一、背景
在大数据领域,数据分析、实时数仓已经成为平台上常见的功能之一。无论是进行实时分析还是离线分析,都离不开数仓中的表数据。
特别是在实时分析领域,查阅实时数据、历史数据以及历史变更数据是非常常见的需求。而这些功能的实现主要依赖于数仓中的实时表、流水表和快照表。
本文将结合前几篇关于实时数仓同步的内容,介绍实际应用中的案例场景,帮助读者更深入地理解这些功能的实际应用价值。
- [Mysql] 业务数据 - 用户表全量数据:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
- [Mysql] 2023-06-02 业务数据新增了一名用户,且更改了tom的手机号,此时表数据如下:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 444 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 |
| 4 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 |
加粗为更新/新增数据
- [大数据平台] 2023-06-02日业务人员在大数据平台中查看用户表实时数据,期望数据和Mysql业务数据一致,如下:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 444 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 |
| 4 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 |
- [大数据平台] 2023-06-03 日业务人员在大数据平台中查看2023-06-02日用户表的历史数据,期望数据如下:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
- [大数据平台] 2023-06-02日业务人员在大数据分析平台中查看用户表实时变更记录,数据如下:
| id | name | phone | gender | create_time | update_time | op(操作类型) | before(变更前数据) | dt |
|---|---|---|---|---|---|---|---|---|
| 3 | tom | 444 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 | u | {3,tom,333,男,…} | 2023-06-02 |
| 4 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 | c | null | 2023-06-02 |
根据以上需求,我们可以按照业务表一比三的表比例创建三张实时数仓表:实时表、快照表和流水表。
然而,离线数仓并不适合满足这一需求,原因如下:
- 数据精确性问题: 对于对数据精确度要求较高的场景,采用 T+1 的同步方式可能会导致数据不一致的问题。更详细的问题分析和解决方案可以参考我另一篇文章:深入数仓离线数据同步:问题分析与优化措施。
- 同步延迟问题: 离线数仓的同步通常为 T+1,而上述需求要求实时查看当天业务数据的变更情况。
接下来,我们将探讨更适合此需求的实现方案。
二、技术架构
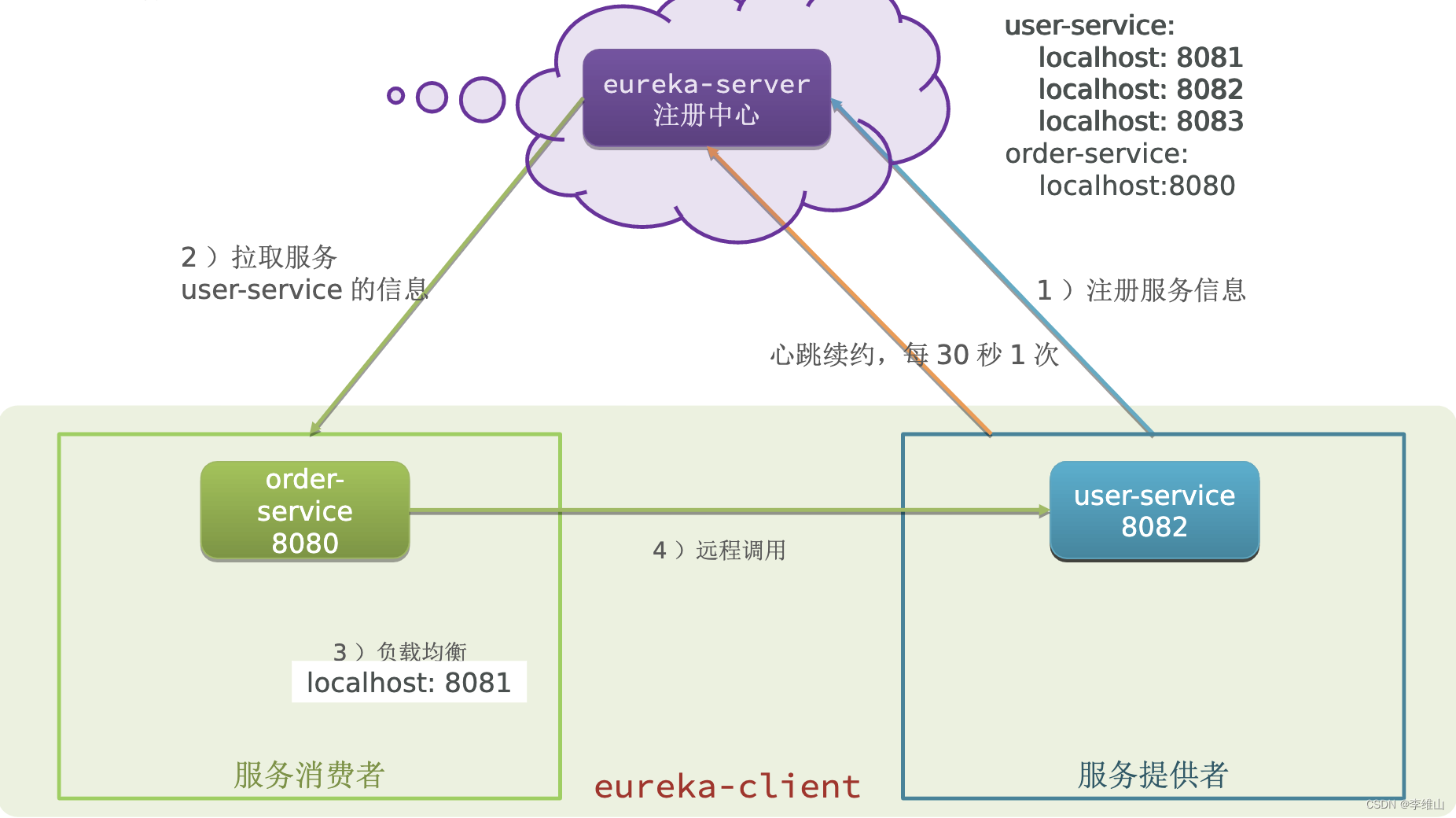
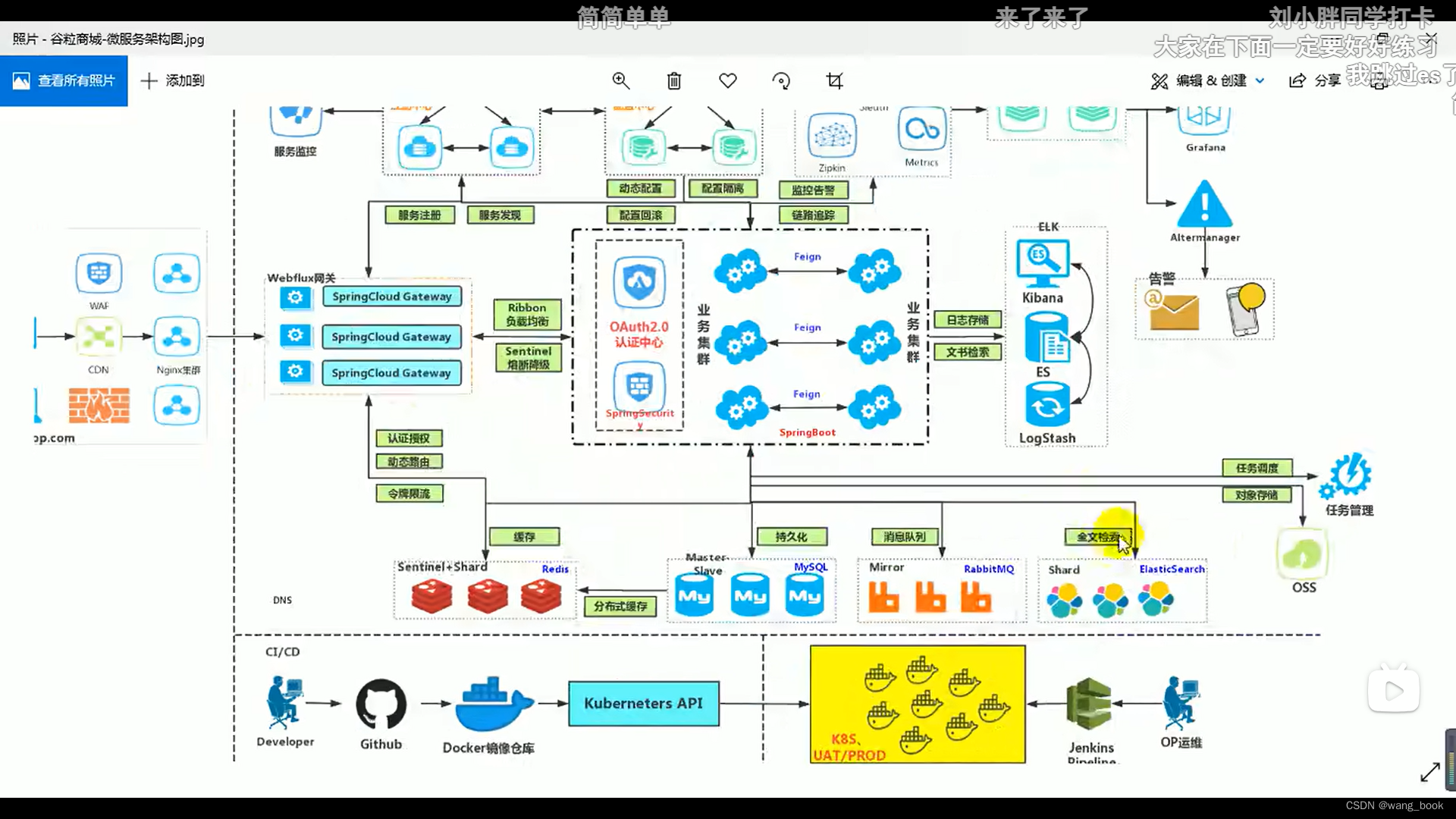
鉴于业务数据通常存储在关系型数据库中,这里选择采用Flink-CDC持续读取binlog日志进行实时同步。为了保证实时数据能够高效写入下游并支持用户OLAP查询分析,这里选择了企业中常见的MMP库Doris作为实时数仓的存储层。整体架构如下图所示:
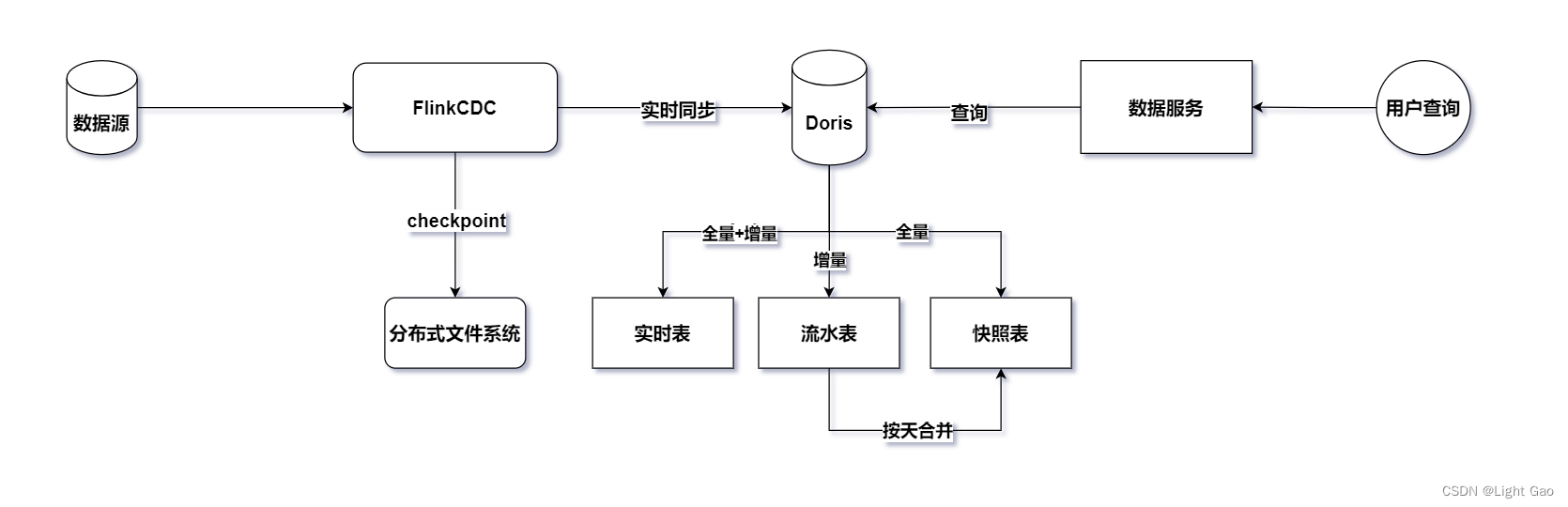
关于图片中的实时表、流水表、快照表各自详细的实现方式均可在文章结尾相关资料中查看对应文章。
三、实现方式
3.1、表设计
- 实时表:以id 为unique key从而保证表数据唯一性
CREATE TABLE `example_user_real`
(
`id` INT NOT NULL COMMENT '用户id',
`name` STRING NULL COMMENT '用户昵称',
`phone` STRING NULL COMMENT '手机号',
`gender` CHAR(5) NULL COMMENT '用户性别',
`create_time` DATETIMEV2(0) NULL COMMENT '用户注册时间',
`update_time` DATETIMEV2(0) NULL COMMENT '用户更新时间'
) ENGINE=OLAP
UNIQUE KEY(`id`)
COMMENT '用户实时表'
DISTRIBUTED BY HASH(id) BUCKETS AUTO;
- 流水表:以id、update_time、dt 为unique key从而保证天粒度秒级唯一性,同时采用动态分区按天进行划分
CREATE TABLE `example_user_stream`
(
`id` largeint(40) NOT NULL COMMENT '用户id',
`update_time` datetime NULL COMMENT '用户更新时间',
`dt` date NULL COMMENT '流水日期',
`create_time` datetime NULL COMMENT '用户注册时间',
`name` varchar(50) NOT NULL COMMENT '用户昵称',
`phone` largeint(40) NULL COMMENT '手机号',
`gender` varchar(5) NULL COMMENT '用户性别',
`op` varchar(4) NOT NULL COMMENT '每条数据的操作类型:r/c/u/d',
`before` STRING NULL COMMENT '变更前数据',
`binlog` STRING NULL COMMENT 'binlog全量日志'
) ENGINE=OLAP
UNIQUE KEY(`id`, `update_time`, `dt`)
COMMENT '用户流水表'
PARTITION BY RANGE(dt)()
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES
(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-90",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "8"
);
- 快照表:以id、dt 为unique key从而保证天粒度唯一性,同时采用动态分区按天进行划分
CREATE TABLE `example_user_snapshot`
(
`id` largeint(40) NOT NULL COMMENT '用户id',
`dt` date NULL COMMENT '流水日期',
`name` varchar(50) NOT NULL COMMENT '用户昵称',
`phone` largeint(40) NULL COMMENT '手机号',
`gender` varchar(5) NULL COMMENT '用户性别',
`create_time` datetime NULL COMMENT '用户注册时间',
`update_time` datetime NULL COMMENT '用户更新时间'
) ENGINE=OLAP
UNIQUE KEY(`id`, `dt`)
COMMENT '用户快照表'
PARTITION BY RANGE(dt)()
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES
(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-90",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "8"
);
关于doris数据模型及动态分区语法可参考文章底部相关资料
3.2、实时同步逻辑
3.2.1、前提介绍
-
首先,由于实时流水表同步使用Flink-cdc读取关系型数据库,flink-cdc提供了四种模式: “initial”,“earliest-offset”,“latest-offset”,“specific-offset” 和 “timestamp”。本文使用的Flink-connector-mysq是2.3版本,这里简单介绍一下这四种模式:
-
initial(默认):在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog。 -
earliest-offset:跳过快照阶段,从可读取的最早 binlog 位点开始读取 -
latest-offset:首次启动时,从不对受监视的数据库表执行快照, 连接器仅从 binlog 的结尾处开始读取,这意味着连接器只能读取在连接器启动之后的数据更改。 -
specific-offset:跳过快照阶段,从指定的 binlog 位点开始读取。位点可通过 binlog 文件名和位置指定,或者在 GTID 在集群上启用时通过 GTID 集合指定。 -
timestamp:跳过快照阶段,从指定的时间戳开始读取 binlog 事件。
-
-
这里采用
initial模式作为实时同步方式,先全量后增量,这是由于此次同步多张表需要对 binlog 数据进行解析及判断更新操作类型,因此,Flink CDC SQL 文件方式的表建立不再满足我们的要求。为了更好地实现这一功能,我们需要采用 API 方式来构建解决方案,代码如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // 设置捕获的数据库, 如果需要同步整个数据库,请将 tableList 设置为 ".*".
.tableList("yourDatabaseName.yourTableName") // 设置捕获的表
.username("yourUsername")
.password("yourPassword")
.startupOptions(StartupOptions.timestamp(1685548800000L)) // 从2023-06-01零点处读取binlog
.deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置 3s 的 checkpoint 间隔
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// 设置 source 节点的并行度为 4
.setParallelism(4)
.print().setParallelism(1); // 设置 sink 节点并行度为 1
env.execute("Print MySQL Snapshot + Binlog");
}
}
代码摘自mysql-cdc-connector官网示例
3.2.2、实时表同步阶段
实时表同步十分简单,只需要在Flink程序中编写flinkSQL即可实现,FlinkSQL如下:
# FlinkSQL 创建Mysql User表
create table mysql_user(
`id` INT,
`name` STRING,
`phone` STRING,
`gender` CHAR(5),
`create_time` TIMESTAMP(0),
`update_time` TIMESTAMP(0),
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector'='mysql-cdc',
'hostname'='10.185.163.177',
'port' = '80',
'username'='rouser',
'password'='123456',
'database-name' = 'database',
'table-name'='user'
);
# FlinkSQL 创建Doris User实时表
create table doris_user(
`id` INT,
`name` STRING,
`phone` STRING,
`gender` STRING,
`create_time` TIMESTAMP(0),
`update_time` TIMESTAMP(0)
) WITH (
'password'='password',
'connector'='doris',
'fenodes'='11.113.208.103:8030',
'table.identifier'='database.user',
'sink.label-prefix'='唯一任务标识,每次启动都要唯一',
'username'='username'
);
# 实时写入
insert into doris_user select * from mysql_user;
3.2.3、流水表、快照表全量同步阶段
- 接下来我们将从全量同步开始逐步演示同步过程,这里我们以2023-06-0日的[Mysql]业务数据为例,此时表数据如下:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
- 此时Flink应用启动获取到的数据如下:仅展示一条
{
"before": null,
"after": { # 实际数据
"id": 1,
"name": "jack",
"phone": "111",
"gender": "男",
"create_time": "2023-06-01T05:00:00Z", # 该日期是UTC时间,只需增加8小时即可转化为北京时间
"update_time": "2023-06-01T05:00:00Z" # 该日期是UTC时间,只需增加8小时即可转化为北京时间
},
"source": { # 元数据
"version": "1.6.4.Final",
"connector": "mysql",
"name": "mysql_binlog_source",
"ts_ms": 0,
"snapshot": "false",
"db": "yushu_dds",
"sequence": null,
"table": "user",
"server_id": 0,
"gtid": null,
"file": "",
"pos": 0,
"row": 0,
"thread": null,
"query": null
},
"op": "r", # 记录每条数据的操作类型[重要]
"ts_ms": 1705471382867,
"transaction": null
}
-
在我们使用 Flink CDC MySQL 同步数据时,默认采用
initial模式,这意味着首先进行全量同步,然后再进行增量同步。因此,在区分全量和增量同步时,关键在于观察获取到的数据中的op字段。op字段是用来记录每条数据的操作类型的标志。具体的操作类型如下:-
op=d代表删除操作 -
op=u代表更新操作 -
op=c代表新增操作 -
op=r代表全量读取,而不是来自 binlog 的增量读取
-
-
在 Flink 程序中,只需要通过
op=r即可筛选出全量数据。在全量数据同步阶段只需将op=r的业务数据直接同步至快照表(之所以将全量数据同步至快照表是为了次日凌晨与流水表变更数据合并成完整数据),流水表在全量阶段无需同步,导入语句如下:
# 快照表
INSERT INTO example_user_snapshot (id, dt, name, phone, gender, create_time, update_time)
VALUES
(1, '2023-06-01', 'jack', 111, '男', '2023-06-01 13:00:00', '2023-06-01 13:00:00'),
(2, '2023-06-01', 'jason', 222, '男', '2023-06-01 13:00:00', '2023-06-01 13:00:00'),
(3, '2023-06-01', 'tom', 333, '男', '2023-06-01 13:00:00', '2023-06-01 13:00:00');
- 此时doris快照表数据如下所示:
| id | dt | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|---|
| 1 | 2023-06-01 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | 2023-06-01 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | 2023-06-01 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
- 此时doris流水表数据如下所示:全量阶段流水表无需同步
| id | update_time | dt | create_time | name | phone | gender | op | before | binlog |
|---|---|---|---|---|---|---|---|---|---|
| NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
3.2.4、流水表、快照表增量同步阶段
- 这里我们以2023-06-02日的[Mysql]业务数据为例,新增了一名tony用户,且更改了tom的手机号,此时表数据如下:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 444 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 |
| 4 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 |
- 此时Flink应用获取到的数据如下:
# 新增tony变更数据如下
{
"before": null,
"after": {
"id": 4,
"name": "tony",
"phone": "666",
"gender": "男",
"create_time": "2023-06-02T02:00:00Z",
"update_time": "2023-06-02T02:00:00Z"
},
"source": {
# 元数据信息忽略
},
"op": "c", # 操作类型
"ts_ms": 1706768344113,
"transaction": null
}
# tom手机号333->444变更数据如下
{
"before": {
"id": 3,
"name": "tom",
"phone": "333",
"gender": "男",
"create_time": "2023-06-01T05:00:00Z",
"update_time": "2023-06-01T05:00:00Z"
},
"after": {
"id": 3,
"name": "tom",
"phone": "444",
"gender": "男",
"create_time": "2023-06-01T05:00:00Z",
"update_time": "2023-06-01T23:00:00Z"
},
"source": {
# 元数据信息忽略
},
"op": "u", # 操作类型
"ts_ms": 1706768454904,
"transaction": null
}
- 当 Flink 同步程序接收到
op=c/u/d表示增量更新数据时,提取其中的op、before和after数据。接着将这些信息拼装成 Doris 的INSERT语句后插入到流水表中,此时流水表数据如下所示:
| id | update_time | dt | create_time | name | phone | gender | op | before | binlog |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 2023-06-02 10:00:00 | 2023-06-02 | 2023-06-02 10:00:00 | tony | 555 | 男 | c | NULL | {“before”:null,“after”:{“id”:4,“name”:“tony”,“phone”:“666”,“gender”:“男”,“create_time”:“2023-06-02T02:00:00Z”,“update_time”:“2023-06-02T02:00:00Z”},“source”:{“version”:“1.6.4.Final”,“connector”:“mysql”,“name”:“mysql_binlog_source”,“ts_ms”:1706768344000,“snapshot”:“false”,“db”:“yushu_dds”,“sequence”:null,“table”:“user”,“server_id”:2307031958,“gtid”:“71221bfd-56e8-11ee-8275-fa163e4ecceb:33719321”,“file”:“3509-binlog.000191”,“pos”:643757739,“row”:0,“thread”:null,“query”:null},“op”:“c”,“ts_ms”:1706768344113,“transaction”:null} |
| 3 | 2023-06-02 08:00:00 | 2023-06-02 | 2023-06-02 13:00:00 | tom | 444 | 男 | u | {“id”:3,“name”:“tom”,“phone”:“333”,“gender”:“男”,“create_time”:“2023-06-01T05:00:00Z”,“update_time”:“2023-06-01T05:00:00Z”} | {“before”:{“id”:3,“name”:“tom”,“phone”:“333”,“gender”:“男”,“create_time”:“2023-06-01T05:00:00Z”,“update_time”:“2023-06-01T05:00:00Z”},“after”:{“id”:3,“name”:“tom”,“phone”:“444”,“gender”:“男”,“create_time”:“2023-06-01T05:00:00Z”,“update_time”:“2023-06-01T23:00:00Z”},“source”:{“version”:“1.6.4.Final”,“connector”:“mysql”,“name”:“mysql_binlog_source”,“ts_ms”:1706768454000,“snapshot”:“false”,“db”:“yushu_dds”,“sequence”:null,“table”:“user”,“server_id”:2307031958,“gtid”:“71221bfd-56e8-11ee-8275-fa163e4ecceb:33719761”,“file”:“3509-binlog.000191”,“pos”:692873739,“row”:0,“thread”:null,“query”:null},“op”:“u”,“ts_ms”:1706768454904,“transaction”:null} |
- 因增量数据无需同步至快照表,故此时快照表与之前06-01号一样保持不变,快照表数据如下:
| id | dt | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|---|
| 1 | 2023-06-01 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | 2023-06-01 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | 2023-06-01 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
3.2.5、合并阶段
在合并阶段,我们将流水表前一天的数据与快照表中前两天的数据进行整合,最终得到前一天的全量数据,并将其写入至快照表的前一天分区。
合并任务会在满足以下任意一个条件时触发:
- 当binlog数据中的日期为第二天。
- 当凌晨过了5分钟(这是一个自定义的时间阈值)。
第二个条件的存在是因为业务数据很可能在凌晨00:00 ~ 00:05 分之间没有增量数据。因此,即使在没有业务数据同步的情况下,我们仍然可以通过第二个条件触发合并阶段,确保数据的完整性和准确性。
- 这里我们假设2023-06-03 00:05:00 触发合并阶段为例,此时业务数据如下所示:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 444 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 |
| 4 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 |
- flink程序中无新增数据,但由于满足第二个触发条件,在flink程序中将会触发合并任务[可用单独线程实现],此时执行的doris合并语句如下:
INSERT INTO example_user_snapshot (id, dt, name, phone, gender, create_time, update_time)
SELECT
id,
'2023-06-02' as dt, -- 通过固定dt字段值从而写入快照表p20230602分区中
name,
phone,
gender,
create_time,
update_time
FROM (
SELECT
snap.id,
snap.name,
snap.phone,
snap.gender,
snap.create_time,
snap.update_time
FROM example_user_snapshot PARTITION p20230601 snap
LEFT JOIN example_user_stream PARTITION p20230602 stream ON snap.id = stream.id
WHERE stream.id IS NULL
UNION
SELECT
id,
name,
phone,
gender,
create_time,
update_time
FROM (
SELECT
id,
name,
phone,
gender,
create_time,
update_time,
-- 使用窗口函数的目的是处理流水表中可能存在多条相同id的记录,例如tom在06-02日更改多次手机号则会有多条相同id的数据,故此窗口函数用于确保选择每个id对应的update_time最大的记录;如果流水表设计的unique key = (id) 则不会出现重复情况无需此处的窗口函数。
ROW_NUMBER() OVER (PARTITION BY id ORDER BY update_time DESC) AS row_num
FROM example_user_stream PARTITION p20230602
) ranked
WHERE row_num = 1
) AS temp;
该 SQL 查询是先获取两表联接中未更新的数据,与已更新的数据合并,最后写入到快照表中,确保了
2023-06-02分区的数据是完整的全量数据。若想详细剖析此sql的运算逻辑可参考笔者另一篇文章:数仓日常维护:剖析每日增量同步的内部机制
- 此时快照表的数据如下:
| id | dt | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|---|
| 1 | 2024-02-02 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | 2024-02-02 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | 2024-02-02 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 1 | 2024-02-03 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | 2024-02-03 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | 2024-02-03 | tom | 555 | 男 | 2023-06-02 13:00:00 | 2023-06-02 09:00:00 |
| 4 | 2024-02-03 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 |
- 用户可以通过如下语句查询2023-06-02全量数据:
SELECT * FROM example_user_snapshot PARTITION p20230602;
| 1 | 2024-02-03 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
|---|---|---|---|---|---|---|
| 2 | 2024-02-03 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | 2024-02-03 | tom | 555 | 男 | 2023-06-02 13:00:00 | 2023-06-02 09:00:00 |
| 4 | 2024-02-03 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 |
合并阶段的主要压力是Doris,Flink程序只是传递sql执行后获取结果即可;至此实时快照表同步逻辑结束。
5.3、数据一致性设计
-
在上述快照表同步过程中,如果Flink程序挂掉或者重启,是否会影响数据一致性?由于Flink程序是通过定时执行checkpoint且binlog可重读溯源,因此在数据获取阶段不会出现数据一致性问题。
-
需要考虑的地方在于合并阶段,如果触发了合并任务,而此时Flink程序还在不断消费业务变更数据,这里是异步还是阻塞?笔者建议使用异步:即Flink程序仍实时同步业务变更数据至流水表,而快照表的合并阶段主要是下沉到Doris库中执行。
-
需要注意的是如果在合并阶段时Flink程序挂掉,重启后该如何处理?笔者建议在Flink程序中采用有状态的计算,即
Rich functions富函数中的ValueState,用于记录当前合并阶段是否成功,如下:
javaCopy codeimport org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.configuration.Configuration;
public class TestMapFunction extends RichMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>> {
// state 用于存放合并后的分区,例如: state=p20230601
private transient ValueState<String> state;
@Override
public Tuple2<String, Integer> map(Tuple2<String, Integer> in) throws Exception {
// 业务逻辑
}
public void open(Configuration parameters) throws Exception {
// 初始化 state
}
}
通过这种方式,即便Flink在同步过程中宕掉,只要根据checkpoint重启后便可检测到上一个分区任务失败,即state != 20230602,从而再次触发合并阶段!
关于flink有状态的计算可参考Flink官网介绍
四、总结
本文主要整合了实时表、快照表和流水表在实际应用中的使用场景。在实践中,通常一张业务数据表会对应三张实时数仓表供大数据平台使用。虽然也可以通过一张快照表来满足上述需求,但从查询性能的角度来看,并不如分表性能优秀。读者可以根据实际使用场景进行选择,以确保系统的性能和效率。
六、相关资料
-
Flink实时数仓同步:实时表实战详解
-
Flink实时数仓同步:流水表实战详解
-
Flink实时数仓同步:快照表实战详解
-
Flink实时数仓同步:拉链表实战详解
-
Doris 数据模型
-
Flink状态计算
-
MySQL CDC Connector
-
数仓日常维护:剖析每日增量同步的内部机制
-
深入数仓离线数据同步:问题分析与优化措施