反压的理解
Flink 中每个节点间的数据都以阻塞队列的方式传输,下游来不及消费导致队列被占满后,上游的生产也会被阻塞,最终导致数据源的摄入被阻塞。简单来说就是系统接收数据的速率远高于它处理数据的速率。
反压如果不能得到正确的处理,可能会影响到 checkpoint 时长和 state 大小,甚至可能会导致资源耗尽甚至系统崩溃。 这两个影响对于生产环境的作业来说是十分危险的,因为 checkpoint 是保证数据一致性的关键,checkpoint 时间变长有可能导致 checkpoint 超时失败,而 state 大小同样可能拖慢 checkpoint 甚至导致 OOM。
因此,我们在生产中要尽量避免出现反压的情况。
反压产生原因和解决方案
(1)数据倾斜
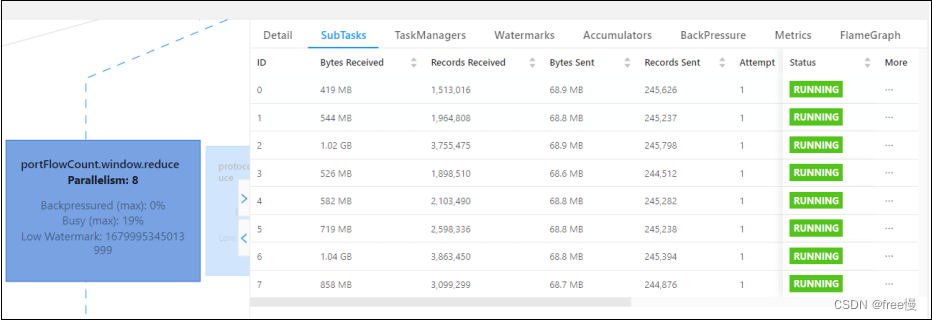
相同 Task 的多个 Subtask 中,个别 Subtask 接收到的数据量明显大于其他 Subtask 接
收到的数据量,通过 Flink Web UI 可以精确地看到每个 Subtask 处理了多少数据,即可
判断出 Flink 任务是否存在数据倾斜。
如下图所示,0 号 SubTask 接受的数据远大于其他 SubTask。
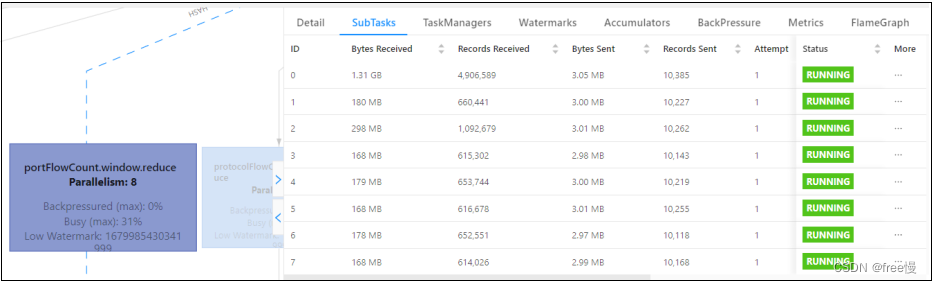
出现这种情况的原因:
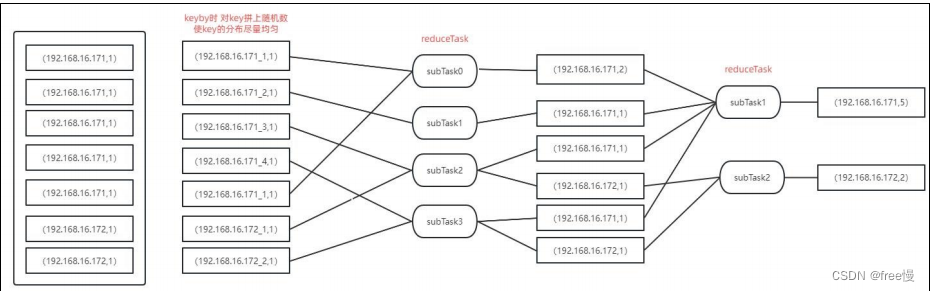
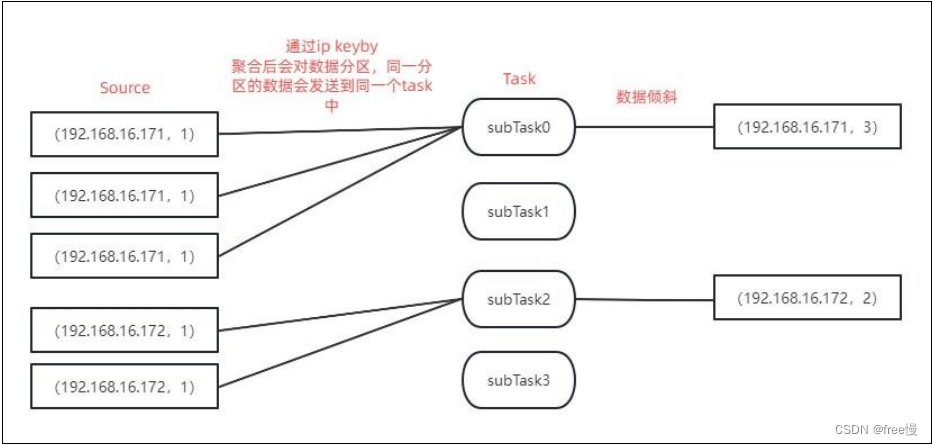 如上图所示,当 key 的分布不均匀时,keyby 后会将数据分区,相同 key 的数据会发送到同
如上图所示,当 key 的分布不均匀时,keyby 后会将数据分区,相同 key 的数据会发送到同
一个 subTask 中,从而造成数据倾斜。
解决方案:
(1)keyby 之后不统计
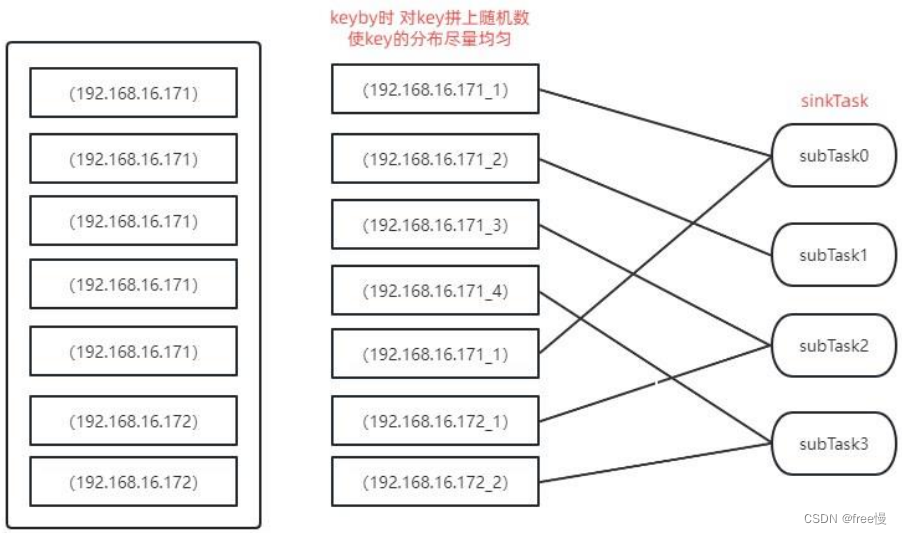
如上图所示,对分布不均匀的 key 拼上一个随机数,使 key 变得分散。
如果我们keyby之后没有统计需求,比如说keyby之后为sink算子,就可以使用此方法解决。
(2)keyby 之后统计(一次聚合)
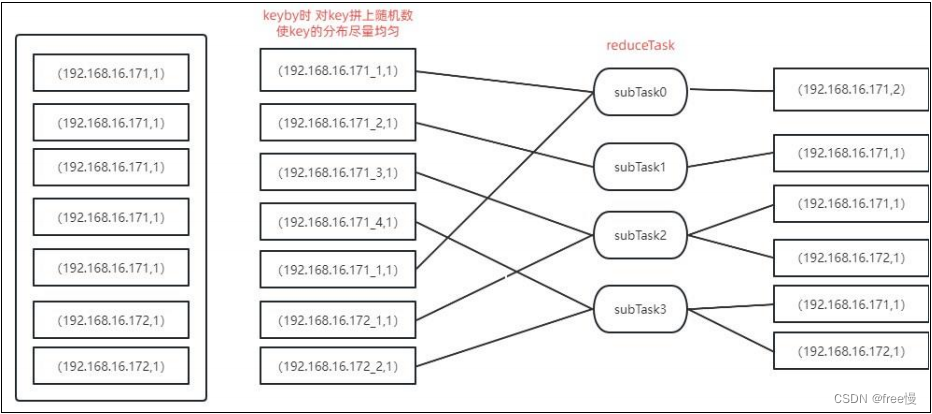
如上图所示,对分布不均匀的 key 拼上一个随机数,使 key 变得分散。但是这样统计
出来的数据有几个弊端。
1、原本统计出来相同 key 只有一条数据,但是现在分散为几条数据,这样虽然减
轻了 reduce 的压力,但是增大了 sink 的压力。
2、如果 sink 端为 mysql 且为多并行度,这样会导致多个 sink 算子操作同一条数据,最
造成插入失败和统计数据丢失的问题。
(3)keyby 之后统计(二次聚合)
如上图所示,对第一次聚合出来的数据再进行一次聚合。
优化后:
(2)代码问题
如果不是数据倾斜,最常见的问题可能是用户代码的执行效率问题(频繁被阻塞或者性能问题),需要找到瓶颈算子中的哪部分计算逻辑消耗巨大。
最有用的办法就是对 TaskManager 进行 CPU profile,从中我们可以分析到 Task Thread 阻塞在哪里,可能是用户函数本身有些同步的调用,可能是 checkpoint 或者 GC 等系统活动导致的暂时系统暂停。
看顶层的哪个函数占据的宽度最大。只要有"平顶",就表示该函数可能存在性能问题。
火焰图如下图所示:
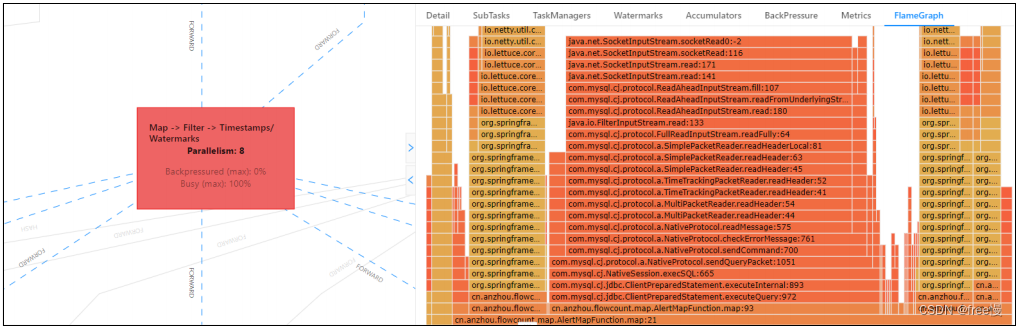
从上图中可以清晰的看出此算子一直在查询数据库,从火焰图进行分析非常方便就定位
到了问题所在。可在配置文件中通过 rest.flamegraph.enabled: true 开启。
容易导致反压的几个代码问题即解决方案:
**1、频繁查询数据库扩充数据或调用外部 API **
使用缓存:
小量数据可以使用进程缓存或者 Redis,尽量不要频繁查询数据库。使用缓存需注意缓存穿透问题。
异步 io:
Flink 提供异步 Api,具体可查看官方文档。
布隆过滤器:
对于数据量很大,且允许一定误判率的情况下,可先使用布隆过滤器对数据进行过滤。
2、Sink 端 Mysql 大量修改统计数据
批量执行:
Sink 端的所有操作都使用批量操作,减小 IO 次数,并且事务一次性提交。
单并行度入库:
多线程操作 Mysql 会导致 CPU 频繁切换上下文,会造成 Mysql 性能降低。
Mysql 参数优化:
innodb_buffer_pool_size:Innodb 缓冲池大小,缓冲池会缓存数据和索引,此值可根据实际情况调整,减少读写 IO 次数。
innodb-flush-log-at-trx-commit:将此值设为 0,每过 1 秒会把 log_buffer 中的数据刷新至log_file 中,然后同步刷新到磁盘,这样性能最高,但是宕机会丢失前 1 秒的数据。
sync_binlog:将此值设为 0,当事务提交之后,并不会将 binlog_cache 中的数据刷新到磁盘,而是由文件系统决定什么时候将 cache 数据刷新到磁盘中,性能最高。
innodb_flush_method:将此值设置为 O_DIRECT,此参数的目的是让 Mysql 在写入时绕过操作系统缓存,直接写入磁盘,提高写入性能。
统计开窗时间可适当延长:对于统计数据来说,操作 Mysql 大量都是修改,可将开窗时间适当延长,减少 IO 次数。
Sink 异步化:
因为统计算子的特殊性,可使用线程池将 sink 任务丢到线程池中异步执行,这样就不会出现操作 Mysql 时反压严重的情况。









![Cocos2dx-lua ScrollView[二]进阶篇](https://img-blog.csdnimg.cn/direct/6c15c1186b0b4709851895abb9b3749f.gif)