本文通过一个回归例子介绍变分自编码器。产生训练和测试样本的代码如下:
# data
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def f(x, sigma):
# y = 10 * sin(2 * pi) + epsilon
return 10 * np.sin(2 * np.pi * (x)) + np.random.randn(*x.shape) * sigma
num_of_samples = 64 # 样本数
noise = 1.0 # 噪音规模
X = np.linspace(-0.5, 0.5, num_of_samples).reshape(-1, 1)
X_test = np.linspace(-1., 1., num_of_samples * 2).reshape(-1, 1).astype('float32')
y_label = f(X, sigma=noise) # 样本的label
y_truth = f(X, sigma=0.0) # 样本的真实值
plt.scatter(X, y_label, marker='+', label='Training data')
plt.plot(X, y_truth, label='Ground Truth')
plt.title('Noisy training data and ground truth')
plt.legend();
训练和测试样本来自正弦函数,并加入了高斯噪音:

首先采用简单的浅层神经网络模型:
class BaseModel():
def __init__(self):
self.w_0 = tf.Variable(tf.random.truncated_normal([1, 8], mean=0., stddev=1.))
self.b_0 = tf.Variable(tf.random.truncated_normal([8], mean=0., stddev=1.))
self.w_1 = tf.Variable(tf.random.truncated_normal([8, 8], mean=0., stddev=1.))
self.b_1 = tf.Variable(tf.random.truncated_normal([8], mean=0., stddev=1.))
self.w_2 = tf.Variable(tf.random.truncated_normal([8, 1], mean=0., stddev=1.))
self.b_2 = tf.Variable(tf.random.truncated_normal([1], mean=0., stddev=1.))
def forward(self, x):
x = tf.cast(x, tf.float32)
h = tf.math.sigmoid(tf.matmul(x, self.w_0) + self.b_0)
h = tf.math.sigmoid(tf.matmul(h, self.w_1) + self.b_1)
y = tf.matmul(h, self.w_2) + self.b_2
return y
def train_predict(self, x, label, x_test):
y = self.forward(x)
y_test = self.forward(x_test)
loss = tf.losses.mean_squared_error(y, label)
optimizer = tf.train.GradientDescentOptimizer(0.01, name="opt")
gradient = optimizer.compute_gradients(loss)
opt = optimizer.apply_gradients(gradient)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
train_batch = 0
while train_batch < 100000:
sess.run(opt)
if train_batch%1000 == 0:
print("train_batch : %s" % train_batch)
print(loss.eval())
train_batch += 1
predict = y_test.eval()
return predict
model = BaseModel()
y_test = model.train_predict(X, y_label, X_test)
plt.scatter(X, y_label, marker='+', label='Training data')
plt.plot(X_test, y_test, 'r-', label='Predict Line')
plt.grid()
plt.legend()
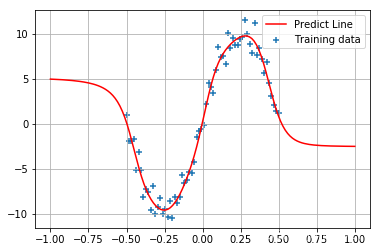
将训练目标改为最大似然目标:
class BaseModelV2():
def __init__(self):
self.w_0 = tf.Variable(tf.random.truncated_normal([1, 8], mean=0., stddev=1.))
self.b_0 = tf.Variable(tf.random.truncated_normal([8], mean=0., stddev=1.))
self.w_1 = tf.Variable(tf.random.truncated_normal([8, 8], mean=0., stddev=1.))
self.b_1 = tf.Variable(tf.random.truncated_normal([8], mean=0., stddev=1.))
self.w_2 = tf.Variable(tf.random.truncated_normal([8, 1], mean=0., stddev=1.))
self.b_2 = tf.Variable(tf.random.truncated_normal([1], mean=0., stddev=1.))
def forward(self, x):
x = tf.cast(x, tf.float32)
h = tf.math.sigmoid(tf.matmul(x, self.w_0) + self.b_0)
h = tf.math.sigmoid(tf.matmul(h, self.w_1) + self.b_1)
y = tf.matmul(h, self.w_2) + self.b_2
return y
def gaussian_pdf(self, x, mu, sigma):
return tf.compat.v1.distributions.Normal(mu,sigma).prob(x)
def train_predict(self, x, label, x_test):
y = self.forward(x)
y_test = self.forward(x_test)
loss = -tf.reduce_sum(self.gaussian_pdf(label, y, 1.0))
optimizer = tf.train.GradientDescentOptimizer(0.01, name="opt")
gradient = optimizer.compute_gradients(loss)
opt = optimizer.apply_gradients(gradient)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
train_batch = 0
while train_batch < 100000:
sess.run(opt)
if train_batch%1000 == 0:
print("train_batch : %s" % train_batch)
print(loss.eval())
train_batch += 1
predict = y_test.eval()
return predict
model = BaseModelV2()
y_test = model.train_predict(X, y_label, X_test)
plt.scatter(X, y_label, marker='+', label='Training data')
plt.plot(X_test, y_test, 'r-', label='Predict Line')
plt.grid()
plt.legend()
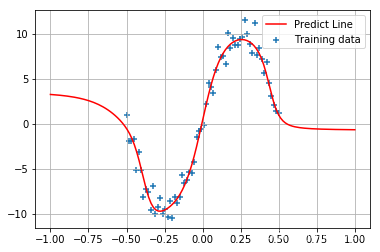
将模型改为变分推断模型:
from tensorflow.keras.activations import relu
from tensorflow.keras.optimizers import Adam
class VI():
def __init__(self):
self.prior_sigma_1 = 0.1
self.prior_sigma_2 = 1.5
self.w_0_mu = tf.Variable(tf.random.truncated_normal([1, 8], mean=0., stddev=1.))
#self.w_0_sigma = tf.Variable(tf.random.truncated_normal([1, 8], mean=0., stddev=1.))
self.w_0_sigma = tf.Variable(tf.zeros([1, 8]))
self.b_0_mu = tf.Variable(tf.random.truncated_normal([8], mean=0., stddev=1.))
self.b_0_sigma = tf.Variable(tf.zeros([8]))
self.w_1_mu = tf.Variable(tf.random.truncated_normal([8, 8], mean=0., stddev=1.))
self.w_1_sigma =tf.Variable(tf.zeros([8, 8]))
self.b_1_mu = tf.Variable(tf.random.truncated_normal([8], mean=0., stddev=1.))
self.b_1_sigma = tf.Variable(tf.zeros([8]))
self.w_2_mu = tf.Variable(tf.random.truncated_normal([8, 1], mean=0., stddev=1.))
self.w_2_sigma = tf.Variable(tf.zeros([8, 1]))
self.b_2_mu = tf.Variable(tf.random.truncated_normal([1], mean=0., stddev=1.))
self.b_2_sigma = tf.Variable(tf.zeros([1]))
self.mu = [self.w_0_mu, self.b_0_mu, self.w_1_mu, self.b_1_mu, self.w_2_mu, self.b_2_mu]
self.sigma = [self.w_0_sigma, self.b_0_sigma, self.w_1_sigma, self.b_1_sigma, self.w_2_sigma, self.b_2_sigma]
def sample_theta(self):
self.w_0 = self.w_0_mu + tf.math.softplus(self.w_0_sigma) * tf.random.normal(self.w_0_mu.shape)
self.b_0 = self.b_0_mu + tf.math.softplus(self.b_0_sigma) * tf.random.normal(self.b_0_mu.shape)
self.w_1 = self.w_1_mu + tf.math.softplus(self.w_1_sigma) * tf.random.normal(self.w_1_mu.shape)
self.b_1 = self.b_1_mu + tf.math.softplus(self.b_1_sigma) * tf.random.normal(self.b_1_mu.shape)
self.w_2 = self.w_2_mu + tf.math.softplus(self.w_2_sigma) * tf.random.normal(self.w_2_mu.shape)
self.b_2 = self.b_2_mu + tf.math.softplus(self.b_2_sigma) * tf.random.normal(self.b_2_mu.shape)
self.theta = [self.w_0, self.b_0, self.w_1, self.b_1, self.w_2, self.b_2]
def forward(self, x):
x = tf.cast(x, tf.float32)
self.sample_theta()
h = relu(tf.matmul(x, self.w_0) + self.b_0)
h = relu(tf.matmul(h, self.w_1) + self.b_1)
y = tf.matmul(h, self.w_2) + self.b_2
return y
def gaussian_pdf(self, x, mu, sigma):
return tf.compat.v1.distributions.Normal(mu,sigma).prob(x)
def prior(self, x):
# 混合高斯先验分布假设
return 0.5 * self.gaussian_pdf(x, 0.0, self.prior_sigma_1) + 0.5 * self.gaussian_pdf(x, 0.0, self.prior_sigma_2)
def train_predict(self, x, label, x_test):
y = self.forward(x)
y_test = self.forward(x_test)
loss = []
for (theta, mu, sigma) in zip(self.theta, self.mu, self.sigma):
q_theta_w = tf.math.log(self.gaussian_pdf(theta, mu, tf.math.softplus(sigma)) + 1e-30)
p_theta = tf.math.log(self.prior(theta) + 1E-30)
loss.append(tf.math.reduce_sum(q_theta_w - p_theta))
p_d_theta = tf.math.reduce_sum(tf.math.log(self.gaussian_pdf(label, y, 1.0) + 1E-30))
loss.append(tf.math.reduce_sum(-p_d_theta))
loss = tf.reduce_sum(loss)
optimizer = tf.train.GradientDescentOptimizer(0.001, name="opt")
gradient = optimizer.compute_gradients(loss)
opt = optimizer.apply_gradients(gradient)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
train_batch = 0
while train_batch < 100000:
sess.run(opt)
if train_batch%1000 == 0:
print("train_batch : %s" % train_batch)
print(loss.eval())
train_batch += 1
predict_num = 0
predicts = []
while predict_num < 300:
predict = y_test.eval()
predicts.append(predict)
predict_num += 1
return predicts
model = VI()
y_test = model.train_predict(X, y_label, X_test)
y_test = np.concatenate(y_test, axis=1)
plt.scatter(X, y_label, marker='+', label='Training data')
plt.plot(X_test, np.mean(y_test, axis=1), 'r-', label='Predict Line')
plt.fill_between(X_test.reshape(-1), np.percentile(y_test, 2.5, axis=1), np.percentile(y_test, 97.5, axis=1), color='r', alpha=0.3, label='95% Confidence')
plt.grid()
plt.legend()
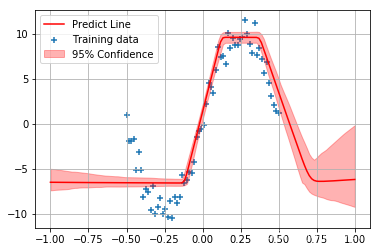
最后将模型改为条件变分自编码器:
from tensorflow.keras.activations import relu
class CVAE():
def __init__(self):
# prior
self.z_dim = 8
self.prior_w_mu = tf.Variable(tf.random.truncated_normal([1+1, self.z_dim], mean=0., stddev=1.))
self.prior_b_mu = tf.Variable(tf.random.truncated_normal([self.z_dim], mean=0., stddev=1.))
self.prior_w_mu_1 = tf.Variable(tf.random.truncated_normal([self.z_dim + 1, self.z_dim], mean=0., stddev=1.))
self.prior_b_mu_1 = tf.Variable(tf.random.truncated_normal([self.z_dim], mean=0., stddev=1.))
# encode
self.encode_w_mu = tf.Variable(tf.random.truncated_normal([2+1, self.z_dim], mean=0., stddev=1.))
self.encode_b_mu = tf.Variable(tf.random.truncated_normal([self.z_dim], mean=0., stddev=1.))
self.encode_w_mu_1 = tf.Variable(tf.random.truncated_normal([self.z_dim+1, self.z_dim], mean=0., stddev=1.))
self.encode_b_mu_1 = tf.Variable(tf.random.truncated_normal([self.z_dim], mean=0., stddev=1.))
# decode
self.w_1 = tf.Variable(tf.random.truncated_normal([self.z_dim + 1, 8], mean=0., stddev=1.))
self.b_1 = tf.Variable(tf.random.truncated_normal([8], mean=0., stddev=1.))
self.w_2 = tf.Variable(tf.random.truncated_normal([8 + 1, 1], mean=0., stddev=1.))
self.b_2 = tf.Variable(tf.random.truncated_normal([1], mean=0., stddev=1.))
def prior(self, x):
# mu, sigma = PriorNet(x)
ones = tf.ones_like(x)
x = tf.concat([x, ones], axis=1)
h = tf.math.sigmoid(tf.matmul(x, self.prior_w_mu) + self.prior_b_mu)
h = tf.concat([h, ones], axis=1)
p_mu = tf.matmul(h, self.prior_w_mu_1) + self.prior_b_mu_1
with tf.variable_scope("cvae_prior_net", reuse=tf.AUTO_REUSE):
p_sigma = tf.get_variable("prior_sigma",
dtype=tf.float32,
initializer=tf.zeros([self.z_dim]),
trainable=True)
return p_mu, p_sigma
def encode(self, x, label):
# mu, sigma = EncodeNet(x)
ones = tf.ones_like(x)
x = tf.concat([x, label, ones], axis=1)
h = tf.math.sigmoid(tf.matmul(x, self.encode_w_mu) + self.encode_b_mu)
h = tf.concat([h, ones], axis=1)
q_mu = tf.matmul(h, self.encode_w_mu_1) + self.encode_b_mu_1
with tf.variable_scope("cvae_encode_net", reuse=tf.AUTO_REUSE):
q_sigma = tf.get_variable("encode_sigma",
dtype=tf.float32,
initializer=tf.zeros([self.z_dim]),
trainable=True)
return q_mu, q_sigma
def sample(self, mu, sigma):
return mu + tf.math.softplus(sigma) * tf.random.normal(tf.shape(mu))
def decode(self, z):
ones = tf.ones([tf.shape(z)[0], 1])
z = tf.concat([z, ones], axis=1)
h = tf.math.sigmoid(tf.matmul(z, self.w_1) + self.b_1)
h = tf.concat([h, ones], axis=1)
y = tf.matmul(h, self.w_2) + self.b_2
return y
def forward(self, x, label):
p_mu, p_sigma = self.prior(x)
q_mu, q_sigma = self.encode(x, label)
z = self.sample(q_mu, q_sigma)
y = self.decode(z)
return p_mu, p_sigma, q_mu, q_sigma, z, y
def predict(self, x):
p_mu, p_sigma = self.prior(x)
z = self.sample(p_mu, p_sigma)
y = self.decode(z)
return p_mu, p_sigma, z, y
def gaussian_pdf(self, x, mu, sigma):
return tf.compat.v1.distributions.Normal(mu, sigma).prob(x)
def train_predict(self, x, label, x_test):
x = tf.cast(x, tf.float32)
label = tf.cast(label, tf.float32)
p_mu, p_sigma, q_mu, q_sigma, z, y = self.forward(x, label)
p_mu_test, p_sigma_test, z_test, y_test = self.predict(x_test)
p_y_z = tf.reduce_sum(tf.math.log(self.gaussian_pdf(label, y, 1.0) + 1e-30))
q_z_x = tf.reduce_sum(tf.math.log(self.gaussian_pdf(z, q_mu, tf.math.softplus(q_sigma)) + 1e-30))
p_z_x = tf.reduce_sum(tf.math.log(self.gaussian_pdf(z, p_mu, tf.math.softplus(p_sigma)) + 1e-30))
dkl = q_z_x - p_z_x
loss = dkl - p_y_z
optimizer = tf.train.GradientDescentOptimizer(0.001, name="opt")
gradient = optimizer.compute_gradients(loss)
opt = optimizer.apply_gradients(gradient)
init = tf.global_variables_initializer()
predict = []
loss_list = []
first_term = []
sec_term = []
with tf.Session() as sess:
sess.run(init)
print(p_y_z.eval())
print(q_z_x.eval())
print(p_z_x.eval())
print(loss.eval())
train_batch = 0
while train_batch < 100000:
sess.run(opt)
if train_batch%100== 0:
loss_val = loss.eval()
loss_list.append(loss_val)
dkl_val = dkl.eval()
first_term.append(dkl_val)
p_y_z_eval = p_y_z.eval()
sec_term.append(p_y_z_eval)
print("train_batch : %s" % train_batch)
print(loss_val)
train_batch += 1
predict_num = 0
while predict_num < 300:
predict.append(y_test.eval())
predict_num += 1
return predict, first_term, sec_term, loss_list
tf.reset_default_graph()
model = CVAE()
y_preds, dkl, prob, losses = model.train_predict(X, y_label, X_test)
y_preds = np.concatenate(y_preds, axis=1)
plt.figure(figsize=(10,6))
plt.scatter(X, y_label, marker='+', label='Training data')
plt.plot(X_test, np.mean(y_preds, axis=1), 'r-', label='Predict Line')
plt.fill_between(X_test.reshape(-1), np.percentile(y_preds, 2.5, axis=1), np.percentile(y_preds, 97.5, axis=1), color='r', alpha=0.3, label='95% Confidence')
plt.grid()
plt.legend()
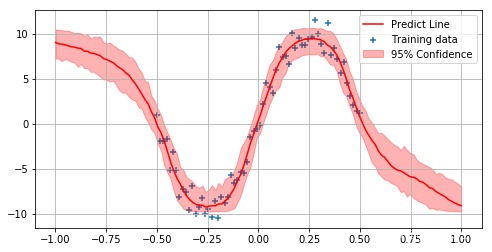
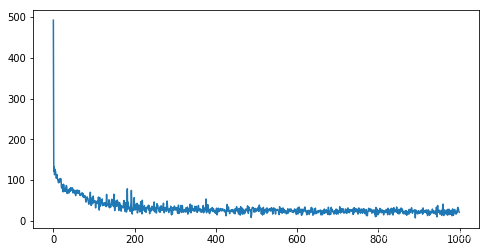
loss 的变化情况:
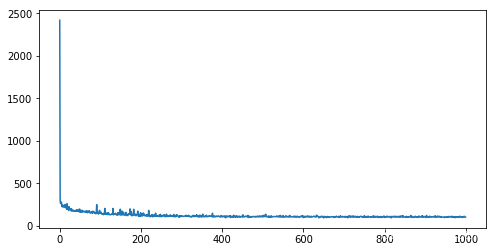
先验和后验分布的KL散度的变化情况: