目录
- 一、实验目的与要求
- 二、实验过程
- 三、主要程序清单和运行结果
- 1、爬取 “中国南海网” 站点上的相关信息
- 2、爬取天气网站上的北京的历史天气信息
- 四、程序运行结果
- 五、实验体会
一、实验目的与要求
1、目的:
理解抓取网页数据的一般处理过程;熟悉应用 Chrome 浏览器的工具分析网页的基本操作步骤;掌握使用 Requests 库获取静态网页的基本方法;掌握 Beautiful Soup 提取静态网页信息的主要技术。
理解网络数据采集的 Robots 协议的基本要求,能合规地进行网络数据采集。
2、要求:
编写一个网络爬虫,爬取某个网站的信息并存储到文件或数据库中。学生既可以使用 Requests/Beautiful Soup 库来实现信息采集,也可以自选其他爬虫技术,对爬取的网站也允许自选,但需要符合相关网站的规定。推荐如下的两个网址,可以选择其中之一采集网页上的信息:
(1)爬取 “中国南海网” 站点上的相关信息。
图1是中国南海网上特定页面(http://www.thesouthchinasea.org.cn/about.html)的部分截图,请爬取该网页中某一栏目的内容并保存在一个TXT文件中,爬取结果如图2所示。


(2)爬取天气网站上的北京的历史天气信息。
图3是天气网关于北京2019年9月份天气信息的部分截图,请爬取该网页(http://www.tianqihoubao.com/lishi/beijing/month/201909.html)中的天气信息并保存在一个 CSV 文件中,爬取结果如图4所示。


二、实验过程
1、观察所爬取网站的Robots协议的相关内容:
https://www.baidu.com/robots.txt

2、网络爬虫抓取网页数据的一般处理过程:
(1)确定目标网站:首先,需要明确自己想要获取哪个网站上的数据。通常情况下,我们需要先通过浏览器访问该网站,并查看其源代码,以便更好地了解其网页结构和所需数据所在位置。
(2)分析目标网站:接着,需要对目标网站进行分析。这包括查看该网站的 robots.txt 文件,了解其对爬虫的限制;查看其页面结构和 URL 规则,以便编写相应的爬虫程序。
(3)编写爬虫程序:在确定了目标网站并分析了其结构后,就可以开始编写爬虫程序了。这需要使用一些编程语言和相关库来实现。在编写程序时,需要注意多线程处理、异常处理等问题。
(4)发送 HTTP 请求:在编写好爬虫程序后,就可以向目标网站发送 HTTP 请求了。这需要使用相应的库或工具来实现。在发送请求时,需要注意设置请求头、代理等参数,以避免被目标网站封禁。
(5)解析 HTML 页面:当爬虫程序成功获取到目标网站返回的响应后,就需要对其进行解析。这需要使用一些 HTML 解析器来实现。在解析页面时,需要注意处理页面中的各种标签、属性等信息,并将所需数据提取出来。
(6)存储数据:在提取出所需数据后,就需要将其存储下来。这可以使用各种数据库或文件系统来实现。在存储数据时,需要考虑数据格式、存储方式等问题。
(7)去重处理:由于同一个网站上可能存在多个相同的页面或数据,因此需要对已经获取过的页面或数据进行去重处理。
三、主要程序清单和运行结果
1、爬取 “中国南海网” 站点上的相关信息
import requests
from bs4 import BeautifulSoup
# 发起请求
url = 'http://www.thesouthchinasea.org.cn/about.html'
response = requests.get(url)
# 解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 查找包含标题为“概说南海”的元素
section = soup.find('h3', text='概说南海')
if section:
# 获取概说南海栏目标题和内容
content = f"{section.get_text(strip=True)}\n\n"
next_element = section.find_next_sibling()
while next_element and next_element.name != "h3":
if next_element.name == "p": # 只获取段落内容
paragraph_text = next_element.get_text(strip=True)
paragraph_text = paragraph_text.replace("[更多]", "")
content += paragraph_text + "\n"
next_element = next_element.find_next()
# 将内容存储到文件中
with open('概说南海.txt', 'w', encoding='utf-8') as file:
file.write(content)
print('“概说南海”内容已成功爬取并保存到概说南海.txt文件中。')
else:
print('未找到“概说南海”栏目的内容。')
用于从指定的 URL(在这个例子中是http://www.thesouthchinasea.org.cn/about.html)爬取标题为“概说南海”的内容,并将这些内容保存到本地文件“概说南海.txt”中。这个过程涉及到发送 HTTP 请求、解析 HTML 内容、文本处理以及文件操作等多个环节。以下是对这个代码的简要分析:
-
发送HTTP请求:使用
requests.get(url)向指定的URL发起GET请求,获取网页内容。 -
解析HTML内容:利用
BeautifulSoup(response.content, 'html.parser')解析服务器返回的内容。这里,response.content得到的是原始的字节流,而'html.parser'是指定的解析器。 -
查找特定元素:通过
soup.find('h3', text='概说南海')查找页面上文本为“概说南海”的<h3>标签,这是定位需要抓取内容的起点。 -
提取并处理内容:从找到的
<h3>标签开始,遍历其后的同级元素,直到遇到下一个<h3>标签为止(或者没有更多同级元素)。在这个过程中,如果遇到的是<p>标签,则提取其文本内容,并去除其中的 “[更多]” 字符串。 -
保存到文件:将处理后的文本内容写入名为
“概说南海.txt”的文件中,文件编码为UTF-8。 -
异常处理:如果在页面中没有找到标题为
“概说南海”的部分,会打印提示信息。
此脚本展示了 Python 在网络爬虫方面的应用,尤其是使用requests库进行网络请求和BeautifulSoup库进行 HTML 解析的实践。
2、爬取天气网站上的北京的历史天气信息
import requests
from bs4 import BeautifulSoup
# 目标网页的URL
url = "http://www.tianqihoubao.com/lishi/beijing/month/201909.html"
# 使用requests库获取网页内容
response = requests.get(url)
# 使用BeautifulSoup解析获取到的网页内容
soup = BeautifulSoup(response.text, "html.parser")
# 在解析后的网页中找到包含天气信息的表格,假设它的class为"b"
weather_table = soup.find("table", class_="b")
# 从表格中找到所有的行(tr元素),跳过第一行(标题行)
rows = weather_table.find_all("tr")[1:]
# 打开(或创建)一个名为"北京天气信息201909.csv"的文件用于写入
with open("北京天气信息201909.csv", mode="w", encoding="utf-8") as file:
# 写入CSV文件头
file.write("日期,温度,天气情况\n")
# 遍历每一行天气数据
for row in rows:
columns = row.find_all("td") # 在当前行中找到所有的单元格(td元素)
date = columns[0].text.strip() # 提取日期数据,并去除两端多余的空白字符
temperature = ' '.join(columns[2].text.strip().split()) # 提取温度数据,将多余的空白字符替换为单个空格
weather = ' '.join(columns[1].text.strip().split()) # 提取天气情况数据,同样将多余的空白字符替换为单个空格
# 将提取的数据写入CSV文件的一行中
# 注意CSV中的数据项通常由逗号分隔,如果数据本身包含逗号,则需要用引号包围该数据项
file.write(f"{date},{temperature},{weather}\n")
# 数据保存完成后打印提示信息
print("天气信息已保存在 北京天气信息201909.csv 文件中。")
这段代码是用 Python 编写的一个简单的网络爬虫脚本,旨在从指定的网页中提取北京市2019年9月份的天气信息,并将提取到的数据保存到CSV文件“北京天气信息201909.csv”中。以下是对代码的简要分析:
-
发送HTTP请求:使用
requests.get(url)向指定的URL发起GET请求,获取网页内容。 -
解析HTML内容:利用
BeautifulSoup(response.text, 'html.parser')解析服务器返回的HTML内容。这里,response.text包含了网页的文本内容,而'html.parser'是指定的HTML解析器。 -
查找特定元素:通过
soup.find("table", class_="b")查找页面上class为"b"的表格元素,用于定位包含天气信息的表格。 -
提取并处理内容:遍历表格中的每一行,提取日期、温度和天气情况数据,并进行适当的清洗(去除空白字符)。
-
保存到文件:将提取的天气信息按照CSV格式写入到名为
“北京天气信息201909.csv”的文件中,每行包含日期、温度和天气情况。 -
CSV文件格式:CSV文件中的数据项通常由逗号分隔,如果数据本身包含逗号,则需要用引号包围该数据项。
-
异常处理:代码中没有显式的异常处理逻辑,如果在实际运行中出现网络连接问题或者页面结构变化,可能会导致程序出错。
请注意,网页的结构和内容经常会发生变化,因此需要定期检查和更新代码以适应目标网站的变化。同时,在实际应用中,也应该尊重网站的robots.txt协议,避免对网站造成不必要的负担。
四、程序运行结果
1、爬取 “中国南海网” 站点上的相关信息
运行结果:
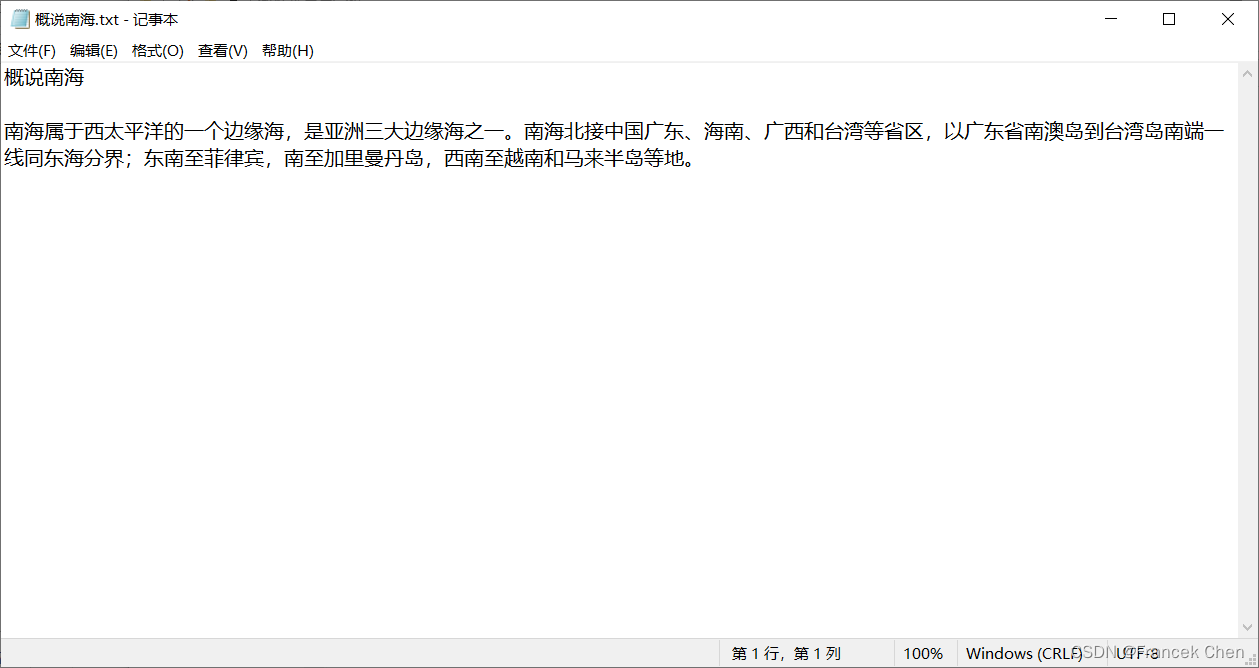
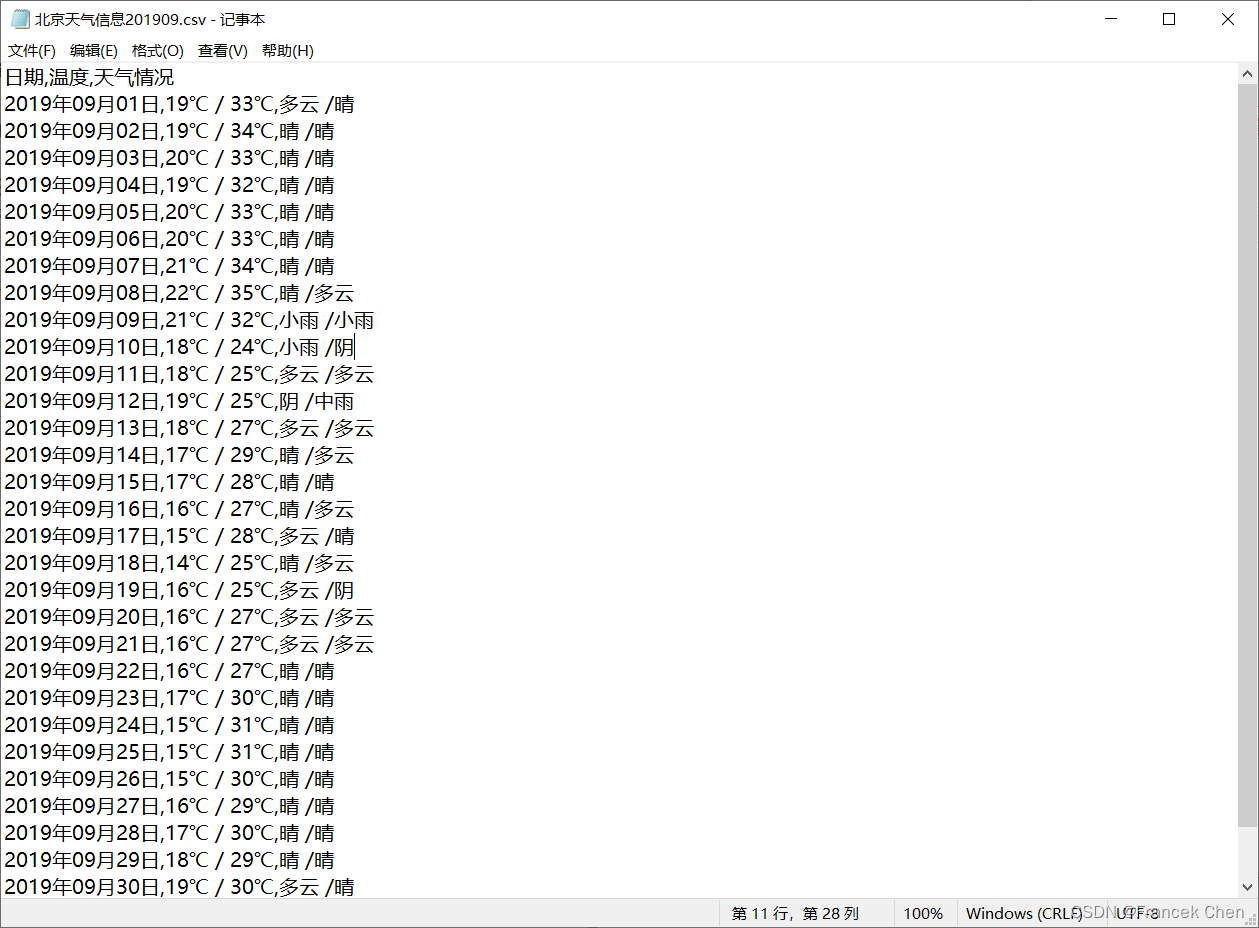
2、爬取天气网站上的北京的历史天气信息
运行结果:
五、实验体会
通过实践,对网络爬虫如何工作有一个直观的认识,包括如何发送 HTTP 请求、如何解析网页内容、如何提取和处理数据等。这个过程能更好地理解网络协议、网页结构(HTML、CSS、JavaScript)以及服务器响应等概念。
在 Python 数据采集与存储实验中,你接触并使用多种第三方库,比如 requests 用于发起网络请求,BeautifulSoup 或 lxml 用于解析 HTML 文档,pandas 用于数据处理,sqlite3 或其他数据库模块用于数据存储等。这些库大大简化了数据采集和处理的过程,提高了开发效率。数据采集后的处理和存储是非常重要的一环。学会如何清洗数据、转换数据格式、有效地存储数据。这包括了解不同数据存储方式的特点,如文件存储(CSV、JSON等)、数据库存储(关系型数据库如 MySQL、SQLite ;非关系型数据库如 MongoDB)等。
在进行网络爬虫实验的过程中,更加深切地意识到遵守目标网站的 robots.txt 协议、尊重版权、保护个人隐私等法律法规和伦理道德的重要性。这不仅是合法合规的要求,也是作为一名负责任的开发者应有的职业操守。









![Spring boot 请求参数包含[]等特殊字符,导致无法接收问题](https://img-blog.csdnimg.cn/direct/96fedd17fa6e4af2bdb791f93c0bdef5.png)