复习前面的内容:
1.auto,可以自动识别auto本身在这种语境下是什么类型
2.decltype,让一个变量的类型和另外一个变量的类型相同
decltype(x) y;//让y的类型和x的类型相同如何理解?
decltype是一个关键词,其作用是检查括号内的表达式,并返回该表达式的类型,因此相当于用返回表达式的类型定义了y。
使用decltype的时候,需要注意的是:
int i;
decltype(i) j;//此时j是int类型
decltype((i)) j;//此时j的int&类型
//原因是在i外面再加一圈括号则会被看作为一个表达式,返回的类型将是内括号类型的引用当定义一个模板函数的时候,有时候没办法确定返回的类型,比如说传入的一个是int类型,一个是double类型的时候返回的是double类型,如果传入的是两个int类型的时候,返回是int类型,为了解决这种情况,则可以使用decltype,
template<class T, class U>
auto sum(T &n, U m)->decltype(n+m)
{
return n+m;
}
函数执行的顺序是,先传入参数,然后执行decltype关键词,auto根据decltype返回的类型来决定自己的类型。
3.回顾模板类中的隐式实例化,显示实例化,全部具体化,部分具体化
template<class T>;
template<typename T>;
//这两个模板头是一个意思,只是习惯问题,有些人喜欢用class,有些人喜欢用typename1)隐式实例化,就像我们平时实例化一个模板类,用模板类创造一个对象就是在使用隐式实例化
template<class T>
class A
{
};
int main(void)
{
A<int > a;//隐式实例化
return 0;
}2)显示实例化,不需要创造对象即可定义模板
template<class T>
class A
{
};
template class A<int >;//显示实例化, 不需要定义对象,但却实例化了模板类
int main(void)
{
return 0;
}3)全部具体化
具体化就是将类型参数限制住,使得模板类更加具体,当传入的类型参数为限制的类型的时候,使用的即为这个更具体的模板类的声明。
template <typename T, typename U>
class MyClass {
//...
};
template <>//<>括号内填入不进行具体化的类型参数,全具体化没有不进行具体化的参数
class MyClass<int, double> {//对类型参数具体化
// 这是一个全具体化版本
// 当T和U分别为int和double时,会使用这个版本
//...
};4)部分具体化
template <typename T, typename U>
class MyClass {
//...
};
template <typename T>//类型参数T不进行具体化,不进行具体化的类型参数要放进<>中
class MyClass<T, int> {
// 这是一个部分具体化版本
// 当U是int类型时,会使用这个版本
};4.转换函数与单参数的构造函数的隐式转换问题
转换函数是将对象转换成其他类型,如
//定义一个转换函数,将复数对象转换成其实部
class Complex
{
private:
double real; // 实部
double imaginary; // 虚部
public:
// 构造函数
Complex(double real = 0.0, double imaginary = 0.0)
: real(real), imaginary(imaginary)
{ }
// 定义一个转换函数,将Complex对象转换为double
operator double() const//转换函数不需要返回类型
{
return real; // 返回Complex对象的实部
}
};我们不希望以下的事情发生:
double a;
Complex temp;
a = temp;//这会隐式地将temp对象转换成double类型的数据,这可能不是我们想要发生生的
//则应该在转换函数前面加上explicit来禁止隐式转换,只允许显示转化
a = temp.operator double();//显示调用转换函数但参数的构造函数可能也会发生类型的情况
比方说:
class A
{
private:
int num;
public:
A(int n = 0) : num(n) {}
}
int main(void)
{
A temp1(10);
temp1 = 20;//这将会用20作为参数隐式调用构造函数来创建一个无名对象,然后赋值给temp1;
return 0;
}我们不希望这样的事情发生,同样的,可以在这个单参数的构造函数前面加上explicit
5.
基于范围的for
c++11引入了基于范围的for,使得遍历容器或者数组变得更加方便,对于一般的数组:
int arr[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
for(int i : arr)
cout << i << endl;
vector<int> arr = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
for(auto i : arr)
cout << i << endl;
//将容器或者数组中的元素放到i中6.
复习左值,右值,以及左值引用右值引用(第八章第9节)
一般来说,左值就是可以放在等号左边的值,右值就是可以放到等号右边的值,我们有一个技巧可以判断哪个是左值哪个是右值,一般来说,左值可以用&取地址,右值不可能用&取地址。而右值引用可以修改引用所指向的对象,右值引用一般用于移动语句。
什么叫做常引用?
常引用可以指向右值
const int &temp = (a+b);
//这将会在内存中创建一个临时变量来存放a+b,temp将是这个临时变量的别名
//但常引用无法改变该临时变量的值,只能读取什么是右值引用?
int &&temp = (a+b);//定义一个右值引用7.
作用域内枚举
当一个类中定义了两个枚举变量,但是这两个枚举变量中有相同的枚举量,我们可以使用类来将枚举量进行封装,然后用作用域来解决这个问题枚举量冲突问题,即在类的作用域中不会出现命名冲突。
class A
{
public:
enum class color1{Red,Blue, Green};
enum class color2{Red, Yellow};//定义两个枚举类,用枚举类来封装枚举量
};
//这样就可以用类名加上作用域解析运算符来指定使用哪个枚举量
A::color1 c1 = A::color1::Red;
A::color2 c2 = A::color2::Red;
if (c1 == A::color1::Red) {
// do something
}
if (c2 == A::color2::Red) {
// do something else
}8.
using=和typedef有什么区别?
c++11中可以使用using加别称 = 模板类名来给模板类起一个别名,而typedef无法做到,毕竟模板类是c++新增的东西。
如:
using v = std::vector<int>;
//让v和std::vector<int>等价,即v成为了别名移动语义和右值引用
移动语义是什么意思?
移动语义是一种理念或方案,它通过避免昂贵的复制操作来提高性能,将右值引用所指向的内存好好利用,使用更改内存所有权的方式来实现复制而不是通过重新开辟内存的方式来复制。而移动构造函数和移动赋值运算符则是实现这种理念的工具或手段。
什么是移动构造函数和移动赋值运算符?
移动构造函数的参数是右值引用,移动构造函数的作用就是将右值引用所指向的对象的内存空间让给移动构造函数所要生成的对象,只是将一个对象的资源转让给另一个对象,相当于把这片内存改了个名字,原来是右值引用所指向的对象拥有的内存,变成了调用移动构造函数的对象的内存,并没有开辟新的内存。
移动赋值运算符也是同理,将右值引用所指向的对象所拥有的内存空间转让给了其他对象,也没有开辟新的内存。
什么时候调用移动构造函数?
当一个临时的对象(或称之为右值)给另一个对象进行初始化的时候,编译器将调用移动构造函数而非复制构造函数,这也是与复制构造函数的区别。
下面是一个使用移动构造函数和移动赋值运算符的例子,帮助理解:
#include <iostream>
#include <vector>
class MyClass {
private:
int* data;
public:
MyClass(int size) { // 构造函数
data = new int[size];
std::cout << "Constructor called!" << std::endl;
}
~MyClass() { // 析构函数
delete[] data;
std::cout << "Destructor called!" << std::endl;
}
MyClass(const MyClass& other) = delete; // 禁止复制
MyClass(MyClass&& other) noexcept : // 移动构造函数,noexcept保证函数不抛出异常,如果抛出异常将会直接终止程序
data(other.data)
{
other.data = nullptr;
std::cout << "Move constructor called!" << std::endl;
}
MyClass& operator=(MyClass&& other) noexcept { // 移动赋值运算符
if(this != &other) {
delete[] data; // 删除当前对象的资源
data = other.data; // 赋值,将资源转让给调用构造函数的对象
other.data = nullptr; // 置空
std::cout << "Move assignment operator called!" << std::endl;
}
return *this;
}
};
int main() {
std::vector<MyClass> vec;
vec.push_back(MyClass(50)); // push_back会调用移动构造函数
MyClass a(100); // 正常构造
MyClass b(200); // 正常构造
b = std::move(a); // 调用移动赋值运算符
return 0;
}使用头文件utility中声明的函数std::move可以将对象的类型强制转换成右值引用,注意,记得将右值引用所指向的对象中使用了动态开辟内存的指针置空,否则该对象调用析构函数的时候将会回收这个已经让出去的内存空间。
编译器会自动生成那6个特殊的成员函数?
1. 默认构造函数
2. 默认析构函数
3. 默认复制构造函数
4. 默认赋值运算符
5. 移动构造函数
6. 移动赋值运算符
一旦你定义了移动构造函数或者移动赋值运算符,编译器将不再自动生成默认构造函数,默认复制构造函数,默认赋值运算符,因为编译器会认为你会完全管理资源,因此不再自动生成这些特殊的成员函数,反之,如果用户定义了构造函数,复制构造函数,以及赋值运算符中任意一个,都不会再自动生成移动构造函数,移动赋值运算符。
需要注意的是复制构造函数和移动构造函数的参数是不同的,移动构造函数传入的不仅仅是右值引用,而且是没有const的,而复制构造函数带有const,原因是移动构造函数会更改传入的临时对象(或者右值)的指针,让其指向的内存转让给其他对象,然后自己指向空指针,这样才能完成空间的转让。
在上述情况下,如果仍然想让编译器自动生成相应的构造函数,可以在声明构造函数的后面加上default
如:
class MyClass
{
public:
MyClass(MyClass &&mc);//一般来说定义了移动构造函数后,程序将不会自动生成复制构造函数
MyClass(const MyClass &mc) = default;//显示得让程序生成复制构造函数
}与default相对应得关键词是delete,使用delete可以禁止编译器使用特定的方法,即禁止某个函数的使用。
class MyClass
{
public:
MyClass(MyClass &&mc);
MyClass(const MyClass &mc) = delete;//禁止使用复制构造函数
}什么是继承构造函数?
继承构造函数即为派生类构造函数直接继承基类的构造函数。
一般来说,构造函数,析构函数,赋值运算符,取地址运算符以及私有成员函数是派生了无法继承的,如果像继承基类的构造函数,则可以使用using来让派生类继承基类的所有构造函数,使用这种方法一般是因为基类的构造函数比较完整,用基类的构造函数就可以完成初始化,这样就可以省去重新定义一个和基类构造函数干相同事情的操作,即使用基类的构造函数却可以创造一个派生类的对象,我们一般说的构造函数无法继承的意思是说无法用基类的构造函数直接创建一个派生类的对象。
举个例子:
// 基类
class Base {
public:
Base(int val) : value(val) {
cout << "Base constructor called with value: " << value << endl;
}
private:
int value;
};
// 派生类
class Derived : public Base {
public:
using Base::Base; // 使用基类的构造函数(继承构造函数)
};
int main() {
Derived d(10); // 直接调用基类的构造函数
return 0;
}
//派生类没有自己的成员变量,只有基类的构造函数即可完成初始化,使用继承构造函数就不需要自己定义构造函数了
//如果没有使用继承构造函数则需要定义一个调用基类构造函数的派生类构造函数
//Derived(int val) : Base(val) {} 重新定义将隐藏方法是什么意思?
意思就是说派生类如果定义了一个和基类方法同名的方法(不考虑参数,只考虑名字),这时候编译器将会只使用派生类的该方法而继承而来的同名方法将会被隐藏(覆盖),这样的现象就叫做"重新定义将隐藏方法"。
如果我像重新定义一个同名方法但却不想隐藏基类的方法应该怎么办?
class Derived : public Base
{
public:
using Base::foo; // Unhide Base::foo(int x)
void foo()
{
// ...
}
//这个时候派生类中将有两个foo方法,一个是继承而来的基类方法foo,一个是自定义的foo
};使用using既可将继承而来的基类方法显现而不会隐藏,这个时候就会根据参数的类型来调用不同版本的foo,传入int类型的参数就调用基类的方法,无参数就调用派生类的同名方法。
重载和重写以及重新定义有什么区别?
1.重载是在一个作用域内进行的,多定义几个参数列表(参数类型和参数个数以及返回值)不同但同名方法,这种叫做重载。重载通常发生在一个类内。
如:
class Demo {
void func() { ... }
void func(int a) { ... }
void func(double a, int b) { ... }
}2.
重写指的是派生类重写基类的方法,更改方法的行为,需要注意的是重写基类的方法要求派生类的方法必须与基类的方法具有完全相同的方法名以及参数列表,这时候如果通过派生类对象调用派生类方法的时候将会调用派生类的方法而不是基类的方法。
3.
重新定义,我们知道重新定义将隐藏方法,在派生类重新定义方法有点像重载,但是重载一般发生在一个类中而且不要求像重写一样参数列表和函数名都相同,而这里的重新定义发生在派生类中,此时派生类将隐藏基类的同名方法,而只使用派生类重新定义的同名方法。
这就是这三种的区别。
介绍两个关键词override和final
override用于派生类重写基类的方法,记住是重写,重写要求方法名和参数列表都必须相同,使用override是为了检查派生类重写格式是否有误。
final
final有两个作用,一是阻止类的进一步继承。二是阻止方法的进一步重写,但是重新定义是可以通过编译的。
如:
#include <iostream>
using namespace std;
class MyClass
{
public:
virtual void fuc() final{cout << "Base " << endl;}
};
class Derive : public MyClass
{
public:
void fuc() {cout << "Derive" << endl;}
};
int main(void)
{
return 0;
}
这样编译是不会通过的,你这样相当于重写,派生类将基类的方法重写了。
但是重新定义是没有问题的
#include <iostream>
using namespace std;
class MyClass
{
public:
virtual void fuc() final{cout << "Base " << endl;}
};
class Derive : public MyClass
{
public:
void fuc(int n) {cout << "Derive" << endl;}
};
int main(void)
{
Derive temp;
temp.fuc(10);
return 0;
}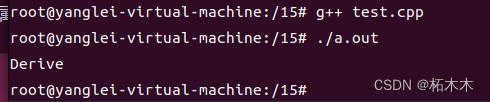
重新定义将隐藏方法,即基类的方法将会被隐藏
Lambda函数
先回顾和介绍三种表达式for_each,count_if, generate
for_each(, ,)
第一个和第二个参数都是迭代器,第三个参数是要执行的操作,可以是函数指针,函数符或者是lambda函数,该表达式的作用就是遍历容器,执行操作。
count_if(,,)
第一个参数和第二个参数都是迭代器,第三个参数是要执行的操作,可以是函数指针,函数符或者是lambda函数,返回值要为bool类型,如果是true则计数+1,如果是false则计数-1,整个表达式的返回值是个整数,即计数值。
generate(,,)
第一个参数和第二个参数都是迭代器,第一个参数和第二个参数都是迭代器,第三个参数是要执行的操作,可以是函数指针,函数符或者是lambda函数,返回值要为容器所容纳的数据类型,该表达式的作用是填充容器的值;
#include <cstdlib>
#include <ctime>
#include <vector>
#incldue <algorithm>
//generate的使用:
srand(time(0));//产生随机数种子
int SIZE = 10;
vector<int > v(SIZE);
generate(v.begin(), v.end(), rand);//用随机数来填充vector
//count_if的使用:
bool countNum(int n)
{
return n % 3 == 0;
}
int count = count_if(v.begin(), v.end(), countNum);
//for_each的使用:
void Show(int n)
{
cout << n << endl;
}
for_each(v.begin(), v.end(), Show);那什么是lambda函数呢?
lambda函数也叫做匿名函数,可以认为lambda函数就是一个小的函数,它是用来简化代码的一种方式。
形如:
[](int n)
{
return n % 3 == 0;
}lambda函数不用定义返回类型,其返回类型是使用decltype来决定的,也无需定义函数名。
[]是捕获列表,lambda函数可以访问作用域内的任何动态变量,而捕获列表指定(限制)了lambda函数可以访问所在作用域的那些变量和如何访问。
以下是一些常用的捕获方式:
-
[]:不捕获任何变量。 -
[x]或[=]:按值捕获,创建x的一个新副本(不论x是值类型还是引用类型都只复制对象的值)。 -
[&x]或[&]:按引用捕获,创建x的一个引用,可以改变x的值。 -
[this]:捕获当前类的this指针,用于在lambda中访问类的成员。 -
[x, &y]:混合捕获,可以同时捕获一些变量的副本和一些变量的引用
例子:
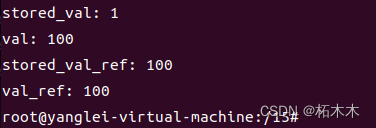
#include <iostream>
int main()
{
int val = 1;
auto copy_val = [val] { return val; };
val = 100;
auto stored_val = copy_val();
std::cout << "stored_val: " << stored_val << std::endl; // 输出: stored_val: 1
std::cout << "val: " << val << std::endl; //输出: val: 100
int val_ref = 1;
auto copy_ref = [&val_ref] { return val_ref; };
val_ref = 100;
auto stored_val_ref = copy_ref();
std::cout << "stored_val_ref: " << stored_val_ref << std::endl; // 输出: stored_val_ref: 100
std::cout << "val_ref: " << val_ref << std::endl; //输出: val_ref: 100
return 0;
}
lambda函数也是可以有名字的,当lambda函数多次出现的时候,应该给lambda一个名字,简化代码,而不是用一次就定义一次,举个例子:
auto Add = [](int x, int y) {return x+y;}
//让lamb函数的名字确定为Add
int num = Add(5, 3);包装器
包装器头文件functional下的一个模板类,可以用来优化程序,包装器可以接收函数,函数指针,函数对象以及lambda函数作为参数来初始化。
那么包装器有什么用呢?
用来优化程序,提高资源的利用率,比如说让模板类的实例化次数降低。
怎么做到的?
先看代码,下面解释。
#include <functional>
function<double(double) > ef = fuc;
//包装器ef可以接收一个参数是double且返回值为double的函数,函数指针,函数对象或者lambda函数
template<class T, class U>
T Fuction(T t, U u)
{
return U(t);
};
//用包装器作为模板函数的参数,这样模板函数只会被实例化一次,因为我们传入的是包装器
如果T的类型为double,函数,函数指针,函数对象,lambda函数作为参数U传入到模板类中,因为其类型不一样,所以U的类型的类型也不一样,导致模板类被实例化了4次。
但实际上可以使用一种方法来让模板类的实例化变为1次,那就是将特征标(参数列表和返回类型)相同的函数,函数指针,函数对象,以及lambda函数都封装成一种类型,这样U就是传入这种封装的类型,而不是分别传这4种类型,这样模板类就只会被实例化一次,第一个参数类型是double,而第二个参数类型是包装器。
所以包装器就是一种封装手段,将特征标相同的函数,函数指针,函数对象以及lambda函数都看作为一种类型。
可变参数模板
可变参数模板是c++11推出的一种模板类,该模板类不限制类型参数的个数
下面是如何使用可变参数模板:
template<class T>//函数参数包中只剩一个参数的时候调用该模板函数,进行结束操作
void Show_List(T t)
{
cout << t << endl;
}
template<class T, class...Args>//模板参数包,里面包的是传入的参数类型
void Show_List(T t, Args...args)//函数参数包,里面包的是传入的值
{
cout << t << " ";
Show_List(args...);//使用递归的方式来使用模板参数包里面的内容,相当于出栈,出栈后对栈剩下的部分再进行一次函数调用,直到只剩一个的时候再进行结束操作;
}