文章目录
- 题目
- 标题和出处
- 难度
- 题目描述
- 要求
- 示例
- 数据范围
- 解法一
- 思路和算法
- 代码
- 复杂度分析
- 解法二
- 思路和算法
- 代码
- 复杂度分析
- 解法三
- 思路和算法
- 代码
- 复杂度分析
- 解法四
- 思路和算法
- 代码
- 复杂度分析
题目
标题和出处
标题:前序遍历构造二叉搜索树
出处:1008. 前序遍历构造二叉搜索树
难度
5 级
题目描述
要求
给定一个表示二叉搜索树的前序遍历的整数数组,构造树并返回其根结点。
保证对于给定的测试用例,总是存在符合要求的二叉搜索树。
示例
示例 1:
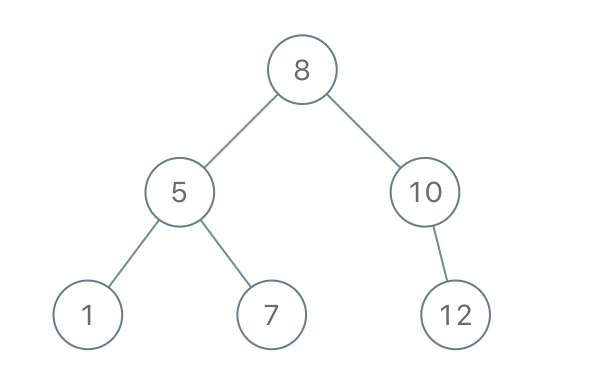
输入:
preorder
=
[8,5,1,7,10,12]
\texttt{preorder = [8,5,1,7,10,12]}
preorder = [8,5,1,7,10,12]
输出:
[8,5,10,1,7,null,12]
\texttt{[8,5,10,1,7,null,12]}
[8,5,10,1,7,null,12]
示例 2:
输入:
preorder
=
[1,3]
\texttt{preorder = [1,3]}
preorder = [1,3]
输出:
[1,null,3]
\texttt{[1,null,3]}
[1,null,3]
数据范围
- 1 ≤ preorder.length ≤ 100 \texttt{1} \le \texttt{preorder.length} \le \texttt{100} 1≤preorder.length≤100
- 1 ≤ preorder[i] ≤ 1000 \texttt{1} \le \texttt{preorder[i]} \le \texttt{1000} 1≤preorder[i]≤1000
- preorder \texttt{preorder} preorder 中的值各不相同
解法一
思路和算法
由于二叉搜索树的中序遍历序列是单调递增的,因此将给定的前序遍历序列排序之后即可得到二叉搜索树的中序遍历序列。在已知前序遍历序列和中序遍历序列的情况下,可以使用「从前序与中序遍历序列构造二叉树」的做法构造二叉搜索树。
根据前序遍历序列和中序遍历序列的信息,可以使用递归分治的方法构造二叉搜索树。
前序遍历序列的第一个元素值为根结点值,只要在中序遍历序列中定位到根结点值的下标,即可得到左子树中的结点数和右子树中的结点数。对于左子树和右子树,也可以在给定的前序遍历序列和中序遍历序列中分别得到对应的子序列,根据子序列构造相应的子树。
代码
class Solution {
Map<Integer, Integer> inorderIndices = new HashMap<Integer, Integer>();
int[] preorder;
int[] inorder;
public TreeNode bstFromPreorder(int[] preorder) {
this.preorder = preorder;
int length = preorder.length;
this.inorder = new int[length];
System.arraycopy(preorder, 0, inorder, 0, length);
Arrays.sort(inorder);
for (int i = 0; i < length; i++) {
inorderIndices.put(inorder[i], i);
}
return buildTree(0, 0, length);
}
public TreeNode buildTree(int preorderStart, int inorderStart, int nodesCount) {
if (nodesCount == 0) {
return null;
}
int rootVal = preorder[preorderStart];
TreeNode root = new TreeNode(rootVal);
int inorderRootIndex = inorderIndices.get(rootVal);
int leftNodesCount = inorderRootIndex - inorderStart;
int rightNodesCount = nodesCount - 1 - leftNodesCount;
root.left = buildTree(preorderStart + 1, inorderStart, leftNodesCount);
root.right = buildTree(preorderStart + 1 + leftNodesCount, inorderRootIndex + 1, rightNodesCount);
return root;
}
}
复杂度分析
-
时间复杂度: O ( n log n ) O(n \log n) O(nlogn),其中 n n n 是数组 preorder \textit{preorder} preorder 的长度,即二叉搜索树的结点数。得到中序遍历序列需要 O ( n log n ) O(n \log n) O(nlogn) 的时间,构造二叉搜索树需要 O ( n ) O(n) O(n) 的时间,因此时间复杂度是 O ( n log n ) O(n \log n) O(nlogn)。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 preorder \textit{preorder} preorder 的长度,即二叉搜索树的结点数。空间复杂度主要是递归调用的栈空间以及哈希表空间,因此空间复杂度是 O ( n ) O(n) O(n)。
解法二
思路和算法
在已知前序遍历序列和中序遍历序列的情况下,也可以使用迭代的方法构造二叉搜索树。遍历前序遍历序列,对于每个值分别创建结点,使用栈存储结点,并利用中序遍历序列的信息得到遍历序列中相邻结点之间的关系,即可构造二叉搜索树。
代码
class Solution {
public TreeNode bstFromPreorder(int[] preorder) {
int length = preorder.length;
int[] inorder = new int[length];
System.arraycopy(preorder, 0, inorder, 0, length);
Arrays.sort(inorder);
TreeNode root = new TreeNode(preorder[0]);
Deque<TreeNode> stack = new ArrayDeque<TreeNode>();
stack.push(root);
int inorderIndex = 0;
for (int i = 1; i < length; i++) {
TreeNode prev = stack.peek();
TreeNode curr = new TreeNode(preorder[i]);
if (prev.val != inorder[inorderIndex]) {
prev.left = curr;
} else {
while (!stack.isEmpty() && stack.peek().val == inorder[inorderIndex]) {
prev = stack.pop();
inorderIndex++;
}
prev.right = curr;
}
stack.push(curr);
}
return root;
}
}
复杂度分析
-
时间复杂度: O ( n log n ) O(n \log n) O(nlogn),其中 n n n 是数组 preorder \textit{preorder} preorder 的长度,即二叉搜索树的结点数。得到中序遍历序列需要 O ( n log n ) O(n \log n) O(nlogn) 的时间,前序遍历序列和中序遍历序列各需要遍历一次,构造二叉搜索树需要 O ( n ) O(n) O(n) 的时间,因此时间复杂度是 O ( n log n ) O(n \log n) O(nlogn)。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 preorder \textit{preorder} preorder 的长度,即二叉搜索树的结点数。空间复杂度主要是栈空间,因此空间复杂度是 O ( n ) O(n) O(n)。
解法三
思路和算法
解法一和解法二的做法是首先得到二叉搜索树的中序遍历序列,然后根据前序遍历序列和中序遍历序列构造二叉搜索树。其实,并不需要中序遍历序列,根据前序遍历序列即可构造二叉搜索树。
由于前序遍历序列的第一个元素值为根结点值,因此首先创建根结点,然后遍历前序遍历序列的其余元素值,对于每个值分别创建结点并插入二叉搜索树中,当遍历结束时所有结点都插入二叉搜索树中,二叉搜索树构造完毕。
由于插入结点的顺序和前序遍历的顺序相同,每次插入的结点一定是一个已有的结点的子结点,因此每次插入的结点在前序遍历序列中的位置一定在已有的结点之后,通过插入操作得到的二叉搜索树一定符合给定的前序遍历序列。
代码
class Solution {
public TreeNode bstFromPreorder(int[] preorder) {
TreeNode root = new TreeNode(preorder[0]);
int length = preorder.length;
for (int i = 1; i < length; i++) {
insert(root, preorder[i]);
}
return root;
}
public void insert(TreeNode root, int val) {
TreeNode insertNode = new TreeNode(val);
TreeNode node = root, parent = null;
while (node != null) {
parent = node;
if (node.val > val) {
node = node.left;
} else {
node = node.right;
}
}
if (parent.val > val) {
parent.left = insertNode;
} else {
parent.right = insertNode;
}
}
}
复杂度分析
-
时间复杂度: O ( n 2 ) O(n^2) O(n2),其中 n n n 是数组 preorder \textit{preorder} preorder 的长度,即二叉搜索树的结点数。需要执行 n n n 次插入操作,每次插入操作的时间复杂度取决于二叉搜索树的高度,最坏情况下二叉搜索树的高度是 O ( n ) O(n) O(n),此时总时间复杂度是 O ( n 2 ) O(n^2) O(n2)。
-
空间复杂度: O ( 1 ) O(1) O(1)。注意返回值不计入空间复杂度。
解法四
思路和算法
解法一和解法二利用了二叉搜索树的中序遍历序列单调递增的性质,但是由于需要排序,因此时间复杂度是 O ( n log n ) O(n \log n) O(nlogn)。在不排序的情况下利用单调性,则可以将时间复杂度降低到 O ( n ) O(n) O(n)。
对于前序遍历序列中的两个相邻的值 x x x 和 y y y,其对应结点的关系一定是以下两种情况之一:
-
如果 x > y x > y x>y,则结点 y y y 是结点 x x x 的左子结点;
-
如果 x < y x < y x<y,则结点 x x x 没有左子结点,结点 y y y 是结点 x x x 的右子结点,或者结点 y y y 是结点 x x x 的某个祖先结点的右子结点。
由于可以根据结点值的大小关系判断是两种情况的哪一种,因此可以使用单调栈实现构造二叉搜索树。单调栈存储结点,满足从栈底到栈顶的结点值单调递减。
由于前序遍历序列的第一个元素值为根结点值,因此首先创建根结点并将根结点入栈,然后遍历前序遍历序列的其余元素值并构造二叉搜索树。对于每个值,创建结点,然后比较当前值与栈顶结点值的大小,执行如下操作。
-
如果栈顶结点值大于当前值,则是第 1 种情况,即当前结点是栈顶结点的左子结点,因此将当前结点作为栈顶结点的左子结点,然后将当前结点入栈。
-
如果栈顶结点值小于当前值,则是第 2 种情况,即当前结点是栈顶结点或者栈顶结点的某个祖先结点的右子结点,因此将结点依次出栈,直到栈为空或者栈顶结点值大于当前值,将当前结点作为最后一个出栈结点的右子结点,然后将当前结点入栈。
当遍历结束时,二叉搜索树构造完毕。
上述操作中,初始时根结点已经入栈,每次创建结点之后都会将结点入栈,因此遍历到每个值的时候都可以确保栈不为空。
考虑示例 1 的前序遍历构造二叉搜索树,前序遍历是 [ 8 , 5 , 1 , 7 , 10 , 12 ] [8,5,1,7,10,12] [8,5,1,7,10,12]。
-
创建结点 8 8 8 作为根结点,将根结点入栈, stack = [ 8 ] \textit{stack} = [8] stack=[8],其中左边为栈底,右边为栈顶,栈内的结点用结点值表示。
-
创建结点 5 5 5,由于 8 > 5 8 > 5 8>5,因此将结点 5 5 5 作为结点 8 8 8 的左子结点,将结点 5 5 5 入栈, stack = [ 8 , 5 ] \textit{stack} = [8, 5] stack=[8,5]。
-
创建结点 1 1 1,由于 5 > 1 5 > 1 5>1,因此将结点 1 1 1 作为结点 5 5 5 的左子结点,将结点 1 1 1 入栈, stack = [ 8 , 5 , 1 ] \textit{stack} = [8, 5, 1] stack=[8,5,1]。
-
创建结点 7 7 7,由于 1 < 7 1 < 7 1<7 且 5 < 7 5 < 7 5<7,因此将结点 1 1 1 和结点 5 5 5 出栈,将结点 7 7 7 作为结点 5 5 5 的右子结点,将结点 7 7 7 入栈, stack = [ 8 , 7 ] \textit{stack} = [8, 7] stack=[8,7]。
-
创建结点 10 10 10,由于 7 < 10 7 < 10 7<10 且 8 < 10 8 < 10 8<10,因此将结点 7 7 7 和结点 8 8 8 出栈,将结点 10 10 10 作为结点 8 8 8 的右子结点,将结点 10 10 10 入栈, stack = [ 10 ] \textit{stack} = [10] stack=[10]。
-
创建结点 12 12 12,由于 10 < 12 10 < 12 10<12,因此将结点 10 10 10 出栈,将结点 12 12 12 作为结点 10 10 10 的右子结点,将结点 12 12 12 入栈, stack = [ 12 ] \textit{stack} = [12] stack=[12]。
此时遍历结束,二叉搜索树构造完毕。
代码
class Solution {
public TreeNode bstFromPreorder(int[] preorder) {
TreeNode root = new TreeNode(preorder[0]);
Deque<TreeNode> stack = new ArrayDeque<TreeNode>();
stack.push(root);
int length = preorder.length;
for (int i = 1; i < length; i++) {
int val = preorder[i];
TreeNode node = new TreeNode(val);
if (stack.peek().val > val) {
stack.peek().left = node;
} else {
TreeNode prev = null;
while (!stack.isEmpty() && stack.peek().val < val) {
prev = stack.pop();
}
prev.right = node;
}
stack.push(node);
}
return root;
}
}
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 preorder \textit{preorder} preorder 的长度,即二叉搜索树的结点数。需要执行 n n n 次插入操作,每个结点最多入栈和出栈各一次,因此时间复杂度是 O ( n ) O(n) O(n)。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 preorder \textit{preorder} preorder 的长度,即二叉搜索树的结点数。空间复杂度主要取决于栈空间,栈内结点个数不会超过 n n n。