数据挖掘(Data Mining),又译为资料探勘、数据采矿,是数据库知识发现(Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘主要是指从大量的数据中,通过算法自动搜索隐藏于其中的特殊关系型信息的过程。在技术层面上,数据挖掘涉及从大量的、不完全的、有噪声的、模糊的和随机的数据中,提取出隐含的、事先未知的但具有潜在价值和有用信息的过程。
数据挖掘通常与计算机科学紧密相关,它利用统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等多种方法来实现其目标。数据挖掘过程涵盖了从定义目标、获取数据、数据探索(包括数据质量分析和数据特征分析)到数据预处理(包括数据清洗、数据集成、数据变换和数据规约)等一系列步骤。
数据挖掘目前是人工智能和数据库领域研究的热点问题,其应用领域广泛,包括情报检索、情报分析、模式识别等。通过高度自动化地分析企业的数据,数据挖掘能够做出归纳性的整理,从中挖掘出潜在的模式,从而帮助决策者调整市场策略,减少风险。
数据挖掘技术融合了统计学、人工智能、模式识别、机器学习、数据库和可视化技术等多个领域的知识和方法,使得人们能够更有效地从海量数据中提取有价值的信息和知识。随着技术的不断发展,数据挖掘将在更多领域发挥重要作用,为决策提供更加科学、准确的支持。
而在大数据的比赛中数据挖掘占有非常中要的地位,但也是最为困难的模块,通常数据挖掘模块与能否进入国赛有很大的关联。
以下是相应的代码:
- 根据Hive的dwd库中相关表或MySQL中shtd_store中相关表(order_detail、sku_info),计算出与用户id为6708的用户所购买相同商品种类最多的前10位用户(只考虑他俩购买过多少种相同的商品,不考虑相同的商品买了多少次),将10位用户id进行输出,若与多个用户购买的商品种类相同,则输出结果按照用户id升序排序,输出格式如下,将结果截图粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下;
结果格式如下:
-------------------相同种类前10的id结果展示为:--------------------
1,2,901,4,5,21,32,91,14,52
package com.rmx.gz.spark.gz2.excavate
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.feature.{OneHotEncoder, StandardScaler, VectorAssembler}
import org.apache.spark.ml.linalg.{DenseVector, SparseVector}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.functions.{asc, avg, col, desc, udf}
import org.apache.spark.sql.types.DoubleType
import org.apache.spark.sql.{DataFrame, Row, SparkSession, functions}
import java.util.Properties
import scala.+:
/**
* 数据挖掘
*/
object Excavate {
val mysqlUrl = "jdbc:mysql://bigdata1:3306/ds_pub?useSSL=false&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useUnicode=true"
System.setProperty("HADOOP_USER_NAME", "root")
Logger.getLogger("org").setLevel(Level.ERROR)
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder()
.master("local[*]")
.appName("extraction")
.config("spark.hadoop.dfs.client.use.datanode.hostname", "true")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
val mysqlProperties: Properties = new Properties()
mysqlProperties.setProperty("user", "root")
mysqlProperties.setProperty("password", "123456")
val order_info = sparkSession.read.jdbc(mysqlUrl, "order_info", properties = mysqlProperties)
val sku_info = sparkSession.read.jdbc(mysqlUrl, "sku_info", properties = mysqlProperties)
val order_detail = sparkSession.read.jdbc(mysqlUrl, "order_detail", properties = mysqlProperties)
val user_info = sparkSession.read.jdbc(url = mysqlUrl, table = "user_info", properties = mysqlProperties)
/**
* 宽表,普通join连接,剔除事实表中不存在现有维表中的记录
*/
val width_table = order_info
.join(order_detail, order_detail("order_id") === order_info("id"))
.join(sku_info, sku_info("id") === order_detail("sku_id"))
.join(user_info, order_info("user_id") === user_info("id"))
/**
* 与用户id为6708的用户所购买相同商品最多的前10位用户
*/
// 用户8880购买过的商品(去重)
val user8880BuySkuIds = width_table
.filter(order_info("user_id") === 8880L)
.select(order_detail("sku_id"))
.dropDuplicates("sku_id")
.collect()
.map(row => row.getLong(0))
// 与用户id为8880的用户所购买相同商品最多的前10位用户
val top10User = width_table
.filter(order_info("user_id") =!= 8880L && order_detail("sku_id").isin(user8880BuySkuIds: _*))
.select(order_info("user_id"), order_detail("sku_id"))
.dropDuplicates("user_id", "sku_id")
.groupBy("user_id")
.agg(functions.count("*").as("count"))
.orderBy(desc("count"), asc("user_id"))
.limit(10)
.collect()
.map(row => row.getLong(0))
println("-------------------相同种类前10的id结果展示为:--------------------")
println(top10User.mkString(","))
/**
* 商品表信息预处理
*/
val sku_dimension_table = width_table
.select(sku_info("*"),order_info("user_id"))
.drop("sku_name", "sku_desc", "sku_default_img")
.filter(col("id").isin(user8880BuySkuIds: _*) || col("user_id").isin(top10User: _*))
.dropDuplicates( "id")
val assemblerPrice = new VectorAssembler().setInputCols(Array("price")).setOutputCol("vector_price")
val scalerPrice = new StandardScaler().setInputCol("vector_price").setOutputCol("standard_price")
val assemblerWeight = new VectorAssembler().setInputCols(Array("weight")).setOutputCol("vector_weight")
val scalerWeight = new StandardScaler().setInputCol("vector_weight").setOutputCol("standard_weight")
val oneHotEncoder = new OneHotEncoder()
.setInputCols(Array("spu_id", "tm_id", "category3_id"))
.setOutputCols(Array("one_hot_spu_id", "one_hot_tm_id", "one_hot_category3_id"))
.setDropLast(false)
// 处理管道
val pipeline = new Pipeline()
val pretreatment_sku_info = pipeline
.setStages(Array(assemblerPrice, assemblerWeight, scalerPrice, scalerWeight, oneHotEncoder))
.fit(sku_dimension_table)
.transform(sku_dimension_table)
// 稀疏向量转值数组
val sparseVectorToArray = udf { x: SparseVector => x.toArray }
// 稠密向量转数组
val denseVectorToArray = udf { x: DenseVector => x.toArray }
import sparkSession.implicits._
val task2Show = pretreatment_sku_info
.orderBy("id")
.limit(1)
.select(
col("id").cast(DoubleType) +:
denseVectorToArray(col("standard_price"))(0).as("price") +:
denseVectorToArray(col("standard_weight"))(0).as("weight") +:
((0 until 12).map((i: Int) => sparseVectorToArray(col("one_hot_spu_id"))(i) as s"spu_id#${i + 1}") ++
(0 until 7).map((i: Int) => sparseVectorToArray(col("one_hot_tm_id"))(i) as s"tm_id#${i + 1}") ++
(0 until 803).map((i: Int) => sparseVectorToArray(col("one_hot_category3_id"))(i) as s"category3_id#${i + 1}")): _*
)
val elements = task2Show
.limit(1)
.select(task2Show.columns.slice(0, 10).map(col(_: String)): _*)
.collect()
.head
println("--------------------第一条数据前10列结果展示为:---------------------")
println(elements.mkString(","))
/**
* 推荐
*/
val cosineSimilarity: UserDefinedFunction = udf((v1: SparseVector, v2: SparseVector) => {
//分子
val member: Double = v2.toArray.zip(v1.toArray).map((num: (Double, Double)) => num._1 * num._2).sum
// 分母
val temp1: Double = math.sqrt(v2.toArray.map((num: Double) => math.pow(num, 2)).sum)
val temp2: Double = math.sqrt(v1.toArray.map((num: Double) => math.pow(num, 2)).sum)
val deno: Double = temp1 * temp2
//余弦
member / deno
})
val sku_vector: DataFrame = new VectorAssembler()
.setInputCols(Array("standard_price", "standard_weight", "one_hot_spu_id", "one_hot_tm_id", "one_hot_category3_id"))
.setOutputCol("vector")
.transform(pretreatment_sku_info)
.select("id", "vector")
val user_8880_sku_info = sku_vector
.filter(col("id").isin(user8880BuySkuIds: _*))
.select(col("vector").as("v1"))
val result = sku_vector
.filter(!col("id").isin(user8880BuySkuIds: _*))
.crossJoin(user_8880_sku_info)
.withColumn("cosineSimilarity", cosineSimilarity(col("vector"), col("v1")))
.groupBy("id")
.agg(avg("cosineSimilarity") as "cosineSimilarity")
.orderBy(desc("cosineSimilarity"))
val tuples: Array[(String, String)] = result
.collect()
.map((r: Row) => (r(0).toString, r(1).toString))
.slice(0, 6)
println("------------------------推荐Top5结果如下------------------------")
for (i <- tuples.indices) {
println(s"相似度top${i + 1}(商品id:${tuples(i)._1},平均相似度:${tuples(i)._2})")
}
}
}
近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。获取的信息和知识可以广泛用于各种应用,包括商务管理、生产控制、市场分析、工程设计和科学探索等。数据挖掘利用了来自如下一些领域的思想:①来自统计学的抽样、估计和假设检验;②人工智能、模式识别和机器学习的搜索算法、建模技术和学习理论。数据挖掘也迅速地接纳了来自其他领域的思想,这些领域包括最优化、进化计算、信息论、信号处理、可视化和信息检索。一些其他领域也起到重要的支撑作用。特别地,需要数据库系统提供有效的存储、索引和查询处理支持。源于高性能(并行)计算的技术在处理海量数据集方面常常是重要的。分布式技术也能帮助处理海量数据,并且当数据不能集中到一起处理时更是至关重要。
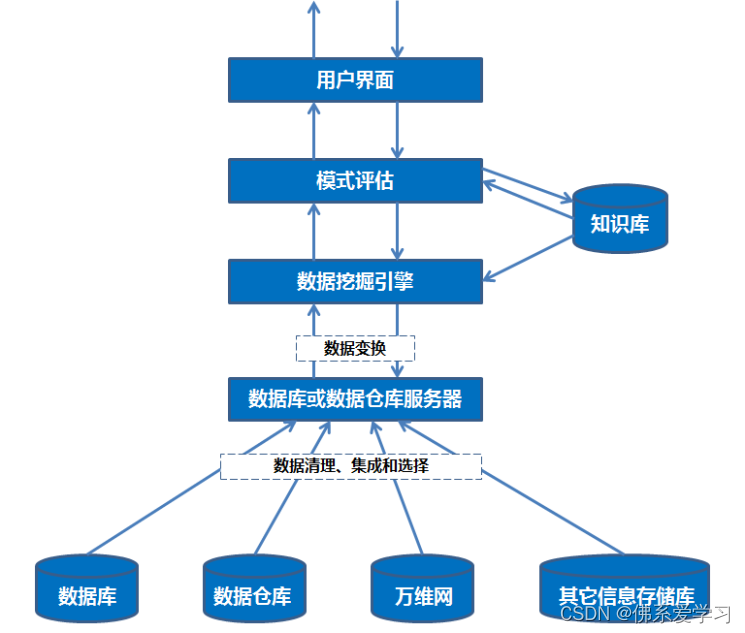
数据挖掘的系统结构