背景
XOP服务运行期间,查看Grafana面板,发现堆内存周期性堆积,观察FullGC的时间,xxx,需要调查下原因

目录
- 垃圾收集器概述
- 常见的垃圾收集器
- 分区收集策略
- 为什么CMS没成为默认收集器
- 查看JVM运行时环境
- 分析快照
- PhantomReference虚引用
- AbandonedConnectionCleanupThread源码分析
- 原因分析
- 解决方案
1、垃圾收集器概述
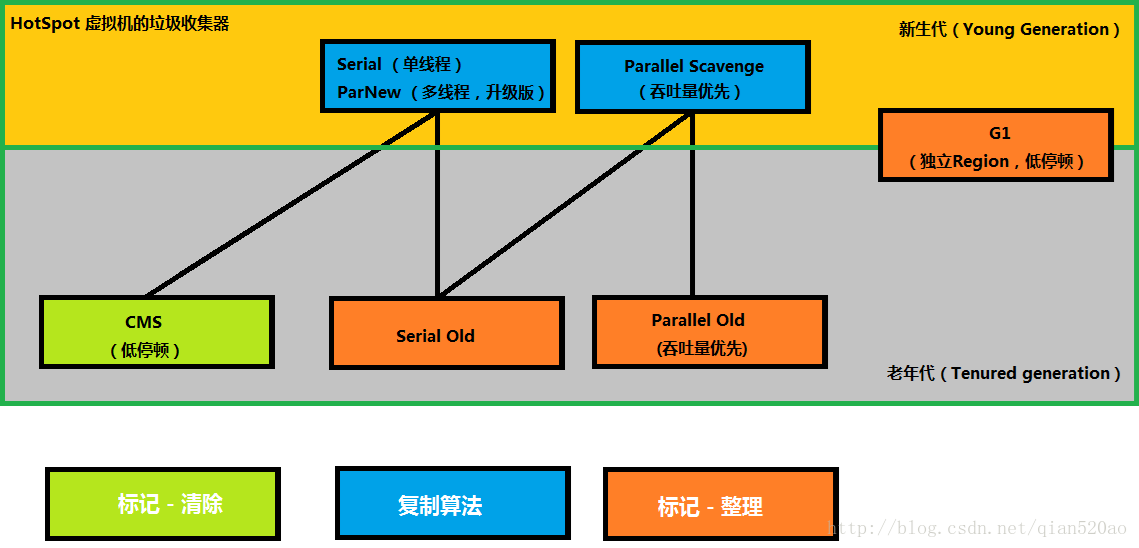
1.1、常见的垃圾收集器
按照收集策略划分
- 新生代收集器:Serial、ParNew、Parallel Scavenge;
- 老年代收集器:Serial Old、Parallel Old、CMS;
- 整堆分区收集器:G1、ZGC、Shenandoah
吞吐量优先、停顿时间优先
- 吞吐量优先:Parallel Scavenge收集器、Parallel Old 收集器。
- 停顿时间优先:CMS(Concurrent Mark-Sweep)收集器。
吞吐量与停顿时间适用场景
- 吞吐量优先:交互少,计算多,适合在后台运算的场景。
- 停顿时间优先:交互多,对响应速度要求高
串行、并行、并发
- 串行:Serial、Serial Old,垃圾回收必须暂停全部工作线程,无法利用多核优势。
- 并行:ParNew、Parallel Scavenge、Parallel Old,并行描述的是多条垃圾收集器线程之前的关系,说明同一时间有多条垃圾收集器线程在工作,此时用户线程默认是处于等待状态。
- 并发:CMS、G1,并发描述的是垃圾收集器线程和用户线程之间的关系
算法,参考往期博客
- 复制算法:Serial、ParNew、Parallel Scavenge、G1
- 标记-清除:CMS
- 标记-整理:Serial Old、Parallel Old、G1
通过参数选择需要使用的垃圾收集器
-XX:+UseSerialGC,虚拟机运行在Client模式下的默认值,Serial+Serial Old。-XX:+UseParNewGC,ParNew+Serial Old,在JDK1.8被废弃,在JDK1.7还可以使用。-XX:+UseConcMarkSweepGC,ParNew+CMS+Serial Old。-XX:+UseParallelGC,虚拟机运行在Server模式下的默认值,Parallel Scavenge+Serial Old(PS Mark Sweep)。-XX:+UseParallelOldGC,Parallel Scavenge+Parallel Old。-XX:+UseG1GC,G1+G1。
1.2、分区收集策略
JDK7/8使用采用分代收集比较多的垃圾收集器组合
 另外随着JDK版本更新,JDK9之后默认的垃圾收集器为G1,之前分代收集思想逐渐被分区收集思想代替,考虑的是收集堆内存的哪个部分才能获得收益最大,如G1、ZGC-JDK15开始准备好生产了、Shenandoah,并且随着JDK的版本的升级吞吐量、响应速度都在不断优化提升。
另外随着JDK版本更新,JDK9之后默认的垃圾收集器为G1,之前分代收集思想逐渐被分区收集思想代替,考虑的是收集堆内存的哪个部分才能获得收益最大,如G1、ZGC-JDK15开始准备好生产了、Shenandoah,并且随着JDK的版本的升级吞吐量、响应速度都在不断优化提升。
- G1:开创了垃圾收集器面向局部收集的设计思路 和 基于Region的内存布局形式。不再像之前那样划代,而是把连续的堆内存划分为一块块的Region,每一个Region都可以根据需要充当之前分代区域的Eden、Survivor、老年代空间,除此之外还有一类特殊的Humongous区域专门用于存储大对象。它可以面向堆内存任何部分来组成回收集(Collection Set),衡量标准不再是它属于哪个分代,而是哪块内存中存放的垃圾数量最多,回收收益最大,优先处理回收收益最大的那些 Region,这也就是 Garbage First 名字的由来。
- Shennandoah:一款RedHat独立开发后来贡献给OpenJDK的收集器,在OracleJDK不存在,目标之一是暂停时间与堆大小无关,并且经过优化,中断时间不超过几毫秒。
- ZGC:目标和Shennandoah类似,希望在对吞吐量影响不大的情况下(相比G1应用程序吞吐量减少不超过15%),实现任意堆内存大小都可以吧垃圾收集器停顿时间限制在十毫秒内。
深入学习参考
- GC - Java 垃圾回收器之G1详解
- Java Hotspot G1 GC的一些关键技术-美团技术团队
- 新一代垃圾回收器ZGC的探索与实践-美团技术团队
1.3、为什么CMS从来没成为默认收集器
CMS(Concurrent Mark Sweep)是一种 以获取最短回收停顿时间为目标 的收集器。
在 JDK 5 发布时,HotSpot 虚拟机推出了一款在强交互应用中具有划时代意义的垃圾收集器——CMS 收集器。这款收集器是 HotSpot 中第一款真正意义上支持并发的垃圾收集器,它首次实现了让垃圾收集线程与用户线程(基本上)同时工作。
CMS 比 G1 早不了多少。CMS 从 JDK 5 开始加入,6 成熟;而 G1 是 7 加入,8 成熟,9 正式成为默认 GC 策略。此时 CMS 就被标记为 Deprecated,随后在 JDK 14 中被移除。
CMS并不是一个非常成功的GC策略,GC优化一般考虑点是吞吐量和响应时间,而CMS
- 采用标记-清除算法,当处理器核比较少的时候,会造成比较大的负载,而且容易产生内存碎片,碎片太多无能为力的时候触发Concurrent Mode Failure还需要Serial Old来擦屁股。
- 仅针对老年代,还需要一个新生代收集器,但是和Parallel Scavenage又不兼容,只能选择性能不如Parallel Scavenage的PerNew。
- 需要调整的参数比较多,比G1多一倍
以上的种种,造成的结果就是 ParNew + CMS + Serial Old 的组合工作起来其实并不稳定。为了得到 CMS 那一点好处,需要付出很多的代价(包括 JVM 调参)。
CMS 相比前辈们,没有带来革命性的改变;而它的后辈们比它强太多。它自身的实现又很复杂,兼容性又差,调参也很麻烦,所以无法成为默认 GC 方案了。
参考
- Java——七种垃圾收集器+JDK11最新ZGC
- 面试:JVM 垃圾回收器-腾讯云开发者社区-腾讯云
- Java 8 vs Java 17 垃圾收集器
2、查看JVM运行时环境
数据库环境是MySQL,连接池使用的是HikariPool,驱动是mysql-connector-java-8.0.21.jar,当前生产环境JVM运行参数
// 测试环境举例
root 14968 1 0 2月23 ? 00:41:51
java -server
-XX:MetaspaceSize=160m
-XX:MaxMetaspaceSize=160m
-Xms1024m
-Xmx1024m
-Xss256k
-Duser.timezone=GMT+08
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled
-XX:CMSInitiatingOccupancyFraction=80
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/data/serviceroot/xkw-xopqbm-api-service/xkw-xopqbm-api-service.hprof
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-Xloggc:/data/serviceroot/xkw-xopqbm-api-service/logs/xkw-xopqbm-api-service-gc.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=1m
-jar /data/serviceroot/xkw-xopqbm-api-service/xkw-xopqbm-api-service.jar
--spring.profiles.active=test
--server.port=9501
-Dons.client.logLevel=ERROR
当前服务器的java版本为1.8
[root@localmdmtest ~]# java -version
java version "1.8.0_281"
Java(TM) SE Runtime Environment (build 1.8.0_281-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.281-b09, mixed mode)
查看使用的垃圾收集器 jmap -heap pid,可以看到当前使用的垃圾收集器 ParNew+CMS+Serial Old
[root@localmdmtest ~]# jmap -heap 14968
Attaching to process ID 14968, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.281-b09
using parallel threads in the new generation.
using thread-local object allocation.
# Concurrent Mark-Sweep GC :CMS回收器
# Mark Sweep Compact GC: 串行GC(Serial GC)
# Parallel GC with 2 thread(s): 并行GC(ParNew)
# 这里看出是CMS
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1073741824 (1024.0MB)
NewSize = 357892096 (341.3125MB)
MaxNewSize = 357892096 (341.3125MB)
OldSize = 715849728 (682.6875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 167772160 (160.0MB)
CompressedClassSpaceSize = 159383552 (152.0MB)
MaxMetaspaceSize = 167772160 (160.0MB)
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 322109440 (307.1875MB)
used = 245758352 (234.37342834472656MB)
free = 76351088 (72.81407165527344MB)
76.2965382200534% used
Eden Space:
capacity = 286326784 (273.0625MB)
used = 239080888 (228.00530242919922MB)
free = 47245896 (45.05719757080078MB)
83.49930965592098% used
From Space:
capacity = 35782656 (34.125MB)
used = 6677464 (6.368125915527344MB)
free = 29105192 (27.756874084472656MB)
18.66117484403617% used
To Space:
capacity = 35782656 (34.125MB)
used = 0 (0.0MB)
free = 35782656 (34.125MB)
0.0% used
concurrent mark-sweep generation:
capacity = 715849728 (682.6875MB)
used = 84539240 (80.6229019165039MB)
free = 631310488 (602.0645980834961MB)
11.809634996466745% used
45864 interned Strings occupying 4725904 bytes.
3、分析快照
dump快照命令:jmap -dump:live,format=b,file=/home/scl/xopqbm/heapdump.hprof xxx
可以使用MAT或者在线工具https://heaphero.io/分析快照,发现11,319 instances of "com.mysql.cj.jdbc.AbandonedConnectionCleanupThread$ConnectionFinalizerPhantomReference"

也就是ConnectionFinalizerPhantomReference占了80%的堆内存,为什么会这么多对象,需要分析下原因。
AbandonedConnectionCleanupThread类是 MySQL JDBC 驱动中用于清理被遗弃连接的线程类。这个类主要用于防止数据库连接泄露,通过在后台运行来清理那些没有正确关闭的数据库连接。
3.1、PhantomReference虚引用
分析之前需要先知道虚引用的概念,分析的是mysql-connector-java-8.0.21.jar下的包com.mysql.cj.jdbc
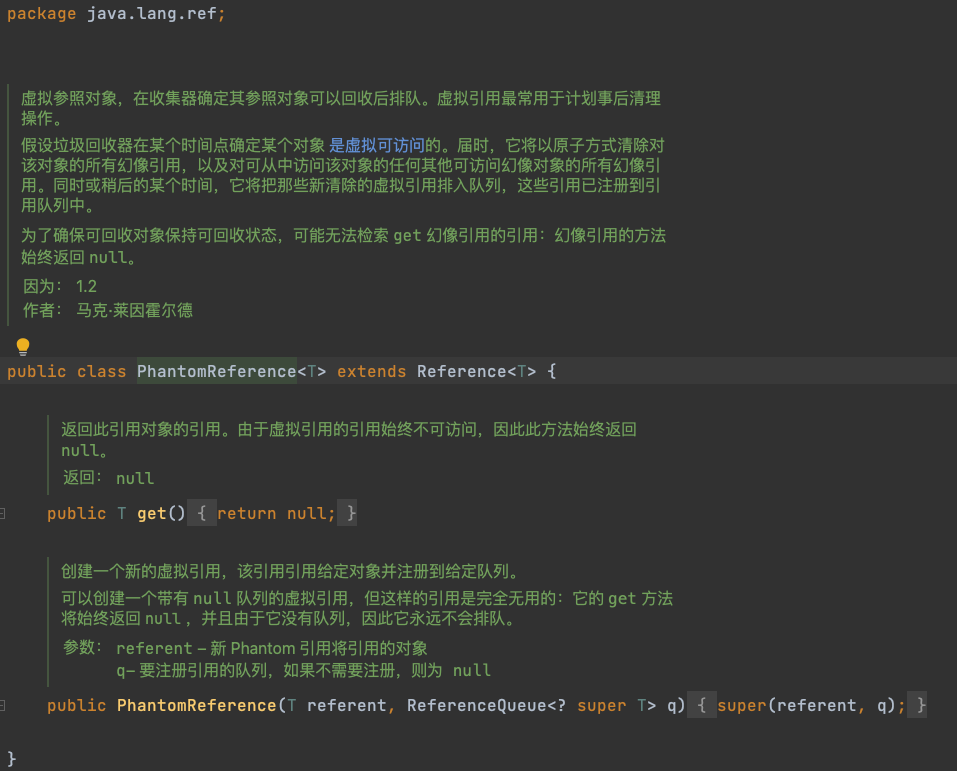
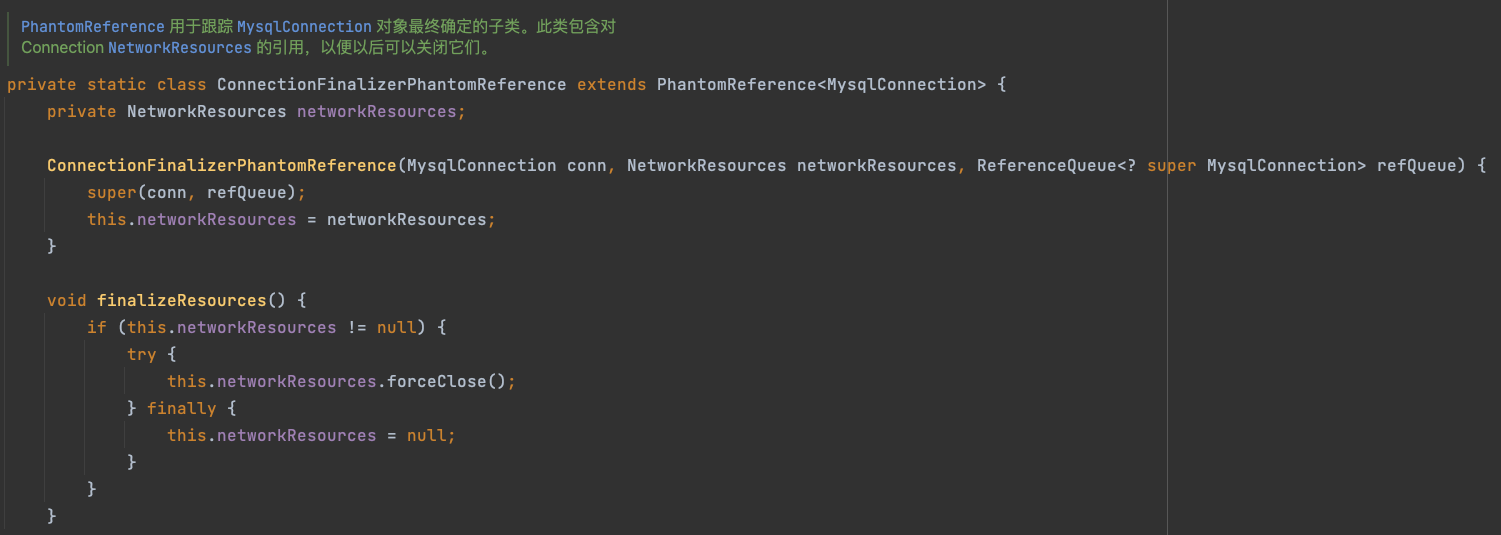
ConnectionFinalizerPhantomReference这个类在AbandonedConnectionCleanupThread类内定义,继承PhantomReference,PhantomReference是JVM四大引用之一虚引用
// AbandonedConnectionCleanupThread类内
private static class ConnectionFinalizerPhantomReference extends PhantomReference<MysqlConnection> {
private NetworkResources networkResources;
ConnectionFinalizerPhantomReference(MysqlConnection conn, NetworkResources networkResources, ReferenceQueue<? super MysqlConnection> refQueue) {
super(conn, refQueue);
this.networkResources = networkResources;
}
// 销毁资源
void finalizeResources() {
if (this.networkResources != null) {
try {
this.networkResources.forceClose();
} finally {
this.networkResources = null;
}
}
}
}
虚引用也称为“幽灵引用”,它是最弱的一种引用关系。对于PhantomReference虚引用的概念,简单就是他可以将某个对象标记,一般和虚引用队列配合使用,一般用于检测标记对象是否被GC回收,当虚引用对象被GC标记可回收的时候,在回收之前,该对象会被放入虚引用队列,
- 如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
- 为一个对象设置虚引用关联的唯一目的只是为了能在这个对象被收集器回收时收到一个系统通知。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在垃圾回收后,将这个虚引用加入引用队列,在其关联的虚引用出队前,不会彻底销毁该对象。所以可以通过检查引用队列中是否有相应的虚引用来判断对象是否已经被回收了。
虚引用理解demo1
static ReferenceQueue<Object> queue = new ReferenceQueue<>();
public static void main(String[] args) throws InterruptedException {
PhantomReference<Object> phantomReference = buildReference();
System.gc();Thread.sleep(100);
System.out.println(queue.poll());
}
public static PhantomReference<Object> buildReference() {
Object o = new Object();
// 绑定对象和虚引用队列
return new PhantomReference<>(o, queue);
}
虚引用理解demo2
public static void main(String[] args) {
ReferenceQueue<byte[]> queue = new ReferenceQueue<>();
PhantomReference<byte[]> phantomReference = new PhantomReference<>(
new byte[1024 * 1024 * 2], queue);
System.gc();Thread.sleep(100L);
System.out.println(queue.poll());
// 只有虚引用直接置为 null,此时才会被回收掉,如果不设置的话还是不会回收
// 可以设置 内存大小为 5M -Xmx5m -Xms5m,然后吧下面代码加上或者不加上,
// 会发现没有吧虚引用对象设置为null的情况下,对象未被回收,在申请的话会OOM
phantomReference = null;
byte[] bytes = new byte[1024 * 1024 * 4];
}
如果我们使用了虚引用,但是没有及时清理虚引用的话可能会导致内存泄露。
3.2、AbandonedConnectionCleanupThread源码分析
分析的是mysql-connector-java 8.0.21版本
相关属性
// 是对数据库连接的一个幽灵引用(PhantomReference)线程安全的集合
// 用于跟踪数据库连接何时可以被垃圾回收器回收。
private static final Set<ConnectionFinalizerPhantomReference> connectionFinalizerPhantomRefs = ConcurrentHashMap.newKeySet();
// 对象被垃圾回收器标记为可回收时,它的引用会被添加到这个队列中。
private static final ReferenceQueue<MysqlConnection> referenceQueue = new ReferenceQueue<>();
// 线程池
private static final ExecutorService cleanupThreadExcecutorService;
// 清理线程的引用
private static Thread threadRef = null;
// 锁对象
private static Lock threadRefLock = new ReentrantLock();
初始化清理线程的静态代码块
通过这个静态初始化块,AbandonedConnectionCleanupThread 类确保了在类被加载时,一个用于清理被遗弃数据库连接的守护线程将被创建并启动。这个设计允许应用程序在运行期间自动管理和清理未正确关闭的数据库连接,从而减少资源泄露的风险。
static {
// 创建单线程执行器
cleanupThreadExcecutorService = Executors.newSingleThreadExecutor(r -> {
Thread t = new Thread(r, "mysql-cj-abandoned-connection-cleanup");
t.setDaemon(true);
// Tie the thread's context ClassLoader to the ClassLoader that loaded the class instead of inheriting the context ClassLoader from the current
// thread, which would happen by default.
// Application servers may use this information if they attempt to shutdown this thread. By leaving the default context ClassLoader this thread
// could end up being shut down even when it is shared by other applications and, being it statically initialized, thus, never restarted again.
// 设置线程的上下文类加载器,这是为了确保线程在执行时能够访问正确的类和资源。
// 如果当前类类是Bootstrap顶级加载器加载的,classLoader为null
ClassLoader classLoader = AbandonedConnectionCleanupThread.class.getClassLoader();
if (classLoader == null) {
// 则将系统类加载器(ClassLoader.getSystemClassLoader())设置为线程的上下文类加载器。
// This class was loaded by the Bootstrap ClassLoader, so lets tie the thread's context ClassLoader to the System ClassLoader instead.
classLoader = ClassLoader.getSystemClassLoader();
}
t.setContextClassLoader(classLoader);
return threadRef = t;
});
cleanupThreadExcecutorService.execute(new AbandonedConnectionCleanupThread());
}
为什么要设置线程下上文类加载器
关于JDK1.2-JDK9使用的类加载器以及双亲委派模型参考往期博客:《深入理解Java虚拟机第3版》类文件结构、虚拟机类加载机制
在Java中,类加载器(ClassLoader)是用于加载类的一个对象。每个类都有一个类加载器,负责将类的字节码加载到Java虚拟机(JVM)中。当你创建一个新的线程时,这个线程会继承创建它的线程的上下文类加载器。设置线程的上下文类加载器是为了确保线程能够访问正确的类和资源,特别是在执行任务时需要加载类或资源的场景下。
为什么需要设置线程的上下文类加载器?
在复杂的应用环境中,特别是在运行在容器中的应用(如Web应用运行在Servlet容器中),不同的组件可能由不同的类加载器加载。如果不正确设置线程的上下文类加载器,线程可能无法找到或访问特定的类或资源,因为它默认使用的类加载器可能不是加载这些资源的类加载器。
举个例子,假设我们有一个Web应用,它运行在一个Servlet容器中,如Tomcat。这个Web应用使用了一个第三方库,这个库在后台启动了一个线程来执行某些任务。这个任务需要加载一些只有Web应用类加载器Application ClassLoader才知道的类(例如,Web应用中定义的类)。
public class MyTask implements Runnable {
@Override
public void run() {
// 任务逻辑,可能需要加载特定的类
}
}
public class MyLibrary {
public void startTask() {
Thread taskThread = new Thread(new MyTask(), "MyTaskThread");
// 设置线程的上下文类加载器为当前类的类加载器
taskThread.setContextClassLoader(MyLibrary.class.getClassLoader());
taskThread.start();
}
}
在这个例子中,MyLibrary 类的 startTask 方法创建并启动了一个新的线程来执行 MyTask。为了确保这个线程能够访问Web应用中定义的类,我们通过调用 setContextClassLoader 方法将线程的上下文类加载器设置为 MyLibrary 类的类加载器。这样,当 MyTask 运行时,它就能够加载和访问那些特定的类了。
如果 MyLibrary 类是由Bootstrap类加载器加载的(这在实际中很少见,因为Bootstrap类加载器主要加载Java核心类库),那么 MyLibrary.class.getClassLoader() 会返回 null。在这种情况下,我们可以将系统类加载器(ClassLoader.getSystemClassLoader())设置为线程的上下文类加载器,以确保线程能够访问系统类路径上的类和资源。
清理数据库连接资源相关方法
public void run() {
for (;;) {
try {
// 检查线程的上下文类加载器是否可哟哦那个
checkThreadContextClassLoader();
// 删除队列的下一个元素,超时时间是5000ms,期间需要加锁
Reference<? extends MysqlConnection> reference = referenceQueue.remove(5000);
if (reference != null) {
// 将持有的数据库连接虚引用对象释放,因为虚引用对象已经到了虚引用队列,下一步就会被GC回收
finalizeResource((ConnectionFinalizerPhantomReference) reference);
}
} catch (InterruptedException e) {
threadRefLock.lock();
try {
threadRef = null;
// Finalize remaining references.
Reference<? extends MysqlConnection> reference;
while ((reference = referenceQueue.poll()) != null) {
finalizeResource((ConnectionFinalizerPhantomReference) reference);
}
connectionFinalizerPhantomRefs.clear();
} finally {
threadRefLock.unlock();
}
return;
} catch (Exception ex) {
// Nowhere to really log this.
}
}
}
检查该类的线程上下文加载器

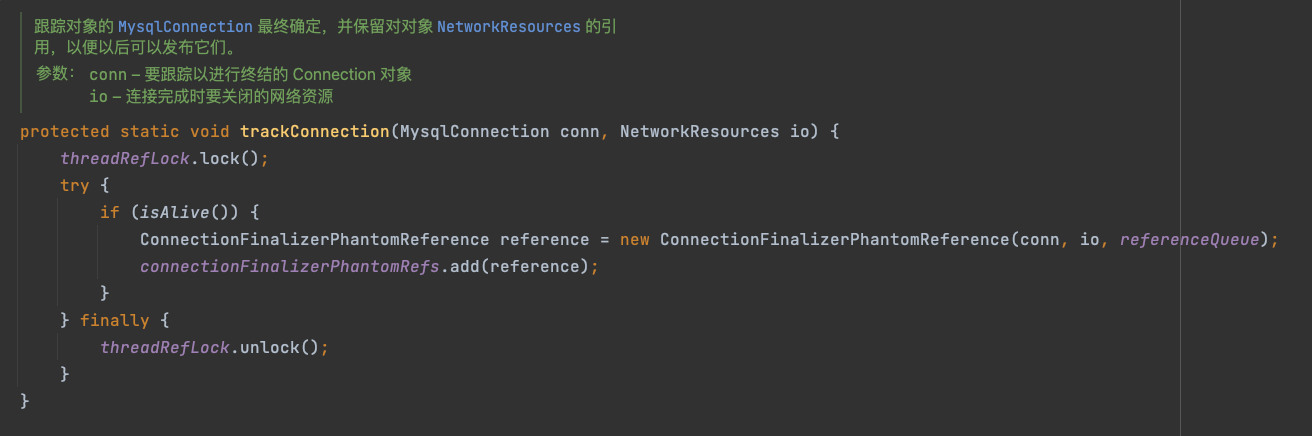
从虚引用队列取出一个虚引用实例,内部逻辑释放虚引用实例标记的数据库连接资源MySQL Connection,然后移除该虚引用实例

具体的关闭MySQL Connection逻辑在NetworkSource类,该类是对Socket mysqlConnection、输入、输出流的封装
/**
* Forcibly closes the underlying socket to MySQL.
*/
public final void forceClose() {
// 关闭connectioon的输入流
try {
if (!ExportControlled.isSSLEstablished(this.mysqlConnection)) { // Fix for Bug#56979 does not apply to secure sockets.
try {
if (this.mysqlInput != null) {
this.mysqlInput.close();
}
} finally {
if (this.mysqlConnection != null && !this.mysqlConnection.isClosed() && !this.mysqlConnection.isInputShutdown()) {
try {
this.mysqlConnection.shutdownInput();
} catch (UnsupportedOperationException e) {
// Ignore, some sockets do not support this method.
}
}
}
}
} catch (IOException e) {
// Can't do anything constructive about this.
}
// 关闭connectioon的输出流
try {
if (!ExportControlled.isSSLEstablished(this.mysqlConnection)) { // Fix for Bug#56979 does not apply to secure sockets.
try {
if (this.mysqlOutput != null) {
this.mysqlOutput.close();
}
} finally {
if (this.mysqlConnection != null && !this.mysqlConnection.isClosed() && !this.mysqlConnection.isOutputShutdown()) {
try {
this.mysqlConnection.shutdownOutput();
} catch (UnsupportedOperationException e) {
// Ignore, some sockets do not support this method.
}
}
}
}
} catch (IOException e) {
// Can't do anything constructive about this.
}
// 关闭connection连接
try {
if (this.mysqlConnection != null) {
this.mysqlConnection.close();
}
} catch (IOException e) {
// Can't do anything constructive about this.
}
}
Socket和MySQLConnectioon之间的联系
上述关闭数据库连接资源是关闭的Socket和输入输出流,但是MySQL JDBC驱动定义的数据库连接资源是MySQLConnection类
- 在 Java 中,Socket 类是 java.net 包的一部分,用于实现网络通信。数据库连接资源标记方法
- 这通常是指在 MySQL JDBC 驱动中定义的一个类,用于表示与 MySQL 数据库的连接。MySQLConnection 不是 Java 标准库的一部分,而是 MySQL Connector/J(MySQL 的官方 JDBC 驱动)或其他 JDBC 驱动实现中的一个类。这个类封装了与 MySQL 数据库服务器进行通信所需的所有细节,包括发送查询、接收结果等。
二者之间的联系:MySQLConnection 和 Socket 类之间的联系主要体现在 MySQLConnection 使用 Socket 来实现与 MySQL 数据库服务器的网络通信。当你使用 JDBC 驱动连接到 MySQL 数据库时,MySQLConnection 类的实例背后通常会创建一个 Socket 连接,通过这个 Socket 连接发送 SQL 命令给数据库服务器,并接收服务器的响应。具体来说,MySQLConnection 类的实现会处理以下任务:
- 解析数据库连接 URL,提取服务器地址、端口号等信息。
- 使用提取的信息,创建一个 Socket 实例,连接到 MySQL 服务器。
- 管理 Socket 连接的生命周期,包括打开连接、发送数据、接收数据以及最终关闭连接。
- 封装 SQL 命令的发送和结果集的接收,提供给应用程序一个高级的接口来执行数据库操作。
因此,虽然应用程序开发者在使用 JDBC 进行数据库操作时不直接与 Socket 类打交道,但 MySQLConnection 的实现确实依赖于 Socket 来完成与 MySQL 数据库服务器的底层通信。这种设计抽象了网络通信的复杂性,使得开发者可以专注于 SQL 逻辑和数据处理,而不需要处理网络编程的细节。
初始化数据库连接并标记为虚引用
位于java.sql包下的Conection是为各个MySQL驱动提供的统一接口,MysqlConnection、JdbcConnection则是位于 com.mysql.cj包下厂商的实现,ProxyConnection、HikarProxyConnection则是com.zaxxer.hikari.pool包下的类
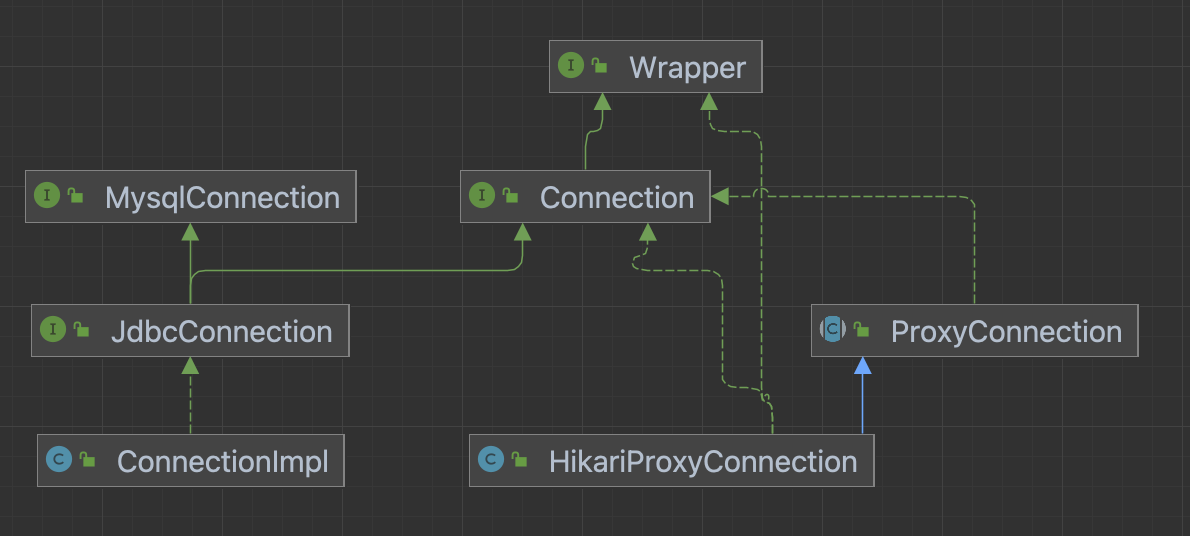
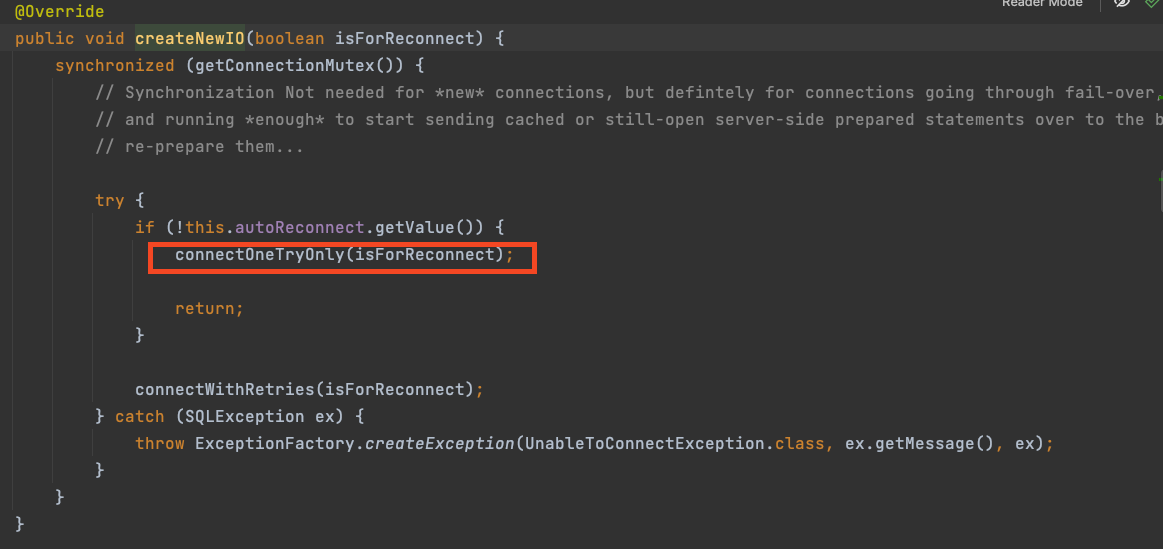
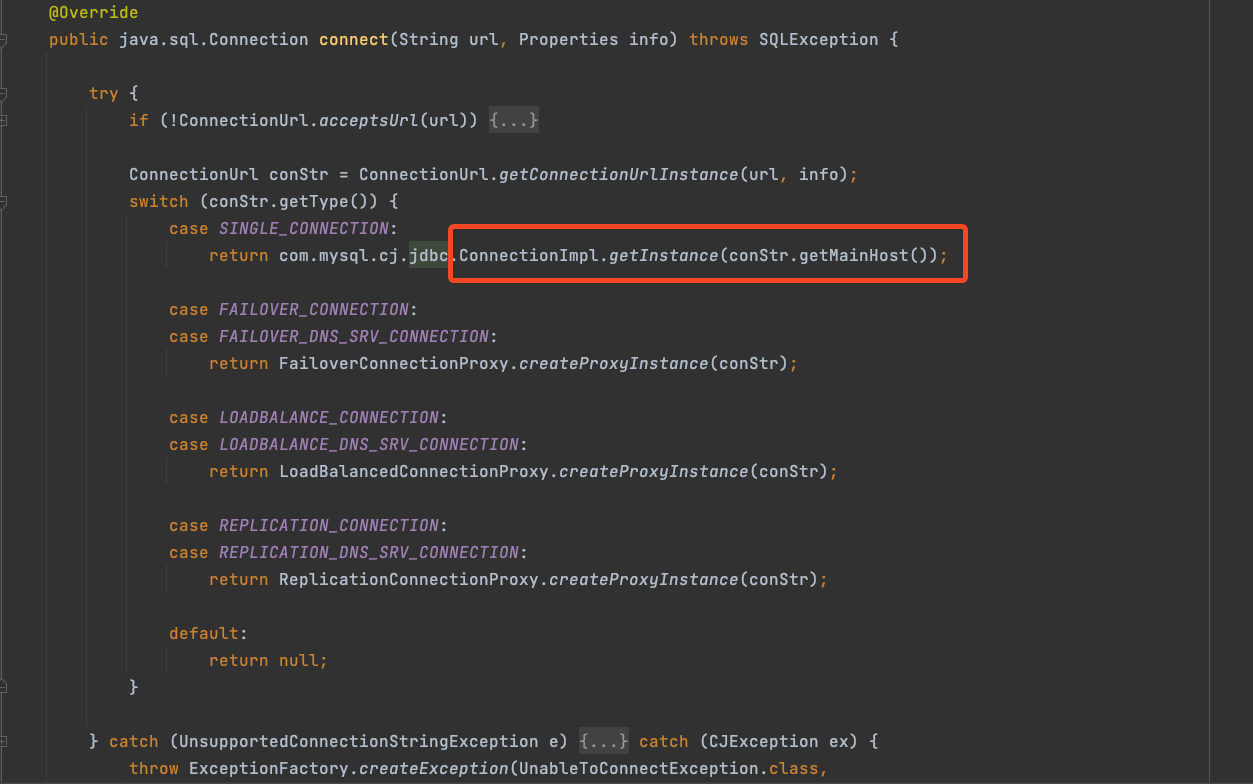
先不看连接池,具体创建数据库连接资源入口在ConnectionImpl实例化会调用的createNewIO方法,然后进入NativeSessioon的connect方法,将数据库连接的一些host、username、password、database、jdbcConnection等创建
这里就是创建了SocketConnection,内部又是一系列协议、封装等
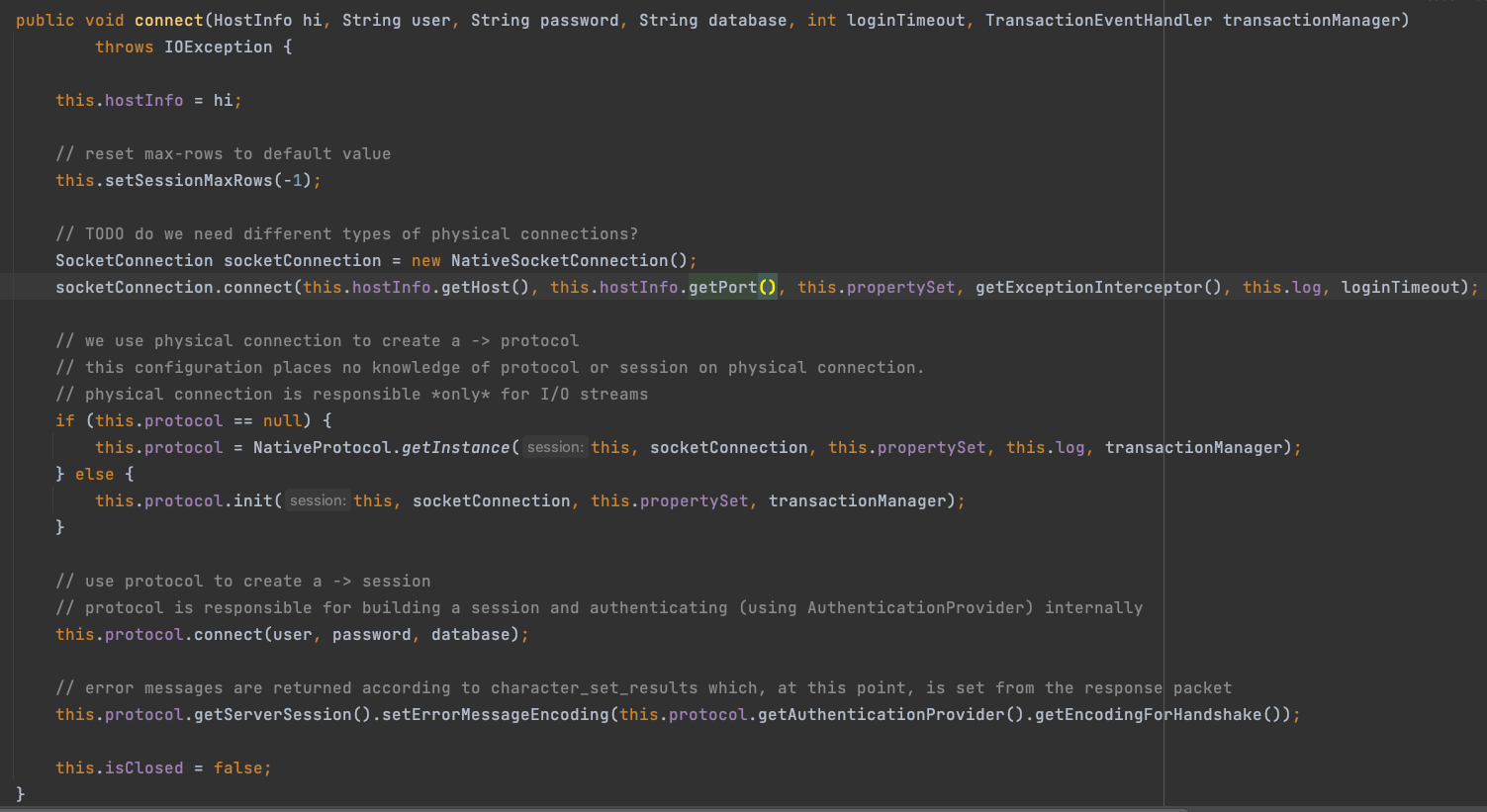
主要关注将连接标记为虚引用的入口,先不看数据库连接池,也就是在ConnectionImpl实例化会调用createNewIO创建SocketConnection之后,调用了一个trackConnection方法,该方法就是将封装在NetworkSource数据库连接标记为虚引用。
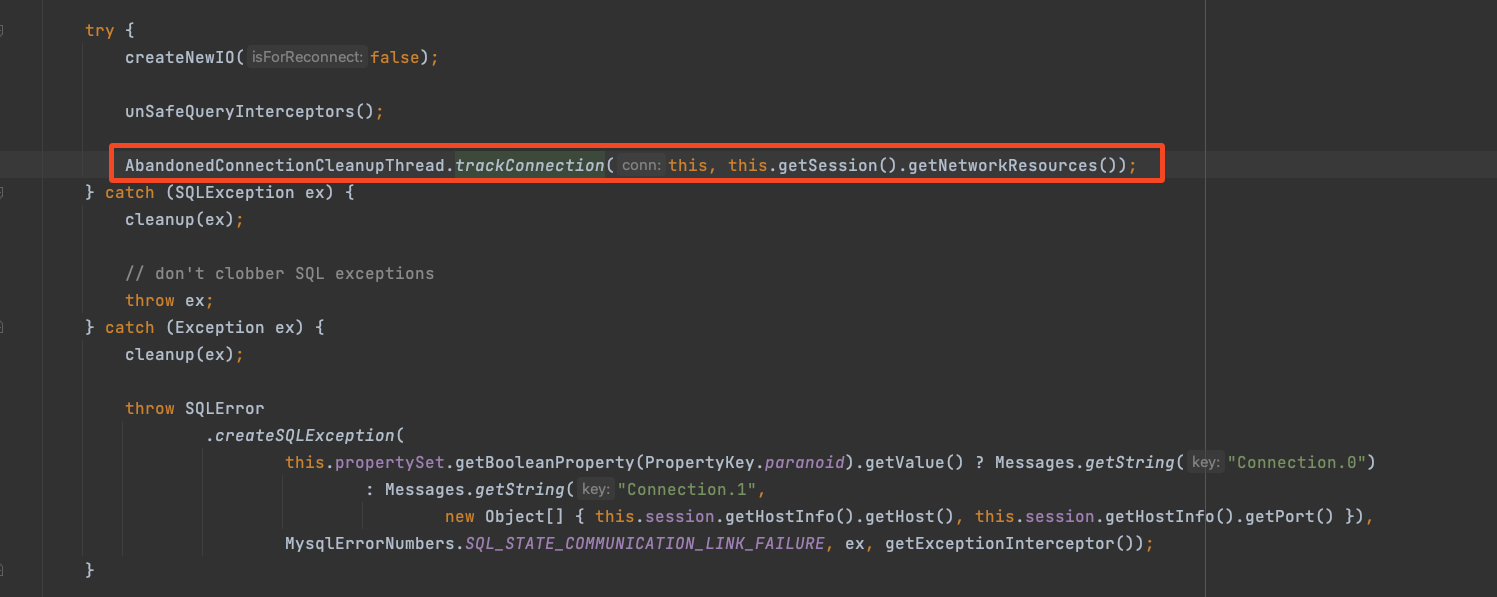
那什么时候会实例化ConnectionImpl呢,在程序启动的时候,如-===-=果引入MySQL Driver的话,类加载器会自动加载驱动获取connection连接,对于MySQL Driver该逻辑主要由类NonRegisteringDriver实现,该类位于包com.mysql.cj.jdbc,实现了位于java.sql包的Driver,就是这块根据url创建了对应的ConnectionImpl实例,进而初始化数据库连接Socket,并经数据库连接标记为虚引用,便于漏关资源。
HikariPool数据库连接池
项目使用的hikari连接池,相关连接池的配置在com.zaxxer.hikari包下的HikariConfig,通过源码可以看出,如果不设置connectionTimeout,默认的是 CONNECTION_TIMEOUT = SECONDS.toMillis(30);
public HikariConfig()
{
dataSourceProperties = new Properties();
healthCheckProperties = new Properties();
minIdle = -1;
maxPoolSize = -1;
maxLifetime = MAX_LIFETIME;
connectionTimeout = CONNECTION_TIMEOUT;
validationTimeout = VALIDATION_TIMEOUT;
idleTimeout = IDLE_TIMEOUT;
initializationFailTimeout = 1;
isAutoCommit = true;
String systemProp = System.getProperty("hikaricp.configurationFile");
if (systemProp != null) {
loadProperties(systemProp);
}
}
加载配置实例化HikariPool的逻辑在HikariDataSource类
根据相关配置创建pool

4、原因分析
为什么HikariPool连接池频繁创建那么多连接?全部堆积到了老年代?理论上来说,连接池是不会频繁的创建连接的,除非有活跃连接很少,且存在波动,即使这种连接对象因该被正常 or 超时关闭,不会导致堆内存一直上升。
查看数据库配置
show global variables like ‘%timeout%’ ;查看数据库wait_time=900s,也就是15分钟
show variables like ‘%max_connection%’; 查看数据库最大连接数
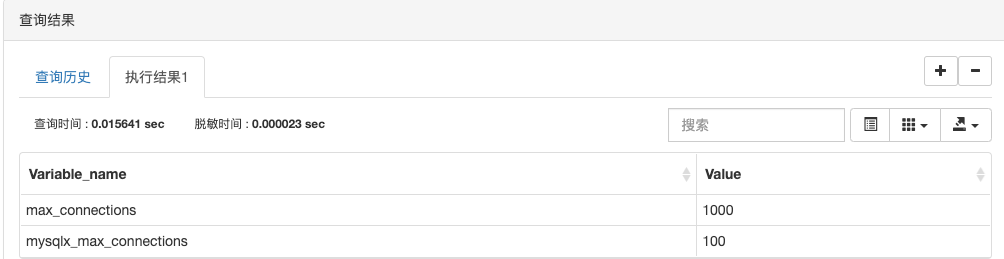
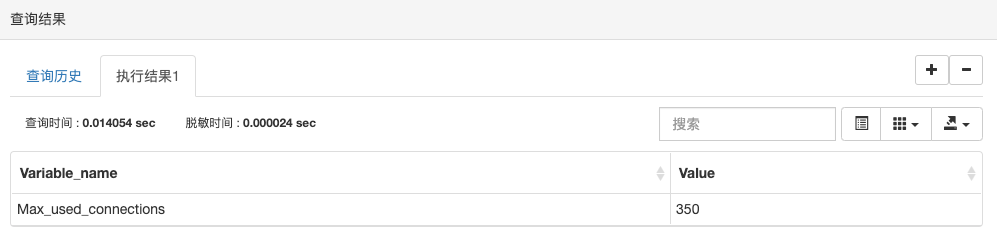
show status like ‘max_used_connections’; 查看数据库当前连接数
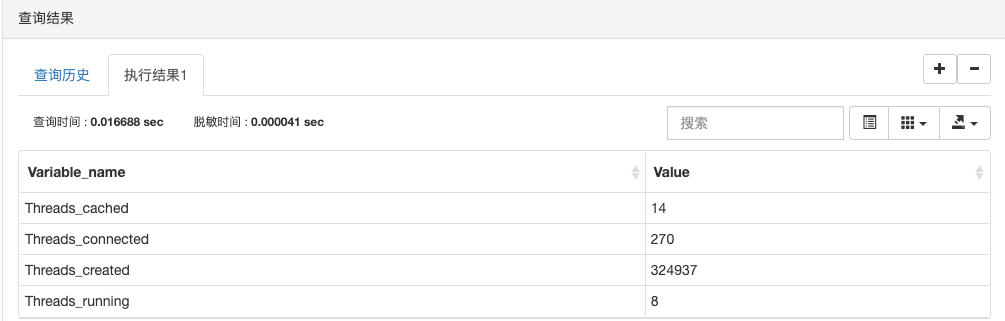
show status like ‘Threads%’; 查看数据库线程信息
show processlist; 查看连接明细
然后需要查看查程序中HikariPool连接池的配置,对于HikariPool有idleTimeout、max-lifetime,目前已经配置,另外还有一个validationTimeout:这个配置项设置了连接在被视为有效之前的最大验证时间(以毫秒为单位)。在从连接池中获取连接时,HikariCP 会检查连接的有效性。如果连接在这个时间内不能被验证为有效,那么它将被关闭并从连接池中移除。默认是5s。
pool-name: xopqbmSpringHikariCP
connection-timeout: 5000 // 获取连接时的最大等待时间(毫秒)。如果超过这个时间还没有获取到连接,则会抛出一个异常。默认值是 30 秒。
idle-timeout: 180000 // 连接在被视为闲置并且可以被关闭之前,可以保持空闲状态的最长时间(毫秒)。默认值是 10 分钟。
max-lifetime: 180000 // 连接的最大生命周期(毫秒)。此值必须小于数据库服务器配置的连接超时时间。默认值是 30 分钟。
maximum-pool-size: 20 // 连接池中允许的最大连接数。这个值会影响应用程序能够处理的并发数据库访问量。默认值是 10。
minimum-idle: 5 // 连接池中维护的最小空闲连接数。HikariCP 会尽力确保连接池中至少有这么多空闲的连接,即使这些连接当前并不需要。默认值与 maximum-pool-size 相同。
回到HikariDataSource创建HikariPool创建的时候,之前有个方法configuration.validate()是检验pool的配置,内部调用 validateNumerics()方法,会对配置的参数检验
private void validateNumerics()
{
if (maxLifetime != 0 && maxLifetime < SECONDS.toMillis(30)) {
LOGGER.warn("{} - maxLifetime is less than 30000ms, setting to default {}ms.", poolName, MAX_LIFETIME);
maxLifetime = MAX_LIFETIME;
}
if (leakDetectionThreshold > 0 && !unitTest) {
if (leakDetectionThreshold < SECONDS.toMillis(2) || (leakDetectionThreshold > maxLifetime && maxLifetime > 0)) {
LOGGER.warn("{} - leakDetectionThreshold is less than 2000ms or more than maxLifetime, disabling it.", poolName);
leakDetectionThreshold = 0;
}
}
if (connectionTimeout < 250) {
LOGGER.warn("{} - connectionTimeout is less than 250ms, setting to {}ms.", poolName, CONNECTION_TIMEOUT);
connectionTimeout = CONNECTION_TIMEOUT;
}
if (validationTimeout < 250) {
LOGGER.warn("{} - validationTimeout is less than 250ms, setting to {}ms.", poolName, VALIDATION_TIMEOUT);
validationTimeout = VALIDATION_TIMEOUT;
}
if (maxPoolSize < 1) {
maxPoolSize = DEFAULT_POOL_SIZE;
}
if (minIdle < 0 || minIdle > maxPoolSize) {
minIdle = maxPoolSize;
}
// !!!这里会判断 ,符合条件的话 idleTimeout 会被设置为0
// ps:该值的缺省值为 MINUTES.toMillis(10),也就是10分钟=600000毫秒。
if (idleTimeout + SECONDS.toMillis(1) > maxLifetime && maxLifetime > 0 && minIdle < maxPoolSize) {
LOGGER.warn("{} - idleTimeout is close to or more than maxLifetime, disabling it.", poolName);
idleTimeout = 0;
}
else if (idleTimeout != 0 && idleTimeout < SECONDS.toMillis(10) && minIdle < maxPoolSize) {
LOGGER.warn("{} - idleTimeout is less than 10000ms, setting to default {}ms.", poolName, IDLE_TIMEOUT);
idleTimeout = IDLE_TIMEOUT;
}
else if (idleTimeout != IDLE_TIMEOUT && idleTimeout != 0 && minIdle == maxPoolSize) {
LOGGER.warn("{} - idleTimeout has been set but has no effect because the pool is operating as a fixed size pool.", poolName);
}
}
根据上面配置,idle-timeout被设置成了0 … 此属性控制允许连接在池中处于空闲状态连接的最长时间(以毫秒为单位)。连接是否因空闲而停用取决于 +30 秒的最大变化和 +15 秒的平均变化。在此超时之前,连接永远不会作为空闲状态停用。值为 0 表示永远不会从池中删除空闲连接,推荐设置的范围为 [0,数据库wait_time]
因此情况就是数据库设置的连接超时wait_time为900s,但是HikariPool中设置的连接超时为180000ms=180s为什么还会有这种情况呢?
连接活跃的时候,会导致HikariPool频繁创建连接,超时又销毁(但是由于某种原因,连接前期正常使用,经过了多次minor GC都没有被回收,晋升到了老年代。但是一段时间过后,由于某种原因连接失效,导致连接池又新建了连接。连接虽然关闭了,但是这个虚引用此时进入了队列,进入队列还占着空间呢),每个连接会被标记一个虚引用,然而连接到了180s最大存活时间,该连接就会进入虚引用队列,越累计越多,而这种队列中的虚引用对象只能等到执行FullGC的时候 or 像前面demo一样,手动将虚引用置为null,才会被释放内存)
导致在两次FullGC的区间时间,ConnectionFinalizerPhantomReference对象堆积的越来越多,占用内存增大,导致最终FullGC压力增大。
建议将这个值设置的大一些,尽量避免频繁的创建连接。
另外就是建议idle-timeout设置的要比maxLifetime小1秒,否则会被设置为默认的0.
5、解决方案
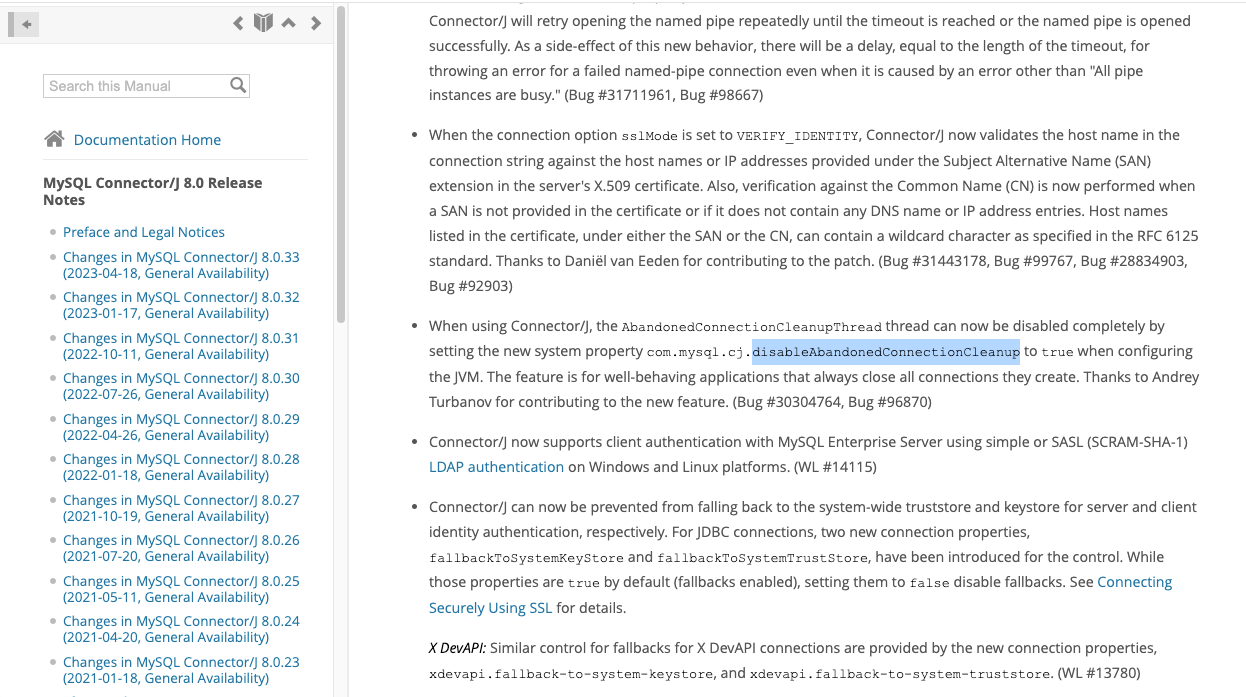
1、升级mysql-connector-java版本为8.0.22,参考https://dev.mysql.com/doc/relnotes/connector-j/8.0/en/news-8-0-22.html,然后禁用数据库连接虚引用功能 -Dcom.mysql.cj.disableAbandonedConnectionCleanup=true
2、使用定时任务清除数据库连接虚引用,在对象堆积到老年代引起FullGC的之前清除对象
// 每两小时清理 connectionPhantomRefs,减少对 FullGC 的影响
SCHEDULED_EXECUTOR.scheduleAtFixedRate(() -> {
try {
Field connectionPhantomRefs = NonRegisteringDriver.class.getDeclaredField("connectionPhantomRefs");
connectionPhantomRefs.setAccessible(true);
Map map = (Map) connectionPhantomRefs.get(NonRegisteringDriver.class);
// 防止对象一存活进入老年代。
if (map.size() > 50) {
map.clear();
}
} catch (Exception e) {
log.error("connectionPhantomRefs clear error!", e);
}
}, 2, 2, TimeUnit.HOURS);
参考
- MySQL 驱动中虚引用 GC 耗时优化与源码分析 | HeapDump性能社区
- 数据库连接池引起的FullGC问题,看我如何一步步排查、分析、解决(Druid)
- PhantomReference 引发的GC问题(HikariPool)
- AbandonedConnectionCleanupThread$ConnectionFinalizerPhantomReference内存溢出_abandoned connection cleanup thread-CSDN博客