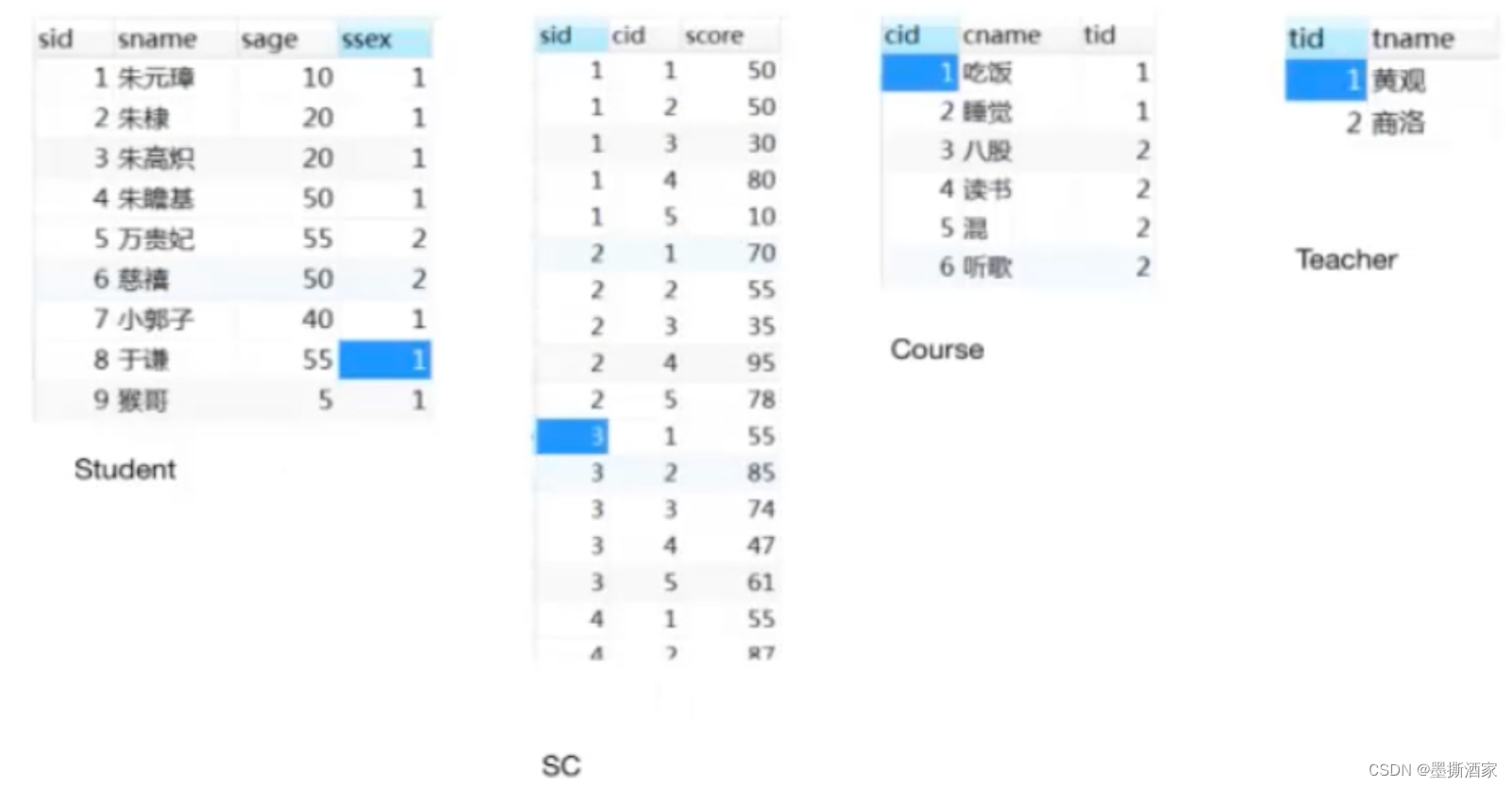
1. coalesce
用于缩减分区,减少分区个数,减少任务调度成本。
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 4)
val newRDD = rdd.coalesce(2)
newRDD.saveAsTextFile("output")
分区数可以减少,但是减少后的分区里的数据分布并不一定是均匀分布的,比如以下场景:
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
val newRDD = rdd.coalesce(2)
newRDD.saveAsTextFile("output")结果现实1和2在一个分区,3 4 5 6四个数在第二个分区。因为coalesce算子默认不会打乱分区的数据进行重新组合的。原来1和2,3和4,5和6分别在三个分区里,如果缩减分区之后1 2 3在一个分区,4 5 6在一个分区,意味着将原来的3和4所在的分区里的数据打乱重新组合了。所以缩减分区后,应该将5和6所在的分区里的数据移到其他分区中去,即3 4 5 6最终在一个分区了。
coalesce算子可能会导致数据倾斜。如果想要数据均衡,需要进行shuffle处理,coalesce算子第二个参数就表示是否shuffle处理,默认是false,改为true即可,但是数据不一定有规律,这就是shuffle的效果。
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
val newRDD = rdd.coalesce(2, true)
newRDD.saveAsTextFile("output")结果显示1 4 5在一个分区,2 3 6在一个分区。
2. repartition
coalesce算子也可以增加分区,但是第二个参数须为true,但用得更多的是repartition算子。
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
val newRDD = rdd.repartition(3)
newRDD.saveAsTextFile("output")repartition算子源码中还是调用了coalesce算子(第二个参数为true)。
3. sortBy
见名知义,就是排序。
val rdd : RDD[Int] = sc.makeRDD(List(1, 4, 2, 3, 6, 5), 2)
val newRDD = rdd.sortBy(num=>num)
newRDD.saveAsTextFile("output")数据重新排序,但是分区数不变,存在shuffle过程。 默认是升序排序,第二个参数传false,表示降序排序。
4. intersection、union、subtract、zip
val rdd1 : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val rdd2 : RDD[Int] = sc.makeRDD(List(3, 4, 5, 6))
val rdd3 = rdd1.intersection(rdd2)
println(rdd3.collect().mkString(","))
val rdd4 = rdd1.union(rdd2)
println(rdd4.collect().mkString(","))
val rdd5 = rdd1.subtract(rdd2)
println(rdd5.collect().mkString(","))
val rdd6 : RDD[(Int, Int)]= rdd1.zip(rdd2)
println(rdd6.collect().mkString(",")) 
注意事项:
1)交集不去重
2)如果两个rdd的数据类型不同,不能做交集、并集、差集操作,但拉链可以
3)拉链操作的两个rdd的分区数需要一致,且分区中的数据数量也要一致
5. partitionBy
只有数据类型为key-value类型的rdd,才有partitionBy操作。partitionBy本身不是RDD的方法,是通过隐式转化得到的PairRDDFunctions的方法。
val rdd : RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val mapRDD = rdd.map((_, 1))
val newRDD = mapRDD.partitionBy(new HashPartitioner(2))
newRDD.saveAsTextFile("output")这里默认使用HashPartitioner,即按照key的哈希值对分区数取模得到分区号,后续会介绍自定义分区器。
6. reduceByKey
val rdd : RDD[Int] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 4)))
val newRDD : RDD[(String,Int)] = rdd.reduceByKey((x:Int, y:Int) => {x + y})
newRDD.collect().foreach(println)
reduceByKey将相同key的值进行聚合,具体来说是两两聚合。 但是上例中"b"只有一个,是不会做两两聚合计算的。
7. groupByKey
val rdd : RDD[Int] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 4)))
val newRDD : RDD[(String,Iterable[Int])] = rdd.groupByKey()
newRDD.collect().foreach(println)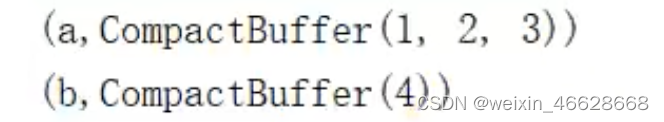
groupByKey根据相同key的值进行分组,形成一个可迭代的集合。这与groupBy类似,但是区别是groupBy的可迭代集合不是原有value的集合,而是原来每个元素(即tuple)的集合:
val rdd : RDD[Int] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 4)))
val newRDD : RDD[(String,Iterable[(String, Int)])] = rdd.groupBy(_._1)reduceByKey和groupByKey的区别:
1) reduceByKey相比于groupByKey不仅做了分组,还做了聚合计算
2)groupByKey会将数据打乱重新组合,即存在shuffle操作。既然存在shuffle操作,如果后续还有map等转换操作,原来一个分区的数据处理完之后还需要等待其他分区的数据处理完,因为shuffle后的分区的数据可能不止来源于原来的一个分区。这种等待可能很耗时,并且占用大量内存,因此需要进行落盘操作。简而言之,shuffle操作必须有落盘处理,不能在内存中进行数据等待,否则可能会导致内存溢出,因此性能也不高。
3)reduceByKey也会有shuffle,也会有落盘操作,但是在落盘之前,会对原来每个分区内的数据事先进行分组并聚合计算(预聚合,combine)。这样落盘的数据量少了,磁盘IO也少了,性能也提高了。
8. aggregateByKey
reduceByKey会进行预聚合,这是分区内的聚合,然后shuffle操作打乱数据,进行分区间的聚合,此时分区内和分区间的聚合规则是一样的。如果分区内和分区间的聚合计算规则不一样,那就要使用aggregateByKey算子。例如,分区内求最大值,分区间求和:
val rdd : RDD[Int] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)), 2)
val newRDD : RDD[(String,Int)] = rdd.aggregateByKey(0)((x, y) => math.max(x, y), (x, y) => x + y)
newRDD.collect().foreach(println)![]()
aggregateByKey有两个参数列表,第一个参数列表表示初始值(aggregateByKey的最终计算结果与这个初始值类型是相同的),用于和第一个key的value进行分区内计算,第二个参数列表的两个参数分别表示分区内和分区间的计算规则。
val rdd : RDD[Int] = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("b", 4), ("b", 5), ("a", 6)), 2)
val newRDD : RDD[(String,Int)] = rdd.aggregateByKey(5)((x, y) => math.max(x, y), (x, y) => x + y)
newRDD.collect().foreach(println)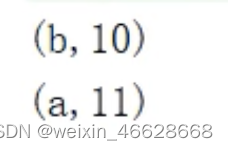
计算相同key的value的平均值:
val rdd : RDD[Int] = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("b", 4), ("b", 5), ("a", 6)), 2)
val newRDD : RDD[(String,(Int, Int))] = rdd.aggregateByKey((0, 0))((t, v) => (t._1 + v, t._2 + 1), (t1, t2) => (t1._1 + t2._1, t1._2 + t2._2))
val result = newRDD.mapValue {
case (val, num) => {
val / num
}
}
result.collect().foreach(println)9. foldByKey
如果分区内和分区间的计算规则一样,可以使用foldByKey算子。
val rdd : RDD[Int] = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("b", 4), ("b", 5), ("a", 6)), 2)
val newRDD : RDD[(String,Int)] = rdd.foldByKey(0)(_+_)
newRDD.collect().foreach(println)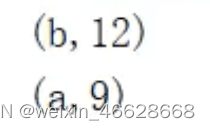
10. combineByKey
aggreagteByKey的初始值在一些场景其实很难确定,但如果初始值是相同key的第一个value或者其适当转换,就更为合理。
val rdd : RDD[Int] = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("b", 4), ("b", 5), ("a", 6)), 2)
val newRDD : RDD[(String,(Int, Int))] = rdd.combineByKey(v => (v, 1))((t : (Int, Int), v) => (t._1 + v, t._2 + 1), (t1 : (Int, Int), t2 : (Int, Int)) => (t1._1 + t2._1, t1._2 + t2._2))
val result = newRDD.mapValue {
case (val, num) => {
val / num
}
}
result.collect().foreach(println)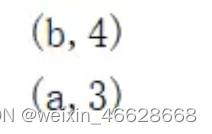
wordCount的多种实现方式(假设已经得到所有的(单词, 1)的tuple):
rdd.reduceByKey(_+_)
rdd.aggregateByKey(0)(_+_, _+_)
rdd.foldByKey(0)(_+_)
rdd.comnbineByKey(v=>v)((x:Int, y:Int)=>x+y, (x:Int, y:Int)=>x+y)观察源码,发现他们底层调用的都是combineByKey






![[Java安全入门]三.URLDNS链](https://img-blog.csdnimg.cn/direct/4dd079fb991e41e3becc80c4bd5fb5dc.png)

![[java入门到精通] 10 常用API , 正则表达式 , Collection集合](https://img-blog.csdnimg.cn/direct/c6fe50c5d8c34bff9beef23d969bfc87.png#pic_center)