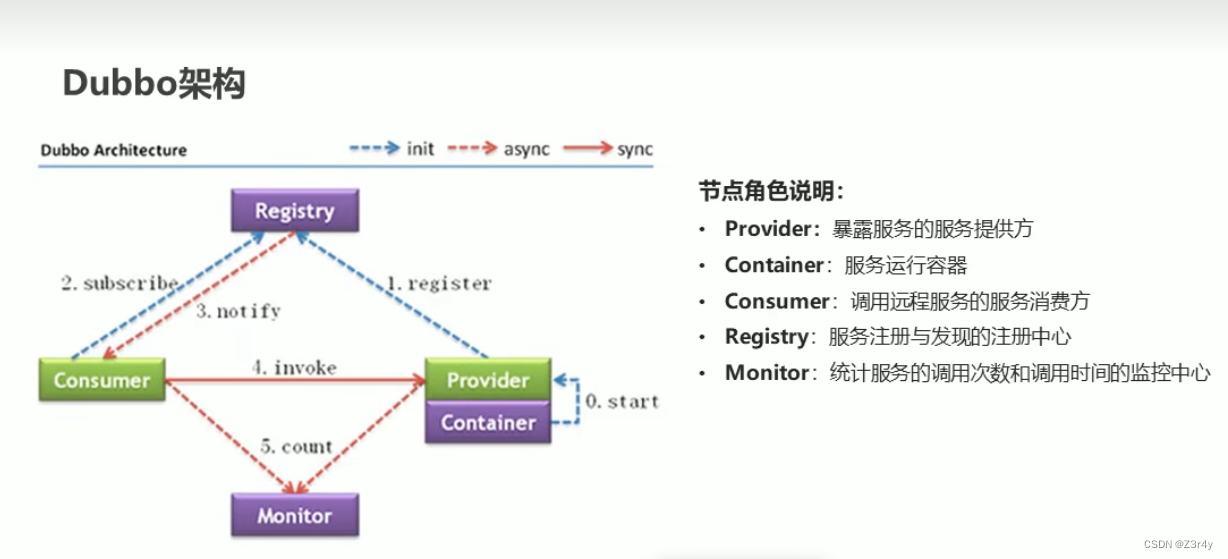
思路分析:
- 使用DFS算法进行全排列,递归地尝试每个可能的排列方式。
- 使用
path向量保存当前正在生成的排列,当其大小达到输入数组的大小时,将其加入结果集。 - 使用
numvisited向量标记每个数字是否已经被访问过,以确保每个数字在一个排列中只使用一次。 - 在递归过程中,对于每个未访问的数字,将其加入排列,标记为已访问,然后递归生成下一个位置的数字。
- 在递归完成后,需要回溯,撤销对当前数字的标记,同时将其从排列中移除,以尝试其他可能的排列。
- 使用额外的
visited向量标记每个数字是否已经在当前排列中被访问过,避免重复访问。
class Solution {
vector<vector<int>> result; // 存储最终的全排列结果
vector<int> path; // 存储当前正在生成的排列
// 深度优先搜索函数,生成全排列
void dfs(vector<int>& nums, vector<bool> numvisited) {
vector<bool> visited(21, false); // 用于标记数字是否被访问过
for (int i = 0; i < nums.size(); i++) {
// 如果当前数字已经在当前排列中使用过,则跳过
if (numvisited[i] == true)
continue;
path.push_back(nums[i]); // 将当前数字加入排列
numvisited[i] = true; // 标记当前数字为已访问
// 如果当前排列长度等于数组长度,说明已经生成一个完整的排列,加入结果集
if (path.size() == nums.size())
result.push_back(path);
// 如果当前数字在当前排列中未被访问过,则递归生成下一个位置的数字
if (visited[nums[i] + 10] != true) {
visited[nums[i] + 10] = true;
dfs(nums, numvisited);
}
path.pop_back(); // 回溯,将当前数字从排列中移除
numvisited[i] = false; // 回溯,撤销对当前数字的标记
}
visited.clear(); // 清除标记数组,节约空间。
}
public:
// 主函数,用于生成给定数组的全排列(包含重复元素)
vector<vector<int>> permuteUnique(vector<int>& nums) {
vector<bool> numvisited(nums.size(), false); // 初始化数字访问标记数组
dfs(nums, numvisited); // 调用深度优先搜索函数生成全排列
return result; // 返回最终结果
}
};



![[leetcode~dfs]1261. 在受污染的二叉树中查找元素](https://img-blog.csdnimg.cn/direct/12acb393fa414fe2bb0638f023b681fb.png)







![[CISCN2019 华北赛区 Day2 Web1]Hack World 不会编程的崽](https://img-blog.csdnimg.cn/direct/8df17b174b844fa19c7c207d219423c9.png)