFrame 的类型返回查询结果.
其中各参数意义如下:
sql:需要执行的sql语句
con:连接数据库所需的engine,用其他数据库连接的包建立,例如SQLalchemy和pymysql
index_col: 选择哪列作为index
coerce_float:将数字形字符串转为float
parse_dates:将某列日期型字符串转换为datetime型数据
columns:选择想要保留的列
chunksize:每次输出多少行数据