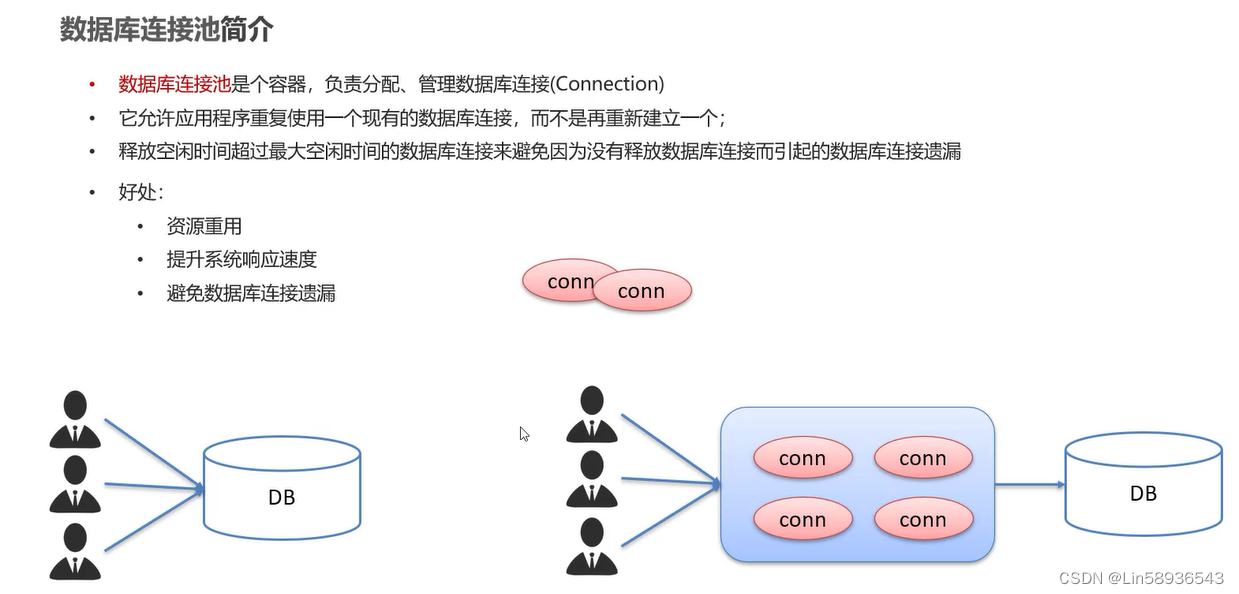



数据库连接池是一个存放数据库连接的缓冲池,它能够管理和重用数据库连接,从而提高数据库访问的性能和效率。数据库连接是一种资源,它的创建和销毁是比较耗时的操作,因此使用连接池可以避免频繁地创建和销毁连接,从而减少了系统资源的消耗,提高了系统的响应速度和稳定性。
下面是一些关于数据库连接池的基本知识点:
1. **连接池的工作原理**:
- 连接池在启动时会创建一定数量的数据库连接,并将它们存放在池中。
- 当应用程序需要连接数据库时,它会从连接池中获取一个空闲连接,并将其分配给应用程序。
- 当连接不再使用时,应用程序会将连接返回给连接池,以便重用。
- 如果连接池中没有空闲连接,而且连接数未达到最大值,则连接池会创建新的连接并将其提供给应用程序。
- 如果连接池中的连接数量已经达到最大值,新的连接请求将会阻塞,直到有连接被释放或超时。
2. **连接池参数**:
- 最小连接数(minIdle):连接池中保持的最小空闲连接数。
- 最大连接数(maxActive):连接池中允许的最大连接数。
- 最大等待时间(maxWait):获取连接的最大等待时间,超过这个时间将会抛出异常。
- 最大空闲时间(maxIdle):连接池中连接的最大空闲时间,超过这个时间将会被释放。
- 验证查询(validationQuery):用于验证连接是否有效的 SQL 查询语句。
3. **连接池实现**:
- 常见的连接池实现包括 Apache Commons DBCP、C3P0、HikariCP、Druid 等。
- 不同的连接池实现具有不同的特性和性能表现,开发者可以根据实际需求选择合适的连接池。
4. **连接池的优点**:
- 减少连接创建和销毁的开销。
- 提高系统的性能和效率。
- 控制数据库连接的数量,防止连接泄漏和资源浪费。
- 提供了连接的管理和监控功能,方便排查和解决数据库连接问题。
总之,数据库连接池是一种重要的数据库访问优化技术,它能够有效地管理和重用数据库连接,提高了系统的性能、稳定性和可维护性。因此,在开发应用程序时,合理地配置和使用数据库连接池是非常重要的。
使用 Druid 数据库连接池也是一个常见的选择。Druid 提供了强大的监控和管理功能,以及优秀的性能表现。以下是一个简单的示例,演示如何在 Java 中使用 Druid 数据库连接池:
1. 首先,确保你的项目中包含了 Druid 的依赖。如果是 Maven 项目,可以在 `pom.xml` 文件中添加如下依赖:
```xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.6</version>
</dependency>
```
2. 在代码中使用 Druid 数据库连接池:
```java
import com.alibaba.druid.pool.DruidDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class DatabaseExample {
public static void main(String[] args) {
// 创建 Druid 数据源配置
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/mydatabase");
dataSource.setUsername("username");
dataSource.setPassword("password");
try {
// 初始化数据源
dataSource.init();
} catch (SQLException e) {
e.printStackTrace();
}
Connection connection = null;
try {
// 从连接池获取连接
connection = dataSource.getConnection();
// 进行数据库操作
// 例如执行查询或更新操作
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (connection != null) {
try {
// 将连接放回连接池
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
// 关闭连接池
dataSource.close();
}
}
```
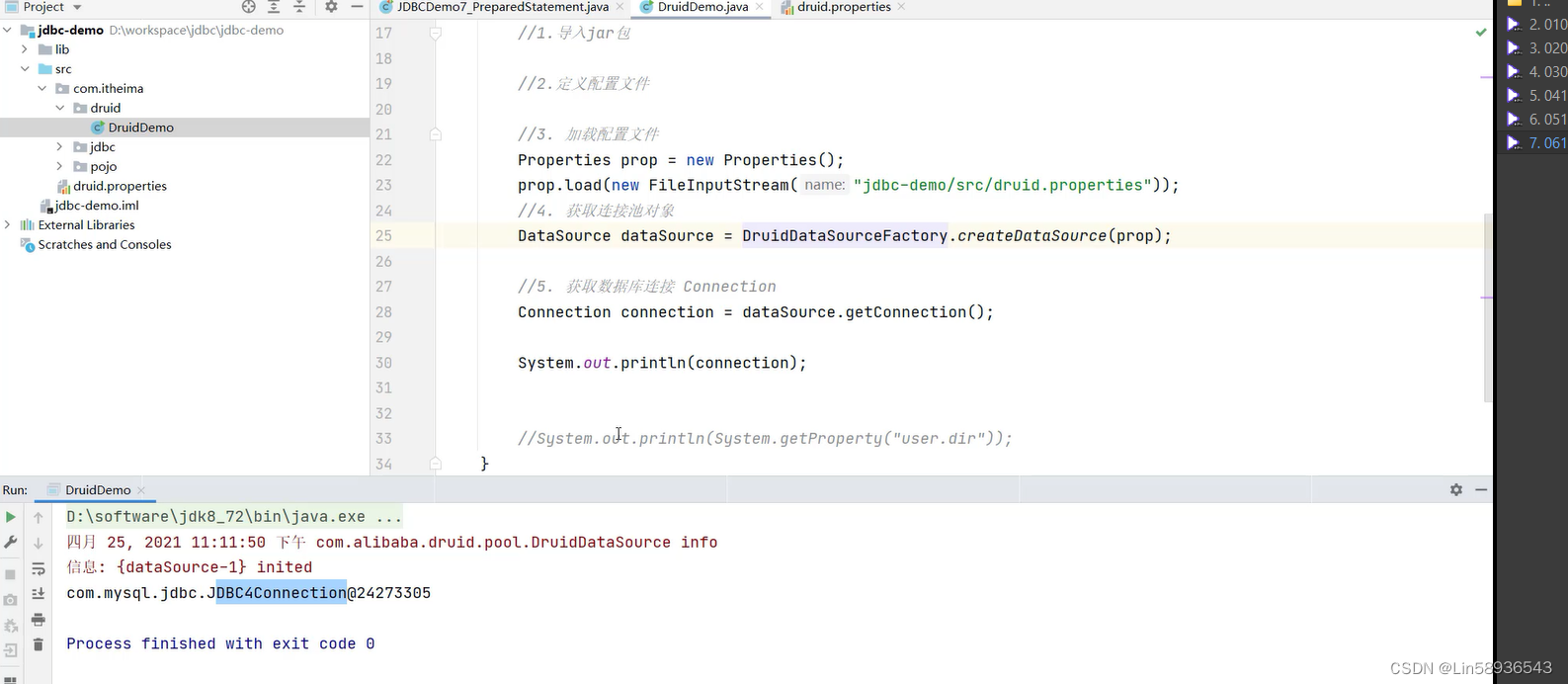
在这个示例中,我们创建了一个 Druid 数据源对象,并设置了数据库连接的 URL、用户名和密码。然后通过 `dataSource.init()` 方法初始化数据源,调用 `dataSource.getConnection()` 方法从连接池中获取一个数据库连接,执行数据库操作后,通过 `connection.close()` 将连接放回连接池。最后调用 `dataSource.close()` 关闭连接池。
Druid 还提供了丰富的配置选项,可以根据实际需求进行配置,以达到更好的性能和稳定性。