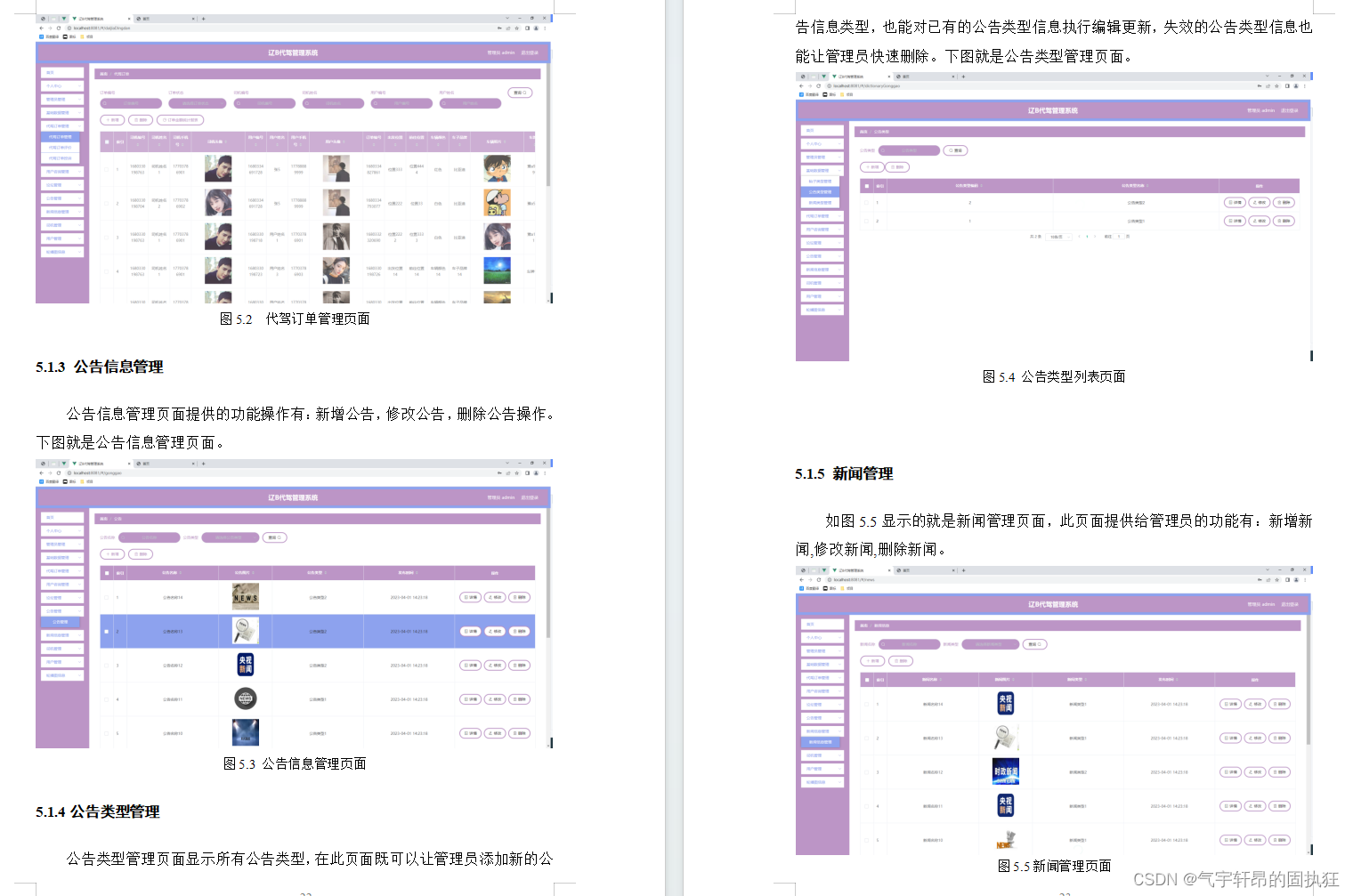
一.内部排序
1.概念
- 什么是排序?是将一个任意排列的记录或者是数据元素,排列成按关键字有序的序列
- 什么是排序方法是稳定的?按照关键字排序的ki=kj,在排序之后,两个关键字相等的记录的顺序与排序之前相同,若相反,则称为关键字是不稳定的。
- 什么是内部排序?指的是待排序记录序列存放在计算机内存随机存储器序列中
- 什么是外部排序?指的是待排序记录数量太多,一部分存放在外存中,在排序时需要进行存取磁盘操作。
2.插入排序
插入排序算法简单,适合记录数量少进行排序,不适合数量大的元素进行排序。
(1)直接插入排序Straight Insertion Sort
- 什么是直接插入排序?将一个记录插入到已排好序的有序序列中,如果采用顺序表存储方式存储的话,插入后需要后移元素,如果改进效率可以使用折半插入。
- 直接插入排序的时间复杂度是多少?
- 代码?
首先给出数据元素的定义
typedef int keytype;//为了方便定义整型
#define maxsize 10
typedef struct{
keytype key;//关键字数据项
keytype otherinfor;//其他数据项
}elemtype;
typedef struct{
elemtype r[maxsize+1];//第一个元素用作临时存储
int length=0;
}Sqlist;void straightSort(Sqlist L)
{
for(int i=2;i<=L.length;++i)
{
if(L.r[i-1].key>L.r[i].key)
{
L.r[0].key=L.r[i].key;//存放待插元素
L.r[i].key=L.r[i-1].key;//先后移一位元素,这也是后移向前插的开始
int j;
for(j=i-2;L.r[0].key<L.r[j].key;--j)
{
L.r[j+1].key=L.r[j].key;
}
L.r[j+1]=L.r[0];//插入到正确位置,因为r[j]不小于r[0]所以,0存在j的后面j+1
}
}
OutPut(L);
}(2)希尔排序Shell's Sort
- 什么是希尔排序?基本思想是先将整个记录序列分割成若干子序列,分别对若干子序列进行插入排序,逐渐缩小分割增量,待整个序列“基本有序”时,再整体进行一次插入排序。
void shellInsert(Sqlist L,int dk)
{
//前后记录增量位置为dk
for(int i=dk+1;i<=L.length;++i)
{
if(L.r[i].key<L.r[i-dk].key)
{
L.r[0].key=L.r[i].key;//存放要插入的元素
int j;
for(j=i-dk;j>0&&L.r[0].key<L.r[j].key;j-=dk)
{
L.r[j+dk]=L.r[j];//向后移动
}
L.r[j+dk]=L.r[0];//后移之后把元素赋值
}
}
}
void shellSort(Sqlist L,int delta[],int t)
{
//按增量delta[]对顺序表L进行排序
for(int k=0;k<t;++k)
{
shellInsert(L,delta[k])//一趟增量为delta的插入排序
}
}关于增量序列delta[],尚未有人得出较好的结论。有人指出当时,希尔排序的时间复杂度是
,其中t是排序趟数,k<=t
3.快速排序Quick Sort
(1)冒泡排序Bubble Sort
- 冒泡排序的思想是什么?首先将第一个记录与第二个记录进行比较,如果逆序就swap,一直比较到最后一个记录的位置上;每一趟会比较出一个剩余最大的元素 放在后面,第i趟冒泡排序是从第1个到第n-i+1个依次比较。
(2)快速排序Quick Sort
- 快速排序如何选择枢轴Pivot?由于如果记录序列最初是基本有序,然后快排序列的Pivot选择第一个元素的话,那么整个流程类似于冒泡排序,所以Pivot通常采用“三者取中”,即比较L.r[s].key和L.r[t].key和L.r[(s+t)/2],取三者中其关键字的中值作为枢轴。
- 快速排序的思想?首先按照“三者取中”的原则选取一个Pivot,然后进行一趟排序,排序的结果是,将所有小于Pivot的元素移动到Pivot左侧,所有大于Pivot的元素移动到Pivot右侧,继续对Pivot左右两侧分别快排。And每一趟排序选取left和right,假设枢轴值是pivotkey,如果pivotkey大于high那么交换pivotkey和high,high--。
int Partition(Sqlist& L,int low,int high)
{
//交换顺序表中子表r[low..high]
L.r[0].key=L.r[low].key;
int pivotkey=L.r[low].key;//将最小值赋值给枢轴
while(low<high)
{
while(low<high&&L.r[high].key>=pivotkey)--high;
L.r[low]=L.r[high];//将比枢轴小的记录移动到低端
while(low<high&&L.r[low].key<=pivotkey)++low;
L.r[high]=L.r[low];//将比枢轴大的记录移动到高端
}
L.r[low]=L.r[0];//将枢轴记录到位
return low;//返回枢轴位置
}
void quickSort(Sqlist& L,int low,int high)
{
if(low<high)
{
int pivotloc=Partition(L,low,high);//将L一分为二
quickSort(L,low,pivotloc);//对低表进行递归排序
quickSort(L,pivotloc+1,high);//对高表进行递归排序
}
}快速排序被认为在所有同数量级O(nlogn)的排序中,其性能最好。
4.选择排序Selection Sort
(1)简单选择排序Simple Selection Sort
- 简单选择排序的基本思想?在第i趟选择的过程中,从剩下n-i+1个元素中找到关键字最小的元素,与第i个元素进行交换,作为有序序列中的第i个元素。
- 时间复杂度为
(2)堆排序Heap Sort
- 什么是堆?n个元素的序列{k1,k2,...,kn},当且仅当满足如下关系时,称之为堆:
或者
其中
- 若将此序列对应的一维数组看成是一个完全二叉树,堆表明什么含义?完全二叉树所有非终端结点的值不大于(或不小于)其左右孩子结点的值。那么堆顶元素必为序列中n个元素的最小值或者最大值。
- 使用堆排序应该解决哪两个问题?如何由一个无序序列建成一个堆;如何在输出堆顶元素之后,调整剩余元素称为一个新的堆。
- 堆排序的代码?
void HeapAdjust(HeapType& H,int s,int m)
{
elemtype rc=H.r[s];
for(int j=2*s;j<=m;j*=2)//沿key较大的孩子结点向下筛选
{
if(j<m&&H.r[j].key<H.r[j+1].key)
++j;//j为key
if(rc.key>=H.r[j].key)break;
H.r[s]=H.r[j];
s=j;
}
H.r[s]=rc;//插入
}
void HeapSort(HeapType& H)
{
//对顺序表H进行堆排序
for(int i=H.length/2;i>0;i--)
{
HeapAdjust(H,i,H.length);
}
for(int i=H.length;i>1;--i)
{
swap(H.r[1],H.r[i]);//将堆顶记录,最后一个记录相互交换
HeapAdjust(H,1,i-1);//将H.r[1..i-1]重新调整为大顶堆
}
}5.归并排序Merging Sort
- 什么是归并排序(什么是2-路归并排序)?假设有n个记录,将每一个记录看作n个有序的记录,两两归并,得到(n/2)向上取整 个长度为2或者1的有序序列,再继续两两归并,如此重复得到n个有序的序列为止。
- 代码是什么
void merge(int R[], int low, int mid, int high)
{
int len = high - low + 1;
int* temp = new int[len];
int i = low, j = mid + 1;
int k = 0;
while (i <= mid && j <= high) {
if (R[i] <= R[j]) {
temp[k] = R[i];
k++;
i++;
}
else {
temp[k] = R[j];
k++;
j++;
}
}
while (i <= mid) {
temp[k] = R[i];
k++;
i++;
}
while (j <= high) {
temp[k] = R[j];
k++;
j++;
}
for (k = 0; k < len; k++)
R[low + k] = temp[k];
}
void mergeSort(int R[], int low, int high){//主排序函数
if (low < high) {
int mid = (low + high) / 2;
mergeSort(R, low, mid);//左侧继续排序
mergeSort(R, mid+1, high);//右侧继续排序
merge(R, low, mid, high);//合并
}
}