前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

准备工作
既然要去赚马内,咱们首先要获取往期的数据来进行分析,
通过往期的规律来对当前进行预测,准不准我不知道,反正比人预测的准,
不准也不要喷我,咱们是来交流技术的,不是来炒股的。

我们需要使用这些模块,通过pip安装即可。
-
requests: 爬虫数据请求模块
-
pyecharts: 数据分析 可视化模块
-
pandas: 数据分析 可视化模块里面的设置模块(图表样式)
后续使用的其它的模块都是Python自带的,不需要安装,直接导入使用即可。
基本流程
思路分析
采集什么数据?怎么采集?
首先我们找到数据来源,从network当中去找到数据所在的位置,这一步就不详细讲了。
代码实现
我们想要实现通过爬虫获取到数据,正常情况下有几个步骤:
-
发送请求
-
获取数据
-
解析数据
-
保存数据
接下来我们来看代码
代码展示
数据采集
导入需要使用的模块
import requests # 数据请求模块
import csv # 表格模块
1、发送请求
通过response模块来访问需要获取数据的地址
(因不可抗原因,网址屏蔽了,完整代码可文末名片领取)
url = 'https://stock.*****.com/v5/stock/screener/quote/list.json?page={page}&size=30&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz'
requests.get(url=url)
直接这么进去是不一定能获取到数据,所以需要使用 cookie 来伪装一下,cookie代表着用户身份信息。
当然光cookie是不够的,咱们再加上当前网页的 user-agent
import requests # 第三方模块
import csv
# 伪装
headers = {
# 用户身份信息
'cookie': 's=bq119wflib; device_id=90ec0683f24e4d1dd28a383d87fa03c5; xq_a_token=df4b782b118f7f9cabab6989b39a24cb04685f95; xqat=df4b782b118f7f9cabab6989b39a24cb04685f95; xq_r_token=3ae1ada2a33de0f698daa53fb4e1b61edf335952; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTY3MjE4Njc1MSwiY3RtIjoxNjcwNTAxMjA5MTEyLCJjaWQiOiJkOWQwbjRBWnVwIn0.iuLASkwB6LkAYhG8X8HE-M7AM0n0QUULimW1C4bmkko-wwnPv8YgdakTC1Ju6TPQLjGhMqHuSXqiWdOqVIjy_OMEj9L_HScDot-7kn63uc2lZbEdGnjyF3sDrqGBCpocuxTTwuSFuQoQ1lL7ZWLYOcvz2pRgCw64I0zLZ9LogQU8rNP-a_1Nc91V8moONFqPWD5Lt3JxqcuyJbmb86OpfJZRycnh1Gjnl0Aj1ltGa4sNGSMXoY2iNM8NB56LLIp9dztEwExiRSWlWZifpl9ERTIIpHFBq6L2lSTRKqXKb0V3McmgwQ1X0_MdNdLAZaLZjSIIcQgBU26T8Z4YBZ39dA; u=511670501221348; Hm_lvt_1db88642e346389874251b5a1eded6e3=1667994737,1670480781,1670501222; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1670501922',
# 浏览器的基本信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
url = 'https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page={page}&size=30&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz'
# 1. 发送请求
response = requests.get(url=url, headers=headers)
print(response)
伪装加好之后,咱们就能得到一个相应结果,先打印出来看看。
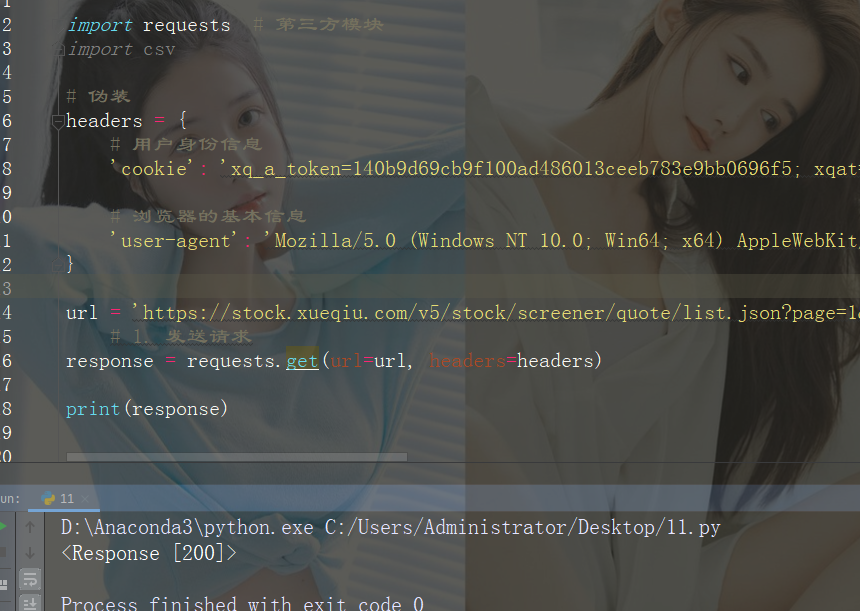
运行后出现 <Response [200]>求请求成功,出现404就是访问不到资源,一般是被反爬了。
所以这时候我们需要加一个 referer 防盗链参数进去
'referer: https:// ****.com/hq'
如果加了还不行,就是自己链接有问题了。
取数据的话 .json 就好了
import requests # 第三方模块
import csv
# 伪装
headers = {
# 用户身份信息
'cookie': 's=bq119wflib; device_id=90ec0683f24e4d1dd28a383d87fa03c5; xq_a_token=df4b782b118f7f9cabab6989b39a24cb04685f95; xqat=df4b782b118f7f9cabab6989b39a24cb04685f95; xq_r_token=3ae1ada2a33de0f698daa53fb4e1b61edf335952; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTY3MjE4Njc1MSwiY3RtIjoxNjcwNTAxMjA5MTEyLCJjaWQiOiJkOWQwbjRBWnVwIn0.iuLASkwB6LkAYhG8X8HE-M7AM0n0QUULimW1C4bmkko-wwnPv8YgdakTC1Ju6TPQLjGhMqHuSXqiWdOqVIjy_OMEj9L_HScDot-7kn63uc2lZbEdGnjyF3sDrqGBCpocuxTTwuSFuQoQ1lL7ZWLYOcvz2pRgCw64I0zLZ9LogQU8rNP-a_1Nc91V8moONFqPWD5Lt3JxqcuyJbmb86OpfJZRycnh1Gjnl0Aj1ltGa4sNGSMXoY2iNM8NB56LLIp9dztEwExiRSWlWZifpl9ERTIIpHFBq6L2lSTRKqXKb0V3McmgwQ1X0_MdNdLAZaLZjSIIcQgBU26T8Z4YBZ39dA; u=511670501221348; Hm_lvt_1db88642e346389874251b5a1eded6e3=1667994737,1670480781,1670501222; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1670501922',
# 防盗链
'referer: https:// ******.com/hq'
# 浏览器的基本信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
url = 'https://stock.****.com/v5/stock/screener/quote/list.json?page={page}&size=30&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz'
# 1. 发送请求
response = requests.get(url=url, headers=headers)
print(response.json())

2、获取数据
什么是json数据?
以 {}/[] 所包裹起来的数据 {“”:“”, “”:“”}
json_data = response.json()
3、解析数据
data_list = json_data['data']['list']
# data_list[0]
# data_list[1]
for i in range(0, len(data_list)):
symbol = data_list[i]['symbol']
name = data_list[i]['name']
current = data_list[i]['current']
chg = data_list[i]['chg']
percent = data_list[i]['percent']
current_year_percent = data_list[i]['current_year_percent']
volume = data_list[i]['volume']
amount = data_list[i]['amount']
turnover_rate = data_list[i]['turnover_rate']
pe_ttm = data_list[i]['pe_ttm']
dividend_yield = data_list[i]['dividend_yield']
market_capital = data_list[i]['market_capital']
print(symbol, name, current, chg, percent, current_year_percent, volume, amount, turnover_rate, pe_ttm, dividend_yield, market_capital)
4、保存数据
csv_writer.writerow([symbol, name, current, chg, percent, current_year_percent, volume, amount, turnover_rate, pe_ttm, dividend_yield, market_capital])
爬虫部分就结束了,接下来看数据分析部分,文章不理解,我还录了视频讲解,视频以及完整代码在文末名片自取即可。
数据可视化分析
导入需要使用的模块
import pandas as pd # 做表格数据处理模块
from pyecharts.charts import Bar # 可视化模块
from pyecharts import options as opts # 可视化模块里面的设置模块(图表样式)
读取数据
df = pd.read_csv('股票.csv')
x = list(df['股票名称'].values)
y = list(df['成交量'].values)
c = (
Bar()
.add_xaxis(x[:10])
.add_yaxis("成交额", y[:10])
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="Bar-旋转X轴标签", subtitle="解决标签名字过长的问题"),
)
.render("成交量图表.html")
完整代码文末名片自取就好了哈~
另我给大家准备了一些资料,包括:
2022最新Python视频教程、Python电子书10个G
(涵盖基础、爬虫、数据分析、web开发、机器学习、人工智能、面试题)、Python学习路线图等等
全部可在文末名片获取哦!

尾语 💝
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝