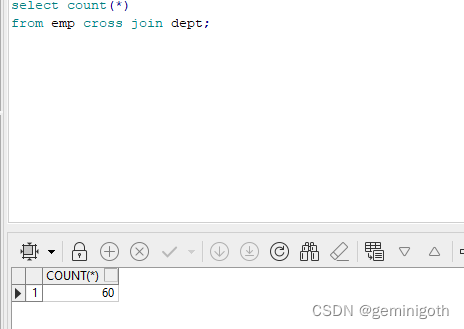
写在前面
最近工作从CV转向了NLP,于是空余时间便跟着哔哩哔哩李沐老师的视频学习。其实研一NLP课程讲论文的时候,我们小组就选择了经典的Attention和Bert,但还有很多细节并不完全理解,实际使用时也很困惑。
因此这个系列就来记录NLP复习知识!文章内容会结合工作实际所需持续更新。加油哇~
Transformer
- 1. 简介和背景
- 2. 相关工作
- 3. 模型结构
- 3.1 整体概览——编码器-解码器(Encoder-Decoder)
- 3.2 注意力机制(Attention)
- 3.3 "point-wise"前馈神经网络
- 3.4 向量化层(Embedding)
- 3.5 位置编码(Positional encoding)
- 4. 为什么使用自注意力?(self-attention)
- 5. 文章评价
1. 简介和背景
- 论文的工作:聚焦于序列转录模型,序列转录模型是一类根据一个序列生成另外一个序列的模型,以往主流的方法通常基于RNN或者CNN、结构上采用Encoder-Attention-Decoder;提出的Transformer这种新的网络结构仅使用Attention机制。
- RNN特点:能够处理序列数据的关键所在,是对输入序列从左到右依次进行计算,并将前面学到的知识放入隐藏状态向后传递
- 这种计算机制带来的问题:
- 无法并行计算
- 当输入序列较长时,前面学到的知识在向后传递的过程中存在信息丢失的风险
- 已有的提升计算效率的方法,如分解技巧,并不能从根本上解决问题
- 这种计算机制带来的问题:
- Attention机制在以往的工作中主要用来将Encoder的信息更好地传递给Decoder,论文提出的Transformer网络,不再使用循环层,仅使用attention学习输入和输出的全局依赖关系,而且能够有效进行并行计算。
2. 相关工作
- 减少时序计算代价途径之一——使用卷积神经网络
- cnn的缺点在于难以建模长序列,每次计算使用的是k*k(k=3,5)的卷积核,如果需要建模两个距离较远的像素,需要使用多层卷积逐层计算;而Transformer中的注意力机制,每次计算使用全部像素;
- 卷积的好处在于使用多个输出通道计算不同的特征,所以设计多头注意力机制进行模拟。
- 自注意力机制:在计算一个序列表达时,将序列不同位置关联起来的一种注意力机制;已有工作并非论文创新。
3. 模型结构
3.1 整体概览——编码器-解码器(Encoder-Decoder)
Transformer基于经典序列转录模型的Encoder-Decoder架构:
- 长度为n的输入x=(x_1, x_2,…x_n),如果是一个句子,x_t表示第t个单词
- 编码器E:将输入映射为长度同样为n的连续向量z=(z_1, z_2,…z_n)
- 解码器D:以编码器的输出z为输入,生成长度为m的输出序列y=(y_1, y_2, …y_m)
- m可以不等于n,例如英翻中任务中,输入的英文句子长度可以不等于输出的中文句子长度
- 解码器是典型的自回归模型,即逐步生成序列的每个元素来生成整个序列,生成y_t时考虑已经生成的y_1到y_(t-1),过去时刻的所有输出作为当前时刻的输入
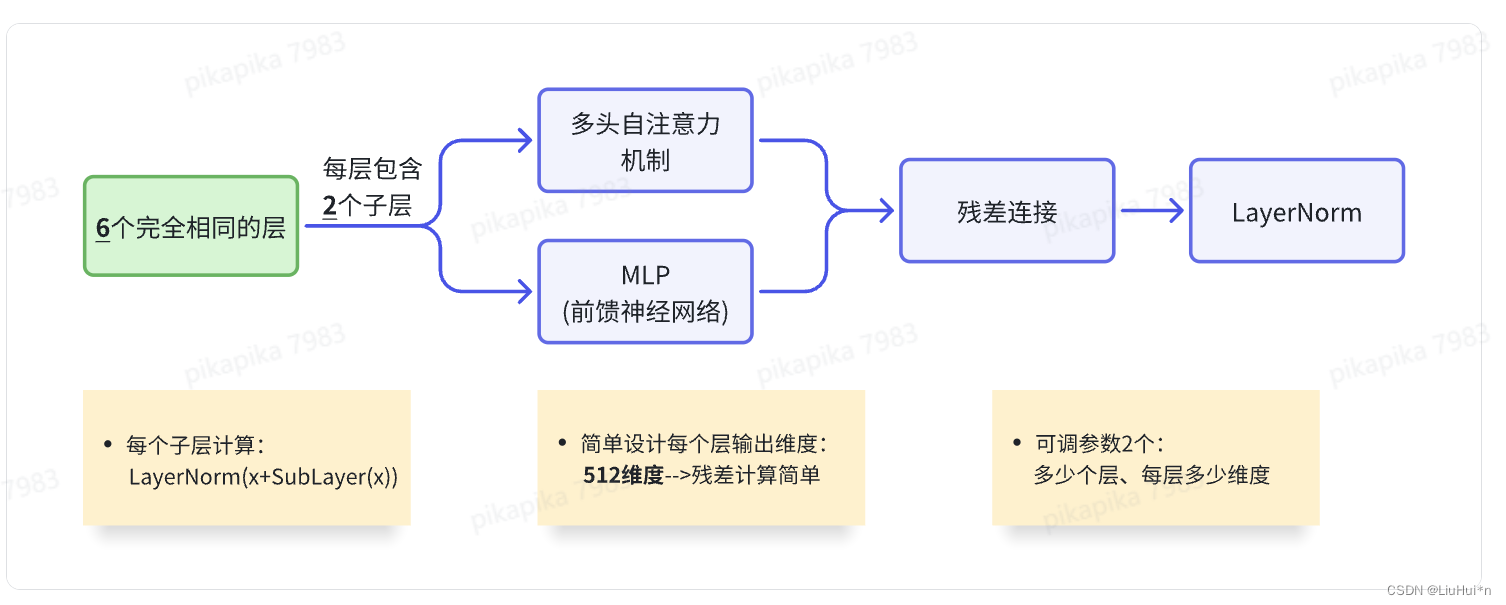
同时在编码器和解码器堆叠了多层self-attention、norm和fc
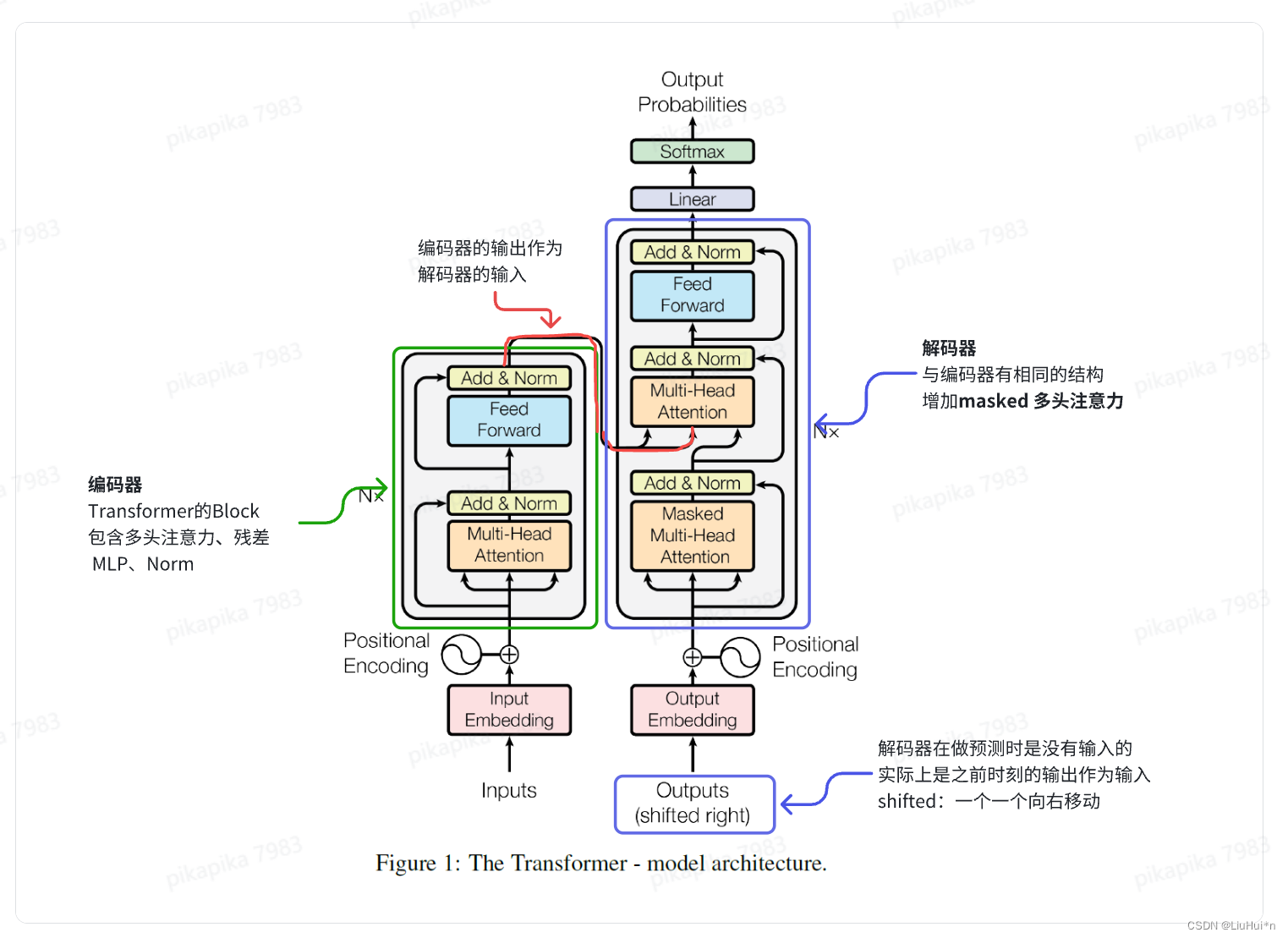
- 编码器
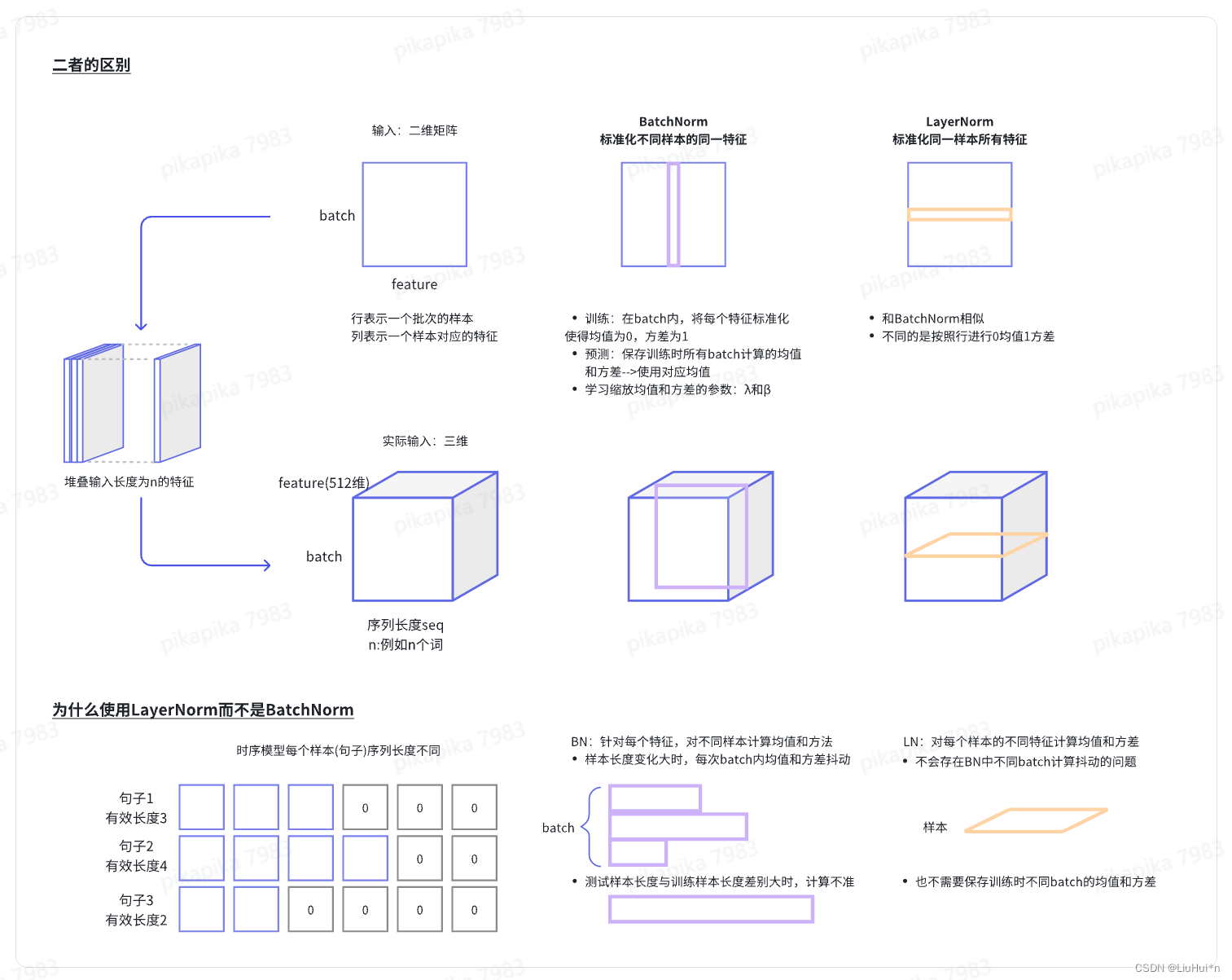
- batchnorm和laynorm
- 解码器
- 与编码器结构相似,包含6个完全相同的层,每层除了与编码器相同的两个子层(多头自注意力和前馈神经网络)外,增加一个额外的子层,同样是多头注意力;
- 由于解码器预测t时刻输出时,只能使用0到t-1时刻的输出作为输入,而t时刻后的不能;但注意力机制每次可以看到完整输入;因此使用带掩码的注意力机制–>保证训练和测试一致。
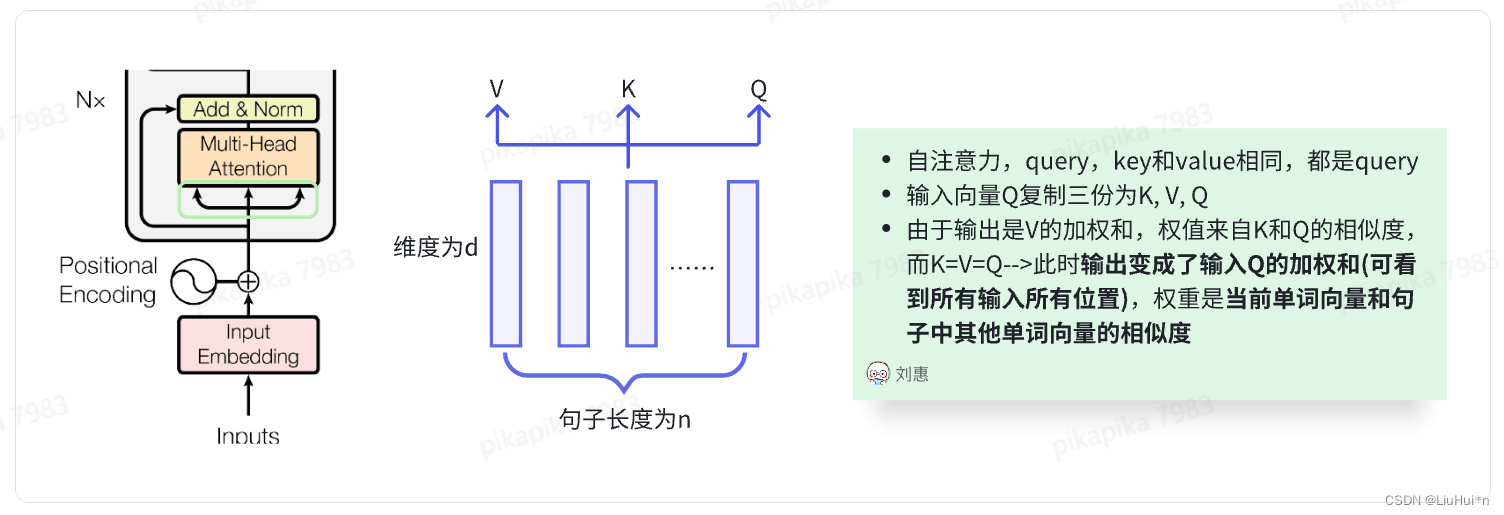
3.2 注意力机制(Attention)
简要理解:注意力函数将输入的 query,key-value 映射为输出output;具体来说,输出是value的加权和(二者维度相同),权重由query和key的相似度函数计算得出。其中不同的相似度函数则对应不同的注意力机制。
- 点乘注意力(Scaled dot attention)——TransFormer中使用的注意力机制
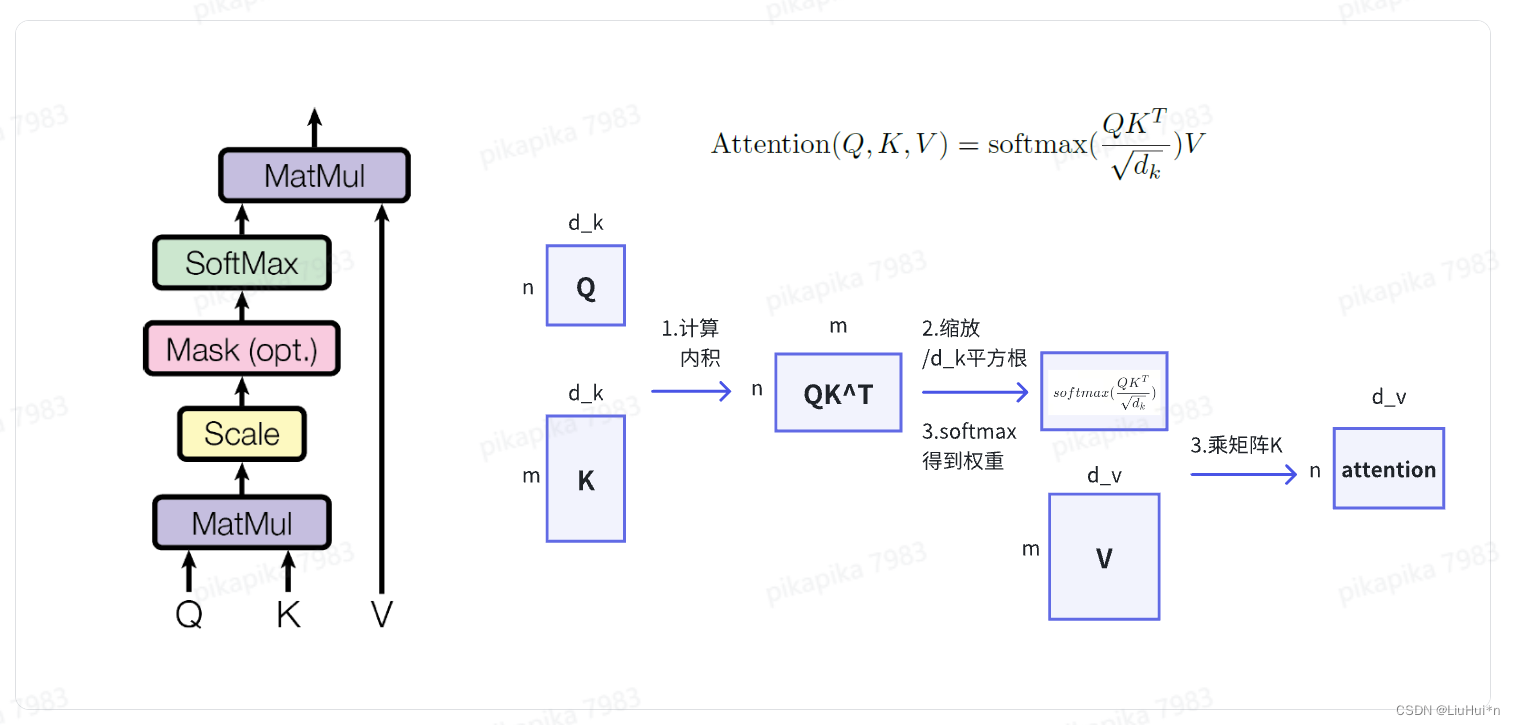
- quey的个数可以和kye-value对的个数不一样,但维度相同
- 为什么要做缩放?当d_k较大时,点乘的值会变大,对应的softmat结果靠近1,使得梯度比较小
- mask的目的——避免t时刻的query看到t时刻之后的key-value对;具体计算时,将t时刻之后的qk设置成较大的负数,经过softmax计算后变成0
-
多头注意力(Multi-Head attention)
目的:模拟卷积神经网络不同输出通达学习不同特征
做法:将QKV先投影到低维空间,投影h次–>缩放的点乘注意力机制–>拼接之后投影到原维度
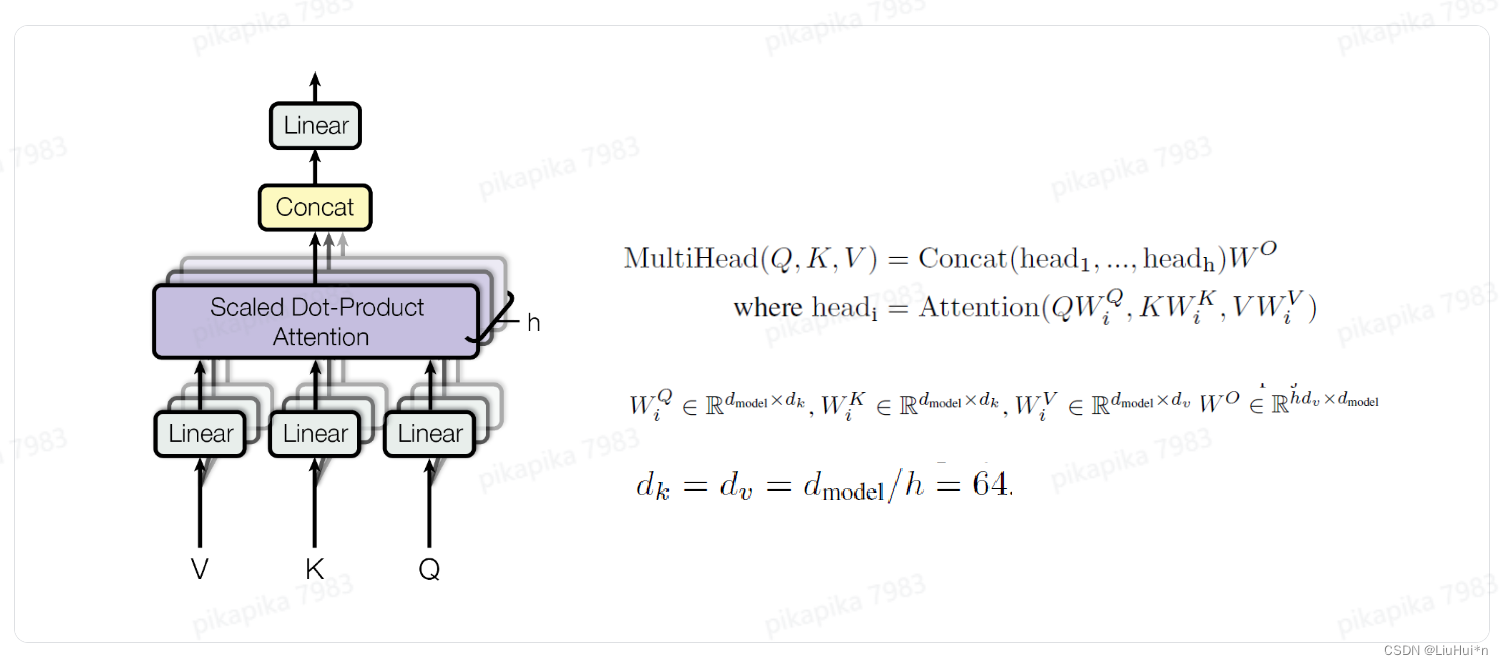
-
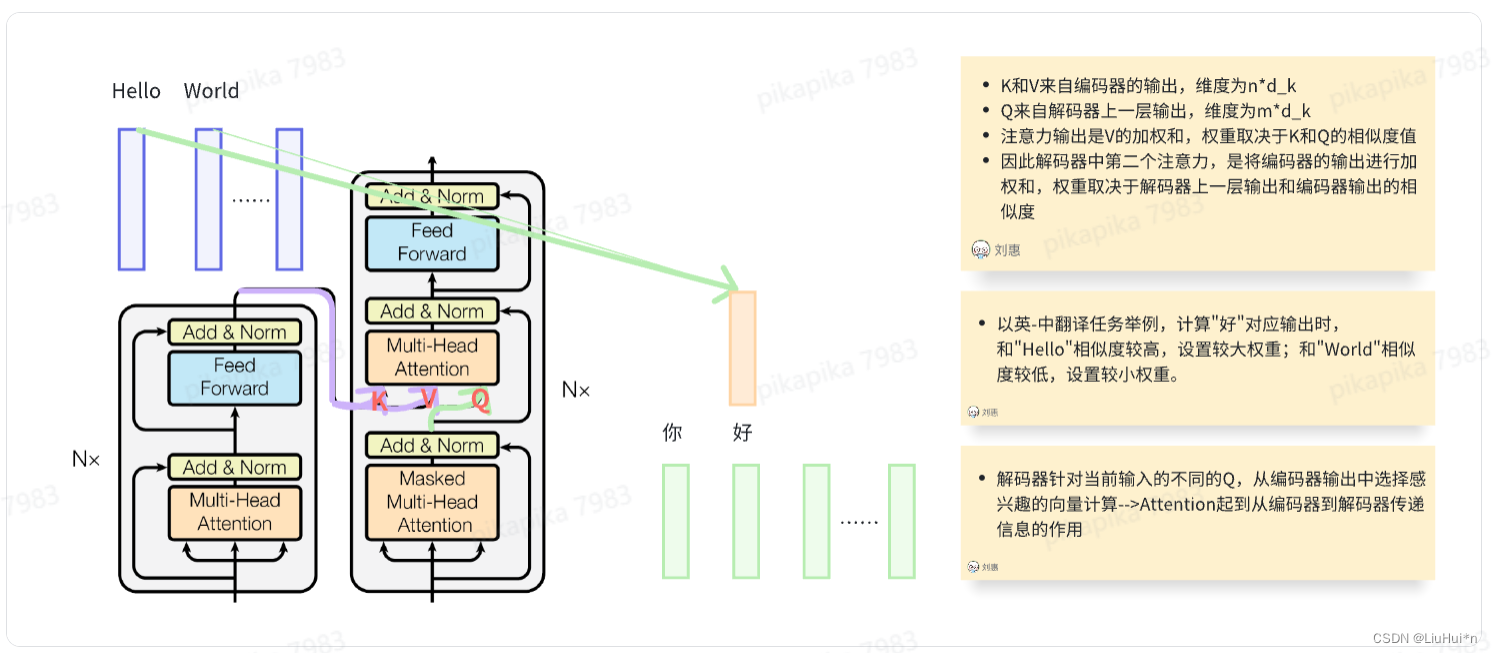
Transformer中三种不同的注意力
(1)Encoder中
(2)Dncoder中
第一个注意力机制与Encoder相似,增加了mask机制:预测t时刻输出时,t时刻之后的权重设置为0
第二个不再是自注意力,key-value对来自编码器的输出
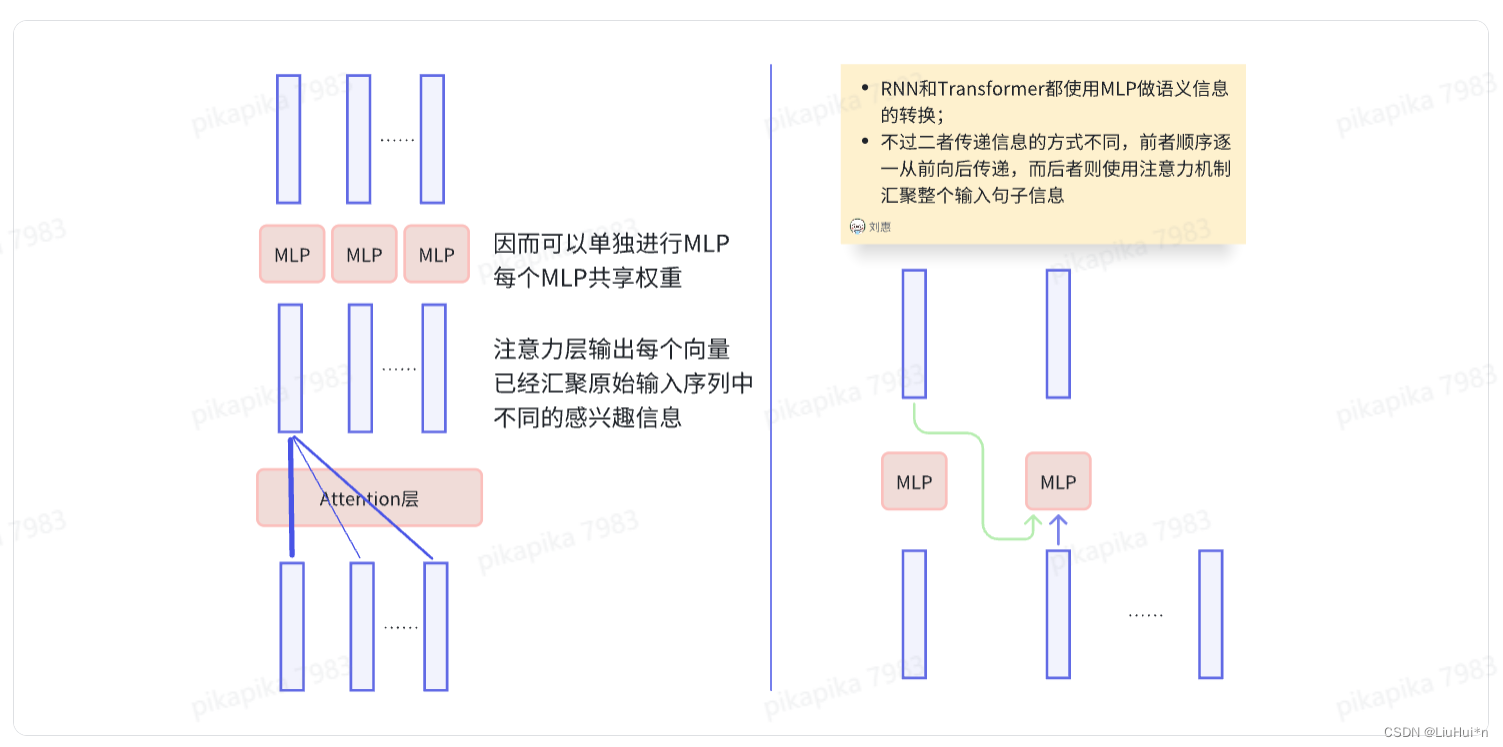
3.3 "point-wise"前馈神经网络
- point-wise的意思:输入序列每个位置的词语都会经过相同的前馈神经网络计算
- 两个线性层,使用Relu激活函数,将512维输入映射到2048维度后再映射回512维
- 为什么是point-wise?注意力子层已经把输入的整个句子信息做了一次汇聚,使得注意力层输出的每个向量中都融合了其他位置信息(权重不同,感兴趣信息不同),因此每个位置词语对应的注意力子层输出向量可以单独进入前馈神经网络进行计算。
3.4 向量化层(Embedding)
- 整个网络包括三个向量化层,分别在编码器输入、解码器输入和解码器输出softmax层前。三者共享权重(训练简单)
- 在编码器和解码器的输入部分,目的是将输入词映射成d_model向量;在解码器的输出部分,则是将隐藏状态的向量(eg:512维)映射到词汇表大小(eg:3万)的维度空间,然后进入softmax函数计算每个词概率值。
补充chatgpt的解释: Q:在decoder的softmax之前也会embedding,这是为什么呢?
A:在Transformer解码器中,在进行softmax之前进行额外的嵌入操作,通常是因为需要将解码器的输出(即经过softmax后的概率分布)转换为最终的词汇预测。这个额外的嵌入操作通常被称为"输出投影"(output
projection)或者"生成词嵌入"(generation embedding)。 这个额外的嵌入操作的作用有几个方面:
- 维度匹配:通常情况下,解码器的隐藏状态的维度可能与词汇表的大小不匹配。因为在解码器的隐藏状态中,每个时间步都有一个隐藏状态向量,而词汇表的大小通常远大于隐藏状态的维度。所以,需要通过输出投影将隐藏状态的维度转换为词汇表大小,以便之后进行softmax计算得到每个词汇的概率分布。
- 生成词嵌入:除了维度匹配之外,输出投影还可以被看作是将隐藏状态映射到词嵌入空间的过程。通过这个过程,模型可以更好地捕捉输出词汇的语义信息,从而更准确地预测下一个词汇。
综上所述,在Transformer解码器中,在进行softmax之前进行额外的嵌入操作,既可以保证维度匹配,又可以提高模型对输出词汇的表示能力,从而提高预测的准确性。
3.5 位置编码(Positional encoding)
- RNN是通过将上一时刻输出作为下一时刻输入来编码序列信息的,但注意力却缺少对时序信息的编码,针对这个问题,Transformer选择直接在输入中加入词语的位置信息。
- 位置编码是一个与位置相关的向量,它被加到词嵌入向量中,以使模型能够区分不同位置的词汇。它通过周期不同的正弦、余弦函数计算而得,使得每个位置都会有一个唯一的位置编码向量与之对应。
4. 为什么使用自注意力?(self-attention)
虽然论文中这个章节标题是why self-attention,但并不是解释为什么这么设计,而是侧重时间复杂度、并行程度等相比RNN和CNN的优势

衡量三个维度
- 每层的时间复杂度
- 顺序计算:下一步计算必须等前面多少步完成计算,值越低并行程度越高
- 最大路径长度:信息从一个点到另一个点要走多少步
(1) 自注意力层:query矩阵n行d列,key矩阵n行d列,二者时间复杂度是n^2d;query和所有的key计算,输出是所有value的加权和,所以query一次就可以完成所有key-value计算,同时矩阵之间并行运算,所以每一步无需等待,信息传输一次完成。
剩余三者计算量再补充
TODO:剩余循环层和卷积层计算之后遇到实际场景后再补充
5. 文章评价
论文写作:正文精简讲好一个故事,为什么要做?设计理念是什么?思考–>增加文章深度
模型本身:几乎可以用于所有NLP任务;扩展到图像、语音等领域;预训练让整个训练过程变的简单
2024.03.09 春日伊始,阳光明媚;在北京的小破出租屋,第一次更新:论文中Transformer基本结构。