问题重述:
博物馆是公共文化服务体系的重要组成部分。国家文物局发布, 2021 年我国新增备案博物馆 395 家,备案博物馆总数达 6183 家,排名全球前列;5605 家博物馆实现免费开放,占比达 90%以上;全国博物馆举办展览 3.6 万个,教育活动 32.3 万场;虽受疫情影响,全国
博物馆仍接待观众 7.79 亿人次。
但在总体繁荣业态下,一些地方博物馆仍存在千馆一面、公共文化服务供给同质化的尴尬局面,在发展定位、体系布局、功能发挥等方面尚需完善提升。这给博物馆基于自身特色进一步迈向真正的公共性提出了新课题,也即坚持守正创新,坚持直面公众和社会的公共文化服务的创造性转化、创新性发展。
为了提升博物馆公共服务水平,课题组收集大众点评平台上用户对南京市朝天宫、瞻园、甘熙宅第、江宁织造博物馆和六朝博物馆五个博物馆的点评数据,数据字段主要包括:用户编号、评论内容、评论时间等。
问题1:针对每位用户的评论,建立情感判别模型,判断评论内容的情感正反方向,输出评论内容的情感方向为正面、中立、负面, 并统计每个博物馆历史评论各个方向情感的比例分布情况。
问题 2:综合考虑评论内容中情感词、程度副词、否定词、标点符合等等影响情感方向的指标,建立情感得分评价模型,得到每位户评论的情感得分,并基于得分对五个博物馆进行客观排名。
问题 3:针对每位用户评论的内容,可通过事件抽取或实体抽取算法,从评论内容中抽取影响用户情感的关键事件或因素,如某用户评论“非常不错!环境高大上!好多是最近房地产开发盖新房子时新挖出来的,不错“,可得知该评论为正面情感,影响其正面评价的是” 房地产开发盖新房子时新挖的“、”环境高大上“两个因素。基于上述抽取的关键事件或影响因素,综合分析得到影响用户对五个博物馆情感的影响因素
问题 4:基于上述分析得到的数据结果,为五个博物馆撰写一段提升公共服务水平的可行性建议,建议要有理有据,且具有一定的可操作性。
问题分析
- 建立情感判别模型,对评论内容的情感方向进行分类(正面、中立、负面),并统计每个博物馆历史评论各个方向情感的比例。
- 建立情感得分评价模型,考虑情感词、程度副词、否定词、标点符号等因素,为每条评论打分,并基于得分对博物馆进行排名。
- 通过事件抽取或实体抽取算法,从评论中抽取影响用户情感的关键事件或因素,分析影响用户情感的因素。
- 基于以上分析,为五个博物馆提出提升公共服务水平的可行性建议。
解题代码
使用python脚本对数据集进行分析
import pandas as pd
# 加载数据
data_path = '数据-五个博物馆评论内容.xlsx'
df = pd.read_excel(data_path)
# 数据清洗
# 转换评论星级至正确的比例
df['评论星级(抓取的数据/10=评论星级)'] = df['评论星级(抓取的数据/10=评论星级)'].apply(lambda x: x / 10)
# 确保所有文本字段都是字符串类型
df['评论内容'] = df['评论内容'].astype(str)
# 处理时间数据,这里简单示例,实际情况可能需要根据时间数据的具体乱码情况做更复杂的处理
# 假设我们只是转换时间格式,并忽略乱码问题
df['时间(部分时间有乱码,或无法抓取,是平台后端问题,爬虫无法解决)'] = pd.to_datetime(df['时间(部分时间有乱码,或无法抓取,是平台后端问题,爬虫无法解决)'], errors='coerce')
# 查看处理后的数据
print(df.head())
# 注意:这里的时间处理仅为示例,根据实际乱码情况可能需要更详细的处理步骤
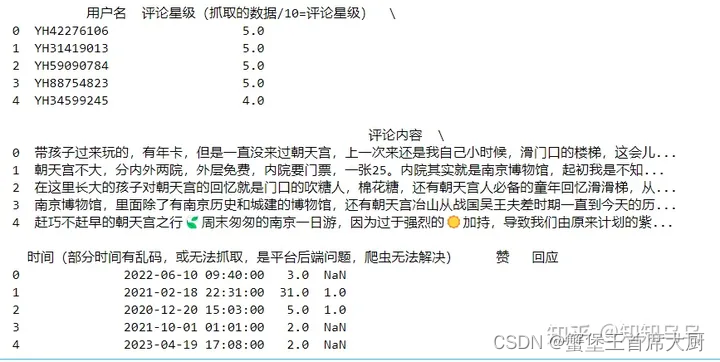
对于“赞”和“回应”这样的字段,NaN可能表示没有人点赞或回应。在进行数据分析时,我们可以选择将这些NaN值替换为0,表示“没有赞”或“没有回应”,而不是直接删除这些记录。这样,我们可以保留更多的评论数据进行分析,因为评论内容本身对于情感分析来说是最重要的。
# 处理NaN值,将“赞”和“回应”字段中的NaN替换为0
df['赞'].fillna(0, inplace=True)
df['回应'].fillna(0, inplace=True)
# 确认整个数据集处理情况
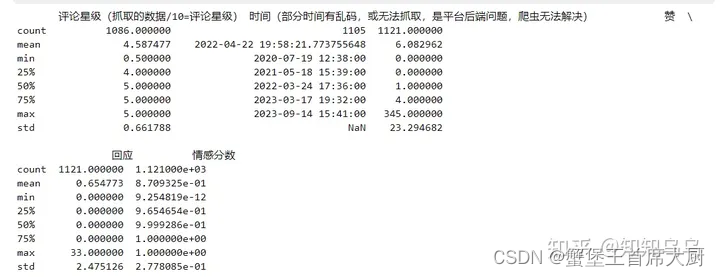
print(df.describe()) # 展示数据的统计概况来确认处理范围
# 对整个DataFrame按情感分数排序
df_sorted = df.sort_values(by='情感分数', ascending=False)
# 显示情感分数最高的评论
print("最积极的评论:")
print(df_sorted.iloc[0])
# 显示情感分数最低的评论
print("\n最消极的评论:")
print(df_sorted.iloc[-1])
# 如果想显示更多的积极或消极评论,可以调整iloc的索引,例如使用df_sorted.iloc[:5]来查看前5个最积极的评论

import jieba
# 自定义情感词典、程度副词典和否定词典
sentiment_dict = {
"好": 1,
"高兴": 2,
"喜欢": 2,
"棒": 2,
"不错": 1,
"差": -2,
"失望": -2,
"糟": -2,
"讨厌": -2,
}
degree_dict = {
"非常": 1.5,
"很": 1.2,
"稍微": 0.8,
"一点": 0.5,
}
negation_dict = {
"不": -1,
"没": -1,
"无": -1,
}
# 情感得分计算函数
def calculate_sentiment_score(text):
words = list(jieba.cut(text))
score = 0
negation = 1
degree = 1
for word in words:
if word in negation_dict:
negation = -1
elif word in degree_dict:
degree = degree_dict[word]
elif word in sentiment_dict:
score += sentiment_dict[word] * negation * degree
# Reset negation and degree
negation = 1
degree = 1
return score
# 测试代码
comments = [
"非常喜欢这个博物馆,展览很棒",
"不是很好,稍微有点失望",
"没那么差,但也没有很好",
"真的很讨厌,完全失望",
]
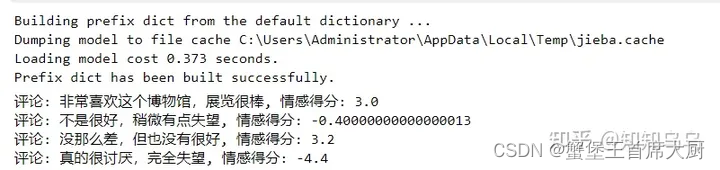
for comment in comments:
print(f"评论: {comment}, 情感得分: {calculate_sentiment_score(comment)}")
import pandas as pd
import jieba
xls = pd.ExcelFile(data_path)
all_museums_df_list = []
for sheet_name in xls.sheet_names:
df = pd.read_excel(xls, sheet_name=sheet_name)
df['评论内容'] = df['评论内容'].astype(str) # 确保评论内容为字符串
df['情感得分'] = df['评论内容'].apply(calculate_sentiment_score)
df['博物馆名称'] = sheet_name
all_museums_df_list.append(df)
all_museums_df = pd.concat(all_museums_df_list, ignore_index=True)
museum_avg_sentiment = all_museums_df.groupby('博物馆名称')['情感得分'].mean()
museum_ranking = museum_avg_sentiment.sort_values(ascending=False)
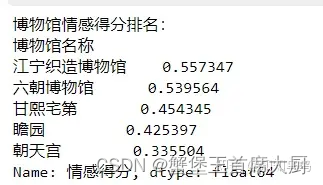
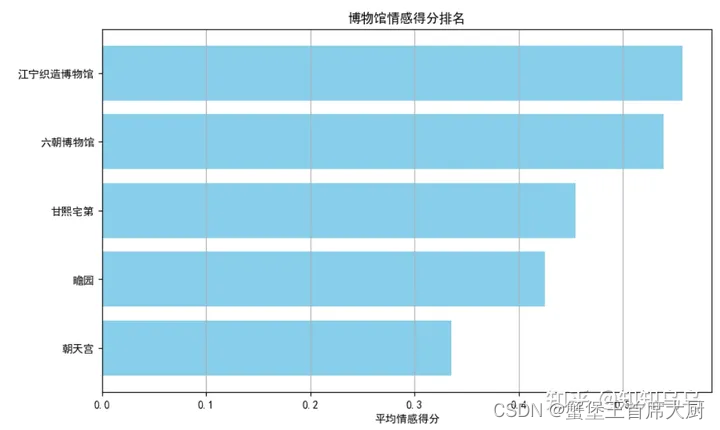
print("博物馆情感得分排名:")
print(museum_ranking)
import matplotlib.pyplot as plt
# 已给出的博物馆情感得分排名数据
museum_names = ["江宁织造博物馆", "六朝博物馆", "甘熙宅第", "瞻园", "朝天宫"]
sentiment_scores = [0.557347, 0.539564, 0.454345, 0.425397, 0.335504]
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 绘图
plt.figure(figsize=(10, 6))
plt.barh(museum_names, sentiment_scores, color='skyblue')
plt.xlabel('平均情感得分')
plt.title('博物馆情感得分排名')
plt.gca().invert_yaxis() # 让最高得分的博物馆显示在最上面
plt.grid(axis='x')
# 显示图形
plt.show()
import pandas as pd
import jieba.analyse
# 初始化一个空字典来存储每个博物馆的关键词
museum_keywords = {}
# 遍历每个sheet
for sheet_name in xls.sheet_names:
df = pd.read_excel(xls, sheet_name=sheet_name)
df['评论内容'] = df['评论内容'].astype(str) # 确保评论内容为字符串类型
# 初始化一个列表来存储当前博物馆的所有关键词
keywords_list = []
# 提取每条评论的关键词
for text in df['评论内容']:
keywords = jieba.analyse.extract_tags(text, topK=5)
keywords_list.extend(keywords)
# 存储当前博物馆的关键词
museum_keywords[sheet_name] = keywords_list
# 汇总分析结果
for museum, keywords in museum_keywords.items():
print(f"博物馆: {museum}, 关键词: {set(keywords)}")

详细的视频讲解(代码文件内附视频讲解)

![Leetcode每日一题[C++]-1261.在受污染的二叉树中查找元素](https://img-blog.csdnimg.cn/direct/4d2fa0a624d542e0a8ef45f236917367.png)